融合實用性與科學性的互聯網信息分類體系構建*
2015-08-10 06:01:26路永和彭燕虹中山大學資訊管理學院廣東廣州510006
圖書與情報 2015年3期
路永和 彭燕虹(中山大學資訊管理學院 廣東廣州 510006)
·信息組織與服務·
融合實用性與科學性的互聯網信息分類體系構建*
路永和彭燕虹
(中山大學資訊管理學院廣東廣州510006)
摘要:
分類體系是信息組織的有效形式,傳統文獻分類體系難以適用分類對象的轉變,實用性不足,已有的網絡分類體系則缺乏科學性。構建融合實用性與科學性的互聯網信息分類體系,能夠有效滿足用戶信息需求,且是自動文本分類技術研究的基礎。文章分別以中圖法、新浪門戶為例,研究傳統文獻分類法與網絡信息分類法的優缺點,提出互聯網信息分類體系的實用性、科學性以及均衡性設計原則,基于三個設計原則構建了互聯網信息分類體系。為了驗證所構建的分類體系的有效性,通過網絡爬蟲抓取網易門戶以及騰訊網的語料作為實驗數據,與復旦語料庫的分類體系進行對比實驗。實驗結果表明,相比于復旦語料庫的分類體系,文章所提出的互聯網信息分類體系具有更高的實用性,且能更為全面地涵蓋各種互聯網信息,類目之間交叉度小,各個類目信息量接近,文本分類效果更為理想。關鍵詞:
互聯網信息;分類體系;中圖法;語料庫伴隨著網絡信息的指數增長,海量信息所帶來的信息冗余,使得越來越多的信息用戶無法有效獲取所需信息。特別是在用戶無法明確得知關鍵詞以進行信息檢索的情況下,如何幫助用戶在信息海洋中更加快速有效地獲取需求信息,具有一定的研究價值。信息分類是信息組織的有效途徑之一,以中圖法、杜威分類法為代表的傳統文獻分類體系能夠有效組織大量的文獻信息,網絡環境下以各個門戶網站分類體系為代表的網絡分類體系可以組織海量的網絡信息,但傳統文獻分類體系過分強調類目體系嚴謹科學,體系龐大、術語生僻;網絡分類體系注重體系實用性,但存在措詞隨意,類目之間科學性欠佳等問題。良好的分類體系是實現自動文本分類的基礎,如果能對網絡中的文檔進行處理,使其形成良好的分類,有助于人們組織、挖掘、檢索文本信息。同時,伴隨著文本分類技術的發展,越來越多的學者迫切需要文本分類語料庫以支撐其實驗研究,而最便捷最龐大的語料獲取來源即為互聯網,但這些互聯網信息需要一個有效的分類體系將其囊括。分類體系作為構建文本分類語料庫的前提,分類體系的好壞,直接影響了一個文本分類語料庫的優劣,繼而影響自動文本分類技術的研究。構建融合實用性與科學性的互聯網分類體系,除了能夠有效滿足用戶信息需求這一實用性要求,還能夠促進自動文本分類技術的進步。
