基于多主分量神經網絡的同步DS-CDMA偽碼盲估計
2016-11-11 08:24:58張天騏趙軍桃江曉磊
系統工程與電子技術 2016年11期
關鍵詞:信號
張天騏,趙軍桃,江曉磊
(重慶郵電大學信號與信息處理重慶市重點實驗室,重慶 400065)
?
基于多主分量神經網絡的同步DS-CDMA偽碼盲估計
張天騏,趙軍桃,江曉磊
(重慶郵電大學信號與信息處理重慶市重點實驗室,重慶 400065)
針對批處理方法在實現非等功率同步直接序列碼分多址(direct sequence code-division multiple access,DS-CDMA)信號偽碼序列盲估計時存在的復雜度高、收斂速度慢的問題,引入了3種多主分量神經網絡(Sanger NN、LEAP NN和APEX NN)。首先將已分段的一周期DS-CDMA信號作為神經網絡的輸入信號,用神經網絡各權值向量的符號函數代表DS-CDMA信號各用戶的偽碼序列,然后通過不斷輸入信號來反復訓練權值向量直至收斂,最終DS-CDMA信號各用戶的偽碼序列就可以通過各權值向量的符號函數重建出來。此外,本文提出了一種在遞歸最小二乘(recursive least square,RLS)意義下的最優變步長收斂模型,極大地提高了網絡的收斂速度。理論分析與仿真實驗表明:將3種神經網絡用于同步非等功率DS-CDMA信號偽碼盲估計時的復雜度均明顯降低,且LEAP NN與Sanger NN均可有效地實現-20 dB信噪比、10個用戶下的同步非等功率DS-CDMA偽碼盲估計,APEX NN則相對較差,此外,LEAP NN消耗內存較大、收斂速度快,APEX NN相反,Sanger NN則介于兩者之間。
盲估計; 碼分多址; 偽碼; 多主分量; 神經網絡
0 引 言
直接序列碼分多址(direct sequence code-division multiple access,DS-CDMA)信號是通過將多個攜帶有用信息的窄帶信息碼序列分別與多個高速偽碼序列相乘再求和而獲得的寬帶擴頻信號,因而其具有優良的抗干擾能力和低截獲特性。然而,DS-CDMA系統中不可避免地存在的遠近問題和多址干擾嚴重影響著這一技術的推廣應用。第三代移動通信系統利用多用戶檢測技術來有效的解決這一問題,提高了這一信號應用的廣泛性。目前,該信號已被廣泛的應用于通信、雷達、遙感和遙控等領域。因此,研究該信號偽碼序列的盲估計具有重要意義。
目前,針對DS-CDMA信號的偽碼序列的盲估計已提出多種方法,如基于批處理(SVD或EVD)的方法[1],基于盲源分離的方法[2]以及基于子空間[3]的方法,但是批處理方法不可避免的會涉及到相關矩陣的R預先計算,具有計算復雜度高、收斂速度慢及計算存儲量大等缺點,且當序列長度較長或工作于非平穩環境中時,該方法變得不再可行。而主分量神經網絡可以自適應地進行模式識別與特征提取[4-5],且不需要進行R的預先計算,不涉及批處理運算,具有開銷小、效率高、復雜度低等優點,因此得到了廣泛的應用。文獻[6]分別將主分量神經網絡及奇異值分解(singular value decomposition,SVD)方法用于音頻信號消噪,并對其性能進行了對比分析,但由于該文用到的神經網絡為單主分量神經網絡,因此并不適用于接收信號為DS-CDMA信號時的情況。然而,經典的Sanger神經網絡[7-8]、通過主分量實現自適應特征提取的在線無監督學習(on line unsupervised learing neural network for adaptive feature extraction via principle component,LEAP)神經網絡[9-11]以及自適應主分量提取(adaptive principle components extraction,APEX)神經網絡[12-13]均為多主分量神經網絡,且屬于無監督檢測,因此是一類很有潛力的非等功率同步DS-CDMA偽碼盲提取工具。
本文利用多主分量神經網絡復雜度低、效率高且可用于盲提取偽碼序列的優良特性,將其用于非等功率同步DS-CDMA偽碼序列的盲估計。另外,本文提出了一種在遞歸最小二乘[14-15](recursive least squares,RLS)意義下的最優收斂模型,極大地提高了網絡的收斂速度。此外,本文網絡僅需要已知偽碼周期就可實現盲估計,由于已有大量文獻可以求出同步DS-CDMA信號的偽碼周期,如文獻[16-17],所以本文假定偽碼周期已知。本文首先引入Sanger NN、LEAP NN以及APEX NN,其次對各神經網絡模型的收斂性及復雜度進行了詳細分析,最后根據各神經網絡能夠收斂的最多用戶數、最低信噪比以及相應的收斂速度進行了詳細的仿真實驗。理論分析與仿真實驗表明,3種方法均可有效地實現較低信噪比與較多用戶數條件下的非等功率同步DS-CDMA偽碼序列盲估計,并且具有較好的收斂性能。
1 DS-CDMA模型
DS-CDMA信號可以簡單的看作將K個性質類似的單用戶DS-SS信號線性疊加而成的,一個有K個用戶的基帶數字DS-CDMA系統的接收信號可以表示為
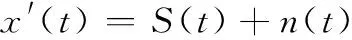
