壓縮對Hadoop性能影響研究*
2015-07-10 01:11:36向麗輝張大方
計算機工程與科學 2015年2期
向麗輝,繆 力,張大方
(湖南大學信息科學與工程學院,湖南 長沙 410086)
1 引言
隨著數據的高速增長,作為海量數據處理的代表性技術,MapReduce[1]思想越來越被重視。Hadoop作為MapReduce的一個開源實現,具有良好的擴展性和容錯性,得到了廣泛的研究與應用。然而,Hadoop在數據處理性能和效率方面與并行數據庫相差甚遠。根據一項實驗表明:在100節點規模上處理簡單查詢,DBMS-X(DataBase Management System-X)平均比Hadoop快了3.2倍,基于列存儲的數據庫Vertica平均比Hadoop快了2.3倍[2,3];如果處理復雜的關聯查詢,數據庫的效率比Hadoop高出一個數量級。如何在保持Hadoop高擴展性和高容錯性等特點的前提下提升Hadoop性能,已經成為一個廣泛關注和研究的問題。
現階段Hadoop性能優化自頂向下主要包括以下四個方面:(1)優化Hadoop應用程序,如減少不必要的reduce階段[4];(2)Hadoop自身的優化,主要包括參數調優[5~7]、優化調度算法[8]和日志監控[9];(3)優化Hadoop的運行環境,如操作系統的配置調優;(4)改善Hadoop運行的基礎設施。目前Intel公司已在致力發展提高Hadoop性能的硬件設備,其中包括使用固態磁盤SSD(Solid-State Drive)技術[10,11]。
多年來,在磁盤存儲容量快速增長的同時,磁盤I/O速度卻未能成比例地加快;現有的網絡帶寬越來越難以滿足人們的需求,I/O常常成為了磁盤與網絡的性能瓶頸。以HDFS(Hadoop Distributed File System)作為分布式文件系統的Hadoop能實現PB級的海量數據存儲,I/O問題更加明顯,因此I/O操作的優化都有可能帶來Hadoop性能的提升。在Hadoop中,由一組配置參數來控制I/O,如塊大小、復制因子、壓縮算法等。這些參數直接影響Hadoop 的I/O性能:塊大小和內存分配對Hadoop性能影響并不十分明顯[12];減少復制因子能大大減少集群的寫操作[13],從而減少磁盤訪問來提高Hadoop性能;壓縮技術是提高文件系統效率的重要手段之一,并行數據庫系統比Hadoop性能好很多的一個重要原因是使用了壓縮。Intel內部測試表明:相比未壓縮,使用LZO的作業運行時間減少60%[4]。從這些方面來看,壓縮是Hadoop I/O調優的一個重要方法。
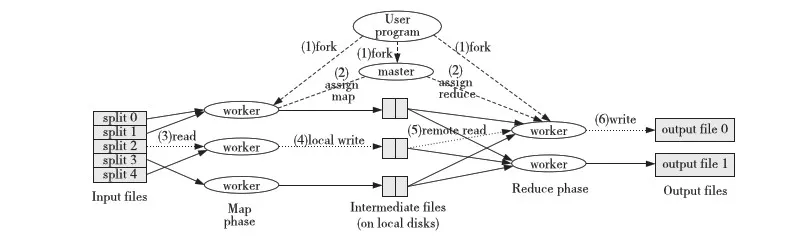
Figure 1 Flow diagram of MapReduce’s working圖1 MapReduce執行流程圖
目前,國內外關于Hadoop壓縮的探討,從作者所知的研究中,只有文獻[12]。 文獻[12]從一個能量角度評估了壓縮的好處:通過對四種不同壓縮比例的數據進行實驗,得出一個以壓縮比例為閾值的決策算法,該算法能平衡CPU代價和I/O收益,實現性能提升。但是,Hadoop輸入數據的壓縮比例是無法預知的,且未考慮壓縮與具體應用之間的關系,也未考慮使用不同壓縮算法。本文探討在輸入數據壓縮比例未知的前提下,如何使用壓縮來提高Hadoop的性能。
文章結構如下:第2節介紹了Hadoop以及Hadoop中的壓縮機制,得出一個壓縮使用策略。第3節搭建集群,對應用使用不同的壓縮配置來驗證策略的正確性,并探討策略在不同的應用、不同的數據格式以及不同的數據規模中的可行性,總結出一個完整的壓縮使用策略。最后,在以上兩節的基礎上,分析了該壓縮策略的優劣,并給出展望。
2 介紹
2.1 關于Hadoop
