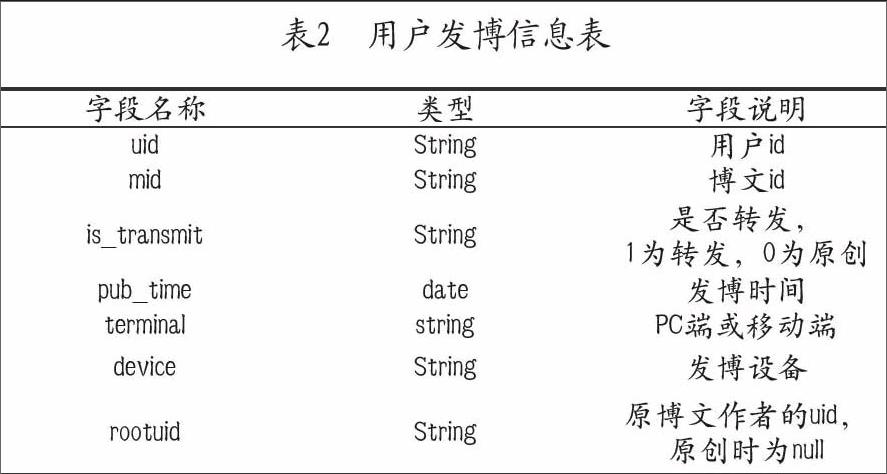
基于機器學習的微博機器用戶識別研究
2016-12-20 03:27:06金丹滕潔琪
中國高新技術企業 2016年30期
金丹 滕潔琪
摘要:文章以微博用戶為研究對象,從發博行為、博文內容、用戶關系和發博設備四個方面建立特征維度,借助機器學習的方法構建有效的機器用戶識別模型,分別在決策樹C4.5和隨機森林算法下驗證了該模型的識別性能,證實了該方法的可行性和準確性,對維護健康的網絡環境有一定的指導意義。
關鍵詞:微博;機器用戶;機器學習;用戶識別;決策樹C4.5;隨機森林算法 文獻標識碼:A
中圖分類號:TP391 文章編號:1009-2374(2016)30-0004-04 DOI:10.13535/j.cnki.11-4406/n.2016.30.003
1 概述
微博作為一種社會信息傳播平臺,以其易操作、低門檻、傳播速度快等優點,受到公眾更多的青睞。然而,隨著微博的普及和互聯網絡技術的升級,一些不良分子借助新興技術手段,譬如,依靠批量發布助手、自動廣播器等自動化軟件來操控賬戶,由此構成了機器用戶。機器用戶能夠模仿真實用戶發布、轉發、評論博文,這類用戶不具備感情、邏輯和互動性,卻以其良好的偽裝性,大量發布虛假信息,擴散輿論謠言,嚴重擾亂網絡的正常秩序,破壞網絡環境。機器用戶造成的危害具體概括為以下四點:(1)耗費系統資源,降低平臺效率,影響用戶體驗;(2)污染社交環境,降低用戶信任度,造成平臺虛假繁榮現象;(3)難以辨別信息真實性,干擾用戶正常判斷力;(4)從數據分析角度,這些機器用戶的存在部分掩蓋了真實用戶的特征,對后續數據挖掘、用戶分析等研究造成了干擾。
鑒于此,機器用戶的識別是一個緊迫而困難的工作,構建有效的機器用戶識別模型,借助相關算法快速、準確地識別微博中的機器用戶,對減少網絡謠言的傳播、凈化網絡環境有重要的意義。
2 相關研究
早期對社交網站不良用戶的研究主要集中在對垃圾用戶,例如網絡水軍、廣告用戶、僵尸粉用戶的識別研究上,而機器用戶出現的時間并不長,對它的研究還不多,僅有的研究大多數以Twitter為平臺,其成果無法直接應用于新浪微博等中文微博平臺。
國內方面,劉勘等向自動化軟件公司申請并獲取了機器用戶樣本,提取了行為模式、微博內容、用戶關系和發布平臺四個維度的八個特征屬性,基于隨機森林訓練了一個機器用戶識別系統,機器用戶的識別準確率達到了96.7%。中國的微博起源于Twitter,國外基于Twitter的機器用戶研究主要有以下幾人:Chu等從用戶行為、Twitter內容和賬戶屬性的角度建立分類系統,將Twitter用戶分成機器用戶、人類用戶和半機器用戶。Main采用決策樹C4.5算法訓練分類器,從用戶的發博間隔、垃圾詞語檢測、重復博文檢測、社交分值和發博設備五個方面構建模型,對訓練結果采用了比較分析法,分別選用2個主要屬性,發博間隔和垃圾信息檢測,還有完全采用5個屬性時分類器的效果差異。結果表明,發博間隔是機器用戶的重要特征,有著更好的區分度。Zhang等構建了一個基于每條Twitter發布時間的檢測機器用戶方法,并用此模型得到Twitter中大約有16%的活躍賬戶具有較高自動化行為。Wang提取3個基于圖模型的Twitter用戶特征和3個基于Twitter內容的屬性并設計算法,識別出Twitter中的機器用戶。