(1)
(2)
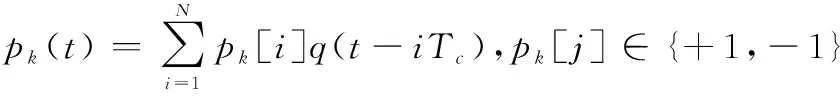
當τ1=τ2=…=τK=Tx時,式(2)代表了K個用戶的同步DS-CDMA信號;而當τ1≠τ2≠…≠τK時,式(2)代表了K個用戶的異步DS-CDMA信號。
本文只考慮非等功率的同步基帶DS-CDMA信號。而且,不失一般性,取M=0,Tx=0,即每個用戶每幀只有一個數據符號位。所以,本文所用到的接收信號模型可表示為
(3)
2 多主分量 NN方法
2.1Sanger NN、LEAP NN與APEX NN
根據Hebbian與Oja學習規則,Sanger提出了一種多主分量分析神經網絡模型,如圖1所示。

圖1 Sanger 神經網絡Fig.1 Sanger neural network

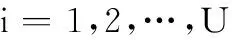
(4)
則由圖1可得,輸出為
(5)
式中,x(k)=[x1(k),x2(k),…,xN(k)]T;y(k)=[y1(k),y2(k),…,yU(k)]T,且權值更新公式為
(6)
(7)
Chen H和Liu R W在Sanger NN的基礎上提出了LEAP NN。其更新公式為下式給定的非線性、非自治動態差分方程:
(8)
式中
(9)
式中,I表示一個N×N的單位矩陣。在每次迭代時,Ai和Bi是所有連接權值中用于實現施密特正交化的去相關條件。當k→∞時,LEAP NN也可以提取任意大小的一組主分量。
根據反Hebbian規則(anti Hebbian rule)與Oja規則,Kung S Y提出了APEX NN。其特點是若給出前i-1個主分量,可用遞推方式計算第i個主分量。APEX NN如圖2所示,與Sanger NN的不同之處在于其在前向連接的基礎上增加了用于使輸出信號正交化去相關的側向連接。
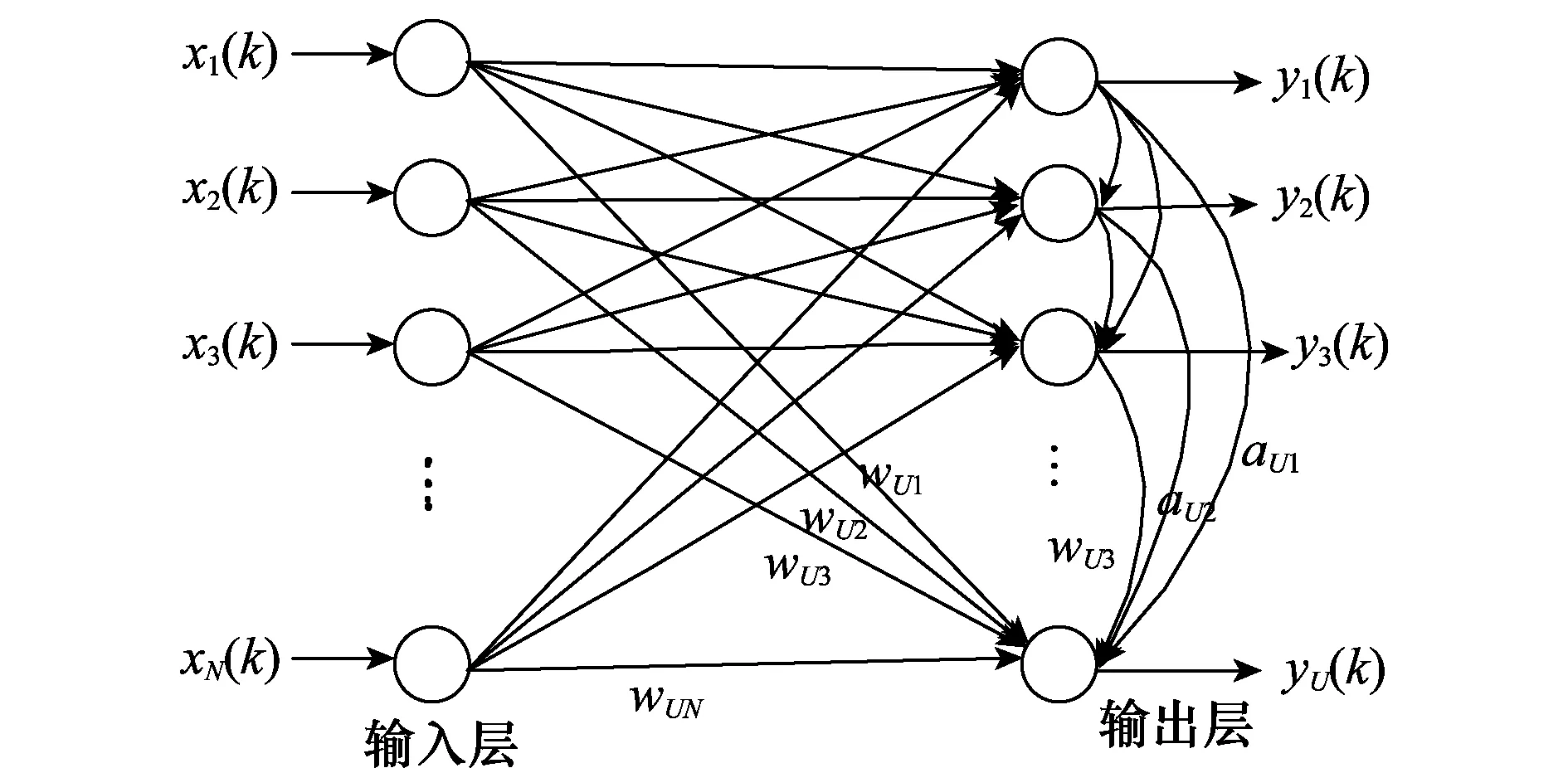
圖2 APEX 神經網絡Fig.2 APEX neural network
圖2中各神經元均為線性神經元,其含有兩種連接:前向連接、側向連接。前向連接與Sanger NN中的wij(k)等效,它是按照一個Hebbian學習規則來工作的;側向鏈接是指從輸出神經元1,2,…,i-1,i=1,2,…,U到輸出神經元i的連接,它將反饋應用到網絡。這些連接被表示為反向權向量,即
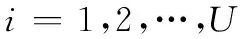
(10)
側向連接是按照一個反Hebbian學習規則來工作。由圖2可知APEX NN的輸入輸出關系為
(11)
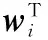
(12)
假設輸入向量x(k)是來自于一個平穩過程,其自相關矩陣R具有互相區別的按降序排列的特征值,即
(13)
進一步假設圖2中輸出神經元1,2,…,i-1已經收斂到它們各自的穩定點,表示為
(14)
(15)
式中,ej是相關矩陣R的第j個特征值對應的特征向量,并且時刻k=0表示了網絡的神經元i計算的起點,故此時式可以寫為
(16)
式中,Q是一個(i-1)×N的矩陣,由相關矩陣R的前i-1最大特征值λ1,λ2,…,λi-1對應的特征向量e1,e2,…,ei-1構成,即
(17)
神經元i的前向權向量wi(k)和反向權向量ai(k)的更新等式分別定義為
(18)
(19)
2.2Sanger NN、LEAP NN與APEX NN在RLS下的最優變步長學習速率
由于Sanger NN、LEAP NN與APEX NN的權值更新公式中均含有x(k)-yi(k)wi(k)項(特別地,對于APEX NN中的側向連接,令ai(k)與wi(k)取相反的符號,則可得側向權值增量中含有yi-1(k)-yi(k)ai(k)項,這將與x(k)-yi(k)wi(k)具有相同的形式),因此可令x(k)或yi-1(k)作為RLS算法中輸入信號的期望信號,yi(k)作為RLS算法中的輸出信號,wi(k)與ai(k)作為RLS算法的連接權值,以此來構建的RLS算法代價函數為
(20)
或
(21)
式中,0<γ≤1為遺忘因子,其作用是確保在過去某一段時間內的值被遺忘,從而使系統工作于平穩狀態。
由代價函數推導得相應RLS算法的更新公式為
(22)
或
(23)
式中
(24)
由此,可得出3種多主分量神經網絡在RLS意義下的最優變步長學習速率為
(25)
或
(26)
進一步可等效為
(27)
由文獻[14]可知,d(0)是一個很小的正數,且由式(27)可知,初始值d(0)與γ值越小,變步長β(k)將越大,收斂速度越快。但是當d(0)與γ取值過小(尤其是γ過小)時,會導致收斂性不穩定,從而導致收斂速度變慢甚至不能收斂。
2.3Sanger NN、LEAP NN與APEX NN用于同步DS-CDMA信號偽碼序列盲估計
當接收信號為式(3)給定的非等功率同步DS-CDMA信號時,假設Tx=0(已有文獻可以求出Tx),將接收信號在不重疊的周期窗內采樣,不失一般性,這里假設采樣周期等于一個碼片寬度,即采樣周期為Ts=T0/N=Tc。則系統進行N次采樣得到的一周期接收信號為