Hadoop由Doug Cutting即Apache Lucene創始人開發,源于開源的網絡搜索引擎Apache Nutch。用戶可以在不了解分布式底層細節的情況下開發分布式程序。Hadoop實現了一個分布式文件系統HDFS和一個分布式計算模型Hadoop MapReduce。在分布式集群中,HDFS存取MapReduce需要的數據,MapReduce負責調度與計算。兩者都是C/S(Client/Server)的服務模式:在HDFS中,Server為namenode,Client為datanodes;在MapReduce中,Server為master,Client為worker。后者的工作原理如圖1所示[14]:用戶程序首先產生一個master子進程和多個worker子進程;接下來master給各worker分配map任務,將map任務所需的輸入塊地址傳給worker;worker從HDFS中讀取相應的輸入塊,用戶自定義的map函數會處理輸入塊,輸出即中間結果存于本地磁盤;reduce階段再通過網絡讀取相應的reduce輸入,經shuffle/copy 以及sort后的數據由用戶自定義的reduce函數處理,輸出結果存于HDFS中。
2.2 Hadoop中的壓縮
Hadoop通過參數配置來控制壓縮,在配置文件core-site.xml、mapred-site.xml中,可以從以下三個方面來配置壓縮:
(1)壓縮對象:Hadoop允許用戶壓縮任務的中間結果或者輸出,或者對兩者都進行壓縮。同時,Hadoop會自動檢查輸入文件是否為壓縮格式,并在需要時進行解壓縮。
(2)壓縮格式:Hadoop支持的各壓縮格式及特點如表1所示。
在Hadoop-0.20.203版本中,Hadoop自帶三種壓縮格式:Default、Gzip和Bzip2。Default 和Gzip[15]實現的是Lempel-Ziv 1977(LZ77)和哈夫曼編碼相結合的DEFLATE算法,兩者的區別在于Gzip格式在DEFLATE格式的基礎上增加了一個文件頭和一個文件尾。Bzip2[16]采用了新的壓縮算法,壓縮效果比傳統的LZ77/LZ78壓縮算法好。LZO(Lempel-Ziv-Oberhumer)[17]算法實現了以解壓速度著稱的一種LZ77變體,但LZO代碼庫擁有GPL的許可,因而未包含在Apache的發行版中,需要自行安裝、編譯[18]。是否包含多文件:表明壓縮文件是否支持文件邊界處分割,是否可包含一個或多個壓縮文件,當前版本不支持zip,所以各壓縮格式都不支持包含多文件。是否可切分:表示壓縮算法是否可以搜索數據流的任意位置并進一步往下讀取數據,它是處理海量數據時的一個重要屬性。例如一個1 GB的壓縮文件,如果該壓縮文件使用的壓縮算法支持可切分,塊大小為64 MB,該壓縮文件可分割成16塊,每塊都能由一個獨立的mapper處理,從而實現并發。如果該壓縮算法不支持可切分,該壓縮文件只能由一個mapper串行完成。目前,Hadoop支持的壓縮格式中:Bzip2 格式的壓縮文件,塊與塊間提供了一個48位的同步標記,因而支持可切分;LZO格式的壓縮文件,加索引后也支持可切分。
(3)壓縮單元:Hadoop允許對任務的輸出以記錄或者塊的形式進行壓縮,塊壓縮效果更好。
2.2.1 各種壓縮方式的性能
不同壓縮方式有不同的性能表現,Hadoop中各壓縮算法的性能表現如表2所示[19]。

Table 2 Comparison of performance amongdifferent compression algorithms in Hadoop
從表2中可知:在空間/時間性能的權衡中,Gzip/Default居于其他兩個壓縮方法之間,LZO是最快速度壓縮,Bzip2是最優空間壓縮。
2.2.2 關于壓縮的研究