3 基本思路及相關方法
機器用戶的識別問題可以看作是一個將用戶分為機器用戶和真實用戶的二分類問題:設用戶的全集是U,類別集合C={,},表示機器用戶集合,表示真實用戶集合,機器用戶的識別問題就是求一個分類函數F,將U中的用戶映射到C上。
(1)
上述映射函數F即代表了一個分類器,它可由機器學習算法習得,在本研究中選取決策樹C4.5和隨機森林算法。
C4.5算法是目前決策樹中最常用的算法。它在樹的構造過程中進行剪枝,并且用信息增益率來選擇屬性,克服了用信息增益選擇屬性時偏向選擇取值多的屬性的不足。C4.5決策樹算法不僅能對離散型數據、連續屬性的離散化進行處理,還能夠對不完整數據進行處理。
隨機森林算法是Leo Breiman提出的一種利用多個樹分類器進行分類和預測的方法。隨機森林不僅訓練和預測速度快而且不容易出現過度擬合的問題。
4 特征研究
通過深入觀察和分析,發現機器用戶在發博行為、微博內容、用戶關系和發布平臺4個方面存在顯著差異,因此本文對這4個維度的特征進行深入分析。
4.1 發博行為特征
發布博文是用戶在微博上的主要活動之一。經過瀏覽機器用戶的發博歷史,發現機器用戶發博方式呈現兩種極端:一類機器用戶依靠不斷轉發某一條博文來增加人氣;另一類機器用戶依靠不斷發布某領域原創博文來維持粉絲的粘性。因此,我們定義轉發率來觀察機器用戶和真實用戶的異同。轉發率為:
(2)
用戶發布博文包括原創和轉發,表示某用戶發博總數,表示該用戶轉發博文的數量,表示用戶轉發博文比率。
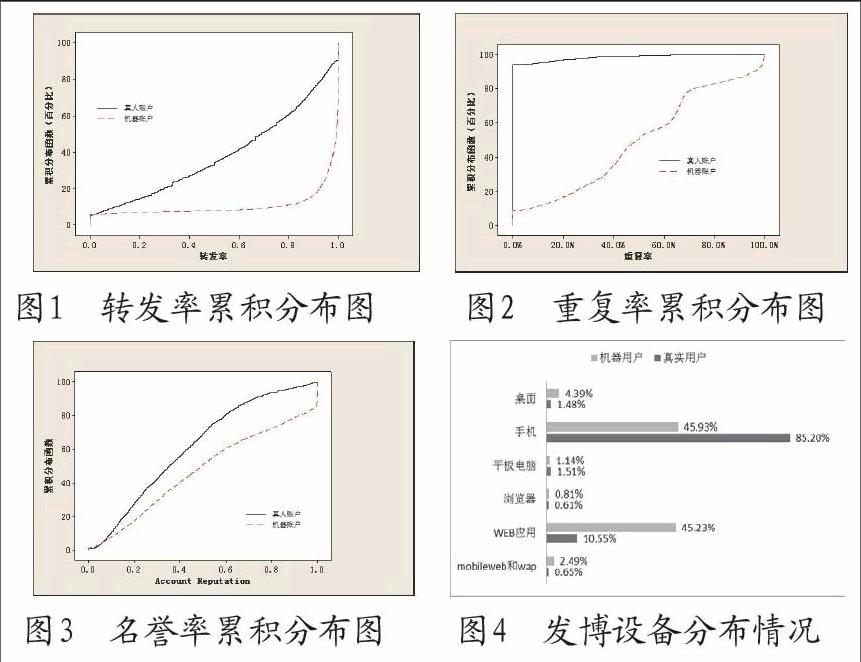
CDF累積分布曲線能夠定量地顯示數據的分布,每一條CDF曲線代表了一群樣本某一特征的數據分布,CDF曲線上的每個點對應統計特征的一個值以及統計特征小于這個值的樣本數量占總樣本數量的百分比。利用CDF曲線,可以很容易地找到多個樣本群體對應一個統計特征在數據分布上差異,而這種差異正是我們尋找的特征的“區分度”。從圖1是轉發率累積分布圖,真實用戶轉發率分布較均勻,隨著轉發率的增加,曲線穩步上升,而機器用戶轉發率在0.9之前,曲線平緩,波動不大,而在轉發率大于0.9后猛然上升,可見機器用戶中大部分用戶僅以轉發為主,幾乎不發表自己的言論。
4.2 博文內容特征
從上文轉發率可知,機器用戶的轉發率非常高,并且轉發的原作者集中且單一,如何通過轉發來描述轉發行為的重復情況,在微博后臺數據集群中,用戶發博日志存儲的形式有一個字段為被轉發博文的作者rootuid,據觀察經驗,機器用戶總是固定某一個或某一些用戶的博文,被轉發用戶重復率非常高,因此,定義重復率為:
(3)
表示轉發博文的原創用戶相同的博文數,表示所有轉發的博文數,重復率一定程度上反映了用戶的傾向和意圖,普通用戶轉發的博文多種多樣,機器用戶目的單一,轉發的原作者的范圍狹窄,因此根據用戶是否頻繁轉發某一用戶的博文,具有一定的區分度。
