基于似然比檢驗的工業小企業債信評級研究
2017-04-19 01:17:51趙志沖遲國泰
中國管理科學 2017年1期
趙志沖,遲國泰
(大連理工大學管理與經濟學部,遼寧 大連 116024)
基于似然比檢驗的工業小企業債信評級研究
趙志沖,遲國泰
(大連理工大學管理與經濟學部,遼寧 大連 116024)
債信評級是評價一筆債務償還的可能性或違約損失率。由于工業小企業貸款存在風險高、額度小、財務數據不真實等特點,使商業銀行無法準確對工業小企業貸款的信用風險進行科學評估。因此,構建一套合理的債信評級體系成為亟待解決的問題。本文一是構造某一個指標與違約狀態之間的邏輯回歸方程,通過對比僅含常數項的零模型的對數似然值與僅含有某一個指標的完整模型的對數似然值,構造χ2統計量,若有、無某指標時的兩個對數似然值偏差越大,則該指標對區分違約與非違約狀態的貢獻越大,該指標越易保留的思路對指標進行遴選,保證遴選出的指標都對違約狀態具有顯著的區分能力,彌補現有研究不以能否區分違約狀態對指標進行篩選的不足。二是通過計算同一準則層內任意兩個指標的相關系數,確定這兩個指標反映信息的重復程度,在相關系數大于某一閾值的兩個指標中,刪除χ2統計量小、即對違約狀態區分程度小的指標,既避免指標體系的信息冗余、又避免誤刪對違約狀態判別能力強指標。改變現有研究在相關系數大的指標中人為主觀刪除一個的弊端。三是通過提取中國某區域性商業銀行分布在全國28個城市分支行的貸款數據進行實證,建立了由資產負債率、成本利潤率、近三年企業授信情況等26個指標構成的適用于工業小企業信用風險評價的指標體系。四是通過對工業小企業進行債信評級,不僅得到每個小企業的信用等級,還得到每個貸款小企業對應的違約損失率,改變現有的信用評級研究僅僅計算貸款客戶的信用得分和進行評分排序的不足。
工業小企業;信用風險;評價體系;違約狀態;似然比檢驗
1 引言
債信評級不僅是對某一筆貸款進行評級,同時確定該筆貸款對應的違約損失率。如何控制眾多工業小企業的信用風險是商業銀行重點關注的問題之一。
小企業在國民經濟中扮演重要的角色。目前中國中小企業總數已經達到全國企業數量的99.9%,創造的產品及服務價值相當于GDP的60%,提供了80%以上的城鎮就業崗位。但是由于工業小企業貸款存在風險高、額度小、財務數據不真實等特點,使商業銀行無法準確對工業小企業貸款的信用風險進行科學評估。
建立合理可行的工業小企業債信評級體系具有重要意義:一是由于小企業財務信息不健全等現實原因,目前國內外還沒有針對工業小企業的債信評級體系,建立合理的債信評級體系,可以對小企業的信用狀況進行科學評估。二是通過對工業小企業信用等級進行合理劃分,測算不同等級貸款客戶的違約損失參數,為貸款定價提供決策參考。
國內外學者在信用風險評價指標體系、指標的篩選及綜合評價等方面進行了大量的研究。美國的標準普爾、穆迪及惠譽[1-2]三家典型國際評級機構構建了包括流動比率、資產報酬率等反應小企業清償能力的信用風險評價指標體系。中國工商銀行[3]建立了針對小企業客戶的、包括資產負債率、法人代表基本情況、行業景氣指數等指標的信用評價指標體系;中國建設銀行[4]建立了包括主營業務利潤率、貸款客戶歷史有無違約等指標的綜合評價指標體系。Dainelli等[5]建立了包括盈利能力、償付能力、流動性狀況和信貸質量共4個準則的中小企業信用評級體系。Van Laere等[6]建立了包括資產收益率、行業類型、EBITDA/銷售收入等反映企業償債能力的信用評級指標體系。高麗君[7]通過貝葉斯模型估計了企業產權比率、資產負債率、企業過去償還歷史等指標對企業信用違約風險具有重要影響。衣柏衡等[8]提出一種改進SMOTE的SVM分類算法,以小額貸款公司客戶為樣本構建了包括個人、信用、借款和擔保四個維度的信用風險評估指標體系。遲國泰等[9]通過偏相關分析和綜合判別能力相結合,構建了16個指標構成的農戶小額貸款信用評價指標體系。Shi Baofeng等[10]利用多重共線性對反映信息重復的指標進行篩選,利用邏輯回歸顯著判別遴選出對違約與非違約兩類樣本具有顯著性區分的關鍵指標。Hai Lingping等[11]利用相關分析刪除了反映信息重復的指標,利用顯著性判別的方法篩選出對農戶貸款違約狀態影響顯著的指標,建立了包括貸款用途、地區GDP增長率等13個指標的農戶貸款信用風險評價體系。謝威等[12]利用變異系數法和灰色關聯分析法,對海選指標體系進行了修正。霍海濤[13]通過因子分析法和調查問卷法確定高科技中小企業信用風險評價指標體系并對體系的有效性進行驗證。Zhang Zhiwang等[14]基于內核、模糊性、懲罰因子提出了一種新穎的多目標分類模型KFP-MCOC,構建了信用風險評分模型。Terry Harris[15]采用支持向量機的方法構建了巴巴多斯信貸聯盟的信用評價得分模型。Chi Bo-wen等[16]通過遺傳算法結合銀行內部評分模型與外部信用局評分模型,構建了雙重信用風險評價模型對銀行貸款客戶進行信貸風險管理。盧超等[17]利用因子分析和Logistic回歸建立了中小企業信用風險評價模型,并計算了各個企業的違約概率。柳玉鵬等[18]利用信息熵確定評價準則的權重,利用偏好順序結構評估法確定了貸款客戶的貸款順序,并驗證了該方法在銀行信用風險評價中的有效性。張大斌[19]等利用差分進化自動聚類模型對上市公司的信用風險進行評價,并通過數據仿真進行了實證分析,確定該種評價方法具有較高的信用評估準確性。陳曉紅[20]等利用改進模糊綜合評價模型AFF模型對中小企業進行信用評估。該模型能準確地得到公司的信用等級。Doumpos等[21]利用多標準分類模型構建了一種包含公司的預測財務數據和信息披露程度的多標準的信用評級模型。Jones等[22]在比較了多種分類方法的優劣后,選擇了logit回歸與probit回歸構建了國際信用評級體系,其中金融、市場、公司內部政策、宏觀經濟等方面的因素均被考慮。
