HTR-PM反應(yīng)堆保護(hù)系統(tǒng)軟件可靠性增長模型的研究
2015-05-04 05:40:50劉瑜,李鐸,郭超
原子能科學(xué)技術(shù) 2015年10期
劉 瑜,李 鐸,郭 超
(清華大學(xué) 核能與新能源技術(shù)研究院,先進(jìn)核能技術(shù)協(xié)同創(chuàng)新中心,先進(jìn)反應(yīng)堆工程與安全教育部重點實驗室,北京 100084)
HTR-PM反應(yīng)堆保護(hù)系統(tǒng)軟件可靠性增長模型的研究
劉 瑜,李 鐸,郭 超
(清華大學(xué) 核能與新能源技術(shù)研究院,先進(jìn)核能技術(shù)協(xié)同創(chuàng)新中心,先進(jìn)反應(yīng)堆工程與安全教育部重點實驗室,北京 100084)
研究數(shù)字化反應(yīng)堆保護(hù)系統(tǒng)軟件的可靠性對提高保護(hù)系統(tǒng)的整體可靠性具有重要的意義。本文在分析、整理HTR-PM保護(hù)系統(tǒng)軟件開發(fā)過程中記錄的測試數(shù)據(jù)基礎(chǔ)上,研究并提出了基于錯誤嚴(yán)重程度的軟件可靠性模型。軟件測試過程中不同嚴(yán)重程度的錯誤其檢測難度不同,導(dǎo)致檢測率隨時間的變化趨勢不同,本文提出了嚴(yán)重程度比函數(shù)的概念以表述這一現(xiàn)象,并對不同嚴(yán)重程度錯誤的檢測數(shù)據(jù)分別建模,使軟件可靠性模型的預(yù)測結(jié)果更具有工程應(yīng)用價值。
反應(yīng)堆保護(hù)系統(tǒng);軟件可靠性;錯誤嚴(yán)重程度;軟件可靠性增長模型
反應(yīng)堆保護(hù)系統(tǒng)是核電廠儀表與控制(I&C)系統(tǒng)中最重要的系統(tǒng)之一。隨著技術(shù)的發(fā)展,數(shù)字化系統(tǒng)的技術(shù)優(yōu)勢(如容錯、自檢、信號確認(rèn)、系統(tǒng)診斷等)日益突顯出來,過去的模擬保護(hù)系統(tǒng)已逐步被數(shù)字化保護(hù)系統(tǒng)所替代[1]。由于系統(tǒng)中軟件的存在,數(shù)字化保護(hù)系統(tǒng)具有完全不同的失效原因和失效模式。研究數(shù)字化保護(hù)系統(tǒng)軟件的可靠性具有重要意義。
對于軟件可靠性的研究,國內(nèi)外學(xué)者已發(fā)表了近百種軟件可靠性的評估方法,其中時間域方法被認(rèn)為是應(yīng)用最廣的方法[2]。時間域方法是對過去的失效數(shù)據(jù)建模,以預(yù)測未來。該方法使用單位時間內(nèi)的軟件失效次數(shù)或軟件的失效間隔時間(用日歷時間和計算機(jī)執(zhí)行時間測量)兩種數(shù)據(jù),基于這些數(shù)據(jù),前人已建立了很多數(shù)學(xué)模型來估計軟件的失效率、平均失效時間、可靠性等。由于軟件可靠性隨著測試的進(jìn)行逐漸增加,所以這些基于時域的模型又稱為軟件可靠性增長模型(SRGM)。雖然已有很多相關(guān)的可靠性模型被提出和研究,但這些模型的前提假設(shè)因為研究對象的不同而有所差別,因此,沒有一個模型能成功適用于所有場合。
