EDM用于研究生就業(yè)能力的預(yù)測(cè)
2017-08-19 22:29:54廖鳳露周慶
教育教學(xué)論壇 2017年33期
關(guān)鍵詞:數(shù)據(jù)挖掘
廖鳳露+周慶
摘要:研究生就業(yè)一直是社會(huì)、高校和學(xué)生關(guān)注的熱點(diǎn)問(wèn)題。本文基于教育數(shù)據(jù)挖掘(Educational Data Mining)技術(shù),通過(guò)研究生的行為數(shù)據(jù)來(lái)預(yù)測(cè)就業(yè)能力,從而為研究生的就業(yè)工作提供幫助。首先對(duì)收集到的數(shù)據(jù)進(jìn)行預(yù)處理,然后運(yùn)用特征選擇方法篩選出與就業(yè)能力相關(guān)的課程和網(wǎng)絡(luò)訪問(wèn)類型,最后建立樸素貝葉斯模型進(jìn)行就業(yè)能力進(jìn)行預(yù)測(cè)。本文的模型可實(shí)現(xiàn)接近90%的召回率,說(shuō)明該方法能準(zhǔn)確地預(yù)測(cè)學(xué)生的就業(yè)能力。
關(guān)鍵詞:就業(yè)能力預(yù)測(cè);學(xué)生成績(jī);上網(wǎng)日志;數(shù)據(jù)挖掘
中圖分類號(hào):G643 文獻(xiàn)標(biāo)志碼:A 文章編號(hào):1674-9324(2017)33-0065-02
一、引言
在我國(guó)高等教育進(jìn)入大眾化階段后,研究生人數(shù)逐年激增,研究生的就業(yè)能力和就業(yè)狀況一直是高校和社會(huì)關(guān)注的熱點(diǎn)問(wèn)題。如果能預(yù)測(cè)每位學(xué)生的就業(yè)能力,不僅有利于了解學(xué)生的總體情況,有利于改進(jìn)教學(xué)工作,也有利于學(xué)生及時(shí)調(diào)整個(gè)人的學(xué)習(xí)計(jì)劃和目標(biāo)。然而,研究生的就業(yè)能力受到多個(gè)因素的影響,因此準(zhǔn)確預(yù)測(cè)研究生的就業(yè)能力是一個(gè)困難的問(wèn)題。
教育數(shù)據(jù)挖掘(Educational Data Mining,以下簡(jiǎn)稱EDM)是解決這一問(wèn)題的潛在技術(shù)。EDM利用計(jì)算機(jī)科學(xué)、教育學(xué)、社會(huì)心理學(xué)和統(tǒng)計(jì)學(xué)等多門學(xué)科的理論和技術(shù)解決教育研究和實(shí)踐中的各類問(wèn)題[1],如輔助教學(xué)管理者進(jìn)行教育決策、提高學(xué)生的學(xué)習(xí)積極主動(dòng)性和幫助教師改進(jìn)教學(xué)方式方法等。EDM的特點(diǎn)在于使用教育環(huán)境中產(chǎn)生的數(shù)據(jù)發(fā)現(xiàn)知識(shí),并將產(chǎn)生的知識(shí)應(yīng)用于優(yōu)化教育環(huán)境的目的[2]。
二、研究方法
為了挖掘出學(xué)生就業(yè)能力和學(xué)生行為表現(xiàn)之間的關(guān)系,本次研究主要分為以下幾個(gè)步驟進(jìn)行:首先對(duì)原始數(shù)據(jù)進(jìn)行采集,然后進(jìn)行預(yù)處理和特征篩選,最后選取分類器建立預(yù)測(cè)模型。
(一)數(shù)據(jù)采集
本次實(shí)驗(yàn)數(shù)據(jù)來(lái)源于某大學(xué)計(jì)算機(jī)學(xué)院2013級(jí)專業(yè)碩士和學(xué)術(shù)碩士共計(jì)139人的基本信息,研究生階段的所有課程成績(jī),2016年3月在校期間上網(wǎng)記錄,就業(yè)單位信息以及在校期間發(fā)表的論文信息等。在數(shù)據(jù)處理過(guò)程中,我們首先對(duì)所有學(xué)生的學(xué)號(hào)進(jìn)行加密操作,以保護(hù)學(xué)生的隱私。
(二)數(shù)據(jù)預(yù)處理
