基于n-gram頻率的語種識別改進方法
2018-04-16 11:55:49郝洺徐博殷緒成王方圓
自動化學(xué)報 2018年3期
郝洺 徐博 殷緒成 王方圓
現(xiàn)如今,隨著社交媒體全球化的發(fā)展以及其以短文本作為主要載體的特點,使得識別短文本的語言種類成為社交媒體中自然語言處理任務(wù)的一個挑戰(zhàn)性熱點課題.語種識別主要的解決方案是觀察所有語言典型的字母序列發(fā)生的頻率.早在1994年Cavnar等提出了基于n-gram的詞頻排序方法[1],核心思想是比較語言模型文件和目標(biāo)文本的n-gram詞頻排序列表.這個方法在400字以上的長文本取得了99.8%的準(zhǔn)確率.Frank于2003年,將這個方法實現(xiàn)成語種識別工具,并命名為Textcat[2].
其他應(yīng)用在短文本語種識別上的方法也有很多,Hammarstrom在2007年闡述了一個用詞綴表來擴充詞典的方法,并且用一個平行語料庫來進行測試[3].Ceylan等在2009年提出了使用決策樹來分類語言種類的方法[4],Vantanen等在2010年針對5~21個字符的文本,提出了使用n-gram語言模型并結(jié)合樸素貝葉斯分類器的方法來實現(xiàn)語言種類的目的[5].
Carter等于2013年針對推特信息提出了基于用戶先前消息和嵌入在消息中的連接的內(nèi)容來實現(xiàn)語種識別的方法,同時該方法也運用在TwitIE上[6].Tromp等在2011年提出基于n-gram的圖結(jié)構(gòu)語種識別方法[7],該方法不僅利用詞本身的信息,還有效利用了詞與詞之間的信息,使得短文本的語種識別效率大大提升.隨后Vogel等在此基礎(chǔ)上做了改進[8].
在這期間,又有很多語種識別工具被研發(fā)出來,Lui等在2012年利用n-gram特征結(jié)合多項式樸素貝葉斯分類器創(chuàng)造出langid.py[9];Nakatani在同年發(fā)布了IDIG,一個基于常識、正則化和貝葉斯分類器的語種識別工具[10],該工具用于推特數(shù)據(jù)集.2013年Brown提出基于n-gram字符特征權(quán)重的空間向量模型[11].
隨著深度學(xué)習(xí)技術(shù)越來越成熟,許多研究員開始思考如何將深度學(xué)習(xí)技術(shù)運用到語種識別中,并且做了很多嘗試.然而經(jīng)過實踐,深度學(xué)習(xí)技術(shù)在語音領(lǐng)域有很好的效果[12?18],與此同時,面向語音領(lǐng)域的語種識別技術(shù)也愈發(fā)成熟[19?21].但對于短文本而言,隨著語料庫不斷地完善,基于統(tǒng)計的機器學(xué)習(xí)方法更為簡單高效[22?23].
然而,傳統(tǒng)基于n-gram的語種識別對數(shù)據(jù)集有很強的依賴.Baldwin等指出,在6種歐洲語料集上取得良好的識別效果并不意味著在含有更多語種的語料集上會取得同樣不錯的效果[24].Lui等對各個語種識別模型的評測實驗中指出,同一種模型在不同數(shù)據(jù)集上的準(zhǔn)確率也相差甚遠[25].同時他們也指出去除數(shù)據(jù)集中的噪音,如推特數(shù)據(jù)集的特殊字符,對識別率的提高有明顯的幫助.
在本文中,我們將Textcat、LIGA和logLIGA三個模型在 Europarl[26]、LIGA-dataset、Twituser-21、Twituser-7四個數(shù)據(jù)集中分別做交叉驗證,同時,我們使用Europarl做訓(xùn)練集,LIGA-dataset、Twituser-21、Twituser-7做測試集,兩組實驗結(jié)果相差較大.因為在同一個數(shù)據(jù)集中,訓(xùn)練集的內(nèi)容往往涵蓋了測試集或者跟測試集相近,因此一旦訓(xùn)練集與測試集分別為兩個不同的數(shù)據(jù)集,那么測試集中會含有大量訓(xùn)練集中沒有出現(xiàn)過的詞,即集外詞.同時,不同語種但屬于同一種語系的語言,會含有很多拼寫相同的詞(如英語和荷蘭語都有“is”).在短文本中,這些詞匯在文中所占的比例要比長文本高得多,對語種識別的正確率有一定的影響.
我們可以提高每一個語種特征詞的權(quán)重,提高單詞在所屬語種的辨識度,這樣不僅可以解決大類別語種數(shù)量增加而導(dǎo)致相似度計算的干擾,同時使集外詞在句子中所占比例減小,減少集外詞對語種識別的影響.此外我們還可以減少所有語種都含有的共有詞的權(quán)重,以降低其在短文本中所占的比重,從而達到提高識別率的效果.
因此,本文提出一個根據(jù)不同的訓(xùn)練數(shù)據(jù),自適應(yīng)學(xué)習(xí)特征詞和共有詞的權(quán)重,來增強語種識別模型在不同數(shù)據(jù)集的魯棒性的方法,并將其應(yīng)用在Textcat、LIGA和logLIGA三個模型上,實驗證明了該方法的有效性.
1 相關(guān)工作
1994年Cavnar等[1]提出了基于n-gram的詞頻排序方法,并且在400字以上的長文本中取得很好的效果.然而多數(shù)現(xiàn)代社交軟件(如推特、微博等)的信息長度均限制在140個字符以內(nèi),這對語種識別任務(wù)提出了新的挑戰(zhàn).針對這一類短文本信息,Tromp等[7]指出,基于n-gram 的方法在區(qū)分6種歐洲語言的推特數(shù)據(jù)集上,只有93.1%的準(zhǔn)確率,Tromp還提出一種基于n-gram的圖結(jié)構(gòu)語種識別模型,使其分類的準(zhǔn)確率達到了97.5%,將錯誤率減少了一半,他們將其命名為LIGA.而后,Vogel等[8]于2012年6月提出了4種對LIGA的改進方案,分別是“加入詞長度信息”、“減少重復(fù)信息的權(quán)重”、“中位分?jǐn)?shù)法”、“l(fā)og頻率法”,并且通過實驗,指出log頻率法分類效果最佳.