綜上可知,現有研究存在的主要問題有以下三點:一是沒有建立針對工業類型的小企業的債信風險評價指標體系。二是現有的篩選方法不能保證篩選出的指標都能對客戶違約與非違約進行顯著性判別,即對違約狀態不具有顯著性區分。三是現有評價體系中指標冗余,反映信息重復,不利于銀行實際操作。
本文的特色與創新主要體現在以下三個方面:一是構造某一個指標與違約狀態之間的邏輯回歸方程,通過對比僅含常數項的零模型的對數似然值與僅含有某一個指標的完整模型的對數似然值,構造χ2統計量,若有、無某指標時的兩個對數似然值偏差越大,則該指標對區分違約與非違約狀態的貢獻越大,該指標越易保留的思路對指標進行遴選,保證遴選出的指標都對違約狀態具有顯著的區分能力,彌補現有研究不以能否區分違約狀態對指標進行篩選的不足。二是通過計算同一準則層內任意兩個指標的相關系數,確定這兩個指標反映信息的重復程度,在相關系數大于某一閾值的兩個指標中,刪除χ2統計量小、即對違約狀態區分程度小的指標,既避免指標體系的信息冗余、又避免誤刪對違約狀態判別能力強指標。改變現有研究在相關系數大的指標中人為主觀刪除一個的弊端。三是通過對工業小企業進行債信評級,不僅得到每個小企業的信用等級,還得到每個貸款小企業對應的違約損失率,改變現有的信用評級研究僅僅計算貸款客戶的信用得分和進行評分排序的不足。
2 工業小企業債信風險評級的原理
(1)科學問題的性質
債信評級不僅是對某一筆貸款進行評級,同時確定該筆貸款對應的違約損失率。債信評級體系的建立必須能夠顯著區分客戶的違約狀態。
(2)問題的難點
難點一:如何保證評級指標體系中的每一個指標都能對違約狀態具有顯著性區分能力。
難點二:如何避免評級指標反映信息冗余,并在反映信息重復的兩個指標之間保留對違約狀態影響顯著的指標。

圖1 工業小企業債信風險評級的原理
難點三:如何通過債信評級確定每一筆債務或貸款對應的違約損失率。
(3)解決難點的思路
難點一的解決思路:通過似然比檢驗篩選出對違約狀態有顯著影響的指標,即構造某一個指標與違約狀態之間的邏輯回歸方程,通過對比僅含常數項的零模型的對數似然值與含有某一個指標的完整模型的對數似然值,構造似然比統計量,若有、無該指標時的兩個對數似然值偏差越大,則該指標對區分違約與非違約的貢獻越大,指標越易保留。
難點二的解決思路:通過計算同一準則層內任意兩個指標的相關系數,確定指標反映信息的重復程度,在相關系數大于某一閾值的兩個指標中,刪除χ2統計量小、即對違約狀態區分程度小的指標。
難點三的解決思路:通過與商業銀行合作,獲取包括違約樣本小企業貸款數據,確定每一筆貸款的違約損失率。
基于似然比檢驗的工業小企業債信評級研究原理如圖1所示。
3 信用風險評價的模型
3.1 指標數據的標準化處理
(1)正向指標標準化處理
正向指標指數值越大對評價結果越好的指標。
設:xij-第i個指標第j個企業的標準化值;vij-第i個指標第j個企業的實際值;m-企業數。根據正向指標標準化公式[23]:
(1)
(2)負向指標標準化處理
負向指標指數值越小對評價結果越好的指標。負向指標標準化公式[23]為:
(2)
(3)區間指標標準化處理
區間指標指數值在某一特定區間[q1,q2]內最好,距離該區間越近對評價結果越好的指標。區間指標標準化公式[23]為:
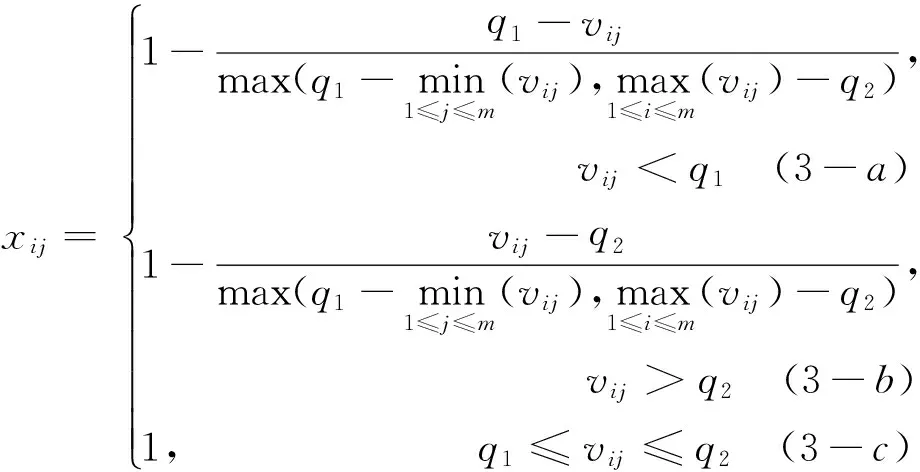
下文實證中有2個區間指標,分別是“年齡”、“居民消費價格指數”。其中,年齡指標的最佳區間是[31,45][20],即左右端點分別是q1=31,q2=45;居民消費價格指數的最佳區間是[101,105][20],即左右端點分別是q1=101,q2=105。
(4)定性指標標準化處理
定性指標指無法直接用定量方法進行評價的指標。例如學歷、性別、婚姻狀況等。
將定性指標分為不同的檔次,按照從高到低不同的檔次進行打分,將定性指標轉化為[0,1]區間內的定量數據,定性指標的評分標準如表1所示。

表1 定性指標的打分標準
3.2 指標篩選的方法
3.2.1 第一次篩選
基于似然比檢驗篩選指標的目的:保留能夠顯著區分違約與非違約兩種狀態的指標,刪除對違約狀態影響不顯著的指標。
似然比檢驗步驟:
(1)構造邏輯回歸方程:設yk-第k個客戶的違約狀態(yk=1代表違約,yk=0代表非違約),Pk(y=1)-第k個客戶違約的概率,zk-隱變量,xjk-第j個指標第k個客戶的標準化后數據(j=1,2,…,m,k=1,2,…,n),0、k-待估系數,uk-誤差項。
則邏輯回歸方程[25]為:
(4)
(5)
其中,zk=0+kxjk+uk
式(4)的含義:指標xjk與違約概率Pk(yk=1)之間的非線性關系,回歸系數k越大,說明第j個指標xjk對第k個客戶違約概率大小的影響程度越大。
式(5)的含義:指標xjk與非違約概率Pk(yk=0)之間的非線性關系,系數k越大,說明第j個指標xjk對第k個客戶違約概率大小的影響程度越大。
(2)構造對數似然函數LL[25]:
(6)
式(6)的含義:全部n個小企業貸款客戶同時違約的概率的對數值。
(3)采用極大似然估計模型參數:
零模型:式(4)-(5)中僅含有常數項、不含有任何指標的模型。零模型中zk=α0+uk。
