文學模式識別:文本細讀與機器學習之間的現代主義①
2016-12-20 02:41:05霍伊特懿譯
山東社會科學 2016年11期
關鍵詞:文本
[美]霍伊特·朗 [美]蘇 真 撰 林 懿譯
(芝加哥大學 東亞語言與文化系,美國 芝加哥 60637;芝加哥大學 英文系,美國 芝加哥 60637)
?
文學模式識別:文本細讀與機器學習之間的現代主義①
[美]霍伊特·朗 [美]蘇 真 撰 林 懿譯
(芝加哥大學 東亞語言與文化系,美國 芝加哥 60637;芝加哥大學 英文系,美國 芝加哥 60637)
本文的標題即宣告了它的核心目標:提出一種可以整合常見的人文主義手法和電腦計算手法的文學文本閱讀形式。近年來,運用計算機來闡釋文學引發了激烈的爭論。一方面,弗朗科·莫瑞狄(Franco Moretti)、馬修·喬克斯(Matthew Jockers)、馬修·威爾肯斯(Matthew Wilkens)和安德魯·派博(Andrew Piper)等學者支持運用主題建模、網絡分析等精密機器技術來揭示從海量數字化文學資料庫中挑選出的語言與形式的宏觀模式。*Franco Moretti, Distant Reading, London, 2013; Matthew L. Jockers, Macroanalysis: Digital Methods and Literary History, Urbana, Ill., 2013; Matthew Wilkens, “The Geographic Imagination of Civil War-Era American Fiction,” in American Literary History 25 (Winter 2013), pp. 803-40; and Andrew Piper and Mark Algee-Hewitt, “The Werther Effect I: Goethe, Objecthoods, and the Handling of Knowledge,” in Matt Erlin and Lynn Tatlock (eds), Distant Readings: Topologies of German Culture in the Long Nineteenth Century, Rochester, N.Y., 2014, pp. 155-84.另一方面,亞歷山大·加洛韋(Alexander Galloway)、大衛·科倫比亞(David Golumbia)、塔拉·麥克弗森(Tara McPherson) 和艾倫·劉(Alan Liu)等新媒體研究領域的學者則批評機器技術,認為此類技術將文學文本的復雜性化約成純粹的“數據”,或它們與批評理論的目標無法匹配。*有關加洛韋、科倫比亞與麥克弗森的近期批評,參見期刊Differences關于“在數字人文的陰影下”主題的特別話題。他們的論文包括:Alexander Galloway, “The Cybernetic Hypothesis,” in Differences 25, No.1(2014), pp.107-31; David Golumbia, “Death of a Discipline,” in Differences 25, No. 1 (2014), pp.156-76; 與 Tara McPherson, “Designing for Difference,” in Differences 25, No. 1, 2014, pp.177-88.同時參見Alan Liu, “Where is Cultural Criticism in the Digital Humanities?” in Debates in the Digital Humanities, Matthew K. Gold (ed), Minneapolis, 2012, pp. 490-509.這里我們要通過創建一個不將一種閱讀模型與另一種模型對立,而是把人文主義方法和電腦計算方法整合進一種我們稱為文學模式識別的文學分析方式,來超越這一僵局。
這一整合的動機是雙重的。首先,當下多數人文主義學者已經參與了某些形式的電腦計算批評。正如泰德·安德伍德(Ted Underwood)指出的,任何計算機輔助的信息搜索,不管是通過谷歌還是更正式的諸如JSTOR這樣的學術數據庫,都是一種由機器學習算法所支持的“數據挖掘”。*Ted Underwood, “Theorizing Research Practices We Forgot to Theorize Twenty Years Ago,” in Representations 127 (Summer 2014), p.65.每次我們在谷歌圖書或其他數字化資料庫中輸入一個搜索詞條,我們都在與這些算法互動。安德伍德補充道,人文主義研究者們傾向于忽略這種互動而不進行理論研究,他們認為搜索引擎僅僅是幫助我們通達真正闡釋工作的工具,同時還往往堅稱這些工具背后的科學是非人性的、僵硬的、機械的。甚至在我們批評這些工具與我們作為人性讀者所參與的細致分析和批判性思考相比的“黑箱”性質時,我們還是在自己的研究中把這些工具黑箱化。*“黑箱”是理工類程序中的常見概念,指某程序的機制無法被人完全掌控或觀測,只能知道輸入和輸出的結果。——譯者注運用更復雜數據挖掘工具的文學研究學者更是加倍地受到指責,理由是他們通過冰冷而不知變通的機器邏輯來扭曲了文學文本。然而,隨著我們與文本(以及信息)的互動越來越多地受到數字格式和大數據庫的影響,這一立場變得愈發站不住腳。我們無法在繼續忽視機器算法如何“閱讀”文學信息的同時,又盲目地依賴它們來強化我們自身的閱讀與闡釋實踐。
與此同時,主張批評家們必須學習這些計算程序如何操作并不表示這些程序是毫無問題的人力閱讀模式的替代品——也不意味著對機器技術正當性的評判可以由更復雜的計算模型和更大容量的數據庫來滿足,盡管斯坦福文學實驗室(Literary Lab)的莫瑞狄、馬克·阿爾及-休伊特(Mark Algee-Hewitt)與萊恩·霍伊澤爾(Ryan Heuser)已在這些方面作了杰出的工作。*參見這一團隊在斯坦福文學實驗室印發的一系列出色的手冊,Pamphlets,
以上正是我們這里通過一個對文學現代主義、特別是英語俳句的案例分析所試圖達到的目標。從什么定義了現代英語俳句這一基本問題開始,我們同時運用常見批評模型(文本細讀與歷史主義批評)和計算機手段(機器學習)來給出三種相異的答案。也就是說,我們將通過三種文本分析模型來考察一個實質為文體辨認的問題。這種做法意在表明每一種模型都暗含了其自身的文本本體觀,且每種模型都揭示了與它的本體觀相連的對文學模式和文體學影響的理解。不過,我們并非要偏重某一模型而貶低另一模型,而是要主張通過這類人力閱讀與機器閱讀的交互作用,凸現出一種關于俳句這種文學事物的新的批評視角。通過將這些文學分析模型理解為按其自身視域具有理據、而在更廣闊的模式識別闡釋學中可相互對照,一種關于俳句——以及廣義地關于現代主義文本——的新的本體觀出現在人們視野中。
本論文由四部分組成。第一部分通過文本細讀來詳述俳句的特點;第二部分將俳句作為社會歷史事物來閱讀;第三部分則通過機器學習的框架來闡釋俳句。在以上各部分中,我們將分析每一種批評手法提供的特有而自發的關于俳句的觀念,并且揭示這些觀念如何架構起相應手法辨別俳句——作為一種特殊且可重復的文體或文學模式——的能力。在最后一部分中,我們使各批評手法直接對話,以表明盡管它們遵循的對俳句的本體論認識各不相同,不同的識別文學模式(pattern)的方式卻可以補充各自的不足。綜合起來考察,這些批評手法提供了作為社會與文化氛圍的英語俳句的更全面的圖景——它是更廣闊的流行于20世紀初的東方主義風格的一部分。*結語部分將闡明我們運用這一術語的準確意義。由此,本論文最終通過展示我們如何能夠把美國現代主義時期的東方主義歷史重新理解為不同本體論范疇所表達的一套相互重疊的文本模式,為現代主義時期的東方主義研究作出貢獻。
作為現代主義文本的英語俳句
首先,什么決定了一首詩是否是英語俳句?一種判定詩歌屬于某種創作體裁的方法是將它當作一個單獨的文本來研究,并仔細分析它的內容與形式特點。這種方法就是我們認為的典型的文本細讀。假設我們面對埃茲拉·龐德的《四月》這首詩,我們將怎樣決定它是否是英語俳句?
三個幽靈向我走來
撕裂我
引我走向橄欖樹枝
赤裸躺臥之地;
光亮霧靄下的蒼白尸體。*Ezra Pound, “April,” in Personae: Collected Shorter Poems of Ezra Pound, London, 1952, p. 101.
由于這首詩不具備日本俳句“五七五”的傳統音節模式,我們可以首先總結出,就最嚴格的形式定義而言,這首詩不是俳句。然而一些縱然天真卻是直覺性的觀察卻能夠支持該詩借用了日本俳句的其他文體特點這一看法。首先,這是首短詩,特別短。其次,這首詩不關注敘事而突出了一系列生動的意象——詩里沒有故事,也沒有“人物”——并且這些意象取自自然。在這些方面,《四月》與淺表觀點中的俳句特點相吻合。更深刻更投入的讀法則可以把該文本視為某種哲學聲明來考察。在開頭兩行中,我們發現說話的自我或詩中的“我”實際上被文本撕裂且迅速被一個具體意象所取代:橄欖樹枝。主體性——該文本暗示道——是棲居于外部事物而非人的身體或心靈中。是“樹枝”赤裸躺臥在地,它替換了之前被撕裂的身體或意識。最后一行則通過與其他意象的重疊而強調了這一意象,樹枝被轉移為“光亮霧靄”下的“蒼白尸體”。主體性回歸了(與“樹枝”的純粹物性不同,“蒼白尸體”這一意象暗示了情緒與感情),但此時是經由一個以并置方式運作的生動意象的中介。一半是取自自然的物質(“霧靄”),另一半則蘊含情緒(“蒼白尸體”),詩句成功地將主體與客體融合起來。
基于這樣的閱讀,我們可以認為《四月》代表了一例英語俳句,因為它滿足了我們賦予其他這一類型的詩歌的某些標準。我們又是怎樣獲得這些標準的呢?部分靠直覺。作為文學作品的讀者,我們繼承了關于用英文寫成的俳句是何模樣的普遍直感:它應該是短的,包含自然意象,并在表達上是含蓄的。更嚴密地說,我們用以判斷一首詩是否是英語俳句的標準源自其他文學研究者的論著。例如,厄爾·邁納(Earl Miner)提出英語俳句通常具有以下特征:對精簡與準確的倚重、對常常將具體卻不相稱的意象并置的視覺語言的運用,以及由這些意象的運用產生的具有暗示性而非刻意或外顯的意義。*參見Earl Miner, The Japanese Tradition in British and American Literature, Princeton, N. J., 1958, p.125; 下文簡稱JT.我們可以將這些特征視為英語俳句普遍遵循的一套規則。
運用這些標準,我們還可以開始通過判斷詩歌甲或詩歌乙是否具備與《四月》相似的美學特征來辨別出這一時期的其他英語俳句。試思考威廉·卡洛斯·威廉斯的《婚姻》:
如此不同,這男人
和這女人:
田里流動的
一條小溪。*William Carlos William, “Marriage,” in The Collected Poems of William Carlos William, A. Walton Litz and Christopher MacGowan (eds), 2 vols. (New York, 1986-1988), 1:56.
直覺再一次暗示了這是一首受到俳句啟發的詩。這首詩簡短、基于意象,并以取自自然的事物結尾。更為重要的是,它也滿足了邁納提出的基本標準。在內容與排印兩個方面看,它都聚焦于呈現而非再現,并且將男人、女人與自然景物相重疊,明顯地使用了并置法。然而,將它與《四月》對比時又出現一些區別。詩中確實有并置(或疊加)發生,但這一技巧卻沒有那般牢固地基于意象。詩歌雖然也有從主體性的到客體性的轉換和二者最終的相互融合,卻不似前詩那般專注于將這一現象凝結為視覺觀感。學術界也肯定了以上粗略的比較。查爾斯·阿爾提艾瑞(Charles Altieri)寫道,“總體而言,威廉斯拒絕龐德那種關于形式的抽象話語,并強調對地點與尋常話語的敏感性就已足夠使事實更加生動。”*Charles Aliteri, The Art of Twentieth-Century American Poetry: Modernism and After, Malden Mass., 2006, p.41.如此一來,要把兩首詩都辨識為俳句,我們必須進行妥協,承認二者雖都體現了俳句的風格影響,但個體詩人的性情和身處環境各自不同。事實上,這正是當我們試圖分析某一文體跨作家和跨語境的豐產性和流變過程時,文本細讀常常使我們處于的分析立場:探查不同藝術家如何不同程度地加入了這一文體。正如此處所演示的,這些分析步驟的實施預設了英語俳句具有某種理想模式,將某首詩與它進行比對即可根據其近似或偏離的程度來評估該詩的“俳句性”。
這些分析步驟在現代主義詩歌研究中無疑是很常見的。阿爾提艾瑞、瑪喬瑞·帕洛夫(Marjorie Perloff) 與海倫·文德勒(Helen Vendler)等重要學者在描述某文體與某一特定詩人或詩人圈的關聯時,常常運用與形式有關的語言。例如,阿爾提艾瑞認為意象主義詩人追求一種關于“感知”的“與眾不同的形式”*Charles Aliteri, The Art of Twentieth-Century American Poetry: Modernism and After, Malden Mass., 2006, p.23.,而文德勒則肯定了一種華萊士·史蒂文斯形式的存在,它運作起來就像“一種代數式的陳述,每個讀者都能用自己的價值來取代其中的x或y”*Helen Vendler, Wallace Stevens: Words chosen out of Desire, Knoxville, Tenn., 1984, p. 8.。這類批評思路試圖辨明現代主義詩人是如何將語言的整個范疇改造成某種文體或寫作形式——帕洛夫稱之為詩歌的“模式”(pattern),在她的理解中它與語義和印刷版式均有關。*參見Marjorie Perloff, The Dance of the Interllect: Studies in the Poetry of the Pound Tradition, Evanston, Ill., 1996.