目前,Hadoop 0.20.x和Hadoop 0.23.x是Hadoop版本的兩個分支,其中CDH(Cloud Distribute Hadoop)版本從Hadoop 0.23.x發展而來,而Hadoop 0.20.x是當前的Apache系列[20]。CDH的版本中,Hadoop還支持snappy壓縮算法[21],如需使用snappy壓縮,只需調用snappy的壓縮器/解壓縮器即可。同時,數據壓縮往往是計算密集型的操作,考慮到性能,常使用本地庫(Native Library)來壓縮和解壓,這與HDFS的初衷不謀而合:移動計算要比移動數據便宜。Hadoop的DEFLATE、gzip和Snappy都支持算法的本地實現。
基于以上調研的啟發,可以得出一個壓縮使用策略,即LZO主要用于分布式計算場景,Bzip2主要用于分布式存儲場景。對于壓縮使用策略的正確性與可行性,以下以實驗的方式對其進行驗證補充。
3 實驗
3.1 不同的應用與壓縮的關系
3.1.1 任務和數據
實驗選擇了三個經典的Hadoop基準程序:即Grep、Wordcount和Terasort。這些基準程序都包含map階段和reduce階段,能充分體現壓縮在各階段的作用。同時采用由Teragen產生的10 000 000個記錄(大小為1 GB)來進行實驗。
對于每種壓縮算法,它有多種設置。用0表示不壓縮,1表示壓縮,輸入-中間結果-輸出的配置有0-0-0、0-1-0、0-0-1、0-1-1這四種可能。其中0-0-1、0-1-1又可以分兩種情況,因為輸出結果的壓縮類型分為block和record兩種。每種配置情況下重復運行基準程序10次,取平均值做比較。
集群規模為4,盡管一個4節點的集群規模比較小。一項集群產品的調查表明:70%的MR集群包括不到50臺機器,因此小集群上的發現很容易推廣到更大規模的集群[22]。在本文中,性能是指各benchmark的反應時間。
3.1.2 不同的壓縮配置
為了簡化實驗,除了復制因子為2,其他配置都采用默認配置。Teragen格式下,Grep、Terasosrt和Wordcount采用不同的壓縮配置時運行所需的時間分別如圖2~圖4所示。其中有些算法未配置成0-0-1-r和0-1-1-r,因為實驗需要的是最優壓縮配置,如果0-0-1-b配置下平均運行時間比0-0-1-r配置下少,且0-1-1-b配置下平均運行時間比0-0-1-b配置多,為了簡化實驗,就不再對壓縮方式采用0-1-1-r的配置。
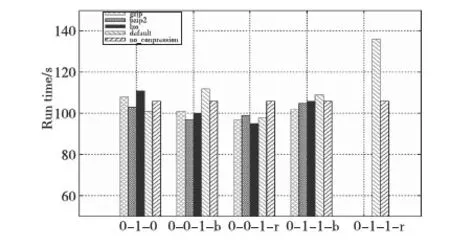
Figure 2 Performance impact of different compression algorithms on Grep圖2 不同壓縮算法對Grep的性能影響
圖2顯示,Grep應用的最優壓縮配置方式為LZO-0-0-1-r,即使用LZO壓縮算法對任務輸出進行記錄壓縮時效率最高。

Figure 3 Performance impact of different compression algorithms on Terasort圖3 不同壓縮算法對Terasort的性能影響
從圖3可知,Terasort應用的最優壓縮配置方式為LZO-0-1-1-r,即使用LZO壓縮算法對任務的中間結果和輸出進行記錄壓縮時效率最高。圖4表明,Wordcount應用的最優壓縮配置方式也為LZO-0-1-1-r。
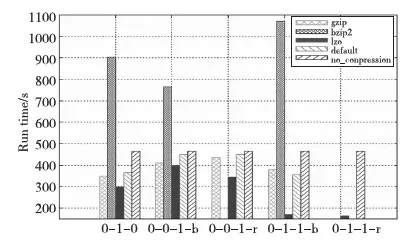
Figure 4 Performance impact of different compression algorithms on Wordcount圖4 不同壓縮算法對Wordcount的性能影響
