基于擴展質量功能展開和網絡圖的產品大數據分析方法及其應用探討
2017-12-20 09:21:31唐中君崔駿夫禹海波
中國科技論壇 2017年12期
唐中君,崔駿夫,禹海波
(北京工業大學經濟與管理學院北京現代制造業發展研究基地,北京 100124)
基于擴展質量功能展開和網絡圖的產品大數據分析方法及其應用探討
唐中君,崔駿夫,禹海波
(北京工業大學經濟與管理學院北京現代制造業發展研究基地,北京 100124)
現有大數據分析方法存在側重算法提升而忽視數據固有關系、難以綜合分析網絡形態數據之間連動關系的問題。為解決這些問題,提出了一個基于擴展QFD和網絡圖的產品大數據分析方法。該方法由面向數據關系的擴展QFD、基于網絡圖的產品大數據關系描述模型和基于該描述模型的產品大數據分析模型組成。該方法有助于厘清產品各類數據間的固有關系,可將具有復雜結構、多重關系的數據以清晰的網絡結構表現出來,并可綜合利用多種大數據分析模型對產品大數據進行模式探索,從而達到從海量數據中獲取關鍵數據、發現新數據及數據間的新關系等目標。解決了現有大數據分析方法忽視數據固有關系、難以綜合分析數據間連動關系的問題,使數據建模與算法技術更好地結合。
大數據分析;質量功能展開;網絡圖;產品大數據
1 引言
數據采集和存儲技術的長足進步使企業得以擁有大量與產品有關的數據,其主要來源有企業自有數據、公開信息和有償獲取數據[1]。來自各類信息源的數據存在不同表現形式,如歷史數據和實時數據、線上和線下數據、傳感數據和社會數據等。這些多源異構數據產生于產品全生命周期的不同階段,共同組成了產品大數據。多源異構和產生于全生命周期不同階段的性質使得產品大數據呈現出復雜的結構、多重的關系,使數據及其關系具有了網絡形態特性。產品的全生命周期包含需求分析、設計、制造、銷售和售后階段。本文結合產品全生命周期各階段將產品大數據分為需求類、產品屬性要求類、制造要求類(零部件要求子類、工藝要求子類、生產要求子類)、銷售要求類、運營類和售后使用類。其中運營類數據產生于供應鏈活動,涉及原材料采購、產品制造、生產、銷售和售后服務等活動。各類產品大數據產生于產品生命周期不同階段,反映產品處于不同階段的狀態,將這些數據融合分析能夠清晰地識別產品全生命周期內各類數據之間的關系,有助于提取新的關系與模式,從而為開拓市場和制定商業模式提供決策參考。
大數據分析方法源于多個領域,如統計學、計算科學和經濟學等,主要有關聯規則學習、分類、聚類、網絡分析、神經網絡等方法[2]。這些方法側重于算法性能優化和處理技術的提升。例如,Zhang等使用spark技術提升了關聯模式挖掘中頻繁集挖掘的迭代計算效率[3]。Wu等使用基于迭代樣本的頻繁模式挖掘方法優化了大數據處理的效率問題[4]。Sarma等使用一種尋找分割面的方法優化了K-means聚類方法;該方法以犧牲聚類質量為代價,顯著增加了大數據集的聚類速度[5]。一些學者改進了支持向量機方法,降低了原有算法的時間復雜度和空間復雜度[6-8]。Jiang等結合約束聚類和KNN算法生成增強型KNN算法;該算法降低了文本相似度的計算量,提升了對文本型大數據分類的效率[9]。可以看出目前有關大數據分析方法的研究主要針對算法本身,欠缺對數據之間固有關系的分析研究。