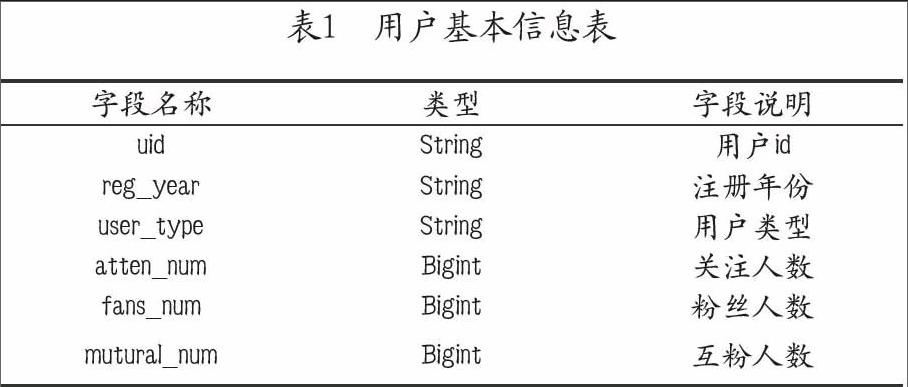
圖2所示為被轉發用戶重復率的累積分布圖,機器用戶的轉發用戶重復率明顯高出真實用戶,表示機器用戶總是固定頻繁地轉發某些人的博文,最典型的是機器用戶中的明星水軍用戶,長期圈粉某一位公眾明星,批量轉發此人微博,并加入該明星話題詞,從而達到提高人氣和利用影響力進行炒作的目的。
4.3 用戶關系特征
用戶關系是社交網絡上的重要體現之一,機器用戶中認證用戶較多,他們利用認證身份的優勢以及借助自動化手段發布優質博文,收獲更多的粉絲。而真實用戶是將現實生活中的關系映射到其社交關系中,因而其關注數和粉絲數相差不大。根據以上分析,定義名譽率,計算公式如下:
(4)
式中:為用戶粉絲數,為用戶關注數,名譽率越接近0,表示關注數遠遠大于粉絲數,受歡迎度接近1,表示粉絲量大,言論會受到眾多關注,更受歡迎。名譽度指標反映的是用戶粉絲量占總體關系的比例,該指標越高說明此用戶粉絲越多,越受粉絲歡迎。受歡迎指數的CDF曲線圖如圖3所示,橫坐標為受歡迎指數的值,取值范圍是0~1,縱坐標表示統計值小于該值的樣本數量占總樣本的比例,因此曲線偏向左邊,則該組樣本的受歡迎指數偏低,反之,曲線偏向右邊,該組樣本的受歡迎指數較高。
由圖3可見,機器用戶的受歡迎度比真實用戶名譽率更高。因為機器用戶并不是通過大量關注普通用戶,來獲取更多的被關注機會,操縱這些機器賬號的用戶更多的是通過創造良好的口碑和微博形象,提供更有價值的信息,以此來吸引粉絲,這些粉絲與博主具有相同的興趣,樂于接受博文更新。由受歡迎度累積分布圖來看,在相同概率下,機器用戶比真實用戶具有更高的受歡迎度,而真實用戶通常利用微博瀏覽興趣話題,因而關注量大于粉絲量。
4.4 發博設備特征
機器用戶通常借助第三方平臺來更新博文信息流,發博設備作為區分特征之一是有效的,發博設備有Mobileweb和Wap、Web應用、瀏覽器、平板電腦、手機和桌面。
如圖4所示,87%以上真實用戶的發博行為都發生在移動端,而機器用戶僅有50%的用戶在移動端發布博文,機器用戶常用的設備是Web應用即第三方軟件平臺,由此可見,機器用戶大多是在PC平臺操作,借助Web應用軟件來批量發送博文,而普通用戶僅把微博作為及時記錄心情和新鮮事的工具。
圖1 轉發率累積分布圖 圖2 重復率累積分布圖圖
圖3 名譽率累積分布圖 圖4 發博設備分布情況
5 模型構建
從上文提出的行為、內容、關系和平臺4個特征維度,分別是轉發率、重復度、名譽率、設備信息。識別某用戶是否為機器用戶的算法就是根據這幾個特征構建模型。本文使用機器學習工具Weka來訓練和測試算法模型,基于微博數據和分類算法決策樹C4.5和隨機森林構建模型。選用決策樹和隨機森林算法,是因為決策樹和隨機森林在解決分類問題的良好性能。
5.1 數據來源
本文數據樣本均來自于新浪微博數據倉庫。抽取用戶樣本的規則是基于機器用戶單位發博量巨大的顯著特征,抽取2016年2月一整月發博數最高的前3000個賬號標記為機器用戶,真實用戶按照合理發博數隨機取2406為初始實驗數據。