本文以華能山東石島灣核電廠高溫氣冷堆核電站示范工程(HTR-PM)保護(hù)系統(tǒng)[3-4]的軟件為研究對象,在HTR-PM保護(hù)系統(tǒng)的軟件開發(fā)過程中記錄大量的測試數(shù)據(jù),通過對這些數(shù)據(jù)的整理、分析和建模,研究和分析HTR-PM保護(hù)系統(tǒng)軟件的可靠性增長模型。
1 HTR-PM保護(hù)系統(tǒng)軟件的測試數(shù)據(jù)及分析
HTR-PM保護(hù)系統(tǒng)的軟件開發(fā)過程中積累了大量的測試數(shù)據(jù),這些數(shù)據(jù)反映了每個軟件模塊開發(fā)過程中檢測到的錯誤及其消除的過程。從記錄數(shù)據(jù)的構(gòu)成來看,每個記錄項包括3方面的信息,分別是反映錯誤發(fā)現(xiàn)位置的版本信息、屬性信息和時間信息,如圖1所示。
本文關(guān)注的是測試數(shù)據(jù)記錄項中錯誤屬性的嚴(yán)重程度,HTR-PM保護(hù)系統(tǒng)軟件測試中對每個發(fā)現(xiàn)的錯誤都根據(jù)影響的嚴(yán)重程度不同進(jìn)行等級劃分,分為提示、一般、嚴(yán)重及致命4類。不同嚴(yán)重程度的錯誤除了對運(yùn)行造成不同的損害,也會對軟件測試過程產(chǎn)生不同的影響,如提示性錯誤是軟件語句格式、變量命名方式等方面的錯誤,一般在軟件的靜態(tài)測試階段就可檢測出來,也較容易修改;嚴(yán)重性錯誤是不完全的邏輯、忽略了特殊數(shù)據(jù)邊界等錯誤,需在軟件的動態(tài)測試階段設(shè)計大量的測試用例才能檢查出來,且錯誤的修改也較麻煩。

圖1 軟件測試數(shù)據(jù)記錄項的結(jié)構(gòu)Fig.1 Data field of software test record
為簡化研究模型,將HTR-PM保護(hù)系統(tǒng)軟件測試中記錄的錯誤類別歸為2類:提示和一般類錯誤合并為非關(guān)鍵錯誤;嚴(yán)重和致命類錯誤合并為關(guān)鍵錯誤。同樣以測試日為基本時間(剔除節(jié)假日的工作日)單位,統(tǒng)計兩類錯誤隨時間變化的累計錯誤數(shù)。按上述統(tǒng)計方法,HTR-PM保護(hù)系統(tǒng)軟件模塊A開發(fā)過程中記錄的錯誤數(shù)據(jù)統(tǒng)計如圖2所示(錯誤數(shù)是歸一化后的統(tǒng)計數(shù)據(jù))。

圖2 軟件模塊A的測試數(shù)據(jù)統(tǒng)計Fig.2 Testing data statistics of module A
