個人名稱規范維護新方法探析
2016-07-19 08:54:08郝嘉樹國家圖書館北京100081
圖書館建設 2016年2期
郝嘉樹 (國家圖書館 北京 100081)
?
個人名稱規范維護新方法探析
郝嘉樹(國家圖書館 北京 100081)
[摘 要]我國采用自上而下、人工操作和封閉的模式影響名稱規范的維護能力、效率及規范控制效果。基于著者交互的自規范、自動人名消歧和開放關聯數據的個人名稱規范維護方法,借鑒了文獻數據庫系統中的著者唯一標識、機器學習領域的自動身份辨識和有效信息源獲取,可改變我國個人名稱規范數量少、覆蓋范圍受限和數據質量不高的現狀,解決當前名稱規范模式維護能力差、效率低下和無法與外界互操作等問題,真正發揮出名稱規范控制應有的功能及效果。
[關鍵詞]個人名稱規范維護 自規范 自動人名消歧 開放關聯數據 MARC格式
1 引 言
名稱規范的重要功能及近幾年越來越傾向于以人為中心的資源組織,使得個人名稱規范數據維護成為圖書館信息組織的重要內容。目前,國內對我國名稱規范維護工作問題的探討大多集中于從完善編目格式和規則的角度提升規范數據質量,從多機構聯合構建角度解決數據的共享和重用[1-2]。然而,數據質量的提升如果沒有信息源的有效獲取模式,完善格式和規則只能成為空殼,并且國內多機構聯合共建仍為自上而下的維護模式,并沒有從根本上提高維護的效率,規范控制能力仍跟不上資源增長的速度。
筆者認為,當前我國個人名稱規范維護工作的突出問題有:一是面對海量數據資源采用自上而下、由領域內少數權威機構維護的模式,使得個人名稱規范數據質量、規模和范圍受到影響與限制,規范控制能力跟不上資源增長的速度;二是面對大量數據和難以獲取有效信息的事實,完全由編目員承擔個人名稱規范維護工作,出現較多影響規范控制效果的不完整和白板數據①,這種人工維護的方式耗費人力、財力而又效率偏低;三是網絡中發布了大量與人相關的資源和規范數據,我國名稱規范數據封閉在圖書館環境內無法與已開放數據關聯,阻礙發現、整合已有資源以擴大本地個人名稱規范規模和補充完善自身數據,另外,數字化環境充斥的今日,期刊數據庫、網絡資源等對人名消歧和辨識有強烈的需求,然而封閉在圖書館內的規范數據卻無法提供給外界使用。
針對以上問題,本文借鑒文獻數據庫系統中的著者唯一標識、機器學習領域的自動身份辨識和有效信息源獲取,提出基于著者交互的自規范、自動人名消歧和開放關聯數據的個人名稱規范維護方法,并分別對這些方法進行介紹,指出它們可解決的名稱規范問題,并給出如何實現維護的具體方案或做法。
2 著者交互的自規范
2.1 自規范模式及相關應用