然而,在其他案例中,現代主義學者們運用對比性的文本細讀來達成相反的目標。他們傾向于關注各文本“活生生的獨一性”而非它們共享的對某一“形式”或“模式”的繼承。*Peter Nicholls, “The Poetics of Modernism,” in The Cambridge Companion to Modernist Poetry, Alex Davis and Lee M. Jenkins (eds.), New York, 2007, p. 61.在這些例子中,學者們會關注一首詩通過它被寫就以及它通過語言獲得形式的過程所獲得的意義的深淺。意義產生于物質性的語言和文本自身的顯現。不但詩歌表達的力量來自于它自身的語言,而且詩歌閱讀也關乎將詩歌本身視為一起正在發展的事件。這些觀點被處于龐德、威廉斯與史蒂文斯等作家的經典闡釋領域中的權威學者們著重肯定。例如,彼得·尼科爾(Peter Nicoll)認為每個現代主義文本都揭示了“某一語言的紋理內的一個嶄新和‘別樣的現實’”,并“創建了它自己的世界”*Peter Nicholls, “The Poetics of Modernism,” in The Cambridge Companion to Modernist Poetry, Alex Davis and Lee M. Jenkins (eds.), New York, 2007,p.6,p.61.。在這些描述中,一首詩就是一個表達之獨一性的例子;它只屬于其被創造出來的那種語言。潛藏在此處的是這樣一種信仰,即每一個文本,它作為在讀者眼前展開的一個語言世界,只能是且只將其自身呈現為某一獨特類別的詩歌。
如果放在一起考察,這兩種文本細讀的闡釋傾向留給我們一種多少有些油滑的現代主義文本本體觀。一方面,文本被視為不同程度地隸屬于更普遍的文學風格形式,如“史蒂文斯形式”。另一方面,文本又作為一個“活生生的獨一性”而存在,或是作為一個自我建構的現實,其美學價值取決于它對一切成規的背離。在現代主義詩歌研究中,第二種觀點往往獲得勝利。對個體文本進行精深細讀并說明它們的獨特性質在這些研究中成為主流,而將詩歌根據普遍化的風格形式或模式來分類則受到較少關注。這自然與相關領域盛行的某些批評傾向有關,不過,我們也可以將之部分歸因于文本細讀這一方法自身的限制。根據一個共享的風格模式來不斷篩選詩歌的計劃在數十篇詩歌的層面似乎還可行,但到數百篇的層面該怎么辦呢?如果人們偏向于認為每個閱讀行動本質都是主觀的,且文本的風格也取決于僅對那一特定例子適用的一干因素,那么將文本細讀當作一種模式辨認的方式就變得十分難以操作了。詳述某文本的獨特方面或描述它如何偏離了預設的規范模型會比試圖界定該模型更有回報。如果某一形式在每次閱讀新文本時都需要進行更改或調整,要設想它有任何可確證的一致性就變得更困難了,因此放棄形式或僅僅將之假定為一個模糊的概念會更容易些。
我們本來或可接受這種不穩定的文學模式概念,然而英語俳句卻給我們呈現了一個特殊的例子。作為文本細讀的對象,英語俳句往往在學術批評中同時橫跨兩個方面。也就是說,它被一些人理解為遵循一個明顯可辨的模式,又被另一些人解讀為一個極度開放且模糊的美學形式。例如,杰弗瑞·約翰遜(Jeffrey Johnson)堅持認為存在一個明確的“俳句形式”,并同邁納一樣勾勒出一套規則來描述這一形式的特征。這些規則包括“以名詞為主宰的詩句”和“無評論的意象”等例,而一首英語俳句中總會呈現這些規則的某些組合。*Jeffrey Johnson, Haiku Poetics in Twentieth Century Avant-Garde Poetry, Lanham, Md., 2011, p. 69,p.68.但另一些學者卻認為這些規則達成的是一個寬松得多的對形式與風格的限定,甚至只是一個模糊的美學傾向。例如,當文德勒提出“史蒂文斯形式”時,她所想的是這些詩歌共有的一種普遍特質或感覺,而不是一個形式準則清單。*Vendler, Wallace Stevens, p. 57.英語俳句既像“五七五”格律一般易于辨認,又變幻不定得只是一種共有的感覺。
這種雙面特征在勞拉·賴丁(Laura Riding)和羅伯特·格雷夫斯(Robert Graves)的經典專著《現代主義詩歌考察》(ASurveyofModernistPoetry, 1927)中被很好地體現出來。在兩位作者為創造性活動的自足性辯護時,用俳句作為反面例子來表達這種自足性。在他們看來,俳句在現代主義詩歌中到處泛濫寄生,已成為一種模仿性的、更像社會建制而非個體行動的詩歌范例。身為杰出的文本細讀讀者,兩位作者用幾例代表性詩歌就診斷出問題所在(見圖1),并進而“繪制一幅文學圖示”來追索英語俳句的起源和出問題之處:*Laura Riding and Robert Graves, A Survey of Modernist Poetry (London, 1927), p. 216,p. 217,p.218.
是誰發明了前兩首詩的文體,奧爾丁頓先生(Mr.Aldington)還是威廉斯先生?抑或H. D.或弗林特(F. S. Flint)?……在后兩首詩中誰為其形式負責?是誰首先想到模仿日本俳句的形式?或者應該說是誰首先想到模仿法國人對俳句形式的模仿?是奧爾丁頓先生向史蒂文斯先生或龐德先生建議了短一些的詩歌,或是龐德先生向奧爾丁頓先生建議了長些的詩歌等等,或者是龐德先生、史蒂文斯先生和奧爾丁頓先生、威廉斯先生兩隊伙伴決定作為一個學派團隊共同工作;又或者是威廉斯先生、史蒂文斯先生和奧爾丁頓先生、龐德先生兩相結合,鑒于從國別上這樣配對更合適?*Laura Riding and Robert Graves, A Survey of Modernist Poetry (London, 1927), p. 217.

圖1 以上賴丁和格雷夫斯引用的四首詩表現了俳句的寄生特性。這幾首詩也是引文中所指的詩
然而,在嘗試將俳句形式的興起和傳播獨立出來的問題上,賴丁和格雷夫斯就走到這兒。剩下的只能留待猜測。他們面對的僵局正是一個偏向于將詩歌視為自我實現的活生生的獨一體的研究手法所面臨的僵局。他們將俳句視為典型性的文學模式,認為俳句激起了一種共有的感覺,它又形成了一種更廣泛的、被過度復制的風格。但是誰首先開始的?誰是傳播它的罪魁禍首?這些詩歌是如何相像的?堅決忠于一種閱讀模型和一種對詩文的看法,賴丁和格雷夫斯只能戲擬出一串文學批評問題,既不相信也不愿意找到令人信服的答案。對他們來說,英語俳句既是一種傳統文學模式的典型,同時又是一種他們樂于僅僅通過指認就分辨出來的東西。
作為社會歷史事件的英語俳句
一種在更大數量的詩歌之中發現文體模式的辦法是選擇一種不同的英語俳句文本本體觀。這里我們可以求助于新現代主義研究(New Modernist Studies)。它以新歷史主義為指導,為現代主義學者拓展了研究手法與材料。麗貝卡·沃克維奇(Rebecca Walkowitz)與道格拉斯·毛(Douglas Mao)提出,現代主義研究的對象一度只狹隘地聚焦于一小眾經典的、精英的、大半為英語的文本,但現在正朝著新的“時間、空間和深度方向”發展。*Douglas Mao and Rebecca L. Walkowitz, “The New Modernist Studies,” PMLA 123 (May 2008), p.737.這意味著現代主義的時間范疇在向前向后都有擴展;其空間范疇含括了表面上與英美地理中心相距遙遠的地方;其文化范疇也伸向了小圈子精英創作之外的各種文本和體制環境。伴隨這些擴展而來的是對現代主義文本的看法變化:它是體制與媒體環境的產物,并同樣根植于歷史話語體系。*如參見Lawrence Rainey, Institutions of Modernism: Literary Elites and Public Culture, New Haven, Conn., 1999, 以及Andrew Goldstone, Fictions of Autonomy: Modernism from Wilde to de Man, New York, 2013.關于體制環境,還可參見Mark Wollaeger, Modernism, Media, and Propaganda: British Narrative from 1900 to 1945, Princeton, N.J., 2008和Mark Goble, Beautiful Circuits: Modernism and the Mediated Life, New York, 2010中關于現代主義與現代媒體形式的關系。這些看法改變了我們閱讀文本的方式,并將文本視為更廣闊的美學與社會學模式的一部分。
根據這種看法,英語俳句開始看起來不那么像一個自足獨立的詩歌藝術品,而更像美國作家們借鑒外國詩歌體裁的集體嘗試。這里,俳句成了流行體裁和歷史事件——一個陷在特定社會物質流通模式中的美學關注對象。很大一部分在現代主義和東方主義名義下的研究(如克里斯托弗·布什、羅伯特·科恩、埃里克·海奧、史蒂文·姚*上述學者英文名分別為Christopher Bush, Robert Kern, Eric Hayot, Steven Yao.——譯者注和錢兆明等學者的研究)已經提供了一個以濃厚歷史主義為支持的框架,意在將亞洲美學文本在英語中的出現理解為20世紀早中期西方藝術家對東亞文化廣泛癡迷的一部分。*參見Christopher Bush, “Modernism, Orientalism, and East Asia,” in A Handbook of Modernism Studies, ed. Jean-Michel Rabaté, Malden, Mass., 2013, pp.193-208; Robert Kern, Orientalism, Modernism, and the American Poem, New York, 1996; Eric Hayot, Chinese Dreams: Pound, Brecht, Tel Quel, Ann Arbor, Mich., 2004; Steven G. Yao, Translation and the Languages of Modernism: Gender, Politics, Language, New York, 2002; and Zhaoming Qian, Orientalism and Modernism: The Legacy of China in Pound and Williams, Durham, N.C.,1995.這種癡迷已經超出了純粹的美學興趣;受更大政治力量影響的異域情調和帝國主義等話題激起了西方世界對中國和日本藝術的興趣。科恩就這一課題提出了精辟的總結:“我們面臨的問題可被稱為‘囚禁于西方的中國詩歌’,以及翻譯實踐自身被某些具有優先權的事物征用與引導的程度,這些事物試圖擾亂并改變中國詩歌接觸西方讀者的本來過程。”*Kern, Orientalism, Modernism, and the American Poem, p.175.
