基于情感分析的評論數(shù)據(jù)用戶滿意度影響因素研究
2017-08-25 19:58:22劉甲學(xué)陶易
現(xiàn)代情報 2017年7期
關(guān)鍵詞:影響因素
劉甲學(xué)+陶易
[摘要]通過對用戶的滿意度影響因素的分析,能夠幫助商家挖據(jù)用戶需求、提升用戶滿意度、從而提高商品銷量。本文使用商業(yè)智能軟件PowerBI對用戶評論文本進(jìn)行數(shù)據(jù)挖掘,通過提取評論數(shù)據(jù)中的質(zhì)量、物流、尺碼、價格、顏色等影響用戶滿意度影響的因素,利用情感分析法進(jìn)行賦值,然后統(tǒng)計各影響因素的樣本得分,識別出價格和質(zhì)量是最重要的影響因素。
[關(guān)鍵詞]評論數(shù)據(jù);情感分析;用戶滿意度;影響因素
伴隨電子商務(wù)的蓬勃發(fā)展,電商網(wǎng)站下累積了大量用戶在線評論數(shù)據(jù),通過對評論數(shù)據(jù)相關(guān)研究的解讀和分析,我們發(fā)現(xiàn):評論數(shù)據(jù)是用戶表達(dá)真實需求和情感極性的重要途徑,故而可以挖掘出其隱藏的用戶偏好以及真實需求。姜巍等人創(chuàng)造性地將評論數(shù)據(jù)看作一種內(nèi)容互連的網(wǎng)絡(luò)拓?fù)涞男螒B(tài),利用評論網(wǎng)絡(luò)節(jié)點的重要性來度量評論的有用性,該方法對用戶需求獲取能夠達(dá)到較高的準(zhǔn)確率和覆蓋率。評論數(shù)據(jù)中的情感極性對商品銷量會產(chǎn)生一定程度地影響作用。如Sonnier,G.P.等人驗證了積極的評論數(shù)據(jù)、中性的評論數(shù)據(jù)、消極的評論數(shù)據(jù)都對銷量有著顯著影響作用。因此,通過對評論數(shù)據(jù)進(jìn)行情感分析來挖掘用戶需求、提升用戶滿意度最終可以達(dá)到提高商品銷量的目的。本文將從用戶評論數(shù)據(jù)中提取如質(zhì)量、顏色、服務(wù)等具有實體意義的影響因素指標(biāo),通過建設(shè)多維度數(shù)據(jù)集進(jìn)行用戶滿意度影響因素研究。
1數(shù)據(jù)來源
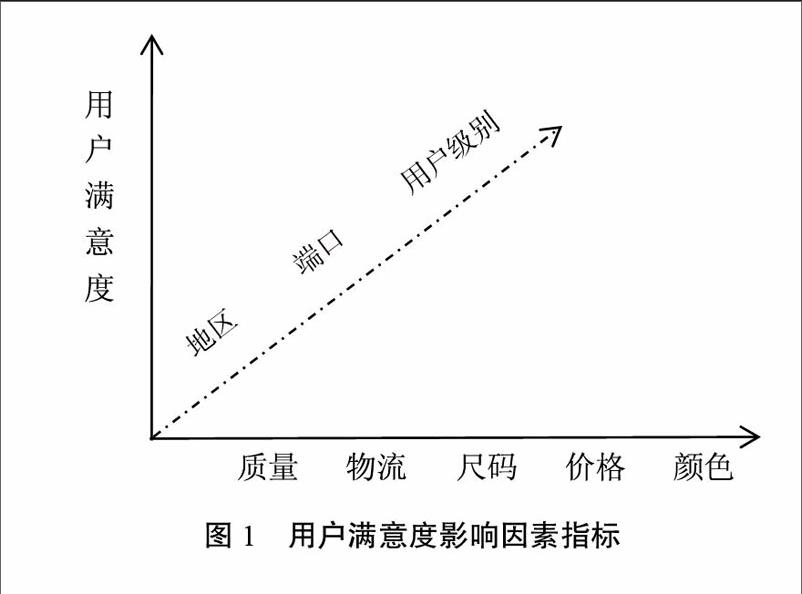
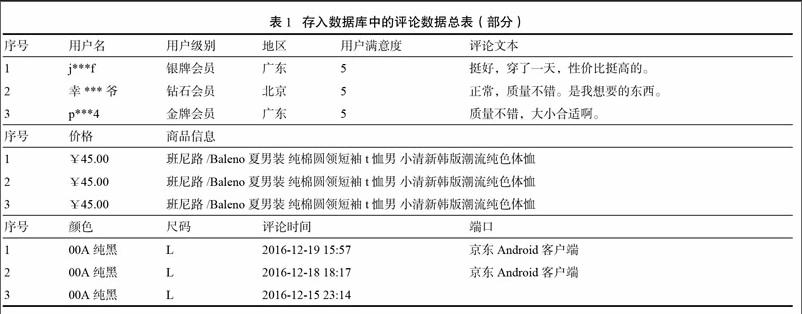
本文對京東商城的用戶評論數(shù)據(jù)進(jìn)行采集,使用網(wǎng)絡(luò)爬蟲軟件八爪魚對班尼路官方旗艦店男裝T恤(鏈接https://item.id.COB/1574267931.html)的用戶評論數(shù)據(jù)進(jìn)行抓取,對每一條評論數(shù)據(jù)(如圖1所示)中方框內(nèi)各字段進(jìn)行抽取,抽取的字段分別是:用戶名、用戶級別、地區(qū)、用戶滿意度(星級好評)、評論文本、價格、商品信息、顏色、尺碼、評論時間、端口。將抽取的字段設(shè)置為自動導(dǎo)入數(shù)據(jù)庫中以備后續(xù)分析。
2數(shù)據(jù)的抽取、清理和加載