因為著者更了解自身的相關信息和著作,所以采用自下而上、由著者主導的聯合共建模式,是提升個人名稱規范數據質量、規模和范圍的途徑與方法。本文將無需外界指令而由著者自發和協同地實現個人信息生成和完善,以及不同人辨識的過程稱為自規范。自規范是一種自下而上、去中心化的由著者主導的聯合共建模式,由著者協同地維護個人名稱規范數據。
著者交互的自規范可解決自上而下維護模式的問題,具體表現在:一是廣泛的著者參與能消除自上而下維護的局限,擴大個人名稱規范數據的規模和范圍;二是著者熟悉自身情況,能準確辨識規范庫中的個人身份,區分同名著者,發現由更名、別名構建的重復記錄;三是添加和修改生卒年、研究領域、相關作品、所在機構等信息,可完善名稱規范數據,提高個人名稱規范數據質量。
自規范應用出現在文獻數據庫系統,這些系統大都由著者填寫自身及相關學術信息并進行注冊,系統會為每個著者分配一個唯一標識符(Identifier),如Research ID[3]、Scopus Author ID[4]和arXiv Author ID[5]等。該做法可有效消除姓名拼寫方式混淆和重名問題,但只局限在某一范圍或系統內,整體上還是削弱了著者標識符辨識度,同時系統間的分割導致了同一著者多次注冊、多入口操作和有多個標識符。針對以上情況,近幾年出現了ORCID(Open Researcher and Contributor Identifier,開放研究者與貢獻者身份),目的是解決各系統間著者姓名混淆和識別問題。ORCID在兼容性和互操作方面進行嘗試,建立與各系統著者標識符的關聯,并將著者相關信息和科研情況聚合起來;同時不受學科、機構和地理的限制,免費向全球學術界開放并提供服務[6],這種擴大數據和服務范圍的做法真正起到了不同著者唯一身份辨識的作用。
2.2 基于自規范的個人名稱規范維護
個人名稱規范維護可借鑒自規范相關應用,以搭建網絡平臺為渠道,通過著者辨識、修改、合并和新增等參與形式達到維護個人名稱規范數據的目的。構建自規范平臺要重點實現以下3方面:
(1)在數據維護方面,著者新增或修改的信息項包括別名、更名、出生年月、所在機構、發表文獻情況、研究興趣、教育程度、工作單位和開展項目等,平臺構建者需將其與規范數據MARC格式建立映射,用以自動完善個人名稱規范數據附加成分、單純參照等相關字段,并能將著者在平臺新建的數據批量轉化為圖書館規范記錄,從而大幅提高個人名稱規范數據的維護效率。
(2)在系統設計方面,通過技術手段和友好性設計降低著者參與的復雜度。平臺構建者需規避專業的MARC格式,設計新增、修改、合并模板并內嵌到系統內,通過著者參與挖掘頭腦里有關人的事實信息來新建、修改和補充個人記錄。除此之外,以易于理解的形式和語言幫助著作開展相關操作,同名規范數據的展示要利于其辨識,盡量采取客觀形式完成信息項的填寫。
