融合檢索技術的譯文推薦系統
2017-04-08 05:55:36蔣宗禮王威
哈爾濱工程大學學報 2017年3期
蔣宗禮, 王威
(北京工業大學 計算機學院,北京 100124)
融合檢索技術的譯文推薦系統
蔣宗禮, 王威
(北京工業大學 計算機學院,北京 100124)
本文將基于單語語料的檢索技術運用到機器翻譯中,構建了一個漢英譯文推薦系統,解決傳統方法雙語料庫構建代價高昂的問題,同時提高最終譯文的流暢性。譯文推薦系統包括查詢翻譯和信息檢索兩部分:查詢翻譯根據給定的一組中文,生成N-best英文結果;信息檢索評價目標語言與候選譯文的相似程度。系統綜合兩部分得分返回推薦譯文。考慮到N-best結果與候選譯文的詞序一致性,采用Levenshtein距離使得排序結果更加合理。在英漢數據集上的實驗表明:在不同n階語言模型下,譯文推薦系統都有很好的表現,加入Levenshtein距離取得了最高70.83%的f測度值。
信息檢索;機器翻譯;自然語言處理;單語語料;Levenshtein距離;推薦系統;跨語言
信息時代,每天都有不同語言的信息在生成、傳播和轉換。跨語言信息檢索[1](cross-language information retrieval, CLIR)為克服語言障礙提供了一種方便的途徑。
融合檢索技術的譯文推薦系統,簡稱為翻譯檢索(translation retrieval, TR)系統,將翻譯問題轉化成檢索問題,屬于CLIR問題的一個特例。其不同之處在于檢索模型的相關性評價。CLIR返回與用戶查詢意圖最相近的文檔,而TR的文檔庫由單個句子構成,最終得到的是包含查詢譯文的句子。
翻譯檢索的概念最早由Baldwin等[2]在翻譯記憶系統中提出,與基于樣例[3]的翻譯相似,該方法依賴大規模的高質量雙語語料。學者從互聯網中獲得平行語料[4-5],代價仍然高昂。Berger等[6]將統計機器翻譯的方法運用到信息檢索中,Federico等[1]實現了一個基于N-best查詢翻譯的CLIR系統,將需求分為查詢翻譯模型和查詢文檔模型。信息檢索方面,Ng[5]采用一個最大似然估計的信息檢索模型,Witten[6]使用平滑策略來優化概率估計,Navarro在文獻[7]介紹了字符串相似性匹配的相關技術。Sanchez-Martinez等[8]用源文檔檢索目標文檔,比較了使用統計機器翻譯技術的不同策略。陳士杰等[9]實現了一個基于Lucene的英漢跨語言信息檢索系統,旨在尋找更為有效的英漢查詢翻譯方法以及提高中文檢索系統的性能。
傳統漢英翻譯檢索方法的效果嚴重依賴于漢英平行語料庫的規模與質量。TR系統使用單語語料庫實現翻譯檢索,提高譯文流暢性的同時,解決了雙語料庫構建代價太大的問題,其返回的單個句子直接為翻譯人員提供輔助。
本文研究如何在漢英數據集上利用檢索模型為翻譯人員提供參考譯文。系統由查詢翻譯子系統和檢索子系統構成,查詢翻譯子系統采用基于短語的統計機器翻譯方法,對給定的中文查詢,翻譯出N-best條查詢譯文。檢索子系統采用單語語料庫,基于向量空間模型評價查詢譯文與文檔的相似性,最后返回高質量的參考譯文。同時,檢索子系統根據Levenshtein距離給出更恰當的參考譯文排序。
1 翻譯檢索系統
依統計學的角度,融合檢索技術的譯文推薦系統可以描述如下。
給定一個中文查詢s,本文希望從文檔集合D中返回具有最大翻譯概率的譯文d′:
d′=argmaxd∈D{Pr(d|s)}
