中文笑話語料庫的構建與應用
2018-08-17 08:38:54徐琳宏樊小超刁宇峰林鴻飛
中文信息學報 2018年7期
任 璐,楊 亮,徐琳宏,樊小超,刁宇峰,林鴻飛
(1. 大連理工大學 信息檢索研究室,遼寧 大連116023;2. 大連外國語大學 軟件學院,遼寧 大連 116044)
1 概述
1.1 笑話的概念以及分類
笑話是我們日常生活中不可或缺的重要組成部分。古人云,“古今世界一大笑府”“不笑不話不成世界”[1]。從古至今,笑話無處不在,是最通俗易懂貼近人們日常生活的文學形式之一。笑話可以使人身心愉悅,也可以拉近人與人之間的距離。作為生活中必不可少的調味劑,笑話可以減輕我們的壓力,消除我們的緊張,有助于我們的工作、學習以及生活。
“笑話”,在現代漢語詞典里的解釋是“能引人發笑的談話或故事”。笑話是一種文體名,通常篇幅短小,情節簡單而巧妙,往往能夠出人意料,給人帶來歡樂,取得笑的藝術效果。笑話作為第二批國家級非物質文化遺產,通常通過口頭傳播,這種傳播方式造成了笑話的多樣性。中國笑話不同于西方的幽默,但中國笑話自古就包含幽默成分,本文所要研究的笑話是狹義的幽默。
笑話作為通俗易懂的文學形式,不少學者對其進行分類。現在國內則傾向于按不同標準進行分類,如譚達人從幽默技法把幽默分為四個大類共51個小類;任紹偉從構成原理把笑話分為74類,是迄今最為詳細、也最為明晰的一種分類方法。更多幽默笑話集和網絡笑話則基本沿用了中國傳統上按主題或內容分類的方式,如海笑把幽默分為生活、機智、家庭、校園、愛情、軍事、動物、交通、醫療、國際、商業、職業、愚人、諷刺14個大類[2]。綜上所述,目前笑話并沒有明確的分類標準,為了研究的需要,本文按照主題分類,將笑話分為校園笑話、職場笑話、家庭笑話、名人笑話以及古代笑話;根據笑話產生的原因分類,將笑話分為諧音笑話、諧義笑話、類比笑話、委婉笑話、反語笑話、諷刺笑話、夸張笑話以及反轉笑話。
1.2 笑話的相關理論基礎
西方幽默三大理論為優越論、釋放論以及乖訛論,其中,目前影響最廣、最受認可的是乖訛論。乖訛論是從人們的心理認知角度來分析幽默,認為幽默產生的原因是由于某種不和諧產生的。現代學者很多都是在乖訛論的基礎上提出了新的幽默理論。
第一個語言學意義上的幽默理論,即幽默的語義腳本理論(semantic script theory of humor,SSTH),就是Raskin于1985年在乖訛論的基礎上提出的[3]。SSTH對人工智能中的幽默計算起到了指導作用。SSTH提出的最終目標是成為確定和證明文本為幽默的充要條件。語義腳本理論提出將笑話的結構定義分為主體(set-up)與妙語(punch line)兩部分。其中,主體由兩個或兩個以上的解釋(腳本)構成,只有一個解釋被呈現出來,而第二個不明顯解釋的妙語以令人意外的方式觸發產生幽默效果。
基于幽默語義腳本理論,Attardo將笑話表示成五層模式: 表層、語言層、目標+情景層、模板層以及基本層,這五層的順序是依據語言學中句子的形成從意義到聲音的理論依次排序的[2]。本文定義的笑話框架就是基于這五層定義的。所謂表層就是指最表層的信息,比如標點、字詞句等。語言層在語料庫對應的是笑話產生的原因,即對應的修辭手法。目標+情景層在語料庫中以人物以及場景的形式體現。基本層就是笑話包含的語義信息以及邏輯機制,跟外界知識相關聯的,也是最難攻克的難點之一。
1991年,Attardo和Raskin在SSTH的基礎上提出了語言幽默的一般理論(general theory of verbal humor,GTVH)[4]。相較于SSTH,GVTH包含更多的笑話語言學源素。GTVH包含了六個不同級的幽默源素,即語言(language, LA)、敘述策略(narrative strategy,NS)、目標(target,TA)、場景(situation,SI)、邏輯機制(logical mechanism,LM)以及腳本對立(script oppostion,SO)。1994年,由Attardo撰寫的專著《幽默語言學理論》(LinguisticTheoriesofHumor)[5]提出了笑話的同位分離模型(isotopy-disjunction model of jokes,IDM)。IDM模型是對Attardo早期提出理論更為詳細的一種描述,并沒有在本質上有所突破。近年來,幽默本體語義理論(OSTH)也是在乖訛論的基礎上提出、發展并完善的。本文的工作就是在幽默理論的基礎上開展的。
1.3 國內外研究進展
林語堂[6]最早將英文單詞“humor”音譯為“幽默”,他指出幽默具有“戲謔”性。而笑話作為幽默包含的文體之一,并且國內外很多學者也是在標簽為“#joke#”的推文做幽默的相關工作。所以,本文不對幽默與笑話做區分。
Attardo[5]指出幽默識別是自然語言處理中一個非常具有挑戰性的課題。笑話識別之所以能夠歸為較高級的人工智能范疇,是因為它涉及人類的認知以及相關的背景知識才能被理解,感到“有趣、好笑”。擁有不同背景知識的人對于同一個笑話的感覺都會不一樣。例如,
妻子: 每次我唱歌的時候,你為什么總要到陽臺上去?
