基于預分類和特征擴展的JPEG圖像隱寫分析
2016-11-11 08:25:30郭繼昌劉曉娟田煜衡
系統工程與電子技術 2016年11期
郭繼昌,劉曉娟,田煜衡
(天津大學電子信息工程學院,天津 300072)
?
基于預分類和特征擴展的JPEG圖像隱寫分析
郭繼昌,劉曉娟,田煜衡
(天津大學電子信息工程學院,天津 300072)
聯合圖像專家組(joint photographic experts group,JPEG)圖像的隱寫分析性能不僅與信息嵌入方式有關,同時與其自身的內容復雜度也緊密相關。本文提出一種基于預分類和特征擴展的新方法以提高JPEG圖像通用隱寫分析準確性。首先采用圖像內容復雜度度量準則將訓練樣本劃分為若干互相重疊的類別,并對每一類子庫分別提取更加有效的擴展特征集以及構造各自的分類器模型;對于給定的待測圖像,根據其內容復雜度與各類復雜度均值的最小距離進行預分類,提取特征并進行相應類別的分類器測試。實驗結果表明,該方法對典型的JPEG圖像隱寫算法具有更好的檢測性能。
隱寫分析; 圖像內容復雜度; 預分類; 特征擴展
0 引 言
隱寫分析的目的在于檢測多媒體數據中隱藏信息的存在性[1]。聯合圖像專家組(joint photographic experts group,JPEG)圖像由于壓縮比高、質量好且獲取方便,成為隱寫術的主要載體之一,相應的隱寫分析也成為研究熱點。
作為隱寫分析技術的主流,通用隱寫分析主要采用“特征提取-分類器訓練-決策”的模式,通過構建敏感特征提高檢測準確率[2]。針對JPEG圖像,文獻[3]利用移位剪切重壓縮的校準方法提取離散余弦變換(discrete cosine transform,DCT)系數特征,對部分隱寫術取得了較好的檢測效果。文獻[4]提出基于Markov模型的塊內和塊間轉移概率矩陣,文獻[5]融合了DCT系數特征和Markov特征,均能實現對多種隱寫算法的有效檢測。隨后,文獻[6]通過分析轉移概率的缺陷,構建了相鄰系數的聯合概率密度矩陣;文獻[7]從特征選擇的角度出發,對兩類矩陣的檢測性能進行了理論分析和實驗對比。近幾年來,研究者們又提出一系列包含豐富DCT系數模型的高維特征集[8-10],充分反映和刻畫了JPEG圖像的紋理和邊緣特征,進一步提高了隱寫分析的準確性。
隨著隱寫分析算法性能的提升,其特征維數和運算復雜度也越來越高。此外,傳統算法對所有圖像采用相同的處理過程,忽略了圖像內容對隱寫分析結果的影響。由于圖像相鄰系數之間存在較強的相關性且不同內容圖像具有明顯的統計差異,決定隱寫分析準確性的因素除了秘密信息的嵌入機制,還包括圖像自身的內容特征。文獻[11]提出一種基于圖像復雜度的通用隱寫分析框架,該方法通過對圖像庫分類,有效提高了對多種隱寫算法的檢測性能,但其假設載體和相應載密圖像的復雜度一致并不符合實際情況,這是因為在秘密信息嵌入后,系數相關性的改變使得圖像內容復雜度也發生了變化。文獻[12]通過對圖像分塊進行聯合判決,在提高檢測準確率的同時大大增加了特征維數;文獻[13]采用的圖像分割模型同樣提高了隱寫分析的運算復雜度。
本文從圖像內容描述出發,提出一種基于預分類和特征擴展的JPEG圖像通用隱寫分析方法。該方法以JPEG圖像的DCT系數分布特征作為其內容復雜度的測度,通過預分類將特性相似的圖像劃分至同一子庫,使每類子庫中圖像的隱寫檢測特征更加聚合;通過特征擴展提高檢測特征對嵌入信息的敏感性,使載體和載密圖像特征具有更佳的可分性。實驗結果表明,在不明顯增加特征維數和運算復雜度的前提下,本文方法對典型JPEG圖像隱寫算法的檢測性能優于現有方法。
1 方法原理及流程
