基于DQN的開放域多輪對話策略學習
2018-08-17 08:39:06宋皓宇張偉男
中文信息學報 2018年7期
宋皓宇,張偉男,劉 挺
(哈爾濱工業大學 社會計算與信息檢索研究中心,黑龍江 哈爾濱 150001)
0 引言
隨著社會媒體的發展,微博和Twitter等社交媒體上積累了大量的短文本,這些短文本可以近似作為對話語料來訓練基于深度神經網絡的對話生成模型[1]。基于深度神經網絡的對話生成模型能夠有效對輸入產生回復,展現出巨大的研究潛力[2-4]。這些模型中得到廣泛應用的是seq2seq模型。seq2seq模型基于編碼器—解碼器結構,應用于對話生成任務時,輸入通過編碼器編碼為一個特征向量,再由解碼器根據特征向量解碼得到回復。這一模型基于最大似然估計(maximum likelihood estimate,MLE)最大化回復的生成概率[5]。Shang L等將該模型應用于單輪對話生成,取得了很好的效果[6]。
實際的對話過程在大多數情況下都是多輪交互的過程,而非一問一答的單輪對話。seq2seq模型基于MLE的生成方式難以有效建模多輪對話的過程[7]。現有的關于多輪對話相關工作大多數基于填槽(slot filling)的方式進行[8-10],這類工作的目標是完成特定任務;而在開放域多輪對話最近的研究工作中,端到端的方式逐漸成為主流: 基于大量的多輪對話訓練數據,通過考慮最近的對話歷史信息,使得生成的回復能夠照應上文信息[11-13]。
盡管相關工作強調了歷史對話信息,但是考慮對話歷史而得到的回復并不一定有利于對話過程的持續進行。此外,對話生成任務中以seq2seq模型為代表的端到端生成方式基于MLE,每次得到的回復都是生成概率最大的句子。這就導致了那些經常出現但是沒有實際意義的萬能回復,比如中文里的“哈哈哈哈”以及英文里的“I don’t know”,非常容易被選中[2-3,14]。一旦出現輸入與回復相同的情況,那么模擬的多輪對話就會陷入死循環;有很高生成概率的萬能回復則很可能把模擬的多輪對話帶入這樣的死循環中。表1展示了這樣兩類問題。
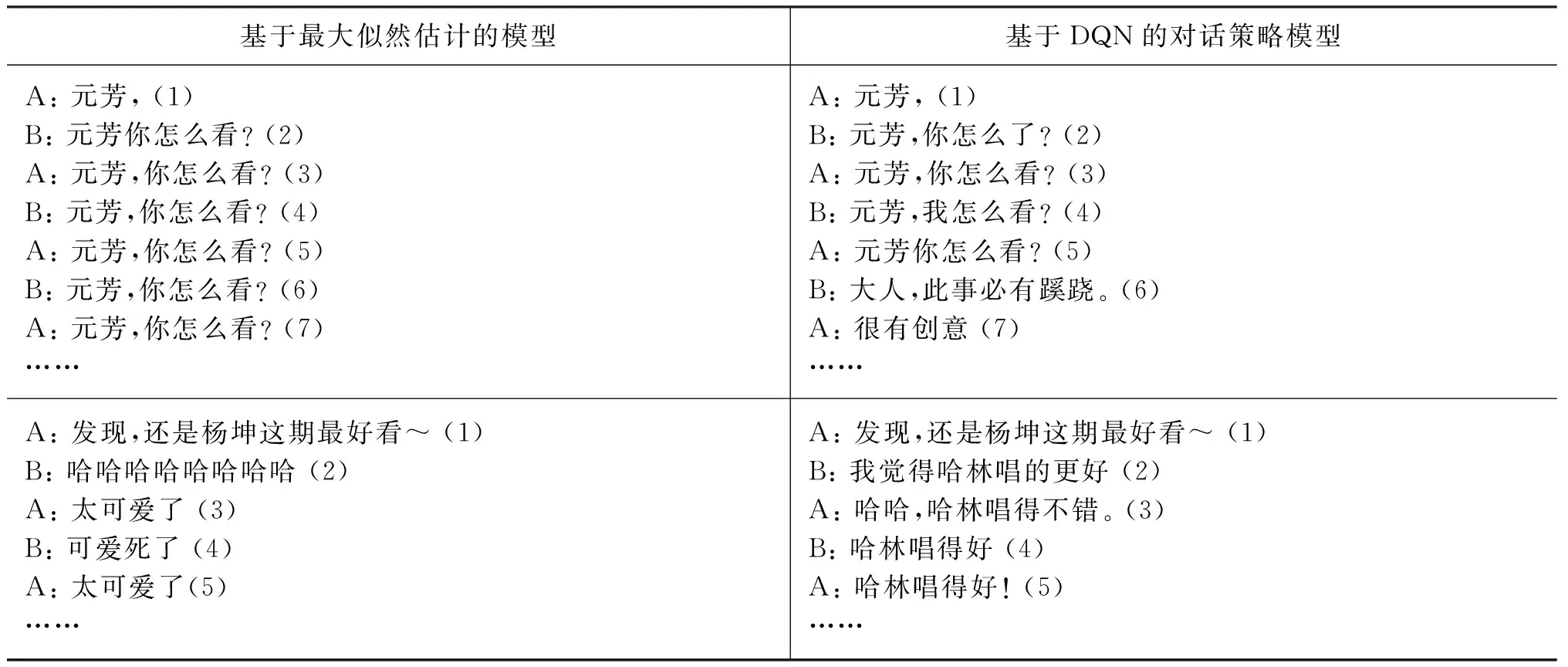
表1 中文微博數據集上不同方法的多輪模擬對話結果對比