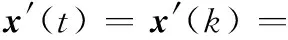
(28)
式中,{xi(t)=x[t-(i-1)Tc],i=1,2,…,N}是以采樣周期Ts=Tc進行采樣,即每切普一個采樣點。在x′(t)輸入神經網絡之前,將其歸一化為
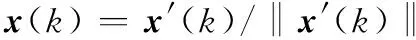
(29)
式中
(30)
這樣,主特征向量就會以一個較為魯棒的形式估計出來。輸出神經元的數量U等于所需主分量的個數(在本文中等于DS-CDMA信號用戶的個數),通常取U≤N。在許多“降維”的實際應用中U?N。通過網絡權值的反復更新,最終權值將收斂于DS-CDMA信號的偽碼序列。另外,為了使該神經網絡取得更好的收斂性能,本文采用式(27)所給定的變步長。
3 收斂性分析
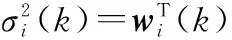
3.1數學等價模型
現以APEX NN為例(其他兩種網絡的數學等價模型推導與其相似)。為了獲得一個實際中易于處理的數學模型,利用Ljung L提出的隨機估計算法收斂性分析工具,本文可以應用兩種近似:存在足夠大的正整數M,充分小的正常量β,使得:
(31)
(32)
(33)
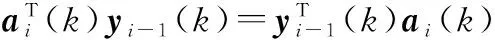
(34)
和
(35)
進一步,可以用{k,k+1,k+2,…}來代替{k,k+M,k+2M,…},式(34)與式(35)就可以簡化為下式:
(36)
(37)
式中,γ=Mβ,此時的wi(k)、ai(k)是M個時刻的瞬時權值的平均值。這是非常關鍵的一步,因為通過上述等價,前面的非線性、非自治動態差分方程就可以近似為非線性、自治確定性差分方程。一般來說,兩個系統的漸進軌跡是等價的,即其中一個系統收斂就意味著另一個系統也收斂。
同理,可推導得Sanger NN非自治動態系統的自治確定性系統數學等價模型為
(38)
LEAP NN非自治動態系統的自治確定性系統數學等價模型為
(39)
3.2i=1時的收斂性分析
對于Sanger NN,當i=1時,有
(40)
這里,將連接權值向量w1(k)按照相關矩陣的正交歸一化特征向量集展開如下:
(41)
式中,ej是矩陣R的特征值λj對應的特征向量;θ1j(k)是展開時的時變系數,則有
(42)
(43)
利用定理1可得
(44)
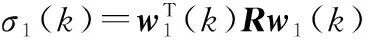
定理1(證明見文獻[9])已知
(45)
則有
(46)
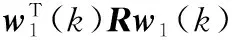
3.3i≠1時的收斂性分析
當i≠1時,利用歸納法,首先假設輸出神經元1,2,…,I-1,I>1已經收斂到它們的穩定狀態,然后證明在假設條件下第I個神經元也能收斂。接下來分別證明3種多主分量神經網絡在i≠1時的收斂特性。
3.3.1Sanger NN的收斂性分析
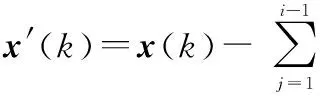
3.3.2LEAP NN的收斂性分析
現取i=I,則有
(47)
令εl(k)=wl(k)-el∈RN,l=1,2,…,I-1,則由假設可得存在常量c>0,0 (48) 則有 (49) 其中 (50) (51) 顯然所有ΦI(k)∈RN×N的絕對值有一致的上界3(I-1)cdk,其值當k→∞時,以指數形式收斂于0。現設ΨIi(k)是ΦI(k)ei到向量ei上的映射,則當k→∞時,其值也以指數形式收斂于0。因此,式可以簡化為 (1)當1≤j≤I-1時 (52) (2)當I≤j≤N時 (53) 利用定理2可得: (54) 定理2(證明見文獻[9])已知: (55) 則有 (56) 3.3.3APEX NN的收斂性分析 現取i=I,且令其前向連接權值向量按式展開,接著用基本關系式: Rej=λjej (57) 來表達矩陣積RwI(k)如下: (58) 類似地,用式(17),可以將矩陣積RQTaI(k)表達為 (59) 式中,A=[aI1(k),aI2(k),…,aII-1(k)]。因此,將式(59)代入式(36),并簡化,得 (60) 同理,反向權向量aI(k)的更新等式(37)可以被轉化為 (61) 式中,1j是除了第j個元素等于1,其他所有I-2個元素都為零的向量;下標j被限制在1≤j≤I-1。 有兩種情況需要被考慮(依賴于下標j以及I-1的分配值)。下文情形1表示的1≤j≤I-1,其涉及該神經網絡“老”主模式的分析;情形2表示的I≤j≤N,其涉及該神經網絡“新”主模式的分析。 情形 1當1≤j≤I-1時,在這種模式下,由式(60)和式(61)可得: (62) (63) 用矩陣形式,可以將式(62)和式(63)變換為 (64) 式中 則式(64)描述的系統矩陣的特征值如下: (65) 從式(65)中,能夠得出兩個重要的結論: (1)在式(65)中矩陣系統的特征值ρIj是獨立于相關矩陣R的所有特征值λj。 給定ρIj<1時,式(48)的展開式系數θIj(k)和反向權向量aIj(k)將對所有的k以相同的速度漸進的趨于零,因為網絡所有的主模式都具有相同的特征值。