注意到中文查詢一般為一句話,因此文檔集合包含的并非一系列長段文檔,而是目標語言的一系列句子。更一般地,系統應返回多個按相關度排序的候選譯文,翻譯人員依次瀏覽獲得幫助。
為了解決中文查詢s與對應的英語文檔d的差異問題,引入隱藏變量t,表示查詢s對應的N-best譯文中的某個句子。同時假設對給定的s與t,d產生的概率只與t有關:
Pr(d|s)=Pr(d,t|s)=Pr(t|s)×Pr(d|t)
式中:Pr(t|s)由查詢翻譯子系統計算,Pr(d|t)將由檢索子系統計算。
1.1 系統架構
圖1給出融合檢索技術的譯文推薦系統的整體架構,系統接受一個中文查詢,最終返回多個候選譯文。

圖1 翻譯檢索系統總體架構Fig.1 Translation retrieval system architecture
系統分為查詢翻譯子系統和檢索子系統,其中漢英平行語料庫用來訓練查詢翻譯模型,英文單語語料庫用來提供檢索查詢。
本文借助NiuTrans構建查詢翻譯子系統[10],訓練翻譯模型以及n-gram語言模型。輸入的中文經過查詢翻譯子系統得到目標語言英文的N-best譯文。檢索子系統接受查詢翻譯系統的輸出結果,以Apache Lucene為基礎,采用向量空間模型計算查詢語句與候選文檔的相似度,通過加入Levenshtein距離,使最終返回的參考譯文的排序更合理。
1.2 查詢翻譯子系統
查詢翻譯子系統計算將中文查詢翻譯成英文的概率,并得到N-best英文譯文,該問題可描述為
式中:Pr(t|s)表示把給定源語言查詢s翻譯成目標語言查詢t的可能性。為了求得Pr(t|s),引入對數線性(log-linear)模型:
(1)
式中:{hi(s,t)|i=1,2,…,M}是計算Pr(t|s)的特征集合,λi表示第i個特征對應的權重值,該值由最小錯誤率函數訓練[11](minimum error rate training,MERT)。
本文的查詢翻譯子系統采用基于短語的翻譯模型,選用了如下特征:
1) 短語翻譯概率PrΦ(t|s),該概率決定了源語言短語是否能正確地翻譯成英文,其值通過最大似然估計獲得。
2) 反向短語翻譯概率PrΦ(s|t),雙向的翻譯概率通常優于僅僅使用正向的模型。
3) 詞匯加權概率Prlex(t|s),這是一種平滑方法,把短語分解成詞的翻譯來檢查它們的匹配程度,用來衡量不常出現短語的可靠性。
4) 反向詞匯加權概率Prlex(s|t),雙向的詞匯加權概率得到更優的翻譯質量。
5) 語言模型概率Prlm(t),表示目標語言查詢t在語料中出現的概率,確保輸出句子的流利性,賦予較大權重。
6) 位變模型概率Prd(s,t),衡量短語調序的正確性,包括基于最大熵的調序模型fme(s,t)和基于MSD的調序模型fmsd(s,t)。
7) 加權激勵(bonus),包括單詞激勵(TWB)length(t);單詞刪除激勵(WDB);短語激勵(PB)。
用式(1)將所有的特征用對數線性模型結合起來,得到
Pr(t|s)=PrΦ(t|s)λ1×PrΦ(s|t)λ2×
Prlex(t|s)λ3×Prlex(s|t)λ4×
Prd(s,t)λ5×Prlm(t)λ6×exp(λTWB×
length(t))×exp(λPB)×exp(λWDB)
為了優化特征權值,令S=(s1,s2,…,sm)表示源語言句子,u(λ)為權值的估計,T(u(λ))=(t1,t2,…,tm)為目標譯文結果,R=(r1,r2,…,rm)是標準譯文,根據MERT算法有
