基于文本挖掘技術的95598重復投訴分析
2017-01-18 11:30:34李靜1劉思濤2
消費導刊 2016年12期
李靜1. 劉思濤2.
1.國網山東省電力公司電力科學研究院2.國網山東省電力公司物資公司
基于文本挖掘技術的95598重復投訴分析
李靜1. 劉思濤2.
1.國網山東省電力公司電力科學研究院2.國網山東省電力公司物資公司
重復投訴工單的挖掘與分析,對供電業務薄弱點的發現與改進,提升供電企業的服務品質,提升企業形象具有重要且深遠的意義。目前重復投訴工單的發現,主要依靠人工,費時費力,效率低。本文提出了一種基于客戶投訴內容的重復投訴工單識別,對文本信息進行中文自然語言處理和數據挖掘,通過大數據對文本挖掘結果進行分析監控,構建適合電力公司的重復投訴工單文本挖掘模型,高效準確的識別重復投訴工單,便于分析人員及時準確地發現重復投訴原因熱點。
重復投訴 文本挖掘 文本相似度 多維分析
引言
在95598來電工單中,包含了大量投訴類工單,這些文本數據蘊含了對用戶訴求的直接描述,如何快速從來電工單中挖掘出重復投訴的工單,成為投訴管理的迫切需求。目前重復投訴工單的識別挖掘,主要依靠投訴分析人員通過對95598投訴工單的分析,人工逐條查閱工單內容,分析效率低,無法及時了解客戶重復投訴的原因,容易產生客戶服務滯后的問題。另外,工單中的投訴內容為文本內容,文本信息量大非結構化,難以對數據進行直接分析。因此,為解決以上問題,本文引入了文本挖掘的理念和方法,通過構建重復投訴模型,實現重復投訴工單的識別,根據重復投訴的分析結果,查找重復投訴原因,制定行之有效的投訴處理策略,提高投訴處理質量和效率。
一、文本挖掘相關理論
(一)文本挖掘技術。文本挖掘(Text Mining,TM)是近幾年來數據挖掘領域的一個新興分支,是以文本數據為特定挖掘對象的知識挖掘。文本挖掘的要點是分詞,根據文本數據中的特征信息進行分詞處理,以此構建文本的中間表示。文本挖掘分析大量的半結構化或非結構化文本數據,利用數據挖掘的算法,抽取出關鍵的詞語和文字間的關聯關系,并按照內容對文檔進行分類或聚類,進而發現新的概念和獲取相應的關系。
(二)基于領域特征詞表的特征詞標注。以大量投訴工單中反映業務種類、問題現象、問題原因的特征詞為基礎,設立特征詞表,進行基于特征詞匹配的子句標注,并依不同緯度進行工單分類。在實際應用中發現,基于領域特征詞表的輔助分析,可以顯著提高工單分類、聚類等的準確性和效率。
(三)基于大數據的數據監控分析。通過構建檢測模型和確定模型指標體系、指標閥值等參數,對工單數據進行大數據分析,采取可視化大屏全屏展示的方式進行全方位多角度的展開實時監控、分析,及時發現當前重復投訴問題變化趨勢,并對問題點改進情況進行跟蹤。
二、重復投訴模型
所謂重復投訴工單是指客戶第一次投訴后,再次來電投訴相同事情的工單。具體描述如下:從查詢周期內,同一戶號、同一來電號碼、受理內容相似的工單、并對重復事件數、工單數、電話數的單位分布進行分析。
根據重復投訴工單定義,采用2015年全年的投訴工單數據,先進行數據清理、數據預處理等步驟完成數據的清洗,通過文本建模分析,識別重復投訴工單,并利用多維分析手段,對結果進行可視化展示。重復投訴模型如下圖所示:
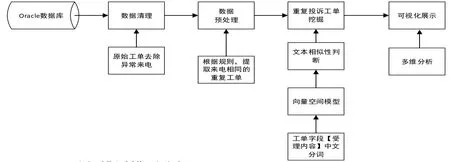
圖1 重復投訴模型分析
(一)數據清理。清除投訴工單中存在異常來電的數據,如信息不全的工單、受理內容含“無故掛斷”,等內容的工單,客戶編號或地址或電話為*的工單。
(二)數據預處理。根據重復投訴定義,提取工單中電話號碼、供電公司、供電單位都相同的工單,作為一組重復工單。
(三)文本挖掘。對每組重復工單的受理內容,進行兩兩相似度的判斷,選取相似度相同的工單合并為重復投訴工單。