比較各圖,發現各應用使用合理的壓縮配置后,性能提高了10%~65%,其中以Wordcount使用LZO壓縮算法的表現最為突出。此外,對比HDFS讀、HDFS寫以及shuffle數據,雖然Bzip2情況下I/O最不緊張,但Bzip2壓縮和解壓縮速度慢,壓縮產生的CPU代價大于壓縮帶來的好處。所以在效率方面,LZO最好,Gzip和Default次之,Bzip2最差。對于Terasort、Wordcount這些計算密集型的程序,使用Bzip2的時間是不使用壓縮的兩倍,但使用Bzip2壓縮能節省約90%的空間。所以,壓縮使用策略是正確的,同時記錄壓縮效率高于塊壓縮。
3.2 不同的數據格式對壓縮的影響
Hadoop需要處理的數據類型很多,圖5表示各基準采用由Teragen、Randomtextwriter和Randomwriter產生的1 GB數據作為輸入后,使用最好壓縮配置和不使用壓縮的性能表現。
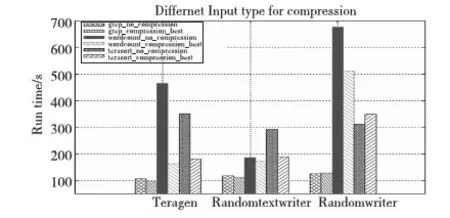
Figure 5 Performance impact of compression_best vs uncompression on benchmarks in different input types圖5 不同格式下最好壓縮與不壓縮對各基準的性能影響
對于不同的數據格式,各benchmarks性能效率變化如表3所示。

Table 3 Change of Benchmarks’ performance efficiencyunder different data formats
從表3可以看出,三種不同的數據格式下,benchmarks在Teragen數據格式下性能提高得最多,Randomtextwriter次之,Randomwriter最差。若對Teragen、Randomtextwriter和Randomwriter生成的文件分別采用Gzip壓縮,壓縮比例分別為0.13、0.25、1。因而可以得知:隨著壓縮比例的增大,各benchmarks使用壓縮的性能逐漸下降。其次, Randomtextwriter數據格式相比于Teragen:Grep和Terasort性能小幅度下降的同時,Wordcount性能降低了16倍,而Wordcount的輸出減少了20倍。因為數據格式的不同,會使得同一應用的中間結果和輸出不同,所以最好的壓縮配置帶來的效益也不一樣。同樣在Randomwriter格式下,Wordcount采用壓縮性能提高了24%,而Grep和Terasort分別下降3%和12%,結合未壓縮的輸入和壓縮后的輸出,發現該數據格式下,采用壓縮后Wordcount的輸出約為輸入的兩倍。因此:不使用壓縮時,若輸出遠小于輸入,即使數據可壓縮比例高,性能不會大幅度提升;當輸出大于或等于同比例規模的輸入且數據可壓縮比例高,在本實驗中性能可提高35%;即使數據可壓縮性不高,如果輸出大于輸入的同比例規模,壓縮也能提高性能。因此,壓縮還是不壓縮,輸出大小是非常重要的,原因在于壓縮的屬性是針對中間結果和輸出設置的。從輸出大小可以判斷中間結果的大小:如果輸出規模大,reduce前的中間結果不會小。無論對中間結果還是輸出進行壓縮,需要一定的數據規模才能體現壓縮的價值。而輸出如何本質上由數據格式和Hadoop應用程序共同決定。
3.3 不同數據規模對壓縮的影響
Hadoop通常處理的數據規模很大,壓縮使用策略是否適用于大規模數據?圖6是Wordcount運行由Teragen產生的1 GB、5 GB和10 GB數據的性能表現。實驗環境為四個節點的集群,系統存儲能力為70 GB,復制因子為1。從圖6中可以看出:1 GB、5 GB和10 GB的數據,最好壓縮配置使得程序運行的效率分別提高了53%、60%和55%。前兩個數據規模之間,壓縮帶來的效率是成上升狀態,原因首先在于數據規模越大,壓縮的效果更加明顯;其次,在數據增長的過程中,資源特別是CPU資源充足。后兩個數據規模之間,壓縮帶來的效益有所下降,主要原因是數據增倍,壓縮占用的CPU資源越來越多,集群資源出現了緊張狀態。因此,數據規模在一定程度上能使壓縮效益顯著,但數據越大,壓縮會占用更多的CPU資源,這樣會降低壓縮效益。