在分析具有復雜結構和網絡型多重關系的數據時,一些學者使用了網絡分析方法。例如Sudhahar等使用中心度、同配性等多種網絡分析指標對2012年美國大選期間的網絡新聞數據進行了分析,找出了競選期間候選人在其社交網絡中與其他節點的關系;各節點代表資助方或黨派候選人,節點間連線表示資助關系[10]。He等構建了一個基于隨機矩陣論的統一數據分析模型用于分析移動網絡數據的特點[11]。Alamsyah等人使用社交網絡方法分析了某組織內員工的36000多封郵件的收發關系,以幫助該組織實施組織內部的知識管理[12]。Lobb等利用網絡分析方法對癌癥項目進行分析并提出優化建議[13]。Chopade等利用節點屬性和邊的結構對網絡數據進行分析,并根據網絡屬性設計了網絡社區識別算法[14]。可以發現網絡分析方法廣泛用于描述數據之間的關系。但是,運用網絡分析方法分析數據之間關系的文獻鮮有利用數據之間的固有關系。此外,目前學者在分析具有復雜結構和網絡型多重關系的數據時僅使用單一的分析方法,尚未發現將多種大數據分析模型綜合運用于數據分析的研究。因而目前的大數據分析方法難以綜合利用各類數據建模與算法技術,難以綜合分析數據之間的聯動關系。
針對上述問題,本文將提出一個基于擴展QFD和網絡圖的產品大數據分析方法。該方法由三部分組成:面向數據關系的擴展QFD,基于網絡圖的產品大數據關系描述模型和基于該描述模型的產品大數據分析模型。其中面向數據關系的擴展QFD能將復雜的數據類抽象為變量集,并識別出變量之間的固有關系。基于網絡圖的產品大數據關系描述模型能將擴展QFD識別出的數據及其多重關系以直觀清晰的網絡形式表現出來。基于描述模型的產品大數據分析模型通過聯用多種大數據分析方法對描述模型的網絡圖進行研究,對數據之間的關系進行綜合分析,以實現多角度的模式探測。該方法解決現有大數據分析方法側重算法提升而忽視利用數據間固有關系的問題,并能綜合多種大數據分析方法分析具有復雜結構和網絡型多重關系數據之間的聯動關系,使數據建模與算法技術高效地結合。
2 面向數據關系的擴展QFD
傳統QFD是一種重要的產品設計技術,通過四個質量屋的順次分析將顧客要求轉化成產品屬性要求、零部件要求、工藝要求和生產要求[15]。QFD通過描述數據及其之間的關系實現各類信息之間的轉化,從而使QFD可用于識別數據之間的固有關系。傳統QFD涉及的數據有顧客需求類數據、產品屬性要求類數據、零部件要求類數據、工藝要求類數據和生產要求類數據。這些數據類涉及的數據間關系有兩類。一類是同類數據之間的關系,包括顧客不同類別要求之間的相互約束關系、產品屬性要求間的相互約束關系、零部件要求之間的相互約束關系、工藝要求之間的相互約束關系、生產要求之間的相互約束關系。另一類是不同類數據之間的關系,包括顧客要求與產品屬性要求之間的因果關系、產品屬性要求與零部件要求之間的因果關系、零部件要求與工藝要求之間的因果關系、工藝要求與生產要求之間的因果關系。然而傳統QFD是一種以顧客需求為起點的產品設計工具,從描述產品全生命周期內數據之間關系的角度看,存在兩方面局限。首先,傳統QFD的信息轉化過程是單向的[16],僅考慮產品生命周期中相鄰階段數據類之間的關系,沒有同時考慮所有階段所有數據間可能存在的關系。其次,傳統QFD的四個質量屋僅反映產品生產之前的數據類及其關系,無法體現全生命周期的產品大數據及各數據類之間的關系。
