基于多維索引樹編碼的數據庫分層訪問技術研究
2016-05-14 22:04:23王艷劉繼華
軟件導刊 2016年5期
王艷 劉繼華
摘要:通過對數據庫分層訪問優化算法的設計,提高大型數據庫的數據調度和信息索引能力。傳統方法對分層數據庫的訪問算法采用語義指向索引技術,隨著數據量的增大和干擾數據增多,對數據庫訪問的準確度不高。提出一種基于多維索引樹編碼的數據庫分層訪問技術,對大型分層Web數據庫的數據結構模型進行系統分析,然后構建數據庫中的數據信息流模型,以此為信息源進行多維索引樹編碼設計與數據庫的語義信息特征模板匹配,實現對數據庫的分層訪問優化設計。仿真結果表明,采用該方法進行數據庫分層訪問,通過多維索引樹編碼,可提高數據庫訪問過程中的數據召回率和配準率,數據庫訪問的收斂性和抗干擾性較好,訓練時間較短。
關鍵詞:數據庫訪問;分層訪問;多維索引樹;編碼
DOIDOI:10.11907/rjdk.161243
中圖分類號:TP392
文獻標識碼:A 文章編號:1672-7800(2016)005-0173-03
0 引言
隨著信息技術和大數據技術的快速發展,社會進入大數據信息管理時代。對大數據的管理主要是通過分層網絡Web數據庫實現,在數據庫中采用云存儲和云調度方法,實現對大型信息數據的管理和調度,以提高數據庫的信息處理和信息加工能力。分層大數據庫作為存儲數據信息的重要載體,對數據庫的優化訪問是提高數據查詢和調度性能的關鍵。因此,相關的算法研究受到人們的極大重視[1-3]。
分層Web大型數據庫廣泛應用于大型的網絡信息數據和云存儲信息數據的存儲和調度架構中。對分層Web大型數據庫頻繁訪問的過程中,進行特征分區和數據文本的指向性索引,有利于提高數據庫訪問性能。傳統方法對分層數據庫的訪問算法采用語義指向索引技術,隨著數據量的增大和干擾數據增多,對數據庫訪問的準確度不高。對此,相關文獻進行了算法改進設計。其中,文獻[4]提出一種基于信息流減法聚類和模糊C均值調度的數據庫訪問算法,通過粗糙集索引實現數據庫訪問,但是該方法對數據庫訪問過程中的稀疏度均衡能力不好;文獻[5]提出一種基于關鍵字有向圖模型的數據庫訪問算法,然而該算法對非線性MIMO級聯數據庫分層訪問特征分區性能不好。