Huffman編碼在不同場景中的應(yīng)用研究
2018-02-09 21:25:13陳泓夫
科技傳播 2018年3期
陳泓夫
摘 要 文章主要針對不同場景的信源進行概率統(tǒng)計,并進行Huffman編碼。通過編碼分析得到了不同信源Huffman編碼的區(qū)別,并將編碼長度與香農(nóng)極限進行了比較。發(fā)現(xiàn)在信源長度較長時,實際Huffman編碼長度接近于香農(nóng)極限,而在信源較短時,則與香農(nóng)極限差別較大。
關(guān)鍵詞 信源編碼;Huffman編碼;香農(nóng)極限
中圖分類號 TP3 文獻標(biāo)識碼 A 文章編號 1674-6708(2018)204-0148-02
信源編碼是將人類可以感知的機械信號轉(zhuǎn)化為計算機或者數(shù)字邏輯電路可以感知的電信號,數(shù)學(xué)上表示為“01”串,是通信領(lǐng)域的一個重要環(huán)節(jié)。除進行信息轉(zhuǎn)化,信源編碼要消除信息冗余,從而提高傳輸效率,所以信源編碼又叫信源壓縮編碼。
文章主要分為以下幾個方面:1)統(tǒng)計了特定場景信源的符號特征,得到了其頻率;2)把得到的頻率作為概率,對該場景的信源進行了Huffman編碼,并與香農(nóng)極限進行了比較;3)針對不同場景的Huffman編碼結(jié)果進行了分析。
本文的剩余章節(jié)安排如下:第1章介紹Huffman編碼的基本原理;第2章介紹一個特定場景下的Huffman編碼;第3章介紹不同場景的 Huffman編碼研究分析;第4章對本文進行總結(jié)。
1 基本原理
文章主要介紹Huffman編碼的基本原理。Huffman編碼基于Huffman樹的構(gòu)造,構(gòu)造過程如下:
1)統(tǒng)計字符序列的每種字符的頻率,并為每種字符建立一個節(jié)點,節(jié)點權(quán)重為其頻率;
2)初始化最小優(yōu)先隊列中,把上述的結(jié)點全部插入到隊列中;
3)取出優(yōu)先隊列的前兩種符號節(jié)點,并從優(yōu)先隊列中刪除;
4)新建一個父節(jié)點,并把上述兩個節(jié)點作為其左右孩子節(jié)點,父節(jié)點的權(quán)值為左右節(jié)點之和;
5)如果此時優(yōu)先隊列為空,則退出并返回父節(jié)點的指針。否則把父節(jié)點插入到優(yōu)先隊列中,重復(fù)步驟3)。
完成構(gòu)造Huffman樹之后,將每個父節(jié)點的左子節(jié)點編碼為1(0),右子節(jié)點編碼為0(1),每個字符正好是Huffman樹的葉子節(jié)點,從根節(jié)點做深度優(yōu)先搜索即可得到并將路徑上節(jié)點的編碼拼在一起即為該字符的Huffman編碼。在本文中,用上下子節(jié)點來代替左右子節(jié)點。
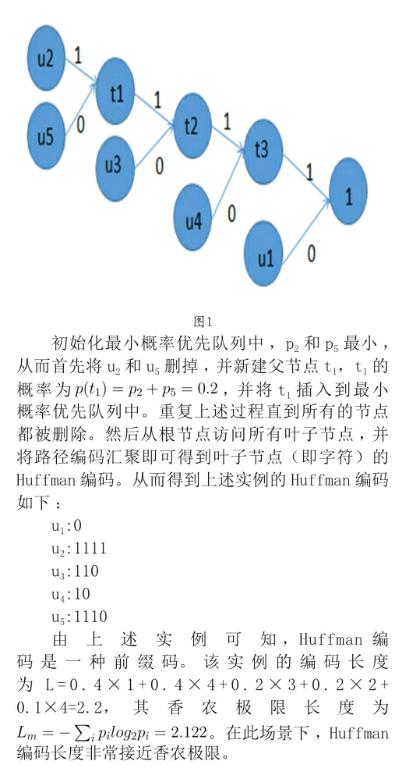
2 特定場景下的Huffman編碼
文章摘取了BBC一篇新聞稿,對其Huffman編碼情況進行了研究分析。首先我們統(tǒng)計了該新聞稿的字符頻率情況(共12 524個字符),如表1所示。
將上標(biāo)的字符頻率作為字符概率,構(gòu)建得到的Huffman樹如圖2所示。
3 不同場景下的Huffman編碼分析
更換一個場景的信源做統(tǒng)計,將統(tǒng)計得到的頻率作為概率使用,并進行Huffman編碼,發(fā)現(xiàn)當(dāng)統(tǒng)計字符個數(shù)較多時(如超過10 000個字符),各個字符的統(tǒng)計頻率趨于穩(wěn)定,Huffman編碼長度非常接近香農(nóng)極限長度,所以,Huffman編碼是一種熵編碼。
4 結(jié)論
文章主要介紹了Huffman編碼在實際信源場景中的應(yīng)用,并對不同應(yīng)用場景下的編碼進行了研究分析,在不同場景下,各個字符的統(tǒng)計頻率趨于穩(wěn)定,所以,Huffman編碼形式趨于穩(wěn)定。Huffman在實際應(yīng)用中的編碼長度趨近于香農(nóng)極限。
參考文獻
[1]Shannon C E.A mathematical theory of communica tion[J].ACM SIGMOBILE Mobile Computing and Communications Review,2001,5(1):3-55.
[2]Knuth D E.Dynamic Huffman coding[J].Journal of algorithms,1985,6(2):163-180.表1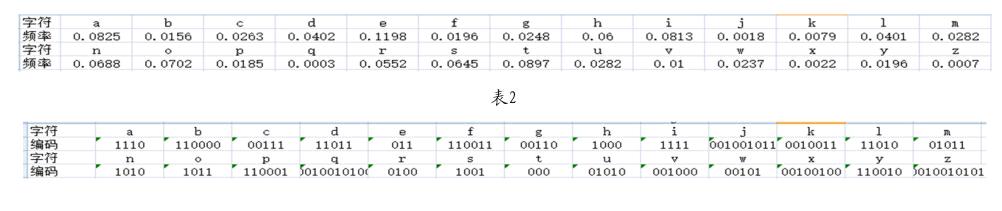 endprint
endprint