1 分類體系研究
一直以來,學者們都試圖尋找一個更適用于互聯網環境的分類體系。陳樹年、張琪玉等先后提出過互聯網環境下的分類體系框架,主要劃分了一、二級類目,力求涵蓋所有互聯網信息,但其分類體系過多直接引入傳統文獻分類法的類目,如陳樹年的體系大綱中所出現的“圖書館與參考資料”、“工程技術”等類目,且較少考慮現實情況下的網絡信息資源分布,體系重點不明晰,與用戶直接使用的指南性網絡分類體系有所不同。反觀現有的門戶網站分類體系,其基于點擊率構建、體系適用范圍較窄、類名措詞隨意性大、歧義度高、類目之間交叉明顯、網絡信息混亂、用戶查找困難重重。不僅導致用戶在瀏覽不同網站的過程中存在明顯的閱讀障礙,更使得用戶無法通過分類體系有效獲取所需信息,常常出現如點擊某一類目后,出現大量與需求信息完全無關的內容等問題。由傳統文獻分類體系直接改造而來的分類體系框架以及各個門戶網站的自編分類體系,無法有效應對海量網絡信息環境下的用戶信息需求,建立通用性高、更加符合網絡信息資源分布現狀、適合網絡信息組織與傳播的互聯網信息分類體系具有一定的現實意義。
傳統文獻分類法與網絡信息分類法的分類對象不同決定了傳統文獻分類法對于互聯網信息的不適用性,但兩者都是對于知識、信息的組織,這一共性決定了網絡信息分類能夠借鑒傳統文獻分類法。傳統文獻分類法一般以學科為中心建立分類體系,將有關主題的文獻集中到學科之下,如《中國圖書館分類法》(下文簡稱中圖法)。傳統文獻分類體系更傾向于科學性,依據學科屬性進行知識體系組織,強調類目體系覆蓋全面、穩定,類目命名準確嚴謹。但存在結構過于龐大、缺乏簡明性,劃分太細、缺乏實用性,操作復雜、缺乏易用性,體系僵化、缺乏靈活性,單線排列、缺乏多維性等多種問題。而網絡分類法以主題為中心或主題結合學科的方式組織分類體系,如新浪門戶、網易采用主題與學科結合方式,建立以事物對象為中心的分類體系。網絡信息分類法更傾向于依據用戶需求來設置類目體系,特別是某些實用性很強的網站,如淘寶網。網絡信息分類體系具有更高的實用性,類目名稱通俗易懂,但存在著類目交叉明顯,如“新聞”一級類目下的“國內”、“深度報道”,用戶無法明確選擇哪個渠道點擊瀏覽信息,降低網站訪問效率,科學性明顯不足。