在傳統(tǒng)的研究中,軟件可靠性增長模型都是基于非齊次泊松過程,通過擬合錯誤檢測的數(shù)據(jù)來尋找可刻畫錯誤發(fā)現(xiàn)過程的均值函數(shù),且大多數(shù)模型均默認(rèn)每個錯誤具有相同的測試努力和策略[5-9]。如前所述,這一假設(shè)在實際的開發(fā)過程中并不完全成立,不同的錯誤,可能會經(jīng)過不同的檢測努力和策略才能從系統(tǒng)中移除。為描述這一現(xiàn)象,有些研究者將錯誤劃分為不同的類型,并分別進(jìn)行處理。Yamada等[10]提出一個改進(jìn)的指數(shù)可靠性增長模型,假設(shè)有兩種錯誤類型,各自的檢測率呈現(xiàn)不同的指數(shù)曲線;Pham[11]進(jìn)一步提出一個可描述多種類型錯誤的可靠性模型;Kapur等[12]提出了一般Erlang模型,建立3種可靠性模型分別擬合簡單、困難、復(fù)雜3種錯誤類型。Tamura等[13]對JM模型進(jìn)行擴(kuò)展,從故障率的角度出發(fā),將錯誤的故障率根據(jù)起因的不同劃分為兩類并分別歸屬以不同的變化趨勢。這些軟件可靠性模型研究中只對軟件的錯誤進(jìn)行了分類研究,未研究不同類別錯誤的相對變化趨勢,即未將分類后的錯誤作為一個整體來研究。本文在研究HTR-PM保護(hù)系統(tǒng)軟件的可靠性模型中提出嚴(yán)重程度比函數(shù)的概念,既考慮軟件測試過程中不同嚴(yán)重程度的錯誤檢測率隨時間的變化趨勢有所區(qū)別,同時對不同嚴(yán)重程度錯誤的數(shù)據(jù)進(jìn)行建模,使軟件可靠性模型的預(yù)測結(jié)果更具有工程應(yīng)用價值。
2 考慮錯誤嚴(yán)重程度分類的軟件可靠性模型
2.1 錯誤嚴(yán)重程度比函數(shù)
在HTR-PM保護(hù)系統(tǒng)軟件測試過程中,關(guān)鍵錯誤與總錯誤數(shù)比的變化具有一定的規(guī)律性,如圖3所示(圖中數(shù)據(jù)取自HTR-PM保護(hù)系統(tǒng)軟件中模塊A的測試記錄)。可看出,隨著測試的進(jìn)行,關(guān)鍵錯誤與總錯誤數(shù)的比近似呈指數(shù)遞減。
為模擬這一變化,定義錯誤嚴(yán)重程度比函數(shù)(SRF)ρc(t)(c=1,2),它表征不同嚴(yán)重程度錯誤的檢測率占總體檢測率的比隨時間的變化情況,ρ1(t)和ρ2(t)分別為關(guān)鍵錯誤比函數(shù)和非關(guān)鍵錯誤比函數(shù)。根據(jù)定義,ρc(t)需滿足:
(1)
根據(jù)SRF的變化趨勢(在測試的初始階段,比例呈指數(shù)變化,之后由于潛在錯誤的減少,比例趨于飽和),可借助Logistic函數(shù)來描述這一變化。
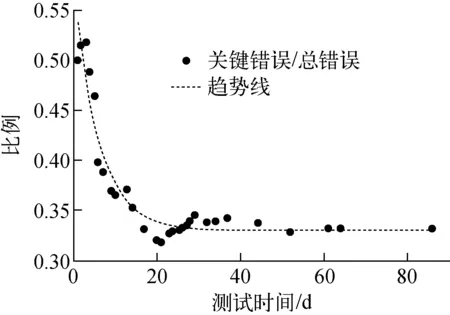
圖3 測試過程中關(guān)鍵錯誤與總錯誤數(shù)比的變化趨勢Fig.3 Ratio tendency of critical fault to total fault during testing