丈夫: 我是想讓大家都知道,不是我在打你。(《避嫌》)
如果沒有一定的背景知識,可能就無法理解這個笑話的主旨是“丈夫”在利用委婉的手段表達“妻子”唱歌不好聽。計算機在處理這段話的時候,并不能理解文字背后的意義,所以幽默計算必須計算文本隱性的語義信息。
現在大多數的幽默識別為二元分類問題,試圖添加一些語言特征來識別幽默與否。最具代表性的是Mihalcea和Strapparava[7]結合幽默語言學特征定義了三個幽默特征,即頭韻、反義詞以及俚語,基于這些特征訓練了分類器對幽默進行識別。類似地,Zhang和Liu[8]設計了幾個類別的幽默相關的特征,這些特征是從目前具有影響力的幽默相關理論、語言規范和情感維度推斷出的,并添加了約50個特征到迭代決策樹模型(GBRT)中識別幽默。Taylor和Mazlack[9]基于N-gram統計語言識別技術識別雙關語笑話,為雙關語是否發生提供了一個啟發式的焦點。除了語言特征之外,一些其他研究者還利用語音或多維信號等作為特征。例如,Purandare和Litman[10]分析了聲韻律和語言特征,用來在口語對話期間對幽默進行自動識別。目前,很多工作沒有系統地對幽默相關的特征進行擴展或解釋。
目前,幽默識別多使用的是傳統的機器學習,深度學習使用得并不多。基于深度學習的幽默研究工作主要代表是Bertero等人[11]。Bertero和Fung從《生活大爆炸》中獲得了相關劇本,根據視頻的音頻中的笑聲自動對語料進行標注,他的主要工作是笑點識別,使用RNN和CNN來預測劇本中的笑點[11]。實驗結果表明CNN比RNN的效果更好。Fung等人的另一篇文章[12]使用CNN對對話序列進行編碼,然后將其作為LSTM的輸入來預測劇本中的笑點。
目前的幽默識別處于起步階段,現有的數據集也非常少。文獻[7]分別整理了路透社新聞內容、諺語以及英國國家語料庫的文本作為負例構建語料進行幽默識別任務。Zhang和Liu[8]等人選取了Twitter中1 500條非幽默推文作為負例。現有相對標準的幽默數據集是基于Mihalcea和Strapparava[7]等人構建的16 000條幽默文本。另外,Castro等人[13]選取了Twitter上帶有“jokes”的推文,共有16 488條,非幽默的語料包含新聞、反思、奇怪的事等主題,共22 875條。國外也有一些專門發布幽默文本的網站,如http: //www.punoftheday.com,該網站主要收集具有雙關語的幽默文本。
現在國內還沒有標準的幽默數據集或是語料庫,因此整理并構建語料庫迫在眉睫。幽默識別與生成技術還處于起步階段,尤其是中文幽默的識別與生成研究更是少之又少。本文構建中文笑話語料庫的相關工作,將為中文笑話研究打下堅實的基礎。
2 語料庫的構建
2.1 語料庫構建流程
整個標注過程包括語料收集和處理、自動識別部分標注內容、人工確認自動識別結果、人工標注其余元組部分、一致性檢測、迭代標注等幾個過程,如圖1所示。
由圖1可以看出,語料庫的建立過程分為三個階段: 語料收集及準備工作、標注存儲過程和分析及應用。第一階段是語料收集及準備工作,包括收集語料、制定標注體系和開發標注工具三部分。第二階段是標注存儲過程,分為自動識別標題以及提取關鍵字等、兩人組確認、兩人組標注幽默機制和等級及一致性檢測、存儲五個步驟,其中如果一致性檢測不能通過,則由仲裁確認。如果一致性檢測通過,存儲后進入第三階段,語料庫的分析及應用。