對此不少學者提出了自己的建議,陳樹年提出建立網上信息的知識分類系統,必須遵循面向網絡信息資源、面向網絡技術環境、面向網絡用戶的原則,突出其實用性和易用性。黃如花提出網絡信息組織模式應該以用戶為中心,遵循實用性和易用性原則,綜合運用自然語言和人工語言(分類語言、主題語言),充分利用新興技術和人們經驗的積累。王麗珺等提出網絡信息分類體系應具備動態性、多維性、實用性和易用性原則。鄭慶勝等認為在構建網絡信息分類體系時應注意分類體系的實用性、全面性、規律性、統一性和特殊性。
2 分類體系設計原則
基于上述對傳統文獻分類法與網絡信息分類法的綜合分析,并考慮到網絡分類體系分類對象的轉移以及當前網絡信息本身所呈現的特點:數量多、內容龐雜;變化快、穩定性差;類型多、范圍寬、用途廣;信息組織特殊、控制性差,本文采用以事物對象為中心的方式構建知識體系,并繼承傳統分類體系科學性、類目體系全面的優點,進一步改進和完善現有網絡信息分類體系設計原則,總結提出以下三個原則:(1)實用性原則,即要求類目設置方便用戶使用。各大門戶在設立分類體系時一個重要的原則就是方便網絡用戶的查找,互聯網分類體系區別于傳統文獻分類體系,其目的是有效地組織網絡信息,并最大效能地滿足網絡信息用戶的需求。只有滿足實用性,才能制定出更加符合用戶需求的體系,使用戶更快更準地查詢到需要的信息;(2)科學性原則,其要求類目體系不僅能夠全面涵蓋幾乎任何主題的網絡信息,且各個類目具有明顯主題范圍,能夠明顯區分類目的主題內涵與外延,大類與子類之間具有邏輯性。目前大部分的互聯網分類體系只是基于其本身網站的點擊率設計,類目體系全面性不足,大量互聯網信息無法實現有效分類,大大弱化了信息的利用率;同時,大量類目重復設置,影響了用戶的準確判斷。堅持科學性原則,有利于構建更完善的互聯網分類體系,且各個類目特征明顯,類目上下級符合邏輯,有助于后續語料收集、語料訓練等機器自動學習的實現;(3)均衡性原則,即要求分類體系各個類目訪問頻率相近。從信息論角度來看,可以把網站信息分類體系類比為一個信息通道。一般來說,通道的利用率要高,這要求每個類別包含的元素要盡量均衡,即內容多分得細,內容少分得粗。若不引入類目體系均衡原則,則可能有的類目只有兩三層,有的類目則多達十幾層,有時用戶從分類途徑查找某個類名,往往要鏈接十多個頁面,既費時又費力。堅持類目體系均衡原則,有助于體系更加簡潔、更加方便。
3 互聯網信息分類體系構建