針對上述問題,本文提出一種基于多維索引樹編碼的數據庫分層訪問技術,首先對大型分層Web數據庫的數據結構模型進行系統分析,然后構建數據庫中的數據信息流模型,以此為信息源進行多維索引樹編碼設計,在此基礎上,實現對數據庫的分層訪問優化設計。仿真實驗進行了性能測試,得出有效性結論,并展示了較好的數據庫訪問性能。
1 大型分層數據庫的數據結構模型與數據信息流特征分析
1.1 大型分層數據庫數據結構模型
為了實現對大型Web分層數據庫的優化訪問,需要首先進行數據庫的數據結構分析。首先分析數據庫的存儲結構模型,假設在查詢接口模塊中進行數據訪問的語義有向圖的特征矢量信息流表示為:
根據上述分析,進行數據庫訪問信息的瞬時頻率估計,以此為基礎,通過對數據庫存儲節點的分布調度,實現對大型分層數據庫的數據結構分析。
1.2 數據庫訪問分層信息特征模型構建
根據上述數據庫的數據結構分析原理,為了實現對數據庫的分層訪問,需要進行數據庫的數據信息流訪問特征模型構建,為實現數據庫優化訪問提供準確的數據基礎。本算法設計采用兩個空間層的正交特性進行層迭代處理和特征量檢測和提取。基于定量遞歸分析的滑動窗口混合模型,估計數據庫的規模大小,得到分層數據庫的分層信息特征監測混合模型。輸入控制參量采用自適應線性相關方法進行數據庫訪問的信道均衡設計,得到分布式緩存系統中的數據庫信息訪問信號模型為:
3 仿真實驗與結果分析
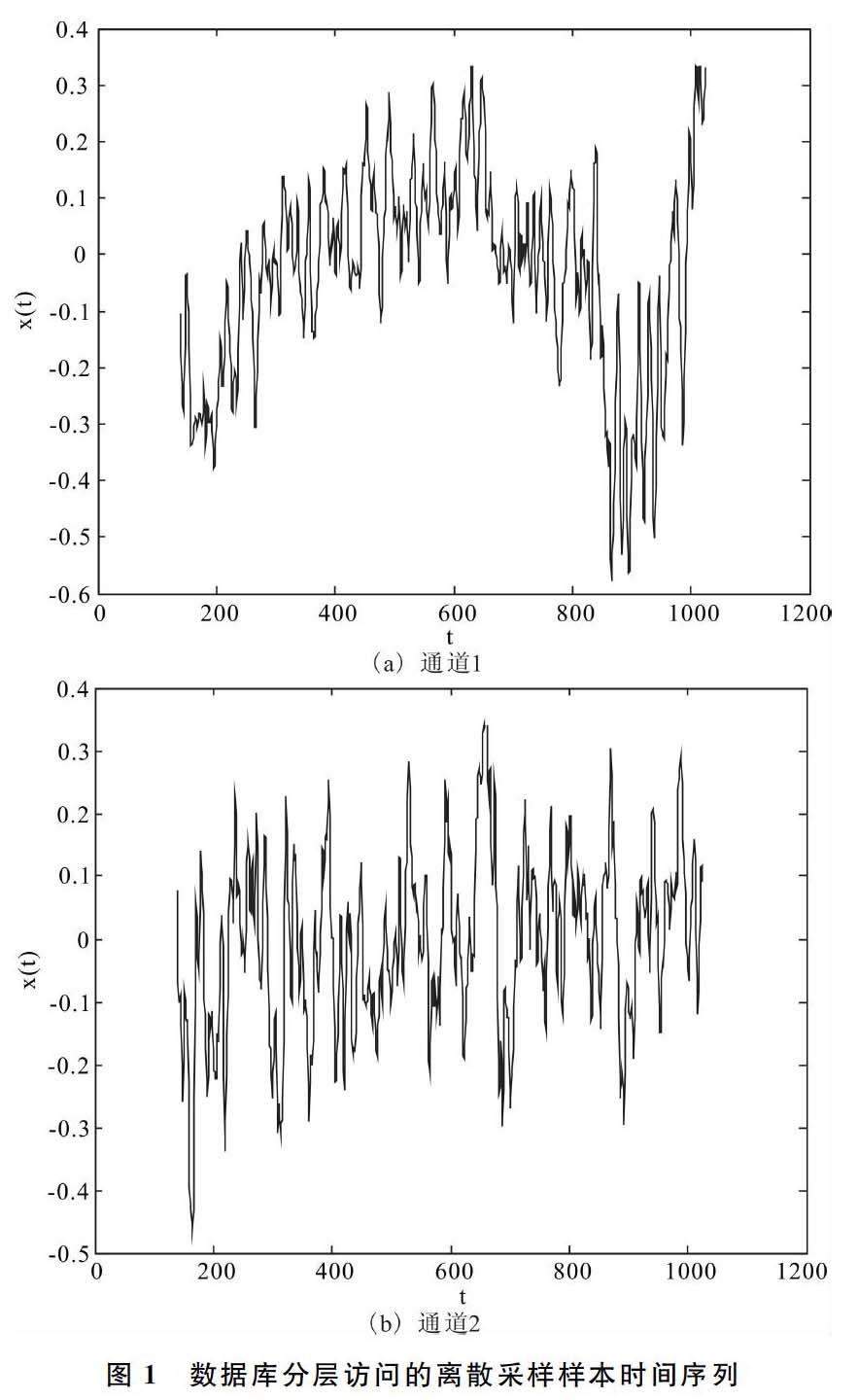
為了測試本文改進算法在實現數據庫分層優化訪問中的應用性能,進行仿真實驗。實驗建立在Matlab仿真軟件基礎上,實驗中首先進行參數設定,根據樣本的屬性規模和數據集種類數目,在進行數據庫的分層訪問控制中,數據集采樣的初始頻率為1 024 Hz,數據庫訪問接口數據AD采樣的截止頻率為50kHz,分層數據庫訪問的時頻特征載波間隔為1.2ms。在上述仿真環境和參數設計的基礎上,進行數據庫分層訪問仿真實驗。在兩個數據庫訪問通道中進行數據離散采樣,得到采樣波形如圖1所示。
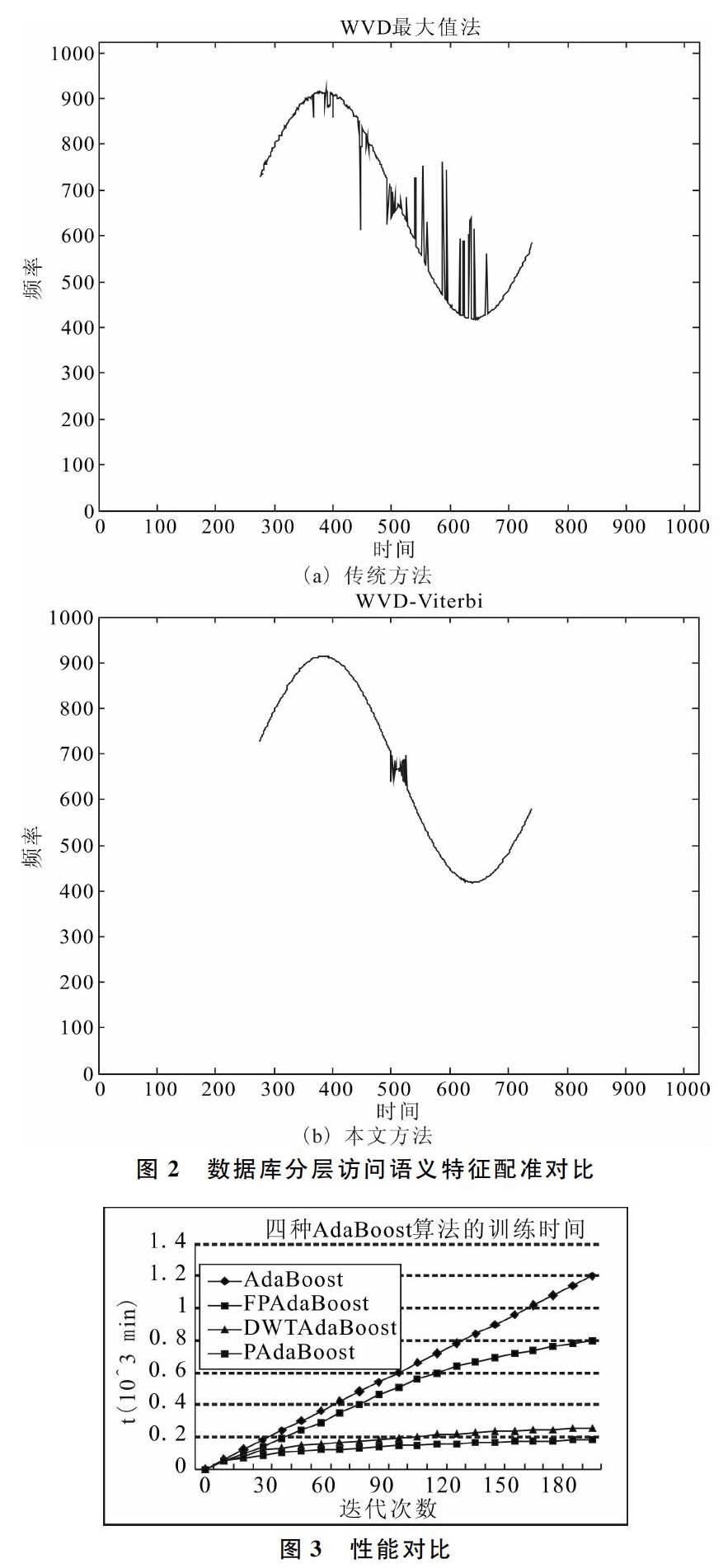