針對上述局限,本文提出了如圖1所示的“面向數據關系的擴展QFD”。圖中,平行四邊形代表數據類,矩形代表質量屋的左墻和天花板,虛箭線連接了數據類與質量屋,表示質量屋所需的數據由所連數據類提供,實折線表示質量屋之間的信息傳遞。在傳統QFD的基礎上,本文從數據類、質量屋和數據關系等方面進行了擴展。

圖1 面向數據關系的擴展QFD
首先,根據產品全生命周期數據的分類,將銷售要求類數據、運營類數據和售后使用類數據加入傳統QFD中。銷售要求類數據用于提供營銷要求。運營類數據包含供應鏈活動所涉及的企業采購、生產、營銷和售后等活動數據。相較于要求類數據(產品屬性要求類、制造要求類、銷售要求類),運營類數據屬于動態數據。售后使用類數據包含產品使用數據、服務數據、維護數據和回收數據。這些數據與顧客相關,對這些數據的分析能析出消費者的新需求,為新一階段擴展QFD提供需求類數據。產品全生命周期所有數據類的加入,使得面向數據關系的擴展QFD可以進行全生命周期內多重數據類關系識別。
其次,增加了兩個質量屋。隨著銷售要求類數據的加入,添加了產品屬性要求、零部件要求、工藝要求及生產要求與營銷要求的質量屋。該質量屋用于識別產品屬性要求數據、零部件要求數據、工藝要求數據及生產要求數據和營銷要求數據之間的關系。供應鏈活動受傳統QFD中各類要求數據的影響,例如原材料采購與零部件要求有關、生產制造活動與工藝要求及生產要求有關、產品銷售活動與營銷要求有關等。因此,本文添加了一個將產品屬性要求、零部件要求、工藝要求、生產要求和營銷要求共同作用于供應鏈活動的質量屋。
最后,根據新加入的數據類和質量屋,擴展得到兩類新的數據關系。一是有關同類數據之間的關系,包括營銷要求之間的相互約束關系、不同類別售后使用數據之間的約束關系、不同供應鏈活動數據之間的約束和反饋關系。二是有關不同類數據之間的關系,包括產品屬性要求、零部件要求、工藝要求、生產要求分別與營銷要求之間的因果關系,以及產品屬性要求、零部件要求、工藝要求、生產要求、營銷要求分別與供應鏈活動之間的因果關系。
從圖1可知,面向數據關系的擴展QFD可以識別兩大類數據關系。一類是依據數據產生于生命周期的階段而得的關系,即擴展QFD中全部質量屋內左墻數據間關系、屋頂數據間關系以及兩者相互之間的關系,形成了如圖1所示的從左上到右下的依產品生命周期不同階段的瀑布型關系。
