基于數據并行的神經語言模型多卡訓練分析
2018-08-17 08:38:36李垠橋阿敏巴雅爾朱靖波
中文信息學報 2018年7期
李垠橋,阿敏巴雅爾,肖 桐,薄 樂,朱靖波,張 俐
(東北大學 自然語言處理實驗室,遼寧 沈陽 110819)
0 引言
使用神經網絡進行語言建模依賴于大規模的語料數據,同時更大規模的參數設置一般來說也會對神經語言模型的訓練有著正向的作用[1-3]。但當面對海量的數據和大規模的網絡參數時,如何更加快速地進行模型訓練便成了一個亟待解決的問題。
針對此問題,研究人員引入了GPU加快矩陣運算,為了進一步獲得速度提升,訓練也開始從單一設備轉變到多設備并行。其主要方法有兩種,數據并行和模型并行[4]。本文主要針對數據并行進行研究,該方法將數據分成若干部分,在多個設備上進行訓練,以達到加速的效果。但該方法的簡單實現并未達到令人滿意的速度提升[5],問題在于訓練過程中,設備間的數據傳輸占用大量時間。實驗中,我們使用四張NVIDIA TITAN X (Pascal)GPU卡對循環神經網絡進行訓練,數據傳輸的時間占比高達70%。可以看出減小這部分耗時成為解決多設備訓練中的重要問題。
科研人員針對如何在單位時間內傳輸大量的數據進行了研究,提出了許多可行的方法,如異步參數更新[6]、基于采樣的更新[7]等。本文主要針對使用All-Reduce算法以及采樣策略的神經網絡梯度更新進行實驗,在不同設備數量下訓練前饋神經網絡和循環神經網絡語言模型[8],對比分析時間消耗隨設備數量的變化趨勢。實驗中,使用上述兩種方法訓練的循環神經語言模型相對點對點結構在四張NVIDIA TITAN X (Pascal)GPU設備環境下分別可節約25%和41%左右的時間。
1 面向神經語言模型的數據傳輸
1.1 數據并行訓練
數據并行的方法最早由Jeffrey Dean等人提出[4],將數據分散到不同的設備中訓練,過程如圖1所示,參數按照式(1)進行更新。
