一種基于Hadoop云計算平臺大數(shù)據(jù)聚類算法設(shè)計*1
2016-09-02 07:26:14司福明卜天然安徽機電職業(yè)技術(shù)學(xué)院信息工程系安徽蕪湖241000
楚雄師范學(xué)院學(xué)報 2016年3期
關(guān)鍵詞:數(shù)據(jù)挖掘
司福明,卜天然(安徽機電職業(yè)技術(shù)學(xué)院信息工程系,安徽 蕪湖 241000)
一種基于Hadoop云計算平臺大數(shù)據(jù)聚類算法設(shè)計*1
司福明,卜天然
(安徽機電職業(yè)技術(shù)學(xué)院信息工程系,安徽 蕪湖 241000)
傳統(tǒng)的數(shù)據(jù)挖掘技術(shù)由于受到編程模型等的約束,產(chǎn)生了不同瓶頸,聚類算法的研究面臨著海量的大數(shù)據(jù)處理與分析的挑戰(zhàn),新興計算模型Hadoop作為一種可并行處理的云計算平臺得到了廣泛應(yīng)用。文章對傳統(tǒng)聚類挖掘算法進行改進和優(yōu)化,在Hadoop云計算平臺上進行K-means算法的并行化實現(xiàn),降低算法的時間復(fù)雜度,提高了計算效率。實踐證明,改進的K-means算法適合大規(guī)模數(shù)據(jù)集的聚類挖掘,具有高效、準(zhǔn)確、穩(wěn)定、安全等特性,適合于海量數(shù)據(jù)的分析和處理。
Hadoop;云計算平臺;大數(shù)據(jù);聚類挖掘算法;并行化
1 引言
大數(shù)據(jù)技術(shù)、物聯(lián)網(wǎng)、云計算是當(dāng)今IT產(chǎn)業(yè)具有顛覆性的技術(shù)革命。大數(shù)據(jù)時代的到來對人們的生活方式、商業(yè)模式都發(fā)生著重要影響。隨著大數(shù)據(jù)的提出,給信息技術(shù)產(chǎn)業(yè)帶來了新的發(fā)展機遇,尤其對數(shù)據(jù)挖掘技術(shù)影響更為明顯。數(shù)據(jù)挖掘技術(shù)進入一個新的發(fā)展階段,要提高大數(shù)據(jù)的準(zhǔn)確性,大數(shù)據(jù)的挖掘算法對大數(shù)據(jù)處理結(jié)果的誤差率必須在可接受的范圍內(nèi),這就需要對傳統(tǒng)數(shù)據(jù)挖掘算法進行改進。文章以提高大數(shù)據(jù)挖掘效率和準(zhǔn)確度為目標(biāo),將面向大數(shù)據(jù)的聚類挖掘算法準(zhǔn)確度和效率作為研究重點,對傳統(tǒng)的聚類算法進行了必要的改進并利用云計算平臺將改進后的聚類挖掘算法進行并行化實驗。改進型的聚類算法具有較好的理論和實用價值,可在大數(shù)據(jù)集的應(yīng)用平臺進行廣泛推廣和應(yīng)用[1]。
2 關(guān)鍵技術(shù)概述
2.1基于hadoop的云計算平臺
2.1.1云計算技術(shù)
云計算作為一種基于互聯(lián)網(wǎng)的服務(wù)交付和使用模式,是指通過網(wǎng)絡(luò)以按需、易擴展的方式獲得所需服務(wù)。它的核心思想是將大量用網(wǎng)絡(luò)連接起來的計算資源統(tǒng)一管理和調(diào)度,構(gòu)成一個資源池向用戶提供按需服務(wù)。云計算為用戶提供了最可靠、最安全的數(shù)據(jù)存儲中心,用戶可不再顧慮數(shù)據(jù)丟失、病毒入侵等問題。云計算的應(yīng)用模式主要有:軟件即服務(wù) (SaaS)、平臺即服務(wù)(PaaS)、基礎(chǔ)實施即服務(wù) (IaaS)三種。
2.1.2Hadoop
Hadoop是一個開源的、可以編寫和運行分布式應(yīng)用來處理大規(guī)模數(shù)據(jù)的框架 (平臺)。其主要特點是用戶可以在不了解分布式底層細節(jié)的情況下,開發(fā)分布式程序充分利用集群的威力進行高速運算和存儲。
(1)HDFS(Hadoop Distributed File System):分布式文件系統(tǒng),可實現(xiàn)分布式存儲;
(2)MapReduce:分布式程序框架,可實現(xiàn)分布式計算。MapReduce程序框架如下:
Map函數(shù):鍵/值對映射
<k1,v1>→<k2,v2>
E.g.:<k1,v1>:<1,“abcd”>,<2,“cde”>,<3,“acd”>,…..