(3)在參與度方面,要增強著者粘性。只維護數據難以提高著者的參與興趣,平臺構建者應設計相關功能來增強著者參與的驅動力,如開發個人科研管理模塊以自動導入和生成科研成果,幫助著者發現開展相似項目的合著者等;同時與出版界、科研機構、學術界等開展合作,他們對科研產出者有準確識別和名稱消歧的需要,通過這些切合點帶動更多的科研產出者參與到自規范中,從而擴大個人名稱規范維護和控制的范圍和能力。
3 自動人名消歧
我國存在大量未能顯著區分的同名個人名稱規范數據,該類數據在維護和書目掛接時需要人工逐條分析、比對和辨別,嚴重影響編目員的工作效率,成為個人名稱規范維護和控制中的突出問題。自動人名消歧可彌補人工維護的不足,利用相關方法和技術自動區分重名著者和聚合著者別名作品,從而實現個人名稱規范維護及控制。另外,受圖書館傳統維護模式與方法的影響,我國名稱規范控制工作局限于專著領域,而數字圖書館、網絡資源和期刊數據庫等對名稱規范控制有強烈的訴求,自動人名消歧非常適用于網絡和數字環境,有快速區分海量數據著者及其作品的能力,更好地適應不斷擴大的數字化趨勢。
3.1 基于著作文體的辨識
文體學是用統計學中定量方法來分析著者寫作風格的一種學科。著者都具有自己特定的寫作習慣和風格,這種無意識和根深蒂固的寫作習慣和風格會在所寫的著作中通過各種特征表現出來。因此,計算機可以通過統計特征來分析著者寫作風格,從而能快速區分同名著者作品、聚合同人異名作品。
首先,著者文體識別需要提取出能代表著者文體風格的識別特征(Identification Attributes),并根據這些特征評估作品之間文體風格的相似程度。能有效區分著者文體的識別指標可歸類為4個方面(見表1)[7-8]。其中,詞匯和句法特征中詞、標點符號和功能詞等的使用情況可以體現著者的寫作特點和風格;結構特征反映著者如何組織整個篇章結構,不同著者對整體文本的呈現有不同偏好;內容特征體現著者感興趣的主題類別。
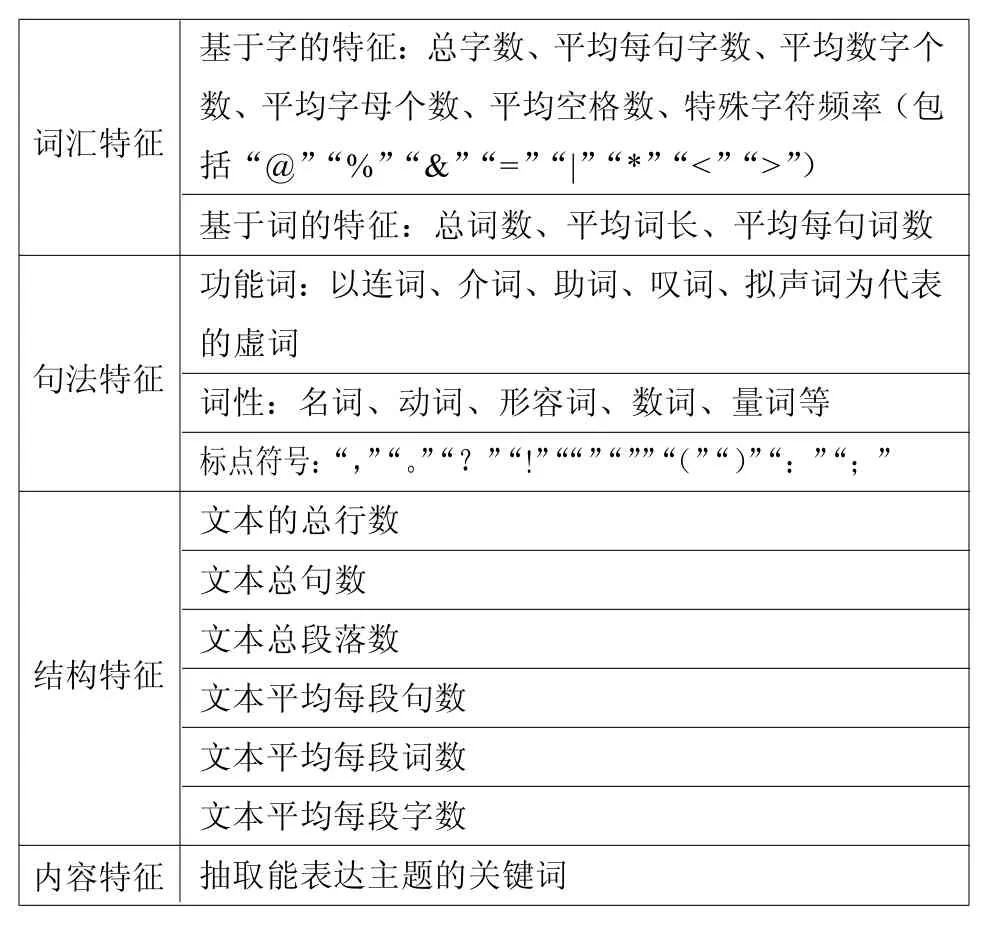
表1 文體風格識別指標
其次,著者文體識別需設計各識別指標的統計方法或公式。詞匯特征中,基于字的特征中各平均數指標分別用總數字個數、總字母個數、總空格數、每個特殊字符數除以總字數得出,而平均每句字數用總字數除以句子數得到;基于詞的特征提取要進行中文分詞,可利用已有成熟的分詞軟件,平均詞長用總字數除以總詞數,平均每句中的字數和詞數分別用總字數和總詞數除以句子數獲取;句法特征中,通過統計標點符號、功能詞和詞性的使用頻率來判斷著者的寫作風格;結構特征中平均每段的句、詞、字數分別用總句數、詞數和字數除以段落數獲得;內容特征主要抽取能表達主題的關鍵詞,可通過TF-IDF、詞頻、互信息等方法提取。
3.2 基于著作外部特征的辨識