完整模型:式(4)-(5)中含有常數項、指標xk的模型。完整模型中zk=0+kxk+uk。
以對數似然函數LL最大為目標,采用極大似然估計對零模型和完整模型中zk的系數進行估計,并將估計值代入式(6),得到零模型的對數似然函數值LL0,完整模型的對數似然函數值LLV。
(4)構造χ2統計量,進行顯著性檢驗:
LL0-僅含有常數項的零模型的對數似然值;LLV-含有某一個指標xk的完整模型的對數似然值,則χ2統計量為:
χ2=-2(LL0-LLV)
(7)
自由度等于完整模型中變量個數與零模型中變量個數個差,即自由度df=1。
給定顯著性水平α=0.05,通過查χ2分布表,確定P{χ2(1)>χα2(1)},若P{χ2(1)>χα2(1)}<α=0.05,則拒絕原假設H0,即k≠0,認為指標xk對違約狀態具有顯著性區分[25]。
式(7)的含義:通過對比不含任何指標、僅含常數項的零模型的-2倍對數似然值LL0與含有某一個指標的完整模型的-2倍對數似然值LLV,若兩個對數似然值的偏差越大,越易通過檢驗,該指標越能區分違約與非違約狀態。
(5)重復步驟(1)-(4),對其他指標依次進行似然比檢驗,判斷指標是否對違約狀態有顯著性影響。
通過似然比檢驗篩選指標的特色:構造某一個指標與違約狀態之間的邏輯回歸方程,通過對比僅含常數項的零模型的對數似然值與含有某一個指標的完整模型的對數似然值,構造似然比統計量,若有、無某指標時的兩個對數似然值偏差越大,則該指標對區分違約與非違約狀態的貢獻越大,該指標越易保留。保證了篩選出的指標都能顯著區分違約與非違約狀態,彌補現有研究不以能否區分違約狀態對指標進行篩選的不足。
3.2.2 第二次篩選
通過相關性分析篩選指標的目的:刪除在同一準則層內相關系數大于某一閾值M的指標,避免反映信息冗余。
選擇準則層內做相關分析的原因:避免因為數值相關、實際意義不相關的指標被誤刪的弊端。
相關分析的步驟:

(8)
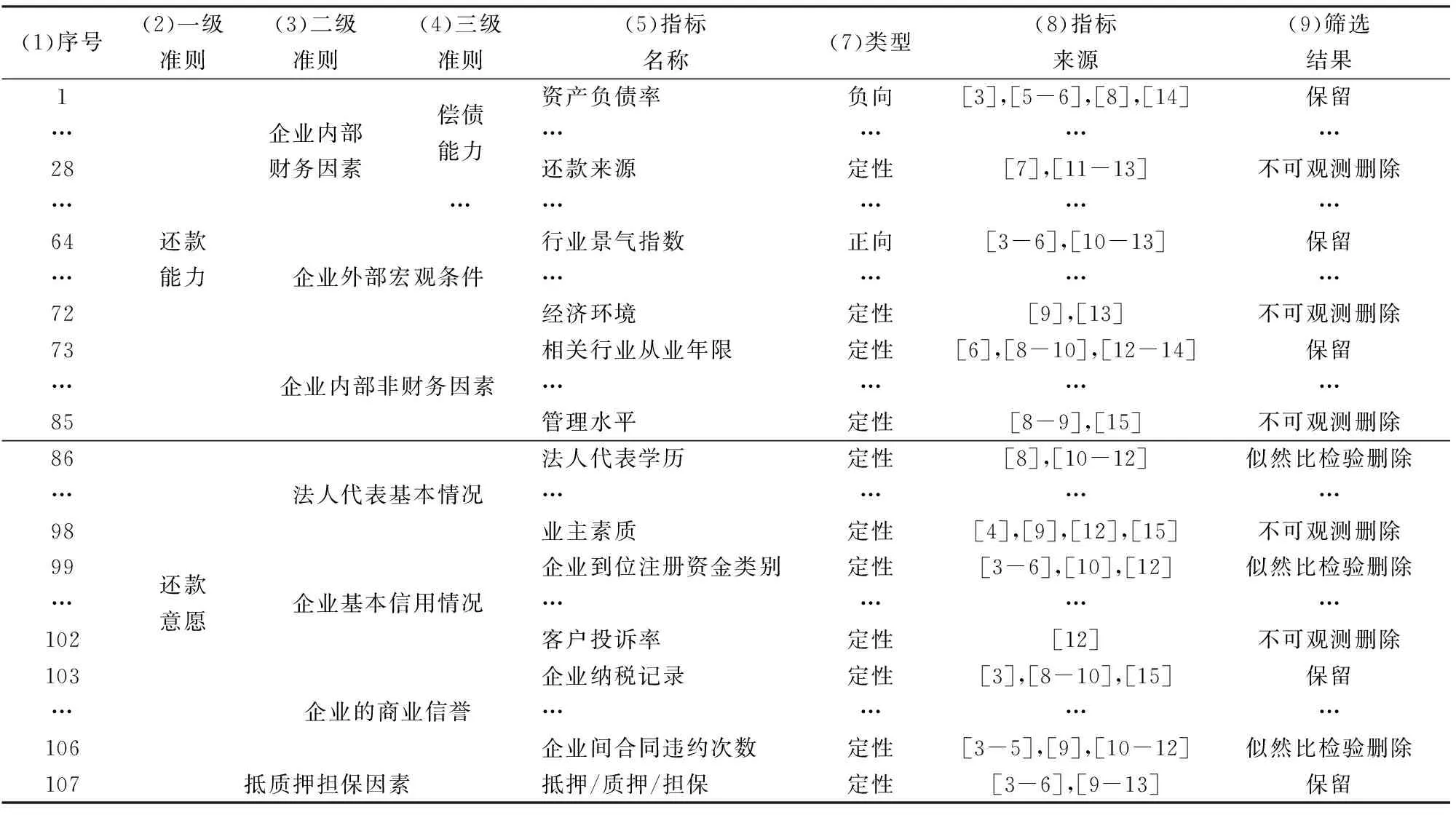
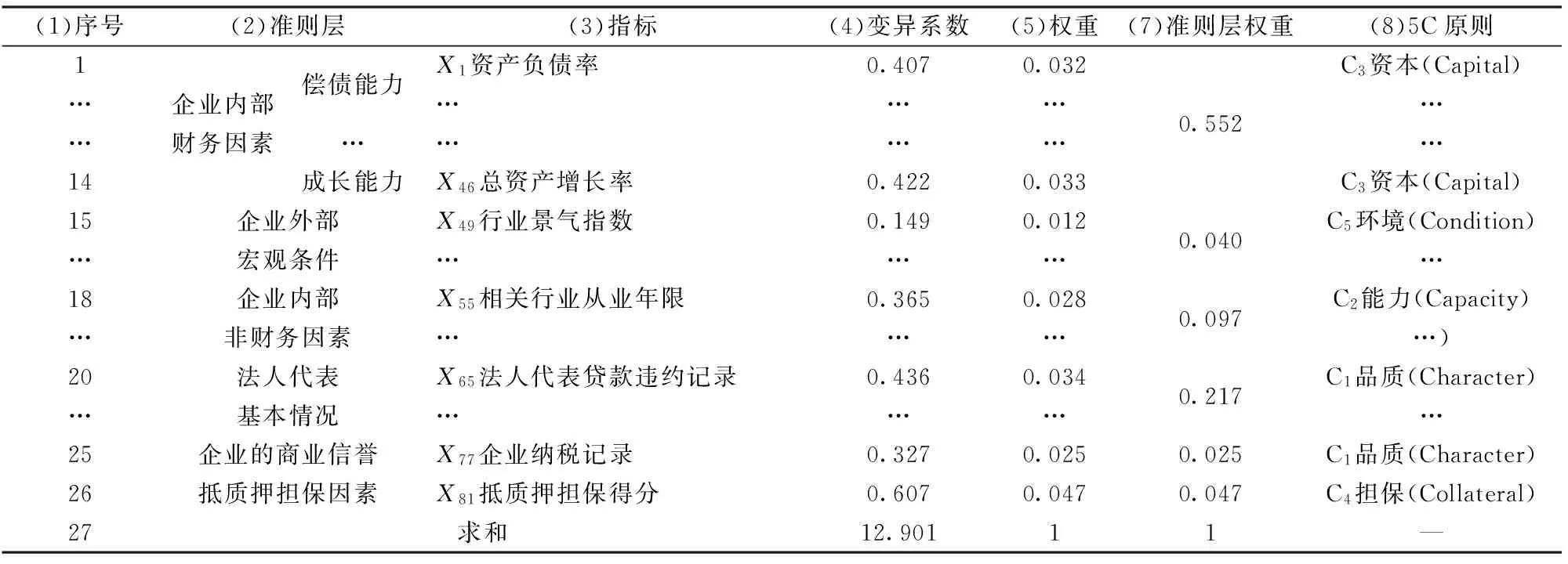
(2)指標相關性篩選:設:M-臨界值,此處M=0.8[23]。若rij 通過計算同一準則層內任意兩個指標的相關系數,確定這兩個指標反映信息的重復程度,在相關系數大于某一閾值的兩個指標中,刪除χ2統計量小、即對違約狀態區分程度小的指標,既避免了指標體系的信息冗余、又避免了誤刪對違約狀態判別能力強指標。改變現有研究在相關系數大的指標中人為主觀刪除一個的弊端。 3.3 指標權重和評價方程的確定 3.3.1 權重的計算 通過變異系數對指標進行賦權,變異系數衡量指標數據離散程度,某一個指標的變異系數越大,該指標的數據越離散,反映的信息含量越大,對應的權重也就越大。 (9) 對變異系數vi進行歸一化處理,得到第i個指標的權重wi為: (10) 式(10)的含義:指標的變異系數vi反映了該指標在債信評價中的鑒別能力。變異系數越大,表明該指標在債信評價中的信息含量越大,指標的信息分辨能力越強,權重wi也越大。 3.3.2 評價方程的確定 (1)評價得分的計算: 設pk-第k個企業的評價得分,wi-第i個指標的權重,xik-第i個指標第k個小企業的標準化值,則第k個工業小企業評價方程為: (11) 式(11)的含義:式(11)即為工業小企業債信風險評價方程。通過評價方程計算每個客戶的債信得分,得分越高,對應的客戶的債信狀況越好。 (2)評價得分的標準化: 設Pk-第k個工業小企業債信評價標準化得分,pk-第k個企業的評價得分,則第k個工業小企業客戶標準化的債信得分為[23]: (12) 式(12)的作用:將債信評價得分轉化為0-100之間,更能直觀地反映客戶的債信狀況,債信得分越高,客戶的債信狀況越好。 3.4 債信等級的劃分 劃分標準:根據債信等級越高、違約損失率越低的金字塔標準對客戶進行債信等級劃分。 劃分思路:通過將計算的每個客戶的債信得分按照從高到低進行排序,并將所有的客戶按照人數均勻的劃分為9個等級,計算每個等級的違約損失率,并用金字塔標準、即債信等級越高違約損失率越低的標準進行檢驗。 若不滿足金字塔標準,則通過調整每個等級的分數、從而伴隨每個等級的違約損失率的變化,使得調整后的債信等級滿足債信等級越高違約損失率越低的金字塔標準。 劃分方法:每調整一次債信等級的分數,就會改變這個等級的貸款客戶的數量,進而改變這個等級的違約損失額和違約損失率。因此,債信等級得分的調整會導致該債信等級違約損失率的變化。通過這種調整,總可以得到債信等級越高、違約損失率越低的、合理的債信等級劃分結果。這種債信等級劃分方法可參加我們科研團隊在這方面的研究[26]。 4.1 指標的海選 以美國的標準普爾、穆迪及惠譽[1-2]三家典型國際評級機構,中國建設銀行[3-4]等國內主要金融機構經典觀點的高頻指標為重點,結合文獻的梳理,建立工業小企業債信風險評價指標海選體系,海選了107個指標。107個海選指標如表2所示。 通過數據可觀測原則,剔除了還款來源等數據無法獲取的指標,海選了數據可獲取的81個信用風險評級指標。 4.2 樣本的選取與數據分析 (1)研究對象的確定 不同行業的特點各不相同,其對違約狀態具有顯著判別能力的指標也不盡相同。因此、根據不同行業建立不同的債信評級體系是理所當然的。本研究建立的是工業小企業的債信評級體系。 這里的小企業樣本,是根據中國工業和信息化部等四部委的《中小企業劃型標準規定》(工信部聯企業[2011]300號)[27]標準中定義的工業小企業。即從業人員20人以上1000以下,且營業收入300萬元以上40000萬元以下的工業企業。 (2)樣本選取 提取中國某區域性商業銀行在全國28個城市分支行的工業行業小企業貸款數據,數據時間跨度是1994年5月-2012年9月,共有1814筆借據,其中違約樣本15筆,非違約樣本1799筆。 將數據可獲取的81個指標按照順序分別以X1,X2,…,X81標注,列入表3第c列。表3共由3部分構成,表3前段第1-1814列是提取的原始數據,記為矩陣(vij);表3最后兩列是每行對應原始數據vij的最大值和最小值;表3中段第1-1814列是對原始數據標準化后的數據,記為矩陣(xij),標準化過程詳見下文4.3。 (3)數據分析 在選取的1814筆工業小企業貸款數據中,違約樣本為15筆,非違約樣本為1799筆。選取兩種比例差距大的樣本進行研究的原因主要有兩點: 一是在中國商業銀行的貸款中,小違約樣本的現象是普遍存在的。本研究選取的樣本是中國某商業銀行1994年以來20年的實際發放的1814筆工業小企業貸款數據,實際上違約的樣本僅包括15筆。 二是以銀行實際發放的全部貸款為樣本,不對樣本進行挑選,不僅能保證數據滿足銀行實際違約樣本與非違約樣本的比例,還可以保證測算的不同債信等級違約損失率是銀行真實的違約損失率。 4.3 海選指標數據的標準化 (1)定量指標的標準化處理 分別按照表2第7列正向、負向指標的類型,將指標的原始數據vij代入相應類型的指標標準化處理公式中(1)-(2)中,對指標數據進行處理。以正向指標“現金比率”的標準化處理為例進行說明: 將表3第14行第1列v14,1=0.95,表3后段第1行max(v14,j)=2.82、min(v14,j)=0代入式(1),得到標準化數據x14,1=0.337,列入表3中段第14行第1列;類似對該指標下其他客戶的數據進行標準化處理,分別列入表3中段第14行其他列。同理,對其他定量指標標準化處理。結果列入表3中段第1-1814列相應行。 表2 工業小企業債信風險評價的海選指標集 如前所述,年齡和居民消費價格指數是區間型指標,上文已給出這兩個指標的左右端點,將表3前段指標數據vij帶入區間指標標準化公式(3-a)-(3-c)進行處理,將結果xij列入表3中段相應行。 (2)定性指標的標準化處理 根據3.1(4)所列定性指標評分方法,將“擔任該職務的時間”等定性指標轉化為[0,1]區間內的值。 以指標“擔任該職務的時間”為例,如表3第74行第1列所示,借據為200412140029的樣本數據缺失,根據表1第4行第3列的評分標準,數據缺失評分為0,所以將評分后的數據0列入表3中段第74行第1列。類似的,對其他借據對應的數據進行標準化,列入表3第74行其他列。同理對其他定性指標進行標準化處理。 4.4 工業小企業債信風險評價指標體系的建立 4.4.1 基于能否顯著區分違約狀態的第一次篩選 以指標“資產負債率”為例,說明能否顯著區分違約狀態的指標篩選過程。 (1)構造不含任何指標的邏輯回歸方程: 在表3第82行中:將中段第1至第1814列的數據分別代入式(4)-(5)的左端,采用極大似然估計估計系數0=-4.787,此過程可通過SPSS軟件完成。 (2)求解不含指標、僅有常數項的對數似然值: (3)構造含指標“資產負債率”的邏輯回歸方程: 將表3中段第1-1814列中,第82行數據yk、第1行指標“資產負債率”的數據x1k分別代入式(4)-(5),采用極大似然估計估計系數0=-3.419,1=-2.956。此過程可由SPSS軟件完成。 (4)求解指標“資產負債率”的對數似然值: (5)求解χ2統計量: 將上文(2)中求解的LL0=-86.866,(4)中求解的LL1=-82.876,代入式(7),得到χ2=7.980,列入表4第1行第3列。 (6)顯著性檢驗:給定顯著性水平α=0.05,通過查χ2分布表,χ0.052(1)=3.841。因為表4第3列的χ2(1)=7.980>χ0.052(1)=3.841,拒絕原假設,即1≠0,指標“資產負債率”對違約狀態具有顯著性區分。 對通過檢驗的指標在表4第5列中用“√”標識。同理計算其他指標的χ2值,列入表4第3列相應行。 由表4第5列的檢驗結果可知,最終保留了對違約狀態具有顯著性區分能力的資產負債率、流動負債經營活動凈現金流比率、抵質押得分等32個指標,刪除了81-32=49個對違約狀態具有區分不顯著的指標。 4.4.2 基于信息冗余分析的第二次篩選 (1)計算任意兩個指標之間的相關系數 經過上述4.4.1中第一次篩選,刪除了49個指標,剩余32個指標。 對表3中剩余的32個指標中任意兩行的標準化數據xik、xjk代入式(8),得到32行的相關系數矩陣(rij),如表5所示。 (2)同一準則層內指標相關性篩選 若rij<0.8[23],則同時保留第i個和第j個指標這兩個指標;若rij≥0.8,則在第i個和第j個指標間存在高相關性,刪除這兩個指標中χ2小、即對違約狀態判別能力弱的指標。 如表5所示,“資產負債率”與“股東權益比率”之間的相關系數是0.997,大于0.8,所以這兩個指標中應該刪除一個。由表4可知,資產負債率指標的χ2=7.980,股東權益比率指標的χ2=7.939,所以刪除χ2值小的“股東權益比率”指標。 同理,對其他相關系數大于0.8的一對指標進行判別刪除。 經過相關分析刪除“流動負債經營活動凈現金流比率”、“股東權益比率”等6個相關性大、反映信息重復的指標,保留了32-6=26個指標,如表6第3列所示。 4.4.3 工業小企業債信風險評價指標體系 在數據可觀測的81個海選指標中,通過第一次篩選刪除49個對違約狀態影響小或無影響的指標,通過第二次篩選刪除6個反映信息重復的指標,所以共保留了81-49-6=26個指標,如表6第3列所示。 