隱寫分析可看作模式識別問題,其關鍵在于尋找對嵌入變化敏感的檢測特征。設xi和yj分別表示載體和載密樣本集的隱寫分析向量,其中i=1,…,Nc,j=1,…,Ns,則有
(1)
(2)
(3)
(4)
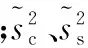
為了區分兩類數據,定義判別函數[14]:
(5)
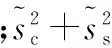
由于圖像內容千差萬別,而秘密信息嵌入引起的變化非常微小,通常情況下,載體和載密兩類數據的類間距離很小,同類數據的類內分布卻差異很大。基于此,本文從減小類內散度和擴大類間距離兩個角度出發,在不明顯增加運算量的前提下,提出一種新的JPEG圖像通用隱寫分析方法,具體流程如圖1所示。
在訓練階段,首先從圖像庫中隨機選取部分載體圖像和相應的載密圖像形成訓練樣本集,根據圖像的內容復雜程度將其劃分為若干個互相重疊的類別,使每一類子庫所包含的圖像都具有相同或相似的統計特性;然后對每一類子庫分別提取擴展后對嵌入變化更加敏感的檢測特征并建立分類器進行訓練。在測試階段,同樣先計算待測圖像的內容復雜度及其與各類子庫復雜度均值的歐氏距離,按照最小距離原則將待測圖像劃分至相應類別中,提取擴展的隱寫檢測特征并使用對應的分類器進行測試,進而得到最終的判決結果。
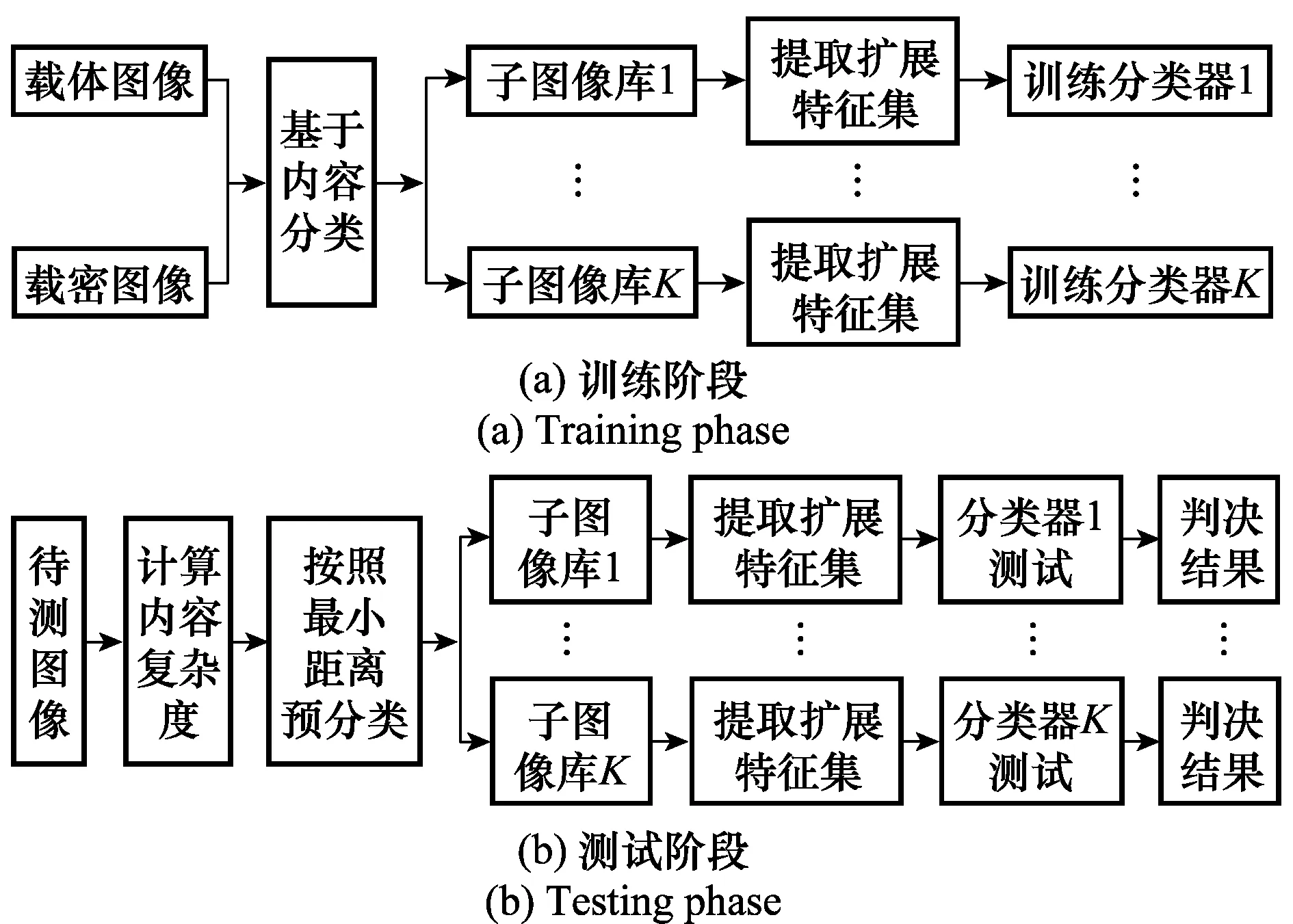
圖1 JPEG圖像通用隱寫分析方法流程圖Fig.1 Framework of JPEG image universal steganalysis
2 基于圖像內容的預分類
2.1圖像內容復雜度度量
對于數字圖像而言,經過DCT變換和量化后,平滑區域的能量聚集在系數的直流和交流低頻部分,復雜區域的能量聚集在系數的交流高頻部分。由于大多數隱寫算法不在直流系數中嵌入秘密信息,因此本文以JPEG圖像中非零交流系數個數與交流系數總數的比值(non-zero AC-DCT coefficients ratio,NZAR)作為圖像內容復雜度度量,部分圖例如圖2所示。

圖2 圖像及圖像內容復雜度示例Fig.2 Example of images and image content complexity
由圖2可以看出,圖像的平滑區域越多,NZAR值越小;圖像的紋理細節越豐富,NZAR值就越大,這與人眼的視覺判斷基本相符,說明NZAR特征可以在一定程度上反映圖像內容的復雜程度。
2.2分類方法
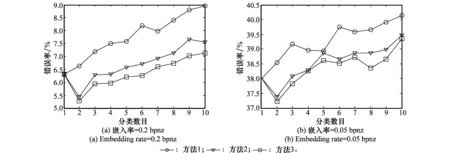
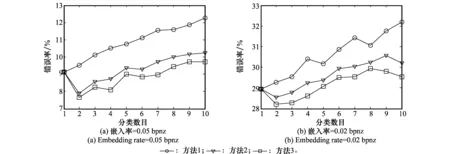
在文獻[11]的分類方法中,假設載體和相應載密圖像的復雜度一致,并將它們分至同一類子庫中進行隱寫檢測。實際上在秘密信息嵌入后,相鄰系數相關性的改變使得圖像復雜度也發生了變化,載體和相應的載密圖像有可能不屬于同一類別。以nsF5[15]算法為例,對圖2中4幅圖分別嵌入0.2 bpnz(bits per non-zero AC-DCT coefficient)秘密信息,隱寫前后圖像DCT系數的分布變化如圖3所示。可以看出,圖像內容越復雜,嵌入的秘密信息比特數就越多,載體和載密圖像之間的統計量差異就越大,NZAR值的改變就越明顯。
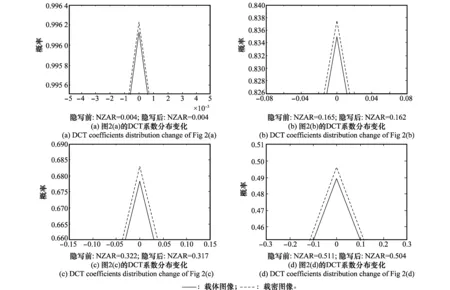
圖3 不同內容圖像在隱寫前后的DCT系數分布變化Fig.3 DCT coefficients distribution change of different content images before and after steganography