基于著作外部特征的辨識是利用著者的合著者、題名、研究方向、關鍵詞、出版物名稱及類型、著者機構、引文和分類號等作為特征,使用機器學習中的相似度計算、自動分類及自動聚類等方法,將重名著者中同一人的作品聚合在一起,而將不同人的作品分開的過程,可利用該方法自動區分重名著者和聚合同人別名著者的作品,達到個人名稱規范維護及控制的目的。
(1)算法介紹
基于著作外部特征的辨識包括著者分組法和著者分配法。著者分組法通過相似度函數計算文獻屬性的相似度值從而將同一著者的作品集合到一起,其中值越高代表文獻之間的相似度越高,表明為同一著者所著的可能性就越大。計算相似度包含兩種算法:預定義相似度函數是在算法中植入預先定義的函數或公式,如余弦相似函數、TFIDF、Levenshtein距離和Jaccard公式等[9];基于學習的相似度函數需要訓練數據集②來標注各個文獻是否屬于同一著者,然后在此基礎上生成精確的相似度函數來區分同名作品[10-11]。
著者分配法構建著者模型,將作品分配給不同的著者,包括分類和聚類兩類方法。分類法需要準備訓練數據集,即用相關特征與正確著者關聯以幫助訓練生成消歧函數,之后用該函數對作品集合選擇分類算法進行分配[12-13];聚類方法通過構建著者的數學模型,直接選擇相應的聚類算法,如劃分法、層次法、基于密度的方法和基于網格的方法等將作品分配給所屬的著者[14-15]。
(2)算法選用
著者分組法針對只有一個同名著者而有多個作品的情況,通過計算作品之間的相似度聚合同一著者的作品;著者分配法適合有多個同名著者且有多個作品的情況,區分同名異人的作品,聚合同人異名的作品。
著者分組法包含的兩種方法各有優劣,在區分同名著者作品時,要根據自身數據情況選擇合適的算法。基于學習的相似度函數對不同數據集都有好的區分結果,但是需要大量的例子和充足的特征,構建費時費力;預定義函數不需要訓練數據集,但是面對不同的集合需要調整新的函數來適應。對于已有訓練數據集基礎、易構建的情況,可考慮采用基于學習的相似度函數方法,否則可采用高效的預定義函數,嵌入較多的預定義函數以增強對數據的適應性。
著者分配法中,分類方法有較高的準確度,但需人工構建訓練數據集,面對海量數據進行人工標注的工作量巨大,限制了該方法在自動人名消歧中的應用。聚類方法不需要訓練數據集,適用性較高,是當前自動人名消歧的主流方法,但預先設定聚類個數、判斷數據分布特征等做法影響準確性,因此EM算法和Gibbs抽樣可彌補一般聚類算法的不足。
4 發布開放關聯數據
4.1 去除MARC格式