4.5 工業小企業債信評價指標權重的確定和評價方程的建立 4.5.1 基于變異系數的指標賦權 對上文4.4中保留的26個指標進行賦權,因此這里的數據處理只與表3中這些被保留的指標數據有關。以指標“資產負債率”為例說明指標權重的求解:對表3中段的xij形成的常數矩陣處理,將第1行第1-1814列xij求指標資產負債率均值為0.544。 將表3中段xij數據的第1行第1-1814列標準化數據及均值0.544代入式(9),求解指標資產負債率的變異系數v1=0.407,列入表6第1行第4列。同理得到表6第4列其他行數據。 在表6第4列中,將前26行數據求和,結果為12.901,列入第27行。以表6第4列數為分子,分別除以該列最后一個數,得到權重如第5列所示。在表6第5列中,將前14行的數據求和,得到企業內部財務因素準則層的權重為0.552,列入表6第6列第一個數。同理得到表6第6列其他數。 4.5.2 評價方程的建立 將表3中1815-3628列數據按照篩選出的指標順序進行重新排序,列入表7第4-1817列。將表6第5列計算的權重wi列入表7第1818列。 將表7第1818列的權重wi代入式(11),確定第k個工業小企業債信風險評價方程為: pk=0.032xk1+0.086xk2+…+0.047xk,26 (13) 式(13)的含義:式(13)即為工業小企業債信風險評價模型,若pk越大,則第k個企業的評價得分越高,即企業的債信越好。 表5 指標間的相關系數 表6 工業小企業債信風險評價指標體系 以借據號為200411120136的企業為例,將表7第4列第1-26行對應的26個指標的標準化數據xki代入式(13),計算該企業的評價得分p1=0.156,列入表7第27行第4列,同理計算其他1813個客戶的評價得分,列入表7第27行第5-1817列。 其中,計算出的評價得分的最大值是借據為X2010041600009的客戶對應的得分0.677,評價得分最小值是借據200601090008的客戶對應的得分0.048。將計算的每個客戶的債信得分,及債信得分的最大值0.677、債信得分的最小值0.048代入式(12),對債信得分進行標準化,轉化為0-100之間的數,將結果列入表7第28行第4-1817列。 4.5.3 債信評分模型的合理性檢驗 每一個小企業對應一個債信得分,同時也對應一個違約狀態,將債信得分作為一個指標,按照4.4.1中指標第一次、能否顯著區分違約狀態的篩選過程,計算債信得分的χ2統計量為: χ2=-2(-86.866-(-47.860))=78.014 檢驗結果:通過查χ2分布表,在顯著性水平α=0.05下,χα2(1)=3.841,而計算出的χ2(1)=78.014,遠大于3.841,通過顯著性檢驗。因此,建立的債信評分模型是能夠顯著區分違約狀態、是合理的。 4.6 工業小企業債信等級的劃分 (1)債信等級的初步劃分 將表7第28行第4-1817列的每個客戶的債信得分按照從大到小的順序進行排序,并按照樣本數隨機劃分為9個等級。計算每個等級的違約損失率,即等于該等級所有樣本的應收未收本息和與應收本息和的比值。若債信等級越高、違約損失率越低,則該等級劃分方式是合理的。反之,則需要對債信等級進行調整。 (2)債信等級的調整 對每個等級的得分進行調整,相應的客戶數、違約損失率也發生變化,直至滿足債信等級越高、違約損失率越低的金字塔標準后停止調整。 由于債信等級劃分方法不是本研究的主要內容,而且這種方法很難,例如,每調整一個等級的人數,相鄰兩個等級的人數及違約損失率均會發生變化,若同時調整多個等級變化更是復雜,人工計算是不可行的,需要借助計算機程序。此文僅列債信等級劃分結果。債信等級劃分方法詳見我們團隊在這方面的研究[22]。債信等級劃分結果如表8所示。 表7 債信得分的計算 表8 工業小企業債信等級劃分結果 從表8第3列可知,工業小企業債信等級從高到低,即從AAA到C等級,對應的違約損失率從低到高變化,滿足債信等級越高、違約損失率越低的金字塔原理。債信等級金字塔如圖2所示。 圖2 工業小企業債信等級金字塔 4.7 工業小企業債信風險評級體系合理性判定 (1)符合債信等級越高、違約損失率越低的標準 根據4.6中債信等級的劃分,可知本研究建立的工業小企業債信風險等級的劃分滿足債信等級越高、違約損失率越低的標準。 (2)建立的工業小企業債信風險評價指標體系滿足國際金融界普遍認可的5C原則 一是通過“近三年企業授信情況”、“企業納稅記錄”等3個指標反映了品質(Character)原則,如表6第7列的符號C1所示。 二是通過“主營業務收入現金比率”、“成本利潤率”等14個指標反映了能力(Capacity)原則,如表6第7列的符號C2所示。 三是通過“資產負債率”、“速動比率”等5個指標反映了資本(Capital)原則,如表6第7列的符號C3所示。 四是通過“抵質押擔保得分”指標反映了擔保(Collateral)原則,如表6第7列的符號C4所示。 五是通過“行業景氣指數”、“城市居民人均可支配收入”等3個指標反映了經營環境(Condition)原則,如表6第7列的符號C5所示。 (3)體系中指標能顯著區分違約與非違約狀態 一些看起來應該納入體系中的指標被剔除,因為這些指標不能顯著區分違約與非違約狀態。例如 “現金比率”,“利潤增長率”等指標,看起來對工業小企業債信風險評價具有很大影響,應該納入評價指標體系,但是經過4.4.1的實證,可知這些指標未通過似然比檢驗,是對違約狀態無顯著性影響的指標,應該剔除。 