本文所選數據包含以下方面:用戶的基本屬性、用戶的關系屬性、用戶的行為屬性和用戶發布博文屬性,數據存儲表信息如下:
5.2 模型構建與評估標準
從前文提出的發博行為、博文內容、用戶關系和發博設備四個特征維度,計算得到數值型變量、轉發率、重復率、名譽率,發博設備是標識性變量,識別機器用戶的分類器就是基于這四個特征值構建的模型,識別的流程圖如圖5所示:
對于一個二分類問題,模型預測可能產生四種不同的結果,如表3所示:
實驗評價模型的標準有:命中率(TP Rate),誤判率(FP Rate),正確率(Precision),召回率(Recall),F值(F-measure)和ROC area,這些指標的計算公式是:(1)命中率:TP Rate=TP/(TP+FN):正樣本分類成正樣本數/正樣本總數;(2)誤判率:FP Rate=FP/(FP+TN):負樣本分類成正樣本數/負樣本總數;(3)正確率:Precision=TP/(TP+FP):返回的正確樣本數/返回的樣本總數;(4)召回率:Recall=TP/(TP+TN):返回的正確樣本數/全部的正確樣本數;(5)F值:F-measure=2*Precision*Recall/(Precision+Recall);(6)ROC area(Receiver Operating Characteristic):在ROC空間中,每個點的橫坐標是FPR,縱坐標是TPR。ROC是計算曲線下的面積,面積越接近1,說明模型效果越好。
5.3 實驗與結果分析
基于上述模型,本文標注了一些數據集,用于測試和檢驗模型的有效性。實驗數據來源于新浪微博數據倉庫,隨機選取約4000用戶作為實驗樣例。實現方法上,本文分別采用基于C4.5決策樹的分類算法和改進決策樹的隨機森林分類算法對模型進行訓練,并用10折交叉驗證的方法驗證模型。本文利用機器學習工具集Weka分別用上述兩種算法訓練模型,兩種算法的模型效果分別如表4和表5所示。圖6是這兩種算法統計對比圖。
實驗中,本文標記了3771個用戶數據,其中機器用戶2069個、真實用戶1702個,從分類結果來看,決策樹C4.5和隨機森林對機器用戶的識別效果相差不大,但隨機森林稍微優于C4.5,從表4看到,C4.5的準確率94.2%,而表5中隨機森林的準確率為94.4%。整體來講,隨機森林模型優于決策樹C4.5模型。
為了檢驗各個特征屬性對模型效率的影響,分別去除某一特征,查看模型性能的變化情況。表6列出了分別去除發博平臺、名譽率、重復率和轉發率這4個特征之后,性能指標的變化情況。從數據中可以看出:(1)對于決策樹C4.5算法來說,去掉名譽率和轉發率,模型性能略微提升,模型中去掉任意一個是合理的。但對于隨機森林來說,去掉任何一個指標,都將導致性能的下降,因此隨機森林宜保留全部特征屬性;(2)重復率對模型效率起到重要作用,去掉重復率以后,模型的效率下降幅度明顯,僅僅在0.7左右,并且對決策樹模型影響偏大,識別效率不到0.7;(3)發博平臺對整體模型,無論是決策樹還是隨機森林都有一定貢獻。