MARC格式是制約當前圖書館資源開放利用的最大障礙。隨著技術的發展和信息環境的改變,讀者利用圖書館資源的對象和方式發生巨大變化,MARC格式的種種局限在網絡時代越來越成為絆腳石:一方面在技術上,圖書館的MARC記錄雖然可以通過互聯網查詢,但是ISO2709格式依然作為其交換格式,除了按照C/S時代研發的Z39.50標準開放的API接口之外,基本沒有其他互操作方式;另一方面在領域上,網絡上充斥的錯誤、冗余和虛假信息需要規范控制,而MARC因其領域上的封閉性已無法滿足這種需求。MARC格式的數據被牢牢“圈養”在各個圖書館的OPAC范圍內,缺乏方便生成一個國家或地區的聯合數據的技術和能力,更不用說開放給整個社會使用[16]。
名稱規范發布為開放關聯數據,是采用RDF格式將封閉在圖書館由MARC格式表示的名稱規范數據開放到Web上,通過定義能用于識別名稱規范的詞匯集以實現唯一標識,并借助這些詞匯建立相關名稱標識的自動語義鏈接,實現與其他系統數據的互操作以及無縫訪問和獲取多來源、異構資源,具體表現在:
(1)我國名稱規范控制工作局限于專著領域,名稱規范通過獲取來源于期刊數據庫、網絡和他國信息源的開放關聯數據,能夠擴展本地名稱規范數據種類、范圍和規模[17]。
(2)完善和提升本地數據質量。本地規范記錄可通過URI(Uniform Resource Identifier,統一資源標識符)和詞匯集的關聯自動發現和整合開放數據集合中特定人的相關信息,可用來完善自身附加成分、單純參照和信息附注,提高個人名稱規范數據質量。除此之外, skos:related等詞匯挖掘與該規范記錄相關的人和機構等從而幫助構建個人名稱規范數據的相關參照。
(3)圖書館高質量的規范數據在語義網環境下開放,可以被外部檢索使用,能夠促進對分布異構式網絡發揮規范控制作用。
4.2 基于開放關聯數據的個人名稱規范維護
基于開放關聯數據的個人名稱規范維護涉及到管理策略和具體實現。機構首先要制定相關管理策略,包括開放哪些數據,在技術和人力方面的支持、準備和管理等。在實施初期可以分階段逐步推進,在實現規范數據自身開放的基礎上,逐漸實現與其他資源的互操作。
實現基于開放關聯數據的個人名稱規范維護的措施具體有以下3方面:
(1)用URI標識規范記錄
URI形式穩定,和規范記錄是固定關系,因此無論何種環境都可用URI來表示該規范記錄,避免由名稱表示人名帶來的種種歧義[18]。用戶通過HTTP URI訪問來實現對數據的參引(Dereference,即查找和獲取)。
(2)個人名稱規范數據的語義描述
名稱規范數據的語義描述就是將名稱規范數據MARC格式轉換為RDF表達形式,即通過“主體-謂詞-客體”三元組(Triple)描述著者規范中各項內容[19]。
建立個人名稱規范數據MARC格式字段及子字段對應的RDF詞匯映射表,方便計算機自動批量實現名稱規范數據的語義化描述。為保證共享和重用,數據在轉化過程中要盡量利用已標準化和成熟的詞匯集描述,避免自造新詞匯,并根據中文人名的特點,采用SKOS(Simple Knowledge Organization System,簡單知識組織系統)[20]、Schema. org[21]和FOAF(Friend of a Friend,朋友的朋友)[22]已有詞匯組合定義中文人名規范數據的語義描述詞匯集,如表2所示。
