基于MapReduce的Apriori算法并行化研究
2015-05-30 03:25:42謝志明
寧波職業技術學院學報 2015年5期
謝志明


摘 要: 針對目前傳統的Apriori算法對硬件要求較高且運算效率低下的情形,提出將經典的數據挖掘關聯規則算法Apriori移植到云計算平臺,并結合MapReduce機制進行海量數據挖掘,有效地解決了傳統Apriori算法存在的瓶頸問題以及對硬件要求高的依賴。通過數據和節點對比實驗共同驗證了移植后的Apriori算法的運算效率比傳統的Apriori算法提高了許多倍,且隨著數據量和節點數的增加效果愈發明顯。由于改良后的Apriori算法具有高效性和可行性,這將為解決當前大數據挖掘問題提供了一種全新的、有效的解決方案,并且這一結論還可為其他數據挖掘算法的移植提供可靠的參考。
關鍵詞: Apriori算法; 數據挖掘; 關聯規則; 云計算; MapReduce機制
中圖分類號: TP 399 文獻標志碼: A 文章編號: 1671-2153(2015)05-0076-05
0 引 言
傳統Apriori算法是數據挖掘中研究最成熟、最活躍的關聯規則算法之一,利用它可以發現數據中所蘊含的相互關系[1]。由于傳統的數據挖掘算法大多是以單節點的機器為平臺,所處理的數據對象也主要是小到中等規模的,當面對海量的、多維的、分散的數據集合時,現有的算法則往往顯得力不從心[2]。
如何處理異構海量數據,選用那種高效的數據處理模式來提高運算速度并降低內存的消耗,已成為亟待解決的問題。隨著云計算技術和大數據技術相繼提出和應用,分布式大數據處理系統日漸被人們關注和研究。基于Hadoop搭建的云計算平臺具有分布式大數據處理能力和海量的數據存儲能力,這些都將為解決當前異構海量數據挖掘問題提供了一種全新的、有效的解決方案[3-4]。
1 Apriori算法描述及相關研究
Apriori算法原型是以用戶事先設置好的最小支持度(min_support)和最小可信度(min_confidence)為條件,通過對需處理的事務數據集進行重復多次掃描,從中找出項與項之間所存在的并發關系,找到所需的關聯規則和判斷是否滿足用戶要求的過程,即發現頻繁項集和產生規則的過程。如圖1所示。
文獻[5]中說到Apriori算法在掃描數據庫時需經過自連接、剪枝生成頻繁項集,并采用逐層迭代法直到無法產生新的頻繁項集時才停止掃描。文獻[6]解釋了在處理大規模數據時,當設置的最小支持度偏小且產生的頻繁項也較多時,發現該算法效率低下。隨著研究的不斷深入和擴大,人們發現在大規模數據量下傳統Apriori算法的優勢越來越不明顯;相反,在實際應用中很多時候還達不到用戶的要求。于是許多專家學者對該算法做了一些專門的改良實驗,如文獻[7]中提出了一種基于數據劃分的思想用于提高Apriori算法處理海量數據挖掘的效率等。鑒于此,本文將結合分布式大數據處理系統Hadoop,對移植到云計算平臺的Apriori算法進行實驗驗證,證明是否能有效提高數據挖掘效率。
2 Apriori算法并行化描述
Hadoop平臺有自己的分布式文件系統(HDFS),它是Hadoop的核心子項目之一,能對海量數據進行存儲和管理。當數據上傳到HDFS上后,由命名節點(Namenode)統一管理對各個節點文件的訪問。上傳來的大文件將會被分割成一個或多個塊(block),這些block存儲在數據節點(Datanode)集合里,并由Datanode負責調用Map()函數[8]。Hadoop平臺中的Map()函數負責處理局部的數據,對候選項集做本地統計后,然后把統計信息傳到主節點,最后啟動Reduce程序,它負責把Map()函數局部統計統計結果匯總,然后判斷那些是滿足要求的候選項集,即形成頻繁項集[9]。MapReduce Apriori(簡稱Apriori_MR)算法偽代碼如下:
輸入:D(HDFS上的數據), min_support
(1)L1=find_frequent_1-itemsets(D);
(2)for(k=2;Lk-1≠Φ;k++) {
(3)Map1(key,value,Lk-1,X.count),
Map2(key,value,Lk-1,X.count),……,
Mapi(key,value,Lk-1,X.count)
(4)Lk=Reduce(Lk-1,X.count,Lk-1,K.support)}
(5)return L=LUkLk;
輸出:頻繁項目集L
MapReduce Apriori算法處理過程如圖2所示。
3 Apriori_MR算法設計