另一類是如表1所示依據數據間抽象關系的種類而得的五種關系。第一種關系是層級關系,表示數據類A可以細分為若干子類。例如制造要求類數據可以細分為零部件要求、工藝要求和生產要求類數據。第二種關系是約束關系,表示數據類A和數據類B中任一類的變動將導致另一類的變動。例如任一質量屋中位于屋頂的數據之間可能存在約束關系。第三種關系是反饋關系,表示數據類A在影響數據類B后,數據類B又反饋影響數據類A。例如供應鏈活動數據中的生產類數據會影響營銷類數據,營銷類數據又將反饋作用于生產類數據。第四種關系為因果關系,表示數據類A在受到一定影響后,產生數據類B。例如售后使用類數據可以析出消費者對產品的部分新需求。第五種關系是自更新關系,表示數據類A隨著時間的推移,對自身狀態進行更新。
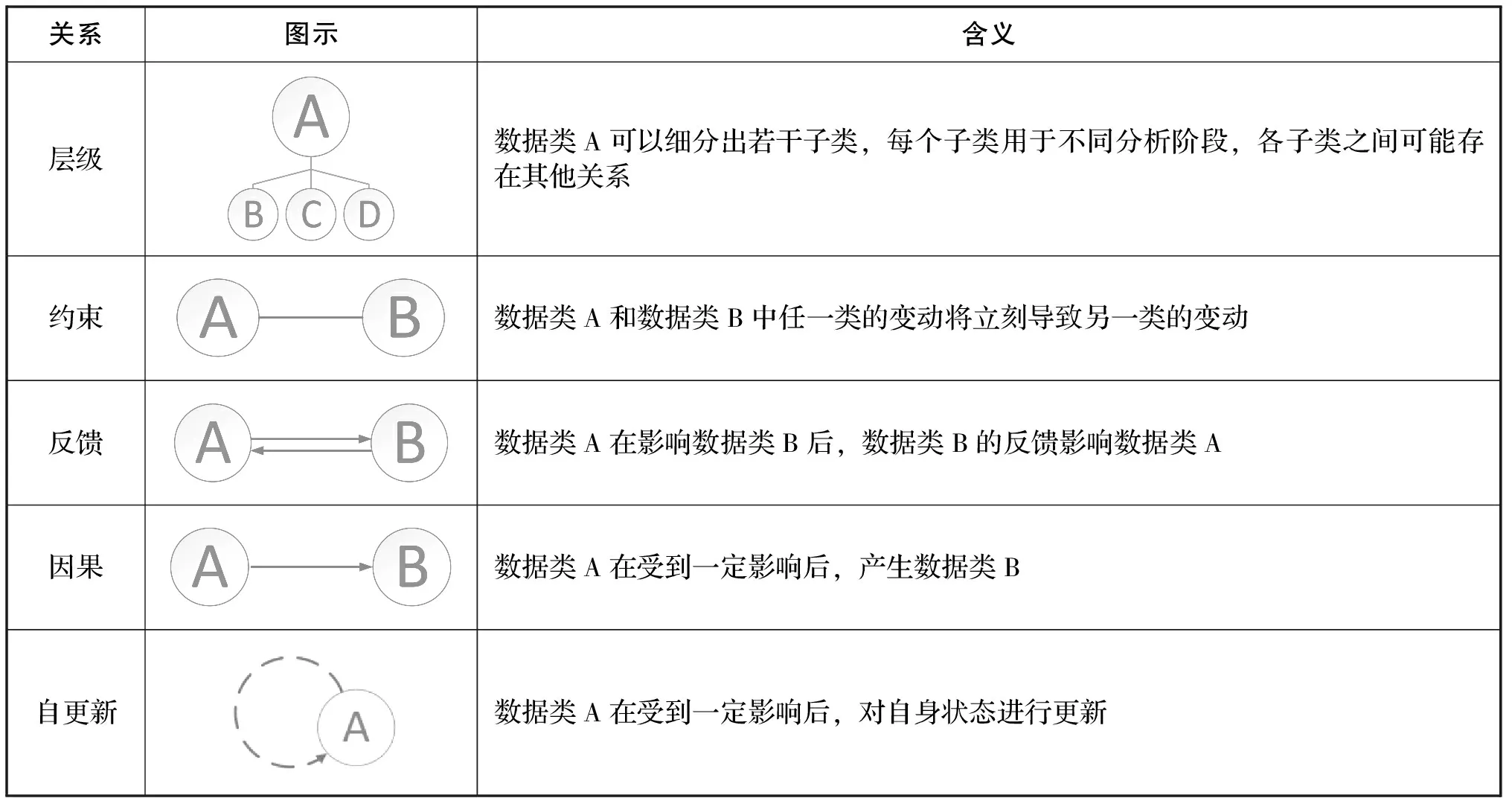
表1 數據關系
面向數據關系的擴展QFD將產品全生命周期內產生的大數據融入傳統QFD,延長了傳統的信息轉化過程,并在延長的過程中豐富了數據類固有關系。數據類關系分為依據生命周期產生階段而得的關系和依據數據間抽象關系種類而得的關系,兩類關系皆借助QFD中質量屋結構來體現。在大數據時代,每個數據類都與其他數據類之間存在多重復雜關系,無法脫離其他數據類而單獨發揮作用,故利用擴展QFD能以結構化方式識別數據類間固有關系,為后續分析提供便捷。此外,供應鏈活動質量屋的加入將直線式的QFD變成了閉環式的結構。這種閉環式結構將QFD中多個質量屋分別與營銷要求質量屋和供應鏈活動質量屋相連,可同時考慮相連兩者所涉及數據類的固有關系。
總之,面向數據關系的擴展QFD是一種幫助識別數據類間固有關系的工具。使用該工具可以對數據分類,并識別出產品大數據間存在的兩大類固有關系。
3 基于網絡圖的產品大數據關系描述模型
網絡圖由節點和連線構成。節點可以具有不同屬性,兩個節點之間的連線反映節點之間的關系。該關系可以通過節點間連線的方向性、強弱等多種方式加以描述。網絡圖中所有連線反映了所有節點之間的全局關系,可以通過節點的度、中心性、最短路徑和介數等方式加以描述。
由上節可知,通過面向數據關系的擴展QFD可以幫助識別產品大數據包含的數據類及其間的固有關系。對數據類及數據關系的描述,既要描述所有的數據類,還要描述局部數據類之間的關系,更要從整體描述所有數據類之間的全局關系。基于網絡圖的上述特點,本文提出如圖2所示的產品大數據關系描述模型。圖中平行四邊形代表不同的數據類,虛線表示不同顆粒度數據之間的關系,圓圈代表數據。圈中的符號代表數據類別;類別符號含義如表2所示。C代表顧客要求變量;D代表產品屬性要求變量;M代表制造類數據變量,其子類有零部件要求變量Part、工藝要求變量Tech和生產要求變量Prod;S代表營銷要求變量;As代表售后使用數據變量;Sc代表供應鏈活動變量。圖中每層內的連線表示數據間的關系;關系類型如表1所示。

圖2 基于網絡圖的產品大數據關系描述模型
圖2所示的模型是一個三層網絡結構。上層從宏觀角度描述產品大數據間的關系。中層描述數據類變量集間的關系,由上層各數據類具體化而成。下層從微觀角度全面描述各數據類變量間的關系,是對中層數據間關系的細化。

表2 數據類變量
上層網絡中各數據類間的連線表示數據類間具有因果關系。需求類與產品屬性要求類、產品屬性要求類與制造要求類、制造要求類與銷售要求類均呈因果關系。此外,產品屬性要求類、制造要求類共同與銷售要求類數據呈因果關系。產品屬性要求類、制造要求類、銷售要求類和售后使用類數據共同與運營類數據呈因果關系。