1.1 Textcat模型
Cavnar等[1]的核心思想是Zipf定律—在自然語言的語料庫里,一個單詞出現(xiàn)的次數(shù)與它在頻率表里的排名成反比.他們先將文本進行清洗,去掉所有的標(biāo)點、數(shù)字等非字符的符號,然后將每個單詞前后均加上空格,將這些單詞切分成n-gram元組,并根據(jù)元組在該語種中出現(xiàn)的頻率由高到低進行排序,生成語言文件.同時對待識別文本也進行相同的處理,生成目標(biāo)文件.識別流程如圖1.
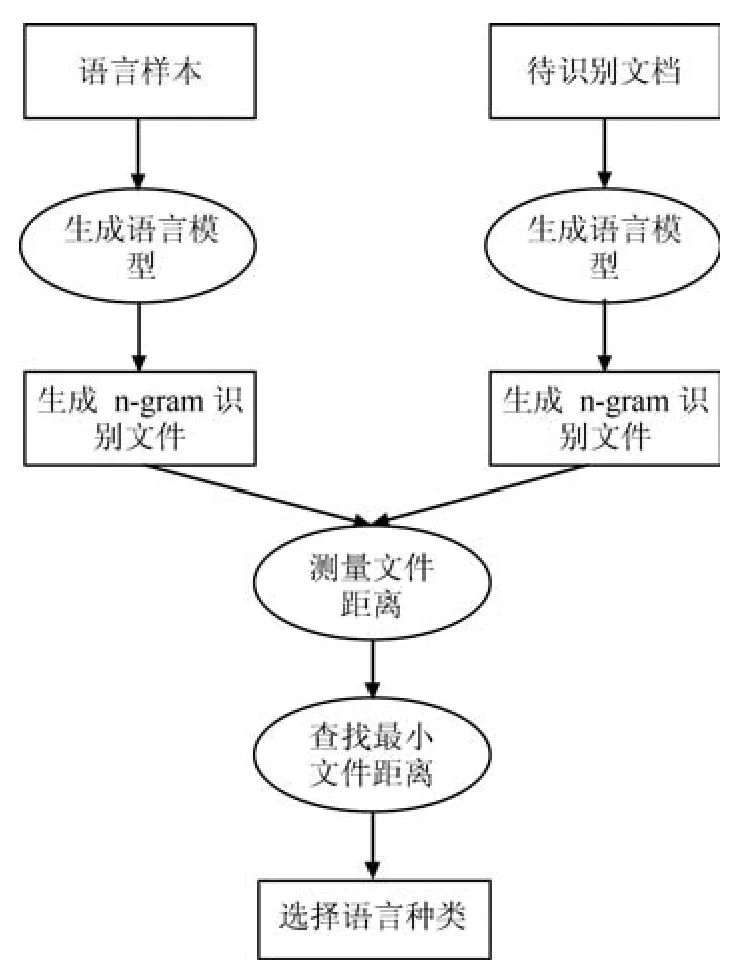
圖1 Textcat方法識別流程Fig.1 Identi fi cation process of Textcat
將目標(biāo)文件中每一個n-gram元組與每類語種中相同的n-gram元組的位置求差并取絕對值,如果語言文件中不包含目標(biāo)文件的n-gram元組,則位置差取該目標(biāo)文件的最大值.將目標(biāo)文件與每一類語言文件的位置差求和,位置差最小的那一類語種,即為目標(biāo)語種.相似度計算流程如圖2.
這個模型在400字以上的長文本中效果很棒,然而在140字以下的短文本中,效果大打折扣.同時,該模型對語料訓(xùn)練集的選取具有很強的依賴性,它在計算相似度時,如果如果語言文件中不包含待測語言的元組,相似度分?jǐn)?shù)則加上最大距離(即目標(biāo)文件最大值),然而語料集長度相差較大時,則匹配錯誤率會大大提高.
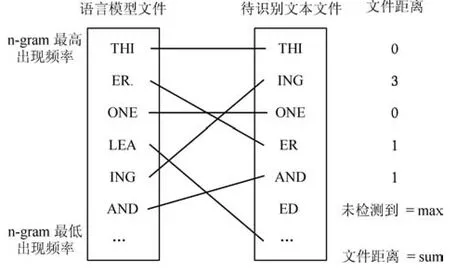
圖2 Textcat模型相似度計算Fig.2 Similarity calculation of Textcat
1.2 LIGA模型
LIGA是Tromp等[7]提出的基于n-gram的圖結(jié)構(gòu)模型,他們是構(gòu)建一個5元組G=(V,E,L,Wv,We),其中,V是n-gram元組,E是n-gram元組變換的邊,L是語種類別的標(biāo)簽,Wv和We分別是元組點和邊的權(quán)重.如:
(t1,NL)=is dit een test
(t2,EN)=is this a test
構(gòu)建成的圖結(jié)構(gòu)如圖3所示.
構(gòu)建好圖結(jié)構(gòu)之后,可以將待識別的文本也按照句子順序切分成3-gram元組,構(gòu)建成一個線性的圖結(jié)構(gòu),將這個結(jié)構(gòu)與之前語言模型的圖結(jié)構(gòu)進行比較,計算相似度,如圖4所示.
相似度計算方法為:圖模型中,如果某一語種含有待識別文件的點,則該語種的分值加一;同理,將如果某一語種含有待識別文件的邊,則該語種的分值也加一.將每一類語種的得分除以該語種圖內(nèi)所有點和邊的和(即求得目標(biāo)文件在該語種中所占的比重).最終哪一種語種分值最高,則認定其為待識別文件的語種.
這種方法不僅使用了單詞本身的信息,還有效利用了詞與詞之間信息,通過構(gòu)建圖模型將孤立的單詞元組聯(lián)系起來,使得識別準(zhǔn)確率得到了質(zhì)的飛躍.