該算法在MapReduce編程模式中是以鍵值對(Key/Value)的形式進行計算的,計算完畢后也是以鍵值對的形式輸出。在進行MapReduce處理的過程中,Map()函數和Reduce()函數是最為關鍵的兩個函數。如需要實現某些特定功能,可以通過改寫Map()和Reduce()函數來完成。
3.1 Key/Value的設計
表1為定義的Key/Value類型情況。表1中,Map()函數是以Key/Value鍵值對輸入的,期間會產生一系列Key/Value鍵值對并作為中間結果輸出寫入到本地磁盤。MapReduce框架則按照Key值自動聚集原則將具有相同的Key值統一交給Reduce()函數處理。Reduce()函數將這些具有相同的Key進行合并得到相應的Value值,最終產生一個全新的系列Key/Value鍵值對并將結果寫入到HDFS中。
3.2 Map的設計
在Hadoop中,用遠程過程調用(RPC,Remote Procedures Call)的方式來實現各個節點的通信[8]。RPC協議主要作用是將消息編碼為二進制流,該過程是通過序列化方式實現的。在MapReduce編程模型中,用戶的輸入與輸出數據要求Key和Value都必須是序列化的。
Hadoop的序列化核心是Writable,它提供了兩個接口方法來實現二進制格式數據流的寫入和讀出,其特點是快速和緊湊。MapReduce的數據路徑傳遞中最重要的就是Writables,通過重新定義該接口能控制二進制值表示和排序等功能。當使用這個經重新定義過的擴展Writables接口的Frequent類,可以把每次生成的頻繁Lk存儲到類Frequent里面,然后通過算法Apriori_gen(Lk)得到候選項集Ck,最后可以掃描局部的數據得到各個候選項項集Ck中各個項的個數。其偽代碼如下:
map(key, value, Lk, X.count)
{
Ck= Apriori_gen(Lk);
for(i=1;i<=Ck .size();i++) {
if(value中含有Ck中的項)
Ck .item的計算記錄為1;
write(Ck .item, 1); }
}
3.3 Reduce的設計
Reduce的主要工作是將由Map過程所生成的候選項集中每一項的計數通過Reduce函數將相同項的局部計數進行相加,并把滿足用戶最小支持度的那部分寫入到文件中的過程,如圖3所示。
由圖3可以看出,Map()函數在處理數據的過程時,它首先統計每個項的數量,再對每個存在的項記錄一次;而Reduce()函數則僅用于匯總候選集項的數量,其偽代碼為:
public void reduce(Candidate key, Iterablevalues, Context context) throws IOException, InterruptedException {
IntWritable result = new IntWritable();
int sum = 0;
對候選集中相同的項進行計數
for (IntWritable val : values) {
sum += val.get(); }
if ((double) sum >= supportCount) {
result.set(sum);
context.write(key, result); }
}
4 Apriori_MR實驗和結果分析
以下所用到的實驗數據是由人工數據合成工具(IBM Quest Market-Basket Synthetic Data Generator)生成的,它是關聯規則數據挖掘實驗中經常用到的工具。通過數據對比實驗和節點對比實驗來驗證該算法是否具有高效性。
4.1 數據對比實驗
本研究使用了集群里的9個節點做數據測試,數據記錄以文件的形式進行存放,其最小支持度均設為70%,在計算節點不變而數據量變化的情況下進行多組實驗后兩種算法的對照結果如圖4所示。
由圖4可以看出,當數據量在一百萬條記錄期間時,基于MapReduce框架的Apriori算法和經典的Apriori算法所用時間相差不大,然而,隨著數據量的增加,程序運行的時間差距逐漸拉大。產生這種現象的主要原因是,當數據量較少時,通信開銷所占總運行時間比例相對較大,隨著數據量的增多,處理數據的時間占總運行時間比例上升,通信開銷則可以忽略不計。而且在集群環境下可以并發處理數據,加快了數據處理速度。根據數據對比實驗可以得出以下結論:Apriori_MR比傳統的Apriori更適合處理海量數據,且隨著數據量的增加相對單機的優勢愈發顯得明顯。
4.2 節點對比實驗
在此實驗中以加速比(Speedup)作為一個重要的衡量標準。加速比,指的是運用單處理器系統和并行處理器系統來處理同一任務所消耗時間的比對關系,并通過這一對比結果衡量出串行系統與并行系統的性能差。加速比Sp定義如下:
Sp=Ts / Tp,