<k2,v2>:<‘a(chǎn)’,2>,<‘b’,1>,<‘c’,3>,……
Reduce函數(shù):規(guī)約
<k2,list(v2)>→<k3,v3>
E.g.:<k2,list(v2) >:<‘a(chǎn)’,list(1,2,3) ><k3,v3>:<‘a(chǎn)’,6>
基于Hadoop云計算平臺,建立HDFS分布式文件系統(tǒng)存儲海量文本數(shù)據(jù)集,通過文本詞頻利用MapReduce原理建立分布式索引,以分布式數(shù)據(jù)庫HBase存儲關(guān)鍵詞索引,并提供實時檢索,從而可實現(xiàn)對海量數(shù)據(jù)進行的分布式并行處理。
2.2大數(shù)據(jù)技術(shù)
Big Data(大數(shù)據(jù)技術(shù)),因近年來互聯(lián)網(wǎng)、云計算、移動和物聯(lián)網(wǎng)的迅猛發(fā)展而成為廣為關(guān)注的熱點話題。大數(shù)據(jù)是一種規(guī)模大到在獲取、存儲、管理、分析方面大大超出了傳統(tǒng)數(shù)據(jù)庫軟件工具能力范圍的數(shù)據(jù)集合,具有海量的數(shù)據(jù)規(guī)模、快速的數(shù)據(jù)流轉(zhuǎn)、多樣的數(shù)據(jù)類型和價值密度低四大特征。從技術(shù)層面來看,大數(shù)據(jù)與云計算的關(guān)系是密不可分的。大數(shù)據(jù)在使用過程中必須采用分布式架構(gòu),其特點在于對海量數(shù)據(jù)進行分布式的數(shù)據(jù)挖掘。但它必須依托云計算的分布式處理、分布式數(shù)據(jù)庫和云存儲、虛擬化技術(shù)[2]。
2.3聚類挖掘技術(shù)
聚類分析是數(shù)據(jù)挖掘采用的核心技術(shù),聚類分析基于“物以類聚”的樸素思想,根據(jù)事物的特征對其進行聚類或分類。從隱性層面來看,聚類分析的結(jié)果將會得到一組數(shù)據(jù)對象的集合,我們稱其為簇。在簇中的對象是彼此相似的,而其他簇中的對象則是相異的。在許多應(yīng)用中,可以將一個簇中的數(shù)據(jù)對象作為一個整體來對待。
聚類挖掘技術(shù)最早在統(tǒng)計學(xué)和人工智能等領(lǐng)域得到廣泛的研究。近年來,隨著數(shù)據(jù)挖掘的發(fā)展,聚類以其特有的優(yōu)點,成為數(shù)據(jù)挖掘研究領(lǐng)域一個非常活躍的研究課題。在數(shù)據(jù)挖掘領(lǐng)域內(nèi),經(jīng)常面臨含有海量數(shù)據(jù)的數(shù)據(jù)庫,因此,要不斷改進面向大規(guī)模數(shù)據(jù)庫的聚類方法,以適應(yīng)新問題帶來的挑戰(zhàn)。
3 改進K-means聚類算法研究
3.1K-means聚類算法基本思想與方法
K-means算法是很典型的基于距離的聚類分析算法,它采用距離作為相似性評價的指標(biāo),即:如果兩個對象的距離越近,則它的相似度就越大。這種算法是認為簇是由距離靠近的對象而組成的,因此它把能夠得到緊湊并且獨立的簇作為最終的目標(biāo)[3]。
算法過程如下:
(1)從N個文檔中隨機地選取K個文檔作為質(zhì)心
(2)測量剩余的每一個文檔到每個質(zhì)心的距離,同時將它歸到最近質(zhì)心的類
(3)再進行重新計算已經(jīng)獲得的每個類的質(zhì)心
(4)迭代第二和第三步直到新質(zhì)心和原質(zhì)心相等或小于指定閾值
(5)算法完成
具體算法描述如下:
輸入:k,data[n];
(1)選擇k個初始中心點,例如c[0] =data[0],…c[k-1] =data[k-1];
(2)對于data[0]….data[n],分別與c[0]…c[k-1]比較,假定與c[i]差值最少,就標(biāo)記為i;
(3)對于所有標(biāo)記為i點,重新計算c[i] ={所有標(biāo)記為i的data[j]之和}/標(biāo)記為i的個數(shù);
(4)重復(fù) (2)(3),直到所有c[i]值的變化小于給定閾值。
3.2基于密度的增量的DBIK-means改進方法