1.3 logLIGA模型
Vogel等[8]在2012年提出4種對LIGA的改進方案,分別是“加入詞長度信息”、“減少重復(fù)信息的權(quán)重”、“中位分?jǐn)?shù)法”、“l(fā)og頻率法”.并且通過實驗證明,4種方法中“l(fā)og頻率法”效果最佳.簡單地說,該方法在LIGA模型計算相似度時,加入log平滑函數(shù).使用該方法的LIGA模型在6種歐洲語言的數(shù)據(jù)集上,取得了99.7%的效果.
以上方法均有效地提高了短文本識別的效果,但對數(shù)據(jù)集有很強的依賴性.在6種歐洲語言的數(shù)據(jù)集上,有不錯的效果,一旦更換數(shù)據(jù)集,效果就差強人意,魯棒性極差.分析其原因,是因為計算未知語種的n-gram的頻率,與已知語種的n-gram加以比較,因此它們對訓(xùn)練集有著強大的依賴.隨著大類別語種數(shù)、集外詞和共有詞的增加,訓(xùn)練集中各個語種的區(qū)分度就越來越小,導(dǎo)致識別率越來越低.因此我們提出了特征詞、共有詞的權(quán)重調(diào)整法,增強每一個語種的區(qū)分度,從而增強其魯棒性.
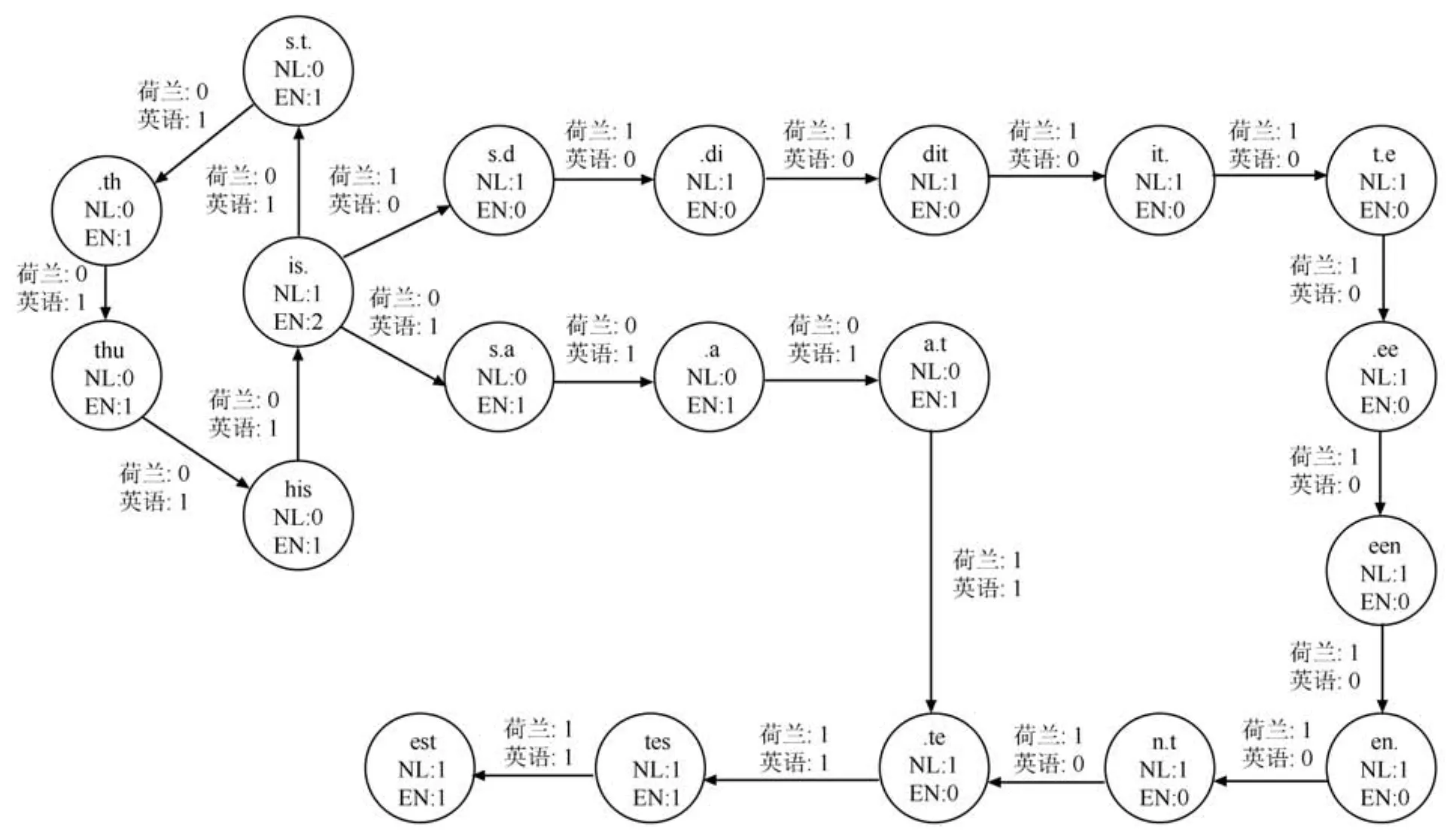
圖3 LIGA構(gòu)造圖模型樣例Fig.3 An example of the model of LIGA
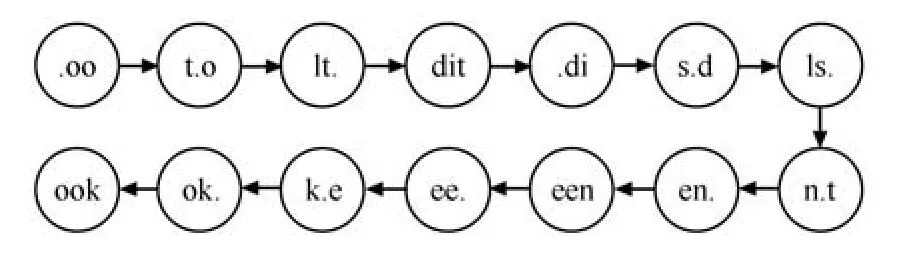
圖4 待識別文本的線性圖結(jié)構(gòu)Fig.4 The linear structure of the text to be recognized
2 方法
本文提出的方法是應(yīng)用于上述三個模型中.上述三個模型均是在已被標(biāo)記好的語料中進行訓(xùn)練,形成語言模型,標(biāo)簽是這些語料所屬的語種.具體做法是提取訓(xùn)練集中的特征詞和共有詞,并更新其權(quán)重,增強每一類語種的辨識度,從而達到提高模型魯棒性的目的.