2.2 基于歷時與共時的語料收集
語料采集工作需要考慮語料庫的歷時性及共時性,這樣語料庫才能更加客觀、全面、覆蓋面大。所謂覆蓋是指語料和文本在各個不同領域的分布或散布。這些不同領域通常是指由時間軸(反映時代特征)、空間軸(反映地域特征)、學科軸(反映知識特征)、風格軸(反映語體特征)構成的四維模型[14]。
從時間軸上看,本文采集的語料包括十年前出版的書籍中的笑話,這滿足了語料庫歷時性;也包括近兩年的書籍、微博、文學期刊、笑話網站等刊登的笑話,這也符合語料庫的共時性;還包含從人們口口相傳的笑話集錦、微博以及笑話網站近一年更新的笑話作品。從空間軸上,語料中既包含了國內的笑話,也包含了國外的笑話,以及帶有阿凡提等明顯民族特色的笑話。從學科軸上,笑話本身就因為讀笑話人的不同,產生笑點的強度不同,這是由于不同人擁有不同的知識背景,對笑話的理解不同。從風格軸上,來自書籍上的笑話體裁多樣而且相對比較規范,從民間收集的笑話并不規范。
2.3 語料庫的標注體系
語料庫標注是對原始語料進行預處理,使用便于計算機存儲以及讀取的標注格式結合笑話本身特殊需求進行標注。TEI(text encoding initiative)是機讀語篇的國際信息編碼規范。TEI標注模式是由計算語言學學會(Association for Computational Linguistics,ACL)、文學與語言學計算協會(Association for Literary and Linguistic Computing,ALLC)和計算機與人文科學學會(Association for Computers and Humanities,ACH)三家學術團體共同參與制訂的[15]。目前許多大型語料庫都是基于TEI標注準測的,如“英國國家語料庫” (The British National Corpus)等。
結合笑話本身簡潔、便于標注以及TEI便于計算機存儲及讀取等特點,本文采用TEI標注與自定義標注相結合的方式進行標注。中文笑話語料庫體系基本框架如下:
JokeModel=([title], [scene],
person,keywords, level, reason, category)
標注體系包括以下內容: 笑話題目(title)、場景(scene)、人物(person)、關鍵詞(keywords)、幽默程度(level)、幽默方式(reason)以及笑話類別(category)。上述變量中方括號內的title、scene是可選的,其他變量是必選不能為空的。幽默程度表示的是笑話的幽默程度: “1”表示幽默程度最低,“3”表示中等幽默,“5”表示幽默程度最高。變量中的person、keywords取值都是一個集合,即變量中不止包含一個變量。如person=(person1,person2,…,personi,…,relationship),keywords = (keyword1,keyword2,keyword3)。需要說明的是,person中的relationship指的是主要人物間的相互關系;相互關系包含師生關系、 醫患關系、情侶關系、親屬關系、上下級關系、朋友關系以及其他關系。關鍵詞序列使用Textrank算法,選取權重最高的三個詞作為該笑話的關鍵詞序列。本文使用的是由Mihalcea[16]等人提出的基于PageRank的Textrank算法, 用來提取關鍵詞。標注說明如表1所示。