k-means算法缺點:在K-means算法中,K往往是給定的,因此,K值的選定是很難估計的。在運算之前,不清楚給定的數(shù)據(jù)集應(yīng)該分成多少種類別才最恰當(dāng)。在K-means算法中,需要根據(jù)初始聚類中心來確定初始劃分,然后進行優(yōu)化。這種選擇對聚類分析的結(jié)果會產(chǎn)生比較大的影響,如果初始值選擇不好,則有可能無法獲取有效的聚類結(jié)果。此外,在K-means算法框架中可以發(fā)現(xiàn),當(dāng)運算的數(shù)據(jù)量較大時,算法的時間開銷則非常之大。所以需要對算法的時間復(fù)雜度進行一定程度的改進[4]。
綜合k-means聚類算法的缺點,結(jié)合密度增量的基本思想,文章提出基于密度的增量kmeans聚類算法。
改進的k-means算法以基于密度的k-means聚類結(jié)果為依據(jù),對X-Y數(shù)據(jù)集合聚類。作為相異度的計算公式,DBIK-means聚類算法的偽代碼如下:
輸入:數(shù)據(jù)集合X,密度閾值minPts
輸出:若干任意形狀的簇
步驟:
從集合X中隨機取小部分數(shù)據(jù)集Y,YX,同時計算Eps的大小
List centerPoint=null,clusters=null;//初始中心點集合,簇的集合都為空
for i=1 to|Y|//|Y|表示數(shù)據(jù)集合Y的大小,for循環(huán)用于計算數(shù)據(jù)點的密度


將集合Y中沒有劃分到任意簇的點劃分到與其相異度最近的簇中;
計算簇的中心點之間的距離的均值Dave;
for i=1 to|X-Y|//將集合X-Y中的點劃分到與其相異度最小的簇中

DBIK-means聚類算法可以發(fā)現(xiàn)若干任意形狀的簇,在準(zhǔn)確率和時間復(fù)雜度方面,算法對數(shù)據(jù)的輸入順序和minPts參數(shù)不敏感,DBIK-means算法可以有效處理高維混合屬性的數(shù)據(jù)集。
4 DBIK-means在云計算hadoop平臺設(shè)計
4.1DBIK-means聚類算法基于hadoop的并行優(yōu)化設(shè)計
聚類算法在Hadoop平臺上的實現(xiàn)過程比較復(fù)雜,需要實現(xiàn)map和reduce函數(shù)。DBIK-means聚類算法在Hadoop上的具體實現(xiàn)分為兩個階段。其設(shè)計最主要的內(nèi)容就是設(shè)計和實現(xiàn)map和Reduce函數(shù),包括輸入和輸出 <key,value>鍵值對的類型以及 map和 Reduce函數(shù)的具體邏輯等[5]。
(1)map函數(shù)設(shè)計
map函數(shù)的輸入包括一組<key,value>鍵值對的集合和密度閾值minPts,其中<key,value>是MapReduce框架默認的格式,key表示當(dāng)前數(shù)據(jù)集合相對于輸入數(shù)據(jù)文件起始點的偏移量,value為對應(yīng)的數(shù)據(jù);函數(shù)的輸出是一組<key1,value1>鍵值對的集合,其中key1表示簇的編號,value1表示屬于第key1個簇的相關(guān)屬性,包括簇的中心點、簇中點的個數(shù)Num、簇中所有點的和Sum以及簇中與中心點最遠的點與中心點的相異度,i的取值范圍為1到k,k表示簇的個數(shù)。函數(shù)的偽代碼如下:


(2)combine函數(shù)設(shè)計
combine函數(shù)的輸入為一組<key1,value1>鍵值對的集合,key1和value1的含義同map函數(shù)中的<key1,value1>鍵值對中的key1和value1一樣。combine的偽代碼如下:

(3)reduce函數(shù)設(shè)計
reduce函數(shù)的功能是將同一個DataNode中的多個map函數(shù)生成的<key,value>鍵值對集合進行合并,同時以JSON的格式持久化到分布式數(shù)據(jù)庫中,其偽代碼如下:

4.2hadoop平臺搭建與完全分布式實現(xiàn)
4.2.1hadoop平臺配置
