Spark大數(shù)據(jù)處理平臺(tái)的構(gòu)建及應(yīng)用
2016-09-08 08:56:34蔡文濤
中國(guó)新通信 2016年15期
蔡文濤
【摘要】 本文簡(jiǎn)述了大數(shù)據(jù)產(chǎn)生的原因及背景,并對(duì)大數(shù)據(jù)的4個(gè)特點(diǎn)進(jìn)行了說(shuō)明:數(shù)據(jù)體量巨大,數(shù)據(jù)種類(lèi)繁多,流動(dòng)速度快,價(jià)值密度低。由此引出對(duì)大數(shù)據(jù)處理平臺(tái)的需求,針對(duì)當(dāng)前最為流行的Spark處理平臺(tái),介紹了環(huán)境平臺(tái)的搭建過(guò)程及可能的相關(guān)分析應(yīng)用,為相關(guān)人員開(kāi)展大數(shù)據(jù)分析處理工作提供一定參考。
【關(guān)鍵字】 大數(shù)據(jù)分析 Hadoop Spark 內(nèi)存計(jì)算
一、引言
近年來(lái),大數(shù)據(jù)成為工業(yè)界與學(xué)術(shù)界關(guān)注的熱點(diǎn),因?yàn)殡S著存儲(chǔ)設(shè)備容量的快速增長(zhǎng)、CPU處理能力的大幅提升、網(wǎng)絡(luò)帶寬的不斷增加,也為大數(shù)據(jù)時(shí)代提供了強(qiáng)有力的技術(shù)支撐。從web1.0到web2.0,每個(gè)用戶(hù)都成為一個(gè)自媒體,一個(gè)互聯(lián)網(wǎng)內(nèi)容的提供者,這種數(shù)據(jù)產(chǎn)生方式的變革更是推動(dòng)著大數(shù)據(jù)時(shí)代的到來(lái)。
二、相關(guān)研究
什么是大數(shù)據(jù)呢?大數(shù)據(jù)是由結(jié)構(gòu)化與非結(jié)構(gòu)化數(shù)據(jù)組成的,其中10%為結(jié)構(gòu)化數(shù)據(jù),存儲(chǔ)于各類(lèi)數(shù)據(jù)庫(kù)中,90%為非結(jié)構(gòu)化數(shù)據(jù),非結(jié)構(gòu)化數(shù)據(jù)如圖片、視頻、郵件、網(wǎng)頁(yè)等,現(xiàn)如今,大數(shù)據(jù)應(yīng)用以滲透到各行各業(yè),數(shù)據(jù)驅(qū)動(dòng)決策,信息社會(huì)智能化程度大幅提高。目前,國(guó)內(nèi)相關(guān)技術(shù)主要集中在數(shù)據(jù)挖掘相關(guān)算法、實(shí)際應(yīng)用及有關(guān)理論方面的研究,涉及行業(yè)比較廣泛,包括零售業(yè)、制造業(yè)、金融業(yè)、電信業(yè)、網(wǎng)絡(luò)相關(guān)專(zhuān)業(yè)、醫(yī)療保健及科學(xué)領(lǐng)域,單位集中在部分高等院校、研究所和公司,特別是在IT等新興領(lǐng)域,阿里巴巴、騰訊、百度等巨頭對(duì)技術(shù)發(fā)展推動(dòng)作用巨大,而這些互聯(lián)網(wǎng)巨頭們?cè)诖髷?shù)據(jù)處理中,又紛紛采用了Hadoop、Spark這一處理框架。
三、基于spark的大數(shù)據(jù)處理平臺(tái)
3.1大數(shù)據(jù)平臺(tái)搭建
環(huán)境說(shuō)明:3臺(tái)裝有Ubuntu14.04操作系統(tǒng)的PC機(jī),Hadoop 2.6.0,Spark1.6.0。
