基于網(wǎng)絡(luò)爬蟲的京東電商平臺數(shù)據(jù)分析
2018-04-16 00:55:00魏倩男賀正楚陳一鳴
經(jīng)濟(jì)數(shù)學(xué) 2018年1期
關(guān)鍵詞:數(shù)據(jù)分析
魏倩男 賀正楚 陳一鳴
摘 要 以京東平臺的網(wǎng)頁數(shù)據(jù)抓取為例,研究如何提高網(wǎng)絡(luò)爬蟲技術(shù)對網(wǎng)頁數(shù)據(jù)的抓取效率,進(jìn)而對抓取到的數(shù)據(jù)進(jìn)行數(shù)據(jù)挖掘和數(shù)據(jù)分析.該網(wǎng)絡(luò)爬蟲技術(shù)主要建立在分布式系統(tǒng)的基礎(chǔ)上,多臺計(jì)算機(jī)多線程同時運(yùn)行,使數(shù)據(jù)抓取效率顯著提高.分析京東平臺的網(wǎng)頁信息,統(tǒng)一分類,抓取分類下的商品信息,獲取到網(wǎng)頁內(nèi)容后,利用解析器重建網(wǎng)頁DOM樹,通過JQUERY選擇器,針對選擇不同的標(biāo)簽名稱和標(biāo)識名稱獲取商品信息,把獲取到的數(shù)據(jù)進(jìn)行過濾、整合,然后進(jìn)行數(shù)據(jù)挖掘和數(shù)據(jù)分析,對電商行業(yè)走勢進(jìn)行預(yù)測,進(jìn)而指導(dǎo)電商運(yùn)營團(tuán)隊(duì)決策.
關(guān)鍵詞 電商平臺;數(shù)據(jù)分析;分布式系統(tǒng);AJAX;MapReduce;Jumony Core
中圖分類號 F424,F(xiàn)716,F(xiàn)724.6文獻(xiàn)標(biāo)識碼 A
Abstract Taking the data web Jingdong platform as an example, this paper researched how to improve the efficiency of data capture of web crawler technology, and to crawl into data for data mining and data analysis. The crawler technology is mainly built on the basis of distributed system, and multiple computers run simultaneously at the same time, so that the efficiency of data capture is significantly improved. After analyzing Web information, Jingdong platform unified classification, grasping under the category of commodity information, and the access to web content, DOM tree was reconstructed by using parser, and through the JQUERY selector, different commodity information was selected according to the label name and logo name, and the obtained data was filtered, integrated, and then data mining and data analysis were carried out to predict the trend of the e-commerce industry, and then to guide the decision-making of the e-commerce operations team.
Key words electronic business platform;data analysis;distributed system;AJAX;MapReduce;Jumony Core
1 引 言
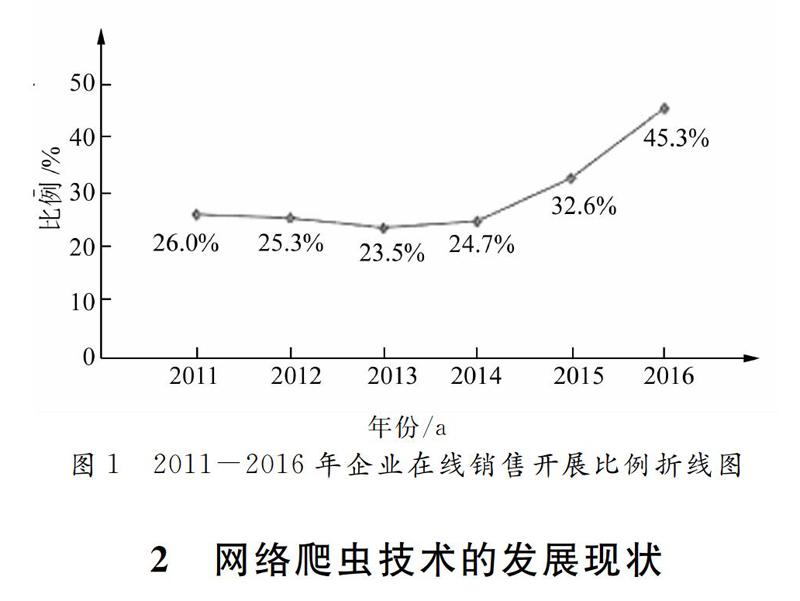
2017年1月,中國互聯(lián)網(wǎng)絡(luò)信息中心(CNNIC)發(fā)布第39次《中國互聯(lián)網(wǎng)絡(luò)發(fā)展?fàn)顩r統(tǒng)計(jì)報告》,根據(jù)報告顯示,截至2016年12月,中國網(wǎng)民規(guī)模相當(dāng)于歐洲人口總量,高達(dá)7.31億,全年新增網(wǎng)民共計(jì)4229萬人.互聯(lián)網(wǎng)普及率達(dá)53.2%,較2015年底提升了2.9個百分點(diǎn).其中在商務(wù)交易應(yīng)用類發(fā)展方面,截至2016年12月,中國有99.0%的企業(yè)使用計(jì)算機(jī)辦公.在電子商務(wù)方面,開展在線采購、在線銷售的比例分別為45.6%和45.3%,大約有38.7%的企業(yè)利用互聯(lián)網(wǎng)開展?fàn)I銷推廣活動.中國的互聯(lián)網(wǎng)行業(yè)整體向價值化、規(guī)范化的方向發(fā)展,同時,移動化聯(lián)網(wǎng)推動了共享化、設(shè)備智能化和場景多元化的消費(fèi)模式[1].