采用完全分布模式才能真正體現(xiàn)Hadoop框架的優(yōu)勢所在。在綜合考慮資源使用效率和實驗中PC數(shù)量有限的情況下,采用將U0作為JobTracker和NameNode,U1至U4作為TaskTracker和DataNode的方式來實現(xiàn)完全分布模式的配置。從分布式存儲的層面考慮,Hadoop集群由三個部分組成,包括兩個必選部分即一個NameNode和若干個DataNode,和一個可選部分即Secondary NameNode;為了確保Hadoop集群的可靠性,Secondary NameNode作為NameNode的備份,當(dāng)且僅當(dāng)NameNode出現(xiàn)異常時,采用Secondary NameNode重新啟動整個Hadoop集群。從分布式應(yīng)用的層面考慮,Hadoop集群由一個JobTracker和若干個TaskTracker兩個必選部分組成,前者負責(zé)任務(wù)的調(diào)度管理,后者負責(zé)任務(wù)的并行執(zhí)行。為了便于進行數(shù)據(jù)的讀取和本地的計算,JobTracker最好運行在DataNode上,JobTracker和NameNode可以不在同一臺機器上[6]。
文章采用開源的分布式軟件Hadoop來搭建實驗用的云計算平臺,用于測試DBIK-means聚類算法的性能。使用四臺機器,都安裝fedora 9一個master三個slave這么做是為了測試hdfs分布式存儲時備份成三份,關(guān)掉某一臺slave看是否影響整體的文件系統(tǒng)。
虛擬機:VMware-workstation-6.0.5-109488;
操作系統(tǒng):操作系統(tǒng)fedora 9
系統(tǒng)配置:
四臺機器的具體網(wǎng)絡(luò)配置為:
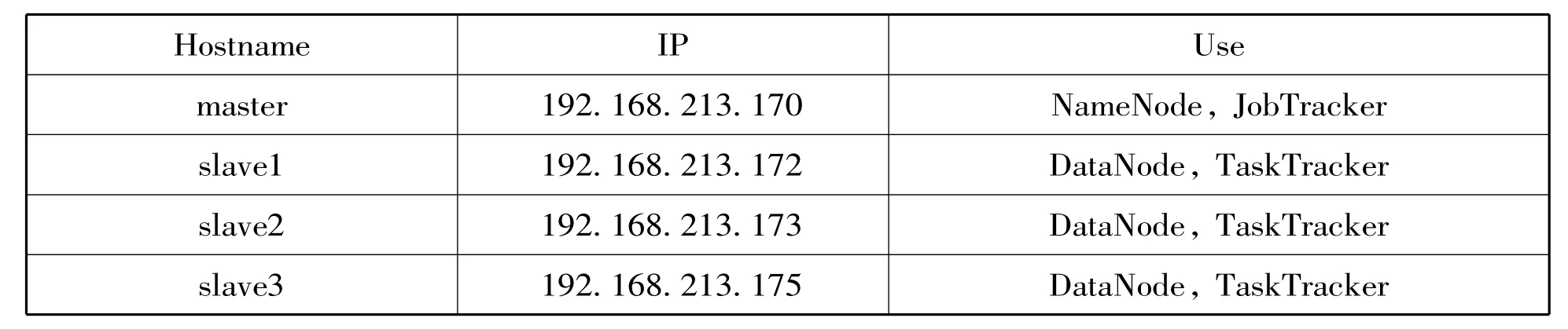
Hostname IP Use master 192.168.213.170 NameNode,JobTracker slave1 192.168.213.172 DataNode,TaskTracker slave2 192.168.213.173 DataNode,TaskTracker slave3 192.168.213.175 DataNode,TaskTracker
(1)進入到hadoop目錄下,配置conf目錄下的hadoop-env.sh中的JAVA_HOME的jdk路徑,例如:"export JAVA_HOME=/usr/Java/jdk1.6.0_23"。
(2)配置conf目錄下的core-site.xm l,在標(biāo)簽<configuration></configuration>中添加如下配置:
Xm l代碼如下:

(3)配置conf目錄下的mapred-site.xm l在標(biāo)簽<configuration></configuration>中添加如下配置:
Xm l代碼如下:

4.2.2實驗分析及小結(jié)
Hadoop配置好之后,在NameNode即U0機器的終端中執(zhí)行start-all.sh,啟動Hadoop進程。當(dāng)?shù)谝淮螁親adoop時,需要運行Hadoop namenode-format命令對系統(tǒng)進行格式化。Hadoop啟動之后,會自動啟動瀏覽器,顯示NameNode的管理頁面,集群中各個DadaNode節(jié)點的狀態(tài)、已用存儲空間、剩余存儲空間和blocks數(shù)目等[7]。在完全分布式環(huán)境下對DBIK-means聚類算法進行仿真實驗,通過實驗驗證了DBIK-means聚類算法在處理大數(shù)據(jù)時,能夠得到更好的聚類結(jié)果和更短的運行時間,數(shù)據(jù)量越大,時間性能優(yōu)勢越明顯,借助云平臺能夠獲得更好的加速比。但改進算法對于具有密集噪聲點等方面的數(shù)據(jù)處理仍然存在局限性,需要進一步加以完善。
[1]周愛武,崔丹丹,潘勇.一種優(yōu)化初始聚類中心的K-means聚類算法 [J].微型機與應(yīng)用,2011,30(13):1—3,9.
[2]江小平,李成華,等.K-means聚類算法的MapReduce并行化實現(xiàn)[J].華中科技大學(xué)學(xué)報,2011,39(S1):120—124.
[3]孫吉貴,劉杰,趙連宇.聚類算法研究[J].軟件學(xué)報,2008,19(1):48—61.
[4]Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107—113.