在新的現代主義框架內,關注焦點由之轉向決定俳句如何接觸到英語讀者的歷史要素,以及這些要素對俳句接受的影響。整個過程可分為三個階段來描述。第一階段稱為發現階段,開始于20世紀初并主要由收集行動或樣本采集行動所決定。這時的目標是為了在東方文學的陳列柜里再添珍品。當時,隨著日本在地理政治舞臺的出場增多,東方文學的陳列品也在擴大。威廉·喬治·阿斯頓(William George Aston)和巴茲爾·霍爾·張伯倫(Basil Hall Chamberlain)兩位日本研究學者在20世紀初搜集了部分最早的俳句學術翻譯。*當時更常用“hokku”和“haikai”兩詞來指稱這一文體。兩個詞雖然與“haiku”同義,但嚴格說來它們仍有區別。“Hokku”指具有五七五音節的開放序列,在歷史上它是長得多的系列相連詩歌。“Haikai”則專指這種相連詩歌的特定傳統,它可以追溯到17世紀早期。“Haiku”則是詩人正岡子規在19世紀90年代新造的詞,用以將這些詩歌分離出來作為各自獨立的詩歌單元。他們還提出了一些關于俳句音節結構和文學譜系的最早的形式描述。然而,在努力把俳句介紹給英語讀者時,兩位學者傾向于以典型東方主義話語的方式來對待俳句——把它作為異域的新奇事物和國家民族特點的標志。如此一來,這許多“極小的情感迸發”*W. G. Aston, A History of Japanese Literature, New York, 1899, p. 294.和“微觀創作”*Basil Hall Chamberlain, “Bash and the Japanese Poetical Epigram,” in Transactions of the Asiatic Society of Japan 30, no. 2 (1902), p.243.——他們這樣稱呼俳句——就被歸統于類型學的描述,以便理解這一文類何以如此奇怪和特別。例如,阿斯頓就認為他們珍藏的是“微小卻珍貴的真實情感與美麗幻想之珠”,它“最突出的品質就是暗示性”*Aston, A History of Japanese Literature, p. 294.。與此相似,張伯倫也把俳句形容為“最微小的文本”,它在最好的情況下是“一個為自然中的小事和日常生活的偶然事件而開啟的孔洞”*Chamberlain, “Bash and the Japanese Poetical Epigram,” p. 245、p. 305.。拉芙卡迪奧·赫恩(Lafcadio Hearn)則以更流行的方法對待該形式,聲稱“短詩的創作者努力通過運用一些精選的詞匯……來激發某個意象或某種情緒,”其造詣深淺“完全取決于暗示的能力”*Lafcadio Hearn, In Ghostly Japan, Boston, 1899, p.154.。
這批珍奇搜尋者雖急于搜集歸檔這一異國文學品種,最終卻對培養本土特點沒什么興趣。不過他們對俳句翻譯的選擇——以及這些譯作日后的流行——可以說為一套美學考慮要素和“精選詞匯”提供了示例,這些都在下一階段的俳句接受中繼續表達出來。*例如,有些人運用俳句譯作的語言(尤其是像廟鐘、小花、盤旋的昆蟲等短語)來描述俳句帶給讀者的理想效果;參見同上,以及Chamberlain, “Bash and the Japanese Poetical Epigram,” p. 309. 與之類似,保羅-路易·庫蘇1906年在一篇有影響的文章中寫道,一首俳句的意義“像屏風背后的豎琴之聲或穿過霧靄而來的梨花香氣那樣”向我們飄來。(Paul-Louis Couchoud, “The Lyric Epigrams of Japan,” in Japanese Impressions: With a Note on Confucius, Frances Rumsey (trans), London,1921, p.38.我們稱這下一階段為試驗階段,此時詩人們變得更愿意激活運用起上一代人積累下來的范例。這是現代主義學者們最為關注的階段,他們往往將其發源追溯到1913年前后一個文學家們組成的小圈子。不過誰和誰說話、在什么時候這樣的細節則較為模糊不清。實際上,把這一階段界定為一個高度活躍于早期接受者和“本土”信息提供者中的“議論”階段或許最為合適。參與其中的主要是英美兩國的與意象主義運動有關的詩人,他們在俳句中發現了各種美學創新的可能性。正如其中一位詩人弗林特于1915年提到的,意象主義運動的起源可追溯到一批倫敦藝術家,他們對英語詩歌不滿,并“在不同時刻提倡用純粹的自由體詩(vers libre)來替換它,用日本的短歌(tanka)和俳諧(haikai);我們都寫了數十首日本俳諧以資娛樂”*F. S. Flint, “The History of Imagism,” in The Egoist 2 (May 1915), p. 71. 詩人把短歌和俳諧與自由體詩聯系在一起,體現出他并不知曉這些形式的音節結構在創作實踐中有多么嚴苛。這也暗示了模糊二者區別的廣泛傾向,我們會在下個部分中考察這一論點。。某些人視為娛樂的東西對另一些人則是嚴肅的事,俳句在先鋒雜志與意象主義文選中激起了一陣改編為英語語言的熱潮。這些現象自然產生了一套關于什么使俳句如此與眾不同的新依據。
龐德與倫敦團體意趣相投,他于1912年開始嘗試這一文體,并在1914年的論文《旋渦主義》中達到頂峰。他在該文中強調了日本詩歌的簡潔、意象和疊加(“一個想法在另一想法之上”),認為這些特征是造出他的名詩《在地鐵站》(1913)那樣的“形似俳句的句子”的根本。同年龐德協助結集了第一部意象主義文選,其中奧爾丁頓(Richard Aldington)、洛威爾(Amy Lowell)和之后的弗萊徹(Fletcher)都嘗試了受発句(hokku)啟發的詩歌。*一位批評家甚至聲稱“日本発句詩歌無疑就是組成首部意象主義文選的參照模本,尤其是其中龐德先生的貢獻”。(George Lane, “Some Imagist Poets,” in The Little Review 2, May, 1915, p. 27)值得注意的是,洛威爾和弗萊徹欣賞俳句的原因與第一階段批評家指出的某些俳句特征相吻合,即它的簡潔性、暗示性,以及情感與自然世界的明確連接。*洛威爾力圖在她的改編詩歌中“保持発句的簡潔與暗示,并將它維持在自然的空間中”(引自JT, p. 165)。弗萊徹欣賞俳句對“源自自然事物的普世情感”的運用,以及它“用最少的詞語”來表達這種情感”(引自JT, p. 177)。事實上,暗示性已成為批評話語中的支柱,以至于到了1913年,日本詩人野口米次郎(Yone Noguchi)(他也是所有這些議論的關鍵貢獻者)宣稱:“沒有哪一個詞像暗示性那樣被西方批評者們這樣泛濫地使用,它造成的損害大于啟迪。”*Yone Noguchi, “What is a Hokku Poem?” in Rhythm 2, Jan.1913, p. 355.然而野口在把“內在廣闊而外在模糊”的俳句語言比作“沾滿夏日露水的蛛絲,像空氣中的隱形幽靈一般在樹枝間搖擺,保持著完美平衡”*Noguchi, The Spirit of Japanese Poetry, London, 1914, pp. 42-43、p. 51. 關于野口對龐德等早期接受者的影響,參見Edward Marx, “A Slightly Open Door: Yone Noguchi and the Invention of English Haiku,” in Genre 39 (Fall 2006), pp. 107-26.時,同樣渲染了這一批評話語中的東方主義意味。
雖然表面上對俳句的新穎之處已有共識,但學者們也展示了龐德、威廉斯、野口以及其他詩人在俳句的運用上如何各具不同。不過正如上文指出的,這些學者同樣堅持認為俳句有一套吸引詩人們的共同特征:“[俳句的]短小與簡練:它的直接性,它的呈現模式,它的暗示,以及它對并置的具體細節的運用。”*Johnson, Haiku Poetics in Twentieth Century Avant-Garde Poetry, p. 45.正是這些前后銜接的觀點推動俳句進入了第三個接受的階段:模仿的狂潮繞之興起,超出了原先意象主義詩人及其友人的小圈子。這一最為平民化的階段可由改編詩作的數量上升、俳句在詩歌領域的更廣泛分布和當時的批評評論所印證。實際上,這后一點暗示了俳句到1920年已達到了一個飽和點。此時俳句無處不在。在某些人看來,這一現象值得慶祝,因為它顯示了東西方藝術“出人意料的緊密修好”,以及日本詩歌和美國詩歌前所未有的根本性融合。*Royall Snow, “Marriage with the East,” in The New Republic, 29 (June 1921), p.138. 另參閱Torao Taketomo, “American Imitations of Japanese Poetry,” in The Nation, 17 Jan. 1920, p. 70.但在其他人看來,現在有理由對這場狂熱叫停了。一位研究洛威爾和其他“用英語寫発句(hokku)”的詩人的評論家把俳句貶斥為一個“遠遠被高估的形式,它只適合于傳達情感的最微小面相”*Marjorie Allen Seiffert, “The Floating World,” review of Pictures of the Floating World by Amy Lowell, in Poetry 15 (Mar. 1920), p. 334.。哈佛的一位學者雖承認発句的“靈敏和精確”是“詩歌珍貴價值的重要部分”,但也將它視為詩歌形式由長到短的普遍消極轉向的癥候。“人們對某些人稱為‘水洼中的星星的迷你素描’會很快感到厭倦。”*John Livingston Lowes, Convention and Revolt in Poetry, Boston, 1919, p. 166、p. 309.中西部諷刺雜志《塞壬》則更不友善地戲仿起発句與高眉藝術的關聯,并以如下“五七五”形式的嘲諷副歌結尾:“你覺得発句這玩意兒里有什么名堂嗎?/我也覺不出來。”*“Hoch der Hokku!” in Siren (Sept.1921), p. 10.英語俳句終于真正到來了。
隨著英語俳句的到來而出現的大批改編詩作,對我們來說比意象主義者的詩歌要更陌生。據邁納的說法,這些詩作給讀者呈現了一個“由混雜的形式、無意義的技巧模仿和異域風情組成的雜亂叢林”(JT, p. 184)。不過,不論在個體詩歌層面擴散得多廣,在將俳句當作批評話語的研究對象方面則一直保持著令人吃驚的連貫性。日本批評家武友寅夫(Taketomo Torao)聲稱“発句的詩學優點……完全取決于暗示性的力量”,并認為美國的俳句詩人“傾向于使用最少的詞,偏好運用意象與象征而非解釋來展示事物的本來面目”*Taketomo, “American Imitations of Japanese Poetry,” p. 71.。羅亞爾·斯諾(Royall Snow)在為《新共和》撰文時則更進一步聲稱俳句讓“西方人的心靈”如此著迷的原因,在于“它能夠在有限空間內創造出來的效果”。他指出“亞洲詩歌”兩個最主要且有影響力的特征是“集中,還有和它的客觀性神秘相連的暗示性特征”;斯諾只需援引意象主義者們自己的宣告,即可認定這些特征與俳句具有如此根本的他異性和如此明確的東方感的原因是何等緊密相關。*Snow, “Marriage with the East,” p.138. 斯諾援引了龐德914年的一篇文章,其中寫道,“我們在接下來的世紀里躲不開……東方思想的強烈敏銳感和凝練的東方文學形式給我們的既定標準造成的越來越大的改變。”艾米·洛威爾也被提及,特別是她這句“暗示是我們從東方學到的重要的東西之一”(p. 138)。正是這類關于俳句美學影響的概括性說法決定了俳句接受第三階段的批評話語。*杰伊·哈貝爾和約翰·比蒂將俳句視為“亞洲詩歌對當代詩歌產生的巨大且還在日益增大的影響”的一部分,“[這一影響]帶來了更大的簡潔性和潤色度”(Jay Hubbell and John O. Beaty, An Introduction to Poetry, New York,1922, p. 360).然而,伴隨這些說法而來的是一個客體化模式,它像前期階段一樣,忽略俳句的具體細節而去關注一套與明顯東方主義話語相結合的模糊的美學理想。這一模式在一篇關于野口詩歌的評論文章中被最為簡明地體現出來,該文評論道:“這首詩以発句形式寫成,三行詩里包含十七個音節。但形式并不構成発句。一些最優秀的発句并不以該形式寫成。那種決定発句本質的、精細而夢幻般的情感足以啟示宇宙的無限,它藏在哪兒呢?”*Jun Fujita, “A Japanese Cosmopolite,” review of Seen and Unseen: Or Monologues of a Hmeless Snail and Selected Poems of Yone Noguchi by Noguchi, Poetry 20, June 1922, p. 164.