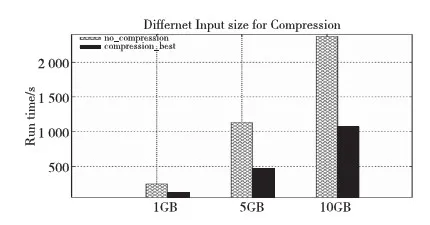
Figure 6 Performance of compression_best vs uncompression to Wordcount in different sizes圖6 不同數據規模下最好壓縮與不壓縮對Wordcount的性能影響
3.4 壓縮使用策略
通過實驗,首先驗證了壓縮使用策略:即一個應用采用不同的壓縮方式時,使用LZO壓縮最好,因為LZO是當前最快速度壓縮,Bzip2雖然壓縮效果好,但壓縮速度慢,所以Bzip2壓縮算法適合分布式存儲的場景,而LZO壓縮算法適合分布式計算的場景;同時記錄壓縮比塊壓縮效率更高,雖然塊壓縮效果好,但速度慢;其次,不同數據格式代表不同的輸入類型,輸入的壓縮比例越大,使用壓縮帶來的性能會逐漸下降,對于類似圖片、視頻、音頻這些不可壓縮的數據,使用壓縮不一定能提高性能;對于不同的數據規模,發現數據規模越大,壓縮的效益越明顯,但數據規模增大到一定程度,壓縮使用的CPU資源過多所以效益會下降;最后同一種壓縮方式對不同應用的影響不同,因為不同的應用會產生不同數據規模的中間結果和輸出,在Hadoop中,相對輸入,對數據規模很少的中間結果和輸出進行壓縮是沒意義的。
因此,得出以下壓縮使用策略:首先,針對應用類型,若僅為存儲,則使用Bzip2進行壓縮存儲,數據存儲之后再用來計算的,則使用LZO壓縮,并建立相應索引,雖然Bzip2也支持可拆分,但它的解壓速度大大慢于LZO;若為計算型應用,則首選LZO。其次,輸入數據的可壓縮性是無法預知的,所以根據負載來進行判斷:選取小部分負載,運行相應的程序,對于文本類型的輸入,如果運行后它的輸出大于輸入,那么采用中間和輸出都采用LZO壓縮;如果輸出遠小于輸入,再或者是圖片、視頻類型的輸入,不建議采用壓縮,同時在數據庫中建立負載檔案,將其壓縮配置存于檔案中,以便運行相同負載時使用;最后,計算應用場景中,首選記錄壓縮。由此可以非常簡單地決定壓縮或不壓縮以及使用何種壓縮。對Hadoop的sort基準使用該壓縮策略,由于sort基準是計算類型的應用,所以選擇LZO記錄壓縮,當輸入是與圖片壓縮比例類似的Randomwriter隨機數文件時,壓縮策略為不使用壓縮。實驗表明:該策略比使用最好壓縮配置的性能提高了26%。
4 結束語
本文分析了Hadoop文件壓縮方式及其特點,得出一個壓縮使用策略,通過實驗分析了不同的文件壓縮方式對Hadoop性能的影響,以及壓縮使用策略在不同數據格式和不同的數據規模下的可行性,從而對壓縮使用策略進行驗證補充。雖然本文的實驗結果很容易拓展到大規模的數據處理,但不同的應用使用壓縮的表現不一樣,同時未考慮對中間結果和輸出分別采用不同的壓縮算法進行測試。希望未來可以通過監控不同負載在Hadoop集群上的運行情況,分析壓縮帶來的CPU成本、量化壓縮的代價和收益,得到一個決策算法來決定如何合理使用壓縮。同時對已有的壓縮算法進行改進:如LZO需要建立索引才能切分,則可以設計一個簡化版的LZO算法,即使用定長的壓縮塊來避免建立索引的開銷;或者研究雙壓縮策略,對存儲類型的數據采用Bzip2壓縮來減少空間,對計算類型的數據采用LZO壓縮或者snappy壓縮來提高速度。
[1] Dean J, Ghemawat S. MapReduce:Simplified data processing on large clusters [J]. Communications of the ACM, 2008, 51(1):107-113.