以上述采樣樣本為研究對象,對數據庫的特征序列進行多維索引樹編碼,以提高數據庫訪問過程中的語義配準率。為了對比性能,以數據庫訪問的語義配準譜分析結果為測試指標,得到數據庫分層訪問的語義特征配準結果如圖2所示。
由圖可見,采用本文算法進行數據庫分層訪問,具有較好的配準性能。
最后,采用不同算法進行數據庫分層訪問的訓練時間對比,得到結果如圖3所示。由圖可見,采用本文方法,通過多維索引樹編碼,提高了數據庫訪問過程中的數據召回率和配準率,訓練時間較短,訪問精度較高。
4 結語
通過數據庫的分層訪問優化算法設計,提高大型數據庫的數據調度和信息索引能力。本文提出一種基于多維索引樹編碼的數據庫分層訪問技術,對大型分層Web數據庫的數據結構模型進行系統分析,然后構建數據庫中的數據信息流模型,以此為信息源進行多維索引樹編碼設計,在此基礎上實現對數據庫的分層訪問優化設計。實驗結果表明,采用本文方法進行數據庫優化訪問,通過多維索引樹編碼,提高了數據庫訪問過程中的數據召回率和配準率,數據庫訪問的收斂性和抗干擾性較好,訓練時間較短,比傳統算法性能優越。
參考文獻:
[1]LIU XIANGDONG.Data clustering algorithm and software design based on disturbance searching of logistic series[J].Bulletin of Science and Technology,2014,30(2):161-163.
[2]孫健,劉鋒,郭文濤,等.一種改進的近似動態規劃方法及其在SVC的應用[J].電機與控制學報,2011,15(5):95-102.
[3]雪剛,唐遠炎.幾何布局和行為檢測相結合的遮擋目標跟蹤[J].計算機工程與應用,2015,51(13):42-46.
[4]劉冬寧,湯庸,滕少華,等.基于時態數據庫的極小子結構邏輯系統[J].計算機學報,2013,36(8):1592-1601.
[5]譚鵬許,陳越,蘭巨龍,等.用于云存儲的安全容錯編碼[J].通信學報,2014,35(3):109-114.
(責任編輯:黃 健)