采用BLEU值定義錯誤函數Err(),通過上述多次迭代得到適合的特征權重。
Err(T(u(λ)),R)=1-BLEU(T(u(λ)),R)
1.3 檢索子系統
檢索子系統計算從查詢語句t到文檔d的可能性,使用基于向量空間模型構建檢索算法。查詢和文檔被表示為向量,其相似度通過向量夾角的余弦值表示:
(2)
其中
wt,t′=lg(N/ft′)+1,wd,t′=lg(fd,t′+1)
本文將查詢語句t中的一項表示為t′。fd,t′是項t′在文檔d中出現的頻率。N是文檔總數,ft′是包含項t′的文檔數目。
受詞錯誤率啟發,考慮到查詢翻譯子系統生成的N-best目標結果與單語語料庫候選譯文詞序上的一致性,本文在檢索模型中引入Levenshtein距離[12]計算查詢語句與候選文檔的最少編輯次數,以此作為衡量兩者相似性的特征之一。Levenshtein距離的加入使得候選文檔可以按對原查詢語言的忠實度排序,在語序上保持一致性,因此可以提高準確率,后文實驗中將對比加入Levenshtein距離和不加入Levenshtein距離的差異性。
用E(t,d)表示Levenshtein距離的得分,式(2)可寫為
E(t,d)λ2
同樣,λ值由MERT算法訓練。
2 翻譯檢索算法
結合兩個子系統,TR系統的算法可描述為兩階段。第一階段計算Pr(t|s)。為縮小解空間,只取源語言s的N-best譯文,生成集合Bn(s):
第二階段計算Pr(d|t)。限定候選文檔中必須至少包含查詢語的一項,令D(t)表示包含查詢項的文檔集合

算法偽代碼見算法1。給定一個中文查詢s,首先生成s的N-best譯文集合Bn(s),對每個屬于集合的t,計算對應的概率得分Pr′(t|s)。然后對包含查詢語的文檔集合D(t)計算其中每個文檔d的得分,最終對候選文檔進行排序。
算法 1:翻譯檢索算法
1)輸入中文查詢s;
2)由查詢翻譯子系統生成集Bn(s);
3)對每一個屬于Bn(s)的目標語句t
4) 計算Pr′(t|s);
5)對每一個屬于Bn(s)的目標語句t
6)N=0
7) 對每一個d∈D(t)
8) 計算Pr′(t|s);
9) 更新N=N+Pr′(d|t);
10) 對每一個d∈T(t)
11) 更新Pr(d)=Pr(d)+Pr′(t|s)×Pr′(d|t)/N;
12)返回n條排序過的候選文檔;
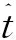
算法2:1-best翻譯檢索算法
1)輸入中文查詢s;
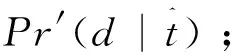
5)返回n條排序過的候選文檔;
3 實驗評估
本文在英漢數據集上進行了多組實驗,對比不同參數對最終結果的影響:
1) 不同個數的N-best譯文。N分別取1、5、10;
2)n元文法模型的n分別取3、4;
3) 是否加入Levenshtein距離。
3.1 數據集
融合檢索技術的譯文推薦系統是數據驅動的系統,采用的數據集由NiuTrans提供。細分為六個部分:
1) 翻譯模型訓練集,包含45 M條漢英平行語料和對應的對齊語料;
2) 語言模型訓練集,包含18 M條單語語料;
3) 優化調整數據集,包含130 k條中文語料以及其對應的參考譯文,用來進行最小錯誤率訓練;
4) 測試數據集,包含140 k條中文語句;
5) 標準譯文數據集,測試集的標準譯文(323 k);
6) 檢索文檔數據集,包含50 M英文語料(內含50%的標準譯文)。