[2] Abouzeid A, Bajda-Pawlikowski K, Abadi D, et al. HadoopDB:An architectural hybrid of MapReduce and DBMS technologies for analytical workloads [J]. Proceedings of the VLDB Endowment, 2009, 2(1):922-933.
[3] Stonebraker M, Abadi D, DeWitt D J, et al. MapReduce and parallel DBMSs:Friends or foes?[J]. Communications of the ACM, 2010, 53(1):64-71.
[4] Xin Da-xin,Liu Fei.Hadoop cluster performance optimization technology research [J].Computer Knowledge and Technology, 2011, 7(8):5484-5486. (in Chinese)
[5] Herodotou H. Hadoop performance models [J]. arXiv preprint arXiv:1106.0940, 2011:1-16.
[6] Babu S. Towards automatic optimization of MapReduce programs[C]∥Proc of the 1st ACM Symposium on Cloud Computing, 2010:137-142.
[7] Herodotou H, Babu S. Profiling, what-if analysis, and cost-based optimization of MapReduce programs [J]. Proceedings of the VLDB Endowment, 2011, 4(11):1111-1122.
[8] Zaharia M, Borthakur D, Sarma J S, et al. Job scheduling for multi-user mapreduce clusters[R]. Berkeley:Technical Report USB/EECS,EECS Department, University of California, 2009.
[9] Boulon J, Konwinski A, Qi R, et al. Chukwa, a large-scale monitoring system[C]∥Proc of CCA, 2008:1-5.
[10] Claburn T.Google plans to use Intel SSD storage in servers [EB/OL]. [2008-07-02]. http://www.informationwee- k.com.
[11] Wong G. SSD market overview [M]. Netherlands:Springer, 2013.
[12] Chen Y, Ganapathi A, Katz R H. To compress or not to compress-compute vs. I/O tradeoffs for mapreduce energy efficiency[C]∥Proc of 1st ACM SIGCOMM Workshop on Green Networking,2010:23-28.
[13] Chen Y, Keys L, Katz R H. Towards energy efficient mapreduce [R]. EECS Department, University of California, Berkeley, Tech. Rep. UCB/EECS-2009-109, 2009.
[14] White T. Hadoop:the definitive guide [M]. California:O’Reilly Media, 2012.
[15] wiki. Gzip[EB/OL]. [2013-6-24]. http://zh.wikipedia.org/wiki/Gzip.
[16] wiki. Bzip2[EB/OL]. [2013-6-24]. http://zh.wikipedia.org/wiki/Bzip2.
[17] wiki. LZO[EB/OL]. [2013-3-12]. http://zh.wikipedia.org/wiki/LZO.
[18] Kevinweil.Hadoop/LZO[EB/OL].[2011-03-11]. https://github.com/kevinweil/Hadoop-lzo.
[19] Ggjucheng. The compressed file supported by Hadoop and the advantages and disadvantages of algorithm[EB/OL]. [2012-04-23].http://tech.it168.com/a2012/0423/1340/000001340446.shtml. (in Chinese)
[20] Hadoop A. Hadoop [EB/OL]. [2009-03-06]. http://hadoop.apache.org.
[21] wiki.Snappy[EB/OL].[2013-8-31].http://en.wikipedia.org/wiki/Snappy_%28software%29.
[22] wiki.Hadoop Power -ByPage [EB/OL].[2011-03-11]:http://wiki.apacheorg/Hadoop/Powered By.
附中文參考文獻:
[4] 辛大欣, 劉飛. Hadoop 集群性能優化技術研究 [J]. 電腦知識與技術, 2011, 7(22):5484-5486.
[19] Ggjucheng.Hadoop對于壓縮文件的支持及算法優缺點[EB/OL].[2012-04-23].http://tech.it168.com/a2012/0423/1340/000001340446.shtml.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
