基于正態(tài)信息擴散的新多變量模糊時間序列模型研究
2018-02-25 05:32:40李肖肖付恒春
統(tǒng)計與決策 2018年24期
薛 曄,李肖肖,付恒春
(太原理工大學(xué) 經(jīng)濟管理學(xué)院,太原030024)
0 引言
時間序列分析方法不但可以從數(shù)量上揭示現(xiàn)象的變化規(guī)律,而且還能預(yù)測現(xiàn)象的未來行為,但在自然科學(xué)與社會科學(xué)研究中常常會存在一些具有模糊、不完備、或變量間相互關(guān)聯(lián)等特性的時間序列。例如,貨幣流通情況通常可描述為正常、不正常、很不正常等模糊語義數(shù)據(jù),這種經(jīng)濟現(xiàn)象的形成往往是受多種因素交互影響的結(jié)果。若用傳統(tǒng)的時間序列模型對其變動趨勢進(jìn)行解釋,很可能會導(dǎo)致模型判定偏差或預(yù)測結(jié)果和實際值間的誤差。因此研究多變量模糊時間序列具有重要的理論和實踐意義。
Song等[1,2]提出模糊時間序列的概念,并對美國阿拉巴馬州的每年招生人數(shù)進(jìn)行預(yù)測。Chen等[3]提出聚類算法,根據(jù)對樣本數(shù)據(jù)的聚類結(jié)果確定各子區(qū)間的劃分。Emrah[4]基于聚類分析建立模糊時間序列模型,以二變量C-均值聚類模型對租船費率做預(yù)測,以衡量模型精度的均方根誤差顯示該模型比傳統(tǒng)模糊時間序列模型優(yōu)越。Rubio等[5]根據(jù)與原始模糊邏輯關(guān)系相關(guān)的時間順序,在模糊時間序列中使用新的加權(quán)算子來提高預(yù)測精度。Avazbeigi等[6]為預(yù)測伊朗公司的汽車工業(yè)產(chǎn)量,利用禁忌搜索算法構(gòu)建了多元高階模糊時間序列模型。邱望仁等[7]基于證據(jù)理論選取開盤價、最高價及最低價的243個日交易數(shù)據(jù)對滬市股指預(yù)測,并得出多變量模糊時間序列模型的預(yù)測精度高于單變量模型的結(jié)論。
綜上所述,目前對于模糊時間序列模型的研究主要集中在大樣本多變量或僅是單變量的的情況,但事實上大多是受多個變量影響且小樣本的情況。鑒于此,本文結(jié)合信息擴散理論可以充分提取樣本數(shù)據(jù)的信息,彌補樣本不足的缺陷,構(gòu)建一個正態(tài)擴散多變量模糊時間序列模型。
1 信息擴散
1.1 信息擴散基本原理
設(shè)X是給定樣本,U是論域V的一個子集。從X×U到[0,1]上的一個映射,即:

則稱X在U上的一個信息擴散。
如果μ(x,u)是遞減的,即若,那么μ稱為一個擴散函數(shù),U稱為一個監(jiān)控空間。
?g∈G,假定Xg的選定監(jiān)控空間為是一個有序等距分割集合ugj所組成的集合,即為Ugj的區(qū)間長度。
1.2 多變量正態(tài)擴散函數(shù)

根據(jù)中心極限定理和大數(shù)定律,目前的經(jīng)濟行為和經(jīng)濟現(xiàn)象一般近似服從正態(tài)分布,因此,本文選取正態(tài)信息擴散函數(shù)[8]。
設(shè)?xi∈X是一個r變量向量,即且令:,為X的選定監(jiān)控空間。U中有個元素。令μ(g)為Xg在Ug上的一個擴散函數(shù),記作

其中,hg稱作第g個擴散系數(shù)。
注:對于每一個Xg,都有一個正態(tài)擴散函數(shù)的模糊集Fg與之對應(yīng),這一過程稱為時間序列的模糊化。模糊集Fg不唯一,隨著區(qū)間長度Δ與擴散系數(shù)h的變化而變化。
1.3 正態(tài)擴散系數(shù)確定方法
正態(tài)擴散系數(shù)h的選擇直接影響著擴散函數(shù)的預(yù)測結(jié)果,若h越小,則函數(shù)結(jié)果就越不穩(wěn)定;若h越大,則函數(shù)結(jié)果的分辨率就越低。因此針對小樣本而言,h的確定顯得尤為重要。目前應(yīng)用最廣泛的確定信息擴散系數(shù)的方法有兩種:
(1)基于兩點擇近原則確定