此外,由于JPEG圖像的NZAR特征范圍較窄,如果采用簡單的平均分類方法對按復雜度排序后的訓練樣本集進行分類,就會使部分內容復雜度相等的圖像被劃分至不同類別中;隨著分類數目的增加,每一類子庫的圖像數量明顯下降,使得分類器的檢測性能也受到影響。針對文獻[11]所提方法的不足,本文提出一種新的圖像庫分類方法,詳細步驟如下:
步驟1對于給定的訓練樣本集,計算所有載體圖像的NZAR特征。
步驟2按照載體圖像NZAR特征的大小對其進行升序排列,并將排序后的圖像平均分為K類;第i類子庫中NZAR特征的最大值記作MAX(i),最小值記作MIN(i),其中1≤i≤K。
步驟3令R(I)表示第i類子庫中圖像I的NZAR值,如果滿足以下任何一種情況,則I同樣屬于第j類,其中1≤j≤K且j≠i:
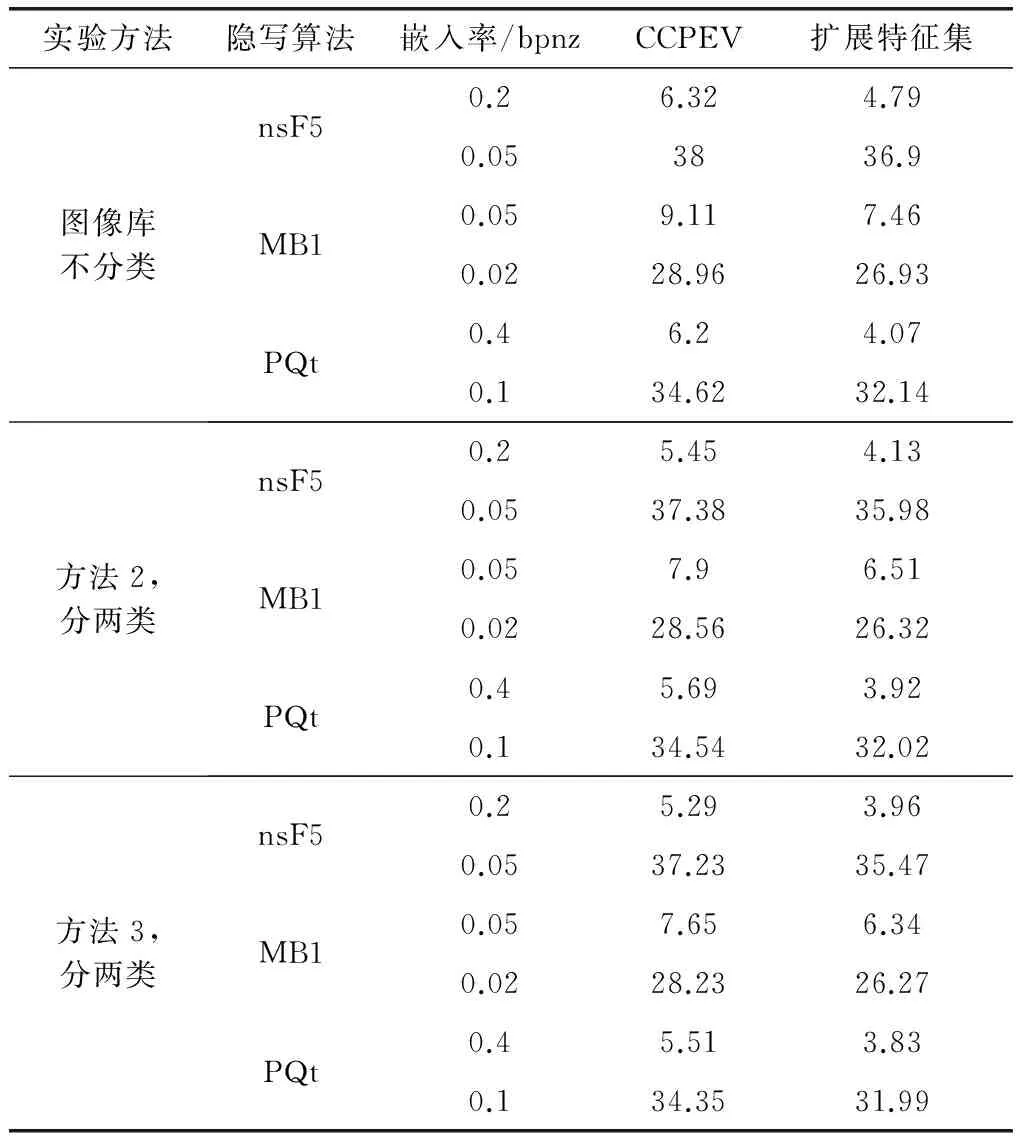
(1)當j>i時,如果
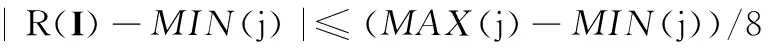
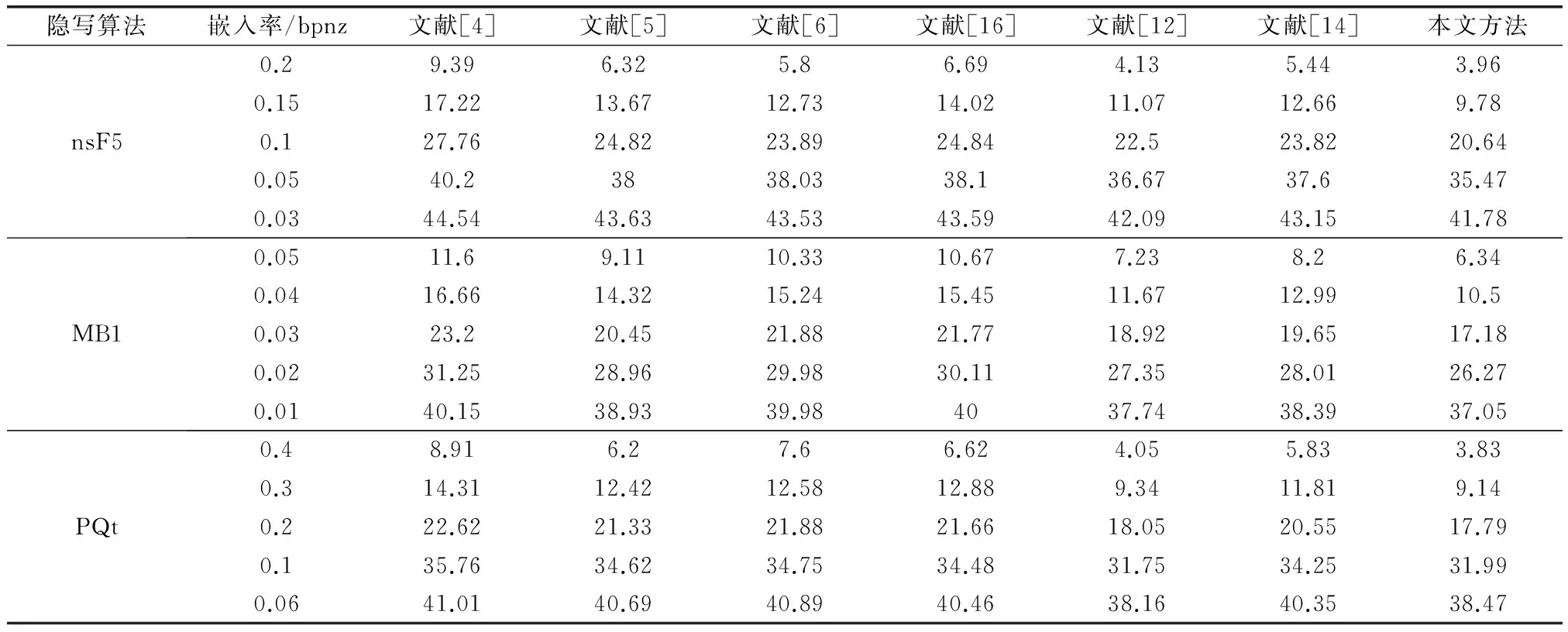
(2)當j 步驟4對所有的載體圖像分別重復步驟3的過程,最終將其劃分為K個互相重疊的類別。 步驟5按照步驟1~步驟4的過程,將所有的載密圖像也劃分為K個互相重疊的類別。在此基礎上,組合載體圖像和載密圖像的對應類別,構成訓練樣本集的各個子圖像庫。 通過上面的步驟,訓練樣本集中內容復雜度相等的圖像被完全劃分至同類子庫,且每一類子庫所包含的圖像都具有相等或相近的NZAR特征;由于各類子庫中訓練樣本數目的增加,相應分類器的檢測性能也有所提升。在測試階段進行預分類時,同樣先計算待測圖像的NZAR值,然后計算其與各類子庫復雜度均值的歐氏距離,并按照最小距離將待測圖像劃分至相應類別中。 CCPEV(cartesian calibrated PEV)[5]是一種廣泛應用的基于校準技術的JPEG圖像隱寫檢測特征,包括全局直方圖、單頻直方圖、對偶直方圖、塊間總偏差、空域塊邊界不連續性、共生矩陣和塊內Markov轉移概率矩陣。其中,直方圖、塊間總偏差和空域塊邊界不連續性屬于全局特征,能夠統計較大范圍的系數改變,但有些隱寫算法會采取修補技術來控制全局特征的擾動,因此需要補充描述局部相關性的特征。轉移概率矩陣主要關心修改DCT系數后對局部引起的變化,CCPEV中直接將不同方向的塊內特征加權平均,雖然能夠降低特征維度,但檢測性能也有所下降,同時也缺少合理性的解釋。此外,為抵抗直方圖等一階統計特征的檢測,某些隱寫算法會刻意保持相鄰DCT系數間的統計特性不變,但對于相鄰的8×8塊,同一頻率系數之間的相關性難以保持。據此,本文對CCPEV的塊內和塊間特征進行了擴展以提高隱寫檢測特征對不同嵌入變化的敏感性。 假設I為一幅尺寸為M×N的JPEG圖像,該圖像的量化DCT系數的絕對值矩陣為A(u,v),其中1≤u≤M,1≤v≤N。對于擴展的塊內特征,首先計算水平(h)、垂直(v)、對角(d)和反對角(m)4個方向的差分矩陣: (6) (7) (8) (9) 式中,Ah是M×(N-1)的矩陣;Av是(M-1)×N的矩陣;Ad和Am均為(M-1)×(N-1)的矩陣。為了降低運算復雜度,設置閾值T,令差分矩陣中數值大于T的元素設定為T,小于-T的元素設定為-T,其余元素的數值保持不變。 把差分矩陣中的單個元素看作Markov變量的實現,可以得到4個不同方向的轉移概率矩陣。而文獻[6]指出,與轉移概率相比,聯合概率更能捕捉由于信息嵌入造成的系數微小變化,因此本文采用聯合概率密度矩陣來描述DCT系數的塊內相關性。 (10) (11) (12) (13) 式中 令AT表示矩陣A的轉置,按照式(6)~式(13)的計算過程,由矩陣AT可以得到4個方向的聯合概率密度矩陣{Ch,2,Cv,2,Cd,2,Cm,2}。根據各向同性的假設,可近似認為A和AT具有相同的分布,從而兩組特征{Ch,1,Cv,1,Cd,1,Cm,1}和{Ch,2,Cv,2,Cd,2,Cm,2}中相應的每對特征也都是同分布的[16]。將這些具有相同分布的特征合并可得 (14) 此外,由式(6)~式(13)的構成,可以看出一些矩陣是相等的,如Ch,1= Cv,2,Cv,1= Ch,2,所以Ch= Cv,Ch可由Ch,1和Cv,1合并得到;由Cd,1= Cd,2得到Cd= Cd,1;而Cm,1和Cm,2關于u=-v對稱,約減Cm,1即可得到Cm。綜上,擴展后的塊內特征為{Ch,Cd,Cm},共 (5T+3)(2T+1)維。考慮到圖像統計特性的描述和特征維數之間的均衡,通常選擇閾值T=4。 對于擴展的塊間特征,由于DCT系數的塊間相關性較弱,因此特征提取的過程中需要考慮幅值和符號兩個方面的相關性。設圖像I的量化DCT系數矩陣為D(u,v),其中1≤u≤M,1≤v≤N。首先計算水平和垂直兩個方向的塊間差分矩陣: (15) (16) 式中,Dh是M×(N-8)的矩陣;Dv是(M-8)×N的矩陣。則DCT系數的塊間差分直方圖為 (17) 式中,-5≤r≤5。相鄰塊的差分聯合概率密度矩陣為 (18) 式中,-2≤s;t≤2。 綜上所述,結合CCPEV中的直方圖、塊間總偏差、空域塊邊界不連續性和共生矩陣特征以及圖像校準技術,擴展后的特征集共872維。各部分特征如表1所示。 表1 擴展特征集 BOWS2[17]是隱寫分析中常用的圖像庫,包含10 700幅分辨率為512×512的灰度圖像,主題涉及自然風景、人文建筑、動植物等。實驗中隨機選取10 000幅圖像經JPEG壓縮后作為隱寫載體,分別使用nsF5[15]、MB1[18]和PQt[19]生成載密圖像。其中,nsF5和MB1的載體圖像質量因子為75,PQt的載體圖像質量因子為85。所有算法的嵌入率根據其自身的檢測難度進行選擇,并以bpnz為單位度量。 為了測試算法的檢測性能,本文采用集成分類器[8]進行分類。從載體和相應的載密圖像中隨機選擇50%作為訓練樣本,剩余50%作為測試樣本,以最小總誤差作為衡量指標: (19) 4.1不同分類方法的性能對比 為了驗證本文分類方法的有效性,分別對以下幾種方法的檢測性能進行對比: 方法 1將訓練樣本庫隨機分為若干類,保證每一類的圖像數目與本文方法基本一致; 方法 2按照文獻[11]提出的方法對訓練樣本庫進行平均分類,載體和相應的載密圖像在同一類中; 方法 3本文提出的圖像庫分類方法。 實驗中提取CCPEV作為各種分類方法的隱寫檢測特征,結果如圖4~圖6所示。 圖4 nsF5在不同分類方法下的檢測錯誤率Fig.4 Detection error rates for nsF5 steganography among different classification methods 圖5 MB1在不同分類方法下的檢測錯誤率Fig.5 Detection error rates for MB1 steganography among different classification methods 從圖中可以看出,本文分類方法能有效提高對多種隱寫算法的檢測準確性。