中層網絡描述各數據變量集及其關系形成的數據關系網。關系網中體現的關系類型有質量屋中左墻數據與屋頂數據之間的因果關系、數據自身固有的層級關系和自更新關系。存在的因果關系有需求變量集C和產品屬性要求變量集D間的關系、產品屬性要求變量集D和制造要求變量集M間的關系。其中制造要求變量集的子變量集間也呈因果關系(零部件要求變量集Part和工藝要求變量集Tech,工藝要求變量集Tech和生產要求變量集Prod)。產品屬性要求變量集D、制造要求變量集M共同與營銷要求變量集S呈因果關系。產品屬性要求變量集D、制造要求變量集M、營銷要求變量集S和售后使用變量集As共同與供應鏈活動變量集Sc呈因果關系。售后使用變量集As和新需求變量集C也呈因果關系。
中層網絡中的層級關系有制造要求變量集M及其三個子類變量集(零部件要求變量集Part、工藝要求變量集Tech、生產要求變量集Prod)。中層網絡中的自更新關系有售后使用變量集As對自身的更新,供應鏈活動變量Sc對自身的更新。
下層網絡描述各數據變量及其關系形成的數據關系網,關系網中體現的關系類型有質量屋中同一數據類變量之間的約束關系、左墻數據和屋頂數據之間的因果關系、數據自身固有的反饋關系。同一數據類變量之間的約束關系體現在每個數據變量集中的變量間相互影響。左墻數據和屋頂數據之間的因果關系同中層數據網絡所體現的一致。存在反饋關系的有各供應鏈活動變量Sc和售后使用變量集As。
圖2所示的描述模型具有以下三方面特點:
(1)該模型通過網絡結構可以直觀清晰地描述數據類型、其間關系和關系強度。網絡結構中的節點表示數據類型,數據節點之間不同類型的連接反映各數據類之間的關系、各數據類形成的網絡之間的關系,邊的不同連接強度反映各數據類之間、各數據類網絡之間的相互影響程度。
(2)將上節所述的兩大類數據關系融入該模型,能從全局出發,體現數據之間的相互作用。兩類關系互不排斥,相互補充。
(3)由于網絡關系可以轉換為矩陣形式,該描述模型易于用矩陣表達。矩陣的行和列均由變量節點組成。所形成的矩陣中,每個位置的元素都表示特定位置兩個變量的關系強度。例如,由圖2下層網絡圖生成的矩陣中,變量D2與變量D3因在圖中不相連,故變量D2所在行與變量D3所在列相交位置的值為0。變量D3與變量Part2相連,則兩個變量節點相交處的值為行變量節點對列變量節點的關系強度。圖2所示模型的矩陣形式可以方便描述因產品大數據節點過多導致的復雜網絡結構[17]。此外,多數大數據分析方法在處理數據時需將數據轉換為矩陣形式,因此使用矩陣表示網絡關系將增加圖2所示模型的分析效率。
總之,基于網絡圖的產品大數據關系描述模型能將面向數據關系的擴展QFD識別出的產品大數據間關系進行網絡化可視化構建,得到一個直觀描述產品大數據間關系的模型。無形的數據可以通過該描述模型有形化,無序的數據可以通過該描述模型有序化。借助矩陣形式,運用該模型可以發現數據之間的關系模式。
4 基于大數據關系描述模型的產品大數據分析模型
基于大數據關系描述模型的產品大數據分析模型是一個數據分析的過程模型,過程步驟如下。