這個結果是相關矩陣特征向量的正交歸一化性質的一種延續。換句話說,wI(k)按照相關矩陣R的整個歸一化特征向量集的展開式是式所描述結果的基礎,特征值λj的選擇是不變的。 情形 2當I≤j≤N時,在這種情況中,反向權向量aIj(k)對網絡節點沒有影響,表示如下: (66) 因此,對每一個主模式I≤j≤N,有一個簡單的等式如下: (67) 其直接從式(60)和式(66)推導得到。根據情形1,對1≤j≤I-1,θIj(k)和aIj(k)將最終收斂到零。且神經元輸出的平均輸出功率為 (68) 這里設θII(k)≠0,且定義 (69) 可以接著將式(69)寫為 (70) 由自相關矩陣的特征值λI>λj,I (71) 因此 (72) 故 (73) 此時,式(68)可以簡化為 (74) 并且由式(67)可得 (75) 推導得 (76) 這個極限條件就暗示了以下雙重含義 (1)從式(48),有 (77) (2)從式(74),有 (78) 換言之,當k迭代次數趨于無窮大時,圖2所示的神經網絡將提取出輸入向量x(k)相關矩陣R的第I個特征值及對應的特征向量。這當然是首先假設了神經網絡的神經元1,2,…,I-1已經收斂到了相關矩陣R的特征值及其對應的特征向量,這就證明了APEX NN在i≠1時收斂性。至此,Sanger NN、LEAP NN與APEX NN的收斂性就證明完畢。 此外,這里對3種多主分量神經網絡分析時按照“串行模式”處理,即,第i個神經元是在前i-1個神經元已經收斂后才開始工作。這樣做的目的僅是為了以一種簡單的方式來解釋網絡的工作原理。然而,實際上,各網絡結構均是按照“并行模式”工作的,即各網絡中的神經元均是趨向于同時收斂。 算法的時間復雜度一般是指算法實現過程中用到的乘法次數與加法次數。本文取用戶數為U,偽碼序列長度為N(本文中等于輸入神經元個數),各算法達到收斂時所需的信息碼元數(本文中等于算法收斂所需要的數據組數)分別為M1,M2,M3,M4,且一般來說M1,M2,M3,M4各不相等,則各算法的單次蒙特卡羅實現所需的復雜度如表1所示。 表1 復雜度分析 由表1可知,若不考慮M1,M2,M3,M4對各算法復雜度的影響,當U=1時,Sanger NN、LEAP NN與APEX NN的計算復雜度相同,這是因為此時3種神經網絡結構相同;當U≠1時,LEAP NN復雜度最大(因為其結構中包含矩陣運算),Sanger NN次之,APEX NN最小。對于批處理方法來說,其復雜度與用戶數無關,且一般有U?N,因此其復雜度遠大于多主分量神經網絡的方法。 實驗說明:以下實驗主要針對非等功率同步DS-CDMA信號。 (1)非等功率同步DS-CDMA信號各用戶的PN序列是長度為100 (或200)位的截斷m序列,序列的幅度為±1。 (2)每個用戶每次均勻隨機地產生幅度為±1的一位信息碼,然后用它們分別去調制對應用戶的PN碼。 (4)實驗中用到的信噪比為 (79) (80) (81) 式中,Var{·} 表示求方差操作;SNRk表示第k個用戶的信噪比;SNRavr 、SNRsum分別為所有用戶的平均信噪比和總的信噪比。 (5)本文各實驗均取蒙特卡羅次數為Mncr=200,上采樣次數為Sa=1,算法達到收斂時允許存在1%的誤碼率。 (6)本文實驗2到實驗5是在式(27)所示的變步長環境下進行,其中d(0)的初始值取10.0,參數γ取恒定值0.995。 實驗 1確定各算法變步長的最優初值以及初步比較3種算法達到收斂時所需的平均數據組數與平均實際時間。 這里取PN碼長為100,用戶數為7,噪聲標準差σV=5。圖 3和圖4是取γ=0.99,d(0)=[eps,1,2,5,8,10,12]時所得實驗結果圖。而圖5和圖6是取d(0)=1.0,γ=[0.98 0.9850.990.9950.998]時得到的實驗結果圖。 圖3 初值對收斂數據組數的影響Fig.3 Influence of the initial value on the number of convergence data sets 圖4 初值對收斂時間的影響Fig.4 Influence of the initial value on convergence time 由圖3和圖4可知,當取d(0)=0時,LEAP NN達到收斂時所需數據組數幾乎為零,事實上,這是由于此時收斂已不穩定,誤碼率收斂到NaN所致,且對于APEX NN,此時的收斂性能也較差。當d(0)≠0時,隨著初值的增大,收斂性略微變差,但效果不明顯,可見當初值d(0)在一定范圍內時,收斂速度對d(0)并不敏感。此外,就神經網絡達到收斂時所需的平均數據組數而言,LEAP NN性能最好,Sanger NN性能次之,APEX NN性能最差;就神經網絡達到收斂時所需的實際平均時間而言,Sanger NN性能最好,APEX NN性能次之,LEAP NN性能最差(這是由于LEAP NN引入了矩陣結構使得運算量增大)。 