基于Hadoop的Web用戶識別與新聞智能推薦算法研究
2016-05-14 15:48:59林中明李文敬
軟件導刊 2016年5期
林中明 李文敬


摘要:為了解決大數據時代用戶閱讀時遇到的“信息過載”與“信息迷失”問題,提出了基于Hadoop平臺的用戶準確識別與新聞推薦算法。首先基于MAC地址識別用戶,通過對用戶瀏覽軌跡的離線和在線挖掘,建立用戶興趣模型。然后對新聞關鍵詞進行聚類,結合協同過濾和啟發式方法,基于關鍵詞對用戶進行新聞的智能推薦。實驗結果表明,基于MAC地址的算法比基于IP地址的算法用戶識別率提高了30%。
關鍵詞:云計算;新聞推薦;Web日志挖掘;Hadoop;MAC地址
DOIDOI:10.11907/rjdk.161378
中圖分類號:TP312
文獻標識碼:A 文章編號:1672-7800(2016)005-0027-03
0 引言
根據ZDNET《數據中心2013:硬件重構與軟件定義》[1]年度技術報告顯示,2013年中國產生的數據總量超過0.8ZB,預計到2020年,產生的數據總量將是2013年的10倍。海量的Web信息讓人們感覺到信息過載和信息迷失,如何快速精準地識別用戶并為其推薦感興趣的內容成為了當今的研究熱點[2]。根據新聞閱讀與設備使用情況的調查問卷[3]數據顯示,95%的人都是在電腦、手機、平板等電子設備上獲取新聞資訊,而且80%的人在閱讀新聞時并未處于登錄狀態,即無法通過用戶的登錄信息給用戶推薦相應內容。面對海量的新聞資訊,文獻[4]針對用戶識別存在的問題提出了IASR(IP,Agent,Session and Referrer)算法,通過引入會話(Session)來識別用戶;文獻[5]提出了基于用戶瀏覽行為的建模,提高了同一個IP下用戶的識別率;文獻[6-8]提出了基于URL相似度的會話識別方法。但這些方法并不能改變IP對于識別用戶的限制,所以不能從本質上提高用戶識別率。因此,利用Hadoop大數據平臺,對無登錄信息的用戶進行快速身份識別和新聞信息的個性化推薦,相關研究具有重要的現實意義和潛在的經濟價值。
1 海量Web日志與用戶識別
MAC地址是網卡物理地址,由網絡設備制造商生產時寫在硬件內部,因此世界上任意一個擁有48位MAC地址的網卡都有唯一標識[9],且MAC地址與網絡無關。通過在Web日志中加入MAC地址,可以實現用戶的唯一性識別,增加用戶識別的準確性。
用戶識別是個性化新聞推薦的基礎和關鍵,詳細有用的用戶數據將決定新聞推薦的效果。由于Web日志中包含了訪問主機IP、訪問時間、訪問頁面、請求方式等信息,詳細記錄了用戶的訪問軌跡,生成巨大的數據量及數據類型,因此將通過Web日志作為用戶識別的數據源。本文將記錄分為長期記錄和短期記錄,一般將10天以前的訪問日志作為長期記錄,最近10天的訪問日志作為短期記錄。針對長期記錄,通過Hadoop平臺進行離線處理。短期記錄則在用戶使用過程當中,以信息增量的形式補充到推薦算法中來。
2 基于MAC地址的用戶識別算法
2.1 算法基本思想
Hadoop的核心是Map/Reduce。Map/Reduce是一個可用于大數據處理的離線計算模型,它將一個任務分成多個細粒度的子任務,并將這些子任務分配到計算節點上進行并行處理,以縮短任務完成時間。將Web日志等份劃分后,利用Map/Reduce對Web日志作長期記錄處理。
利用Hadoop平臺得到用戶長期記錄下的每個MAC地址對應用戶的集合文件,這是一個龐雜的文件,將通過基于URL相似性的用戶識別算法對集合文件進行處理,得到此MAC對應用戶的100條最感興趣頁面的排序文件。
定義長期記錄的日志文件為集合L={l1,l2,……,lm},通過map過程得到每個MAC對應的集合文件K={k1,k2,……,kn},再通過reduce過程,得到對應生成的用戶長期訪問文件為MAC={MAC1,MAC2,……,MACr},每個文件里包含了此MAC地址對應用戶的所有長期訪問記錄。在K的每個文件中包含有訪問時間、IP、URL、訪問時長、訪問次數字段。針對短期日志文件,根據最近10天該MAC地址用戶的所有訪問記錄,同樣生成一個短期的訪問記錄文件。在用戶進入站點后,根據用戶的長期和短期記錄生成一個綜合的用戶訪問記錄文件,與用戶未讀新聞對比后進行推薦。
2.2 特征標簽選擇
由于一篇文章中經常存在多個分頁形式,且每個分頁的訪問次數和瀏覽時間基本相同,所以要將同屬一篇文章多個分頁的URL記錄合并。對ki中URL具有相似性的記錄進行合并,cos(URLi,URLj)為兩條URL的余弦相似性,Smaxi為合并的記錄中訪問次數最多的,i為合并的記錄中訪問時間的平均值,numi為合并的記錄條數。