2.1 定義
假定有K個語種,有已標(biāo)記文本集:
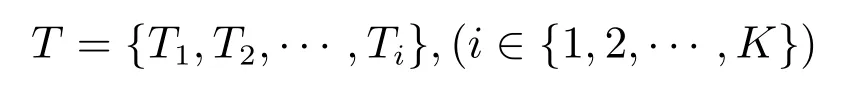
和未標(biāo)記文本集:
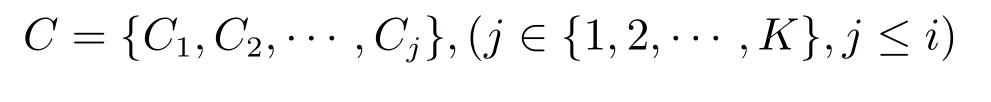
以一個二元組(t,l)∈Ti來表示已標(biāo)記文本集中每一個句子,其中t表示該句子的文本;l∈L表示該文本所對應(yīng)的語言種類,例如:(t1,EN)=hello表示t1句hello屬于英語.
當(dāng)以3-gram為基本單位創(chuàng)建序列時,用N3Ti來表示第i個語種的3-gram序列,可以得到如下序列(用“.”來表示空格):
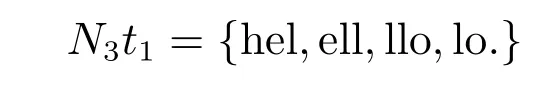
參考Tromp的方法,將語言模型定義成一個5元組:
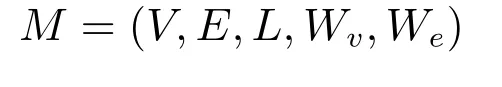
其中,V代表模型中切分好的3-gram點(如(hel)),E代表相鄰兩個節(jié)點轉(zhuǎn)換的邊(如(hel,ell)),L代表圖結(jié)構(gòu)中每一個點和邊所對應(yīng)的語種li∈L(i∈{1,2,···,K}).Wv和We代表點和邊的權(quán)重.特殊的是,在Textcat模型中,E=Φ,We=Φ.
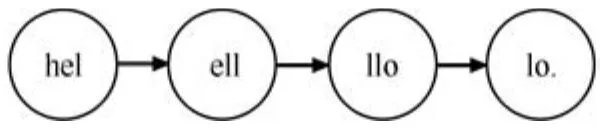
圖5 3-gram切分樣例Fig.5 An example of 3-gram
2.2 初始化與訓(xùn)練
模型初始化如下:

即構(gòu)建語言模型時,統(tǒng)計在同一種語言中點和邊的出現(xiàn)頻率.除此之外,我們分別構(gòu)造特征詞集F和共有詞集R.
2.2.1 構(gòu)造特征詞集F
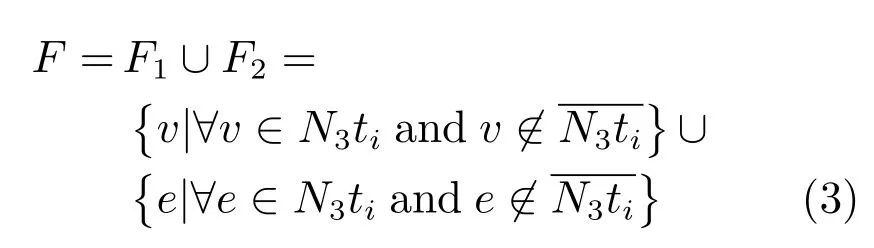
即在特征詞列集F中,點v和邊e只屬于某一語種.這種特征詞一旦出現(xiàn),則說明該待測文本是特征詞所屬語種的概率很大,從而提高語種識別的準(zhǔn)確率.
2.2.2 構(gòu)造共有詞集R
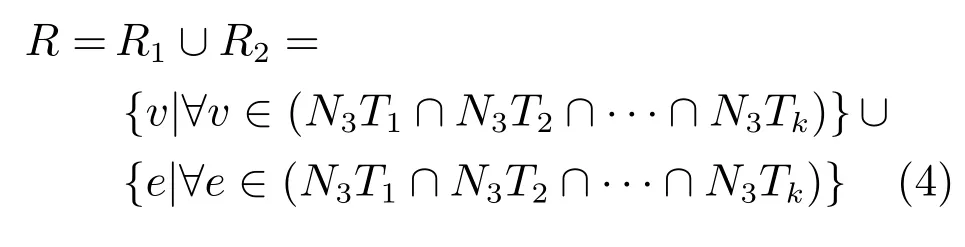
即在共有詞列表中,點v和邊e在N個語種集中均有出現(xiàn).這種共有詞會干擾到語種集中所的識別效果.