對中文語料使用ICTCLAS2011進行分詞,并用空格隔開。漢英對齊來自GIZA++的結果。對英文語料做了符號化和大小寫規整的預處理。檢索的每個文檔由單個句子構成。
3.2 評測指標
本文采用目前應用最為廣泛的自動評測指標BLEU[13](bilingual evaluation understudy)。它是一種有效解決詞序作用的評測方法,考慮了機器翻譯譯文與參考譯文中較長n元文法的匹配情況。
通常將n元文法的最大階數設置為4,因此BLEU指標定義為
式中:T、R分別表示目標語言與標準譯文,Precisionn(T,R) 是n元文法的準確率,BP(brevity penalty)是一個長度懲罰因子。
在BLEU基礎上,加入人工評測,對結果進行準確率和召回率的評測,在返回的n條文檔中比較能否包含參考譯文。一般的,我們既不想輸出錯誤單詞也不想遺漏任何信息,因此同等的對待準確率和召回率,定義準確率和召回率的調和平均f測度[13](f-measure@n):
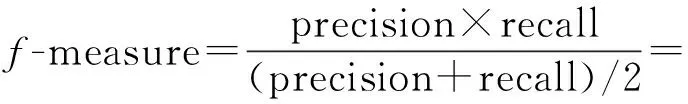
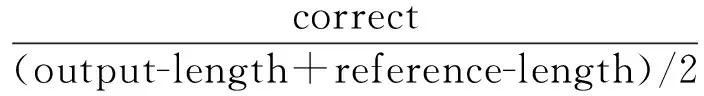
3.3 實驗結果
本文在漢英數據集上隨機地抽取了多組查詢語句對進行了實驗,對參數的不同取值做了對比實驗。
表1是在1-best條件下,不同階數語言模型下的5次實驗結果以及與Moses 4元文法的比較。
表1 不同階數下的BLEU值和與Moses的比較
Table 1 BLEU scores with differentn-gram setting and comparison with Moses 4-gram setting
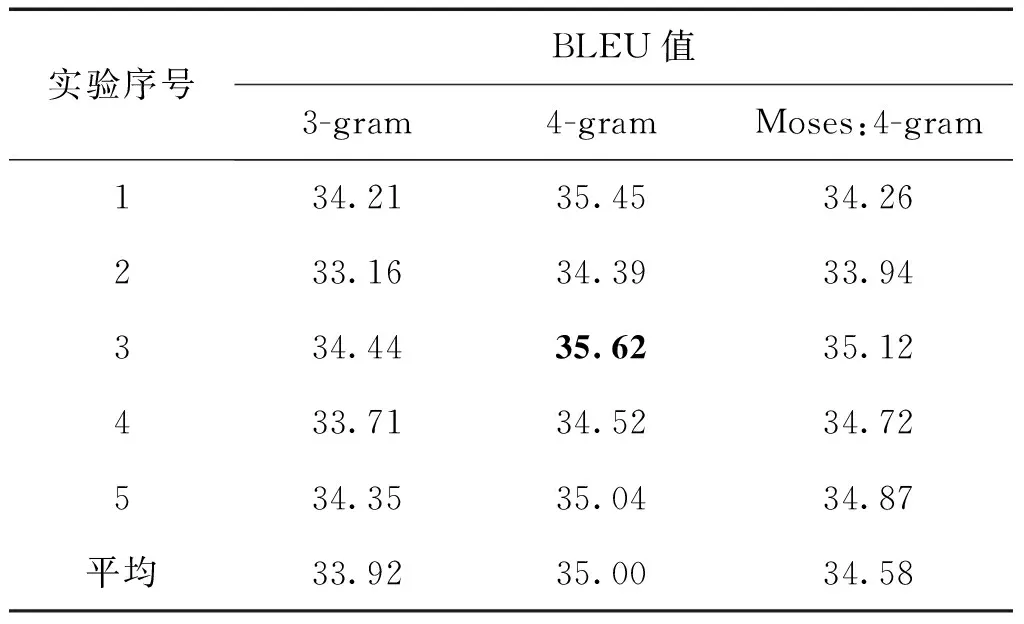
實驗序號BLEU值3-gram4-gramMoses:4-gram134.2135.4534.26233.1634.3933.94334.4435.6235.12433.7134.5234.72534.3535.0434.87平均33.9235.0034.58
從表1中可以看出在1-best條件下,4-gram的語言模型有較好表現,結果優于Moses的翻譯結果。
表2給出在4元文法基礎上不同N-best譯文和加入Levenshtein距離后的實驗結果。表中:-L表示不加入該距離,相反,+L表示加入。
表3給出加入Levenshtein距離條件下,不同N-best譯文的準確率(p)和召回率(r)結果:
表2反映了加入Levenshtein距離的改進效果。事實上,加入Levenshtein距離的檢索模型會考慮檢索語句與候選文檔間的編輯次數,這樣會顯著提高結果的召回率,同時,查詢翻譯模型的語言模型保證了譯文的流暢性,因此,加入Levenshtein距離也可以更好的提高最終結果的準確率,其f測度值也就更高。
表2 不同數量N-best譯文在加入/不加入Levenshtein距離下的f測度結果
Table 2f-measure results without/with Levenshtein-distance by using differentN-best translation
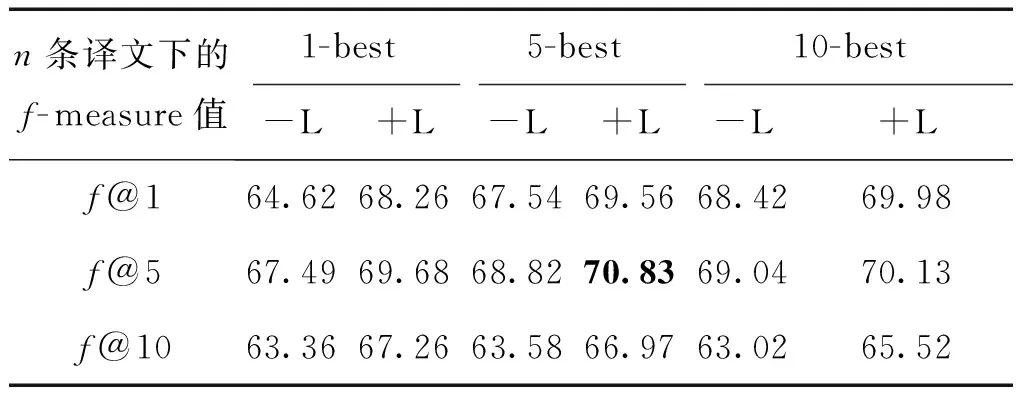