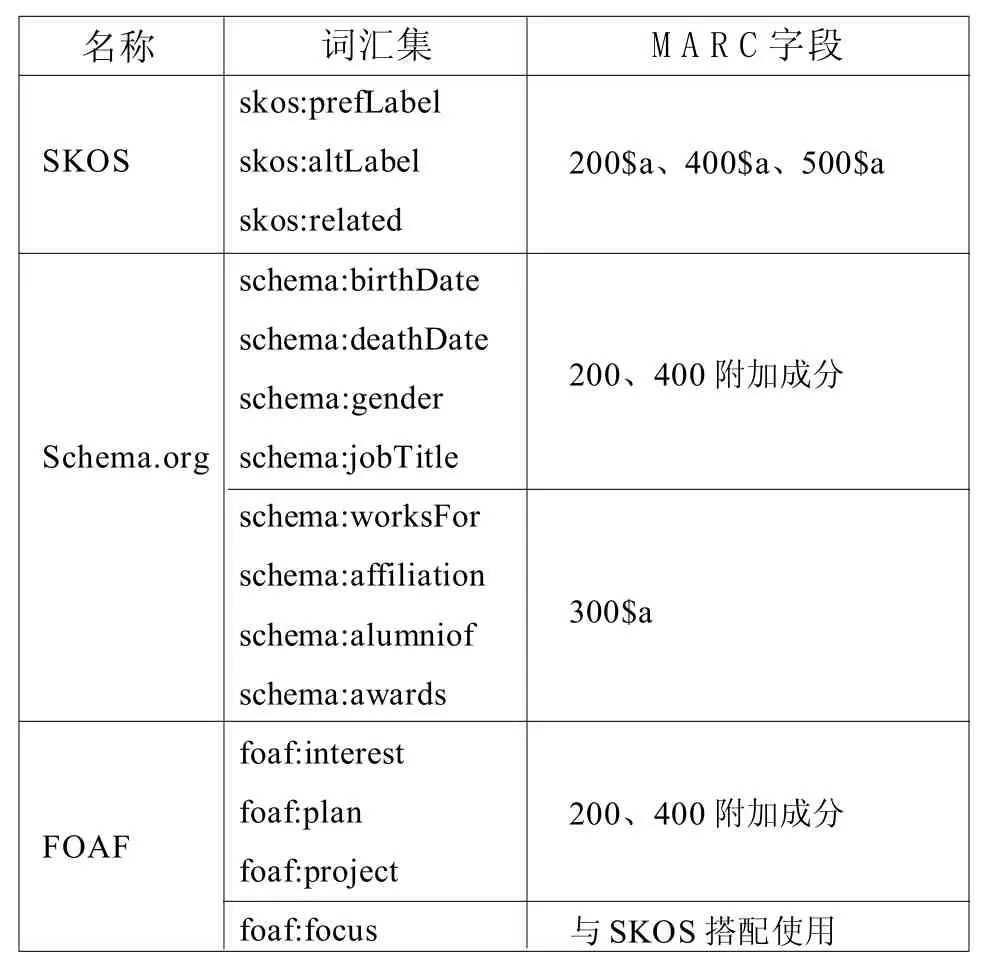
表2 RDF詞匯與名稱規范MARC格式映射表
(3)與其他數據集建立關聯
建立與其他外部數據集的廣泛關聯,便于本地數據在不同數據集跳轉,幫助本地數據發現、重用已有資源來擴大本地規范規模和完善自身數據。目前可選擇關聯的與人相關的開放數據有:VIAF(Virtual International Authority File,虛擬國際規范文檔)和NACO(Name Authority Cooperative Program,名稱規范合作項目)都聯合了多國的名稱規范數據;BIO本體描述關于人的傳記類信息,包括出生日期、職業、事件、地點等信息;Wikipedia可定位關于人的百科文章;FOAF對人及其所關聯的社會網絡進行描述;Organization本體描述機構,包括成員、角色和活動等信息[23]。
關聯其他數據源雖然可通過匹配算法實現,仍需要人工修正,因此并不是要關聯任何來源數據,而是根據一定的標準來選擇:一是該資源被廣泛參考引用,二是該資源信息豐富,可用來完善本地數據。
5 結 語
我國名稱規范維護中的突出問題希望能引起相關機構的關注及重視,采用相關方法和措施幫助改善我國名稱規范維護能力和效率較低下、數據質量不高的現狀,真正發揮出名稱規范控制應有的功能及效果。
注 釋:
①白板數據為只有著者姓名而無其他信息的數據。
②訓練數據集屬于機器學習中語料庫的范疇,通過其可獲得相關參數以提高準確性。
參考文獻 :
[1]曹玉強.國家圖書館中文名稱規范的探討[J].圖書館建設,2007 (3):46-48.
[2]謝琴芳. CALIS中文名稱規范數據庫建設方案及其實施進展[J].新世紀圖書館, 2005(1):3-6.
[3]Research ID[EB/OL]. [2015-08-27]. http://www.researchid.com/.
[4]Scopus Author Identifier [EB/OL]. [2015-08-27]. http://help. scopus.com/Content/h_autsrch_intro.htm.
[5]Author Identifiers[EB/OL]. [2015-08-27]. http://arxiv.org/help/ author_identifiers.
[6]What is ORCID[EB/OL]. [2015-09-18]. http://orcid.org/content/ initiative.
