
序列模式挖掘在教學管理上的運用
2016-06-29 21:14:04劉昆
電腦知識與技術 2016年13期
劉昆
摘要:序列模式挖掘表示在序列數據庫匯總找出頻繁子序列使之成為模式的一項知識發現的過程。在教學管理中應用序列模式挖掘,根據一定的序列數據模式將學生成績樣本實行建模以及信息挖掘,獲得三條高于65%置信度的時序關聯規律。經過實驗可知,在教學管理中運用序列模式挖掘,挖掘學生教學成績具有一定的可行性,得出的時序關聯規律可以促進教學管理,促進學生學業成績的提升。
關鍵詞:序列模式;數據挖掘;教學管理;運用
中圖分類號:TP391 文獻標識碼:A 文章編號:1009-3044(2016)13-0189-02
序列模式挖掘是屬于數據挖掘范疇內的一個常用的分支,該模式未來的應用前景非常廣闊,該模式能夠根據時間序列數據庫發掘先后事件之間存在的關聯規律,序列模式發掘在教師管理中充分應用,能夠發掘學習者在學習成績方面具有前導后續的時序關系規律,同時可以得出這一關聯規律在教學管理應用可以幫助進行科學的決策有利于教師做出指導性的建議。
1序列模式挖掘模型
I代表的是項目全集,這一全集指的是論域內相關的獨立數據項構成的非空數集I={i1,i2,…,Im}(k=1,2,…,m)代表的是單獨的數據項。
項集sj=(1,2,…,2m-1),指的是一個全集 I 若干項目構成的集合,可以得出sj?I且 s 存在的數量2m-1。增加時間屬性之后集合T為:
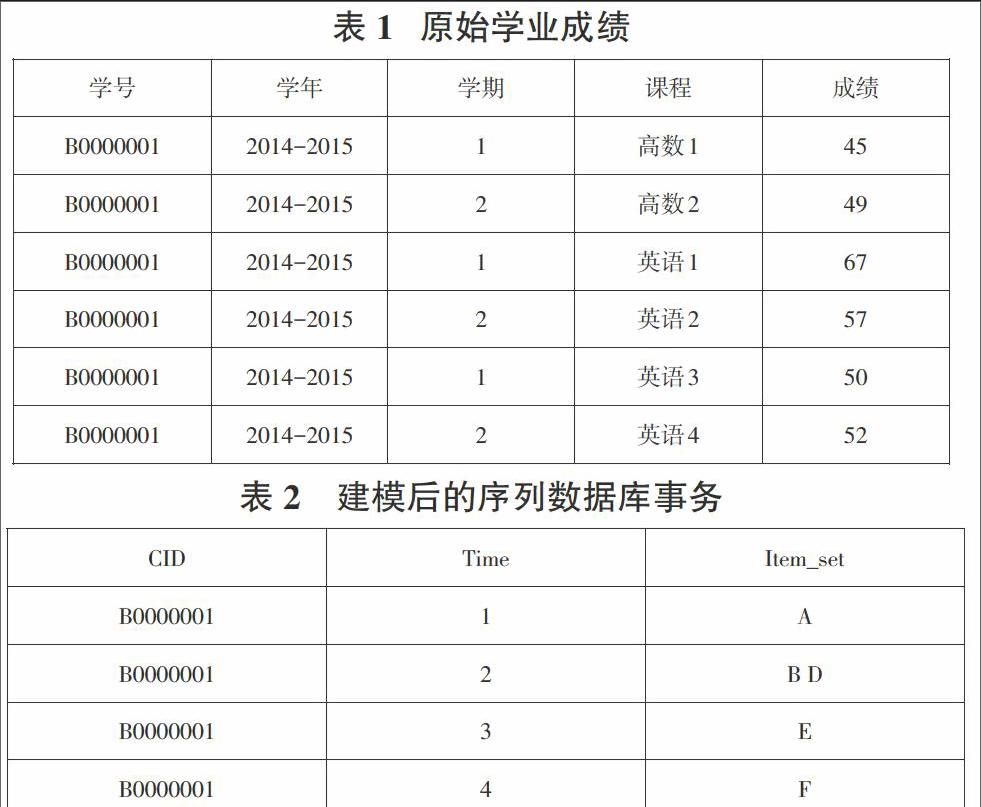
T = { 2 學生成績序列模式建模 2.1數據抽取 從某一教學管理數據庫中抽取一定的學生成績當做初識的數據信息,在數據庫中僅僅讀取和成績相關的數據字段,涉及學年學期、課程名稱、學號等。 2.2 隱私保護 抽取的成績樣本屬于學生的隱私范疇的內容,因此對所抽取的樣本信息實施隱私保護[1]。為了保護信息,可以歪曲處理相關初始的一些信息,關聯規律發掘的對象是集聚信息的數據集并非單獨的數據項目,所以存在足夠數據信息的狀況下,可以對具體的數據進行歪曲處理,數據集設計統計和聚集信息能夠得到準確的儲存,對處理之后的信息發掘關聯規律,一方面可以有效保護隱私,另一方面可以發掘數據集內部存在的關聯性[2]。面對獲得的樣本數據,在數據信息統一的基礎之上,使用隨機的方法替換學號,隱蔽實際的學號,這是隱私保護的主要手段 2.3 過濾 獲得成績信息中總評成績字段涉及部分意義不大字段信息,比如,曠考、緩考等信息,對于這部分信息需要過濾掉[3]。與此同時,為了確保數據自身的完善性,假如過濾掉部分信息,那么這一實體需要刪除全部信息。 2.4 離散化 總評成績字段最初信息可以在0 ~100進行隨意取值,為方便進行分類處理,最為簡便的方式是設置一個合格界限60,離散為是否合格兩種取值形式。 2.5 建立序列數據模型 在教學數據庫中,最初的成績保存形式是一條記錄儲存一項成績,這屬于時序數據庫基礎上的事務模式: M={Tid,Cid,Time,Item_set} 差別非常大,因此必須轉變課程信息并建立模型。 1)時間段劃分 通常來說,學習成績可以根據學期將成績獲取時間化為8個時間段,也就是四個學年,每個學年存在2個學期。但是也可能存在別的狀況,比如,一個學年存在三個學期,如果是這種情況的話,需要按照實際的狀況劃分具體的時間段。 2)代換 為方便對數據進行處理,應當對課程名稱以及經過離散獲得成績利用符號的形式進行轉換。比如,我們單純關注不合格成績,這樣對后續的課程出現的不及格成績是否會造成影響,可以將各個幾個成績信息過濾后,使用字母符號針對某一課程涉及的不及格數據進行表示。 3)歸并 在相同的時間段內獲得相同學生的成績應當劃分到一條事務之中,可以保障數據同序列數據事務模式M相符,繼而便于后學的序列模式發掘。假定初始成績如同表1所示,對其進行離散、按照時間段進行劃分、進行一系列的替換以及歸并之后得出的序列數據庫事務(如表2所示)。 