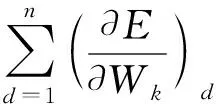
(1)
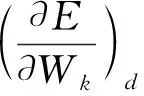
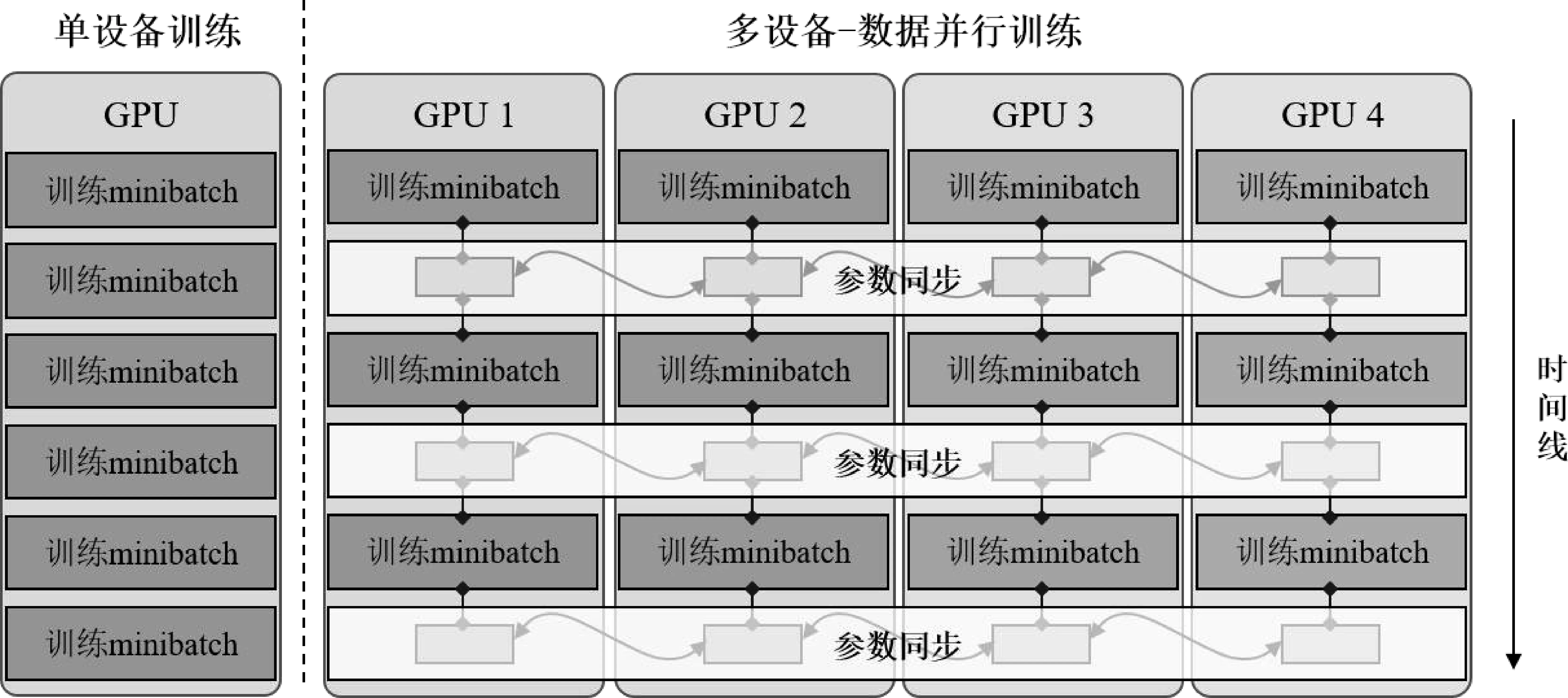
圖1 數據并行訓練與單設備訓練過程對比
1.2 數據傳輸方法
1.2.1 點對點的數據傳輸
點對點數據傳輸是一種常見的參數同步策略,采用中心化結構,如圖2(a)所示。網絡中設置一個參數服務器,保存全局的網絡參數,其余每臺設備在計算好自己的權重梯度后將其發送給參數服務器,然后進入等待狀態。參數服務器端收集到全部設備的梯度后,將它們累加到自身的網絡參數上,之后再將這個更新后的參數值返回給每個計算設備,完成一個minibatch的更新。整個過程如圖3所示,主要分為梯度計算、梯度收集、更新模型和回傳參數四個部分。
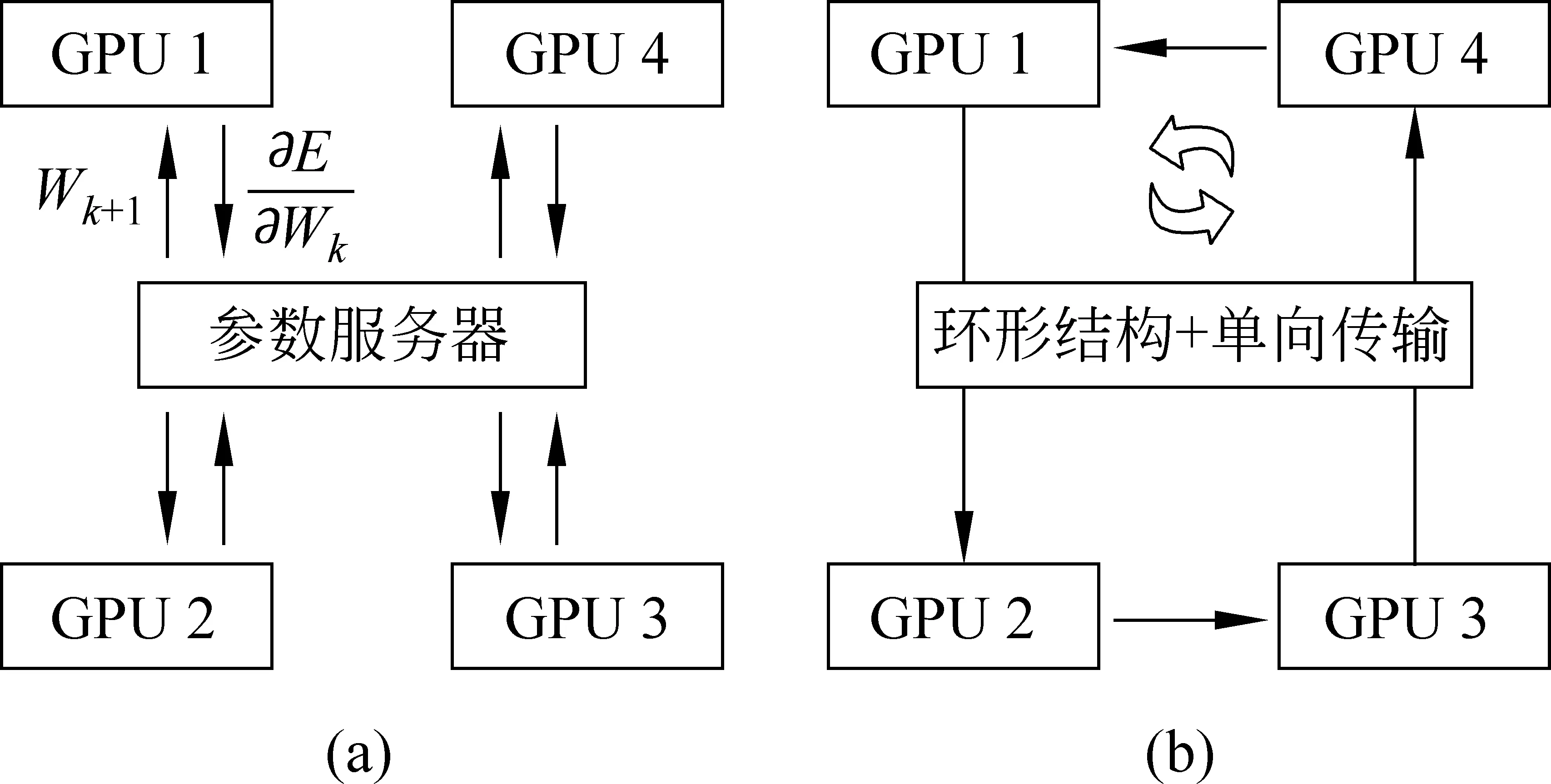
圖2 基于點對點、All-Reduce的梯度更新結構
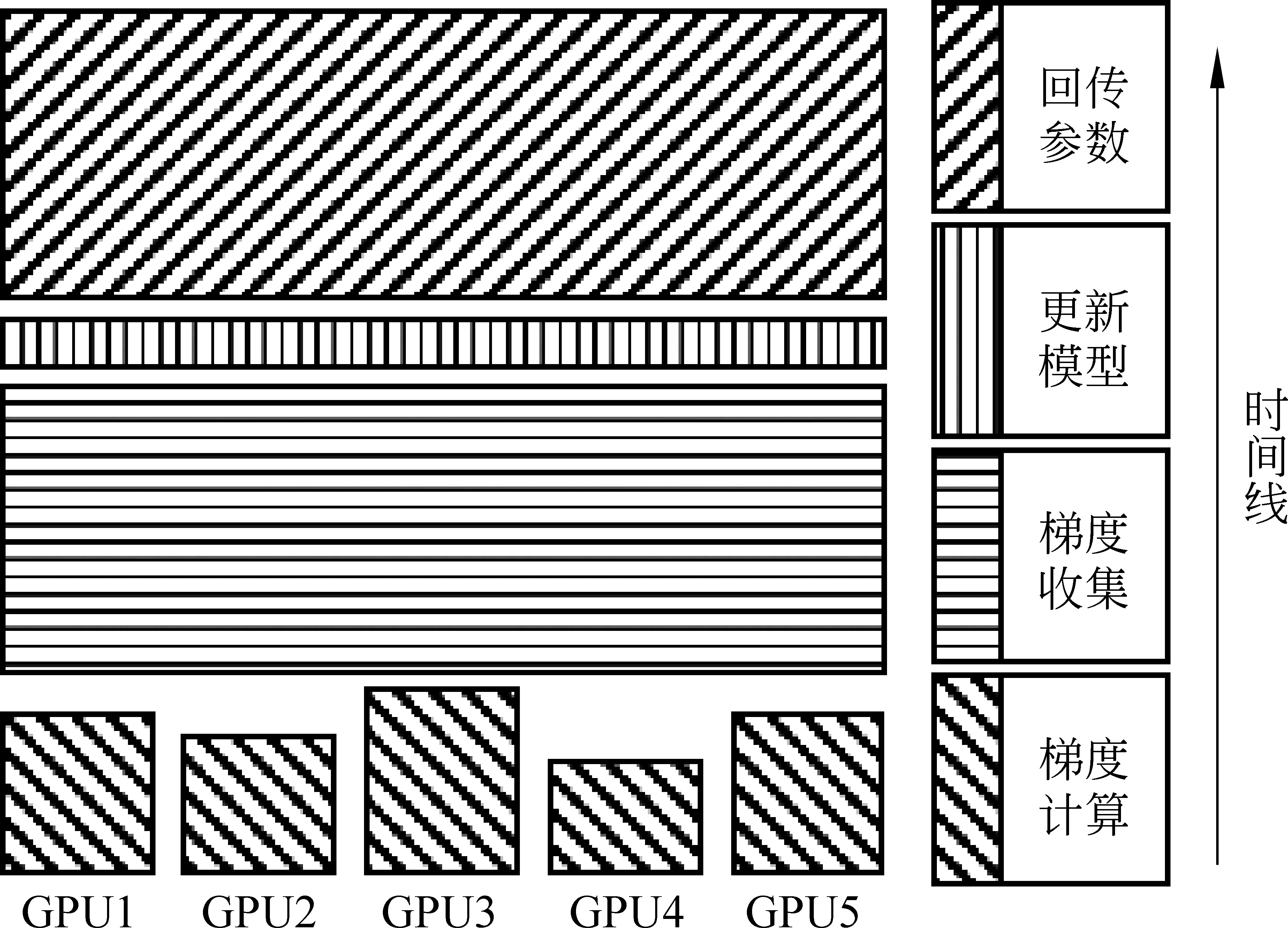
圖3 基于點對點的梯度更新計算時序
由于計算機總線帶寬有限,因此和數據傳輸相關的操作會花費較多時間。假設網絡中計算梯度的設備數量為n,每個設備上所需傳輸的數據量大小是K,網絡中數據傳輸的總線帶寬是B,那么在梯度收集和回傳參數過程中產生的時間消耗如式(2)所示。
(2)
我們可以看出,隨著設備數量n的增加,傳輸的時間消耗也隨之線性增長,這導致很難通過簡單地增加設備數量獲得線性增長的運算速度,難以在更多設備上對網絡進行訓練。
1.2.2 基于All-Reduce的數據傳輸
為減輕參數服務器在數據傳輸過程中的壓力,Linnan Wang等人提出使用All-Reduce算法進行梯度的傳遞[9],結構如圖2(b)所示。