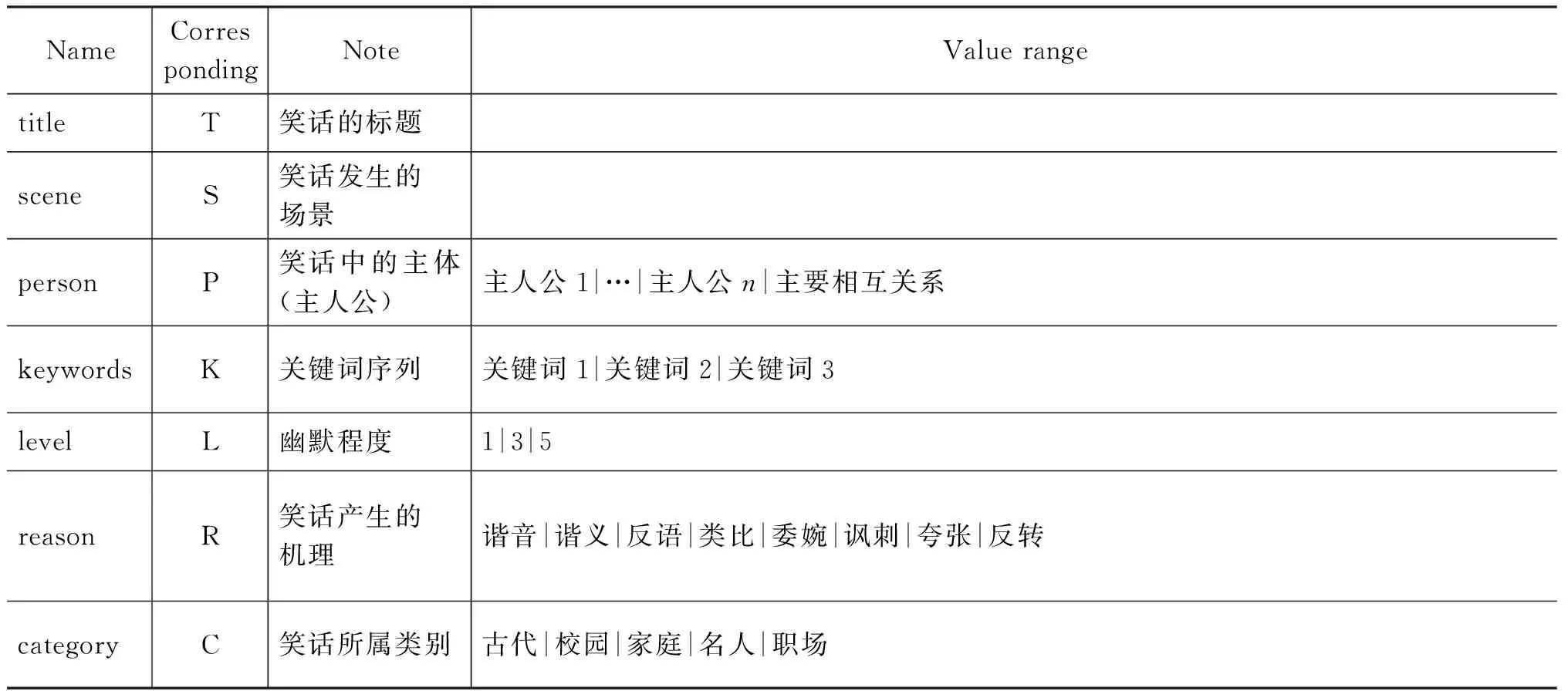
表1 中文笑話語料庫標注說明
2.4 語料庫標注方法
從上面標注體系可以看出,七元組是對笑話的深度標注,顆粒度較細,所需人工成本也較大。所以本文采用半自動的方式完成標注,即其中的標題、主人公、類別、關鍵詞序列等利用命名實體識別等相關技術通過機器自動識別。標注者只需要在機器識別的基礎上修正,能大幅度減少標注者的工作量。產生機制和幽默程度則需要人主觀打分。標注軟件如圖2所示。
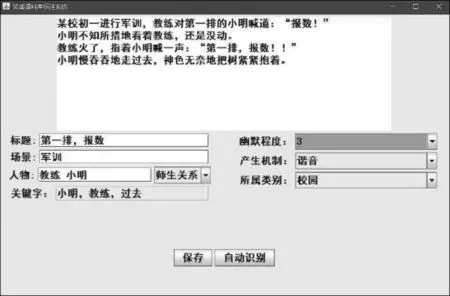
圖2 標注軟件
標注工具能很好地提高標注的效率,使得準確率和速度都有一定幅度的提高。完成后的標注文件經標注者確認后以XML的形式統一存儲。
3 語料庫的一致性評價及分析
3.1 一致性檢測
本文由九名實驗室的博士研究生與碩士研究生共同完成笑話語料的標注工作,分為三個三人組。三人組采取交叉驗證的方式進行標注,其中一人為仲裁。由于每個人的認知不同,對笑話的理解程度不同,所以對笑話的理解存在著不同程度的差異。當三人組中的二人標注相同時,則完成標注;如出現分歧的時候,由仲裁者進行仲裁。當仲裁跟標注的二人觀點都不一致時,如果幽默程度出現分歧,則取平均值,即標注強度為中間值3。如果對產生機制產生分歧,則由全組九人討論,最后進行投票選擇,票數多者為最后標注,盡量最大程度地保證標注的一致性和準確性。統計后結果如圖3所示。
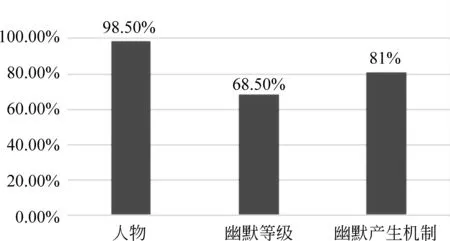
圖3 一致性檢測結果
由圖3可以看出來,對于人物的標注一致性為98.5%,幽默等級為68.5%,幽默產生機制為81%。笑話等級產生的分歧多,這是由于笑話等級是由人的主觀決定的,是由人所掌握的背景知識所決定的。對于笑話產生機制,經過統計分析,標注者對諷刺/委婉以及反轉/諷刺這兩組概念最容易混淆。經過進一步的討論與確認,在仲裁最終確認后,達成組內一致。
3.2 中文笑話語料庫分析
目前收錄的語料包含33 025條笑話,通過統計共158 074句話,包含了3 083 295字數,5 018種字,平均一個笑話包含了4.79句話。與小學生常用字表*http: //www.chinadmd.com/file/6vas6xrvue3xseoz6zscw-erc_1.html(2 500字)做比較,語料中出現100次及以上的有2 004個字,其中有1 859個字在小學生常用字表中,占比92.76%;出現50次及以上的字有2 478個字,其中有2 181個字在小學生常用字表中,占比88.01%。這些數據充分地驗證了笑話是源于生活、面向大眾的特點,說明笑話的受眾很廣,傳播方式很多。
收集的語料中,古代笑話有3 585條,古代笑話是以古代為背景的笑話,并不是傳下來的笑話本身,有些笑話已經被人們用白話文復述;還包括校園笑話、家庭笑話、名人笑話以及職場笑話。具體分布如圖4所示。
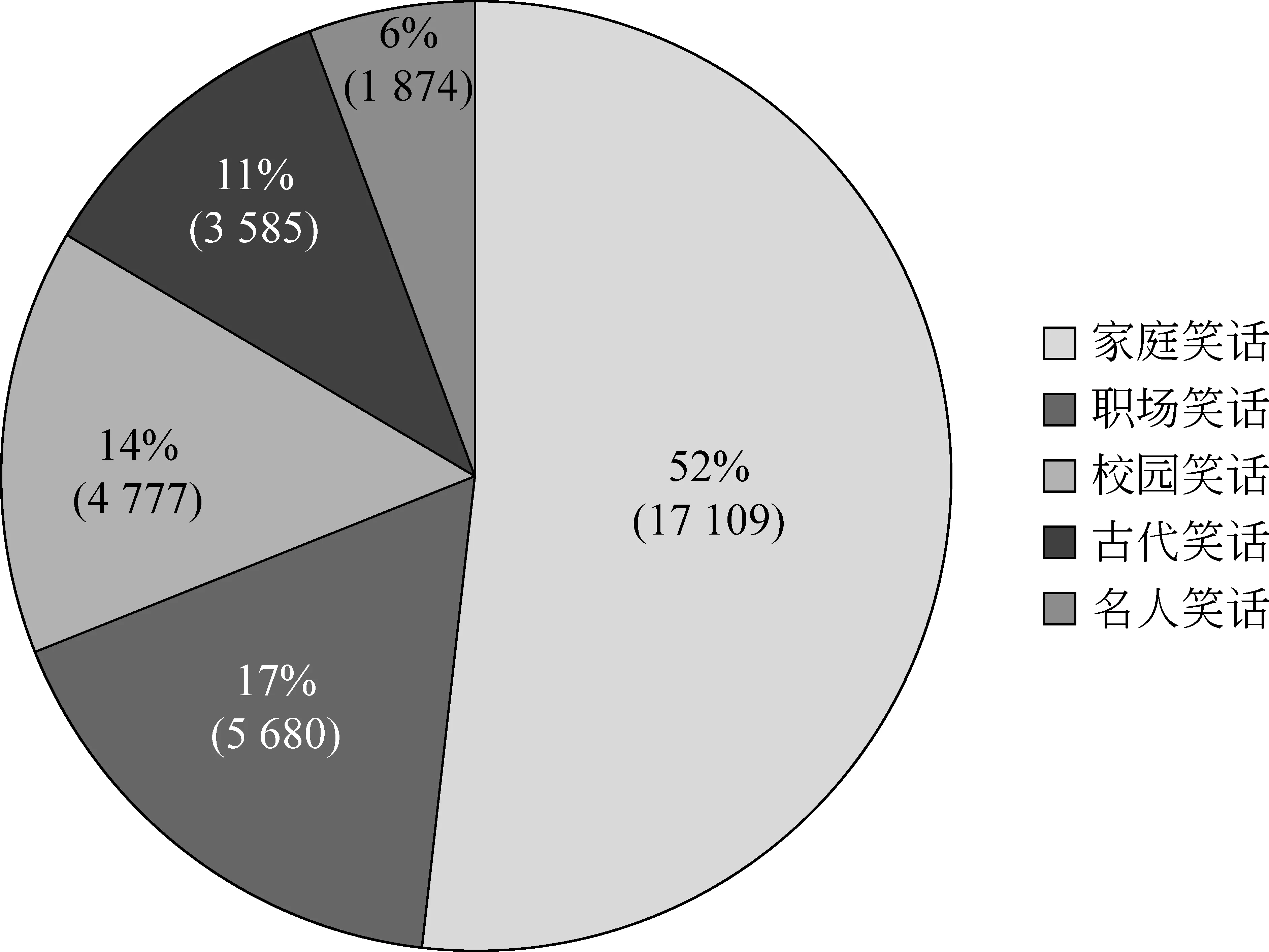