圖1為CNNIC中國互聯(lián)網(wǎng)絡(luò)發(fā)展?fàn)顩r統(tǒng)計(jì)調(diào)查結(jié)果.圖1顯示截至2016年12月全國有45.3%的企業(yè)開展在線銷售業(yè)務(wù).“十二五”期間,中國電子商務(wù)市場發(fā)現(xiàn)迅速,交易額翻了兩番.2016年,“十三五”的開局之年,電子商務(wù)市場規(guī)模的增速依然保持穩(wěn)定,企業(yè)的參與程度越來越深入,開展在線銷售的企業(yè)數(shù)量也大幅增加.隨著企業(yè)對品牌推廣意識的提升、電子商務(wù)的日益普及,以及中國互聯(lián)網(wǎng)的廣告市場逐步規(guī)范化,互聯(lián)網(wǎng)的營銷市場仍然有很大的增長空間.但是近幾年來電商行業(yè)的各大網(wǎng)站為搶占市場經(jīng)常采取的策略是打價格戰(zhàn),紛紛通過促銷、甚至降價等方式來吸引客戶.據(jù)KPCB的調(diào)查報告顯示,2009年到2016年全球移動端新用戶的增長率持續(xù)下滑,可以預(yù)測在2017年這一增長率將繼續(xù)放慢,用戶增長將更加乏力,這就意味著人口增長帶來的流量紅利正在逐漸消退.那么,單純地通過價格戰(zhàn)來吸引新用戶的方式已不容樂觀.嚴(yán)峻的市場競爭形勢迫使企業(yè)思考,在不依靠價格戰(zhàn)這種野蠻增長的方式下,當(dāng)企業(yè)面臨增長困境,該如何應(yīng)對?2017年11月在北京舉辦的“第三屆中國行業(yè)互聯(lián)網(wǎng)大會”為這一問題指出了解決思路,即在互聯(lián)網(wǎng)時代下“新動能,新模式”將助推企業(yè)轉(zhuǎn)型升級,優(yōu)化要素配置,促進(jìn)新經(jīng)濟(jì)轉(zhuǎn)型.因此,對電商平臺來說,數(shù)據(jù)是電商分析問題的基礎(chǔ),面對不斷增長的海量信息,如何高效的獲取數(shù)據(jù)、挖掘信息是電商企業(yè)精細(xì)化運(yùn)營和數(shù)據(jù)驅(qū)動決策中亟待解決的問題.網(wǎng)絡(luò)爬蟲技術(shù)在電商信息來源方面和其他領(lǐng)域都有很廣泛的應(yīng)用.
2 網(wǎng)絡(luò)爬蟲技術(shù)的發(fā)展現(xiàn)狀
隨著Internet規(guī)模的不斷擴(kuò)大的和Internet技術(shù)的迅速發(fā)展,Web信息量呈指數(shù)增長,數(shù)據(jù)呈現(xiàn)出數(shù)據(jù)量大、種類多、實(shí)時性強(qiáng)、價值大等特點(diǎn),大數(shù)據(jù)的應(yīng)用已經(jīng)蔓延到各個領(lǐng)域[2].數(shù)據(jù)挖掘是從海量數(shù)據(jù)中尋找其規(guī)律和聯(lián)系的技術(shù),是統(tǒng)計(jì)學(xué)、數(shù)據(jù)庫技術(shù)和人工智能技術(shù)的綜合.目前,在數(shù)據(jù)挖掘的領(lǐng)域范疇中,相關(guān)研究機(jī)構(gòu)(如:Google、百度等)已經(jīng)給出了較為成熟穩(wěn)定的大型網(wǎng)絡(luò)爬蟲解決方案,由于涉及商業(yè)化利益和機(jī)密,相對成熟的搜索引擎技術(shù)不會被公開化,網(wǎng)絡(luò)中的相關(guān)資源也只是膚淺的描述和概括,而且這些方案大都只能為一般用戶提供一種不可定制的搜索服務(wù),大部分公司并不提供相關(guān)的技術(shù)方案支持.開源在網(wǎng)絡(luò)爬蟲方面,也已經(jīng)有一些相對成熟的網(wǎng)絡(luò)爬蟲項(xiàng)目,但很多并不能被廣泛采用,并且可能會存在一些問題,如:不穩(wěn)定、體驗(yàn)效果差、配置繁瑣等.在開源爬蟲項(xiàng)目中,大部分都是單機(jī)版的,無法應(yīng)用于海量數(shù)據(jù)的采集等其他情況,因此,針對電商平臺研究出一套配置簡單、穩(wěn)定性強(qiáng)、效率高的爬蟲是很必要的.