圖5 遺忘因子對收斂數據組數的影響Fig.5 Influence of the forgetting factor on the number of convergence data sets 圖6 遺忘因子對收斂時間的影響Fig.6 Influence of the forgetting factor on convergence time 由圖5和圖6可知,當取γ<0.98時,3種神經網絡已經不能收斂(或收斂性能很差),故文中不予考慮。當取γ≥0.98,神經網絡達到收斂時所需的平均數據組數與平均實際時間隨γ的變化曲線大致呈“凹”形,這與前面的理論描述相一致。 為了方便對比分析,本文以下各實驗統一取d(0)=10.0,γ=0.995。 實驗 2比較APEX NN、LEAP NN以及Sanger NN在低信噪比條件下的收斂性能(這里僅考慮平均數據組數,下同)。 本實驗中取PN碼長度為100位,用戶數為7。則3種神經網絡在不同信噪比下收斂性能如表2所示。其中表2中σV代表噪聲的標準差,a=SNRavr,b=SNR7分別代表相應噪聲條件下的平均信噪比與第7個用戶(該用戶的功率最小)的信噪比。 由表2可知,當σV≥9時,由于信噪比太低而導致算法收斂所需數據組數太大或不能收斂。且隨著信噪比的降低,各算法達到收斂所需的平均數據組數都在逐漸增加。此外,在相同的信噪比條件下,LEAP NN的收斂性能最好,Sanger NN次之,APEX NN最差。 表2 在不同信噪比下的平均數據組數 實驗 3比較APEX NN、LEAP NN以及Sanger NN在多用戶情況下的性能。 這里取PN碼長度為100位,σV=0.5,其中用戶數分別取U=7,8,9,10,11,且其相應的幅度值分別為 則3種神經網絡在用戶數分別取7,8,…,11時的收斂性能如表3所示,表3中U代表用戶數,a=SNRavr,bk=SNRk,k=7,8,…,11分別代表相應用戶數條件下的平均信噪比與第k個用戶的信噪比。 表3 在不同用戶數下的平均數據組數 由表3可知:當U≥11時,由于信噪比太低而導致算法收斂所需數據組數太大或不能收斂。且隨著用戶數的增加,各算法達到收斂所需的平均數據組數在逐漸增加。此外,在相同的用戶數條件下,LEAP NN的收斂性能最好,Sanger NN次之,APEX NN最差。此外,如果σV值減小,相應的信噪比會增大,用戶達到收斂所需要的平均數據組數會進一步減小,可以收斂的用戶數也會增多。 實驗 4分析APEX NN、LEAP NN以及Sanger NN在不同偽碼長度時的性能。 本實驗中取用戶數為7,則3種神經網絡在偽碼長度取100、200位時的均值收斂性能如圖7所示。 由圖7可知,當PN序列長度為200時,各算法達到收斂所需平均數據組數明顯小于PN序列長度為100時,即PN序列越長,收斂性能越好。此外,隨著信噪比的降低,各算法達到收斂所需的平均數據組數都在逐漸增加。而且,在相同信噪比條件下,LEAP NN的收斂性能最好,Sanger NN收斂性能次之,APEX NN的收斂性能最差。 圖7 不同偽碼長度下的均值性能曲線Fig.7 Average performance curve under different PN length 實驗 5分析APEX NN、LEAP NN以及Sanger NN各個用戶的平均比特誤碼率與平均數據組數。 這里取用戶數為7,PN碼長度為C=100,則3種神經網絡提取信號前3個用戶時的學習收斂曲線如圖8所示,均值性能曲線如圖9所示。 圖8 學習收斂曲線Fig.8 Learning convergence curve 圖9 均值性能曲線Fig.9 Mean performance curve 由圖8可知,各算法的平均誤碼率都隨著輸入信號數據組數的增加而減小,且在相同的條件下,第一個用戶的偽碼序列在剛開始估計時收斂速度明顯快于其他用戶,這是由于第一個用戶的信號強度最大的緣故。 由圖9可知,在相同條件下第一個用戶的偽碼序列估計所需數據組數明顯小于其他用戶,這同樣是由于第一個用戶的幅度值最大的緣故。 其中曲線不夠平滑是因為蒙特卡羅次數較少的緣故,且相互交叉的曲線并不存在直接比較。 本文通過3種多主分量神經網絡權值向量的符號函數來重建非等功率同步DS-CDMA信號各用戶的偽碼序列,從而實現該信號偽碼序列的盲估計。本文提供了一種在RLS意義下的最優變步長收斂模型,極大地提高了算法的收斂速度。通過理論分析與仿真實驗得出,相比于批處理方法,3種多主分量神經網絡在實現非等功率同步DS-CDMA信號偽碼盲估計時的復雜度均明顯降低,且APEX NN的復雜度最低,Sanger NN次之,LEAP NN最高。在允許1%的誤碼率條件下,當用戶數為7時,3種多主分量神經網絡都可以有效地實現在最小用戶信噪比為-27.9 dB下的非等功率同步DS-CDMA偽碼序列的盲估計;當噪聲標準差為σv=0.5時,Sanger NN與LEAP NN可以有效地實現10個用戶的非等功率同步DS-CDMA偽碼序列的盲估計,APEX NN則性能較差;此外,就算法達到收斂時所需的平均數據組數而言,LEAP NN性能最好,Sanger NN性能次之,APEX NN性能最差;就算法達到收斂時所需的實際平均時間而言,Sanger NN性能最好,APEX NN性能次之,LEAP NN性能最差。