整個網絡以環狀結構進行傳輸,起初每個設備節點將自身的梯度數組分成n份,n為環形結構中設備節點的數量。在第一階段,設備節點將依次發送每一塊數據到其下一順位的設備,并從上一個節點接收一個塊,累積進本設備的對應位置。執行n-1次后,每個設備中將擁有一個累加了全部設備上對應位次數據的塊,之后進入第二階段。每個設備依次發送自身擁有最終結果的數據塊到下一位序的設備,同時根據接收到的數據塊進行覆蓋更新,同樣該步驟按序執行n-1次后,網絡中每個設備均將獲得最終的累加結果。算法流程如算法1所示。

算法1: 使用All-Reduce進行梯度累加輸入: 設備數量n(>1),梯度向量grad1blocks = split(grad, n)2for i = n → 2 do3 send(next, block[(i+devID]%n])4 recv_block = recv()5 block[(i+devID-1)%n]+=recv_block6end for7for i = n → 2 do8 send(next, block[(i+devID+1)%n])9 recv_block = recv()10 block[(i+devID)%n]=recv_block11end for
使用All-Reduce算法進行梯度累加,取代了原有方法中梯度收集和回傳參數的過程,其梯度更新計算時序如圖4所示。最終完成整個過程的時間如式(3)所示。
(3)
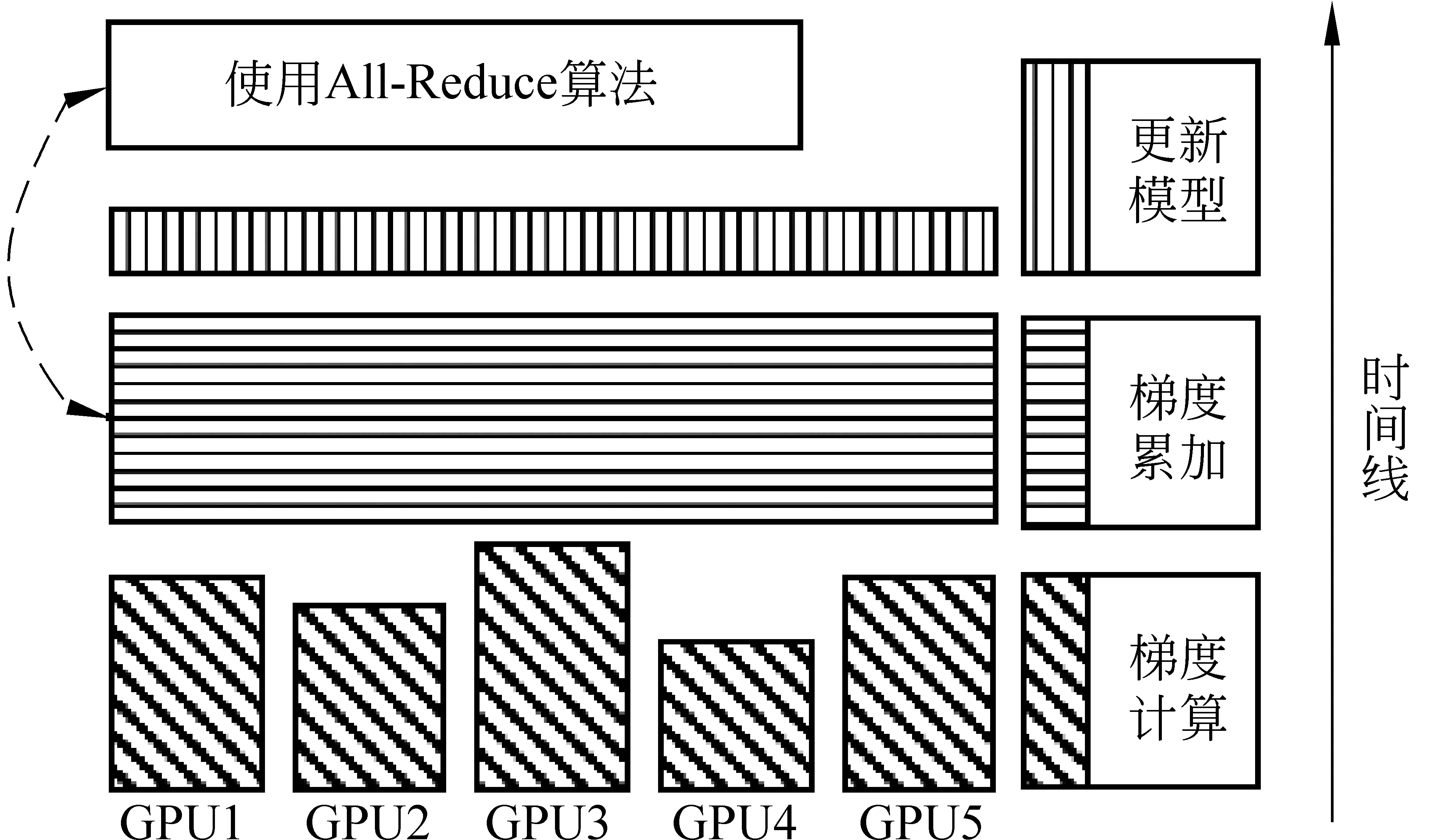
圖4 基于All-Reduce的梯度更新計算時序
從式(3)中我們可以看出,雖然傳輸時間仍隨設備數量n的增大而增大,但不同于點對點的數據傳遞,傳輸時間和設備數量之間不存在線性相關的問題,這一點為引入更多設備參與訓練提供了良好的基礎。此外,由于該方法并未對模型訓練方式及內容進行修改,因此不會對模型本身的性能產生影響。