網(wǎng)絡(luò)爬蟲追求的方向是如何盡可能及時、全面、有效地獲取互聯(lián)網(wǎng)上的數(shù)據(jù)索引,主要包括以下方面的研究:發(fā)展大規(guī)模分布式系統(tǒng)、提高系統(tǒng)的性能[3].一是分布式系統(tǒng)有效地推動了搜索引擎技術(shù)的發(fā)展.搭建一套擴(kuò)展性強(qiáng)、性能穩(wěn)定、成本低廉的分布式集群系統(tǒng),多臺機(jī)器并行運(yùn)算,可以有效地解決多個網(wǎng)間訪問速度過慢對網(wǎng)頁信息獲取的影響,加快數(shù)據(jù)的計(jì)算速度,提高網(wǎng)絡(luò)爬蟲的性能[4];二是網(wǎng)絡(luò)數(shù)據(jù)抓取內(nèi)容越來越多元化.人們對網(wǎng)絡(luò)資源的需求不僅僅是單純的文字,需求正朝著多元化的道路發(fā)展,例如,視頻搜索,圖片搜索以及各類文檔搜索,因此網(wǎng)絡(luò)爬蟲面對這些也應(yīng)該能夠準(zhǔn)確的解析并且準(zhǔn)確的獲取;三是更多的個性化服務(wù).當(dāng)前抓取內(nèi)容需要具備個性化搜索,人們關(guān)心的并不是所有的電商平臺網(wǎng)站和其他品類網(wǎng)站,而只是滿足自己所需要的一些電商網(wǎng)站等站點(diǎn),因此就需要網(wǎng)絡(luò)爬蟲有針對性的去獲取,不同的站點(diǎn)對應(yīng)不同的權(quán)值;四是AJAX數(shù)據(jù)獲取[5].AJAX框架有大量的表現(xiàn)層代碼,由于網(wǎng)絡(luò)和其他的反爬蟲因素在一定程度上降低了網(wǎng)絡(luò)爬蟲的效率.因此,開展支持AJAX框架站網(wǎng)絡(luò)爬蟲的研究,對解決AJAX站點(diǎn)地址(URL)獲取以及檢索隱藏在其中大量數(shù)據(jù)的問題,具有重要的理論意義與實(shí)用價值[6].
事實(shí)上,在網(wǎng)絡(luò)爬蟲領(lǐng)域,學(xué)術(shù)界以及商業(yè)界都已有一些研究,其中包括:網(wǎng)絡(luò)爬行策略、海量數(shù)據(jù)存儲方式、海量數(shù)據(jù)索引方式、網(wǎng)頁評級分類等.隨著網(wǎng)絡(luò)信息資源的快速增長以及網(wǎng)絡(luò)信息資源動態(tài)的變化,傳統(tǒng)的爬蟲技無法滿足人們對個性化服務(wù)的需求,以何種方式訪問網(wǎng)絡(luò),提高爬蟲效率,已成為近幾年來網(wǎng)絡(luò)爬蟲研究的主要問題之一.但大多數(shù)研究僅著眼于某一個方面的改進(jìn),因此對于一個完整的爬蟲系統(tǒng)來說,或多或少的會存在著某些不足.本文在已有研究成果基礎(chǔ)上,設(shè)計(jì)一個高效可行的網(wǎng)絡(luò)爬蟲方案,進(jìn)而對爬取到的數(shù)據(jù)進(jìn)行數(shù)據(jù)分析和數(shù)據(jù)挖掘,為企業(yè)決策提供指導(dǎo).
本文主要基于MapReduce分布式系統(tǒng)實(shí)現(xiàn)了網(wǎng)絡(luò)爬蟲在電商中的應(yīng)用,提高了網(wǎng)爬蟲性能,加快頁面信息獲取速度[7].針對海量信息無法存儲的問題,采用非結(jié)構(gòu)化分布式存儲技術(shù),它是一種全新的非關(guān)系型的分布式存儲技術(shù),采用新的數(shù)據(jù)模型,具有海量數(shù)據(jù)存儲、高性能、高可用性、強(qiáng)伸縮性等特點(diǎn),可以有效地解決數(shù)據(jù)存儲的問題.針對頁面通過AJAX異步請求獲取后臺數(shù)據(jù),呈現(xiàn)到網(wǎng)頁信息無法獲取的問題,采用Selenium技術(shù),它可以通過調(diào)用瀏覽器的方式,加載頁面自身內(nèi)容和通過AJAX異步請求展現(xiàn)的內(nèi)容,完全加載后,Selenium可以獲取到所有頁面內(nèi)容,Selenium還可以模擬鼠標(biāo)單擊、雙擊、右擊等一些操作,解決隱藏數(shù)據(jù)無法獲取的問題[8].
3 相關(guān)理論基礎(chǔ)
3.1 MapReduce
MapReduce是Google在2004年提出的一個用于處理大規(guī)模數(shù)據(jù)集合的分布式計(jì)算架構(gòu).該構(gòu)架的提出是由編程函數(shù)中常用的Map,Reduce函數(shù)啟發(fā)結(jié)合而來,通過這個架構(gòu),可以幫助對分布式計(jì)算不太了解的程序員完成分布式計(jì)算程序的編程,實(shí)現(xiàn)對問題的分解與合并[9].
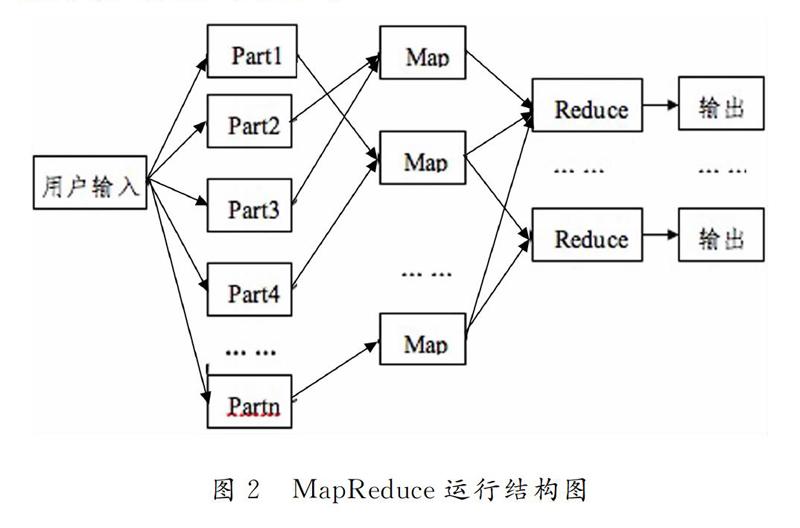
分布式計(jì)算是將整個任務(wù)先分割成很多小的子任務(wù)到子節(jié)點(diǎn)處理,再將子節(jié)點(diǎn)處理得到的結(jié)果進(jìn)行合并整理,獲取最終結(jié)果[10].在MapReduce的執(zhí)行任務(wù)的過程中主要分為Map和Reduce兩個步驟:當(dāng)用戶輸入一條指令后,Map程序首先把任務(wù)分割成不相關(guān)的小任務(wù)塊,這些小的任務(wù)塊會被分配到不同的計(jì)算機(jī)進(jìn)去處理,得到的結(jié)果通過Reduce程序整合.MapReduce的一般運(yùn)行結(jié)構(gòu)如圖2所示.