另外,由于本文神經網絡能夠自適應地處理輸入數據且不需要存儲權值更新的中間變量,因此可以工作于輸入數據無限長以及非平穩的環境中。 [1] Luo Z,Zhu L.A charrelation matrix-based blind adaptive detector for DS-CDMA systems[J].Sensors,2015,15(8):20152-20168. [2] Wu W J,Zhang T Q,Shi S,et al.Parallel blind estimate of spreading sequences in multi-rate DS/CDMA signals[J].Information and Control,2015,44(2):171-178.(吳旺軍,張天騏,石穗,等.多速率DS/CDMA信號擴頻序列并行盲估計方法[J].信息與控制,2015,44(2):171-178.) [3] Zhou L,Leung H,Xu P,et al.The Kalman filtering blind adaptive multi-user detector based on tracking algorithm of signal subspace[J].Information,2015,6(1):3-13. [4] Bouzid A,Ellouze N.Speech enhancement based on wavelet packet of an improved principal component analysis[J].Computer Speech and Language,2016,35:58-72. [5] Bai D,Liming W,Chan W,et al.Sparse principal component analysis for feature selection of multiple physiological signals from flight task[C]//Proc.of the IEEE International Conference on Control Automation and Systems,2015:627-631. [6] Nie Z G,Zhao X Z.Similarity of signal processing effect between PCA and SVD and its mechanism analysis[J].Journal of Vibration and Shock,2016,35(2):12-17.(聶振國,趙學智.PCA與SVD信號處理效果相似性與機理分析[J].振動與沖擊,2016,35(2):12-17.) [7] Sanger T D.Optimal unsupervised learning in a single-layer linear feedforward neural network[J].Neural Networks,1989,2(6):459-473. [8] Zhang T Q.Blind processing for signal of direct sequence spread spectrum[M].Beijing:National Defence Industy Press,2012:195-196.(張天騏.直擴信號的盲處理[M].北京:國防工業出版社,2012:195-196.) [9] Chen H,Lin R W.An on-line unsupervised learning machine for adaptive feature extraction[J].IEEE Trans.on Circuits and Systems-II:Analog and Digital Signal Processing,1994,41(2):87-98. [10] Zhang T Q,Chen Q B,Zhou Z Z,et al.Adaptive feature extraction of lower SNR DS-CDMA signals[C]//Proc.of the IEEE International Conference on Signal Processing,2006. [11] Zhang T Q,Dai S S,Li X S,et al.A neural network method to adaptive feature extraction of weak DS-CDMA signals[C]//Proc.of the IEEE Congress on Image and Signal Processing,2008:385-389. [12] Kung S Y,Diamantaras K I,Taur J S.Adaptive principal component extraction (APEX)and applications[J].IEEE Trans.on Signal Processing,1994,42(5):1202-1217. [13] Zhang