(1)利用面向數據關系的擴展QFD 識別產品大數據及各類關系。
(2)將面向數據關系的擴展QFD識別得到的產品大數據間關系以網絡圖形式表現出來。數據類變量為節點,關系為連接節點的邊,形成基于產品大數據關系的描述模型。
(3)利用多種大數據分析方法對上一步構建的描述模型進行分析處理,得出各關系間相互作用程度,并分析數據間的聯動反應。例如,多源數據類包含大量異構數據,由數據類抽象為數據變量的過程前需使用數據融合的方法預處理。對數據類進行變量提取時,需根據數據的本質特性、應用特性和表現特性等采取不同的方法。如對文本數據進行自然語言處理后使用有向主題建模可獲取特征,或利用聚類方法發現數據相似性聚集所體現的特征等。獲得變量集后,可以使用關聯規則學習的方法識別變量間的關系。在利用各種關系構建出網絡圖后,可利用網絡分析等方法對數據變量網進行分析。
該模型具有三方面功能。第一,基于數據變量間相互作用程度,可識別出如圖3所示依據數據分析目標所得的數據之間的關鍵路徑。關鍵路徑是根據數據分析目標得出的一條從初始變化數據到目標數據之間的一條特殊路徑[18]。關鍵路徑可以識別出為達到分析目標所涉及的重要數據,從而達到從海量數據中識別關鍵數據的目的,并有助于明確數據之間相互作用的機理。第二,可以實現數據連動反應的動態分析。這種連動反應主要體現在數據變化所引起的關系變化和關系網絡結構變化兩方面。首先,數據的更新變化將影響變量之間原有關系作用程度的變化。其次,關系的變化將引起網絡結構的變化。對連動反應進行動態分析可獲取信息流傳遞方向,從而識別市場的動向。第三,可以識別出新的數據和關系。若某數據的加入能改變數據關系網的結構,則該數據為新數據。新數據可用來監控市場中出現的新動向。隨著新數據的出現,可獲得數據關系網中存在但未被識別的連接,從而發現新的關系模式。關系模式可以通過矩陣運算發現。
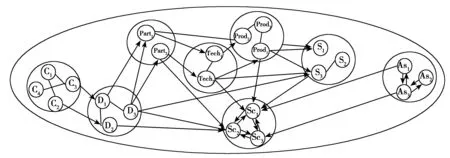
圖3 關鍵路徑圖
總之,基于大數據關系描述模型的產品大數據分析模型是一種綜合運用多種大數據分析方法分析處理數據的過程模型。該模型根據數據自身的特性和數據變量間固有關系從已有的大數據分析方法中選取合適的方法進行分析處理,其目的在于利用已有的大數據分析方法對面向數據關系的擴展QFD識別出的關系進行量化分析,即得出數據變量之間的相互作用程度,進而分析數據之間的聯動反應,通過多角度建模實現數據建模和算法技術的高效結合。
5 應用前景
基于擴展QFD和網絡圖的產品大數據分析方法是一種具有一般性的數據分析方法。一般性在于兩方面。首先,該方法分析的產品大數據不限于實體商品的數據,亦可是服務數據。其次,在產品全生命周期中,只要獲得不少于兩類數據即可進行相應環節的建模分析。例如,利用制造要求類和運營類數據可以構建用于決策支持的智能制造模型,并利用大數據分析來優化生產性能和改進產品工藝[19]。因此,本文構建的方法既可用于有形產品,也可用于無形服務;可應用于數據類不少于兩類的產品大數據分析。