“Map”過程:Master節(jié)點(diǎn)接收到輸入的數(shù)據(jù)后會將數(shù)據(jù)分割成許多小的數(shù)據(jù)塊并把它們分給不同的Worker節(jié)點(diǎn).Worker節(jié)點(diǎn)可能會再次重復(fù)上面內(nèi)容;或者Worker節(jié)點(diǎn)調(diào)用用戶自定義的函數(shù),將處理得到的鍵值數(shù)據(jù)對寫入到本地磁盤中.
“Reduce”過程:在Worker節(jié)點(diǎn)上執(zhí)行Reduce函數(shù),整理Map函數(shù)處理好的全部數(shù)據(jù),把鍵名相同的數(shù)據(jù)通過用戶提交的指定的方法合成不同的數(shù)據(jù)集合,保存到磁盤中.
3.2 AJAX
Ajax并不能說是一種新的研發(fā)技術(shù),而是提取的Java、XML與JavaScript等技術(shù)的特點(diǎn),創(chuàng)建了交互式網(wǎng)頁應(yīng)用的Web開發(fā)技術(shù),其中包括這些技術(shù):使用HTML和CSS定義呈現(xiàn)給用戶的頁面內(nèi)容和媒體信息;使用DOM實(shí)時動態(tài)修改頁面顯示內(nèi)容和加載效果;使用XML和XSLT進(jìn)行數(shù)據(jù)交換獲取和結(jié)構(gòu)化處理;使用XMLHttpRequest方法進(jìn)行異步數(shù)據(jù)的查詢和獲取;使用JavaScript綁定和處理以上部分.
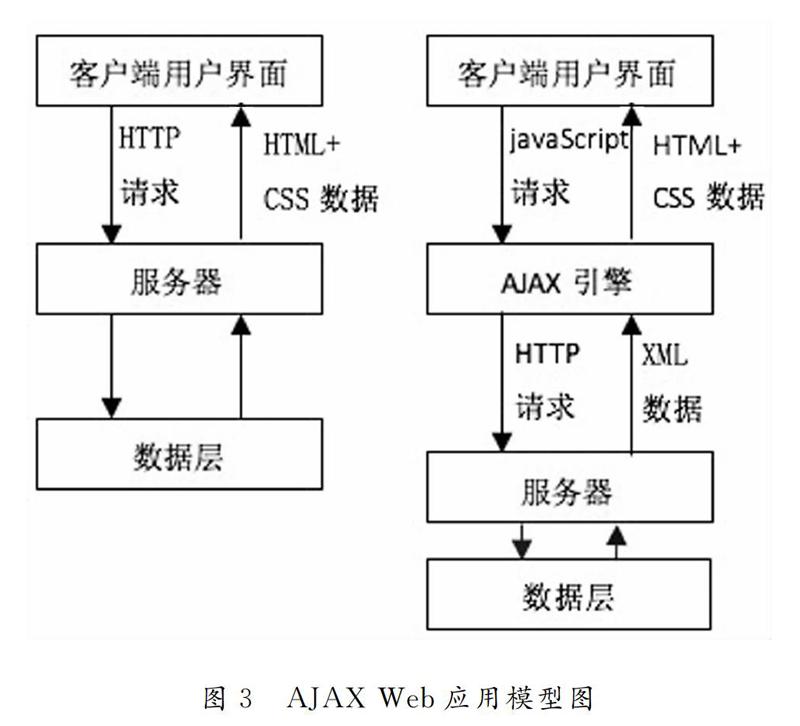
AJAX Web應(yīng)用模型如圖3所示.
客戶端與Web服務(wù)器之間增加了Ajax引擎,客戶端接口與Ajax引擎交互,而Ajax引擎再通過HTTP傳輸協(xié)議與Web服務(wù)器端交互.Ajax Web應(yīng)用采用了異步交互模式,比傳統(tǒng)的Web應(yīng)用體驗(yàn)效果更佳,更加受用戶的喜愛,有5個方面的優(yōu)點(diǎn)[11]:①Ajax能在不刷新整個頁面的前提下更新頁面信息和頁面數(shù)據(jù),網(wǎng)頁加載的速度更加快速,用戶等待頁面加載的時間更短.在等待服務(wù)器響應(yīng)的過程中,用戶可以在已加載頁面進(jìn)行任何操作,縮短可感知時間.②通過異步調(diào)用模式,可以帶來更好的用戶體驗(yàn),用戶可以更加直觀感覺到豐富、動態(tài)的頁面內(nèi)容.③Ajax采用的原則是“按需按量取數(shù)據(jù)”,可以最大程度的減少冗余請求和大量數(shù)據(jù)的一次性加載,優(yōu)化服務(wù)器和客戶端的傳輸,從而提高網(wǎng)絡(luò)帶寬的利用率,減輕服務(wù)器負(fù)擔(dān).④Ajax不但可以調(diào)用本地資源,還可以加載外部數(shù)據(jù),非常具有靈活性.⑤Ajax技術(shù)應(yīng)用非常簡單,沒有任何插件和程序的安裝,操作簡單,能被開發(fā)者廣泛支持.