同上述模型一樣,我們需要將點和邊的權(quán)重求和:
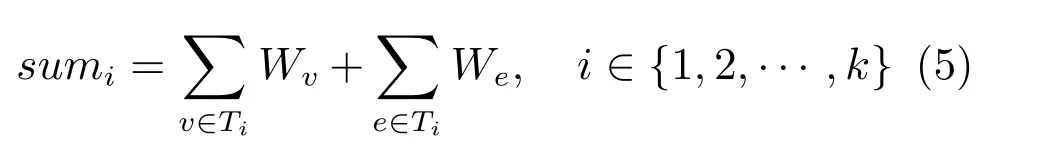
2.3 識別
首先將待識別文本與語言模型相匹配,求得該文本在各個語言模型中的權(quán)重和;然后,加入優(yōu)化的方法調(diào)整權(quán)重;最后,沿用原有模型計算相似度的方
式得出相似分?jǐn)?shù).首先計算待識別文本中點和邊的權(quán)重和,如式(6):
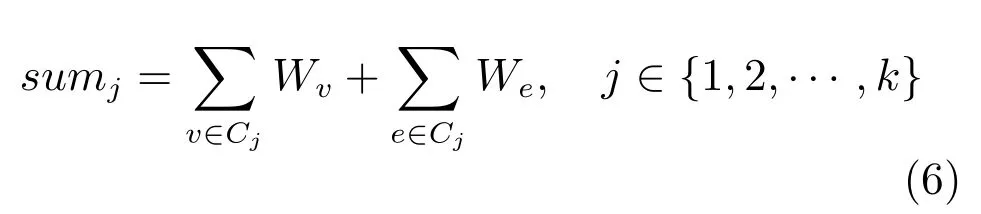
然后調(diào)整里邊含有特征詞的點和邊的權(quán)重,如式(7):
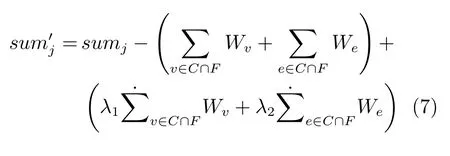
最后,用每個模型自身相似度計算方法計算待識別文本與各個語種的相似度,如式(8):
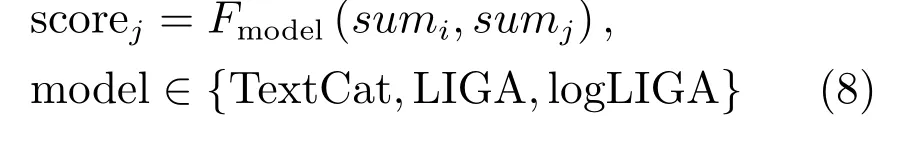
其中,λ1、λ2為調(diào)整點和邊權(quán)重的參數(shù),scorej代表該模型下待識別文本與第j個語種的相似度,Fmodel是原有模型計算相似度的方法,例如logLIGA的相似度計算方法為
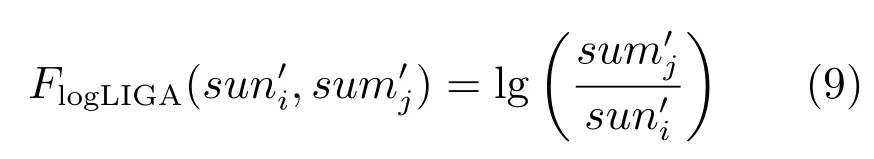
最終將最大的score所在的語種認定為待識別文本的語種:
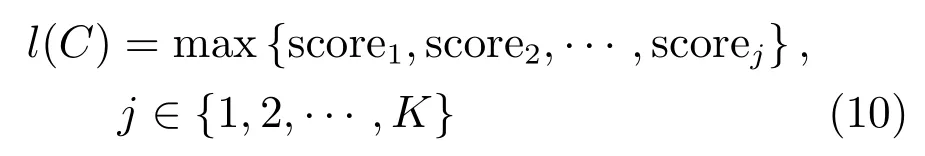
程序流程圖如圖6所示.
3 實驗
3.1 數(shù)據(jù)集
本文分別選取了4個不同的推特數(shù)據(jù)集,具體情況如表1如示.其中,Twituser_7是Twituser_21的子集.
本文做了如下實驗:
模型訓(xùn)練:要得到最優(yōu)的識別效果,就必須找到最合理的參數(shù).本文對式(7)中的λ1、λ2做主要調(diào)整.我們需要做同一參數(shù)下不同模型的效果對比,因此我們將三個模型同時訓(xùn)練,取平均效果最好的那一組參數(shù).
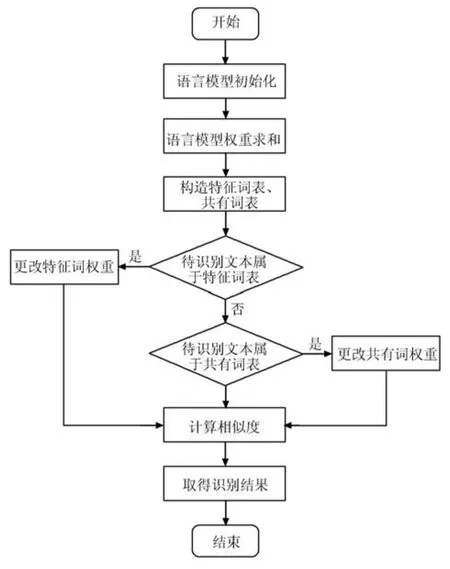
圖6 模型程序流程圖Fig.6 Program fl ow chart of the model
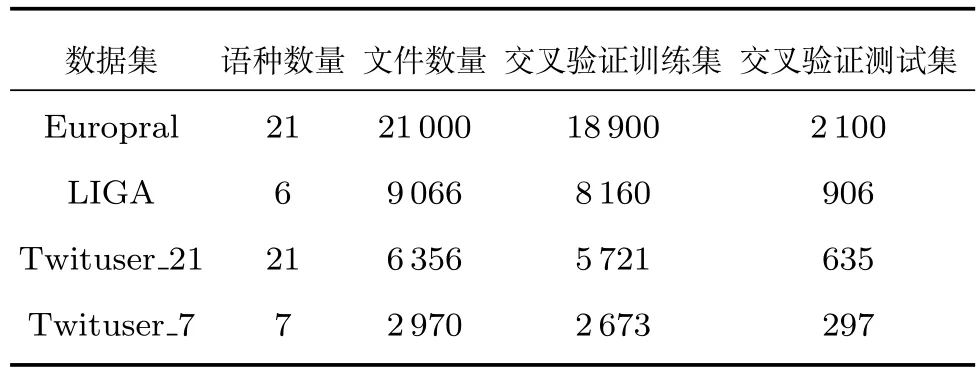
表1 四種數(shù)據(jù)集情況簡介Table 1 Introduction to four datasets
交叉驗證:為了驗證本文方法在同一組數(shù)據(jù)集下是否有效,分別把每一個數(shù)據(jù)集平均分成十份,隨機抽取其中的一份作為測試集,重復(fù)10次,識別結(jié)果取平均值.