以分類體系設計原則為基礎,構建初步互聯網信息分類體系。在初步分類體系基礎上,采用網絡爬蟲從新浪網抓取不同頻道的信息并人工識別后將其作為訓練語料和測試語料,進行文本分類實驗測試。依據測試結果,對初步互聯網信息分類體系進行修改調整,最終得到各個一級類目分類準確率均高于90%的互聯網信息分類體系。該分類體系共有13個一級類目,各個一級類目之下具有2-8個二級類目(見表1)。
4 互聯網分類體系有效性實驗
為了檢驗此分類體系對于互聯網信息的有效程度,我們利用目前已有的文本分類體系進行對比實驗。目前采用網絡信息作為語料測試文本分類效果的分類體系主要有:復旦大學文本分類語料庫的分類體系(以下簡稱復旦分類體系)和搜狗文本分類語料庫的分類體系(以下簡稱搜狗分類體系)。復旦分類體系包含20個類目:Art、Literature、Education、Philosophy、History、Space、Energy、Electronics、Communication、Computer、Mine、Transport、Enviorn-ment、Agriculture、Economy、Law、Medical、Military、Politics、Sports。搜狗分類體系包含9個類目:IT、財經、健康、教育、軍事、旅游、體育、文化、招聘。由于搜狗分類體系的類目較少,類別全面性不足,諸如娛樂、游戲等相關主題的語料,無法被涵蓋,因此本文采用類目更為全面的復旦分類體系作為實驗對比體系。

表1 互聯網信息分類體系
4.1實驗流程
首先通過網絡爬蟲抓取語料,并將抓取的語料依據不同分類體系進行人工分類,將人工分類所得語料分為訓練集與測試集;最后應用文本分類技術,采用KNN分類器進行分類測試。采用KNN分類過程中,主要利用余弦相似度計算以計算各個文本向量空間,設定閥值為20%,即測試文檔與類目之間相似程度超過20%,則輸出該類別。依據測試文檔與不同類目相似程度的不同,按照相似程度從高到低排序,得到測試文檔的第一相似類目、第二相似類目和第三相似類目。考慮到當前一個互聯網信息文檔中涵蓋多種主題的現實情況,故而將第一相似類目、第二相似類目、第三相似類目統稱前三相似類目,能夠有效反映語料的真實分類情況。因而,在傳統的文本分類評價指標——分類準確率的基礎上進行擴展,提出了兩個分類準確率評價指標,包括第一相似類目分類準確率(即傳統的文本分類分類率,見公式1)以及前三相似類目分類準確率(見公式2)。具體實驗流程如圖1所示。