3.3 Jumony Core
Jumony Core是一個非常真實(shí)的HTML引擎.目前的HTML解析器加上簡單的正則表達(dá)式已經(jīng)可以滿足用戶操縱HTML文檔的需求,但對于Jumony Core,它更加強(qiáng)大.Jumony Core解析結(jié)果和瀏覽器的解析結(jié)果相似度非常高,無論是無結(jié)束標(biāo)簽的元素,可選結(jié)束標(biāo)簽的元素,或是標(biāo)記屬性,或是CSS選擇器和樣式,一切合法的,不合法的HTML文檔,瀏覽器解析成什么樣式和內(nèi)容,Jumony Core出來的效果幾乎和瀏覽器一樣.Jumony Core包含的封裝方法及作用如表1所示.
4 本研究對爬蟲技術(shù)的設(shè)計(jì)
4.1 設(shè)計(jì)思想
目前,爬蟲在抓取數(shù)據(jù)上,一般采取兩種策略:廣度優(yōu)先策略與深度優(yōu)先策略[12].廣度優(yōu)先是指爬蟲沿著樹進(jìn)行橫向遍歷,直到抓取完起始網(wǎng)頁中連接的所有網(wǎng)頁為止,然后再選擇其中的一個網(wǎng)頁鏈接,循環(huán)這個過程.此方法可以讓爬蟲并行進(jìn)行,提高了抓取速度.深度優(yōu)先是指爬蟲沿著樹進(jìn)行縱向遍歷.深度優(yōu)先策略是一個遞歸的過程,因此在程序執(zhí)行的時候會大量消耗計(jì)算機(jī)的內(nèi)存,很容易使爬蟲陷入問題,甚至是電腦死機(jī).另外,遞歸與多線程是無法兼容的,因?yàn)槎嗑€程可以一次運(yùn)行多個任務(wù),但每個線程都要有自己的堆棧.而在遞歸時,當(dāng)一個方法調(diào)用它自身時,它們需要使用同一個堆棧.因此,本爬蟲程序采用廣度優(yōu)先策略.具體實(shí)現(xiàn)方式為:首先,統(tǒng)一不同電商平臺的分類信息,通過比較判斷找出不同電商平臺的公共分類信息,分類信息還分為一級分類和二級分類,一級分類下面包含多個二級分類;其次,整合所有二級分類,獲取所有二級分類所對應(yīng)的商品列表URL,初始化URL,直到對應(yīng)的URL沒有商品為止;最后,把獲取到的產(chǎn)品信息存儲到數(shù)據(jù)庫,存儲到數(shù)據(jù)庫中的數(shù)據(jù)經(jīng)過清洗過濾得到標(biāo)準(zhǔn)化的數(shù)據(jù),然后進(jìn)行數(shù)據(jù)統(tǒng)計(jì)分析,從而把握電商行業(yè)的銷售趨勢.圖4為本程序?qū)ι唐窋?shù)據(jù)獲取及保存示意圖.
4.2 操作流程與實(shí)現(xiàn)
圖5清晰地展示了程序的主要流程.收集網(wǎng)絡(luò)中不同的電商平臺進(jìn)行分析對比,獲取不同電商網(wǎng)站針對的不同分類的側(cè)重點(diǎn),對于相似的分類,可以關(guān)聯(lián)分類后統(tǒng)一化名稱.對于每個分類下面的商品,需要不斷的初始化對應(yīng)URL,從而獲得不同分頁下面的商品信息,獲取商品信息的時候,對信息不完整的商品進(jìn)行舍棄.在數(shù)據(jù)整理的時候,過濾不符合規(guī)則、異常的數(shù)據(jù).
4.3 統(tǒng)一分類
當(dāng)前網(wǎng)絡(luò)電商平臺眾多,其中國內(nèi)比較知名的主要有淘寶、天貓、京東等,但這些電商平臺的一級分類和二級分類,甚至更深層的分類錯綜復(fù)雜[13].把這些電商平臺的所有分類整合,挑選出其中具有代表性的一級分類,在一級分類的決斷中,盡可能的要包含人們生活的各方面.對于二級分類的確定,通過與一級分類的關(guān)聯(lián)度和常識去決定.最終,可以得到基于不同電商平臺下的一套相對統(tǒng)一的標(biāo)準(zhǔn)化分類.
4.4 初始化URL
不同電商平臺的二級分類下面可能會有更細(xì)的小分類,但不是商品列表,要盡可能完整的獲取到所有分類下面的信息就需要把這些更小的分類下面的商品列表對應(yīng)的URL也存儲到數(shù)據(jù)庫,這些小的分類應(yīng)該與其父級分類建立關(guān)聯(lián)外鍵.每個URL對應(yīng)的商品列表只有一頁,一般要想獲取更多的頁面列表就需要改變URL中對應(yīng)頁碼的數(shù)值.尚待訪問URL隊(duì)列可以被構(gòu)造為一個先進(jìn)先出(FIFO)隊(duì)列,信息搜索的下一個將要爬行的頁面來自隊(duì)列頭,新的URL被加入到隊(duì)列尾.每一步都是從隊(duì)列頭中選出下一個URL供爬蟲抓取,直到爬完此隊(duì)列中所有URL為止.