Logistic函數(shù)是一種S型曲線函數(shù),借助Logistic函數(shù),ρc(t)可表示為:
(2)
其中,α和β為Logistic函數(shù)的參數(shù)。式(2)中,當(dāng)β接近于1或α接近于0時,ρc(t)近似于一條直線。
2.2 引入SRF的軟件可靠性增長模型
為構(gòu)建描述不同嚴(yán)重程度錯誤的可靠性模型構(gòu)架,對經(jīng)典軟件可靠性增長模型的假設(shè)進(jìn)行修改和補(bǔ)充,修改后的假設(shè)條件如下:1) 假設(shè)錯誤的檢測過程是泊松過程,到時間t的累積檢出錯誤數(shù)為N(t),則N(t)符合均值函數(shù)為m(t)的泊松分布,單位時間間隔內(nèi)期望的錯誤檢出數(shù)與該時間間隔內(nèi)未檢測出的錯誤數(shù)呈正比,因此,均值函數(shù)為有界非減時間函數(shù);2) 軟件中發(fā)現(xiàn)的錯誤依據(jù)其對失效的貢獻(xiàn)程度劃分為兩類,即關(guān)鍵錯誤和非關(guān)鍵錯誤;3) 每個時間間隔檢測出的錯誤數(shù)是相互獨(dú)立的;4) 錯誤被發(fā)現(xiàn)后立刻修正,且不引入新的錯誤;5) 不同嚴(yán)重程度的錯誤,其在(t,Δt+t)的時間間隔內(nèi),期望的檢測數(shù)與該間隔內(nèi)未檢測出的錯誤數(shù)所呈的比例不同。

(3)
其中,b為錯誤檢測模型中假設(shè)的期望檢出率。
(4)
當(dāng)ρc(t)為定值時,累積錯誤數(shù)的期望函數(shù)可簡單地寫為:
(5)
根據(jù)以上的假設(shè),可建立考慮錯誤嚴(yán)重程度的可靠性增長模型,根據(jù)式(3),在Δt→0時,解微分方程可得到:
(6)
其中,τ為時間積分變量。
從而可解得該模型不同嚴(yán)重程度錯誤累計數(shù)的期望函數(shù)為:
(7)
2.3 錯誤嚴(yán)重程度分類模型的可靠性測度
根據(jù)非齊次泊松過程,可估計軟件失效的可靠度。設(shè)Sj(j=1,2,…)表示第j個錯誤被檢測到的時刻,Xj=Sj-Sj-1為相鄰錯誤出現(xiàn)的間隔時間,則在Sk-1=t的前提下,Xk>x的條件概率即為軟件的可靠度度量,則:
(8)
若到時刻t為止的累計錯誤個數(shù)N(t)服從均值為m(t)的非齊次泊松分布,則有:


(9)
對于不同嚴(yán)重程度的錯誤,可類似推導(dǎo)出其可靠度,即:
Rc(x|t)=exp(-(mc(t+x)-mc(t)))
(10)
2.4 參數(shù)估計
上述考慮錯誤嚴(yán)重程度分類的軟件可靠性模型中含有N、b、α和β4個參數(shù),在參數(shù)估計的研究中使用最小二乘法和最大似然估計法。
1) 最小二乘法
應(yīng)用最小二乘法進(jìn)行參數(shù)估計的優(yōu)點為計算較為簡單,但不能保證估計的無偏性,缺乏統(tǒng)計意義。其估計方程為:
(11)

2) 最大似然估計法