n條譯文下的f-measure值1-best5-best10-best-L+L-L+L-L+Lf@164.6268.2667.5469.5668.4269.98f@567.4969.6868.8270.8369.0470.13f@1063.3667.2663.5866.9763.0265.52
表3 不同數量N-best譯文的準確率與召回率結果
Table 3 Precision and recall results by using differentN-best translation
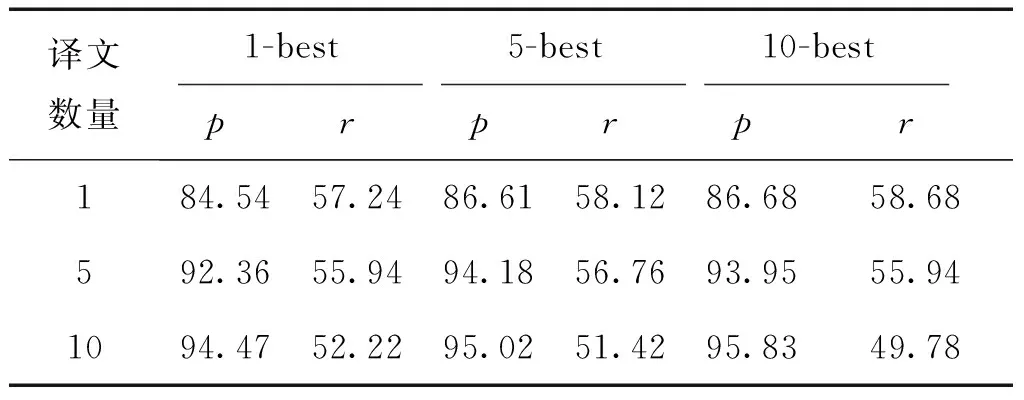
譯文數量1-best5-best10-bestp r p r p r184.5457.2486.6158.1286.6858.68592.3655.9494.1856.7693.9555.941094.4752.2295.0251.4295.8349.78
實驗結果也表明,在5-best譯文和f@5時系統得到最佳f測度值。從表3中可以看出在提供更多候選參考項目時,準確率會不斷升高,但其召回率將下降較多,因此,選用適量的候選項目有利于翻譯人員迅速準確的得到參考結果。
綜上,從本文在英漢的數據集上對實驗結果進行的自動評測(BLUE)和人工評測(f@n)結果看,BLEU指標優于目前主流的基于短語的機器翻譯系統(Moses)。但需要注意的是,BLEU指標只關注句子的局部,沒有更多地考慮整體語法的連貫性,所以系統在4元文法基礎上表現不錯,超出4元文法時就可能混亂。
由此,本文更加看重實驗結果的f測度,從表3看出,準確率高于召回率,這是利于實際應用的。事實上,融合檢索技術的譯文推薦系統旨在為翻譯人員提供參考,提高翻譯的流暢性,并不要求候選文檔與標準譯文完全匹配,因此候選文檔更多的包含標準譯文是更為重要的,即準確率更能反映出翻譯系統的性能。
4 結論
融合檢索技術的譯文推薦系統,將翻譯問題視作為檢索問題,可為翻譯人員提供高質量的參考譯文。檢索數據集的好壞很大程度決定了最終譯文的參考質量,而我們的系統可以方便的獲得大規模的單語語料集,與傳統的基于平行語料的翻譯系統相比有很大優勢。漢英數據集上的實驗表明:
1)與基于短語的翻譯系統相比,我們取得了更優的BLEU指標;
2)將Levenshtein距離加入檢索模型也可以提高f測度值并取得了最高70.83的f測度值。
未來,將把本文的成果運用到更多種類的雙語翻譯中。同時,進一步改進檢索模型,以求針對翻譯問題提供更為高效的檢索算法。
[1]FEDERICO M, BERTOLDI N. Statistical cross-language information retrieval using n-best query translations[C]//Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, NY, USA: ACM, 2003: 167-174.
[2]BALDWIN T, TANAKA H. The effects of word order and segmentation on translation retrieval performance[C]//Proceedings of the 18th Conference on Computational Linguistics. Stroudsburg, PA, USA: Association for Computational Linguistics, 2000: 35-41.