在把俳句文本視為社會歷史事物來研究時,我們發現一般體認的俳句本質特點——簡短、暗示性和自然意象——不斷被眾多評論者積極肯定。現在,我們可以把這些特點視為觀察判斷的歷史積累的一部分。不過我們也可以將其視為一套更廣闊的、如今被簡單稱為東方主義的政治文化形態的一部分。如果說有關俳句的話語和創作嘗試在其第三階段在美國社會中逐漸形成了一個廣為流行的模式,那么應該說這一模式是源自美國在眾多領域對東亞進行異域化處理這一更大的模式中。最后,此處的簡史還揭示出一些對俳句的流行與繁盛十分關鍵的重要的社會偶然性。弗林特需與龐德交流,龐德又需與野口交流才使得他對俳句產生興趣,接著龐德又使其他人也產生了興趣。與貨幣類似,俳句在詩人、編輯和讀者組成的社會物質網絡中流通,而其中的許多人對俳句價值何在的問題抱著同一套優先考慮因素和同樣的認識。這些力量——既有美國東方主義又有藝術網絡——結合起來,將俳句文本的現實標記為一個社會歷史事件,它反映并也激活了藝術家群體中更廣闊的文化話語與社會行為模式。
不過,我們在試圖辨明這些模式時又留下了一些新的問題。尤其是:這些模式與它們表面上幫助生成的“混雜形式的叢林”有什么樣的關系?如果將俳句文本視為更廣闊的社會活動的一部分,那么在文本自身的層面又發生了什么?這些俳句文本經過從外國譯作到先鋒試驗作品到親民流行形式的轉變,它們是否體現出相似性?這里歷史文化的研究方法就沒有多少用處了,因為它只能說明我們之所以能提出這些問題的背景。而文本細讀,就其獨重個體文本的“活生生的獨一性”而言,也無法滿足需求。我們希望找到一種比文化歷史批評更精細、但又開闊到能考慮一個比文本細讀所提供的文本模式定義更寬松的閱讀模型——一個不把文本當作個體美學效應的紐帶或者社會話語的產物,而是將其視為上百個例子共同分享的一套種屬特征。我們需要一個新的關于英語俳句的本體觀,以幫助我們將俳句視為大于某種意象類型和含蓄語言的編排、又小于松散連系在東方主義概念中的雜亂模仿性形式的東西。簡潔與暗示性或許是比嚴格的形式模仿更微妙、同時又比印象主義的美學直覺更具體的文本模式帶來的效果。
作為統計模式的英語俳句
自上世紀90年代初,機器學習以及它在文本自動分類中的應用成為發現大量文本中的模式的一個流行方法。機器學習是指一套完整的統計算法,它們把每個文本視為一個特定的可量化特征的混合體,并認為這些特征跨文本分布的方式有助于識別文本之間的差異。這些統計算法試圖“學習”這些特征,以便就某文本可能所屬的類別或組群進行分類或預測。舉例說明,這樣的算法可以根據它們學到的與每個類型的信息相關聯的特征,來幫助決定一封電子郵件是否有可能是垃圾郵件。*這種篩選是機器學習自上世紀90年代初崛起后最常見的用途之一。它比舊的文本分類方法更為有效和高效,因為舊的分類方法要依靠人類專家以人力來設定與他們分析的任何文本都密切聯系的分類規則。隨著機器學習的發展,專家們可以放手讓機器來推導出規則,他們則把關注點集中在識別類別本身。法布瑞爾·塞巴斯蒂阿尼(Fabrizio Sebastiani)在《文本自動分類中的機器學習》一文里全面介紹了信息系統領域內機器學習的歷史。見“Machine Learning in Automated Text Categorization,”in ACM Computing Surveys 34 (Mar. 2002), pp.1-47.在文學研究中,使用機器學習來完成類似的對文學或其他美學文本的信息篩選已有十年的歷史。學者們試圖用這種方法在戲劇敘事結構、政治隱喻、劇場對話以及小說體裁中識別諸如詞匯的、語義的或其他文本差異上的模式。*參見Stephen Ramsay, “In Praise of Pattern,”in TEXT Technology 14, No. 2 (2005), pp. 177-90; Bradley Pasanek and D. Sculley, “Meaning and Mining:The Impact of Implicit Assumptions in Data Mining for the Humanities,” in Literary and Linguistic Computing 23 (Dec.2008),pp.409-24;Shlomo Argamon et al., “Gender, Race, and Nationality in Black Drama, 1950-2006: Mining Differences in Language Use in Authors and Their Characters,” in Digital Humanities Quarterly 3,No. 2 (2009); Matthew Jockers, Macroanalysis:Digital Methods and Literary History, Urbana, Ill., 2013, chap.6.近來,機器學習已經在高度復雜的分類任務,如小說體裁檢測和人物類型識別中發揮了不可或缺的作用。*Ted Underwood, et al., “Mapping Mutable Genres in Structurally Complex Volumes,”該文是2013年“IEEE大數據國際會議”發言論文(未發表)Santa Clara, Calif., 6-9 Oct. 2013; David Bamman, Underwood &Noah Smith, “A Bayesian Mixed Effects Model of Literary Character,”該文是第52屆計算機語言學年會提交論文,Baltimore, 22-27 June 2014,
機器學習作為一種方法由四項關鍵任務構成,每項任務都促使俳句以迥異于其他閱讀方式的文本對象而存在。這些任務是分類(categorization)、表示(representation)、學習(learning)和歸類(classification)。“分類”指按照文本所歸屬的系列類別或綱目來給它們分配標簽。“表示”指分離出文本的各具體特征,并采取機器學習算法可以解釋的方式來量化這些特征。緊隨其后的是“學習”,此處機器需要把關聯著每個文本的各種特征提取出來,并評估它們使該文本屬于它被分配的類別的區分程度。最后一步是“歸類”的任務,即運用學習階段獲得的信息,僅依靠某一文本的特征(也就是說,標簽是未知的)來預測它的類別。接下來,我們將循序經歷這些任務,并突出每一個階段中的闡釋決策以及這些決策是如何最終塑造了過程中出現的俳句文本本體觀。
“分類”是根據不同的類別來為文本設定標簽的看似簡單的行為。這些類別在最常見的情況下都是二元制的(如垃圾郵件和非垃圾郵件),但也可以是多元的。*對多類型文本分類的解釋與示范,參見Jockers, Macroanalysis, chap. 6.更重要的是,類別“不能被確鑿無疑地決定”, 它們取決于“專家的主觀判斷”,是專家在閱讀一批文獻后根據他/她所感興趣的特質而進行的分類。*Sebastiani, “Machine Learning in Automated Text Categorization,” p. 3.這就叫機器學習的“監督學習方法”*與之相對,“無監督方法”允許機器首先根據某些特定的特點決定文件可以如何聚集;這些聚類是否能與有意義的類型相對應則留待使用者決定。對此較有幫助的解釋見Jockers, Macroanalysis, pp.70-71.。這一步雖然聽起來簡單,但它從根本上決定了分析的結果,并且要求一套內在不同的文本需要在表面上被歸檔到有限數量的類別中去。對我們來說,這意味著要找到一大批符合20世紀初對英語俳句的期待的詩歌,以及一大批不符合期待的詩歌。在分別標記它們為“俳句”和“非俳句”后,我們就可以將兩類文本進行對照劃分。不過,這并不是要強化我們最初所做的區分,而是要檢驗它的界限,并確定什么樣的文本模式才是每一組文本所特有的。也就是說,我們想要知道機器能否識別出俳句和非俳句文本,如果可以識別,它又是用什么樣的統計證據來得出結論的。
為了確定我們的兩個語料庫,我們首先使用原始檔案和次級資源來尋找符合以下基本條件的俳句詩歌:它們必須是來自發現階段的重要學術文獻中的譯作;或者在標題中指認自身為俳句;又或者是由詩人或評論家明確認定受到日本短詩形式的影響。這樣就產生了一個包含400個文本的語料庫;我們又將其分為兩個類別,即翻譯作品和改編作品。翻譯作品代表了最初被英美讀者所接受的、更緊密地遵循“五七五”格律這樣嚴格形式限制的經典俳句。改編作品則代表了一組更為多樣化的詩歌,它們雖偏離了這一形式慣例,但至少詩人和批評家們認為它們在內容或審美意向的層面仍遵從俳句。這其中包括了對日本短歌(tanka)的明確改編作品——短歌是一個由31個音節組成的形式,批評家經常把它與俳句放在一起,作為日本短詩這一更普遍的類型的一部分(見圖2)。*在日本,俳句和短歌天然與截然不同的審美取向、藝術譜系以及風格和社會標記相連。傳統上俳句專門描述自然世界或給出哲學與社會方面的評論;短歌則與情緒和感情表達相關。不過這些精細的區別通常被美國的詩人和評論家忽視,結果二者往往被混在一起,都作為一個單一的日本詩歌傳統的一部分。圖示中上世紀頭十年末期和20年代早期出現的高峰段包括了洛威爾、弗萊徹、野口等人受俳句啟發而創作的大批詩歌,以及一批與意象派無關的大小詩人的翻譯和改編作品。
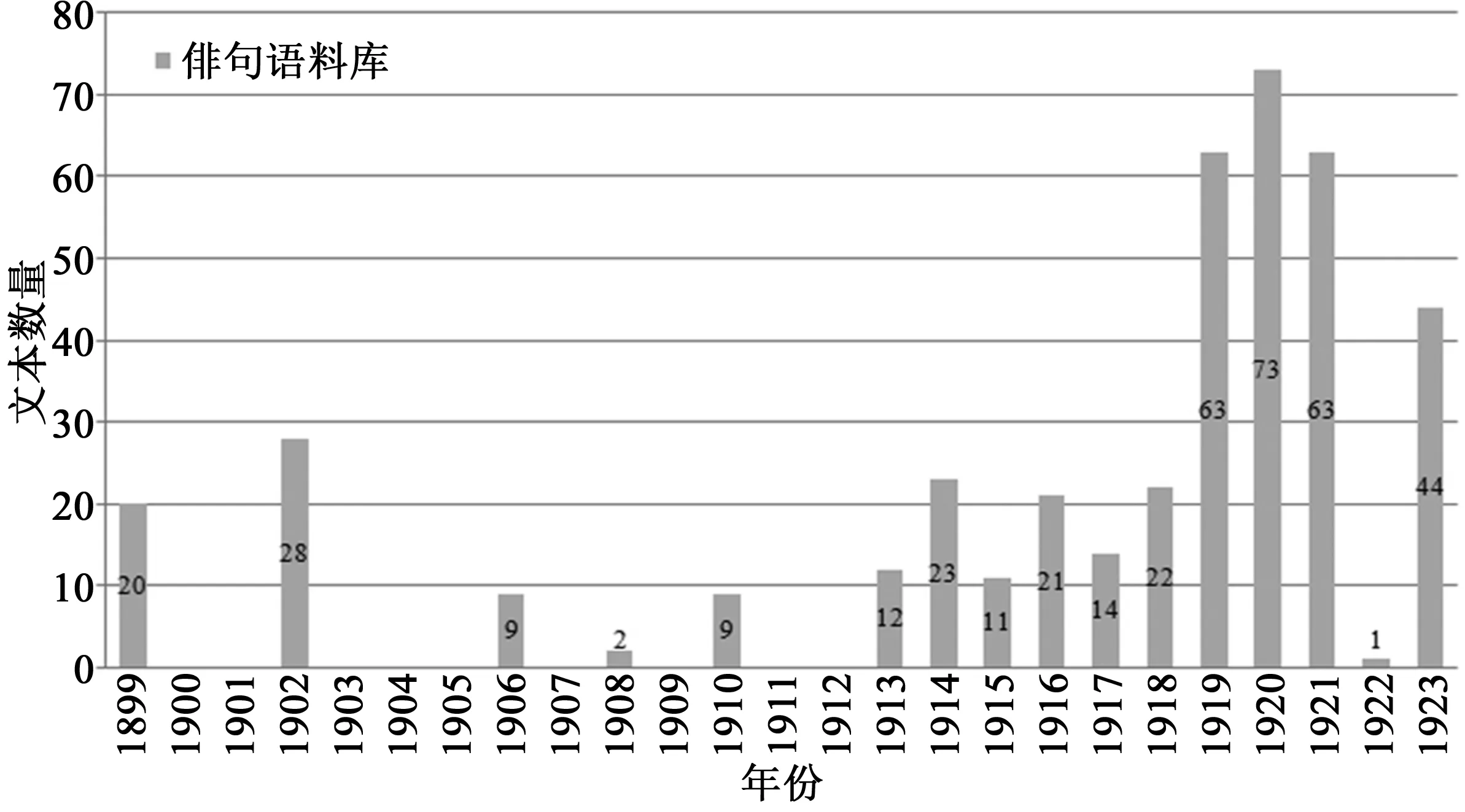
圖2 所選俳句文本隨時間的分布圖