最大似然估計法具有更好的統(tǒng)計意義,算式復(fù)雜,求解難度大。進(jìn)行估計前,需將兩組數(shù)據(jù)的記錄時間轉(zhuǎn)換為相同的間隔,即ti=τj(i=j=1,2,…,k1)。以泊松過程的聯(lián)合概率函數(shù)為似然函數(shù),可得到:
(12)
式中的m1(ti)+m2(ti)為整體期望累計錯誤數(shù)。最大似然估計法的區(qū)間估計可借助Fisher信息矩陣進(jìn)行計算,具體可參閱文獻(xiàn)[14]。
3 實例驗證
實例驗證使用如下方法:選取前部分?jǐn)?shù)據(jù)(包括測試日和對應(yīng)的累計錯誤數(shù))作為擬合數(shù)據(jù),應(yīng)用參數(shù)估計方法得到可靠性模型的參數(shù),基于可靠性模型可預(yù)測剩余的數(shù)據(jù)點。比較預(yù)測數(shù)據(jù)和實際數(shù)據(jù)間的平均方差和決定系數(shù),可評價可靠性模型的誤差。
(13)
決定系數(shù)R2體現(xiàn)了估計結(jié)果和實際數(shù)據(jù)的線性相關(guān)性,R2越大表明擬合的結(jié)果越好。
(14)
評判模型優(yōu)劣的另一個依據(jù)是模型的預(yù)測性能,本文在選取部分?jǐn)?shù)據(jù)進(jìn)行參數(shù)擬合后進(jìn)行一步預(yù)測(x=1),并選用相對誤差作為比較的標(biāo)準(zhǔn),則:
(15)
3.1 模型擬合結(jié)果的比較
將收集到的全部數(shù)據(jù)代入式(7),分別用最小二乘法和最大似然估計法進(jìn)行參數(shù)估計,基于本文模型模塊A的擬合結(jié)果如圖4所示。可看出,最大似然估計法和最小二乘法均可較好地給出不同嚴(yán)重程度錯誤數(shù)的估計,對本文研究的數(shù)據(jù)對象均適用。從90%置信區(qū)間來看,最小二乘法的估計結(jié)果的推斷帶較窄,而最大似然估計法的結(jié)果更偏于保守。表1列出了模型參數(shù)估計和誤差評價結(jié)果,從表1可看出,由于最小二乘法的模型擬合效果的MSEest較小而R2較大,因此其擬合效果更好。
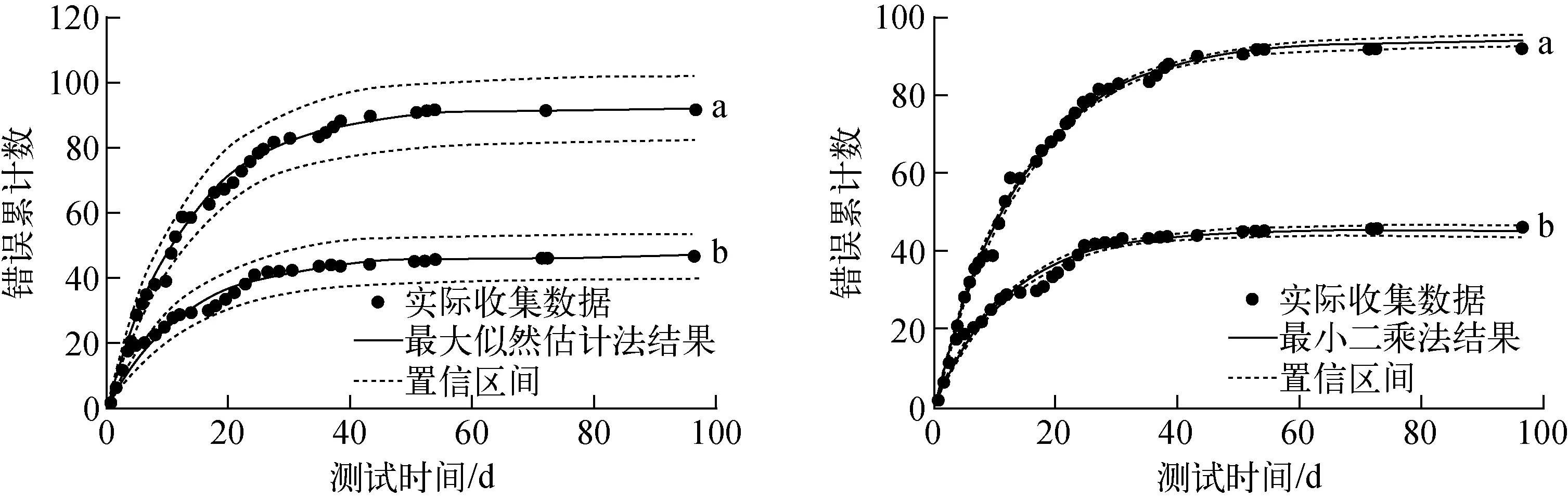
a——非關(guān)鍵錯誤擬合結(jié)果;b——關(guān)鍵錯誤擬合結(jié)果

表1 模型參數(shù)估計和誤差評價結(jié)果Table 1 Model parameters estimation and error evaluation
3.2 模型預(yù)測結(jié)果的比較
為比較兩種估計方法的預(yù)測性能,對數(shù)據(jù)進(jìn)行變結(jié)點預(yù)測。使用部分?jǐn)?shù)據(jù),擬合模型并做出一步預(yù)測,圖5所示為模型的預(yù)測誤差。可看出,最大似然估計法得到的結(jié)果具有更低的預(yù)測誤差,較最小二乘法而言,其在測試早期就已表現(xiàn)出更好的預(yù)測精度。