要對(duì)研究生的就業(yè)能力進(jìn)行統(tǒng)計(jì)和分析,首先應(yīng)對(duì)就業(yè)能力進(jìn)行評(píng)價(jià)。評(píng)價(jià)的依據(jù)主要參照學(xué)生的就業(yè)單位和就業(yè)崗位。盡管這一依據(jù)并不能完全客觀地反映學(xué)生的就業(yè)能力,但可以給教學(xué)管理者提供有價(jià)值的參考信息。將每個(gè)研究生的就業(yè)能力編碼為1和0,分別代表“好”和“一般”兩種情況。
由于原始數(shù)據(jù)里包含噪聲數(shù)據(jù)情況,需要先對(duì)數(shù)據(jù)進(jìn)行預(yù)處理,數(shù)據(jù)預(yù)處理的過(guò)程主要包括以下幾個(gè)方面:
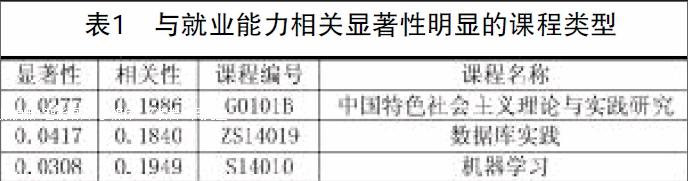
1.成績(jī)數(shù)據(jù)處理。將其中成績(jī)有缺失的項(xiàng)去掉,將成績(jī)等級(jí)用數(shù)字型成績(jī)替換,計(jì)算各學(xué)生的平均成績(jī)。對(duì)每門具體課程,如果學(xué)生沒(méi)有選修該課程,則用該生的平均成績(jī)代替。
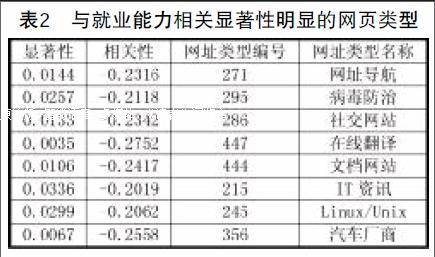
2.學(xué)生上網(wǎng)日志數(shù)據(jù)處理。學(xué)生上網(wǎng)日志原始數(shù)據(jù)存在大量冗余,需要過(guò)濾掉其中的無(wú)用信息,如IP地址、圖像等。然后將網(wǎng)址按照類型不同進(jìn)行分類,統(tǒng)計(jì)學(xué)生訪問(wèn)不同類型網(wǎng)站的時(shí)長(zhǎng)和頻次。
3.學(xué)生發(fā)表論文數(shù)據(jù)處理。根據(jù)發(fā)表期刊的不同,將論文分為5等,然后分別統(tǒng)計(jì)出學(xué)生發(fā)表論文總數(shù)以及發(fā)表論文的最高等級(jí)。
(三)特征篩選
計(jì)算就業(yè)能力與各項(xiàng)特征的相關(guān)系數(shù),篩選出相關(guān)性較強(qiáng)的特征加入預(yù)測(cè)模型。其中與就業(yè)能力相關(guān)性較高的課程如表1所示,上網(wǎng)類型如表2所示。
(四)分類器
本次研究所使用的分類器為樸素貝葉斯分類器(Na?觙ve Bayesian classifier,簡(jiǎn)稱NBC)。它是基于貝葉斯理論的簡(jiǎn)單概率分類器,假設(shè)實(shí)例的各個(gè)特征是相互獨(dú)立的。在此假設(shè)下,如果某個(gè)類別在實(shí)例的特征集合上具有最大的條件概率,則認(rèn)為該實(shí)例屬于此類別。相比一般的分類模型,樸素貝葉斯模型具有簡(jiǎn)單、計(jì)算復(fù)雜度低和內(nèi)存消耗小等優(yōu)勢(shì)。
三、實(shí)驗(yàn)過(guò)程及結(jié)果
本次實(shí)驗(yàn)采用樸素貝葉斯模型,分別在不同的數(shù)據(jù)集上對(duì)研究生就業(yè)能力進(jìn)行預(yù)測(cè)。
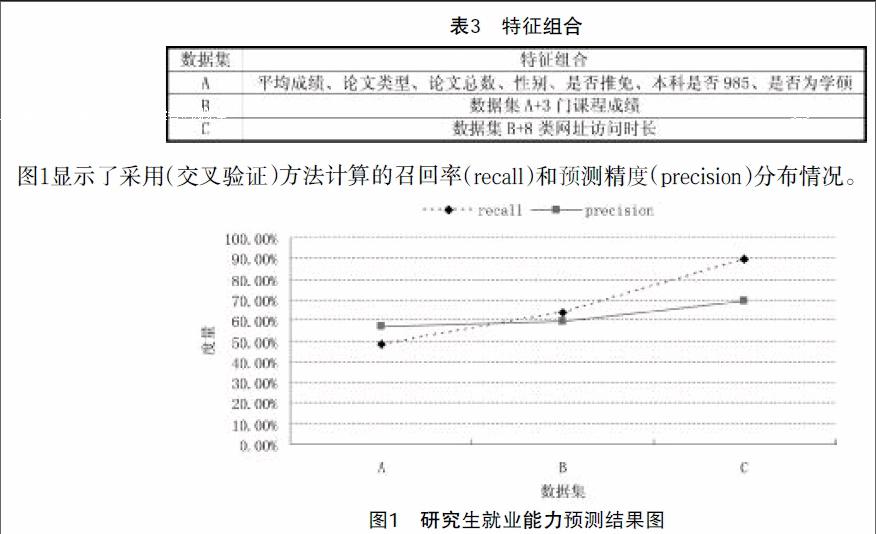
通過(guò)前述的篩選方法確定的特征主要有學(xué)生平均成績(jī)、論文類型、論文總數(shù)、性別、是否推免、本科是否“985”、是否為學(xué)碩、表1選出的3門課程、表2選出8類網(wǎng)址訪問(wèn)時(shí)長(zhǎng)。將以上9類特征組合成3個(gè)數(shù)據(jù)集(參見表3),然后帶入預(yù)測(cè)模型進(jìn)行預(yù)測(cè)。
圖1顯示了采用(交叉驗(yàn)證)方法計(jì)算的召回率(recall)和預(yù)測(cè)精度(precision)分布情況。
根據(jù)上圖我們可以得出以下幾個(gè)結(jié)果:
1.隨著數(shù)據(jù)集特征的增加,召回率呈上升的趨勢(shì),數(shù)據(jù)集C預(yù)測(cè)的召回率達(dá)到最大值89.66%。
2.隨著數(shù)據(jù)集特征的增加,預(yù)測(cè)精度呈上升趨勢(shì),數(shù)據(jù)集C的預(yù)測(cè)精度達(dá)到最大值69.33%。
3.隨著數(shù)據(jù)集特征的增加,召回率提升的幅度大于預(yù)測(cè)精度的提升幅度。