4.2實驗數據
由于本文互聯網信息分類體系主要參考中圖法和新浪網分類體系構建,為保障對比所用語料公平性,本文實驗采用的語料來自網易門戶與騰訊網,通過網站首頁層層遍歷抓取,保證實驗語料能真實反映網絡語料分布現狀,抓取所得語料總數為21614條。
抓取所得的語料,需先進行人工分類,即通過人工識別某一語料歸屬于哪個類目,以作為可用的語料,剔除不可用的語料,得到實驗所需的語料集。其中,可用語料率=該體系可用語料數量/抓取所得語料總數量。人工分類統計后,可得到復旦分類體系與互聯網信息分類體系的語料情況(見表2)。
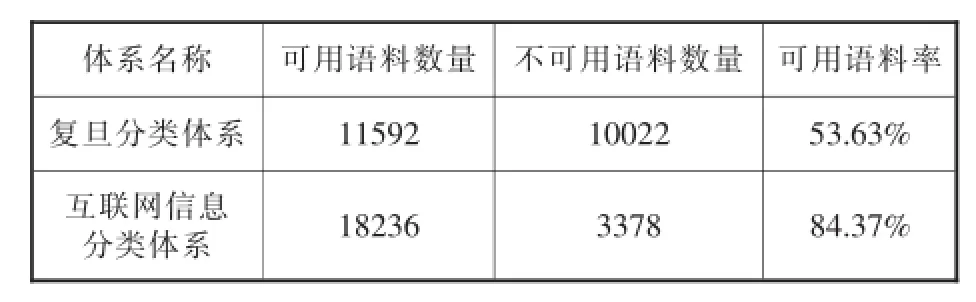
表2 復旦語料庫的分類體系與互聯網信息分類體系的語料情況
由語料情況可知,復旦分類體系可用語料率僅為53.63%,大量娛樂、游戲、時尚、神秘學等相關互聯網信息無法找到相應類目;而互聯網信息分類體系可用語料率達84.37%,無法分類的語料主要集中為語料涵蓋主題過多,人工無法明確識別類目的語料。因而,相比于復旦分類體系,本文構建的互聯網信息分類體系實用性更高,具有包括娛樂、游戲、時尚等多個復旦語料庫分類體系所沒有的類目,符合實用性原則;同時,也體現出互聯網信息分類體系能夠更加全面的覆蓋多種互聯網信息,符合科學性原則所要求的類目體系全面。
本文實驗中的訓練語料、測試語料依據各個類目語料總數大約1:1劃分,根據抓取信息的實際情況,不同類目的訓練語料、測試語料數量有所不同。復旦語料庫分類體系總訓練語料數為5802條,總測試語料數為5790條(具體情況見表3);互聯網信息分類體系總訓練語料數為9142條,總測試語料數為9094條(具體情況見表4)。
由訓練與測試情況可知,復旦分類體系各個類目的語料數量差異較大,語料數量多于1000的類目僅有3個,語料數量低于200的高達11個,相應其訓練語料數量將低于100,會極大的影響后續文本分類實驗;相比于復旦分類體系,互聯網信息分類體系各個類目的語料數量較為均衡,語料數量多于1000的類目有7個,語料數量低于200的僅有2個。由此可知,互聯網信息分類體系各個類目包含的語料數量相對比較均衡,諸如“復旦分類體系”中劃分的Military(軍事)、Politics(政治)類目在互聯網信息分類體系中,均為event(時事)的子類,而互聯網信息分類體系的訓練集、測試集情況也顯示Military(軍事)、Politics(政治)類目語料數量較少,符合均衡性原則。