應用本文提出的方法分析產品大數據的流程如上文所述:先識別數據類之間的關系和數據間的固有關系,再用網絡圖的方式對數據關系進行可視化,最后綜合多種現有大數據分析方法實現多角度建模分析。通過上述流程和多角度建模可實現多種目標的產品大數據分析。目標包括對任意不少于兩類的數據進行建模分析、從海量數據中識別關鍵數據、對數據進行聯動關系分析和利用新數據發現新關系模式等。這些目標的組合可實現多種實際用途。例如可用于提高生產決策的準確率、提供智能制造的決策支持、進行需求預測、識別各類客戶以實現多角度精準營銷,以及實現整個產業鏈的動態戰略規劃。總之,本文構建的產品大數據分析方法可以實現多種分析目標和多種實際用途。
6 結論
本文針對現有大數據分析方法只側重算法性能優化以及現有大數據分析方法難以綜合分析網絡形態數據之間連動關系的問題,提出了一個基于擴展QFD和網絡圖的產品大數據分析方法。該方法可識別出產品大數據之間的固有關系,并以網絡圖的方式表示數據關系,最終用于多目標分析。多目標分析包括從海量數據中獲取關鍵數據、識別產品在市場中的動向等,故使用基于擴展QFD和網絡圖的產品大數據分析方法將對決策者有重要意義。
[1]化柏林,李廣建.大數據環境下的多源融合型競爭情報研究[J].情報理論與實踐,2015,38(4):1-5.
[2]MANYIKA J,CHUI M,BROWN B,et al.Big data:the next frontier for innovation,comptetition,and productivity[J].Analytics,2011:27-31.
[3]ZHANG F,LIU M,GUI F,et al.A distributed frequent itemset mining algorithm using spark for big data analytics[J].Cluster computing,2015,18(4):1493-1501.
[4]WU X,FAN W,PENG J,et al.Iterative sampling based frequent itemset mining for big data[J].International journal of machine learning and cybernetics,2015,1(6):1-8.
[5]SARMA T H,VISWANATH P,REDDY B E.A fast approximate kernel k-means clustering method for large data sets[C]// Recent Advances in Intelligent Computational Systems.IEEE,2011:545-550.
[6]TSANG I W,KWOK J T,CHEUNG P M.Core vector machines:fast SVM training on very large data sets[J].Journal of machine learning research,2005,6(1):363-392.