[5]趙衛(wèi)中,馬慧芳,傅燕翔,等.基于云計算平臺Hadoop的并行k-means聚類算法設(shè)計研究[J].計算機科學(xué),2011,38(10):166—168.
[6]張琳,陳燕,汲業(yè),等.一種基于密度的K-means算法研究[J].計算機應(yīng)用研究,2011,28(11):71-73.
[7]Chang F,Dean J,Ghemawat S,et al.Bigtable:A distributed storage system for structured data [J].ACM Transactions on Computer Systems(TOCS),2008,26(2):1—4.
(責(zé)任編輯劉洪基)
Design of a Large Data Clustering Algorithm Based on Hadoop Cloud Computing Platform
SIFuming&BU Tianran
(Dept.,of Information Engineering,Anhui Technical College of Mechanical and Electrical Engineering,Wuhu,241000,Anhui Province)
The traditional datamining technology due to the constraint programmingmodel,resulting in a bottleneck,clustering algorithm research faces the challenge ofmass of data processing and analysis,the emerging computingmodel Hadoop as a parallel processing of cloud computing platform has been widely used in many fields.In this paper,the traditional clusteringmining algorithm is improved and optimized. The K-means algorithm is implemented on Hadoop cloud computing platform,which can reduce the time complexity and improve the computational efficiency.Practice has proved that the improved K-means algorithm is suitable for large-scale data sets clustering mining,with high efficiency,accuracy,stability,security and other haracteristics,suitable for the analysis and processing ofmassive data.
Hadoop;cloud computing platform;big data;Clustering Mining Algorithm;Parallel
TP301.6
A
1671-7406(2016)03-0049-07
安徽省教育廳2016年度高校自然科學(xué)研究項目,項目編號:KJ2016A134。
2015-12-10
司福明 (1983—),男,講師,碩士研究生,研究方向:數(shù)據(jù)挖掘技術(shù),網(wǎng)絡(luò)化應(yīng)用系統(tǒng)。
猜你喜歡
艦船科學(xué)技術(shù)(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫(yī)藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
西安工程大學(xué)學(xué)報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設(shè)計工程(2014年18期)2014-02-27 12:00:13
電子設(shè)計工程(2014年18期)2014-02-27 12:00:12