1.2.3 基于采樣的數據傳輸
不同于All-Reduce算法從增大傳輸速度的角度減小訓練耗時,采樣的方法希望通過減小數據傳輸量達到加速的目的[7]。該方法在收集梯度的過程中,從完整的梯度矩陣中抽取出對提高神經語言模型性能更有幫助的部分進行傳輸,減少了傳輸的數據量,從而節約了在該過程中的時間消耗。
該方法針對不同層提出了不同的采樣方法。如對于輸出層權重(大小為v×h,v為詞表大小,h為隱藏層節點數目),其中每一行對應著詞表中的一個詞。為使網絡能夠更快收斂,在采樣過程中希望能夠盡可能頻繁地更新那些經常出現的詞,具體的選取策略如式(4)所示。
Vall=Vbase∪Vα∪Vβ
(4)
其中,Vbase為在當前minibatch中出現的詞,Vα為從詞匯表中選擇頻繁出現的若干詞,Vβ為從詞匯表中隨機抽取的詞以保證系統具有良好的魯棒性,在測試集上更穩定。同樣,在輸入層和隱藏層也有不同的采樣策略。另外,由于本方法更加頻繁地對能夠加快收斂的梯度部分進行更新,使得模型收斂速度加快,與此同時模型本身性能變化不大。
2 對比
2.1 實驗系統
本文相關實驗使用東北大學自然語言處理實驗室NiuLearning深度學習平臺,結合NCCL開源框架,在四張NVIDIA TITAN X (Pascal)GPU設備上進行。主要對比不同設備數量下,基于All-Reduce算法和采樣的更新策略對循環神經語言模型訓練速度的影響。此外本文也在前饋神經語言模型[16]中使用All-Reduce算法進行實驗,分析數據并行在不同網絡結構下的適用性問題。
本文實驗數據使用Brown英文語料庫(1 161 169詞,57 341句),從中抽取40 000句子作為訓練集,統計49 036詞作為語言模型詞匯表。在模型參數方面,循環神經網絡和前饋神經語言模型輸入層和隱藏層節點個數均為1 024,minibatch為64。前饋神經網絡訓練5-gram語言模型。