[7]呂英杰, 范 靜, 劉景方. 基于文體學的中文UGC作者身份識別研究[J]. 現代圖書情報技術, 2013,29(9):48-53.
[8]Baayen H, Halteren H V, Neijt A, et al. An Experiment in Authorship Attribution[C]// In Proceedings of the 6th International Conference on Statistical Analysis of Textual Data. Saint Malo:LED, 2002:29-37.
[9]Soler M. Separating the Articles of Authors with the Same Name[J]. Scientometrics, 2007,72(2):281-290.
[10]Torvik V I, Smalheiser N R. Author Name Disambiguation in MEDLINE[J]. ACM TKDD, 2009,3(3):1-29.
[11]Ferreira A A, Goncalves M A. Laender A H F. A Brief Survey of Automatic Methods for Author Name Disambiguation[J]. SIGMOD Record, 2012,41(2):15-26.
[12]郭 舒. 文獻數據庫中作者名自動化消歧方法應用研究[J]. 情報雜志, 2013,32(9):132-137.
[13]Han Hui, Zha Hongyuan, Giles C L. Name Disambiguation in Author Citations Using a K-Way Spectral Clustering Method [C]// In Proceedings of the 5th ACM/IEEE-CS Joint Conference on Digital Libraries. New York: ACM, 2005:334-343.
[14]任景華. 利用優化的DBSCAN算法進行文獻著者人名消歧[J].圖書館理論與實踐, 2014(12):62-68.
[15]Tang Jie, Fong A C M, Wang Bo, et al. A Unified Probabilistic Framework for Name Disambiguation in Digital Library[J]. Knowledge and Data Engineering, 2012,24(6):975-987.
[16]劉 煒.書目數據新格式BIBFRAME及其應用[J]. 大學圖書館學報, 2014(1):5-13.
[17]Ilik V. Cataloger & Makeover: Creating Non-MARC Name Authorities[J]. Cataloging & Classification Quarterly, 2015(53): 382-398.
[18]Report for PCC Task Group on the Creation and Function of Name Authorities in a Non-MARC Environment[EB/OL]. [2015-09-27]. http://www.loc.gov/aba/pcc/rda/RDA%20Task% 2 0grou ps%2 0 and%2 0char ges/R epor t P CC T Gon NameAuthInA_NonMARC_Environ_FinalReport.pdf.
[19]Schreiber G, Raimond Y. PDF 1.1 Primer[EB/OL]. [2015-06-07]. http://www.w3.org/TR/rdf11-primer/.
[20]Simple Knowledge Organization System Reference [EB/OL]. [2015-09-18]. http://www.w3.org/TR/2009/REC-skosreference-20090818/.
[21]Person[EB/OL]. [2015-09-18]. http://schema.org.cn/Person.
[22]Dan B, Libby M. FOAF Vocabulary Specification 0.99[EB/OL]. [2015-09-18]. http://xmlns.com/foaf/spec/.
[23]賈君枝. 開放書目數據的實現與發展[J]. 晉學圖刊, 2015(1): 1-4.
Study on the New Methods of Personal Name Authority Maintenance
[Key words]Personal name authority maintenance; Self-authority; Automatic author name disambiguation; Open linked data; Non-MARC
[Abstract]Top-down, artificial and closed maintenance mode in our country have seriously affected the name authority maintenance's ability and efficiency, and also affected the effect of authority control. Personal name authority maintenance methods of self-authority based on author interaction, automatic author name disambiguation and open linked data draw the lessons from the contributor identifier in the document database system, automatic authorship identification of machine learning domain and effective information source acquisition, change the status of less quantity, limited coverage and low quality of data in China, resolve the problems of name authority maintenance mode, such as poor maintenance capacity, low efficiency and unable to operate with the outside world, which developing function and effect of the name authority control.
[中圖分類號]G254
[文獻標識碼]A
[作者簡介]
郝嘉樹 女,1983年生,現工作于國家圖書館,館員,已發表論文5篇,參與編寫著作5部。
[ 收稿日期:2015-10-13 ]