由于抽取到數(shù)據(jù)庫中的用戶名僅顯示首尾字符,中間字符是由星號鍵組成,故而容易出現(xiàn)不同用戶共享同一用戶名的情況或者同一用戶名在不同時期的評論被數(shù)據(jù)庫禁止讀入的情況發(fā)生,因此需要將序號代替用戶名作為表格中的主鍵進(jìn)行分析以避免數(shù)據(jù)庫讀取數(shù)據(jù)失敗的情況發(fā)生。截止至2017年3月19日共抓取到7000條評論數(shù)據(jù),故而形成一張樣本容量為7000條數(shù)據(jù)的評論數(shù)據(jù)總表(如表1所示)。數(shù)據(jù)庫可實現(xiàn)在線實時更新,抓取的網(wǎng)頁數(shù)據(jù)會自動加載到數(shù)據(jù)庫中的評論數(shù)據(jù)總表中,為減少數(shù)據(jù)冗余,需要對數(shù)據(jù)進(jìn)行清理,減少垃圾數(shù)據(jù)的讀取。從競爭情報角度考慮,如果用戶名、用戶級別、地區(qū)三者完全一致的用戶可被視為同一用戶,因此可以設(shè)置聯(lián)合主鍵的方式作為同一用戶的判斷條件,如果數(shù)據(jù)庫中顯示較為接近的時間段內(nèi)由大批用戶級別較低的評論涌入,則默認(rèn)為是水軍;如果同一用戶在較為接近的時間段發(fā)表多條評論數(shù)據(jù),則默認(rèn)為是重復(fù)評論,只保留該用戶的第一條評論;前者的評論數(shù)據(jù)置信度較低,后者評論數(shù)據(jù)產(chǎn)生冗余,為保證研究結(jié)果的準(zhǔn)確可靠性,應(yīng)將這兩類的評論數(shù)據(jù)予以清除。
3用戶滿意度的影響因素指標(biāo)
本文在數(shù)據(jù)庫存儲設(shè)計時創(chuàng)建多維數(shù)據(jù)集,從評論用戶本身出發(fā),設(shè)計以地區(qū)、端口(上網(wǎng)設(shè)備)、用戶級別三個影響指標(biāo);從商品屬性出發(fā),由表征商品特征屬性的特征詞質(zhì)量、物流、尺碼、價格、顏色五個影響指標(biāo),如圖1所示。本文試圖從不同維度對用戶滿意度進(jìn)行分析,商業(yè)智能軟件Power BI能夠?qū)崿F(xiàn)對多維數(shù)據(jù)集進(jìn)行數(shù)據(jù)處理,通過對用戶滿意度與影響指標(biāo)間的各項數(shù)據(jù)進(jìn)行自動化分析,尋找出用戶滿意度的關(guān)鍵影響因素。地區(qū)、端口、用戶級別三項指標(biāo)都能較易地由字符串?dāng)?shù)據(jù)轉(zhuǎn)化為數(shù)值型數(shù)據(jù);再利用情感分析法將評論文本中的字符型數(shù)據(jù)轉(zhuǎn)化為語義識別后的數(shù)值型數(shù)據(jù),從而作為用戶滿意度影響指標(biāo)中的可分析處理的自變量,從而被商業(yè)智能軟件識別和分析。
4評論文本的情感分析
4.1通過分詞提取特征詞
提取評論文本中特征詞的方法中,Li,F(xiàn)等人采用句法結(jié)構(gòu)樹Skip-Tree CRFs提取評價特征詞進(jìn)行情感極性分析。Li,C.w等人利用了情報學(xué)專業(yè)中常見的逆文本頻率指數(shù)(IDF)方法,對關(guān)鍵詞權(quán)重進(jìn)行排序后提取重要特征詞并進(jìn)行情感極性分析。這些方法效率雖高,但是忽略了評論文本中特征詞的同義詞產(chǎn)生的誤差,從而影響研究結(jié)果的可靠度。本文采用半自動化提取的方式,設(shè)定特征詞同義詞表以提高整個研究的準(zhǔn)確度。