圖4 語料庫中各類笑話數量及其占比
由笑話分類的分布可以看出來,家庭笑話最多,占了語料庫的52%。這是因為,笑話的創作是無時無刻的,而在我們的日常生活中,家庭占了很大的一部分,所以家庭笑話最多也是可以預見的。由于每一類笑話的場景、主題等都不相同,所以表2給出了每類笑話出現頻率較大而且比較關鍵的詞匯。

表2 各類笑話高頻詞
由表2可以看出,每一類別的笑話的高頻詞都不相同。如名人笑話中的高頻詞,阿凡提在我國作為新疆有名的傳說人物,所以帶有新疆特色的名字“依麻目”“巴扎”也成為了高頻詞。阿凡提為傳說人物,人們會在講述其故事的時候帶有古代文化色彩。每個類別下的高頻詞基本都符合該領域的特征。
本文將現代笑話劃分為校園笑話、家庭笑話、笑話以及職場笑話。從高頻詞的分布也可以看出本文對笑話的分類是合理的。校園笑話的高頻詞為“老師、同學、學生……”,既符合校園的主題,也證明了本文分類的有效性。
根據笑話產生的原因,本文將笑話分為諧音、諧義、反語、類比、委婉、諷刺、夸張以及反轉八種類別。基于笑話產生原因的數量統計如圖5所示。
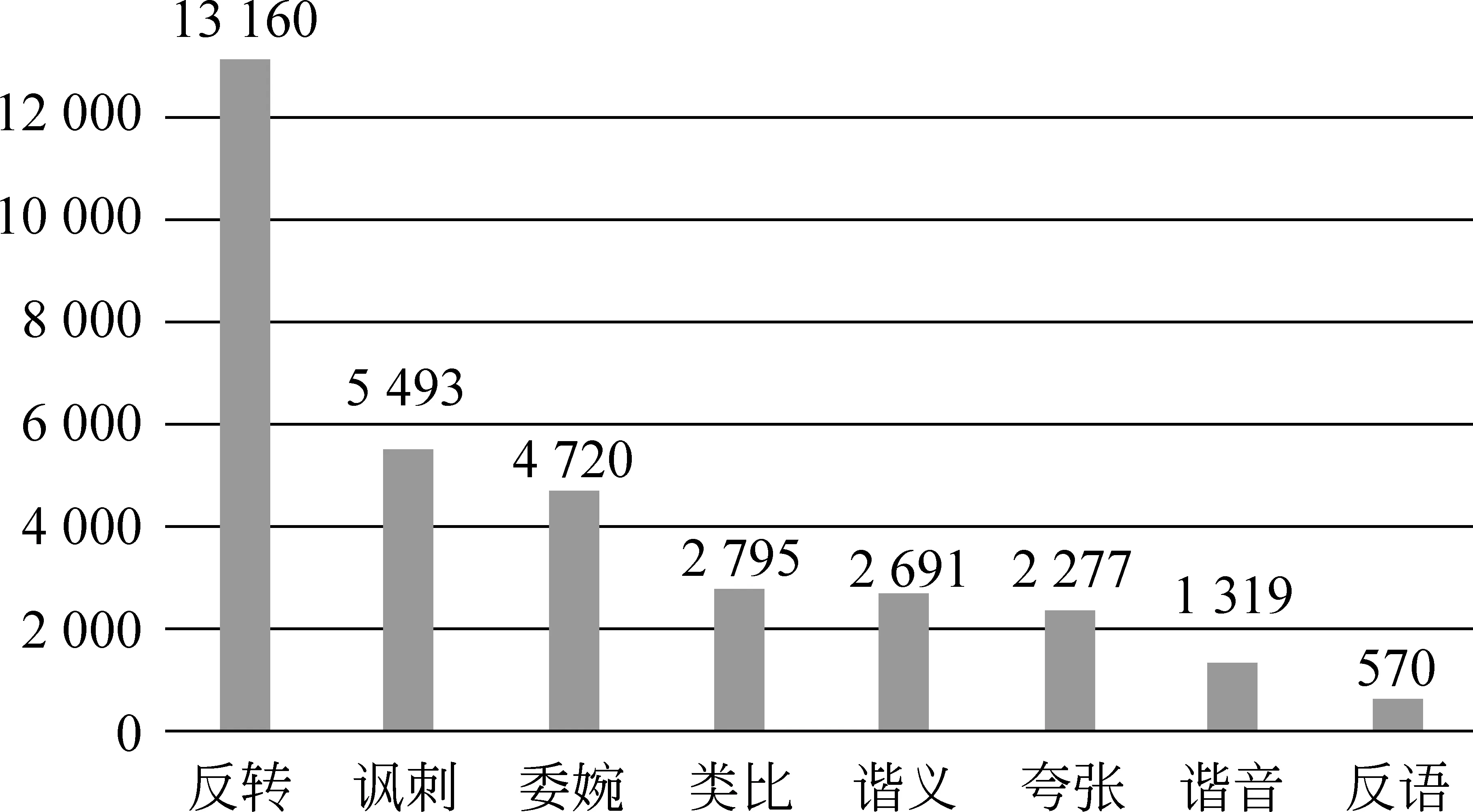
圖5 基于笑話產生原因的各分類笑話數量
由圖5可以看出,在33 025條笑話中,反轉類型的笑話有13 160條,占比39.85%;諷刺類型的笑話有5 493條,占比16.63%;委婉類型笑話有4 720條,占比14.30%;類比類型笑話有2 795條,占比8.46%;諧義類型笑話有2 691條,占比8.15%;夸張類型的笑話有2 277條,占比6.89%;諧音類型笑話有1 319條,占比3.99%;反語類型笑話有570條,占比1.73%。
4 笑話識別
4.1 相關特征
笑話作為最貼近人們生活的文學體裁,它具有簡潔性,大多數能夠揭示生活中乖謬的現象,具有一定的諷刺性和娛樂性等特性。笑話作為幽默的一種體裁,所以幽默識別的一些特征可以借鑒到笑話識別中。本文將從相關的笑話理論以及語言規范等方面梳理本文用到的特征。
長度特征(length): 由于笑話體裁的限定,呈現一定的長度特性。笑話雖然具有簡潔的特點,但是它會簡單扼要地敘述一件事情,所以相較于歇后語、諺語又比較長。因此本文采用了文本長度作為特征之一。在長度相差較大的體裁中,特征可以較準確地區分笑話與非笑話。
句法特征(syntactic): 由于笑話的不一致性,所以一般會使用句法特征。例如“為什么鳥兒在冬天飛往南方? 走著去太遠了。”當目標文本比較短的時候,句子級的句法分析是不能滿足需求的。本文需要使用詞語級的句法特征,利用詞性占比,使用jieba分詞的詞性標注方法,分別計算了名詞占比、動詞占比、形容詞占比、副詞占比以及代詞占比作為特征。
情感特征(emotion): 除了現有的幽默理論和語言學特征,笑話本身是具有情感特征的。如“甲: 我救了不少人耶!乙: 哦?說來聽聽。甲: 我落榜了。”,當甲說到“我救了不少人耶”時候的隱含情感是正向的,當故事講到最后甲說“我落榜了”——“落榜”隱含著負向的情感。這符合笑話的前后不一致性。本文采用徐琳宏[15]等人構建的情感詞典為基礎,作為計算笑話的情感特征的基礎。