4.5 頁面信息提取
在提取頁面信息時,首先必須先判斷頁面的編碼方式,目前的字符集種類非常多,其中主要以“UTF-8”,“GBK”,“GB2312”為主,具體可以在網(wǎng)頁頭部可以看到,例如:.在讀取頁面內(nèi)容時,先要判斷獲取內(nèi)容的類型,如果是多媒體數(shù)據(jù),則可以下載存儲到網(wǎng)頁數(shù)據(jù)庫中,如果是無結(jié)構(gòu)或半結(jié)構(gòu)化的網(wǎng)頁文本,則需要繼續(xù)分析.在獲取URL頁面內(nèi)容時,如果出現(xiàn)超時、頁面丟失、獲取錯誤等現(xiàn)象時,就認(rèn)為此網(wǎng)頁失效,對應(yīng)的URL就被存儲到相應(yīng)的錯誤列表中,如果能正常獲取,則需要解析網(wǎng)頁內(nèi)容.
4.6 解析頁面內(nèi)容
網(wǎng)頁解析主要是內(nèi)容分析和鏈接提取.獲取頁面內(nèi)容后,根據(jù)頁面內(nèi)容去解析提取所需要的信息,并通過標(biāo)簽,CSS名稱或者標(biāo)簽ID獲取目的標(biāo)簽路徑.一般情況下,元素會包含很多屬性,其中具有唯一性的屬性就是元素的ID,這樣能更快更精確的找到需要的內(nèi)容,其次就是元素的CSS名稱,CSS名稱可以存在有很多,可以通過下標(biāo)或者結(jié)合元素其他屬性來準(zhǔn)確獲取,最后就是通過元素的標(biāo)簽獲取,一個頁面內(nèi)容會包含很多這樣的標(biāo)簽,想確定唯一想要的就要逐步的查找該元素的父級,通過不同的父級元素來獲取唯一的子級元素.獲取到的元素內(nèi)容文檔可以提取到如下信息:
1)文檔標(biāo)題:通過文件頭標(biāo)簽
2)商品鏈接:鏈接一般都是元素里面的屬性“href”的值,通過鏈接可以得到商品的詳情頁面,獲取更多的商品信息.
3)商品標(biāo)題:商品標(biāo)題一般可以在兩個地方獲取,第一,商品列表中有標(biāo)題的信息,第二,在商品詳情頁面中可以獲取商品的標(biāo)題信息.
4)圖片:電商平臺中商品幾乎都是存在圖片的展示,圖片的信息可以通過命令符或
5)多窗口頁面:通過命令符
各種電商平臺信息采集最直接得到的就是以上4個方面獲取標(biāo)記,并作相應(yīng)的處理.其中文檔標(biāo)題,商品標(biāo)題這些可以直接從當(dāng)前網(wǎng)頁中獲取,其他通過URL相關(guān)的信息則需要記錄URL并標(biāo)記,從而進(jìn)行更深一步的采集.
電商平臺采集主要是獲取關(guān)于每個商品的詳細(xì)信息,其中包括商品標(biāo)題,商品ID,商品的價格,商品的發(fā)售地,商品的月銷量,商品的評論數(shù)甚至商品的評論,還有當(dāng)前商品的店鋪名稱,店鋪ID,店鋪鏈接,店鋪信譽(yù)(評分)都要獲取到,這些信息有的并不能在網(wǎng)頁內(nèi)容中直接獲取,例如,在京東商品詳情頁里面,店鋪的地址,評分等一些不能直接在網(wǎng)頁內(nèi)容中找到,有的要更加深一步的找到相關(guān)的URL,通過再次解析網(wǎng)頁內(nèi)容的方式獲取.還有的就更加復(fù)雜,這些信息在新的頁面也不能夠找到,這時候就要查找當(dāng)前頁面所有的JS文件,看是否能夠在JS文件中獲取所需要的信息,然后找到相關(guān)此JS文件的路徑進(jìn)行分析,看和其他商品的此路徑有什么不同,找出規(guī)律,拼接成相應(yīng)的URL地址來獲取內(nèi)容.
4.7 程序?qū)崿F(xiàn)
電商平臺數(shù)據(jù)采集建立在分布式系統(tǒng)上,計(jì)算機(jī)集合通過通訊網(wǎng)絡(luò)相互連接,實(shí)現(xiàn)資源共享和協(xié)同工作,而呈現(xiàn)給用戶的是單個完整的計(jì)算機(jī)系統(tǒng),分布式系統(tǒng)與面向?qū)ο蠹夹g(shù)相結(jié)合過后,極大的擴(kuò)展了分布式軟件的應(yīng)用領(lǐng)域,提高了軟件的性能和生產(chǎn)效率.程序使用的開發(fā)程序主要有Visual Studio和SQL SERVER.電商平臺采集數(shù)據(jù)量非常龐大,需要定義多線程或線程池來加快程序的運(yùn)行速度.這里主要以京東為例.首先在程序中定義一個線程,線程執(zhí)行需要一個無返回(void)方法,在這個線程中定義所要執(zhí)行的方法,名稱定義盡量規(guī)范,方法里面是關(guān)于電商平臺采集的主要編程代碼.
1)獲取分類URL:獲取SQL SERVER中存儲的二級分類對應(yīng)的所有URL,聲明一個表格(DataTable),把所獲取到的URL存放到表格當(dāng)中.為避免重復(fù)的用到SQL SEVER增刪改查的一些方法,在程序中新建一個類,這個類中定義了一些基本的SQL SEVER增刪改查的方法,對應(yīng)的代碼填充完畢后,每次需要用到這些方法得時候,可以直接通過類名和相應(yīng)的方法調(diào)用,如表2所示.
2)循環(huán)商品列表:循環(huán)表格里面的URL,獲取并解析里面的內(nèi)容,找到本頁面所有的商品集合,通過URL的規(guī)律,找到下一頁(page=1,2….),直到獲取此分類中的所有商品.