因此,本研究建立的評價指標體系中的指標都能夠顯著區分違約與非違約狀態。 (4)體系中囊括了宏觀經濟指標 當行業或地區經濟不景氣的時候,一些大中型企業會受影響,而小企業由于抵御風險能力較差,會受到更嚴重的影響。經過上文4.4的兩步篩選后,本研究建立的評級指標體系中含有“行業景氣指數”這一反映行業的宏觀指標;又含有“城市居民人均可支配收入”這一反映地區經濟條件的指標。 (5)體系中囊括了抵質押擔保因素 由于小企業貸款的違約風險較大,銀行在給小企業發放貸款時對抵質押擔保的要求比較高。本研究建立的評級指標體系中含有抵質押擔保因素,并經過實證驗證該指標能夠顯著區分違約與非違約狀態。 (6)體系中非財務指標占有重要地位 小企業由于財務信息不健全等特點決定了非財務因素在債信風險評級時占有重要地位。根據表6第6列不同準則層的指標權重和可知,本研究建立的評級體系中非財務因素的權重占比高達41.2%,高于一般銀行設定的非財務因素權重占比30%[4]。 本研究以中國某區域性商業銀行分布在全國28個城市分支行的貸款數據為實證樣本,建立了由資產負債率、成本利潤率、近三年企業授信情況等26個指標構成的適用于工業小企業債信風險評價的指標體系。其中,通過有、無某一指標時兩個對數似然值偏差越大,指標對區分違約與非違約狀態的貢獻越大,指標越易保留的思路進行指標第一次篩選,保證建立的信用風險評價指標體系中的每一個指標都能顯著區分違約與非違約狀態。通過指標間相關系數越大、指標反映信息越重復的思路進行指標的第二次篩選,剔除評級體系中反映信息冗余的指標。 在建立的債信風險評價體系的基礎上,對貸款客戶進行了信用風險評價,不僅確定了客戶的信用水平高低排序,還確定了不同債信等級違約損失率的大小,便于銀行根據客戶信用等級確定貸款的違約風險補償。 本研究建立的債信評級體系不僅適用于銀行的貸款,對債券、公司債等信用工具的評級均適用。 在構建債信評級指標體系時,本研究以指標是否具有違約鑒別能力、即是否能夠顯著區分違約與非違約狀態為標準進行指標篩選,這能保證體系中的每一個指標都具有違約鑒別能力。如何保證評級體系整體具有違約鑒別能力是進一步深入研究的主要問題。 [1] White L J. Markets: the credit rating agencies[J]. Journal of Economic Perspectives. 2010, 24(2): 211-226. [2] 徐廣軍, 倪曉華. 標普、穆迪、鄧白氏企業信用評價指標體系比較研究[J].浙江金融. 2007, 3(5): 51-52. [3] 中國工商銀行. 關于印發《中國工商銀行小企業法人客戶信用等級評定辦法》的通知[Z]. 中國工商銀行, 工銀發[2005]78號. [4] 中國建設銀行. 中國建設銀行小企業客戶評價辦法[Z].中國建設銀行, 2007: 1-8. [5] Dainelli F, Giunta F, Cipollini F.Determinants of SME credit worthiness under Basel rules: The value of credit history information[J]. PSL Quarterly Review. 2014, 66(264): 21-47. [6] Van Laere E, Baesens B. The development of a simple and intuitive rating system under Solvency II[J]. Insurance: Mathematics and Economics, 2010,46(3): 500- 510. [7] 高麗君. 基于貝葉斯模型平均生存模型的中小企業信用風險估計[J]. 中國管理科學, 2012, 20(S1): 327-331. [8] 衣柏衡,朱建軍,李杰.基于改進SMOTE的小額貸款公司客戶信用風險非均衡SVM分類[J]. 中國管理科學, 2016, 24 (3): 24-30. [9] 遲國泰, 潘明道, 程硯秋. 基于綜合判別能力的農戶小額貸款信用評價模型[J]. 管理評論, 2015, 27(6): 42-57. [10] Shi Baofeng, Chi Guotai. A model for recognizing key factors and applications thereof to engineering [J]. Mathematical Problems in Engineering,2014,2014(1):368-381. [11] Hai Lingpeng, Shi Baofeng, Peng Guorong. A credit risk evaluation index system establishment of petty loans for farmers based on correlation analysis and significant discriminant [J]. Journal of Software. 2013, 8(10): 2344-2351. [12] 謝威, 趙嵩正, 徐林. 商業銀行信息科技風險評價指標篩選研究[J]. 金融論壇. 2013, (9): 68- 74. [13] 霍海濤. 高科技中小企業信用風險指標體系及其評價方法[J]. 北京理工大學學報(社會科學版). 