T Q,Tian Z S,Chen Q B,et al.Use APEX neural networks to extract the PN sequence in lower SNR DS-SS signals[J].Lecture Notes in Computer Science,2006,4114:1252-1257. [14] Hong X,Gong Y.A constrained recursive least squares algorithm for adaptive combination of multiple models[C]//Proc.of the IEEE International Joint Conference on Neural Networks,2015:1-6. [15] Hunki K,Shaheen E M,Soliman M,et al.Blind adaptive LMS multiuser detector with variable step size[C]//Proc.of the IEEE International Conference on Engineering and Technology,2014:1-5. [16] Zhang T Q,Zhou Z Z,Kuang Y J,et al.New method for periodic estimation of the PN sequence in the lower SNR long code DS-SS signals[J].Systems Engineering and Electronics,2007,29(1):12-16.(張天騏,周正中,鄺育軍,等.低信噪比長偽碼直擴信號偽碼周期的估計方法[J].系統工程與電子技術,2007,29(1):12-16.) [17] Wu W J,Zhang T Q,Yang R,et al.Blind periodic estimate of PN sequence based on reprocessing of power in multirate DS/CDMA transmissions[J].Telecommunication Engineering,2014,54 (7):937-944.(吳旺軍,張天騏,陽銳,等.利用二次譜盲估計多速率DS/CDMA偽碼周期[J].電訊技術,2014,54(7):937-944.) PN code sequence blind estimate of synchronous DS-CDMA based on multi-principal component neural network ZHANG Tian-qi,ZHAO Jun-tao,JIANG Xiao-lei (Chongqing Key Laboratory of Signal and Information Processing,Chongqing University of Posts and Telecommunications,Chongqing 400065,China) Aiming at the problem of the batch processing method with high complexity and slow convergence speed for the pseudo-noise (PN)code sequence blind estimate of synchronous direct sequence code-division multiple access (DS-CDMA)signals under different power level,three multi-principal component neural networks (NNs)are introduced—Sanger NN,LEAP NN and APEX NN.Firstly,the period segmented DS-CDMA signals are chosen as the neural network input and the symbol function of each weight vector is used to represent the PN code sequence of each user.Then through the continuous input signal,the weight vectors of the NN are trained repeatedly until convergence.Finally,the PN code sequence of each user can be rebuilt by the symbolic function of each weight vector.Furthermore,an optimal variable step convergence model