轉折特征(transition): 根據對中文笑話語料庫的統計觀察,得到很多笑話都是在最后一句產生笑點的結論。根據笑話的這一特征,本文將最后一句默認為笑點,即產生轉折或者有一定的隱含意義的句子。除了最后一句,前面的所有文本作為一部分,最后一句作為另一部分,將二者包含的所有詞的Word2Vec相加求平均作為它們的語義向量,通過相似度差異作為特征。
詞義距離(vocabulary): 本文考慮到在笑話中往往會前后存在沖突,這些沖突一般是由一些詞語造成的,比如“報數”與“抱樹”語義距離相差很大,因此本文將名詞以及動詞作為產生沖突的候選詞,分別將笑話中的笑點包含的名詞/動詞通過Word2Vec計算平均詞向量與其他文本包含的動詞平均詞向量計算距離,作為詞義距離特征。
4.2 數據集描述
笑話數據集采用中文笑話語料庫中的笑話作為正例,共33 025條。從不同時間軸上包含了不同時代的人、事、物,包括古代笑話、校園笑話、家庭笑話、職場笑話和名人笑話,又在一定程度上包含了當下最經典、最日常的場景主題。在不同維度保證了正例的多樣性。
本文使用了故事、新聞體裁、諺語/歇后語以及微博四種不同體裁、不同來源的文本作為負例。從表3的示例可以看出: 四種體裁在長度、敘述手法等方面都不相同。下面將分別對四種體裁的負例進行介紹。
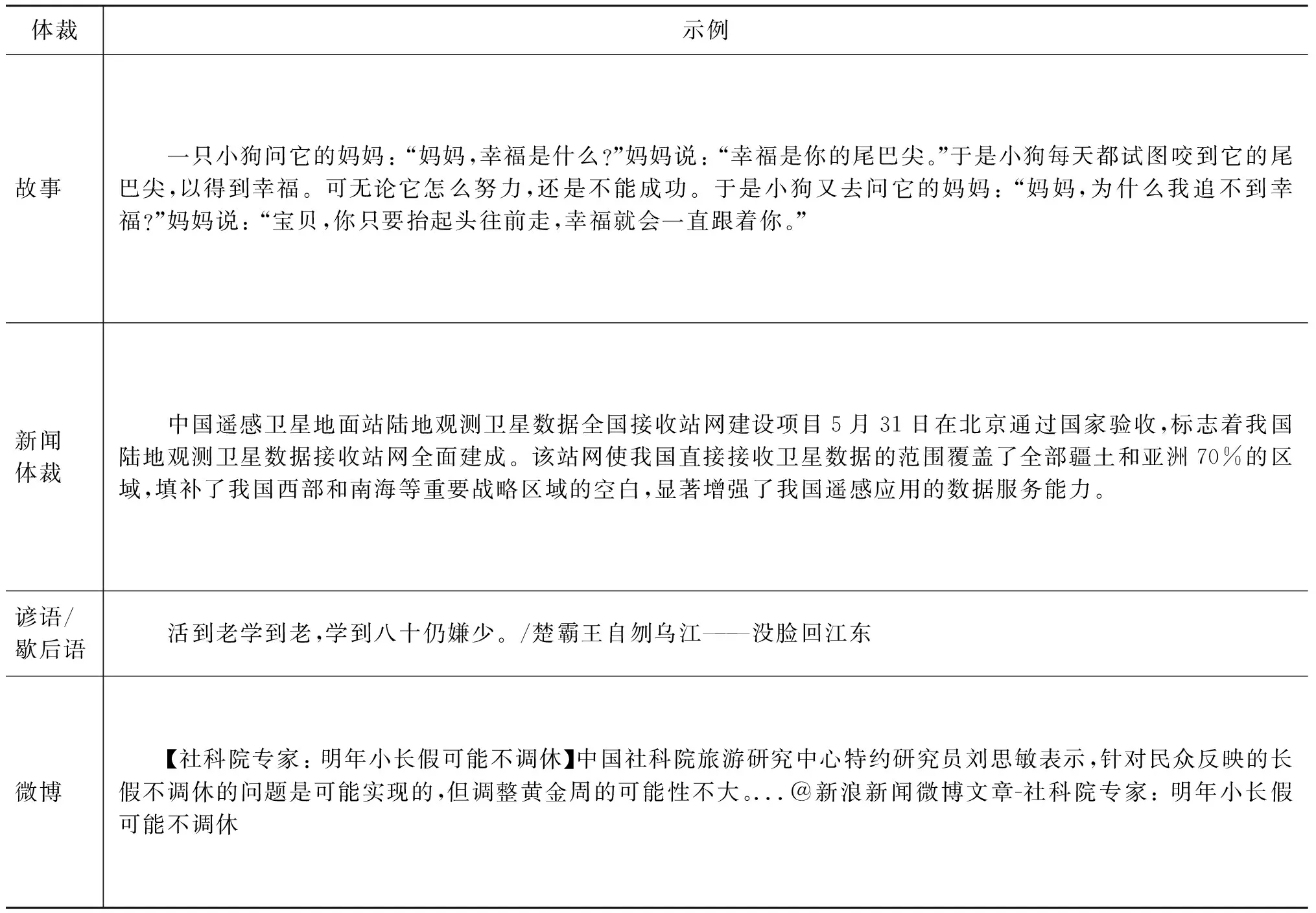
表3 各類負例示例
故事是文學體裁的一種,側重于事件發展過程的描述。這一特點預示著大多數故事不會很短。本文的故事是使用網絡爬蟲程序從網址1*http: //www.xigushi.com/收集到的,該網址包含了很多類故事,共收集到了6 260篇故事,每篇平均長度為965字。除了該網址中的幽默故事,其他類型的故事都存在于語料中。
諺語是廣泛流傳于民間的言簡意賅的短語,多數反映了勞動人民的生活實踐經驗,多是口語形式的通俗易懂的短句或韻語。歇后語是中國勞動人民自古以來在生活實踐中創造的一種特殊語言形式,是一種短小、風趣、形象的語句。諺語以及歇后語也都是貼近人們生活、口口相傳的藝術瑰寶。本文收集了共1 671條文本,其中歇后語有904條,諺語有767條。
新聞是通過報紙、電臺、廣播等媒體途徑傳播消息的一種文體。本文選取了從網址2*http: //www.ssydt.com/sszz/總結的從2007年到2017年6月的時政新聞作為負例。共收集到6 071條新聞體裁類語料。
微博(Weibo),即微型博客(Microblog)的簡稱,也即是博客的一種,是一種通過關注機制分享簡短實時信息的廣播式的社交網絡平臺。微博作為當代人分享心情、傳播消息最熱門的社交平臺之一,每天有超過1億條微博內容產生。本文采用了SMP2016評測任務的微博語料,共237 801條語料,選取了前30 000條微博語料作為負例。
4.3 實驗結果分析
本節利用五類特征分別對笑話與故事、新聞、諺語歇后語以及微博這四類體裁進行區分。實驗采用Logistic Regression算法,用五倍交叉驗證的方式進行實驗。本文采用準確率、召回率以及F1值作為評價指標。
首先使用6 260篇故事與33 025條笑話構成的39 285的數據集進行幽默識別任務。雖然故事與笑話都具有一定的情節,但是由于篇幅的不同,使用長度作為特征就可以把二者區分開。這也進一步證明了笑話的簡潔的特點,結果如表4。

表4 以故事類為負例的實驗結果