Hadoop環(huán)境的搭建首先從apache官網(wǎng)下載合適版本的Hadoop代碼,本文中安裝的Hadoop版本為Hadoop 2.6.0。首先需要在各臺(tái)實(shí)驗(yàn)PC機(jī)之間設(shè)置SSH免密碼登錄,無(wú)密碼登錄的原理:用戶(hù)在 master上生成一個(gè)密鑰對(duì),包括一個(gè)公鑰和一個(gè)私鑰,并將公鑰復(fù)制到所有的 slave上。然后當(dāng) master 通過(guò) SSH 連接 slave 時(shí), slave 就會(huì)生成一個(gè)隨機(jī)數(shù)并用 master 的公鑰對(duì)隨機(jī)數(shù)進(jìn)行加密,并發(fā)送給 master ,master用自己的私鑰進(jìn)行解密得到解密數(shù),并將解密數(shù)回傳給slave,slave確認(rèn)解密數(shù)無(wú)誤之后就允許master不輸入密碼進(jìn)行連接了,通過(guò)免密碼登錄主節(jié)點(diǎn)于從節(jié)點(diǎn)之間即可進(jìn)行數(shù)據(jù)計(jì)算結(jié)果的快速交互。隨后確認(rèn)本機(jī)上是否安裝了jdk,如未安裝需要先安裝Java的jdk,本環(huán)境中使用的是jdk1.8.0版本。
然后將下載的Hadoop文件解壓到某個(gè)目錄下,進(jìn)行Hadoop的配置過(guò)程,涉及的配置文件有7個(gè),分別為hadoop-env.sh,yarn-env.sh,slaves,core-site.xml,hdfs-site. xml,mapred-site.xml,yarn-site.xml,具體配置參數(shù)可查看相關(guān)教程。在主節(jié)點(diǎn)(master)配置完畢后,將整個(gè)Hadoop文件夾依次拷貝到各個(gè)slave節(jié)點(diǎn)。Hadoop安裝完畢后,即可啟動(dòng)驗(yàn)證,首先格式化Hadoop節(jié)點(diǎn),執(zhí)行以下命令,只需格式一次:
$hadoop namenode -format
進(jìn)入Hadoop目錄下的sbin文件夾,啟動(dòng)Hadoop,
$./start-all.sh
檢查Hadoop進(jìn)程,
$jps
master節(jié)點(diǎn)上有如下進(jìn)程,如圖1:
slave節(jié)點(diǎn)上有如下進(jìn)程,如圖2: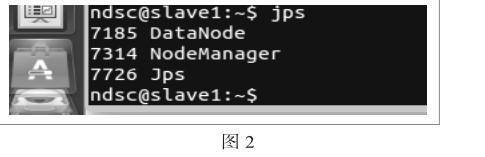
表明Hadoop集群已配置完成。
安裝完Hadoop后,即可進(jìn)行Spark安裝文件的配置,基本同Hadoop的配置相似,將Spark安裝完畢后,可以啟動(dòng)spark-shell查看安裝是否成功。
3.2大數(shù)據(jù)平臺(tái)分析
spark集群處理環(huán)境搭建完畢后,我們可以使用其進(jìn)行簡(jiǎn)單的數(shù)據(jù)分析,spark1.6.0中也為我們提供了示例代碼,涵蓋流計(jì)算、圖計(jì)算、機(jī)器學(xué)習(xí)、sql查詢(xún)處理等程序,用戶(hù)可以方便的參考學(xué)習(xí),從而進(jìn)行自己的開(kāi)發(fā)應(yīng)用。
參 考 文 獻(xiàn)
[1]王珊,王會(huì)舉,覃雄派,周烜. 架構(gòu)大數(shù)據(jù):挑戰(zhàn)、現(xiàn)狀與展望[J]. 計(jì)算機(jī)學(xué)報(bào). 2011(10)
[2]樊嘉麒. 基于大數(shù)據(jù)的數(shù)據(jù)挖掘引擎[D]. 北京郵電大學(xué) 2015
猜你喜歡
心理學(xué)報(bào)(2022年4期)2022-04-12 07:38:02
中老年保健(2021年12期)2021-08-24 03:30:40
水泵技術(shù)(2021年3期)2021-08-14 02:09:20
中國(guó)傳媒大學(xué)學(xué)報(bào)(自然科學(xué)版)(2021年1期)2021-06-09 08:43:00
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國(guó)生殖健康(2020年6期)2020-02-01 06:28:50
中國(guó)生殖健康(2019年11期)2019-01-07 01:28:02
電力與能源(2017年6期)2017-05-14 06:19:37
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
中國(guó)慣性技術(shù)學(xué)報(bào)(2015年1期)2015-12-19 13:12:17