所以,數(shù)據(jù)集C的預(yù)測(cè)效果最好,且召回率和預(yù)測(cè)精度均達(dá)到一個(gè)較好的值,說(shuō)明我的模型能較好地預(yù)測(cè)學(xué)生就業(yè)能力的情況。
四、結(jié)論
本文主要是基于學(xué)生成績(jī)和上網(wǎng)日志,采用數(shù)據(jù)挖掘技術(shù)對(duì)其就業(yè)能力的預(yù)測(cè)。主要工作集中在數(shù)據(jù)預(yù)處理和特征選擇上,對(duì)成績(jī)和上網(wǎng)日志的預(yù)處理,并篩選出一些特征用于模型預(yù)測(cè)。我們采用樸素貝葉斯模型來(lái)對(duì)學(xué)生的就業(yè)能力進(jìn)行預(yù)測(cè),模型預(yù)測(cè)性能良好,召回率可達(dá)到89.66%,預(yù)測(cè)精度達(dá)到69.33%。這說(shuō)明,本文提出的方法可以實(shí)際用于對(duì)學(xué)生就業(yè)的預(yù)測(cè)。
參考文獻(xiàn):
[1]Kisor Y. The state of educational data mining in 2009:A review and future visions[J].Computer Communications,2009,6(2):82-87.
[2]周慶,牟超,楊丹.教育數(shù)據(jù)挖掘研究進(jìn)展綜述[J].軟件學(xué)報(bào),2015,(11):3026-3042.
Forecasting System of Postgraduate's Employability Based on EDM
LIAO Feng-lu,ZHOU Qing*
(College of Computer Science,Chongqing University,Chongqing 400044,China)
Abstract:Graduate employment has always been an important issue for society,universities and students. In this paper,we predict postgraduate's employability through student behavioral data based on the technology of Educational Data Mining,thus providing support for post-graduate employment. First,we preprocess the collected data. Second,we use the feature selection method to filter out the employment-related courses and network access types. Finally,a naive Bayesian model is established to forecast the employability. This model can achieve a recall of about 90%,indicating that the method can accurately predict the employability of students
Key words:employability forecast;student achievement;web log;data mining
猜你喜歡
艦船科學(xué)技術(shù)(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國(guó)交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國(guó)中醫(yī)藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
西安工程大學(xué)學(xué)報(bào)(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設(shè)計(jì)工程(2014年18期)2014-02-27 12:00:13
電子設(shè)計(jì)工程(2014年18期)2014-02-27 12:00:12