(2)基于積分均方誤差(MISE)最小原則確定

其中σ為樣本觀測值的標(biāo)準(zhǔn)差。
2 多變量模糊時間序列預(yù)測模型的建立
多變量模糊時間序列模型的構(gòu)建主要步驟包括:(1)利用多變量正態(tài)信息擴散構(gòu)造模糊信息矩陣;(2)運用模糊集理論構(gòu)建模糊關(guān)系矩陣;(3)基于模糊近似推理方法建構(gòu)多變量模糊時間序列預(yù)測模型。
2.1 模糊信息矩陣的建立


即:

于是W在上的模糊信息矩陣為:
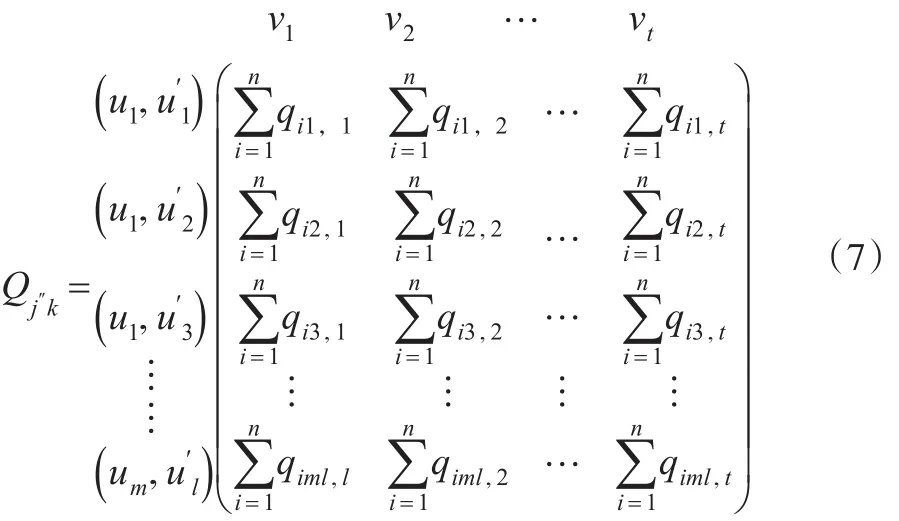
2.2 模糊關(guān)系矩陣的建立
依據(jù)模糊集理論,將式(7)轉(zhuǎn)化為模糊關(guān)系矩陣式(9),具體計算如下:

則模糊關(guān)系矩陣為:

2.3 多變量模糊時間序列模型的建立
利用模糊近似推理方法建構(gòu)多變量模糊時間序列預(yù)測模型:

考慮到模型的復(fù)雜度與模型精度,將“?”選為“∨-*”,則正態(tài)擴散多變量模糊時間序列模型(NDMFTSM):

注:(1)R隨著hx、hy和hz的變化而變化。即,只要確定了hx、hy和hz,模糊關(guān)系矩陣R也隨之確定。(2)基于正態(tài)信息擴散方法構(gòu)建模糊關(guān)系矩陣的操作簡單易行,可以避免大量復(fù)雜計算。
3 中國SO2排放量的預(yù)測
造成大氣污染的重要因素之一SO2的過量排放不僅對人們生活質(zhì)量及國家經(jīng)濟可持續(xù)發(fā)展存在著顯著的負(fù)面影響,而且SO2與能源消耗、經(jīng)濟增長密切相關(guān),因此本文選取度量能源消耗的能源消費總量(TEC)、度量經(jīng)濟總量的人均GDP(PCGDP)兩個指標(biāo)來預(yù)測二氧化硫排放量(ESO2)。
3.1 數(shù)據(jù)來源及預(yù)處理
本文選取的是2006—2016年TEC、PCGDF、ESO2的時間序列數(shù)據(jù)(見表1),數(shù)據(jù)均來自2007—2017年《中國統(tǒng)計年鑒》。

表1 TEC、PCGDF、ESO2的時間序列數(shù)據(jù)
為了減少分散程度和提高預(yù)測精度,將表1中數(shù)據(jù)進(jìn)行對數(shù)預(yù)處理,即Y=ln(ESO2),見表2所示:

表2 ln(T EC)、ln(P CGDF)、ln(E SO2)的時間序列數(shù)據(jù)
3.2 二氧化硫排放量的預(yù)測
3.2.1 NDMFTSM模型的預(yù)測
由表2樣本數(shù)據(jù)可得:ax=12.985,bx=12.565;代入公式(3)可得選取論域:由式(5)至式(7)計算得到模糊信息矩陣:

由式(8)及式(9)可得模糊關(guān)系矩陣:


將模糊關(guān)系矩陣R25×5和信息擴散矩陣P,代入式(11)得到2007—2016年二氧化硫排放量的預(yù)測值F?t,見表3:

表3 NDMFTSMh0的預(yù)測結(jié)果

為了與馬爾可夫模型的預(yù)測結(jié)果進(jìn)行比較,利用式(12)對表3結(jié)果計算模糊集重心GCt,另外,為了更清楚地顯現(xiàn)不同模型預(yù)測結(jié)果的變化情況,進(jìn)一步對GCt進(jìn)行對數(shù)逆變換指數(shù)運算結(jié)果見表4第5列。
此外,進(jìn)一步討論信息擴散系數(shù)對模型預(yù)測精度的影響,將表2數(shù)據(jù)代入式(4)得到,再由式(5)至式(12)得到SO2排放量預(yù)測值見表4第6列。

表4 不同h情況下NDMFTSM對SO2排放量的預(yù)測值及誤差
由表4可知,與NDMFTSMh0相比較而言,NDMFTSMhMISE的絕對誤差較大,在2007年、2010年、2011年、2013—2016年的預(yù)測值與實際值的偏離較遠(yuǎn)。此外,表4第12行的MAE,32.741<51.433;表4第13行的MAPE,0.016<0.024,表明信息擴散系數(shù)對NDMFTSM的預(yù)測精度有影響,且小樣本時,NDMFTSMh0的預(yù)測效果較好,即比較理想地反映了實際值的變動趨勢,而NDMFTSMhMISE預(yù)測值的曲線波動較大,如圖1所示。

圖1 不同的信息擴散系數(shù)對模型精度的影響
3.2.2 Markov模型的預(yù)測
為了與NDMFTSM進(jìn)行比較,選取一階Markov模型[9]對2007—2016年中國二氧化硫排放量進(jìn)行預(yù)測。設(shè)只受的影響,并且選取與NDMFTSM模型相同的論域U、U′與V。則:

其中,RM為模糊馬爾可夫相關(guān)矩陣,且:

基于matlab7.0計算得到RM:

將表2數(shù)據(jù)以及RM代入式(13)得到二氧化硫排放量的預(yù)測值,具體結(jié)果見表5第4列。

表5 Markov對SO2排放量的預(yù)測值及誤差
3.3 結(jié)果比較分析
依據(jù)表4和表5可知,NDMFTSMh0與NDMFTSMhMISE的預(yù)測結(jié)果與實際值的偏差均小于Markov模型,又因為32.741<51.433<81.984,0.016<0.024<0.040,所 以 NDMFTSM的預(yù)測誤差較小,即模型精度較高,其中NDMFTSMh0的預(yù)測最優(yōu)。相對而言,NDMFTSMh0較好地反映了實際值的變動趨勢,NDMFTSMhMISE與Markov模型在預(yù)測期初以及期末都出現(xiàn)了不同程度的偏離,曲線波動比較大,如下頁圖2所示。主要原因在于Markov及NDMFTSM模型中的模糊關(guān)系矩陣R的建立方式不同,前者依據(jù)變量當(dāng)期及滯后一期的時間序列F(Xt)及F(Xt-1)定義的“×”運算取得模糊關(guān)系矩陣RM,當(dāng)變量個數(shù)增加或樣本容量增大時,RM不僅可能出現(xiàn)模糊關(guān)系爆炸的現(xiàn)象,還需大量的運算時間;而NDMFTSM模型在小樣本或信息不充分、不完備的情況下,仍可提取樣本中更多的有用信息以彌補樣本不足的缺陷,進(jìn)一步提高模型的精度。對所建模型值得一提的是:隨著樣本容量的增大,模糊關(guān)系矩陣的計算難度不會增加反而還提高了模型的預(yù)測精度。

圖2 實際值和NDMFTSM及Markov模型的預(yù)測結(jié)果
4 結(jié)論
本文利用正態(tài)信息擴散技術(shù)構(gòu)建了一個多變量模糊時間序列模型,并討論h0與hMISE對NDMFTSM的影響,進(jìn)而與一階Markov模型結(jié)果進(jìn)行對比分析。結(jié)果表明:(1)信息不完備或小樣本問題情況下,NDMFTSM利用正態(tài)信息擴散技術(shù)提高了模型的預(yù)測精度;(2)h影響NDMFTSM的預(yù)測精度;小樣本時,NDMFTSMh0的預(yù)測精度更高;(3)在預(yù)測二氧化硫排放量時,NDMFTSM比Markov模型的預(yù)測效果好且計算過程方便簡潔。需要指出的是,本文僅選取了兩種比較常用的信息擴散系數(shù)的確定方法,雖然結(jié)果比較理想,但還是具有一定的局限性,下一步將對h的確定方法做深入研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
上海金屬(2015年5期)2015-11-29 01:13:59
上海金屬(2015年6期)2015-11-29 01:09:09
數(shù)學(xué)物理學(xué)報(2015年2期)2015-02-28 16:06:39
中外會展(2014年4期)2014-11-27 07:46:46
上海金屬(2013年4期)2013-12-20 07:57:07