(1)中文分詞。分詞,采用 TD-CS 分詞技術,將一段文本轉化為詞語集合。原理:按詞長對中文詞匯分進行分詞,對要分詞的文本進行匹配,如果找到了匹配詞匯,則在該詞匯處分詞,如果沒有匹配,那么縮短詞匯繼續進行匹配,直到匹配為止,如果一直到最后單字都沒匹配,則認為該詞為新詞,在新詞后進行分詞。
(2)向量空間模型。向量空間模型的基本思想是將文本分為若干的特征項,通過特定的手段計算出每個特征項在該文本中的權重,進而將整個文本用以特征項的權重為分量的向量來表示,在將文本用特征向量的方式表示為數學模型以后,再基于特征向量進行文本之間的相似度計算。權值可分為詞頻型和布爾型,詞頻即詞條在文章中出現的次數,布爾型即在詞條在文本中是否出現過,出現為1,未出現為0。由于投訴工單受理內容多位短文本,所以權值采用布爾型表示。
(3)文本相似度判斷。文檔表示成向量后,文本之間的語義相似度就可以通過空間中的這兩個向量間的幾何關系來度量。目前相似度的計量方法有內積、JACCARD系數,余弦函數等方法[1]。本文采用余弦函數的方式計算文本相似度,即用空間中的兩個向量的夾角余弦來度量文檔之間的相似度,夾角余弦值越大,兩個向量的夾角越小,表示文檔越相似[2]。經典的計算公式如下:
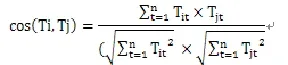
其中,Ti表示文本特征向量,Tit表示文本Ti的第t個向量。
對重復工單進行文本相似度兩兩計算,選取相似度高的為重復投訴工單,如果兩組含有相同工單,則合并兩組工單,去除相同工單,聚為一組重復投訴工單。
(4)模型優化。根據模型訓練的結果,采取優化訓練集、修正關鍵詞、修正模型算法等方式,結合人工經驗,優化模型。
三、分析應用
根據重復投訴工單的挖掘,利用多維分析手段,統計重復投訴的工單數、電話數、事項數等的單位分布,并對重復投訴工單進行詳單的下鉆展示。根據重復投訴工單的電話號碼、客戶編號等關鍵信息,追溯該客戶的的歷史來電記錄,挖掘重復投訴下的深層次的原因。重復投訴工單的結果展示,主要通過報表、柱形圖、條形圖等可視化方式展現的。
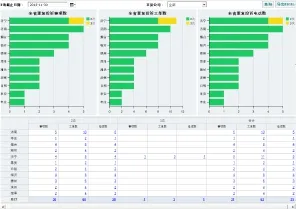
圖2 重復投訴可視化界面圖
表1重復投訴工單明細
一組:工單編號:XX;業務類型:投訴; 受理時間: 2016-01-22 14:52:49;
受理內容:【頻繁停電】客戶反映該地點最近一個月內,出現三四次停電,嚴重影響居民的正常生活生產,至今沒有解決,客戶表示非常不滿,要求供電公司相關部門盡快徹底解決此問題并盡快給客戶合理解釋。同時客戶表示今天楊莊集鎮的夏廟村現在還是正常用電的,自己家唐店村停電了,客戶對此不解。
聯系電話: XX;供電單位:XX縣客戶服務中心。
二組:工單編號:XX;業務類型:投訴; 受理時間:2016-02-27 20:19:56;
受理內容:【頻繁停電】客戶反映該地點最近一個月內頻繁停電,今天一天出現三次停電,嚴重影響居民的正常生活生產,至今沒有解決,客戶表示非常不滿,要求供電公司相關部門盡快徹底解決此問題并盡快給客戶合理解釋,客戶對此不解。聯系電話: XX;供電單位:XX縣客戶服務中心
四、結語
本文引入文本挖掘與智能識別技術,探索基于客戶投訴內容的重復投訴智能識別,實現投訴內容分析快速準確識別客戶重復投訴原因,便于投訴分析人員及時準確地發現重復投訴原因熱點,專家協同工作深耕引發原因背后的產品服務短板,提出短板優化建議并落實。
[1]Salton G, Wong A, Yang C S. A vector space model for automatic indexiBg[J]. Communications of the ACM, 1975,18(11): 613-620.
[2]周昭濤,文本聚類分析效果評價及文本表示研究,中科院,碩士學位論文,2005
[3]王興起,王維才,謝宗曉等.文本挖掘技術在信息安全風險評估系統中的應用研究[J].情報理論與實踐,2013,36(4) :107-110.
李靜(1977-),女,工程師,長期從事電力營銷工作。