is put forward via the recursive least square (RLS),which improves the convergence speed of the network greatly.Theory analysis and simulation results show that the complexity of three kinds of NNs when used to the PN code sequence blind estimate of synchronous DS-CDMA signals under different power level is reduced significantly,and when the signal to noise ratio (SNR)is -20 dB and the number of users is 10,the PN code sequence of synchronous DS-CDMA signals under different power level can still be estimated by LEAP NN and Sanger NN efficiently.Compared with LEAP NN and Sanger NN,APEX NN is poor relatively.In addition,LEAP NN consumes lager memory but it has fast convergence speed.APEX NN is contrary to LEAP NN; Sanger NN is between the LEAP NN and the APEX NN. blind estimate; code division multiple access (CDMA); pseudo-noise (PN)code; multi-principal component; neural networks (NNs) 2016-01-25; 2016-07-05;網絡優先出版日期:2016-08-16。 國家自然科學基金(61671095,61371164,61275099);信號與信息處理重慶市市級重點實驗室建設項目(CSTC2009CA2003);重慶市教育委員會科研項目(KJ130524,KJ1600427,KJ1600429)資助課題 TN 911.7 ADOI:10.3969/j.issn.1001-506X.2016.11.27 張天騏(1971-),男,教授,博士研究生導師,博士,主要研究方向為擴頻信號的盲處理、神經網絡實現以及信號的同步處理。 E-mail:zhangtq@cqupt.edu.cn 趙軍桃(1991-),男,碩士研究生,主要研究方向為基于神經網絡的直擴信號盲處理。 E-mail:1012928803@qq.com 江曉磊(1992-),女,碩士研究生,主要研究方向為導航信號的捕獲與跟蹤。 E-mail:173993170@qq.com 網絡優先出版地址:http://www.cnki.net/kcms/detail/11.2422.TN.20160816.1504.002.html
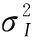
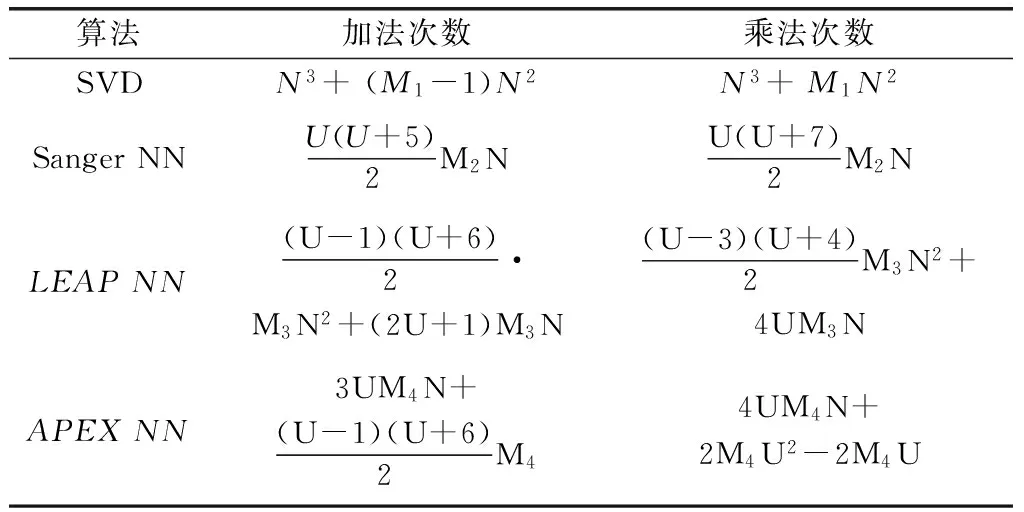
4 復雜度分析
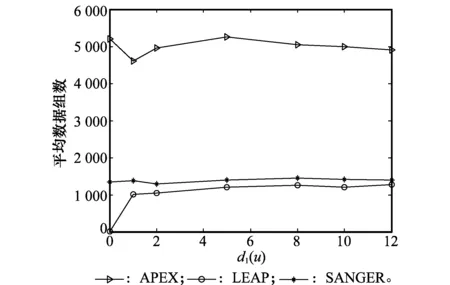
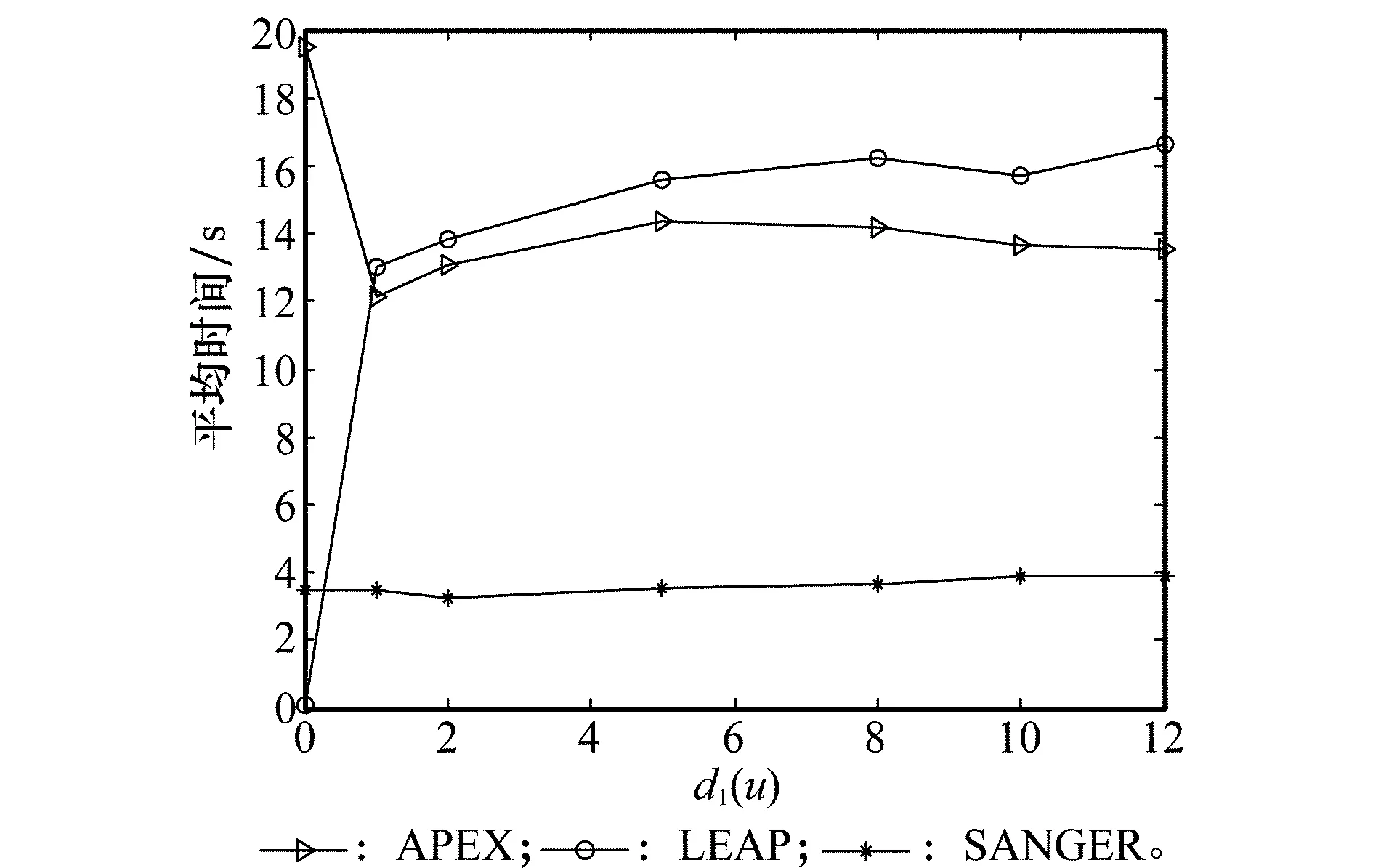
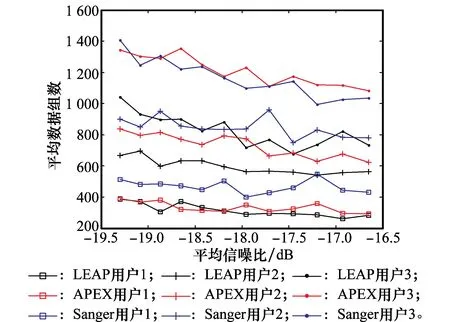
5 仿真實驗
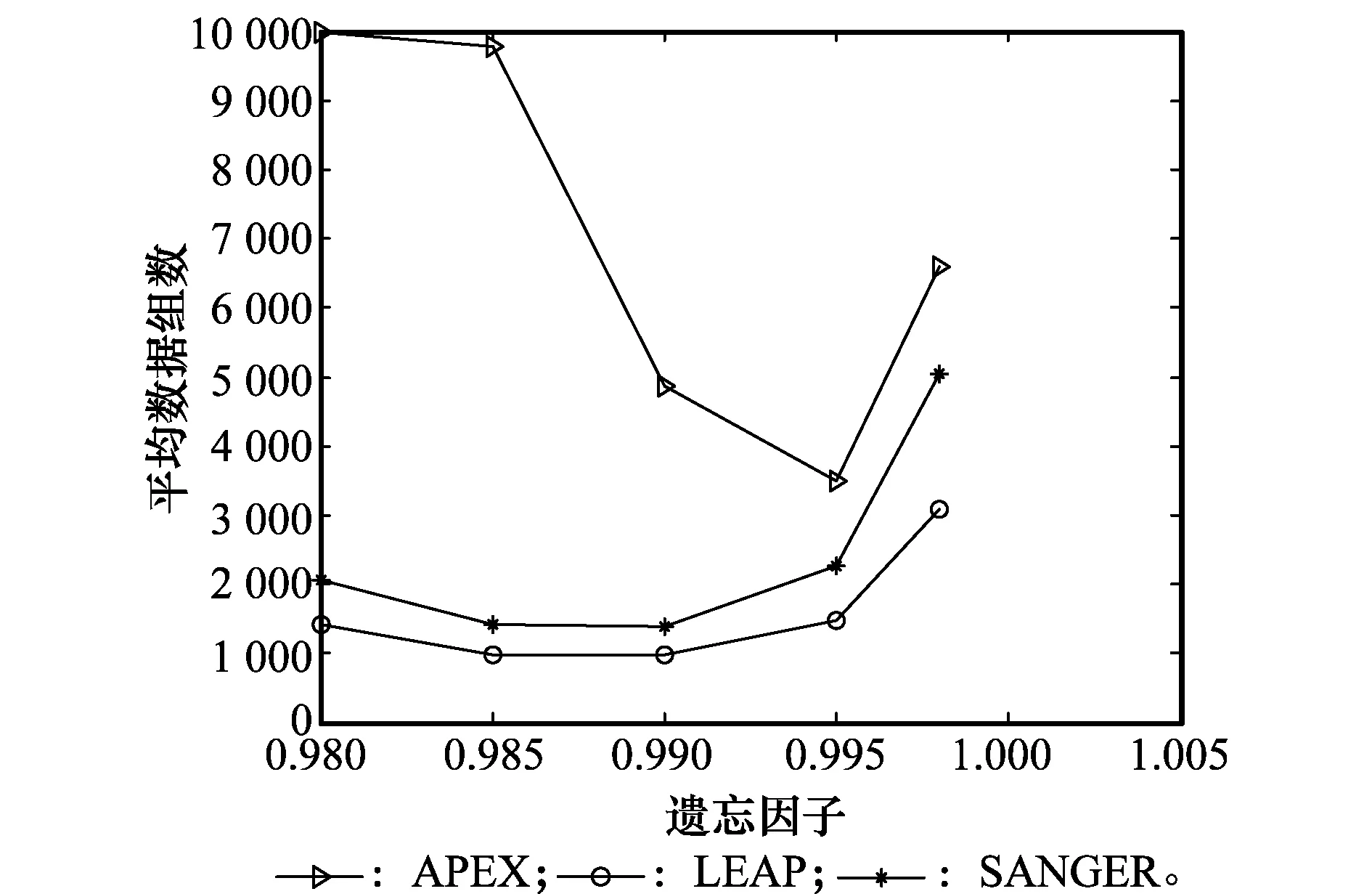
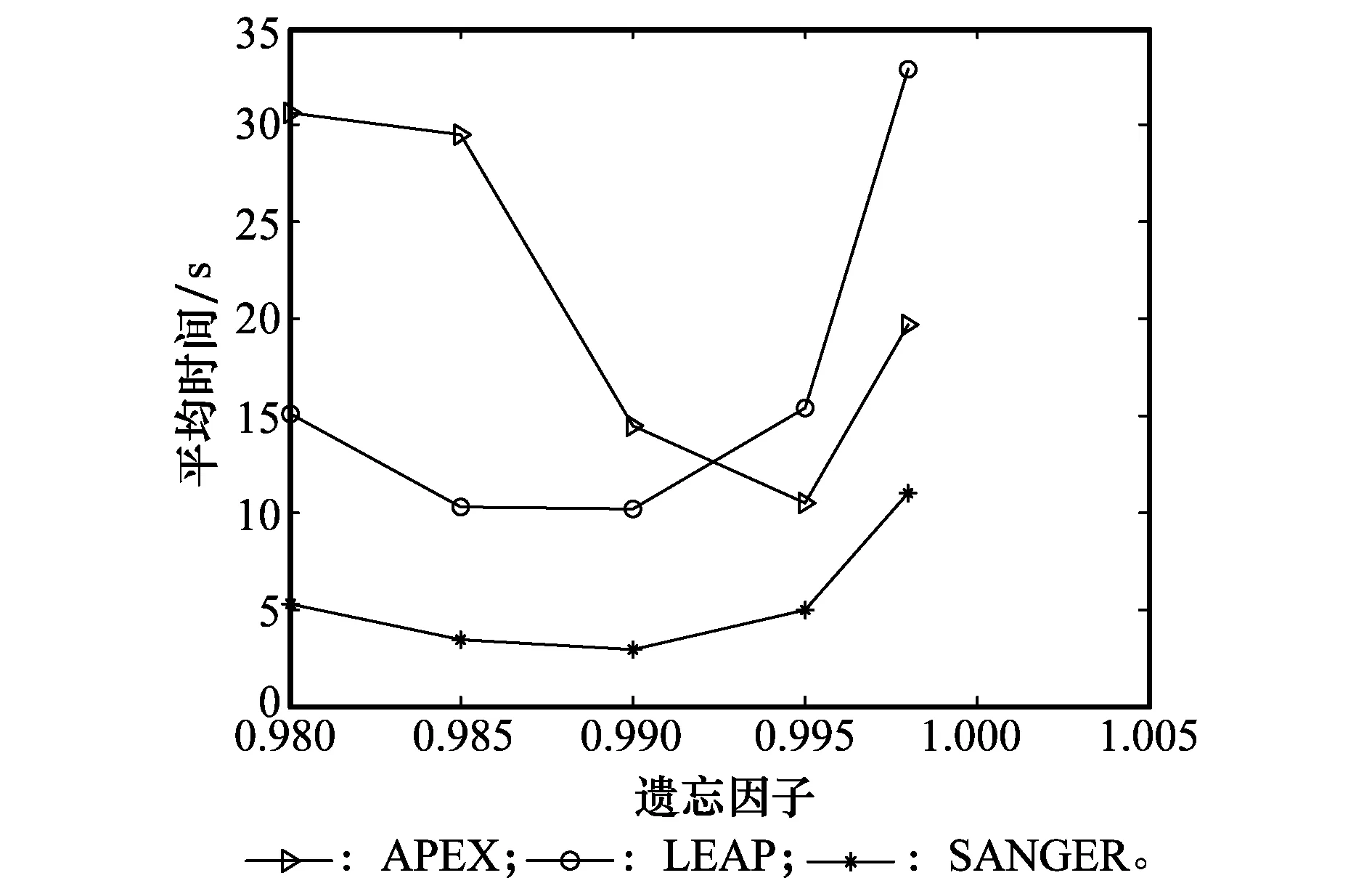


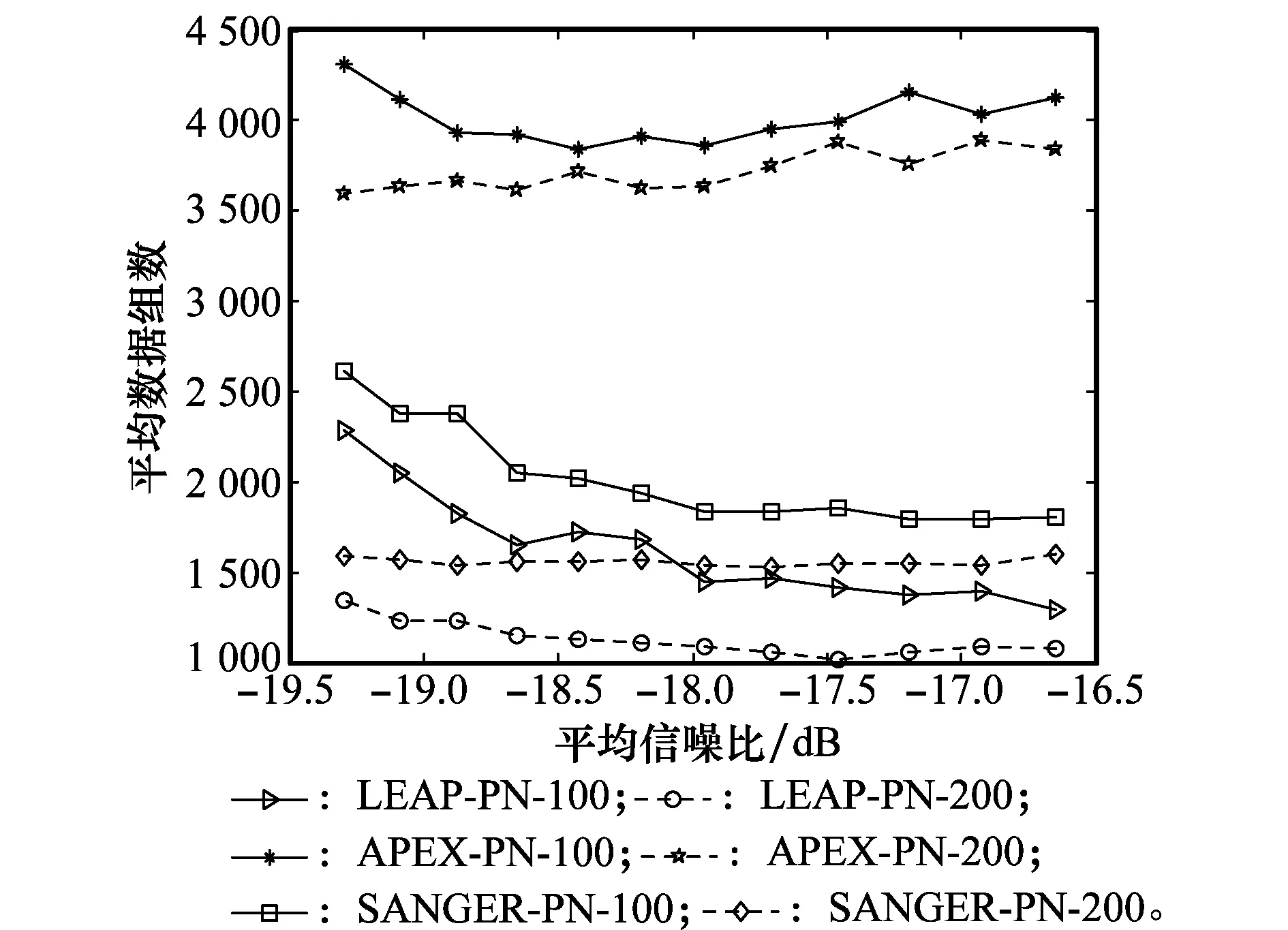
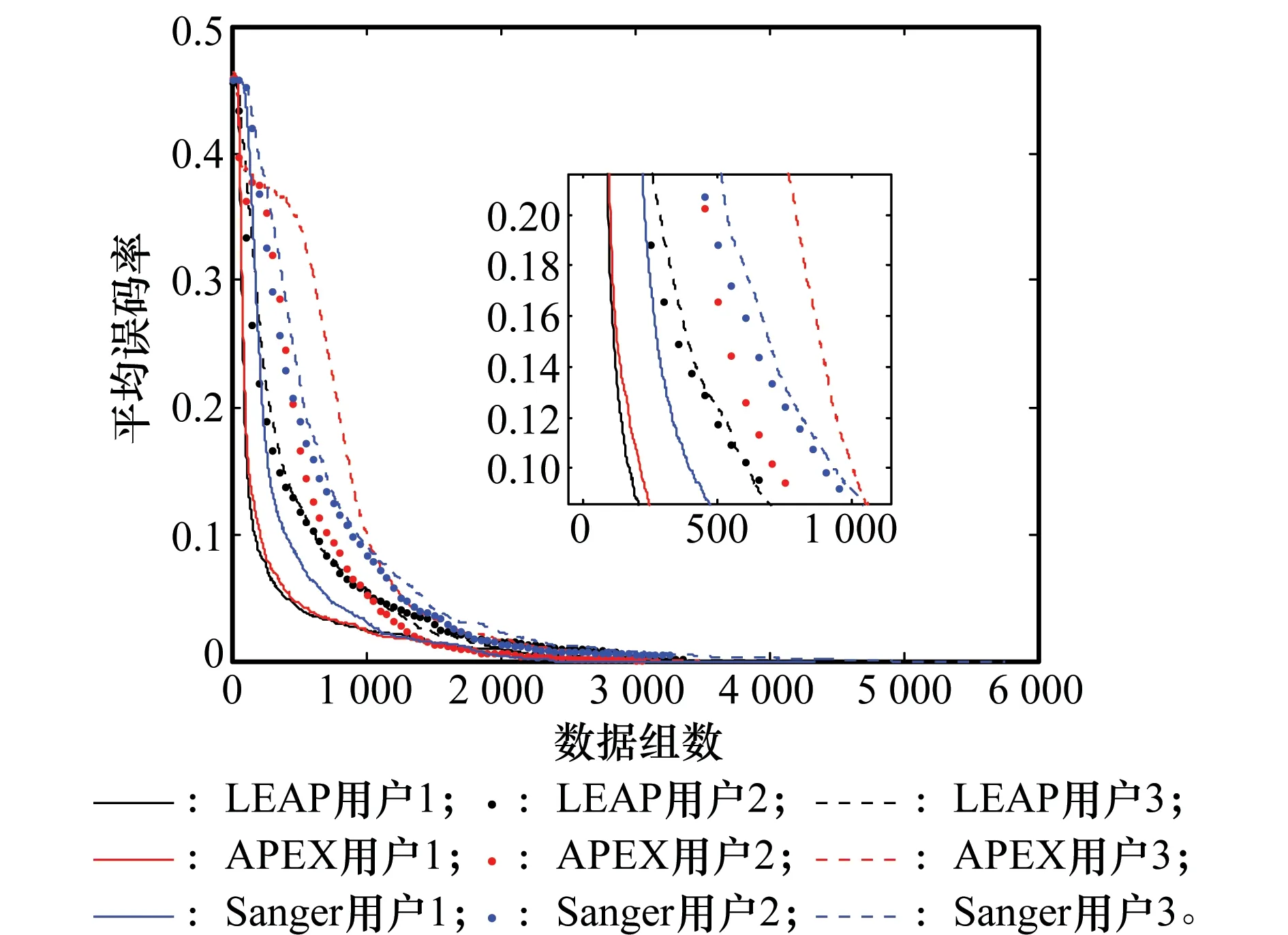
6 結 論
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18考試與評價·高一版(2020年6期)2020-11-02 02:45:24媽媽寶寶(2019年10期)2019-10-26 02:45:34中國生殖健康(2019年3期)2019-02-01 06:12:26鐵道通信信號(2018年11期)2019-01-19 01:15:08電子制作(2018年11期)2018-08-04 03:25:42鐵道通信信號(2018年2期)2018-04-18 12:18:10鐵道通信信號(2016年11期)2016-06-01 12:11:32鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25中國病理生理雜志(2015年8期)2015-12-21 12:38:06