2.2 實驗結果及分析
2.2.1 加速效果及變化趨勢
實驗中將基于點對點進行數據傳輸的系統作為基線,在四張GPU設備上獲得約25%的加速效果,具體實驗結果見表1。使用基于采樣的梯度更新策略,在同樣參數設置下,四張GPU設備加速比達41%左右,具體實驗結果如表2所示,整體趨勢如圖5所示。
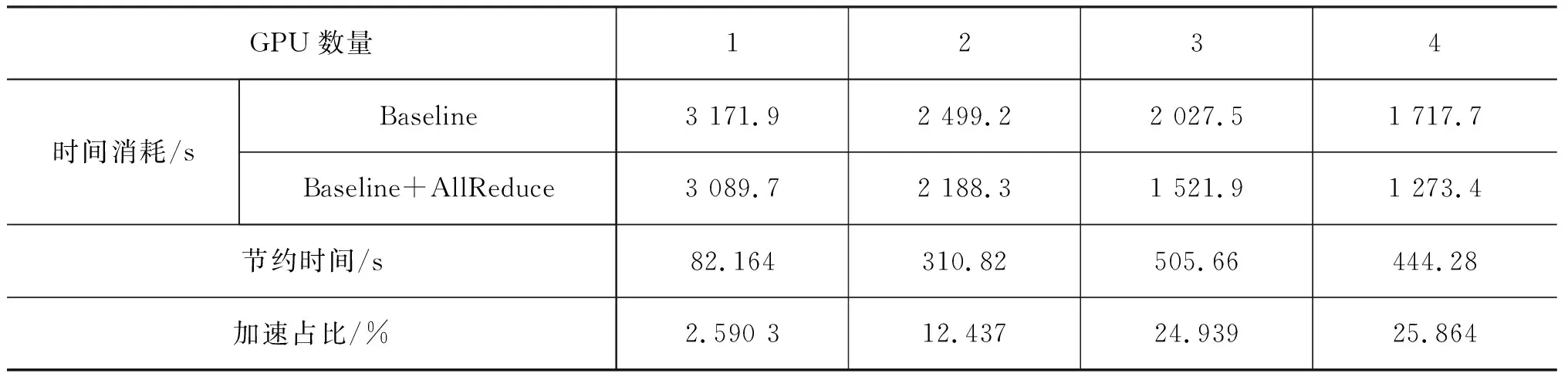
表1 基于All-Reduce梯度更新策略在循環神經語言模型中每個Epoch的時間消耗情況
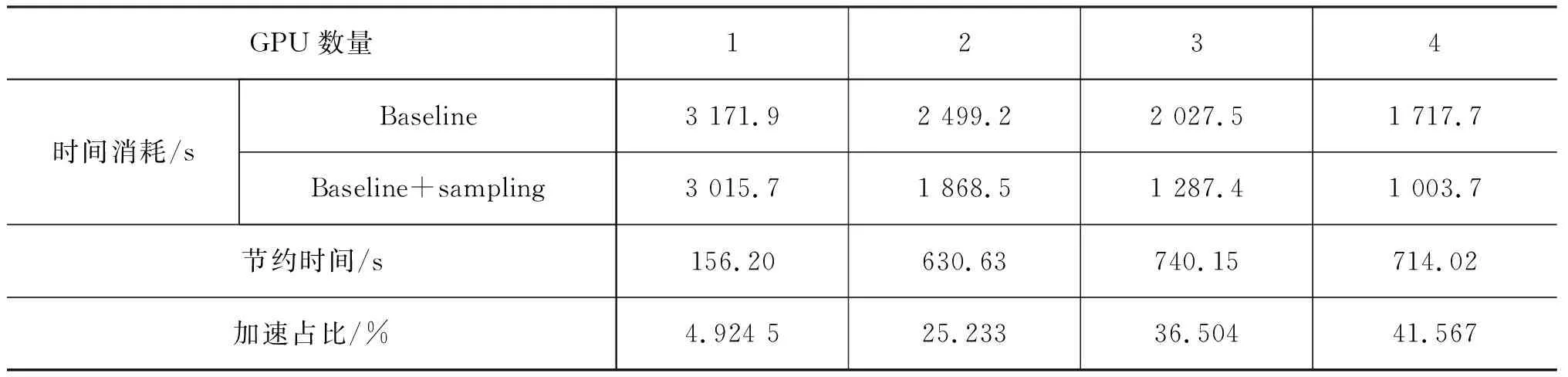
表2 基于采樣的梯度更新策略在循環神經語言模型中每個Epoch的時間消耗情況
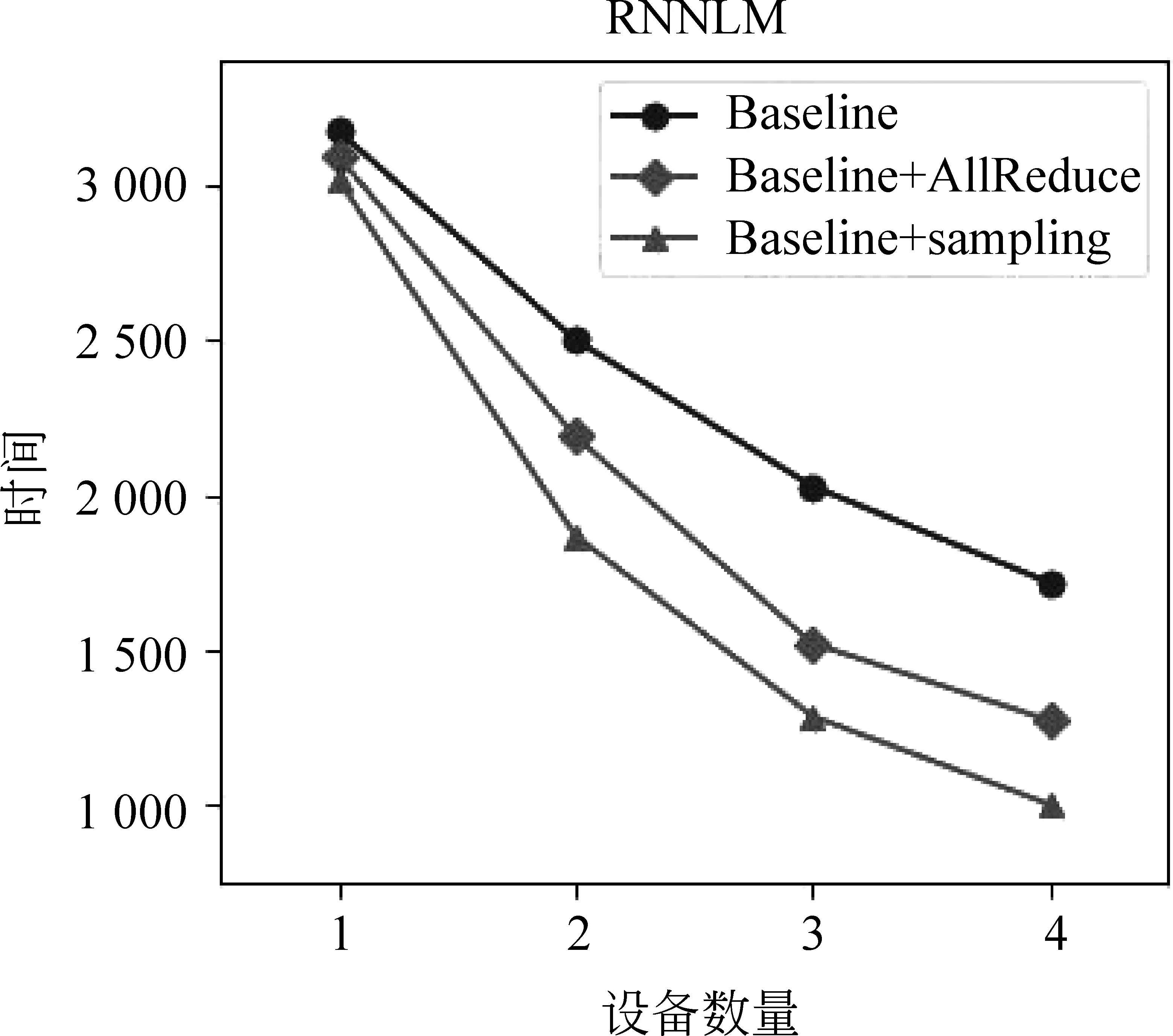
圖5 基于All-Reduce和采樣策略的時間消耗對比
在基線系統的時間消耗中,由于梯度的計算和更新模型不存在內存和顯存的交互,因此速度較快。而對于梯度的收集和參數回傳,其占用的時間隨設備數量的增多而線性變大,因此每個minibatch所消耗的時間如式(5)所示。
(5)
其中tcal&update為梯度計算和模型更新所消耗的總時間。同理,根據圖4我們可以看出,使用了All-Reduce算法的梯度累加替代了原本方案中的梯度收集和參數回傳的過程,同時這部分的時間消耗并不隨設備數量線性增長。在使用了該算法進行梯度更新的情況下,每個minibatch所花費的時間如式(6)所示。
(6)
在整個訓練過程中,由于樣本數量是固定的,因此minibatch數量也是不變的。而多設備訓練將樣本分散到不同設備上并行計算,使得在同一時刻整個系統見到的minibatch個數隨設備數量線性增加,換句話說總時間消耗將降為原本的1/n,因此在每一輪訓練過程中,基線和基于All-Reduce的方法在時間消耗上分別如式(7)、式(8)所示。
(7)