與隨機分類相比,本文依據圖像自身的內容復雜度進行分類,使得同類圖像之間的統計特性較為相似,有效降低了類內總散度,因而檢測性能有較大提升;與文獻[11]的分類方法相比,本文提出按照載體和載密圖像各自的NZAR特征進行預分類的方法更加符合實際情況,且分類使得內容復雜度相等的圖像被完全劃分至同類子庫中,由于每一類子庫中訓練樣本數目的增加,相應的分類器模型也具有更好的檢測性能,因此整體的檢測錯誤率明顯下降。此外,當圖像庫分為2~5類時,本文方法的檢測性能較穩定;綜合考慮運算復雜度和隱寫檢測性能,將圖像分類數目設為2。 圖6 PQt在不同分類方法下的檢測錯誤率Fig.6 Detection error rates for PQt steganography among different classification methods 4.2不同隱寫檢測特征的性能對比 為了驗證本文所提取的擴展特征集的有效性,分別在不同實驗方法下將其與CCPEV的檢測性能進行對比,結果如表2所示。 表2 不同特征的檢測錯誤率比較 從表中數據可以看出,相較于CCPEV,擴展特征集能顯著降低檢測錯誤率。分析隱寫算法可知,nsF5利用濕紙碼技術消除了嵌密引起的直方圖收縮現象,但無法保持DCT系數的塊間相關性不變;MB1使圖像在隱寫后出現了較為明顯的塊效應;PQt通過二次壓縮使整體的嵌入變化最小,但無法修復局部系數變化。擴展特征集補充描述了DCT系數的塊內和塊間統計特性,因而提高了對多種隱寫算法的檢測性能。 此外,與圖像預分類相比,特征集的擴展對錯誤率的改善效果更加明顯,原因在于:擴展特征集通過豐富所提特征的多樣性,大大增加了載體和載密兩類數據的類間距離,使其變得更易區分;而采用NZAR特征衡量圖像內容復雜度時,由于JPEG圖像的NZAR特征范圍較窄,分類后不同類別圖像之間的NZAR值差異不大,同一類中載體和載密數據的類內總散度降低較少,因而檢測性能提升不多。 4.3不同隱寫分析方法的性能對比 為了驗證本文方法對不同隱寫算法的檢測性能,分別將其與文獻[4]、文獻[5]、文獻[6]、文獻[16]、文獻[12]和文獻[14]中的隱寫分析方法進行對比,結果如表3所示。從表中數據可以看出,對于3種不同的隱寫算法,本文所提方法的檢測性能在大多數情況下優于其他方法。相較于文獻[4]、文獻[5]、文獻[6]和文獻[16]中直接在整體圖像上提取特征進行隱寫分析的方法,本文通過對圖像庫預分類和特征擴展使檢測錯誤率下降了2%~7%;與文獻[12]和文獻[14]中基于圖像內容的隱寫分析方法相比,本文方法對多種隱寫算法的檢測性能都略有提升,且比文獻[12]的特征維數和運算復雜度有了明顯降低。 表3 不同隱寫分析方法的檢測錯誤率比較 本文考慮圖像內容對JPEG通用隱寫分析的影響,提出了一種基于預分類和特征擴展的新方法來提高檢測準確性。通過預分類將特性相似的圖像劃分至同一子庫中,通過特征擴展來提高檢測特征對嵌入信息的敏感性。實驗結果表明,與現有隱寫分析方法相比,本文方法對典型的JPEG圖像隱寫算法具有更好的檢測性能。下一步將對圖像統計特性展開更深入的研究以尋找更有效的內容復雜度度量準則。 [1] Li F Y,Wu K,Lei J S,et al.Steganalysis over large-scale social networks with high-order joint features and clustering ensembles[J].IEEE Trans.on Information Forensics and Security,2016,11(2):344-357. [2] Zhu T T,Wang L N,Hu D H,et al.JPEG image steganalysis method based on uncertainty reasoning theory[J].Acta Electronica Sinica,2013,41(2):233-238.