3)獲取商品信息:獲取商品集合后,通過選擇器得到相應(yīng)商品詳情頁的URL,在商品詳情頁里面,把剩下所需要的信息提取出來,提取信息的各種方法如表3所示.
4)存儲到數(shù)據(jù)庫:得到所需要的信息,通過定義的SQL方法把得到的數(shù)據(jù)存入數(shù)據(jù)庫.
在商品信息的獲取過程中,會出現(xiàn)很多不規(guī)范的商品信息,在程序運(yùn)行過程中,無法解析網(wǎng)頁內(nèi)容時,程序就會停止并拋出異常信息.此時就需要手動去處理這些異常,而人工處理的效率非常低,因此添加異常處理是必不可少的,一般情況下,都會舍去這些不規(guī)范的商品.當(dāng)一個商品信息獲取完畢時,開始執(zhí)行保存到數(shù)據(jù)庫的操作,在保存數(shù)據(jù)庫之前,需先判斷數(shù)據(jù)庫中是否已經(jīng)包含此商品,在數(shù)以萬計(jì)的商品中,免不了存在非常多的重復(fù)商品.對于帶有AJAX和JavaScript的動態(tài)網(wǎng)頁,通過模擬鼠標(biāo)事件來獲取相應(yīng)信息.
5 網(wǎng)絡(luò)爬蟲技術(shù)的應(yīng)用
事實(shí)上,越來越多的電商運(yùn)營團(tuán)隊(duì)已意識到精細(xì)化運(yùn)營和數(shù)據(jù)驅(qū)動思維已經(jīng)成為電商自身增長日益重要的因素[14-18],所以一個能高效率的網(wǎng)絡(luò)爬蟲對一個電商平臺進(jìn)行數(shù)據(jù)挖掘有效信息而言是非常重要的.因此,本文主要建立在分布式系統(tǒng)的基礎(chǔ)上,多臺計(jì)算機(jī)多線程同時運(yùn)行,對京東平臺的商品信息進(jìn)行抓取.通過對獲取信息的整理、分析,對京東電商的發(fā)展形勢進(jìn)行把握.基于以上介紹對京東電商平臺信息獲取的運(yùn)行界面如圖6所示.
圖6界面簡潔,信息框顯示程序正在獲取的商品信息.當(dāng)點(diǎn)擊開始時,所有線程開始工作,每個線程都有唯一的標(biāo)識名稱,不同線程分配不同的分類任務(wù),獲取的內(nèi)容信息也不一樣,圖6信息框顯示程序運(yùn)行時商品信息一些展示,其中包括商品標(biāo)題,商品所屬分類,線程標(biāo)識以及商品的型號,當(dāng)某個商品信息不規(guī)則或者信息獲取不符合要求時,程序就會自動提示異常,丟棄此商品.當(dāng)點(diǎn)擊暫停時,所有的線程都會停止工作,多線程提高了商品信息獲取的效率.
通過本程序獲取到了京東電商平臺的各類信息,其中比較重要的有月銷售量、價格、產(chǎn)品的一些重要屬性.通過獲取每個月所有產(chǎn)品的總銷量,總銷售額,通過統(tǒng)計(jì)分析計(jì)算,預(yù)測下個月電商行業(yè)景氣度指數(shù),結(jié)合前端HTML,CSS和JavaScript技術(shù),把結(jié)果進(jìn)行圖形化處理,更加直觀清楚的看到電商景氣度的變化趨勢,如圖7所示.
根據(jù)圖7電商景氣度指數(shù)折線圖顯示,京東電商景氣度大體上呈上升趨勢,雖然在上半年有過幾次波折,但是總體來看是在曲折中上升的,尤其后半年電商景氣度走勢大致已經(jīng)趨于穩(wěn)定,該分析結(jié)果可以在運(yùn)營團(tuán)隊(duì)進(jìn)行決策時作為參考資料.
進(jìn)一步地,分別篩選出一級類目和二級類目數(shù)據(jù),可以對不同分類產(chǎn)品進(jìn)行分析,獲取更詳細(xì)的信息,如圖8所示.
根據(jù)圖8電商類目銷售趨勢顯示,實(shí)線部分展示了護(hù)膚彩妝行業(yè)近一年的銷售量和銷售額的趨勢變化情況.虛線部分展示了對護(hù)膚彩妝行業(yè)未來一個月的銷售量和銷售額進(jìn)行預(yù)測的結(jié)果,結(jié)果僅供參考.同樣的,運(yùn)用網(wǎng)絡(luò)爬蟲技術(shù)可以獲取其他行業(yè)類別的不同信息,然后對獲取到的信息進(jìn)行清洗、整合等標(biāo)準(zhǔn)化處理后,建立不同的數(shù)據(jù)挖掘模型,獲取有效信息指導(dǎo)企業(yè)決策.
6 結(jié)束語
隨著電商平臺信息資源的快速增長以及商品信息資源動態(tài)的變化,傳統(tǒng)的爬蟲技術(shù)無法滿足對海量信息及時獲取的需求,以何種方式訪問網(wǎng)絡(luò),提高爬蟲效率,已經(jīng)成為近年來數(shù)據(jù)挖掘研究領(lǐng)域的主要方向之一.因此,本文采用多線程的網(wǎng)絡(luò)爬蟲技術(shù)對京東平臺資源信息進(jìn)行采集和提取,把整個京東平臺的產(chǎn)品信息集成為一個數(shù)據(jù)倉庫,進(jìn)行數(shù)據(jù)挖掘和數(shù)據(jù)分析,獲取有用的信息以提供完善的實(shí)時監(jiān)控和精細(xì)化運(yùn)營策略.基于MapReduce技術(shù)并行加載頁面,多個頁面內(nèi)容同時采集,針對調(diào)用JavaScript所展現(xiàn)出的內(nèi)容,通過Selenium技術(shù)模擬瀏覽器打開相應(yīng)網(wǎng)址,等待JavaScript執(zhí)行完畢后再獲取頁面內(nèi)容,對于帶有分頁的頁面,Selenium可以模擬鼠標(biāo)單擊指定元素達(dá)到翻頁的效果,頁面加載完畢后再次獲取內(nèi)容,直到獲取最后一頁內(nèi)容為止.