(8)
其中bn為整個訓練集中minibatch的數量。根據上述公式,我們可以得到理論上在1~4塊設備的狀態下每輪執行所需要的時間,如表3所示。其中當設備數量是1,不使用All-Reduce的情況下,由于無需通過總線進行數據傳遞,將這部分耗時用tgather&back表示。從表3中我們可以看出,隨著設備數量的增長,節約的時間越來越多,這一點從圖5的實驗結果中也能觀察到。

表3 在1~4塊設備上執行一輪訓練所需理論時間
從表2的實驗結果我們可以看出,使用采樣的梯度更新策略可以獲得更高的加速比。不同于All-Reduce試圖找到一種更快速的傳輸策略,該方法通過減少數據傳輸量來降低多設備訓練中大量的時間消耗。由于二者出發點不同,因此理論上可以同時使用兩種方法對訓練過程進行加速。
2.2.2 數據并行算法適用性
我們使用不同大小的詞匯表,通過All-Reduce算法訓練循環神經語言模型,時間消耗如圖6所示。可以看到,隨著詞表的減小,多設備訓練的時間優勢逐漸降低。
此外我們在前饋神經語言模型上進行實驗,參數相關設置與循環神經網絡相同,具體實驗結果見表4。在多設備情況下,隨著設備數量的增多,前饋神經網絡在使用All-Reduce算法前后變化趨勢如圖7左側部分所示,類似于循環神經網絡。但從表4中我們可以看出,當設備數為1時,訓練1輪所需時間遠小于多設備訓練的方法。以上兩組實驗均出現了單設備訓練優于多設備并行的現象。循環神經語言模型實驗中,由于詞表的減小,梯度計算耗時變低,導致并行優勢被數據傳輸所掩蓋。同理,前饋神經網絡相較循環神經網絡在結構上更加簡單,數據傳輸占據了耗時的主要部分,即使使用All-Reduce算法對傳輸時間進行稀釋,也無法抵消其所帶來的耗時問題。從表3的理論推導中我們也可以看出,當使用多設備(n>1)訓練神經網絡的時候,時間消耗均與K有著很強的線性關聯,當所需傳輸的數據量較大時,多設備訓練的實際效果并不會很好。