魯棒性驗證:將Europarl數(shù)據(jù)集做為訓(xùn)練集,分別以LIGA_dataset(即6種歐洲語言數(shù)據(jù)集)、Twituser_21、Twituse_7作為測試集.由于這三個數(shù)據(jù)集并不是Europarl的子集,因此測試集會出現(xiàn)大量的集外詞.通過該實驗來驗證加入本文方法后,模型魯棒性是否有提升.
3.2 模型訓(xùn)練
本文將Europarl作為訓(xùn)練集,剩下三個數(shù)據(jù)集作為測試集,分別測試特征詞的權(quán)重從1到100、共有詞權(quán)重從0.01到1在三個數(shù)據(jù)集上的效果,用來選取最合理的參數(shù),如圖7和8所示.
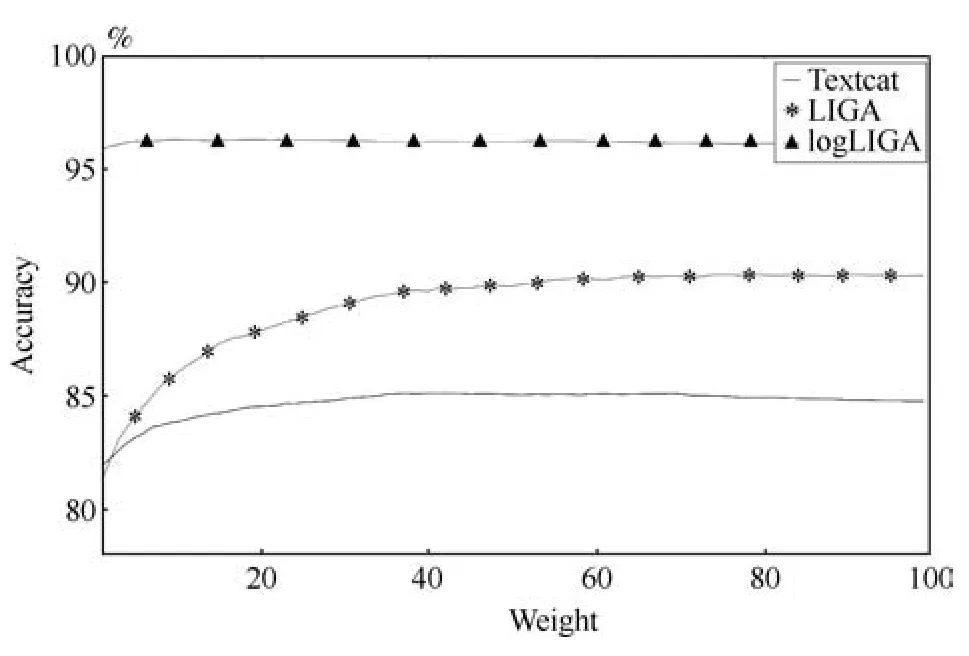
圖7 模型在LIGA數(shù)據(jù)集上特征詞權(quán)重的參數(shù)選擇Fig.7 Parameter selection of feature words′weights
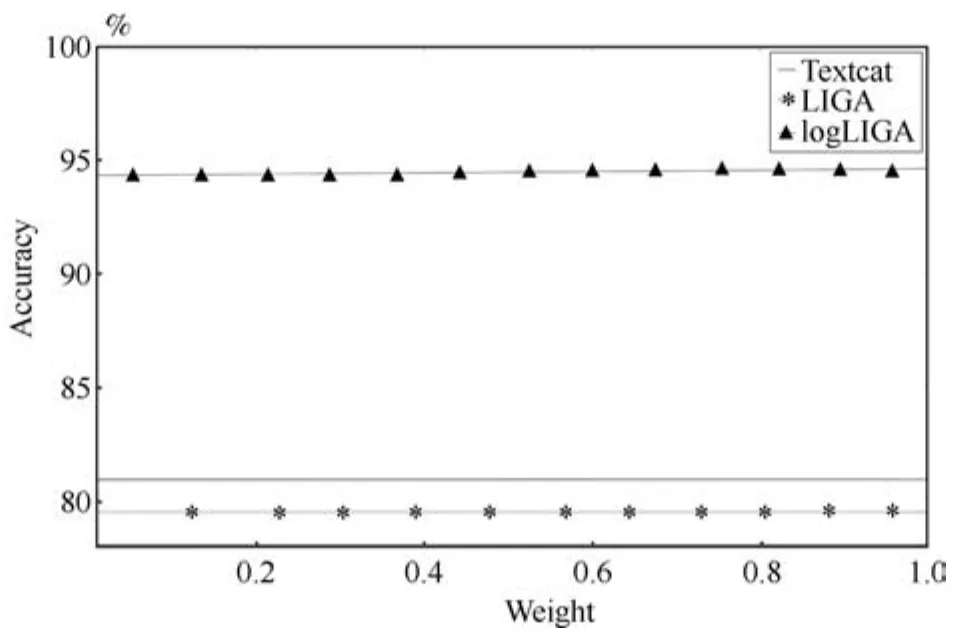
圖8 模型在LIGA數(shù)據(jù)集上共有詞權(quán)重的參數(shù)選擇Fig.8 Parameter selection of common words′weights
以同樣的方法分別在Twituser_7和Twituser_21上做了實驗.實驗表明,特征詞在權(quán)重為40、共有詞的權(quán)重在0.9的時候效果最佳.因此選取特征詞權(quán)重40和共有詞權(quán)重0.9.
同時在選擇共有詞權(quán)重的時候可以看出,共有詞對模型的識別率幾乎沒有任何影響.這是因為隨著大類別語種數(shù)量增多時,所有語種中都存在的詞就很少了.在Europarl數(shù)據(jù)集中,特征詞有329456個,而共有詞只有1441.當(dāng)訓(xùn)練集所包含的語言種類相似(如LIGA_dataset,只有6種歐洲語言,并且都屬于同一種語系)時,共有詞的作用才會凸顯出來.因此我們在后期工作中可以修正共有詞的概念以及權(quán)重調(diào)整的方式,來增強共有詞在大類別語種數(shù)據(jù)集上的魯棒性.