3.3 錯誤嚴(yán)重程度比函數(shù)的分析
根據(jù)表1中擬合效果更好的最小二乘法參數(shù),可繪制關(guān)鍵錯誤比函數(shù)ρ1(t)的曲線,如圖6所示,ρ1(t)隨測試時間的增大呈指數(shù)衰減。
由圖6可看出,測試后期HTR-PM保護(hù)系統(tǒng)軟件中剩余的關(guān)鍵錯誤已很少,這與工程中軟件測試的實際情況是一致的。本文定義的關(guān)鍵類型錯誤是嚴(yán)重影響軟件功能的錯誤,因此關(guān)鍵錯誤往往更易在測試初期被檢測到,這是因為在遍歷測試用例時,大部分測試用例均將指向關(guān)鍵錯誤引起的失效,測試人員更易發(fā)現(xiàn)這些失效。保護(hù)系統(tǒng)的軟件屬于安全級軟件,在軟件的設(shè)計中對代碼的編程規(guī)范增加了許多限制條件,防止軟件不必要的復(fù)雜性,大部分關(guān)鍵類型錯誤的檢測不需要設(shè)計復(fù)雜的測試用例,因此關(guān)鍵錯誤在測試后期已很少。
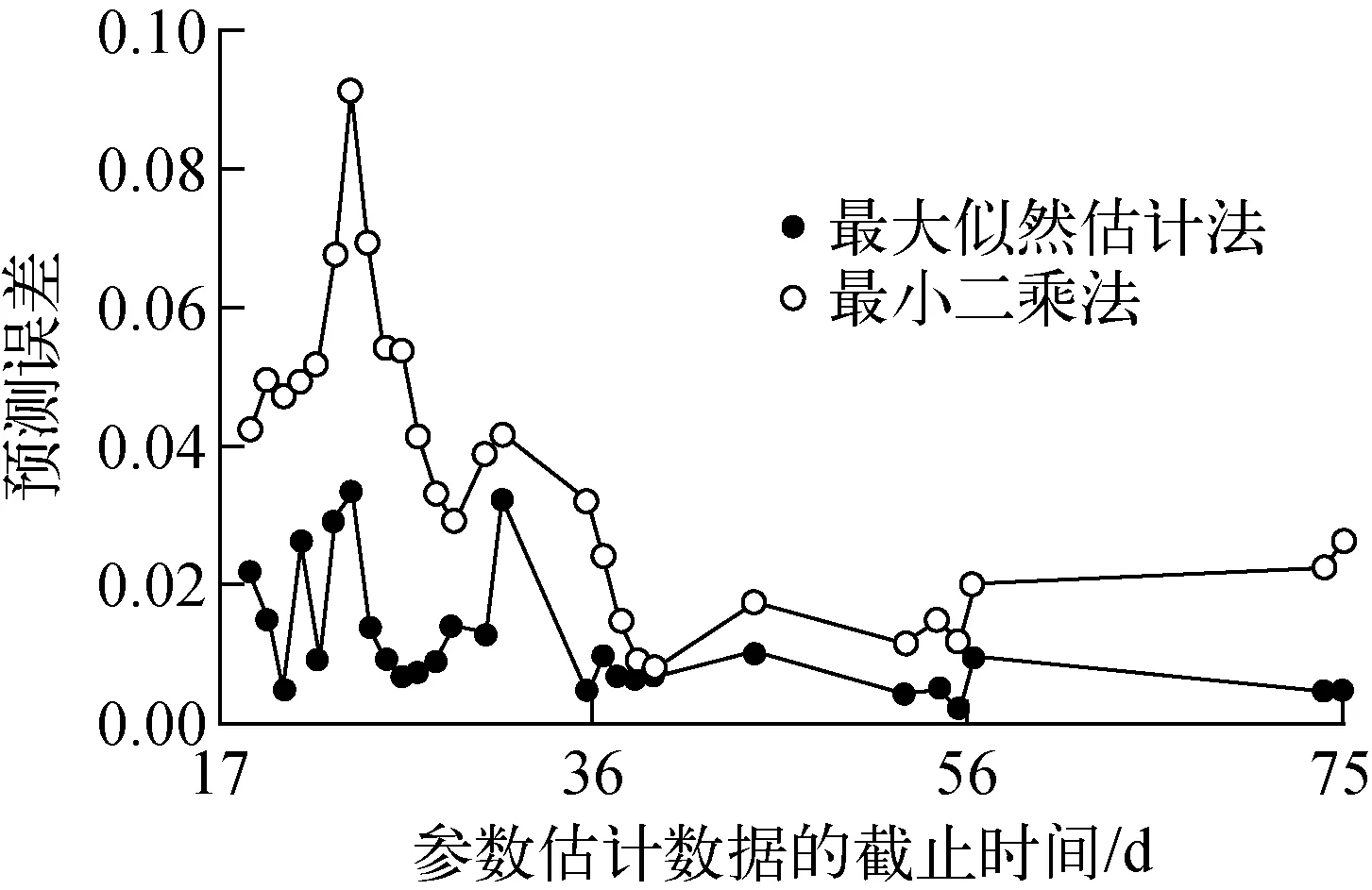
圖5 模型的預(yù)測誤差Fig.5 Prediction error of proposed model

圖6 關(guān)鍵錯誤比函數(shù)曲線Fig.6 Curve of severity rate function of critical fault
4 結(jié)論
研究數(shù)字化保護(hù)系統(tǒng)軟件的可靠性對提高保護(hù)系統(tǒng)的整體可靠性具有重要的意義,本文在分析、整理HTR-PM保護(hù)系統(tǒng)軟件開發(fā)過程中記錄的測試數(shù)據(jù)基礎(chǔ)上,研究并提出了基于錯誤嚴(yán)重程度的軟件可靠性模型。由于在實際測試過程中,不同嚴(yán)重程度的錯誤其檢測的難度不同,導(dǎo)致檢測率隨時間的變化趨勢有所區(qū)別,本文提出了錯誤嚴(yán)重程度比函數(shù)的概念以描述這種現(xiàn)象。考慮錯誤嚴(yán)重程度分類的軟件可靠性模型在傳統(tǒng)可靠性增長模型的基礎(chǔ)上,將某一種錯誤的檢測率轉(zhuǎn)化為隨時間變化的函數(shù),使之更符合實際的測試過程。選用Logistic函數(shù)來擬合錯誤嚴(yán)重程度比函數(shù),通過實驗數(shù)據(jù)分析,其取得了較好的擬合和預(yù)測效果。
[1] ALDEMIR T, STOVSKY M P, KIRSCHENBAUM J, et al. Dynamic reliability modeling of digital instrumentation and control systems for nuclear reactor probabilistic risk assessments[M]. Washington, D. C.: Citeseer, 2007.