(朱婷婷,王麗娜,胡東輝,等.基于不確定性推理的JPEG圖像通用隱藏信息檢測技術[J].電子學報,2013,41(2):233-238.) [3] Fridrich J.Feature-based steganalysis for JPEG images and its implications for future design of steganographic schemes[C]//Proc.of the 6th International Workshop on Information Hiding,2004:67-81. [4] Chen C H,Shi Y Q.JPEG image steganalysis utilizing both intrablock and interblock correlations[C]//Proc.of the IEEE International Symposium on Circuits and Systems,2008:3029-3032. [5] Kodovsky J,Fridrich J.Calibration revisited[C]//Proc.of the 11th ACM Multimedia and Security Workshop,2009:63-73. [6] Liu Q Z,Sung A H,Qiao M Y.Neighboring joint density-based JPEG steganalysis[J].ACM Trans.on Intelligent Systems and Technology,2011,2(2):1-16. [7] Lu J C,Liu F L,Luo X Y.A study on JPEG steganalytic features:co-occurrence matrix vs.markov transition probability matrix[J].Digital Investigation,2015,12:1-14. [8] Kodovsky J,Fridrich J,Holub V.Ensemble classifiers for steganalysis of digital media[J].IEEE Trans.on Information Forensics and Security,2012,7(2):432-444. [9] Li F Y,Zhang X P,Chen B,et al.JPEG steganalysis with high-dimensional features and bayesian ensemble classifier[J].IEEE Signal Processing Letters,2013,20(3):233-236. [10] Chen B,Feng G R,Zhang X P,et al.Mixing high-dimensional features for JPEG steganalysis with ensemble classifier[J].Signal Image and Video Processing,2014,8(8):1475-1482. [11] Amirkhani H,Rahmati M.New framework for using image contents