3 基于關鍵詞的協同過濾智能推薦算法
當前有很多種智能推薦算法,主要有基于內容的推薦、協同過濾推薦和基于知識的推薦。基于內容的推薦是提取對象中的特征屬性,通過用戶信息與待推薦對象的匹配程度進行推薦,但這種算法對特征提取方法的依賴程度很高,無法準確地描述用戶特征;協同過濾推薦是通過聚合待推薦用戶的相似用戶評價的所有對象,計算對象與用戶之間的效用值進行推薦,對于新對象和新用戶都存在冷啟動和稀疏性問題;基于知識的推薦是在特定領域構建規則來進行基于規則和實例的推理,不存在冷啟動和稀疏問題,但知識很難建模。
本文結合各推薦算法的優缺點,提出一種基于關鍵詞的協同過濾智能推薦算法。一般地,在系統中的每一篇文章都包含有最能體現這篇文章主題的關鍵詞。通過對關鍵詞的聚類,避免了項目的冷啟動問題,并去掉了項目特征提取的步驟。對從用戶模型中得到的此MAC用戶的100條最感興趣的記錄文件,對關鍵詞進行聚類。得到關鍵詞聚合文件W={(w1,q1),(w2,q2),……,(wn,qn)},其中q為w的出現次數。利用啟發式方法,先計算文章關鍵詞之間的相似度,再對所有待推薦文章對此MAC用戶的效用值進行計算,得到推薦子集。同時假設待推薦文章的關鍵詞為W'={w1',w2',……,wm'}。
4 實驗結果與分析
實驗在由5臺HP DL380G5服務器組成的集群上進行,其中,一臺是主節點,一臺是任務調度節點,5臺都可以作為計算節點及數據存儲節點。同時,采取Xen的虛擬化技術,使同一節點上同時并發執行多個MapReduce操作。5臺服務器均安裝hadoop-0.20.0和JDK。實驗程序是在PHP集成開發環境中開發的。測試數據集來自某地方綜合新聞資訊網站的Web服務器日志。為了驗證該Web日志分析平臺的有效性及高效性,做了以下2個實驗。
實驗1:在Hadoop平臺上對Web日志中的MAC和IP地址數量分別進行統計。通過比較發現,基于MAC地址比基于IP地址辨別用戶的算法識別率高出了30%以上,且隨著記錄時間的變長,用戶的識別率還會繼續擴大。這表明基于Web日志分析的新聞推薦使用基于MAC地址的用戶識別算法能夠準確地識別用戶,且不依靠用戶前臺的數據,減輕了前臺數據的處理壓力。
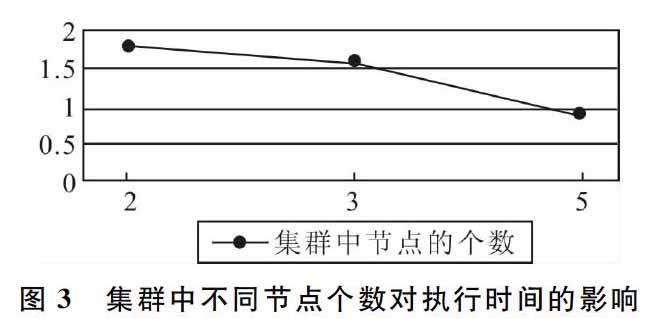
從以上結果可以看出,利用MAC地址的唯一性來識別用戶是一個切實可行的方法。當處理的數據量較小時,基于Hadoop的Web日志分析平臺由于需要生成及傳輸中間文件和最終文件,開啟Hadoop也需要一定時間,因此并行運算的總時間反而大于單機執行時間。但隨著數據量增大,基于Hadoop的并行處理平臺將數據分割后分派給多個節點并行處理,使并行運算的總時間小于單機執行時間,且隨著輸入數據的增加,兩者執行效率的差距也越來越大。從圖3可以看出,集群中擁有的節點數目越多,基于Hadoop的并行處理平臺效率越高。
5 結語
針對目前用戶閱讀新聞普遍遇到的信息過載問題及用戶不登陸瀏覽的閱讀習慣,基于MAC的用戶識別算法提高了新聞推薦中的用戶識別率。同時針對運行于單機集中平臺上的Web日志分析系統不能滿足海量數據處理的問題,本文在對云計算的Hadoop集群框架研究的基礎上,給出了一種基于Hadoop集群框架的Web日志分析方法。實驗結果表明,該平臺能夠獲取隱含的、有實用價值的信息,執行效率高。
參考文獻:
[1]張廣彬,盤駿,曾智強.數據中心2013:硬件重構與軟件定義[R].ZDNet企業解決方案中心,2013.
[2]張誠,郭毅.數據挖掘與云計算——專訪中國科學院計算技術研究所何清博士[J].數字通信,2011(3):5-7.
[3]新聞閱讀與設備使用情況的調查問卷[EB/OL].http://www.lzm07.com/index.php?file=v.html.
[4]吳永輝,王曉龍,丁宇新,等.基于主題的自適應、在線網絡熱點發現方法及新聞推薦系統[J].電子學報,2010(11):2620-2624.
[5]何希真.基于用戶反饋信息的新聞推薦系統設計與實現[D].濟南:山東師范大學,2015.
[6]謝潤泉.基于隱式專家的個性化新聞推薦[D].廈門:廈門大學,2014.
[7]宋科. Hadoop平臺下基于LDA的新聞推薦算法研究[D].成都:西南石油大學,2015.
[8]周松松,馬建紅.基于URL相似度的會話識別方法[J].計算機系統應用,2014(12):191-196.
[9]謝俐,何勇,楊樂.網卡MAC地址探究[J].今日科苑,2008(4):190.
(責任編輯:黃 健)