3.3 交叉驗證
為了驗證方法的通用性,分別將該方法運用在Textcat、LIGA和logLIGA上,并且在4個數(shù)據(jù)集中做了10組交叉驗證.同時我們與沒有加入我們方法的模型進行比較.實驗結(jié)果見圖9.
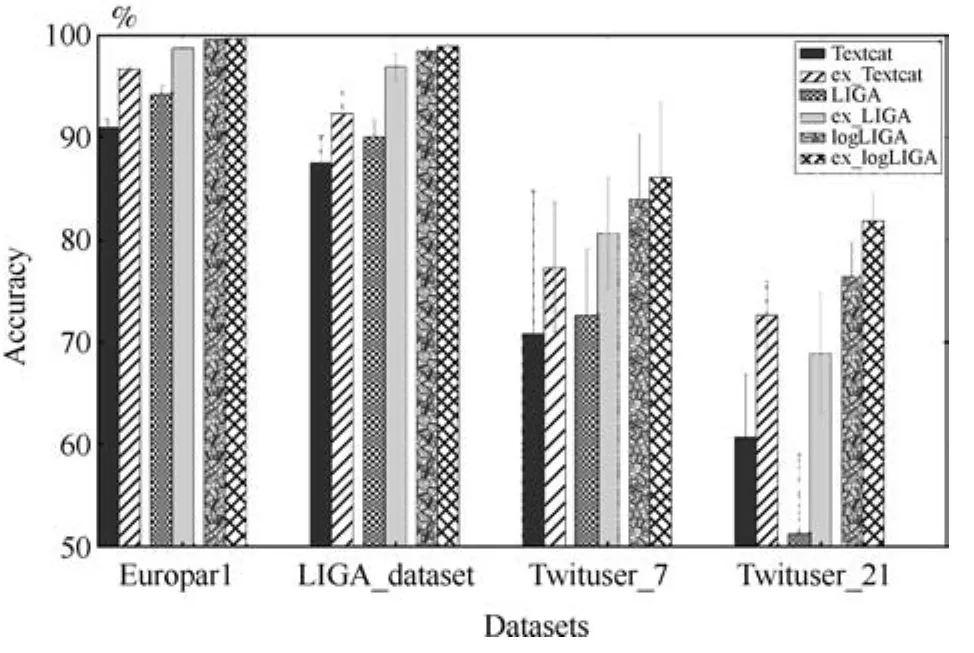
圖9 模型在同數(shù)據(jù)集內(nèi)交叉驗證結(jié)果Fig.9 The crosses validation results within the same dataset
根據(jù)圖表可以看出,傳統(tǒng)模型在很大程度上會受到數(shù)據(jù)量的影響,數(shù)據(jù)量越大,模型的識別率就越高.實驗表明,加入本文方法的模型ex_Textcat、ex_LIGA、ex_logLIGA的識別率分別比之前的模型有了顯著地提升,幅度高達6%.因此可以證明,在訓(xùn)練集、測試集屬于同一數(shù)據(jù)集時,本文方法可以有效地提高模型的識別率.
3.4 模型魯棒性驗證
將特征詞和共有詞的權(quán)重設(shè)定為40和0.9,將Europarl作為訓(xùn)練集,將LIGA_dataset、Twituser_21、Twituser_7作為測試集,通過訓(xùn)練集和測試集的不同來模擬出現(xiàn)集外詞的情況,以驗證模型在加入本文方法后魯棒性的提升.
實驗表明,使用了本文方法后,Textcat、LIGA、logLIGA模型分別在三個數(shù)據(jù)集中有了顯著的提升,尤其是在Twituser21的數(shù)據(jù)集上,分別提高了10.24%、13.096%、1.951%,大大提高了模型在不同數(shù)據(jù)集上的魯棒性.當(dāng)訓(xùn)練數(shù)據(jù)不充分時,Textcat、LIGA兩個模型的效果就會大打折扣,而我們的方法是增加語種之間的辨識度,因此在數(shù)據(jù)量不足的情況下,依然可以提升識別效果.
此外在圖10中還可以看出,Twituser_21的數(shù)據(jù)集上的識別率要高于Twituser_7,即在相同訓(xùn)練集的情況下,增加大類別語種數(shù)量,識別率不會降低.因此可以得出結(jié)論,我們的方法不僅提高了不同數(shù)據(jù)集上的識別效果,增強了模型的魯棒性,同時還解決了大類別語種數(shù)量增多時,語種識別率下滑的問題.
我們還發(fā)現(xiàn)一些問題,比如該方法對logLIGA模型的影響并不是很大.因為logLIGA模型是在計算完相似度后再取log,這樣提高40倍權(quán)重取完log,只比加入本文方法前的權(quán)重高1.6倍,并沒有太顯著的差異;也正是因為加入了log平滑函數(shù),使模型對權(quán)重修改的敏感度大大降低,如果繼續(xù)提高權(quán)重,則會有更顯著的效果.

圖10 模型的魯棒性驗證結(jié)果Fig.10 Result of model robustness
4 總結(jié)
數(shù)據(jù)集的改變會讓傳統(tǒng)基于n-gram語種識別模型的準(zhǔn)確率大打折扣,增強模型在不同數(shù)據(jù)集上的魯棒性能讓模型在實際應(yīng)用中更加有效.本文提出了一種通過動態(tài)調(diào)整語種特征詞和共有詞權(quán)重的方式,提升傳統(tǒng)模型識別性能的語種識別方法.實驗證明了該方法的有效性.