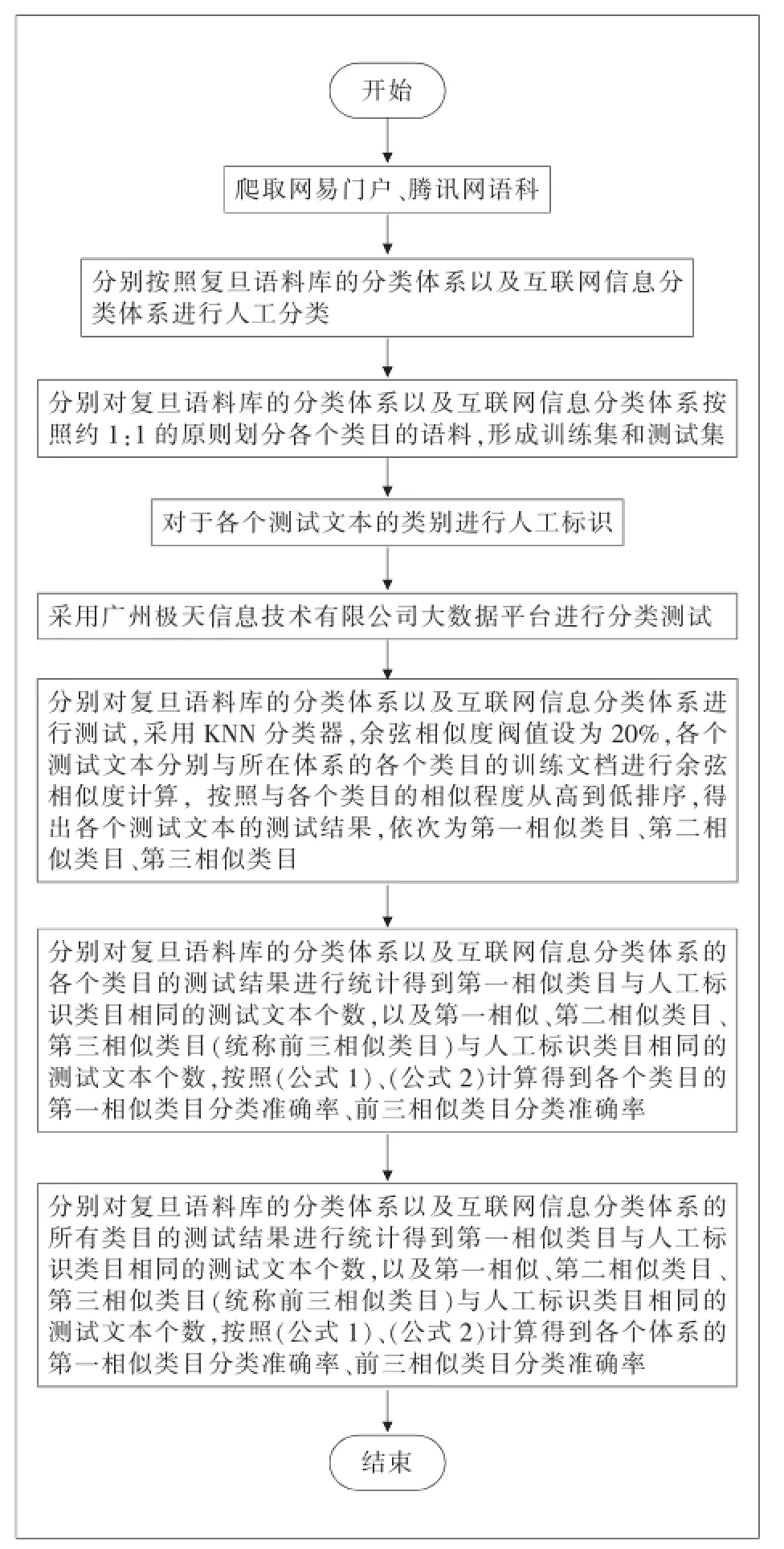
圖1 互聯網分類體系有效性實驗流程
4.3實驗結果
通過實驗,可分別得到復旦分類體系以及互聯網信息分類體系各個類目的測試結果(見表5、表6)。
由兩種分類體系的測試結果可知,互聯網信息分類體系第一相似類目分類準確率高于90%的類目達5個,低于50%的僅有1個,而復旦語料庫分類體系高于90%的僅有1個,低于50%的有10個;互聯網信息分類體系前三相似類目分類準確率高于90%的類目有9個,高于80%的有12個,僅有1個低于80%,而復旦語料庫分類體系高于90%的僅有4個,高于80%的有11個,低于80%的有9個。由此可知,互聯網信息分類體系類目設置具有更高的合理性,類目之間交叉度更低,各個類目特征明顯,符合科學性原則所要求的類目之間相互獨立。
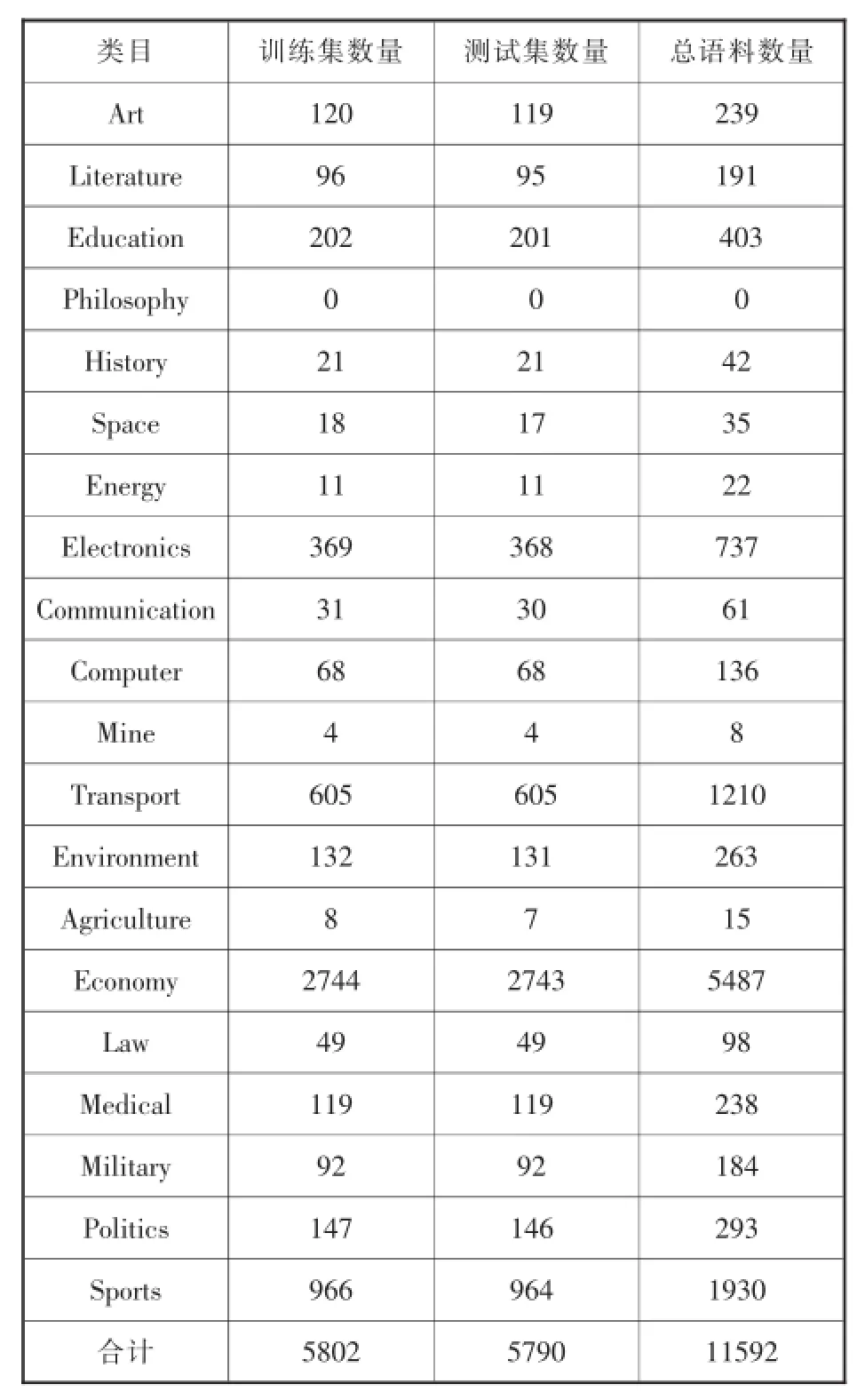
表3 復旦分類體系的訓練集、測試集情況
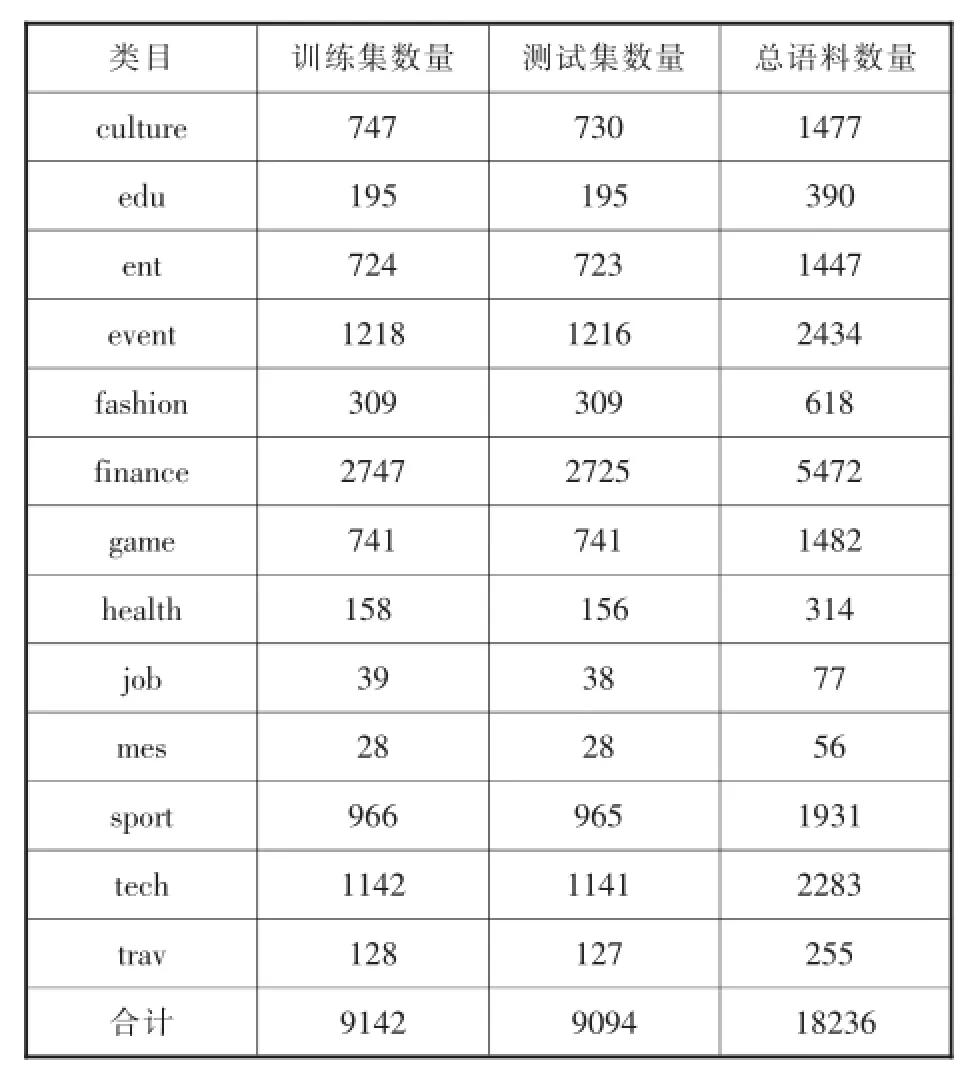
表4 互聯網信息分類體系的訓練集、測試集情況
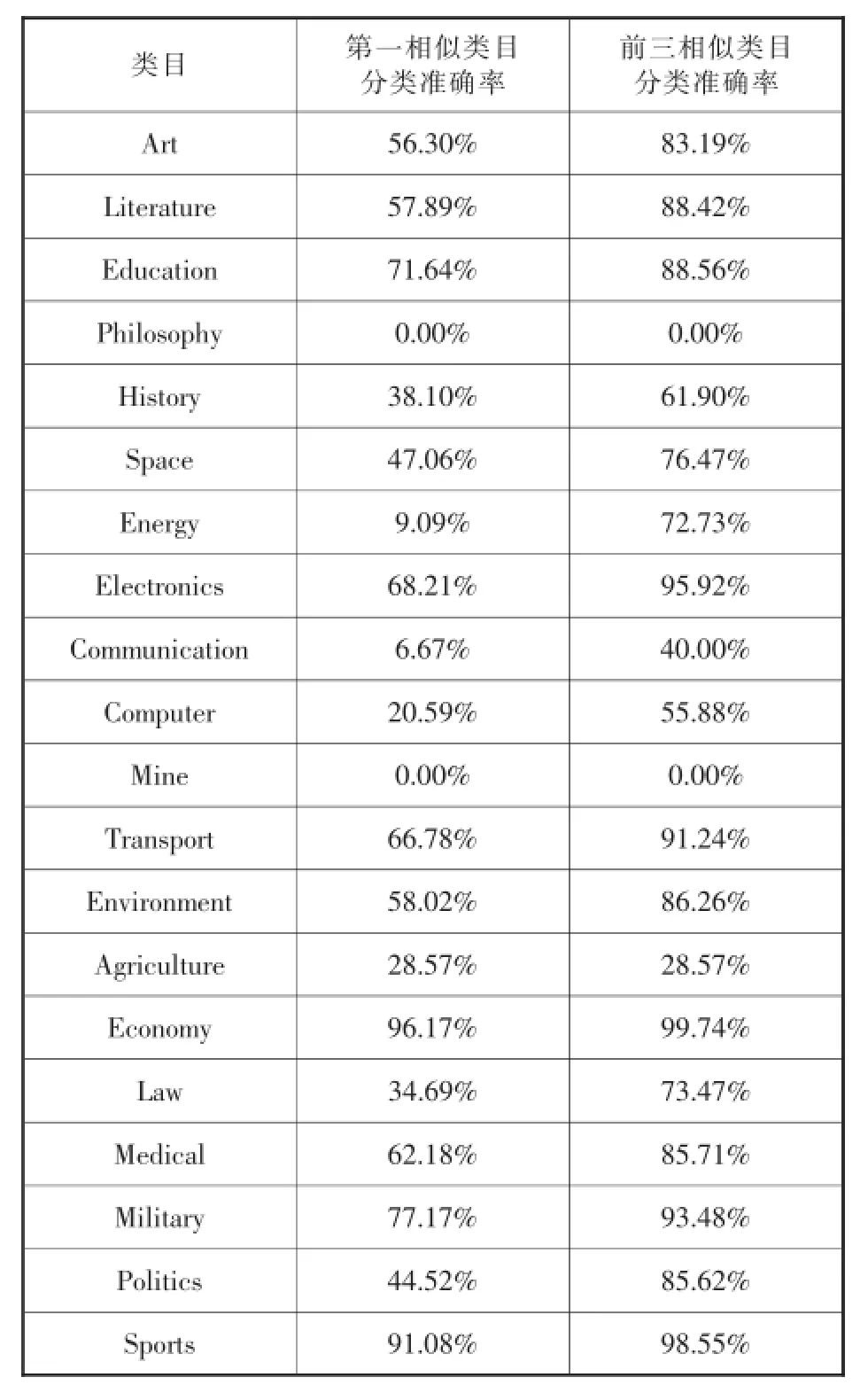
表5 復旦語料庫分類體系各個類目的測試結果
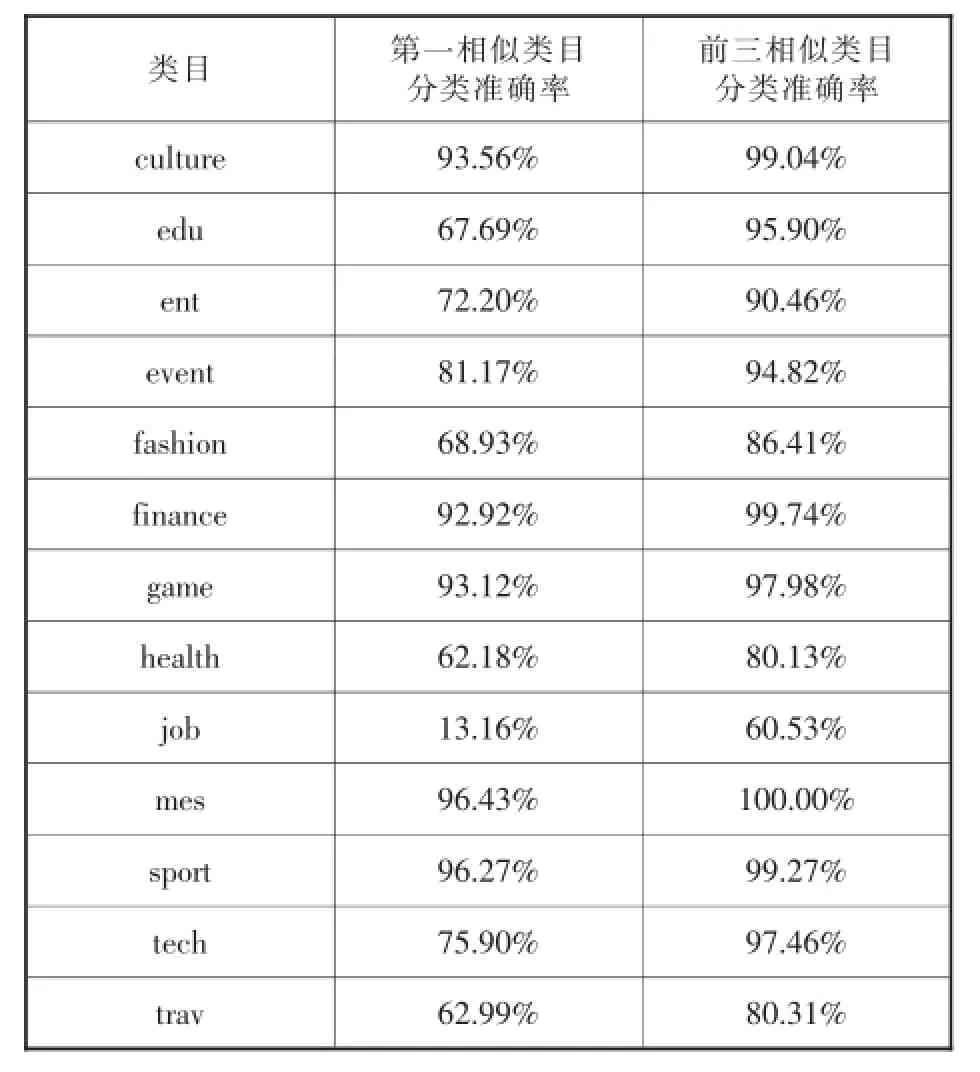
表6 互聯網信息分類體系各個類目的測試結果
對于整體數據集,利用文本分類評價指標——宏平均準確率進行評價,即每個類的分類準確率的算術平均值。由于前面各個類別考慮了第一相似類目分類準確率、前三相似類目分類準確率,故而此處考慮第一相似類目宏平均準確率以及前三相似類目宏平均準確率(復旦分類體系與互聯網信息分類體系的宏平均準確率見表7)。

表7 復旦語料庫分類體系與互聯網信息分類體系的宏平均準確率對比
對比可知,盡管互聯網信息分類體系所含語料數目為18236,復旦分類體系所含語料數目僅為11592,互聯網信息分類體系語料數大大多于復旦分類體系,即互聯網信息分類體系所包含的干擾信息大大多于復旦分類體系,但其第一相似類目宏平均準確率、前三相似類目宏平均準確率均仍高于復旦分類體系,驗證了本文所構建的互聯網信息分類體系的有效性。
5 結語