in blind steganalysis systems[J].Journal of Electronic Imaging,2011,20(1):013016-1-013016-14. [12] Cho S G,Cha B H,Gawecki M,et al.Block-based image steganalysis:algorithm and performance evaluation[J].Journal of Visual Communication and Image Representation,2013,24(7):846-856. [13] Wang R,Xu M K,Ping X J,et al.Steganalysis of JPEG images by block texture based segmentation[J].Multimedia Tools and Applications,2015,74(15):5725-5746. [14] Li W X,Zhang T,Hu G E,et al.Image pre-classification to improve accuracy of universal steganalysis[C]//Proc.of the 5th IEEE International Conference on Software Engineering and Service Science,2014:364-368. [15] Fridrich J,Pevny T.Statistically undetectable JPEG steganography:dead ends challenges,and opportunities[C]//Proc.of the 9th ACM Multimedia and Security Workshop,2007:3-13. [16] Zhang H,Ping X J.New design of markov steganalytic features[J].Journal of Electronics & Information Technology,2013,35(8):1907-1913.(張昊,平西建.Markov隱寫檢測特征的一種新設計[J].電子與信息學報,2013,35(8):1907-1913.) [17] Bas P,Furon T.BOWS-2[EB/OL].[2015-07-10].http://bows2.ec-lille.fr. [18] Sallee P.Model-based steganography[J].Lecture Notes in Computer Science,2004,2939:154-167. [19] Fridrich J,Goljan M,Soukal D.Perturbed quantization steganography[J].Multimedia Systems,2005,11(2):98-107. JPEG image steganalysis based on pre-classification and feature extension GUO Ji-chang,LIU Xiao-juan,TIAN Yu-heng (School of Electronic Information Engineering,Tianjin University,Tianjin 300072,China) The performance of joint photographic