在電商行業(yè)飛速發(fā)展的時代,搜索引擎不斷更新,電商平臺不斷完善,電商平臺數(shù)據(jù)的獲取面臨挑戰(zhàn).電商平臺商品的重要數(shù)據(jù)的不公開,對網(wǎng)絡(luò)爬蟲的訪問限制成了獲取數(shù)據(jù)的主要難題.在以后的研究中,會嘗試通過代理IP、控制訪問速度、尋找真正的JavaScript地址等方式解決上述問題.(本論文特別感謝課題組成員楚少波、楊艷艷等同志的協(xié)助與支持)
參考文獻(xiàn)
[1]中國互聯(lián)網(wǎng)絡(luò)信息中心.中國互聯(lián)網(wǎng)發(fā)展?fàn)顩r統(tǒng)計(jì)報告[R].中國互聯(lián)網(wǎng)絡(luò)信息中心,2017.
[2]李志義.網(wǎng)絡(luò)爬蟲的優(yōu)化策略探略[J].現(xiàn)代情報,2011,31(10):31-35.
[3]李代祎,謝麗艷,錢慎一,吳懷廣.基于Scrapy的分布式爬蟲系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)[J].湖北民族學(xué)院學(xué)報(自然科學(xué)版),2017,35(3):318-322.
[4]ZHONG S J,DENG Z J. A Web crawler system design based on distributed technology[J].Academy Journal,2011,6(12):1682-1689.
[5]楊俊峰,黎建輝,楊風(fēng)雷.深層網(wǎng)站Ajax頁面數(shù)據(jù)采集研究綜述[J].計(jì)算機(jī)應(yīng)用研究,2013,30(6):1607-1616.
[6]張升平.Ajax在優(yōu)化Web系統(tǒng)中的應(yīng)用[J].通信技術(shù),2009,42(2):286-288.
[7]孔濤,曹丙章,邱荷花.基于MapReduce的視頻爬蟲系統(tǒng)研究[J].華中科技大學(xué)學(xué)報(自然科學(xué)版),2015,43(5):130-132.
[8]岳雨儉.基于Hadoop的分布式網(wǎng)絡(luò)爬蟲技術(shù)的設(shè)計(jì)與實(shí)現(xiàn)[J].網(wǎng)絡(luò)通訊及安全,2015,11(8):36-38.
[9]趙輝,楊樹強(qiáng),陳志坤.基于MapReduce模型的范圍查詢分析優(yōu)化技術(shù)研究[J].計(jì)算機(jī)研究與發(fā)展,2014,51(3):606-617.
[10]吳黎兵,柯亞林,何炎.分布式網(wǎng)絡(luò)爬蟲的設(shè)計(jì)與實(shí)現(xiàn)[J].計(jì)算機(jī)應(yīng)用與軟件,2011,28(11):177-213.
[11]胡晟.基于網(wǎng)絡(luò)爬蟲的Web挖掘應(yīng)用[J].軟件,2012,33(7):145-147.
[12]岳雨儉.基于Hadoop的分布式網(wǎng)絡(luò)爬蟲技術(shù)的設(shè)計(jì)與實(shí)現(xiàn)[J].網(wǎng)絡(luò)通訊及安全,2015,11(8):36-38.
[13]李也 賀正楚 , 潘紅玉.基于眾籌商業(yè)模式的中國動漫產(chǎn)業(yè)培育研究[J].東莞理工學(xué)院學(xué)報,2015,22(2):69-74.
[14]賀正楚,黃穎琪,吳艷,等.跨境電商發(fā)展的制約因素、優(yōu)勢及措施--兼以湖南為例而論[J].長沙理工大學(xué)學(xué)報(社會科學(xué)版),2016,31(5):115-121.
[15]吳艷.戰(zhàn)略性新興產(chǎn)業(yè)的評價與選擇[J].科學(xué)學(xué)研究,2011,29(5):678-683,721.
[16]賀正楚,張訓(xùn),周震虹.戰(zhàn)略性新興產(chǎn)業(yè)的選擇與評價及實(shí)證分析[J].科學(xué)學(xué)與科學(xué)技術(shù)管理,2010,31(12):62-67.
[17]賀正楚,潘紅玉.中國制造業(yè)跨境電商發(fā)展面臨的問題及對策[J].求索,2017(6):129-135.
[18]賀正楚, 黃穎琪, 吳艷.制造業(yè)電子商務(wù)發(fā)展面臨的問題及其對策[J].地方財政研究,2016(6):9-18.
猜你喜歡
職工法律天地·下半月(2016年10期)2016-11-30 11:52:57
商情(2016年40期)2016-11-28 11:28:07
商(2016年32期)2016-11-24 17:39:41
科技資訊(2016年18期)2016-11-15 18:05:53
考試周刊(2016年84期)2016-11-11 23:57:34
科技視界(2016年18期)2016-11-03 22:51:40
體育時空(2016年8期)2016-10-25 18:02:39
現(xiàn)代經(jīng)濟(jì)信息(2016年19期)2016-10-20 17:46:29
中國科技博覽(2016年18期)2016-10-19 10:30:11
中國市場(2016年36期)2016-10-19 04:31:23