為了搜集一個非俳句語料庫,我們需要找到一大批不屬于英語俳句運動、卻又有可能從中發現該運動痕跡的詩歌。因此,我們在俳句接受第二階段和第三階段的詩集和其他重要雜志中收集了1900多首短詩;這些雜志包括諸如《詩歌雜志》、《小評論》和《他者們》之類的小雜志,諸如《哈潑斯雜志》、《Scribner出版社雜志》和《國家》這樣的綜合刊物,包括《危機報》和《機遇報》在內的哈萊姆文藝復興的關鍵期刊,以及像俄亥俄州的《中部地區》和加利福尼亞的《抒情西部》這樣的地區雜志(見圖3)。*這些詩歌是從哈蒂信托基金數字圖書館(Hathi Trust Digital Library)和現代期刊項目中收集來的。由于這些資料集僅限于公共領域的作品,我們只能收集在時間限制上早于1923發表的詩歌。對于哈萊姆文藝復興的期刊,我們是根據原版的內容手動輸入詩歌。這里的“短”是指長度低于300個單詞的任何文字,略高于我們語料庫中俳句的平均長度。我們要嘗試對照著這些屬于其他文本類別的詩歌來分析兩組俳句之間的界限。

圖3 從當代雜志匯編的短詩語料庫列表。這些短詩來自大約11,000首在給定的日期中從表中出處發表的詩
接下來,我們必須確定這些文本的“表示”(representation),以便它們可以被歸類算法讀取和解釋。在這一步驟中,文本的本體觀真正變為機器自身所有。由于歸類依賴于文本的統一索引,所以這些文本必須被看作某(幾)種較小單元(單詞、短語、話語片段)的集合體。文本一旦被選中,便被分解成這些單元的簡單列表,以顯示單元的存在與否或相對頻率(即某一單元在文本中是否出現或出現的次數)。每個單元都被看作是其所在文本的一個“特征”(feature)——一種辨識特點——而該文本則成為這些特點的向量(vector)。但是機器“表示”往往不考慮這些個體單元的結合規律,這也佐證了賈斯丁·格里默爾(Justin Grimmer)和布蘭登·斯圖爾特(Brandon steward)的觀察:“自動化的內容分析方法使用有見地的,但卻是錯誤的……文本模型,來幫助研究者從他們的數據中做推論”*Justin Grimmer and Brandon Stewart, “Text as Data: The Promise and Pitfalls of Automated Content Analysis Methods for Political Texts,” in Political Analysis 21 (Summer 2013), p. 270.。“錯誤”是因為它們沒有抓住文本如何通過語言而產生的復雜過程,但“有見地”是因為這些“不正確”的模型可以在大量豐富的數據庫之間探測出文本單元的模式。
機器學習中一個最常見、也最簡單的表示法就是“詞包”(bag-of-words)模型,它將文本視為包含于其內的單詞的集合。我們就以這一模型入手。上圖顯示了單獨一首俳句被轉化成詞包表示時的樣子(見圖4)。當然,這一“表示”還可以進一步細化,這取決于我們決定由什么來構成一個有意義的區分特征。結果表明并不是每一個詞對檢測我們所感興趣的語義模式都是有用的。由此,我們刪除了譬如語法功能詞(或停頓詞),因為這些詞不適用于區分內容層面上的模式。我們也沒有記錄詩歌中單詞的出現頻率,因為這對于小詞匯量的語料庫來說效果不大。*在一個二元制詞包方法中,單詞由它的存在或缺席來表示;關于它的優點,參見Pasanek and Sculley, “Meaning and Mining,” p. 413; 以及Bei Yu, “An Evaluation of Text Classification Methods for Literary Study,” in Literary and Linguistic Computing 23 (Sept. 2008), pp. 329-30. 二人都探討了何時應該包括功能詞的問題。功能詞可能有助于識別作者風格。另見Jockers, Macroanalysis, p. 64. 我們也沒有考慮字母大寫,并且去除了所有標點符號,僅保留俳句文本中經常出現的感嘆號和長破折號。此外,我們把所有的名詞按屈折變化進行合并,像“群山”和“山”這樣的詞被看作是同一個單元,又排除了在受分析文本中只出現一次的單詞。*后一種任務通常被稱為特征選擇(feature selection),它有助于減少由大量的低頻特征產生的統計噪音。我們還可以略去在兩種文本類別中都多次出現的詞,這樣也可以減少其他方向上的特征。最后,除詞匯層面的特征外,我們還可以把更復雜的形式特征囊括進表示中,簡單記錄這些特征在文本中存在還是不存在。考慮到在俳句早期接受中音節數對認知俳句的重要性,我們把音節數這個特征也包括了進去。*詩歌的音節數取自用戶輸入并參照卡耐基梅隆大學(CMU)美式英語發音詞典。隨后,我們查看了翻譯和改編兩種俳句語料庫音節數的分布,并使用該結果來創建截點。這樣在翻譯作品中我們使用18個音節作為閾值,每個文本被表示為或多于或少于這個數量。得出的結果是出現在圖4底部的文字:一個被標記的特征向量,現在它就是所有文本的模板。現在,我們作出的關于如何“表示”這兩類詩的選擇使我們能夠去測試這樣一個假設,即俳句可以通過共有的措詞和音節數模式來區別于非俳句。

圖4 單一俳句文本的機器解讀的“表示”。注意在最后的“表示”中,每個特征被分配到“True”這一參數值(value),表示它在原文本中的存在。“haiku”(俳句)則是分配給該特征向量的標簽
要做到這一點,接下來我們就要選定一個歸類算法(也叫學習方法),它會根據向量的各特征對辨別向量標簽(俳句或非俳句)的影響大小來對它們進行衡量。有許多種這樣算法可以執行該任務,但是每個算法對于“影響”的理解各不相同,也往往不可通約。一些算法將特征看作高維直角坐標空間的坐標,并嘗試畫出一條線來將某一類別的獨特特征最好地與另一類別的特征劃分開來。另一些算法則采取符號化的、非數字化的方法,將某一特征的出現或缺席看作是一套邏輯關聯結果(即這個特征的出現是由先于它出現的其他特征所造成的)。還有其他算法認為有一個概率的過程來驅動這些特征的出現,并試圖確定某特征與某一特定類別相關聯的可能性。*該觀點見Pasanek and Sculley, “Meaning and Mining,” p. 412. 第一組方法包括支持向量機(SVM)和邏輯回歸等基于線性的模型;第二組方法包括樸素貝葉斯算法和隱馬爾科夫模型;最后一組方法包括決策樹分類器。對上述所有方法的詳細描述,參見Sebastiani, “Machine Learning in Automated Text Categorization.”
樸素貝葉斯分類器(the Na?ve Bayes classifier)是最后一組算法廣泛使用的基準方法,也是我們要使用的方法。在給定一個俳句和非俳句向量的隨機樣本后,分類器就對其中的一個部分(訓練集)進行訓練,并學習兩個類別間特征的分布情況。隨后,它會給每個特征分配一個概率評分,以顯示該特征分別屬于兩種類別的概率大小(見圖5)。一旦訓練完成,分類器就利用計算出的概率評分對樣本中的其余向量(測試集)進行分析,試圖根據它所看到的特征對每一個向量所屬的類別進行預測。亦即,它得出每個特征屬于俳句或非俳句的概率大小后,將這些概率分別按這兩個類別相加,并根據哪一參數值更高來預測向量的類別。*對該分類器更全面的介紹,參見Grimmer and Stewart, “Text as Data,” p. 11. 它的“樸素”特征與其核心統計學假設有關,即在一個特定類別的文本中,各單詞都是相互獨立地生成的。這顯然是錯誤的,因為在一組類似的文本中,單詞的使用通常高度相關。但是,在某些種類的文本歸類中,這種簡單的方法仍然被證明是非常有效的。根據樸素貝葉斯算法,一個“文本”是否是俳句只需看它分析出的特征有多大可能是屬于某一類文本而不是另一類。這些特征對于每個類別越是特有的,就越容易作出判斷。雖然有文學學者指出貝葉斯分類器不適用于在美學文本間作出某些區分,但它卻擅長識別那些獨特的、頻率較低的特征(和單詞),這些特征(和單詞)又標記了類別間的差異。*參見Yu, “An Evaluation of Text Classification Methods for Literary Study,” p. 336. 在利用機器學習分析文學文本時,樸素貝葉斯算法經常被拿來與支持向量機(SVM)相對比。參見Argamon et al., “Gender, Race, and Nationality in Black Drama, 1950-2006”; Pasanek and Sculley, “Meaning and Mining”; Yu, “An Evaluation of Text Classification Methods for Literary Study.” 支持向量機往往分離出較高頻次的單詞隔離,將其作為有影響力的特征。這些長處使貝葉斯分類器在我們探索某些初始問題的時候特別有用,如翻譯和改編的俳句作品與這個期間的其他短詩有何不同、能否在其他這些詩歌中也檢測到體現在措詞和音節數上的“俳句性”模式等。

圖5 從單個歸類測試中產生的概率列表樣本。在這個例子中,單詞“天空”(sky)與非俳句(not-ha)相連的概率與是與俳句(haiku)相連的5.7倍。相反,單詞“雪”(snow)與俳句相連的概率是與非俳句相連的3.7倍
帶著這些問題,我們把俳句的翻譯和改編作品分別與來自每一種(或一套)期刊的短詩進行對比歸類。同時我們還包括進一個控制案例,以便驗證樸素貝葉斯算法能識別出我們已知的文本差異。該控制組由長度為300單詞的片段組成。這些片段取自卡爾·桑德堡(Carl Sandburg)的詩,他早期的自由體詩歌描繪了芝加哥和周邊城鎮粗糲的街景以及居住在那里的人,包括工人階級的勞動者、腐敗的政治家、貧窮的移民和妓女。與來自詩歌刊物里的短詩不同,我們事先已經知道桑德堡的這些詩歌表現出的措詞和音節數模式完全不同于俳句。*所有詩歌片段都均取自Carl Sandburg, Chicago Poems, New York, 1916. 我們只選取那些明確表現城市主題或描寫城市居民的詩歌。我們從兩類文本中抽出相同大小的樣品并分為訓練集和測試集,并為每個歸類測試(俳句譯作與《詩歌雜志》作品對比、俳句譯作與桑德堡作品對比等等)進行了100次測試。這一過程被稱為交叉驗證,是為確保得出的結果不偏向某一小個文本子集的特征。*具體說來,我們執行了四重交叉驗證,使用四分之三的組合樣本作為訓練數據,其余四分之一作為測試數據。最后,我們從這些測試中計算出平均準確度得分, 該分數顯示了機器按文本標簽將文本正確歸類的次數比例(見圖6)。