1 Cavnar W B,Trenkle J M.N-gram-based text categorization.In:Proceedings of the 3rd Annual Symposium on Document Analysis and Information Retrieval.Las Vegas,USA,1994.161?175
2 Frank Scheelen.Libtextcat.Software[Online],available:http://software.wise-guys.nl/libtextcat/,2003.
3 Hammarstr¨omh.A fi ne-grained model for language identification.In:Proceedings of the 2007 Workshop of Improving Non English Web Searching.Amsterdam,The Netherlands:ACM,2007.14?20
4 Ceylanh,Kim Y.Language identi fi cation of search engine queries.In:Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP.Stroudsburg,PA,USA:Association for Computational Linguistics,2009,2:1066?1074
5 Vatanent,V¨ayrynen J J,Virpioja S.Language identi fi cation of short text segments with n-gram models.In:Proceedings of the 2010 International Conference on Language Resources and Evaluation.Valletta,Malta:LREC,2010.3423?3430
6 Carter S,Weerkamp W,Tsagkias M.Microblog language identi fi cation:overcoming the limitations of short,unedited and idiomatic text.Language Resources and Evaluation,2013,47(1):195?215
7 Tromp E,Pechenizkiy M.Graph-based n-gram language identi fi cation on short texts.In:Proceedings of the 20th Machine Learning Conference of Belgium and the Netherlands.Hague,Netherlands,2011.27?34
8 Vogel J,Tresner-Kirsch D.Robust language identi fi cation in short,noisy texts:improvements to LIGA.In:Proceedings of the 3rd International Workshop on Mining Ubiquitous and Social Environments(MUSE 2012).2012.43?50
9 Lui M,Baldwint.Langid.PY:an off-the-shelf language identi fi cation tool.In:Proceedings of ACL 2012 System Demonstrations.Stroudsburg,PA,USA:Association for Computational Linguistics,2012.25?30
10中谷秀洋.Short Text Language Detection with In fi nity-Gram.奈良先端科學(xué)技術(shù)大學(xué)院大學(xué),2012.
11 Brown R D.Selecting and weighting n-grams to identify 1100 languages.Speech,and Dialogue.Lecture Notes in Computer Science.Berlin,Heidelberg,Germany:Springer,2013.475?483
12 Gonzalez-Dominguez J,Lopez-Moreno I,Moreno P J,Gonzalez-Rodriguez J.Frame-by-frame language identi fi cation in short utterances using deep neural networks.Neural Networks,2015,64:49?58
13 Zazo R,Lozano-Diez A,Gonzalez-Dominguez J,Toledano Dt,Gonzalez-Rodriguez J.Language identi fi cation in short utterances using long short-term memory(LSTM)recurrent neural networks.PLoS One,2016,11(1):Article No.e0146917
14 Tkachenko M,Yamshinin A,Lyubimov N,Kotov M,Nastasenko M.Language identi fi cation using time delay neural network d-vector on short utterances.Speech and Computer.Lecture Notes in Computer Science.Cham,Germany:Springer,2016.443?449
15 Ghahabi O,Bonafonte A,Hernando J,Moreno A.Deep neural networks for i-vector language identi fi cation of short utterances in cars.In:Proceedings of INTERSPEECH 2016.San Francisco,USA:ISCA,2016.367?371
16 Song Y,Cui R L,Hong Xh,Mcloughlin I,Shi J,Dai L R.Improved language identi fi cation using deep bottleneck network.In:Proceedings of the 2015 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP).South Brisbane,QLD,Australia:IEEE,2015.4200?4204
17 Song Y,Hong Xh,Jiang B,Cui R L,McLoughlin I,Dai L R.Deep bottleneck network based i-vector representation for language identi fi cation.In:Proceedings of INTERSPEECH 2015.Dresden,Germany:ISCA,2015.398?402
18 Jin M,Song Y,Mcloughlin I,Dai L R,Ye Z F.LID-senone extraction via deep neural networks for end-to-end language identi fi cation.In:Proceedings of Odyssey 2016.Bilbao,Spain,2016.210?216
19 Shan Yu-Xiang,Deng Yan,Liu Jia.A novel large vocabulary continuous speech recognition algorithm combined with language recognition.Acta Automatica Sinica,2012,38(3):366?374(單煜翔,鄧妍,劉加.一種聯(lián)合語種識別的新型大詞匯量連續(xù)語音識別算法.自動化學(xué)報,2012,38(3):366?374)
20 Yang Xu-Kui,Qu Dan,Zhang Wen-Lin.An orthogonal Laplacian language recognition approach.Acta Automatica Sinica,2014,40(8):1812?1818(楊緒魁,屈丹,張文林.正交拉普拉斯語種識別方法.自動化學(xué)報,2014,40(8):1812?1818)
21 Xu Jia-Ming,Zhang Wei-Qiang,Yang Deng-Zhou,Liu Jia,Xia Shan-Hong.Manifold regularized extreme learning machine for language recognition.Acta Automatica Sinica,2015,41(9):1680?1685(徐嘉明,張衛(wèi)強,楊登舟,劉加,夏善紅.基于流形正則化極限學(xué)習(xí)機的語種識別系統(tǒng).自動化學(xué)報,2015,41(9):1680?1685)
22 Zubiaga A,Vicente I S,Gamallo P,Pichel J R,Alegria I,Aranberri N,Ezeiza A,Fresno V.TweetLID:a benchmark for tweet language identi fi cation.Language Resources and Evaluation,2016,50(4):729?766
23 Kalimeri M,Constantoudis V,Papadimitriou C,Karamanos K,Diakonos F K,Papageorgiouh.Word-length entropies and correlations of natural language written texts.Journal of Quantitative Linguistics,2015,22(2):101?118
24 Baldwint,Lui M.Language identi fi cation:the long and the short of the matter.In:Human Language Technologies:the 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics.Stroudsburg,PA,USA:Association for Computational Linguistics,2010.229?237
25 Lui M,Baldwint.Accurate language identi fi cation of twitter messages.In:Proceedings of the 5th Workshop on Language Analysis for Social Media(LASM).Gothenburg,Sweden:Association for Computational Linguistics,2014.17?25
26 Koehn P.Europarl:a parallel corpus for statistical machine translation.Proceedings of the 3rd Workshop on Statistical Machine Translation,2005.3?4
猜你喜歡
文苑(2020年4期)2020-05-30 12:35:30
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小學(xué)生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
華北電力大學(xué)學(xué)報(社會科學(xué)版)(2016年4期)2016-12-01 03:59:30
Coco薇(2016年2期)2016-03-22 02:42:52
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
少兒科學(xué)周刊·少年版(2015年4期)2015-07-07 21:11:17
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