[7]LEE L H,WAN C H,RAJKUMAR R,et al.An enhanced support vector machine classification framework by using euclidean distance function for text document categorization[J].Applied intelligence,2012,37(1):80-99.
[8]WAN C H,LEE L H,RAJKUMAR R,et al.A hybrid text classification approach with low dependency on parameter by integrating K-nearest neighbor and support vector machine[J].Expert systems with applications,2012,39(15):11880-11888.
[9]JIANG S,PANG G,WU M,et al.An Improved k-Nearest Neighbor Algorithm for Text Categorization[C]// Advances in Computation of Oriental Languages—Proceedings of the,International Conference on Computer Processing of Oriental Languages.2003:1503-1509.
[10]SUDHAHAR S,VELTRI G A,CRISTIANINI N.Automated analysis of the US presidential elections using big data and network analysis[J].Big data & society,2015,2(1):1-28.
[11]HE Y,YU F R,ZHAO N,et al.Big data analytics in mobile cellular networks[J].IEEE access 2017,4:1985-1996.
[12]ALAMSYAH A,PERANGINANGIN Y.Effective knowledge management using big data and social network analysis[J]Learn organ manage bus int J.2013,1(1):17-26.
[13]LOBB R,CAROTHERS B J,LOFTERS A K.Using organizational network analysis to plan cancer screening programs for vulnerable populations.[J].American journal of public health,2014,104(2):358-364.
[14]CHOPADE P,ZHAN J,BIKDASH M.Node attributes and edge structure for large-scale big data network analytics and community detection[C]// IEEE International Symposium on Technologies for Homeland Security.IEEE,2015:1-8.
[15]赤尾洋二,水野滋.Quality function deployment:integrating customer requirements into product design[M].Productivity Press,1990.
[16]MEHRJERDI Y Z.Applications and extensions of quality function deployment[J].Assembly automation,2010,30(4):388-403.
[17]王國順,曹峰彬.基于產業網絡的企業BP評價模型——以湖南現代制造業為例[J].中南大學學報(社會科學版),2009,15(6):771-775.
[18]曹霞,張路蓬.基于扎根理論的合作創新網絡可拓機理與優化路徑[J].中國科技論壇,2015(9):24-30.
[19]NI M,XU X,DENG S.Extended QFD and data-mining-based methods for supplier selection in mass customization[J].International journal of computer integrated manufacturing,2007,20(2):280-291.
ABigDataAnalyticMethodBasedonAnExtendedQFDandWebGraphandItsApplication
Tang Zhongjun,Cui Junfu,Yu Haibo
(School of Economics and Management,Beijing University of Technology, Research Base of Beijing Modern Manufacturing Development,Beijing 100124,China)
Extant big data analytic methods focus on boosting performance of algorithm but ignore to take inherent relationships of data into consideration.And the methods are lack of ability to process web-based data thoroughly.This paper has proposed a big data analytic method based on extended QFD and web graph.The method consists of①an data relationship-oriented extended QFD that can identify relationships of big product data categories,②a description model of product big data’s categories that is constructed to web form to display the relationships of data categories,and③a description model-based big data analytic model which is aimed to recognize patterns in a multi-dimensional way.The proposed method can display the data with complex shape and multiple connections in an explicit way via web form and then explore the big product data by making use of various suitable big data analytic methods for identifying the key data among huge data and finding new data and its relationship.The method can make it possible to combine the algorithm and data modeling more effectively.
Big data analytics;Quality function deployment;Web graph;Big product data
國家自然科學基金面上項目“基于類比推理的短生命周期無形體驗品需求預測”(71672004)。
2017-04-13
唐中君(1969-),男,湖南人,北京工業大學經濟與管理學院博士生導師;研究方向:需求預測、運營與營銷。
F272.3
A
(責任編輯 劉傳忠)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
Coco薇(2015年1期)2015-08-13 02:23:50
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
玩具(2009年10期)2009-11-04 02:33:14
個人電腦(2009年9期)2009-09-14 03:18:46