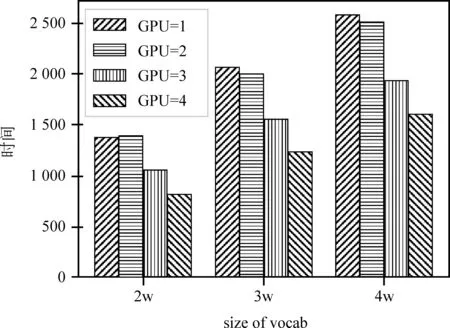
圖6 不同詞表大小下基于All-Reduce的時間消耗

GPU數量1234時間消耗/sBaselineBaseline+AllReduce節約時間/s加速占比/%317.221 280.41 242.61 228.8216.071 245.41 095.4903.58101.1535.003147.18325.2331.8862.733711.84526.467
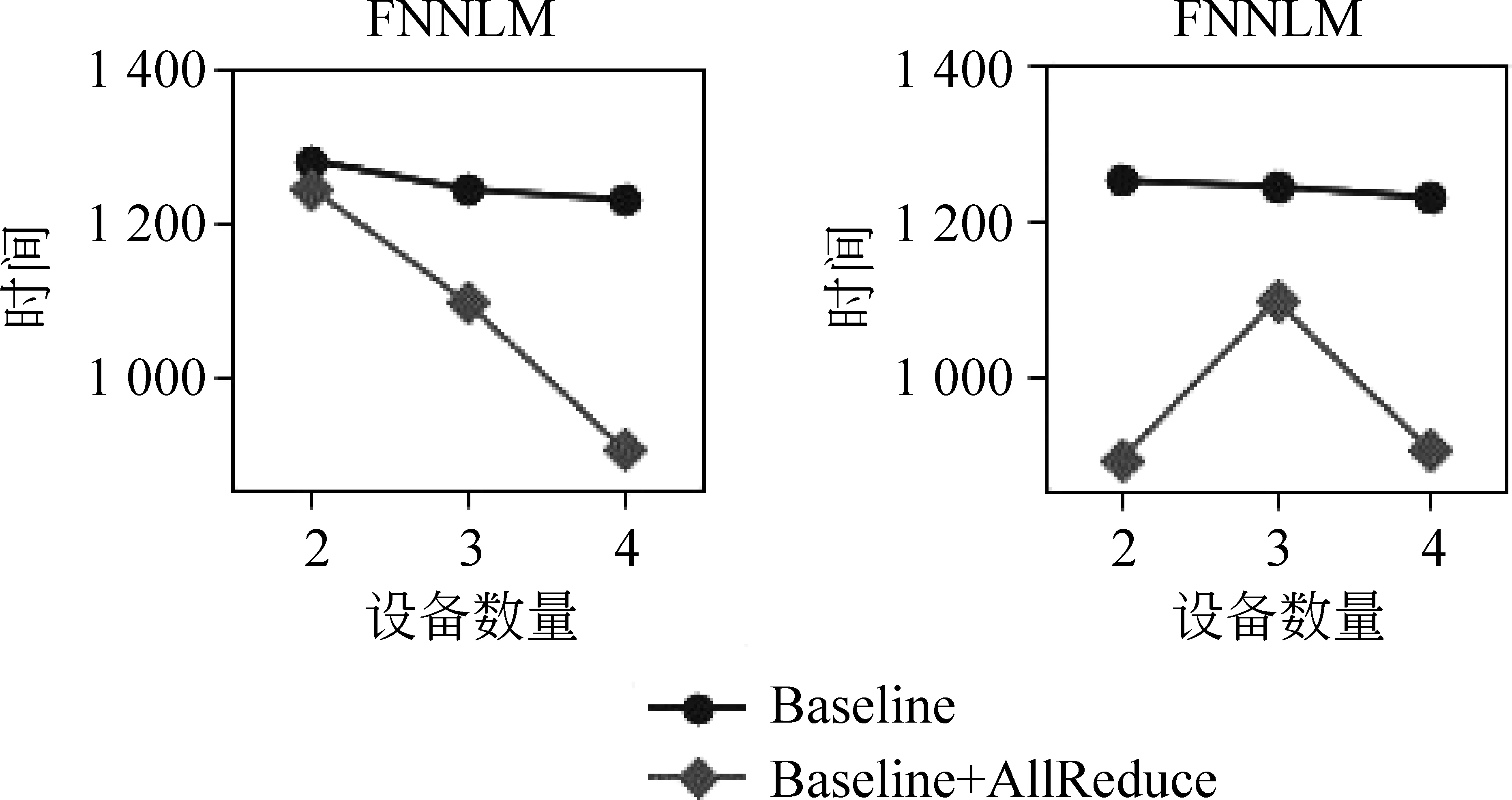
圖7 不同設備配置下基于All-Reduce的時間消耗
2.2.3 硬件連接方式對速度的影響
在實驗過程中發現,設備之間硬件的連接方式也會對傳輸速度產生影響。在前饋神經網絡語言模型的實驗中,當設備數量為2且工作節點使用0號和1號GPU進行訓練時,時間消耗曲線如圖7中右側部分所示,左側部分為使用0號和2號設備所得,我們可以看出,當選擇不同設備進行數據傳輸時,其所消耗的時間也有可能不同。我們實驗平臺上的硬件拓撲結構如圖8所示,0號和1號卡為一組,2號和3號為一組,均使用PCIe Switch進行連接。
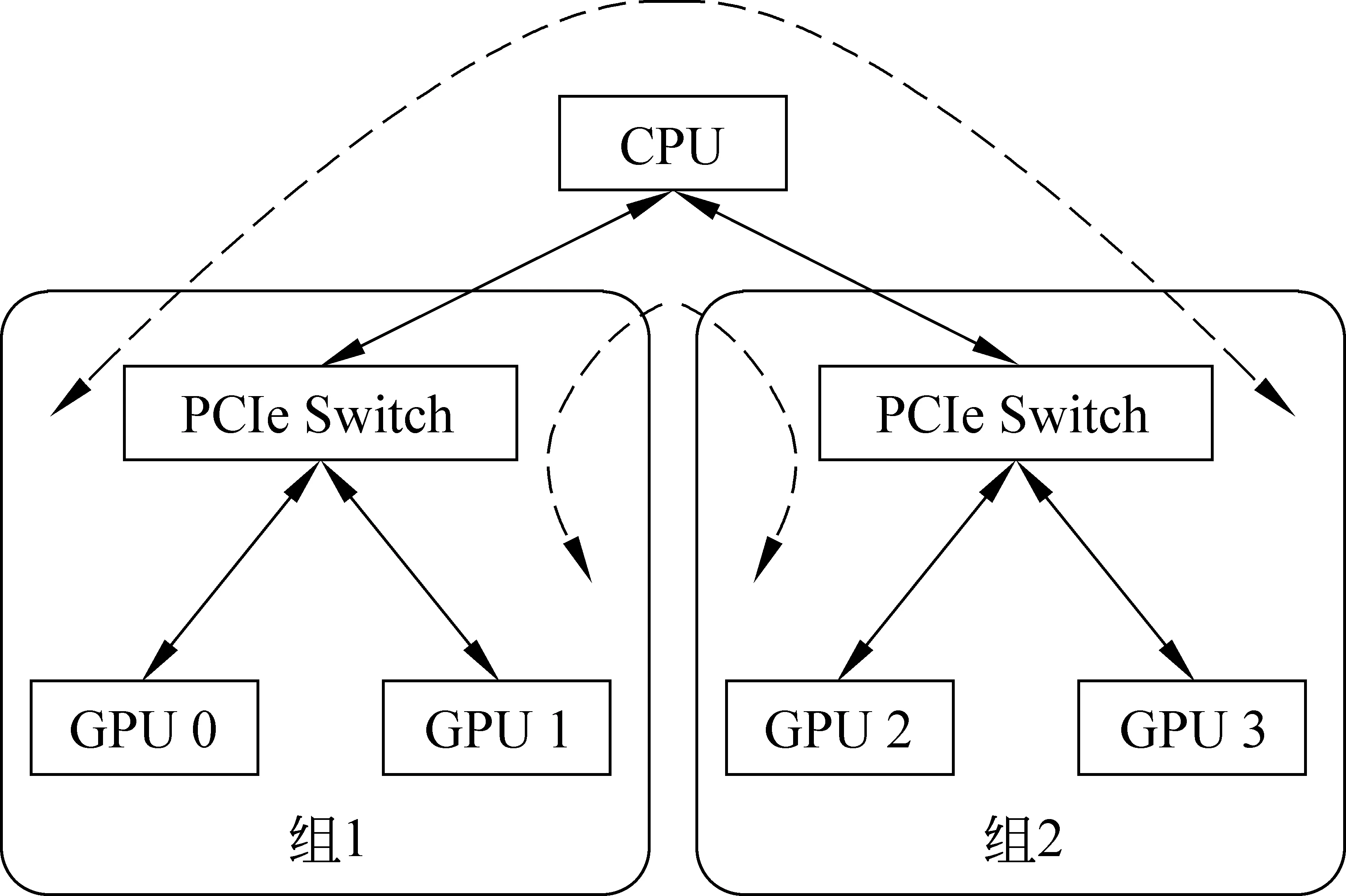
圖8 實驗平臺的硬件拓撲結構
由于組內進行數據傳輸無需通過CPU,占用總線帶寬,因此傳輸速率較快,組間由于需要經過多個設備對數據進行轉發,因此速度相對慢一些。1~3卡之間互相傳輸數據帶寬如圖9左側部分所示,其中顏色越淺帶寬越高,傳輸速率越快,圖9右側給出組內平均帶寬為5.96 GB/s,組間4.46 GB/s。
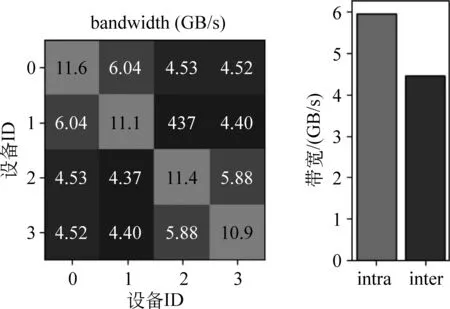
圖9 不同設備之間數據傳輸帶寬