針對當前現有的各大網站自建體系科學性不高,用戶無法通過分類體系有效獲取所需信息,甚至誤導用戶的現狀,本文在對比了傳統文獻分類法與網絡信息分類法的特點基礎上,結合網絡信息分類法——實用性以及傳統文獻分類法的優點——科學性,提出了適用于構建互聯網信息分類體系的設計原則,并初步構建了具有13個一級類目的互聯網信息分類體系。該互聯網信息分類體系以事物為中心進行知識組織,在貫徹網絡信息分類體系實用性原則的基礎上,提高了分類體系的科學性與均衡性。同時,實驗結果表明,對比復旦語料庫的分類體系,本文所提出的互聯網信息分類體系具有一定的有效性,既能有效涵蓋更多的互聯網信息,且能夠保證更高的分類準確率。具體而言,互聯網信息分類體系可用語料率達84.37%,遠高于復旦語料庫分類體系的可用語料率53.63%,涵蓋多個較高實用價值的類目,符合實用性原則;同時,較全地覆蓋網絡信息,能夠使更多的網絡信息找到相應類別。其前三相似類目分類準確率高于90%的類目有9個,占體系總類目數的69.23%,而復旦語料庫分類體系中高于90%的類目占體系總類目數的比率僅為20%,互聯網信息分類體系各個類目特征更加明顯、相互獨立、交叉度低,符合科學性原則。同時,各個類目涵蓋的語料數量相近,語料數量低于200的僅有2個,而復旦語料庫分類體系的語料數量低于200的高達11個,“Economy”類目語料數量設置多于這11個類目的語料總和,表明互聯網信息分類體系各個類目所包含的網絡信息量接近,符合均衡性原則。同時,互聯網信息分類體系具有更高的分類準確率,前三相似類目分類準確率達96.50%,具有較好的自動文本分類效果,其能夠有效解決當下網站自建體系類目交叉明顯,類目科學性不強的問題,幫助用戶更加便利快捷地查找到需求信息。
盡管本文提出了一個具有較好的文本分類效果的體系框架,但仍存在一些不足:本文所提出的互聯網信息分類體系,其主要停留在一級類目體系的構建上,但實際應用過程中,用戶需要層層遍歷體系以指導其進行信息獲取。因而,下一步將會更加深入地研究各個類目的子類目,以期尋求科學的方法將各個大類層層細分。同時,結合自動文本分類技術,在此分類體系的基礎上,實現測試語料自動分類,力求構建一個具有自學習能力的文本分類平臺,實現子類目自劃分、語料數量自增長。
參考文獻:
[1]王興蘭,宋文.基于知識組織體系的自動分類研究[J].圖書館論壇,2013,33(6):8-13.