[3]Nirenburg S, DOMASHNEV C, GRANNES D J. Two approaches to matching in example-based machine translation[C]//Proceedings of the 5th International Conference on Theoretical and Methodological Issues in Machine Translation. 1993: 47-57.
[4]ZHAO Bing, VOGEL S. Adaptive parallel sentences mining from web bilingual news collection[C]//Proceedings of the 2002 IEEE International Conference on Data Mining. Maebashi City, Japan: IEEE Computer Society, 2002: 745-745.
[5]RESNIK P, SMITH N A. The Web as a parallel corpus[J]. Computational linguistics, 2002, 29(3): 349-380
[6]BERGER A, LAFFERTY J. Information retrieval as statistical translation[C]//Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Berkeley, California: ACM, 1999: 222-229.
[7]NG K. A maximum likelihood ratio information retrieval model[R]. 2006.
[8]WITTEN I H, BELL T C. The zero-frequency problem: estimating the probabilities of novel events in adaptive text compression[J]. IEEE transactions on information theory, 1991, 37(4): 1085-1094.
[9]NAVARRO G. A guided tour to approximate string matching[J]. ACM computing surveys, 2001, 33(1): 31-88.
[11]陳士杰, 張玥杰. 基于Lucene的英漢跨語言信息檢索[J]. 計算機工程, 2005, 31(13): 62-64.
CHEN Shijie, ZHANG Yuejie. English-Chinese cross-language information retrieval using Lucene system[J]. Computer engineering, 2005, 31(13): 62-64.
[12]XIAO Tong, ZHU Jingbo, ZHANG Hao, et al. NiuTrans: an open source toolkit for phrase-based and syntax-based machine translation[C]//Proceedings of the ACL 2012 System Demonstrations. Stroudsburg, PA, USA: Association for Computational Linguistics, 2012: 19-24.
[13]OCH F J. Minimum error rate training in statistical machine translation[C]//Proceedings of the 41st Annual Meeting on Association for Computational Linguistics. Stroudsburg, PA, USA: Association for Computational Linguistics, 2003: 160-167.
[14]LEVENSHTEIN V I. Binary codes capable of correcting deletions, insertions, and reversals[J]. Soviet physics doklady, 1966, 10(8): 707-710.
[15]科恩. 統計機器翻譯[M]. 宗成慶, 張霄軍, 譯. 北京: 電子工業出版社, 2012.
KOEHN P. Statistical machine translation[M]. ZONG Qingcheng, ZHANG Xiaojun, trans. Beijing: Publishing House of Electronics Industry, 2012.
Translation recommendation system with information retrieval technology
JIANG Zongli, WANG Wei
(College of Computer Science and Technology, Beijing University of Technology, Beijing 100124, China)
In this study, we apply a retrieval technology based on a monolingual corpus to machine translation and construct a Chinese-English translation recommendation system. The system solves the problem of conventional approaches that mainly rely on a parallel corpus, which is difficult to collect. It also improves the fluency of the final translation references. The translation recommendation system combines query-translation and information retrieval. For a given set of Chinese queries, the query-translation function generatesN-best English results and the information retrieval function computes the similarity of the query and the candidate translation. The two scores are weighted to return recommended translations. Considering the consistency of word order of theN-best results and the translation candidates, we use Levenshtein-distance to obtain more rational retrieval results. Experiments on English-Chinese data sets show that, under differentn-order language models, the proposed translation recommendation system demonstrates good performance and achieves a maximumf-measure value of 70.83% using Levenshtein-distance.
information retrieval (IR); machine translation (MT); natural language processing (NLP); monolingual corpus; Levenshtein-distance; recommendation system; cross-language
2016-01-14.
日期:2017-01-11.
國家自然科學基金項目 (61133003).
蔣宗禮(1956-),男,教授,博士生導師.
蔣宗禮,E-mail: jiangzl@bjut.edu.cn.
10.11990/jheu.201601053
TP391
A
1006-7043(2017)03-0419-06
蔣宗禮, 王威.融合檢索技術的譯文推薦系統[J]. 哈爾濱工程大學學報, 2017, 38(3):419-424.
JIANG Zongli, WANG Wei.Translation recommendation system with information retrieval technology[J]. Journal of Harbin Engineering University, 2017, 38(3):419-424.
網絡出版地址:http://www.cnki.net/kcms/detail/23.1390.u.20170111.1509.011.html
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
光學精密工程(2016年6期)2016-11-07 09:07:19