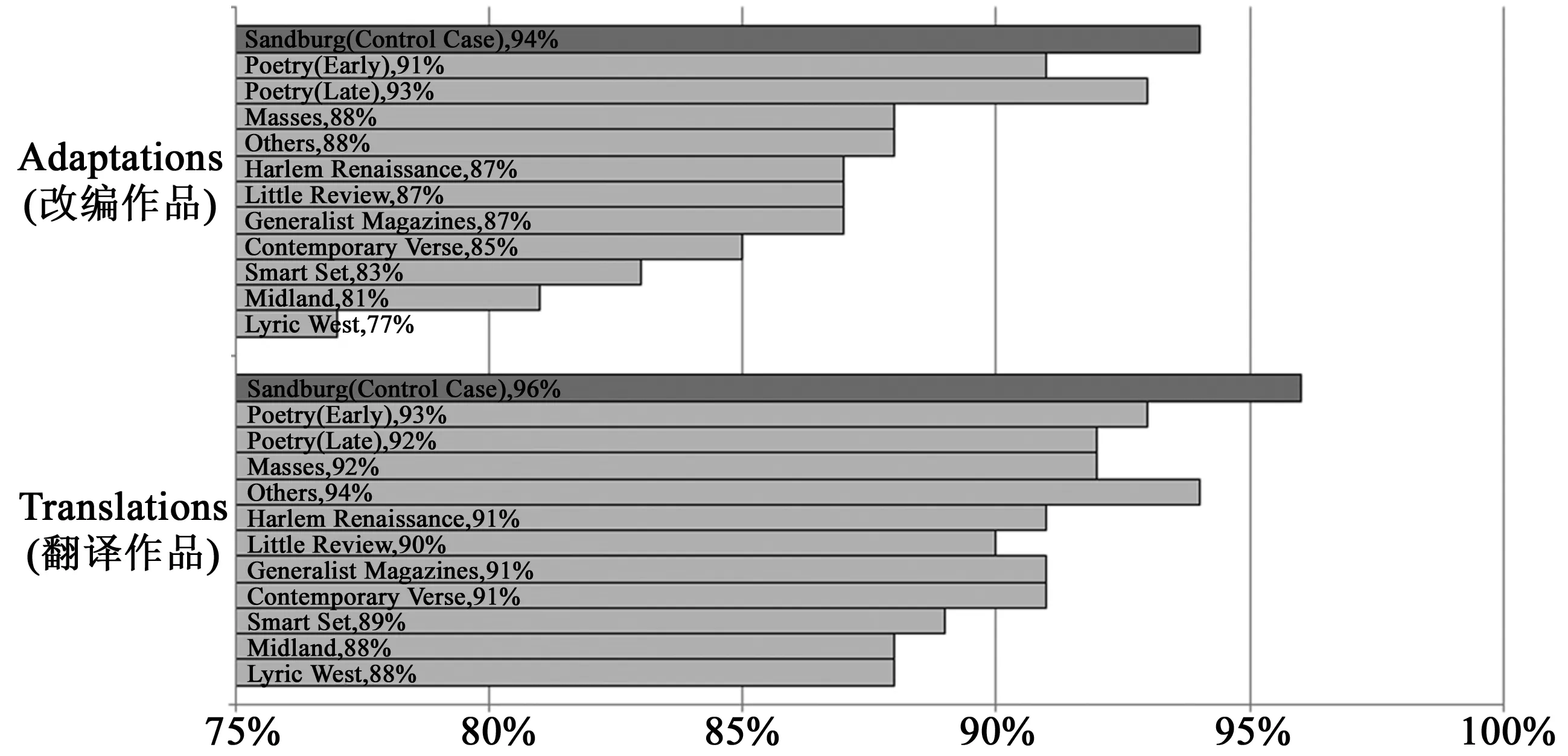
圖6 一百次歸類測試后得出的平均準確度分數。圖表上半部分是對俳句改編作品與各短詩語料庫對比的歸類得分。下半部分是對俳句翻譯作品的歸類得分
這些準確度分數表明,樸素貝葉斯算法能夠特別精確地從各種短詩語料庫中區分出俳句來。平均而言,它猜對俳句翻譯作品的概率是91%,猜對俳句改編作品的概率是86%。與預期相同,桑德堡的詩歌在這兩種情況下都是最容易區分的。*所有這些準確度得分基于對每組歸類做的隨機測試,具有高度統計學意義。得分范圍在54%到64%之間,而這種測試的理想分數是50%,這意味著該機器正確猜測的能力與拋硬幣決定相差無幾。翻譯作品的得分稍高,這證明了它們作為一個依賴于更受限的詞匯量的類別,具有自身的特殊性。相比之下,改編作品的準確度得分稍低則暗示了其特征所具有的多樣性。由于這些分數可以反映出不同的潛在結果,所以有必要看看發生分類錯誤的地方。對于一些期刊,尤其是《詩歌》和哈萊姆文藝復興的雜志,分類器不能準確識別非俳句文本,出現了更多把它們誤判為俳句的情況。也就是說,它在更多的這些短詩中發現了與俳句相關聯的特征。對于其他的期刊,尤其是圖中那些頻譜低下的,分類器識別俳句的能力不敏感,把更多的俳句誤判為非俳句。這可能意味著俳句的特征具有更小的內部統一性,或某些常見于兩個類別的特征,如“春天”(spring)、“寒冷”(cold)這些通用詞,使分類器偏向了某一類別。*在機器學習中,“查準率”(precision)衡量的是分類器的準確度,并顯示分類器正確分辨給定文本所屬類別的頻度。高查準率意味著在某個文本類別中發現了高度獨特的特征。“查全率”(recall)衡量的是分類器的全面性或敏感性,并顯示分類器猜對某一特定類型的文本的數量。低查全率意味著該類別的文本更經常地省略能辨識其所屬類型的特征。因此,舉例說明,如果“春天”出現在非俳句文本中的次數要多得多(這增加了它與這個類別的可能聯系),當被發現在俳句中的時候,它對分類器決策的影響就可能要高過其他的詞。
這類歸類錯誤揭示出樸素貝葉斯預測文本類別時所做的假設。特別是:文本的類別是由在每個類中按特定比例使用的特征所組成的,這個比例決定了某一特征與該文本的類別相關聯的可能性大小。在分析兩種具有非常獨特特征的類別、且這些特征在每個類別中的分布差異鮮明時,這個假設是有用的。但是,如果類別之間重疊得越多,或類別表現出的內部差異越大,該假設就可能導致問題。就是說,如果要斷言兩個類別間的絕對類別差異,可能會有問題。但如果是要像我們這樣尋找重疊點與融合點,那么這些問題實際上是長處。事實上,我們希望看到更多類似的問題。若把音節數和僅僅出現最頻繁的單詞算入考慮范圍,這樣得出的文本差異模型就太過死板,遮蔽了有些詩人不考慮音節數、或某些低頻詞與“春天”和“冷”這些詞結合起來表現俳句美學(或更廣泛的東方主義美學)的情況。要揭示這些潛在的重疊的情況,我們需要一個更為靈活的方式來表示文本。
因此,我們在不使用音節數作為特征的前提下重做了一遍測試,這一次還包括了除功能詞外的所有單詞(見圖7)。我們發現機器的準確度得分大幅下降,翻譯作品的準確度平均為73%,改編作品為65%。控制案例的得分雖然相比之下仍是高的,不過就連它也有明顯下跌,降至82%。一些期刊比其他期刊的獨特性稍高,例如《詩歌》《他者們》以及《小評論》,但總體來說對文本可兼性更高的表示顯示出極多的重疊。但是,與早先的測試一樣,如果不分析錯誤發生在什么地方,準確度得分會帶來誤導。分析結果發現,對許多期刊來說,分數下降的很大一部分原因是分類器把更多的短詩誤歸類為俳句了。*某些期刊出現了相反的情況,即準確率下降是由于更多的俳句被誤判為非俳句了。雖然對這些錯誤的分析不在本文范疇內,但是我們需要注意到,這些結果告訴我們一些關于這些期刊短詩的創作的重要信息。完全基于這些詩的發表出處,我們暫且把它們視為不同于俳句的一個統一類別,盡管事實上這些詩以各自獨特的方式具有內在多樣性。通過擴展樸素貝葉斯用以辨識文本模式的特征集,我們得到了更多的歸類錯誤,也因此得到了更多有關俳句和非俳句語料庫重疊之處的證據。如果說以更為寬松的方式表示語料庫間的區別會讓機器產生混亂,它也為觀察機器概率邏輯下的文本模式創造了更多的機會。
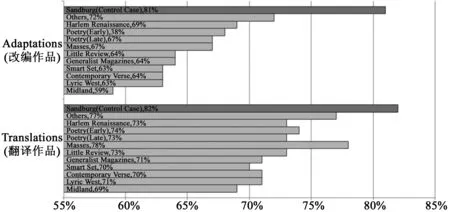
圖7 使用定義更寬松的特征組進行100次歸類測試得出的平均準確率
東方主義氛圍
聽起來或許有些矛盾:通過迷惑機器,我們可以更好地評估它是如何作出決定的。這其中的含義在我們分析迷惑機器所導致的某些結果時,會變得更加清晰。首先,簡要回顧一下機器學習告訴我們的關于英語俳句的知識會有所幫助。對樸素貝葉斯分類器而言,俳句文本只是一些特征的組合,這些特征通常在某類文本中比在其他文本中出現得更多。如果一首詩包含了更多與分派為俳句的詩歌相關聯的特征,如包含“雪”(snow)或“寒冷”(cold)等詞,它就更可能被辨認為俳句,反之亦然。在我們的初步測試中,樸素貝葉斯很擅長以強化我們自己標記俳句或非俳句的方式來進行辨認。測試確認了俳句在措詞和韻律上與同時期的其他短詩不同。機器學習告訴我們的本質上就是,在把英語俳句中出現的特征視為一個整體時,這些特征就組成了一個統計模式,它與流行于其他短詩中的統計模式區別開來,這一區別具有重要的意義。
不過,能否作出這樣清晰的區別,最終取決于我們指示樸素貝葉斯考察什么樣的具體特征。樸素貝葉斯之所以表現出色,是因為我們只選擇最有可能把俳句從其他文本中區分出來的特征放入我們對文本的表示中。根據機器學習的傳統目標,這是一個完全合理的手段。在人們試圖從私人電郵帳戶中過濾垃圾郵件這樣的例子中,更高的準確率是受期待的。如果一個機器學習算法老是把朋友的信息誤判為垃圾郵件,數據科學家就會把這種情況看作是個錯誤,并且尋找方法來改進他/她的模型,以提高該算法的準確率。但是對于我們來說,錯誤卻引發了一個闡釋性的問題:是什么讓朋友的郵件這么像垃圾郵件?如果我們不是去糾正錯誤,而是思考該錯誤如何挑戰了植入程序中的初始類型區別呢?或者更好的選擇是,如果我們嘗試去制造類似的錯誤來模糊這種區別呢?這就是我們擴大樸素貝葉斯用以從非俳句中辨識出俳句的特征集的目的。正是通過放松對英語俳句這一統計模式的限定,我們擴大了該算法發現具有俳句風格的詩歌的能力。
如此一來,被文學機器學習視為歸類錯誤的地方,我們卻將其視為闡釋的契機。在這最后一部分中,我們就以兩種辦法進行闡釋。首先,每首被錯誤歸類的俳句(標簽為非俳句、卻被分辨為可能是俳句的文本)對我們來說都是一個了解機器如何閱讀文本模式的窗口。它促使我們思考機器在該詩中發現了什么更能表示俳句而不是非俳句的特征,該特征是否又在多例錯誤中出現。通過重視俳句作為統計模式的觀念,這些被誤判的文本證明了俳句在現代主義內的影響分布得多么廣泛,也證明了俳句在構成更廣泛的美國東方主義氛圍中的重要角色。不過,它們能作為證據的原因并不僅僅基于機器的本體觀,而是因為這些誤判的俳句為考察機器識別出的模式如何跟文本細讀和文化歷史識別出的模式相協調提供了二次機會。這些誤判不僅使我們得以解釋機器如何理解模式,還提示我們分析如何把機器的理解與人類閱讀模式中所固有的理解進行對比。其結果就是一種新的文學模式識別方法,它因為包含闡釋的多種本體視野間的匯聚點而格外充實。
在我們進行的幾百個歸類測試中,有585首短詩(來自總計大約1900首詩)被誤判為俳句,其中一些測試的歸類錯誤比別的測試要多得多。*相比之下,當我們采用更精確的俳句模型時,僅出現45首分類錯誤的詩歌。在這個組群中,一首詩被誤判的平均次數為6次。如果僅考慮達到或超過這一閾值的詩歌,我們就會有202首額外的俳句添加到我們的語料庫中(見圖8)。這是一批相當可觀的新材料,可以用于重新想象英語俳句的歷史;但遺留的問題是這些新材料如何(或是否)應包含進俳句的歷史中。我們可以簡單地接受機器的判斷,但一個更能產生批評成果的方法,則是去調查機器識別的模式與人類識別的模式在何處相交或不相交。
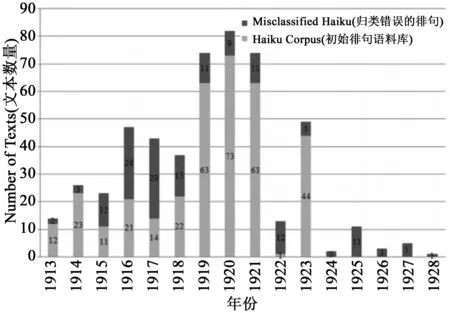
圖8 歸類錯誤的俳句分布與初始俳句語料庫分布的對照圖大部分詩歌發表于1916至1918年間,1922之后的詩來自哈萊姆文藝復興期刊
這些誤判的文本分為三組。第一組我們稱為候補俳句。其中不但包括龐德和理查德·奧爾丁頓(Richard Aldington)等著名俳句承襲者的詩歌,還包括了通常不與意象派相聯系的人物,如路易絲·布萊恩特(Louise Bryant)、伊麗莎白·科茨沃斯(Elizabeth Coatsworth)和哈萊姆文藝復興詩人劉易斯·亞力山大(Lewis Alexander)等人的作品。這些詩之所以是候補俳句,是因為從文本細讀和文化史的角度來看,它們和被納入俳句語料庫的詩歌之間具有相似性。這些詩雖是被機器發現的,但若用更傳統的方式,它們也會很容易地被認定為英語俳句。一個代表性的例子是奧爾丁頓的《雋語》,該詩發表于1916年的《小評論》:
雨鈴在池塘上摔破
蘆葦有白色的雨滴下
她顫抖著喃呢曲身;
風搖蕩著紫藤掉落。
水鳥有紅色的喙
在百合的葉子下畏縮;
一只灰色蜜蜂,震驚于狂風暴雨,
緊緊附著我的衣袖。*Richard Aldington, “Epigram,” in The Little Review 3 (Mar. 1916), p. 29.