2012, 14(1): 60-65. [14] Zhang Zhiwang, Gao Guangxia, Shi Yong. Credit risk evaluation using multi-criteria optimization classifier with kernel, fuzzification and penalty factors [J]. European Journal of Operational Research, 2014,237(1):335-348. [15] Harris T. Quantitative credit risk assessment using support vector machines: Broad versus Narrow default definitions [J]. Expert Systems with Applications. 2013, 40(12): 4404-4413. [16] Chi Bo-wen, Hsu C C.A hybrid approach to integrate genetic algorithm into dual scoring model in enhancing the performance of credit scoring model [J]. Expert Systems with Applications. 2012, 39(3): 2650-2661. [17] 盧超, 鐘望舒. 商業銀行對中小企業信用風險評價的方法探索[J]. 金融論壇. 2009, (10): 13-20. [18] 柳玉鵬, 李一軍. 組合評價方法在銀行信用風險評價中的應用[J]. 中國管理科學, 2008, (16): 215-218. [19] 張大斌, 周志剛, 許職, 等. 基于差分進化自動聚類的信用風險評價模型研究[J]. 中國管理科學, 2015, 23(4): 39-45. [20] 陳曉紅, 楊志慧. 基于改進模糊綜合評價法的信用評估體系研究-以我國中小上市公司為樣本的實證研究[J]. 中國管理科學, 2015, 23(1): 146-153. [21] Doumpos M, Niklis D, Zopounidis C, et al.Combining accounting data and a structural model for predicting credit ratings: Empirical evidence from European listed firms [J]. Journal of Banking & Finance, 2015, 50(C):599-607. [22] Jones S, Johnstone D, Wilson R. An empirical evaluation of the performance of binary classifiers in the prediction of credit ratings changes[J]. Journal of Banking & Finance, 2015, 56:72-85. [23] 遲國泰,王衛. 基于科學發展的綜合評價理論、方法與應用[M].北京:科學出版社,2009. [24] 中國郵政儲蓄銀行.中國郵政儲蓄銀行農戶與商戶信用評級表[R].中國郵政儲蓄銀行,2009. [25] 王熙逸. 多元統計分析方法[M]. 上海:格致出版社, 2009. [26] 遲國泰, 石寶峰. 基于信用等級與違約損失率匹配的信用評級系統與方法[P]. 中國專利:201210201461.6, 2012-06-18. [27] 工業和信息化部, 國家統計局, 國家發展和改革委員會, 財政部. 關于印發中小企業劃型標準規定的通知[S]. 工信部聯企業[2011]300號. 2011-06-18. Facility Rating of Small Industrial Enterprises Based on Likelihood Ratio Test ZHAO Zhi-chong, CHI Guo-tai (Faculty of Management and Economics,Dalian University of technology, Dalian 116024,China) Facility rating aims to evaluate the possibility of repayment or the loss given default (LGD) of one debt. It is hard for commercial banks to accurately evaluate the credit risk of small business loans, because of mall enterprises’ high risk, small amount, and untrue financial data, etc. This paper established facility rating index system for small enterprises, which selected indicators based on the ability of distinguishing default state for the first time, while the second time was to avoid the information redundancy of selected indicators