[2] LYU M R. Software reliability engineering: A roadmap[J]. IEEE Computer Society, 2007: 153-170.
[3] 郭超,李鐸,熊華勝. 高溫氣冷堆示范工程反應(yīng)堆保護(hù)系統(tǒng)故障樹模型的建立和分析[J]. 原子能科學(xué)技術(shù),2013,47(11):2 063-2 070.
GUO Chao, LI Duo, XIONG Huasheng, et al. Development and analysis of fault tree model of HTR-PM reactor protection system[J]. Atomic Energy Science and Technology, 2013, 47(11): 2 063-2 070(in Chinese).
[4] 李鐸,熊華勝,郭超,等. HTR-PM 反應(yīng)堆保護(hù)系統(tǒng)工程樣機(jī)的研制[J]. 儀器儀表用戶,2013,20(5):36-38.
LI Duo, XIONG Huasheng, GUO Chao, et al. Development of HTR-PM reactor protection system engineering prototype[J]. Electronic Instrumentation Customer, 2013, 20(5): 36-38(in Chinese).
[5] GOEL A L, OKUMOTO K. Time-dependent error-detection rate model for software reliability and other performance measures[J]. IEEE Transactions on Reliability, 1979, R28(3): 206-211.
[6] OHBA M. Inflection S-shaped software reliability growth model[M]∥Stochastic Models in Reliability Theory. Heidelberg: Springer, 1984: 144-162.
[7] HUANG C Y, LYU M R, KUO S. A unified scheme of some nonhomogenous poisson process models for software reliability estimation[J]. IEEE Transactions on Software Engineering, 2003, 29(3): 261-269.
[8] OKAMURA H, DOHI T, OSAKI S. Software reliability growth models with normal failure time distributions[J]. Reliability Engineering and System Safety, 2013, 116: 135-141.
[9] PHAM H. A new software reliability model with Vtub-shaped fault-detection rate and the uncertainty of operating environments[J]. Optimization, 2014, 63(10): 1 481-1 490.
[10]YAMADA S, OSAKI S, NARIHISA H. A software reliability growth model with two types of errors[J]. EDP Sciences, 1985, 19(1): 87-104.
[11]PHAM H. Software reliability assessment: Imperfect debugging and multiple failure types in software development[R]. Idaho: National Engineering Laboratory, 1993.
[12]KAPUR P, GROVER P, YOUNES S. Software reliability growth model with errors of different severity[J]. Computer Science and Informatics, 1995, 25: 51-65.
[13]TAMURA Y, YAMADA S. Reliability assessment based on hazard rate model for an embedded OSS porting-phase[J]. Software Testing Verification & Reliability, 2013, 23(1): 77-88.
[14]LAWLESS J F. Statistical models and methods for lifetime data[M]. New York: John Wiley & Sons, 2011.
Research on Software Reliability Growth Model of Reactor Protection System for HTR-PM
LIU Yu, LI Duo, GUO Chao
(InstituteofNuclearandNewEnergyTechnology,CollaborativeInnovationCenterofAdvancedNuclearEnergyTechnology,KeyLaboratoryofAdvancedReactorEngineeringandSafetyofMinistryofEducation,TsinghuaUniversity,Beijing100084,China)
The research on software reliability of digital reactor protection system (RPS) plays an important role to improve the reliability of RPS. Based on analyzing the fault data set collected during the software development of HTR-PM RPS, a new software reliability model involving the fault severity was studied and established. In the practice detecting faults with different severities usually have different levels of difficulty, and the trend of detecting rate with different severities varies with time. In this paper the severity ratio function (SRF) was proposed, and separate models were developed to deal with faults with different severities. This can achieve better prediction and reflect the software reliability in more aspects for engineering application.
reactor protection system; software reliability; fault severity; software reliability growth model
2014-06-18;
2014-09-28
國家科技重大專項資助項目(ZX06901);清華大學(xué)自主科研計劃資助項目
劉 瑜(1990—),男,山東肥城人,碩士研究生,核科學(xué)與技術(shù)專業(yè)
TL36
A
1000-6931(2015)10-1870-06
10.7538/yzk.2015.49.10.1870
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