experts group (JPEG)image steganalysis is related not only to the information-hiding methods but also to the complexity of image content.A novel approach based on pre-classification and feature extension is proposed to improve the accuracy of JPEG universal steganalysis.Firstly,an image content complexity evaluation criterion is exploited to divide the training samples into several overlapping categories.After that,the more effective extended feature set is extracted from each category respectively to build a classifier.Given a testing image,its category is determined according to the minimum distance from its complexity to the average value of each category.Then,the feature set is extracted and sent to the corresponding classifier.Experimental results indicate that this new approach exhibits excellent performance for the detection of typical JPEG steganography algorithms. steganalysis; image content complexity; pre-classification; feature extension 2016-03-24; 2016-07-04;網絡優先出版日期:2016-08-05。 國家重點基礎研究發展計劃(973計劃)(2014CB340400);天津市自然科學基金(15JCYBJC15500)資助課題 TP 391 ADOI:10.3969/j.issn.1001-506X.2016.11.31 郭繼昌(1966-),男,教授,博士,主要研究方向為數字圖像處理及DSP應用系統、語音信號處理、數字和模擬濾波器設計。 E-mail:jcguo@tju.edu.cn 劉曉娟(1991-),女,碩士研究生,主要研究方向為數字圖像處理、圖像隱寫分析。 E-mail:xiaojuan@tju.edu.cn 田煜衡(1986-),男,博士研究生,主要研究方向為數字圖像處理、模式識別、隱寫與隱寫分析。 E-mail:tianyuheng2004@163.com 網絡優先出版地址:http://www.cnki.net/kcms/detail/11.2422.TN.20160805.1523.002.html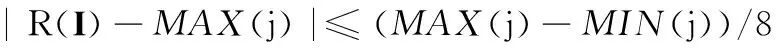
3 特征擴展


4 實驗與分析

5 結 論
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