具體方法是:特征值顯著的特點是詞性為名詞,因此本文通過對評論文本進(jìn)行分詞并統(tǒng)計詞性為名詞的高頻特征詞即可得到用戶滿意度影響因素指標(biāo)。分詞軟件采用PHP簡易中文分詞(SCWS)第四版,將7000條評論文本分詞為詞語\詞性(如質(zhì)量\n)統(tǒng)計匯總后得到的高頻特征詞為以下幾類:質(zhì)量、物流、尺碼、價格、顏色、活動、品牌、服務(wù)等;本文僅選取排名靠前的五項指標(biāo)進(jìn)行詳細(xì)分析,即將質(zhì)量、物流、尺碼、價格、顏色作為用戶滿意度的影響因素指標(biāo)進(jìn)行后續(xù)分析。對出現(xiàn)特征詞的同義詞進(jìn)行歸類形成一特征詞同義詞表,如表2所示。特征詞同義詞表的作用是避免重復(fù)提取特征詞以提高檢索效率。如評論“顏色很好看,色彩很美,價格便宜”,其中“顏色”和“色彩”都屬于顏色類特征詞,數(shù)據(jù)庫在提取同類型特征詞時設(shè)置為僅提取首次出現(xiàn)的特征詞,因此提取結(jié)果為特征詞“顏色”、“價格”,將提取結(jié)果導(dǎo)人數(shù)據(jù)庫一抽取詞表表格中,然后該條評論結(jié)束讀取跳轉(zhuǎn)至下一條評論。
4.2情感詞的定位及提取
相關(guān)學(xué)者將情感分析分為:有監(jiān)督方法,如Ali,F(xiàn)采用機(jī)器學(xué)習(xí)的方法使用基于支持向量機(jī)(SVM)和改進(jìn)版的模糊領(lǐng)域本體(FDO)方法進(jìn)行情感極性判斷;無監(jiān)督方法,如李欣等人采用無監(jiān)督方法通過多重聚類算法進(jìn)行情感極性判斷;f情感詞典方法,如馬松岳等人使用ROST EA情感詞典工具進(jìn)行情感分析。特征詞顯著的標(biāo)志是詞性為名詞,而情感詞則由多種詞性組成,常見的是由副詞和形容詞組成,本文中采用以對評論文本分詞后確定的特征詞位置為基準(zhǔn),在特征詞附近創(chuàng)建字符區(qū)間作為情感詞定位區(qū)間,例如“挺好,穿了一天,性價比挺高的。”分詞結(jié)果為“挺/v好/a穿/v了/v一/m天/n性價比/n挺/v高/a的/ui”。能夠定位到特征詞為“性價比”,屬于“價格”類,情感詞的取值范圍為“一/m天/n、挺/v高/a”,接下來需要通過數(shù)據(jù)庫的一情感詞表與一抽取詞表進(jìn)行關(guān)聯(lián)匹配出情感詞并賦值得分。
猜你喜歡
現(xiàn)代經(jīng)濟(jì)信息(2016年19期)2016-10-20 18:46:44
現(xiàn)代經(jīng)濟(jì)信息(2016年19期)2016-10-20 18:12:28
現(xiàn)代經(jīng)濟(jì)信息(2016年19期)2016-10-20 16:20:30
中國科技博覽(2016年19期)2016-10-19 13:33:22
中國科技博覽(2016年18期)2016-10-19 10:49:54
中國科技博覽(2016年18期)2016-10-19 08:16:45
中國科技博覽(2016年18期)2016-10-19 06:39:44
中國市場(2016年36期)2016-10-19 03:54:01
中國市場(2016年35期)2016-10-19 02:30:10
商(2016年27期)2016-10-17 07:09:07