圖7是決策樹C4.5和隨機森林分別去掉每個屬性后,F值的對比,可見除了重復率,去掉發博平臺、名譽率和轉發率中的任意一個屬性,F值均可達到0.9以上。
以上分析可見,重復率這一屬性對模型的影響效率非常明顯。若只考慮這一屬性特征,訓練模型后得到的準確率決策樹和隨機森林分別為93.3%和92.7%。已經達到很好的區分度,結合機器用戶的發博動機和意圖,一部分以網絡水軍為主體的明星人氣造勢者以及另一部分以廣告營銷為主體的廣播擴散型商業機器用戶,從這一點考慮,頻繁和長久的轉發相同賬號的博文是情理之中的。
6 結語
本文針對國內新浪微博機器用戶的特點,從發博行為、微博內容相似情況、用戶關系、發布平臺4個維度構建模型指標,分別利用決策樹C4.5和隨機森林算法實現了對機器用戶的有效識別。實驗表明,本文采用的模型指標和分類模型能有效地識別微博中的機器用戶,而且轉發博文的高度重復是機器用戶的重要特征。本文的工作對避免虛假、有害信息的擴散,營造積極健康的網絡環境有重要意義。由于網絡信息傳播模式變化較快,機器用戶采用的方法也會不斷變化,因此進一步的研究需要及時關注機器用戶的最新特點和變化趨勢,及時調整或構建新的識別模型。另外,除了微博平臺,機器用戶在論壇、貼吧、新聞評論、商品評論等其他網絡平臺上也較活躍,針對這些平臺中的機器用戶也需要構建相應的識別模型。
參考文獻
[1] 劉勘,袁蘊英,劉萍.基于隨機森林分類的微博機器用戶識別研究[J].北京大學學報(自然科學版),2015,(2).
[2] Chu,Z.,et al.Detecting Automation of Twitter Accounts:Are You a Human,Bot,or Cyborg[J].IEEE Transactions on Dependable and Secure Computing,2012,9(6).
[3] Main,W.and N.Shekokhar.Twitterati Identification System[J].Procedia Computer Science,2015,(45).
[4] Zhang C M,Paxson V.Detecting and analyzing automated activity on twitter[A].Passive and Active Measurement[C].Springer Berlin Heidelberg,2011.
[5] Wang,A.H.Detecting Spam Bots in Online Social Networking Sites:A Machine Learning Approach[M].Data and Applications Security and Privacy XXIV,2010.
[6] Breiman L.Random forests[J].Machine Learning,2001,45(1).
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