3 GSP 算法 GSP 算法數據最具代表性的Apriori 類型的方法,當然也有很多需要進行掃描的數據庫同時具有一定的缺陷比如候選集量太大,但是因為本次研究需要進行處理的樣本信息數量相對小,因此使用GSP 算法具有一定的可行性[4]。GSP 算法描述如下: 4 序列模式挖掘實驗及結果 學生成績樣本經過一定的過濾獲得共計50000多條信息,在進行離散、劃分、替換以及歸并等操作之后,獲得序列模式數據庫D,進而使用GSP 算法發掘序列模式,將最后的發掘情況進行關聯規律的轉變,高于65%的置信度的存在三條: 1)Confidence( 高數 1 不合格→高數 2 不及格)= 66% ; 2)Confidence( 英語1 不合格∩英語2 不及格→英語 3 不合格) =73%; 3)Confidence( 信息技術 1 不合格→信息技術 2不合格) =87%。 其置信度越高就表示假如規律涉及的條件具備的情況下,這樣規則情況出現的幾率也就會更高。規律3具有87%的置信度,通過一系列的分析,產生這一情況的原因是只有極少數人的信息技術1不合格,但是大多數人的信息技術2 是不合格的,也就是說信息技術1沒有過關的這部分人中,大部分的人他們的信息技術2是不合格的。這表明各項功課不合格幾率的差異會在一定程度上影響發掘的最終結果。此外,站在規律推廣立場上講,假如需要采用序列模式發掘獲得 鼓勵對后續工程不合格的概率進行預測,本質上還不存在確切的可以進行表述的約束條件,樣本成績以及需要進行預測的成績不合格率應當基本相當,不然的話獲得的規律缺乏較高的有效性。上述獲得三條管理可以指導學校的教學管理活動,也可以指導學生的學習進展。具有較高置信度的關聯規則,假如其條件具備,則規則中涉及的情況出現幾率就會增加,假如不想出現規則結果,可以實施一定的措施進行補救。比如,一個學生的英語1、2均不合格,必須提醒他英語3很可能還會不合格,不合格風險高達75%,要求該學生充分重視,學習更加努力,另外對其進行針對性的輔導,加快成績的提升。 5 結束語 文章中在教學管理中運用序列模式挖掘,充分發掘學生成績樣本數據,獲得三項較高置信度的時序關聯規則,所得出的規律可以有效指導教學管理工作,教師可以針對具體規律中涉及的情況進行合理的分析,對于問題采取積極的措施進行規避,對于不足進行改善,促進教學質量和水平的提升,對于學生的具體的情況,制定特定的教育方案,提升學生的學業成績。 參考文獻: [1] 侯錕.數據挖掘技術在高校教育教學中的應用[J].吉林省教育學院學報:下旬,2012(28):51-52. [2] 王智鋼,王池社,顧云鋒,等.序列模式挖掘在教學管理上的應用[J].計算機與現代化,2012(11):22-25. [3] 劉美玲,李熹,李永勝.數據挖掘技術在高校教學與管理中的應用[J]. 計算機工程與設計,2010(31): 1130-1133. [4] 劉雨露.數據挖掘在高校學生管理決策中的應用模式分析[J].成都信息工程學院學報,2015(3):373-377.
猜你喜歡
大學(2021年2期)2021-06-11 01:13:24
大眾投資指南(2021年35期)2021-02-16 01:06:26
甘肅教育(2020年17期)2020-10-28 09:01:24
甘肅教育(2020年4期)2020-09-11 07:41:24
電力與能源(2017年6期)2017-05-14 06:19:37
中學課程輔導·教師教育(中)(2016年9期)2016-10-20 15:47:50
中國科技博覽(2016年18期)2016-10-19 07:32:41
考試周刊(2016年76期)2016-10-09 09:26:45
小學教學參考(語文)(2016年9期)2016-09-30 08:58:25
信息通信技術(2015年6期)2015-12-26 01:16:46