[2]陳樹年.搜索引擎及網絡信息資源的分類組織[J].圖書情報工作,2000(4):31-37.
[3]張琪玉.網絡信息檢索工具的分類體系——網絡信息檢索工具發展的方向與提高競爭力的途徑(連載三)[J].江蘇圖書館學報,2002(4):7-11.
[4]蔡厚勇.論圖書館數字化過程中的信息分類體系重建[J].大學圖書情報學刊,2001(3):1-3.
[5]歐潔,俞學寧,朱禮軍,等.基于網易的網絡信息分類體系研究[J].圖書館學研究,2012(1):50-53.
[6]王忠紅.網絡信息環境下的傳統分類法[J].圖書情報工作,1999(2):37-39.
[7]鐘瑩.傳統文獻分類法與網絡信息分類法之比較[J].學理論,2010(2):118-120.
[8]中國圖書館分類法[EB/OL].[2014-07-28].http://clc.nlc.gov.cn/ztfdsb.jsp.
[9]白國應.論文獻分類法的系統特征[J].圖書情報工作,1998(11):7-10.
[10]崔慕岳,劉延章,張中秋.《中圖法》組織網絡信息的可行性、不適應性及其現代化改造[J].鄭州大學學報(哲學社會科學報),2001(6):137-140.
[11]新浪門戶導航頁[EB/OL].[2014-08-25].http://news.sina.com.cn/guide/.
[12]劉星.試論網絡信息分類中存在的問題及對策[J].圖書館工作與研究,2008(2):43-45.
[13]魯曉明,王博文,詹劉寒.淘寶網商品信息組織分析[J].圖書情報工作,2013,57(增刊2):244-248.
[14]黃如花.網絡信息組織的發展趨勢[J].中國圖書館學報,2003,29(4):15-19.
[15]王麗珺,湯亮亮.網絡信息分類體系構建策略研究[J].中國科技信息,2009(23):115-116.
[16]鄭慶勝,易曉陽.從新浪等網站看網絡信息分類體系的建立——兼論綜合性中文網站分類體系之建立[J].圖書館建設,2003(1):69-71.
[17] 史學斌.網絡信息分類體系[J].圖書館,2002(2):33-35.
[18]常璐.對網絡環境下信息分類法的思考[J].科技情報開發與經濟,2011,21(8):30-33.
[19]宛玲,趙喜英.中文網絡信息分類組織分析[J].圖書館理論與實踐,2001(1):46-56.
[20] 復旦大學文本分類語料庫[EB/OL].[2014-12-25].http://www.nlpir.org/?action-viewnews-itemid-103.
[21]搜狗文本分類語料庫[EB/OL].[2014-12-25].http://www.sogou.com/labs/dl/c.html.
·用戶服務與研究·
中圖分類號:
G2503文獻標識碼:
ADOI:
10.11968/tsygb.1003-6938.2015072作者簡介:
路永和(1962-),男,中山大學資訊管理學院副教授;彭燕虹(1992-),女,中山大學資訊管理學院碩士研究生。*本文系
國家自然科學基金項目“面向文本分類的多學科協同建模理論與實驗研究”(項目編號:71373291)研究成果之一。收稿日期:
2015-06-16;責任編輯:魏志鵬The Classification System Construction for Internet Information both Practical and Scientific
Abstract
The classification system is an effective method of information organization.The traditional classification system can not adapt to the transformation of classification object and is no longer practical;at the same time,the existing network classification system is not scientific.An Internet information classification system both practical and scientific can not only effectively meet the users'information demand,but can also promote the development of automatic text classification.Taking Chinese Library Classification and Sina portal for examples respectively,this paper studies the advantages and disadvantages between traditional document classification and taxonomy of network information,come up with the design principles of the internet information classification system,namely practical, scientific and balance.Based on these three design principles,an internet information classification system was built.In order to verify the validity of the classification system,the web crawler is used to grab corpus of www.163.com and www.qq.com which are as experimental data,and Fudan Corpus classification system is used for the comparative experiment.Experimental results show that,compared to the Fudan Corpus classification system,the proposed Internet Information Classification System has a higher practicality,and can more comprehensively cover all kinds of Internet information,little intersections among categories,more approach between the information of each category,the text classification efficiency is quietly improved.Key words
internet information;classification system;chinese library classification;corpus猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
新世紀智能(數學備考)(2020年11期)2021-01-04 00:38:16
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
新高考·高一物理(2014年1期)2014-09-18 01:26:07
語文知識(2014年1期)2014-02-28 21:59:13