其次,本文使用1 671條歇后語/諺語作為負例,由于負例與正例的數據明顯不平衡,將33 025條笑話中名人笑話1 874條笑話與該負例構成數據集,并進行識別任務。由于各自篇幅的特點,實驗采用了長度作為特征,相較與長篇故事,效果更好。由于笑話通常會有一定的情節,而歇后語/諺語是簡單扼要地說明一個問題,一般是通俗易懂的短句或韻語,歇后語/諺語與笑話類型的語料在長度上有天然的分界。實驗結果如表5。

表5 以歇后語/諺語為負例的實驗結果
接著,本文使用收集到的6 071條新聞類語料當作負例,與33 025條笑話構成共39 096條數據的數據集進行笑話識別。先使用長度作為特征,但并未取得較好的效果,這說明新聞類的體裁與笑話類體裁的篇幅差距不大。由于新聞類體裁屬于官方文字,所以情感詞語用得不多,本文使用徐琳宏[15]等人構建的詞典作為基礎,如出現在情感詞典中,則值為1,否則為0。實驗結果如表6所示,證明了句法特征以及情感特征的有效性。
最后本文采用SMP 2016評測提供的微博中的前三萬條作為負例,長度特征、句法特征、情感特征依次添加到模型中,結果如表7所示,證明隨著特征的增加,準確率、召回率、F1值等都有不同程度的提升,再一次證明了特征的有效性。

表6 以新聞類體裁為負例的實驗結果

表7 以微博類體裁為負例的實驗結果
本節分別從故事、歇后語/諺語、新聞以及微博分別構建負例,做笑話識別任務。由于笑話更貼近人們的生活,具有強烈的情感,所以與其他體裁識別效果明顯。
考慮到不同數據集的文本長度分布的不同,僅使用文本長度就可以對笑話與非笑話進行區分,不利于笑話識別工作的開展。針對這個問題,本文從文本長度的角度對正例與負例進行數據集重新構建,正例來自中文笑話語料庫,負例來源于故事、新聞體裁、諺語/歇后語以及微博構建的負例集合。長度統計如表8所示。

表8 正例與負例在不同長度區間的分布
基于正負比例平衡,選取長度大于150小于等于200的笑話作為正例,負例同樣選取該區間的文本。最終選取了3 477條正例與4 242條負例構建的數據集進行幽默識別試驗。由于選取了相同的長度區間的正例、負例,所以長度不能再作為特征之一。首先采用情感作為特征之一,此時僅僅采用情感詞的多少作為特征是遠遠不夠的,將一個樣例中所有的情感詞根據情感詞典中具有積極情感以及消極情感的詞的打分,取出得分最高以及最低的情感詞,并將其得分相減,作為情感特征。實驗采用了情感特征、句法特征、基于笑話本身的轉折特征以及詞義距離訓練分類器,笑話識別結果如表9所示。
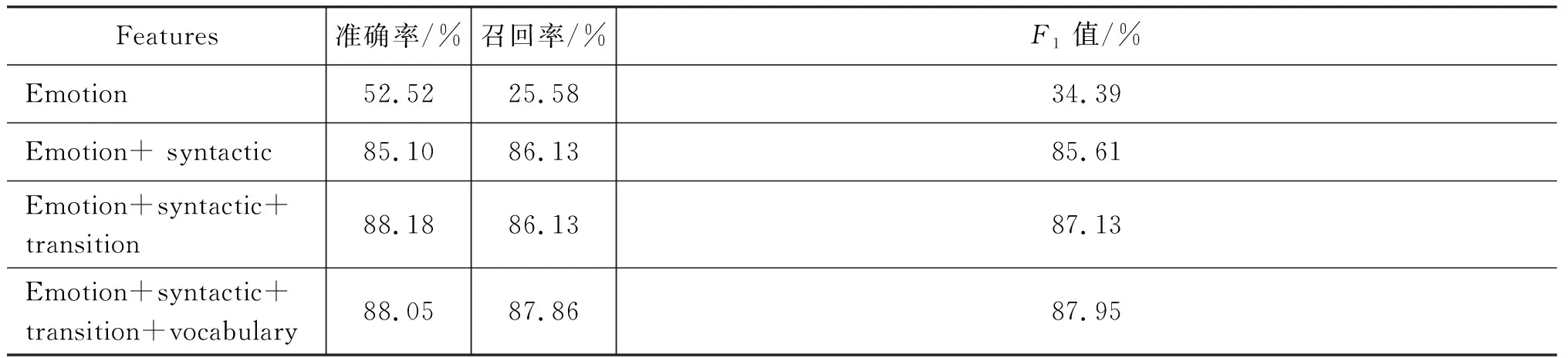
表9 等長文本的笑話識別結果
5 笑話語料庫在聊天機器人中的應用
“人工智能之父”——圖靈在哲學刊物《思維》(Mind)上發表了“計算機器與智能”的文章,提出了后來經典的圖靈測試——交談能檢驗智能,如果一臺計算機能像人一樣對話,它就能像人一樣思考。現有的聊天機器人還處于比較低級的人工智能階段,并沒有通過圖靈測試。目前的聊天機器人還存在缺少人情味、不能思考等問題。為了使聊天機器人更智能、更有人情味以及具有幽默感,本節通過以下幾點分析介紹。
5.1 笑話語料的擴充
現有的聊天機器人在笑話儲備問題上不夠完整,比如Siri、微軟小冰等,讓他們講諸如阿凡提這類具有我國少數民族特色的笑話,他們都不能勝任,因為他們不包含此類笑話。中文笑話語料庫包含了多種類、多視角的笑話,可以滿足更多人的需求。可以通過以下幾個方式來滿足用戶的需求:
(1) 利用用戶提供的關鍵詞,直接搜索,找到對應的笑話;
(2) 對于找不到精確匹配的笑話,可以根據關用戶提供的關鍵字與笑話的題目、關鍵字、場景、分類等依次進行相似度計算,匹配相似度最高的笑話作為輸出。
5.2 笑話識別
聊天機器人想要通過圖靈測試,至少暫時性地讓與它對話的人類認為他是一個人而不是一臺機器,成為一種高級的人工智能。除了使機器人具有情感、智慧、能夠思考外,還應該讓它具有幽默感,能夠理解與它對話的人類幽默的點,這將使人工智能向前推進一步。如何讓計算機擁有幽默感呢?目前國內外也有很多研究者在幽默識別的工作中取得了一些進展,也使用了很多類特征,使用機器學習方法做識別任務。也有很多學者使用了深度學習方法。我們日后可以通過中文笑話語料庫中標注的關系、場景、關鍵詞等訓練需要識別的文本,抽取相應的特征;使用深度學習表示方法對該文本深層語義信息進行表示,利用深度學習網絡模型將抽取的特征添加到模型中,通過深度學習神經網絡計算判斷是否為笑話。
5.3 笑話生成
聊天機器人要想實現高級的人工智能,僅僅能夠理解笑話是不夠的,還需要能夠根據用戶的需求自動生成笑話。中文笑話數據庫的構建為笑話生成技術帶來了可能。笑話的生成是聊天機器人通過用戶的輸入以及笑話產生的機制自動化地生成笑話的過程。在NLP領域中,生成技術一直以來都是一個難點,尤其笑話生成是基于人的認知的高難度難題,它既需要深度理解文本中的語義,也需要對背景知識以及相關文化有所了解。林鴻飛[17]等人提出一種基于深度學習的幽默生成框架,今后可以參照該框架結合中文笑話語料庫自身的特點,最終實現笑話生成技術。
笑話生成技術中的輸入為用戶提供的文本,根據上下文的對話提取關鍵信息,如關鍵詞、場景、人物關系以及雙關語等,利用深度神經網絡模型對關鍵詞進行深層語義挖掘表示,與中文笑話語料庫中的笑話中的高頻詞進行相似度計算,取出相似度最高的高頻詞與笑話對應的關鍵詞進行替換,形成候選笑話文本集合,依次根據笑話識別技術判斷其是否好笑,好笑的文本則作為輸出。
6 結論
在幽默計算對語料資源的迫切需求下,本文構建了大規模笑話語料庫。目前已經完成了第一階段的標注,包括33 025條笑話。本文通過對中文笑話語料庫的分析,總結了許多笑話內部的特點。通過與小學生常用字作對比,驗證了笑話通俗易懂的特點。通過對高頻詞的歸納,可以總結出比如“阿凡提”“小明”等名字、“老婆”“老公”等稱呼、“甲”“乙”等代詞多在笑話中出現。在笑話語料庫第一階段初步標注的基礎上,本文結合笑話簡潔、具有一定的情感等特點,構建了五類特征,并且構建了不同的負例對笑話進行識別,從不同的角度驗證了特征的有效性。但是,語料庫的構建不可能是完美無暇的,我們將在今后的工作中,進一步對語料庫進行完善修訂,補充更多的數據;利用語料庫標注的信息對反轉識別、雙關識別(諧音/諧義)、反語識別、笑話生成等難題進行攻破。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
甘肅教育(2020年8期)2020-06-11 06:10:02
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