這首詩既充滿恰當的自然意象,又得益于一個動靜并置的重疊技巧,客觀的凝視與淡淡的詩意內省相結合。它的作者和發表出處也符合對俳句影響最為普遍之處的預期。機器在“滴水”“葉子”和“依附”等詞匯的索引下發現的模式,與文本細讀的讀者或文化歷史學家辨認的俳句風格相一致。可以肯定,機器是用不同的方式來辨認風格,但它暗示了僅靠措詞和簡短性就可以同樣好地指示出人類讀者所闡明的、更加嚴格但也更加模糊的風格定義。有時候,似乎一種難以言喻的對俳句性質的感覺著實可以化約為詞語選擇的統計模式。在一些情況下,暗示性這個被眾多評論家吟誦的隱晦概念,只不過是選對正確詞匯的事。
第二組誤判的俳句文本則不那么符合文本細讀讀者或文化史家的批評直覺。我們把這些文本稱為機器俳句。其中的一個極端例子是喬治·布里格斯(George Briggs)的《伊芙林》(“Evelyn”)(1917):
當她把頭轉向一邊;
她下巴和喉嚨的連線
延伸到頸肩之下
雅致如孔雀脖子起伏;
又如玫瑰花瓣的柔嫩。
而她的嗓音
聽來如漢子,
把鍋爐的鐵銹清除。*George Briggs, “Evelyn,” in The Smart Set 52 (Aug. 1917), p. 28.
這首詩發表在《聰明人》(TheSmartSet)上 ,與當時人們對仿俳句詩的預期背道而馳。它不僅出現在不符合期待的地方——一個以小說和諷刺笑話聞名的紐約文學雜志,其材料本身也有所欠缺;沒有自然意象,也沒有任何指向更大的存在洞見的暗示性語言。結尾幽默的并置手法把詩人和讀者從他們空靈的幻夢中搖醒,這在日本俳句傳統里絕不陌生,而人們也能夠在英語中找到戲仿的諷刺作品。機器只根據措詞就發現了戲仿作品,這肯定是巧合,不過它也促使我們去進一步研究措詞是如何可能與更復雜的文體特征相關聯的。來自這份期刊的另一首誤判詩歌,題為《自然詩》(“Poem of Native”),1916年發表,就肯定了這種沖動:“一只松鼠順墻而跑。僅此而已。”*Sarsfield Young, “Poem of Nature,” in The Smart Set 50 (Dec.1916), p. 104.我們承認,樸素貝葉斯算法在俳句風格的識別上比文本細讀或文化歷史所允許的要慷慨得多。在《伊芙林》中,“玫瑰”這類頻繁出現在俳句語料庫中的詞引導它把該詩也歸類為俳句,而“鍋爐”這類遠為少見的詞卻被忽略了。*這是被施羅姆·阿加門和馬克·奧爾森稱為“最小公分母”的問題。分類算法往往會倚重所有特征里的一小部分,這樣既沒有足夠突出、也沒有在思辨上公正地對待文學作品的復雜性。(見Shlomo Argamon and Mark Olsen, “Words, Patterns and Documents: Experiments in Machine Learning and Text Analysis,” in Digital Humanities Quarterly 3, no. 2, 2009
最后一組誤判文本給文本細讀和文化歷史方法施加了更大的壓力,同時也指出了一個更普遍的東方主義氛圍。這些詩介于候補俳句和機器俳句之間。這里我們發現樸素貝葉斯也是一個風格上的敏銳“讀者”,能揭示出不同語言模式相交叉的含糊地帶。我們來考察《山間刺柏》(“A Sierra Juniper”, 1921),這首詩由安娜·波特(Anna Porter)所作,刊于洛杉磯的《抒情西部》期刊:
我從花崗巖里奪取生命;
抗擊風暴,我強煉肢體與根莖,
蹲伏,我抓握住危崖的邊緣,
一如我英勇搏斗幾千年。*Anna Porter, “A Sierra Juniper,” in Lyric West 1, No. 4 (1921), p. 18.
作為潛在的俳句,這首頌揚一株嶙峋山木的詩兼具兩方面特征。它給出了一個高度集中的自然事物意象,但又讓人覺得受了韻律編排和重復動詞(奪取、抗擊、蹲伏)的拖累;它融合了詩性主體和客體,但擬人的感覺又太過外顯。把它稱為一首嚴格受俳句影響的詩是走得太遠了,但我們又完全可以說它加入了更大范圍的對東亞文化的熱衷,而英語俳句則是其中不可分割的一部分。正是在這兒,機器學習寬松的本體觀被證明極富價值,盡管它關于詩歌文本的概念相對貧乏。機器學習不僅將我們尋找文本模式的能力拓展到較低知名度以及邊緣詩人的作品,還涵蓋了原本在我們視野之外的文化歷史語境。《抒情西部》,一份立足于加利福尼亞、遠離小雜志文化和意象主義的傳統中心(紐約和芝加哥)的期刊,過去從未成為那個故事的一部分。但機器學習卻表明它可以。這份期刊中的其他詩歌,如喬治·羅爾斯(George Rowles)受俳句啟發的短文或斯諾·蘭利(Snow Langley)對莊周夢蝶的影射——這些同樣作為誤判俳句而被發現的詩歌——看來也參與了那個時代更普遍的東方主義爭鳴。*羅爾斯有好幾首詩被錯誤歸類,其中包括《致武士》《日落》和《藝伎與古箏》,均發表于1922年。對莊子的指涉出自蘭利的《四月幻覺》,同樣發表于1922年。在調查了所有誤判詩歌后,我們發現大約20%屬于候補俳句,40%屬于機器俳句,剩下的40%屬于居中的俳句。
《山間刺柏》這首詩是一個令人信服的例子,它說明,一個多元化的文學模式識別模型有助于重繪文學影響的邊界。僅從文本細讀的角度,這首詩并未嚴格滿足邁納等學者給出的某些標準,也沒有證據支持它受到俳句風格的影響。作為文化歷史學家,我們很難將這首詩定位在現代主義學者所劃定的已知傳播范圍之中,特別是由于波特并不知名。文本細讀和歷史研究限定了一套文學以及社會模式,其中文本卻被輕易排除出來。另一方面,機器學習則表明在統計模式的層面存在著與俳句的某些關聯——一個微妙卻始終存在的關于單詞和單詞配置的模式。這里“影響”是作為一種統計上的可能性,其中詞匯和其他文體特征被認為是各自獨特地分布在不同文本類型之間。這些潛在的、非顯明的影響痕跡正是機器最擅長檢測的,而個體讀者卻無法在一個大的規模中對其進行識別。
在一些情況下,這些痕跡匯成一首符合對俳句文體的既定期望(基于自然意象、暗示性、簡潔)的詩。在另一些情況下得出來的詩與俳句文體的關系卻似乎是完全任意的,或頂多是通過定義得更寬松的東方主義話語和俳句才勉強相關。但需要記住的是,即使機器關于影響上的看法與文本細讀或文化歷史告訴我們的有時不一致,在這些情況中,后兩種的方法也是從一開始就給機器的判斷提供了信息。畢竟,它們是我們一開始用來選定俳句語料庫的依據。機器揭示了存在于這些俳句和誤判文本之間明確的現實關系,雖然這一關系與我們作為文學批評者往往側重的那類關系在本體論上完全不同。在個別詩歌的層面這一關系看似偶然,但在散落于數十家期刊的上百首詩歌的層面,卻出現了一個共享著俳句文體特定要素的文本集合。俳句譯作和改編作中的文本模式似乎滲透進一系列更廣泛的詩作之中,匯成了一個既與俳句文體相關、同時又屬于某些更廣泛的事物的東方主義氛圍。我們可以把這一氛圍想象為一種流傳中的文本模式,由于與其他模式不同,它可能與某些類型而非另一些類型的美學要更加親近。這樣一來,機器就有助于把俳句的接受歷史延長到其最直接和明顯的影響節點之外,使我們得以在一個更廣泛的詩學話語中考察它的影響和地位。
最后這部分僅指出我們可以如何開始追索這一東方主義氛圍的形成和發展,但我們要強調的是,這需要一個在人力解釋與機器解釋之間交替或連接二者的閱讀方法,其中的每一方在批評家從文本中提取意義的努力中都向另一方提供反饋。這樣一來,文學模式識別就把文本細讀、文化歷史和機器學習匯集在一起,使它們相互補充。我們對這些方法的記錄體現了每種方法不可避免的局限性,但也表明每種方法都具有一種模式發現的方式。模式(pattern)這一概念是在各種方法間進行調節的控制條件,更重要的是,它還使各種關于文本(以及文本關系)的本體觀相對化。我們堅持認為,這種結合導致的碰撞可以產生關于英語俳句以及廣泛意義上的現代主義的新歷史。
必須承認,我們的方法得益于這樣一個事實,即俳句以及現代主義詩歌本身的某些看法總是已經有一些模式似的和計算式的東西。這正是19世紀后期日本文學評論家正岡子規(Masaoka Shiki)試圖給出的結論。他寫道:“從排列的理論來看,俳句明顯具有數值上的閾限……它被局限于僅20到30個音節。”*轉引自Janine Beichman, Masaoka Shiki: His Life and Works, Boston, 2002, p. 35. 正岡子規這里借自“‘一名精通數學的當代學者’”來支持俳句即將走到盡頭的論點(p. 35)。達達主義者特里斯唐·查拉(Tristan Tzara)也間接提出了這一觀點,他說詩人從新聞文章中精心地裁剪出單詞,“把它們都放在一個袋子里”,輕輕搖晃,然后將剪下的文字一張張地抽出來,這樣就寫成了詩。*Tristan Tzara, “To Make a Dadaist Poem” (1920); Seven Dada Manifestos, in “Seven Dada Manifestos” and “Lampisteries,” Barbara Wright (trans.), London, 1977, p. 39.還有馬里內蒂(Marinetti),他認為,“語言作為一個系統,根本上是機械的,并能夠被分割成可再組合的元素。”*Johanna Drucker, The Visible Word: Experimental Typography and Modern Art:1909-1923, Chicago, 1994, p. 114.由此看來,提出人力與機器閱讀的融合是一次挑戰,但不是對文學文本及我們作為文學評論家所做工作的異化或是倒退。這里是要使文學對象返回到曾經屬于它自身、且目前也越發屬于它自身的本體觀——我們如今通過數據和計算語言塑造這一本體觀,而前幾代人則通過頻率、公式和模仿的語言來塑造。我們一直知道有一些關系模式在文學體裁的創造和傳播之中運作,但直到現在我們仍受限于自己的識別能力。機器學習能夠幫助我們發現這些模式。
附錄:美國芝加哥大學霍伊特·朗副教授訪談*本文系欄目主持人戴安德、姜文濤對霍伊特·朗所作本刊獨家訪談,由清華大學人文社科學院中文系博士研究生趙薇翻譯。
提問:可以稍微談談您的學術背景嗎?您是怎么進入數字人文領域的呢?
回答:我原本的學術訓練是在日本近現代文學領域,主要集中在20世紀早期這個歷史時段。盡管本科時我也拿到了一個計算機專業的副學位,但計算和量化的研究方法并非我研究生時期專業訓練中的一部分,我博士論文中也沒有采取計算與量化的方法,后來我的博士論文成為我的第一部學術出版物,是關于詩人、作家宮澤賢治(Miyazawa Kenji,1896—1933)的。我第一次接觸到數字人文方法時還是一名助理教授,當時參加了一個由國家人文基金會(NEH)組織的為期兩周的工作坊,內容是關于網絡分析及其在人文領域中的應用的。由于我的早期工作,我對探索藝術家工作網絡的形成與發展發生了興趣,特別是詩人與詩歌流傳的網絡。在這個工作坊期間,我學會了如何將這些網絡可視化和進行分析,此后,我使用這些方法開始了一項關于二戰前日本現代主義詩歌期刊的研究。
最初吸引我轉向這項工作的是掌握大量信息的技能,這些信息是關于詩歌的出版時間和出版地的,以及在此基礎上去發現詩人間合作和社會區分的模式。涉及的規模之大,是我之前沒有想到的。一個擁有幾千名詩人和近十萬首詩歌的數據庫,可以讓我以全新的方式去探索這些檔案,開始以單個文本和作者的方式來提問。轉換了分析的單元和規模之后,潛藏在歷史材料中的模式浮現出來,這促進了新的研究問題的產生,以及對藝術生產中社會過程的新理解。自從參加了2010年的工作坊后,我在學習計算機方法方面投入了越來越多的研究時間,尤其是那些用于發現和分析大體積文學文本模式的技能方面。我現在正寫的一本書就用到了這些方法,從量化的視角來考慮日本近現代文學史。
提問:您接受的訓練是成為日本研究專家,曾對日文和中文文本做過數字人文方面的研究工作。和您相似的做亞洲研究的學者們在使用數字人文工具時會面臨哪些挑戰?或者說,您能談談關于數字人文在北美、日本研究中的現狀嗎?或者它在日本本國的日本研究中的情形,以及這和它在北美及歐洲學界的情況有什么不同?