in the same guidelines layer. First,establishing logistic regression equation about default state and one indicator, then constructedχ2-statistic by comparing the log-likelihood values between the zero-model which has no any indicator and the full-model which has an indicator. The greater the deviation of those two log-likelihood values, the easier the indicator can distinguish the default state, that is to say, the indicator should be retained. It compensates the disadvantage that the existing research has nothing to do with the default state when screening indicators. Second,the paper avoided information redundant by calculating the correlation coefficient between any two indicators in the same criteria layer, if the correlation coefficient between these two indicators is greater than a threshold, then remove the indicator which has smallχ2-value. This method can avoid redundant information and mistakenly deleting the indicator which has more significant impact on default state. What’s more, it changes the disadvantage that the existing researches subjectively delete one indicator when the correlation coefficient is greater than the threshold. The results shows that the established debt rating system of small industrial businesses, including 26 indicators, such as asset-liability ratio, cost margins, the corporate credit situation nearly 3 years, by extracting the related data of 28 regional commercial bank branches of China. the paper can not only get the credit rating of the loan enterprises, but also get the loss given default of per credit rating. It changes the disadvantages that the existing research can only calculate the credit score and give credit rating. small industrial enterprises; credit risk; debt rating; default state; Likelihood ratio test 1003-207(2017)01-0045-12 10.16381/j.cnki.issn1003-207x.2017.01.006 2015-05-25; 2015-11-25 國家自然科學基金資助項目(71171031,71471027);國家社科基金資助項目(16BTJ017);遼寧省社科規劃基金資助項目(L16BJY016);教育部科學技術研究項目(2011-10);大連銀行小企業信用風險評級系統與貸款定價項目(2012-01);遼寧經濟社會發展重點課題(2015lslktzdian-05) 遲國泰(1955-),男(漢族),黑龍江海倫人,大連理工大學管理與經濟學部,金融學教授,博士生導師,研究方向:商業銀行信用評級理論與模型,E-mail:chigt@dlut.edu.cn. F832.42;N945.16 A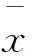
4 工業小企業債信風險評級體系的建立




5 結語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術-中醫藥現代化(2021年10期)2021-03-02 05:52:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