由于All-Reduce算法采用環形結構讓設備之間進行數據傳輸,因此只要系統中存在任意兩臺設備間傳輸速度慢,那么就會拖慢整體系統的傳輸速率。因此在前述兩張卡的實驗中,為保證實驗公平性,我們使用0號和2號進行實驗,保證多設備的每組實驗中均存在組間的數據傳遞。同理,在基于采樣的數據傳輸過程中,其數據傳輸方式仍為點到點的傳輸,慢速的連接只會影響節點本身與參數服務器之間的傳輸過程,對整體的時間消耗影響有限。
3 總結
本文主要針對如何降低多設備訓練神經語言模型中的時間消耗進行實驗,對比不同梯度更新策略的加速效果。
?加速效果: 使用All-Reduce的梯度收集策略在循環神經語言模型上可獲得25%左右的加速效果,同時隨著設備數量的增加,加速效果更加顯著;使用基于采樣的梯度更新方法可達到約41%的加速。
?數據并行適用性: 使用多設備訓練神經網絡在不同模型下速度變化趨勢稍有不同。實驗發現對于大量數據傳輸占主導的網絡模型,多設備訓練反而會降低整體運行速度。在這種情況下即使使用了All-Reduce等的加速方法也很難獲得與單設備可比的運行速度。而對于數據傳輸量偏小的模型,在實際使用中比較適合在多設備上并行訓練。
?硬件連接方式對速度的影響: 實驗中發現,設備之間不同的硬件連接方式會對傳輸速度產生影響。針對該特性,我們在未來工作中考慮將采樣算法與All-Reduce進行結合,對于傳輸較慢的設備在采樣中給予相對較低的采樣率,實現能者多勞,不讓某些設備的傳輸速度拖慢整體。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中國特種設備安全(2022年6期)2022-09-20 02:52:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年11期)2018-08-04 03:26:08
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