回答:在這方面,學者們面臨的最大挑戰是技術上的,這很大程度上和分析非字母腳本(non-alphabetic scripts)時遇到的困難相關,在這些腳本中,詞與詞之間沒有界限。很多計算工具是以單詞為單元進行分析處理的,你想分析的任何文本必須事先是切分(或標記)好的。盡管現在有大量程序可以做這個切分的工作了,卻沒有一個程序可以達到百分百準確,而且大部分工具都偏向于處理當代語言。這意味著,能夠處理20世紀晚期日文文本的程序,在處理20世紀早期文本時可能就沒有那么準確,而且肯定無法應付任何日本書面白話文(written vernacular)定型之前的文本。鑒于這一情況,對中日語言由古典向現代白話轉變關鍵歷史時期的研究,如果以這種大型、量化的方法來進行,就不可能了;或者這種情況至少使得采取大型量化的分析不那么容易了。而這種語言轉變的歷史時期正是界定日本和中國近現代文學的時間點。除了文本分割之外,一個更重要的挑戰來自于如何運用光學字符識別軟件(optical character recognition ,即OCR)來將文本數字化。盡管這個領域的技術已經取得了許多進步,可是在識別亞洲文字中產生的困難情形,尤其是年代越久遠的亞洲文字越難識別,這使得大型數字語料庫的建設速度減慢。這一情況正在有所改觀,大量的工作已經做了起來,尤其是在處理前近代時期文本方面,但毫無疑問,與那些面對字母書寫文字(alphabetic scripts)的研究相比,我們慢了幾十年。需要更多的學者來做數字化的工作,更多的學者愿意去創建和分享數字語料庫,這樣才能趕上去。
就日本研究來說,這些技術障礙已經減慢了北美和日本學者們采用數字方法的步伐。開始進入數字研究的門檻看起來似乎太高了,特別是對于老一代的研究日本的學者來說。幾位北美日本研究學者,包括我自己在內,已經開始組織工作坊,創造探索分析工具,藉此改變現狀,但這畢竟是少數。對于我們從事近現代文學的人來說,一個有利條件是“青空文庫(Aozora bunko)”,它收集了超過12000個無版權約束的20世紀初文本,這些都是以眾包的形式手動輸入的。這便給予我們一個非常重要的起點,來做大規模的現近代文學分析工作。然而,這個數據庫里存在著關鍵性的漏洞和一些不符合規范的地方,這使得它并不那么能代表近現代文學生產。而且這個數據庫覆蓋的范圍也非常小。相比之下,制作精良的數據庫,在英語文學研究者們手里,已經用了一段時間了,它們涵蓋了18世紀晚期到今天的文學作品。日本文學研究者想要用上這樣長時段的數據庫,恐怕還要很多年。
有趣的是,正是前近代領域的學者們在引領人們開拓這方面的研究方法,這種情況在日本尤其如此。比如,早期的一些數字工作是由一些宗教學者們完成的,他們投入了大量的經歷和時間來制作升級版的數字化佛經。古典時期的學者也發現,他們更易于采用數字方法,一部分原因是由于他們的語料庫更小也更易于數字化。早期近代視覺文化的數字化工作也取得了很大進步。同時,也是由于大部分的工作已經做了幾十年了,人們也不會經常同北美和歐洲最前沿的理論和計算技術對話交流。我認為,這一溝壑阻礙了數字人文在日本近現代學者中的流行,因為他們看不到這項技術進步可以帶來的知識上的幫助。我知道只有非常少數的學者在將計算方法運用于近現代文本的研究,而且他們中的大多數還是語言學領域的。我希望,隨著越來越多的人可以使用相關工具,可以使用語料庫,會有更多的日本學者能看到這個領域可以帶來的效能。最近,弗朗科·莫瑞蒂《遠讀》(DistantReading)一書被翻譯為日文,這很可能產生重要影響,也許會有助于復蘇日本文學批評中的量化思路,這一思路可以追溯到夏目漱石(1867—1916)。
提問:假設一名中國的文學研究者想要使用計算機去探索分析100個中文文本,為此,他愿意接受某種培訓(例如,某種程序語言),如果可以拿出半年或兩三年的時間,那么他該做些什么呢?
回答:如果一個人只有六個月的時間,我會建議他首先閱讀一些該領域內領先學者們的文章和書籍,這有助于他弄清哪些類別的分析可以(或不可以)采用計算機方法來進行。這可能包括馬修·約克斯(Matthew Jockers)比較基礎性的著作《大分析》(Macroanalysis),杰弗里·洛克維爾(Geoffrey Rockwell)和斯蒂芬·辛克萊(Stephan Sinclair)的《詮釋學》(Hermeneutica),以及安德魯·派博(Andrew Piper)、泰德·安德伍德(Ted Underwood)、馬修·威爾肯斯(Matthew Wilkens)還有其他很多學者等的學術作品。看過這些后,他有可能想要閱讀一些關于統計學和自然語言處理方面的介紹性材料。就編程來說,這真的取決于他之前的經驗。但是如果之前完全沒有背景,我會建議從一種叫作“旅行者”(Voyant)的線上工具開始,它可以對單個文本做多種分析,也可以用于小批量文本的處理。*參見其網址:https://voyant-tools.org/如果有更大的雄心的話,我推薦去讀一下馬修·約克斯的《文學學者如何使用R語言進行文本分析》(TextAnalysiswithRforStudentsofLiterature),這是一本非常簡單易懂的書。人們在重新為中文文本編碼時很可能會遇上一些難題,但我懷疑這些問題都可以參考R語言的編程書來解決,或者參考一些為中文使用者所寫的在線指導。我也建議去參加數字人文年會,例如數字人文組織聯盟(ADHO)的年會,或者其他會議中的相關專題研討及工作坊。這將便于你熟悉該領域業已存在的學術環境,也會讓你接觸到一些當下的討論和問題。
如果可以投入兩至三年的時間,我建議參加一些編程的課程學習(甚至可以是在線課程),學習一些Python和(或者)R語言的基礎知識,也可以通過一些指導性的教科書來自學。這樣的話,我推薦一些專門的教科書,諸如《使用Python的自然語言編程》(NaturalLanguageProcessingwithPython)。Python和R語言都是用途極為廣泛的編程語言,它們可以用于數字人文中的其他方面,包括社會網絡和空間分析。我也建議與老師和(或者)學生展開跨學科合作(例如語言學的、社會科學的),他們已經對這些方法相當熟悉了,可以更有效地為你提供資源。他們自己在使用工具時可能會有不同的目的,但是可以提供許多幫助,使你學到基礎知識。對于那些想要做網絡和空間分析的人來說,也有大量的指導資源。這取決于他們擁有什么樣的方法和工具,以及你在開始前對現存的文獻資料有多熟悉。
提問:我們對量化的文本分析如何能夠挑戰文學史的現有結論很感興趣。您能談談數字人文如何確認或定義新的文學類型嗎,或者數字人文如何擴張現有文學體裁的邊界?
回答:這是一個相當寬泛的問題,我寧肯你去讀一些我發表的文章,里面描述了我認為比較新的量化分析,以及它將會為文學史研究帶來什么。簡單地說,我認為與其說這種分析在界定新的文學類型方面作出了貢獻,還不如說它更能夠促使我們去批評和重審現有的文學體裁定義。也就是說,這迫使我們去思考,我們如今的定義是如何被某種規模的分析,以及關于文學文本如何起作用的那些不太明顯的假設和模型所規定的。數字方法的關鍵并非是為了要使這些模型以及從中派生出來的解釋無效,而是要將這些模型放置在與不同模型和規模分析的比較中,這樣我們才有可能豐富我們的總體視野。數字人文最有前景的方面不在于它可以讓我們脫離文學基本問題,而在于讓我們能夠從新的有利角度回到這些問題,從而使這些概念的討論可以再度熱起來。它迫使我們重新認識諸如文體、敘事、情節、人物以及話語等全部概念。但也刺激著我們去重審“細讀”和其他解釋實踐,這些解釋實踐處于具體的歷史和意識形態中,充滿了偏見和未經審視的假設。
提問:關于數字人文是如何轉變大學教育和研究使命的,我們想聽聽您的思考。簡言之,有人指責數字人文的興起正是高校新自由主義化的表征,您對此作何感想?
回答:我當然理解這一看法。向量化的靠攏、采取似乎科學的方法,給人一種感覺,似乎我們將很大地盤割讓給了侵蝕人文研究領域的經濟和社會權力。這在日本是尤其現實的,那里的政府努力重建大學體系(以及取消人文科學的項目),為的是使這個體系更直接地與當下的勞動力市場匹配。所以人們對這種威脅的體會非常真實,而且看上去數字人文不過是順其道行之的。但是,我認為這種觀點是非常短視的,它忽視了數字人文領域的學者們實際上真正從事的工作。如果認為只有人文學領域受到了大學新自由主義化的不利影響,進而對此作出的反應不過是對無論任何形式的數字人文研究都拒絕,且毫無旁顧地繼續做我們學術界一直做的那種類型的研究,那都是非常錯誤的。對于我來說,這種心態既反智也誤入歧途,因為它為我們現存體系之外設置了一個批評空間。但這從來未曾發生過。人文學者從來就是在大學的行政體系和經濟結構之內工作的,而且在并不久遠的過去,他們還十分愿意從事跨學科的工作呢。實際上,人文和文化研究與科學研究相悖的思想是相當晚近的發明。在我們為現存的人文學科形式喪失而哀悼之前,我們應該始終記住更長時段的人文學科史。
的確,人文科學和自然科學當然蘊含了不同的認識論以及解釋學假設,我們不能指望文化現象可以像生物或物理過程那樣被量化和抽象化。但是,認為所有形式的量化研究都不適用于人文學科就不夠坦誠了,這忽略了藝術與科學之間長久的交流史。如果新自由主義化正在逼迫人文學者去與科學領域之中發生的研究進行談話、與其他看待世界的模式之間再次溝通對話,那這便未必是一樁壞事 。如果對話是單邊的,那將帶來問題,但這也正是為什么人文學者應該多去參與其他科學領域發展的原因。越是自絕于其他領域,我們將越是無法展開真正的對話,也無法為人文研究的獨特性做辯護。保存我們的相關性并不是要拒絕曾經指引過我們研究的問題和對象,而是要在數字技術全面滲透的今天,重新思考這些問題和對象的處境。我們需要全面參與到這些技術中去,不僅為了幫我們把研究的問題和對象轉換到這新的數字時代,同時也讓我們以一種明智的、知情的方式去質詢這轉變帶來的得失。我們,作為人文學者,應積極為這種討論貢獻力量,但如果我們只是繼續自言自語下去,那終將無濟于事。
(責任編輯:陸曉芳)
2016-09-25
霍伊特·朗(Hoyt Long),美國芝加哥大學東亞語言與文化系副教授,主要研究方向為現代日本文學、媒體歷史、文學社會學與數字人文,著有OnUnevenGround:MiyazawaKenjiandtheMakingofPlaceinModernJapan(2012),與蘇真一起合作負責芝加哥文本實驗室(Text Lab)。 蘇 真(Richard Jean So),美國芝加哥大學英文系副教授,主要研究方向為數字人文等,著有TranspacificCommunity:America,ChinaandtheRiseandFallofaGlobalCulturalNetwork(2016)。
I0-05
A
1003-4145[2016]11-0034-20
譯者簡介:林 懿,女,南京大學英語系博士研究生,美國杜克大學訪問學者,主要研究方向為當代英美文學與文學理論。
①Hoyt Long, and Richard Jean So, “Literary Pattern Recognition: Modernism between Close Reading and Machine Learning,” inCriticalInquiry, 42:2 (2016), pp.235-267. The University of Chicago Press. Translated and reprinted with permission of The University of Chicago Press.
猜你喜歡
云南教育·小學教師(2022年4期)2022-05-17 14:46:24
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
甘肅教育(2020年8期)2020-06-11 06:10:02
藝術評論(2020年3期)2020-02-06 06:29:22
制造技術與機床(2019年10期)2019-10-26 02:48:08
新世紀智能(語文備考)(2018年11期)2018-12-29 12:30:58
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2015年11期)2015-02-28 22:01:59