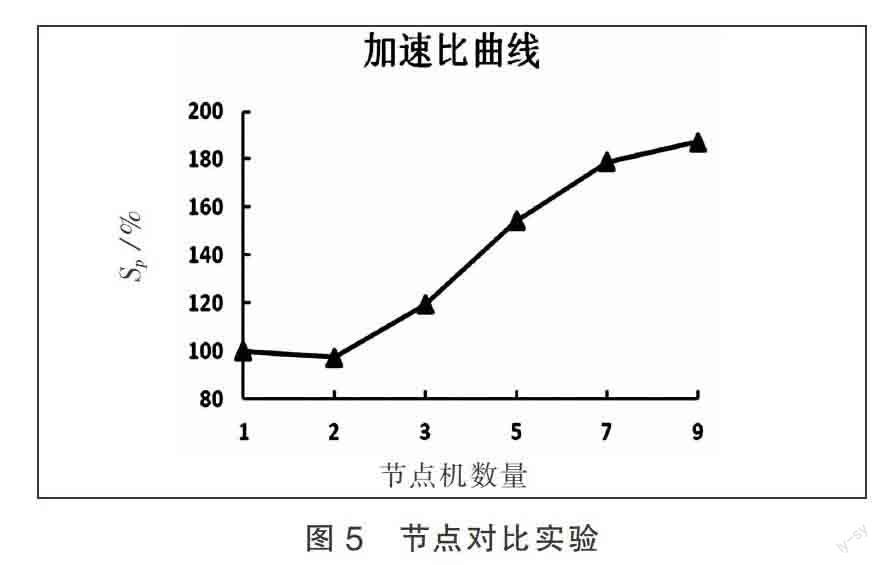
式中:Ts為串行處理時間;Tp為并行處理時間。在實驗中把單一節點機上運行的時間看做Ts,多個節點機上運行的時間看做Tp。根據文獻[10]所提到的MapReduce所具有優點之一是Hadoop集群有很好的伸縮性,能非常方便的將具有計算能力的PC機接入到集群。本實驗將通過改變計算節點來測試移植后的Apriori_MR算法在進行等量數據挖掘的時間差,分析其加速比情況。圖5顯示了1000萬條記錄在不同節點數集群上的測試情況,測試中數據量與支持度一直保持不變。
由圖5可以看出,當節點數小于等于3時,消耗時間的差距不大,主要原因是要考慮到集群的通信開銷。然而,隨著節點數的增加,所花費的時間越來越少,加速比之間的差距也越來越小,按照這種趨勢,加速比曲線會慢慢趨于平穩上升并保持下去。根據節點對比實驗可以得出如下結論:在數據量不變的情況下,當數據節點大于一定數量時,節點數越多,處理速度越快,效率越高。
根據上述兩個對比實驗,在數據量的持續增加和節點數擴展過程中,Apriori_MR算法在數據處理效率和擴展方面表現出良好的性能以及良好的外延性。因此,可以得出如下結論,將傳統的Apriori算法移植到云計算平臺上進行大數據挖掘處理不僅是高效的而且也是行得通的。
5 結束語
云計算目前已經是全球最具有發展潛力的信息類技術之一,如何高效地將傳統的數據挖掘算法移植到云計算平臺上,已成為時下最流行研究的核心領域之一。本文從分析經典的Apriori算法基礎入手,結合云計算平臺和大數據分布式處理技術對該算法加以改進并移植,能有效地解決傳統意義上Apriori算法在數據挖掘過程中遇到的諸多客觀問題。并通過實驗數據、圖形分析證實了Apriori_MR算法要比傳統的Apriori算法在性能上優越許多,該算法的成功移植還進一步為移植更高效的數據挖掘算法提供了可靠的參考。
參考文獻:
[1] 習慧丹. 關聯規則挖掘優化方法研究[J]. 計算機與數字工程,2012,40(5):31-33.
[2] 涂新莉,劉波,林偉偉. 大數據研究綜述[J]. 計算機應用研究,2014,31(6):1612-1616,1623.
[3] 張濱,陳吉榮,樂嘉錦. 大數據管理技術研究綜述[J]. 計算機應用與軟件,2014,31(11):1-5,11.
[4] GONCALVES C,ASSUNCAO L,CUNHA J. Data analytics in the cloud with flexible MapReduce workflows[C]//Proceeding of the 2012 IEEE 4th International Conference on Cloud Computing Technology and Science. Taipei:[s.n.],2012:427-434.
[5] 毛國君,段立娟,王實,等. 數據挖掘原理與算法[M]. 北京:清華大學出版社,2007.
[6] 劉麗. 基于關聯規則的數據挖掘技術綜述[J]. 現代計算機,2011,32(7):25-27.
[7] 段艷明,肖輝輝. 改進Apriori算法處理海量數據的研究[J]. 電腦與信息技術,2013,21(1):22-24.
[8] 董西成. Hadoop技術內幕-深入解析MapReduce架構設計與實現原理[M]. 北京:機械工業出版社,2013.
[9] KOVACS F,ILLES J.Frequent itemset mining on hadoop[C]//Proceeding of the 2013 IEEE 9th International Conference on Computational Cybernetics. Tihany,Hungary,2013:241-245.
[10] 丁祥武,李清炳,樂嘉錦. 使用MapReduce構建列存儲數據的索引[J]. 計算機應用與軟件,2014,31(2):24-28.
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
電腦知識與技術(2016年21期)2016-10-18 23:34:52
電腦知識與技術(2016年21期)2016-10-18 23:24:44
電腦知識與技術(2016年21期)2016-10-18 22:11:15
大學教育(2016年9期)2016-10-09 08:54:03
科技視界(2016年20期)2016-09-29 13:34:06
信息通信技術(2015年6期)2015-12-26 01:16:46
河南科技(2014年23期)2014-02-27 14:18:43