開放域多輪對話的一個重要目標就是盡可能聊得更久。開放域多輪對話中每一輪回復的選擇,不僅需要考慮是否能夠有效回復當前輸入,更需要考慮是否有利于對話過程的持續進行。更好地建模多輪對話過程,引導現有的seq2seq模型有效進行多輪多話,需要從多輪對話過程的整體角度引入一種對話策略。
本文借助強化學習算法的全局視角,在開放域的多輪對話過程中引入了深度強化學習方法DQN[15]來進行對話策略學習,通過這個對話策略指導多輪對話過程中每一輪的回復選擇。與MLE方式不同,強化學習的總體目標是最大化未來的累積獎勵[16]。DQN方法估計的是每一個回復句子能夠為給定的輸入帶來多少的未來獎勵,對話的策略就是選擇能夠帶來最大未來獎勵的那個句子。如前所述,生成概率較低的句子并不意味著句子的質量差,很有可能只是因為這些句子出現頻率沒有萬能回復那么高,相反,這些句子可能引入新的信息并更加有利于多輪對話的持續進行。因此,通過DQN方法進行對話策略學習能夠有效挖掘seq2seq模型進行多輪對話的潛力。如表1所示,基于同樣的輸入,右側根據DQN方法得到的對話策略進行的多輪對話質量明顯更高。
本文的創新之處在于,將DQN應用于對話策略的學習過程中,使用獨立的深度神經網絡對每一句候選回復的未來收益進行評估,從而得到一個有利于多輪對話持續進行的對話策略。通過強化學習方法,DQN得到的深度神經網絡就代表了多輪對話的策略,使得對話策略的學習獨立于回復生成模型本身,在已有的回復生成模型不做任何改變的前提下,就能夠通過DQN得到對話策略。實驗結果表明,通過DQN方法得到的多輪對話策略有效提高了多輪對話的多樣性、平均輪數和對話質量。
得到一個更好的多輪對話策略對于人機對話系統有著很多積極的意義。首先,人機對話系統的一種常見的訓練方式就是通過用戶模擬器(user simulator)來不斷的進行模擬對話,生成式的用戶模擬器需要能夠有效地模擬多輪對話,因此更好的多輪對話策略能夠優化用戶模擬器的回復效果,有利于訓練出質量更高的對話模型。其次,在開放域對話系統中引入多輪對話策略能夠有效提高回復整體上的多樣性,使得回復內容更加豐富,并且能夠引入更多的信息,將其應用到開放域的閑聊機器人中,對于提升用戶的使用體驗也有著積極作用。
1 相關工作
隨著Sutskever等[5]提出序列到序列的學習方法,seq2seq模型在最近幾年開始廣泛應用于對話生成研究領域[2,4,6]。深度強化學習是利用深度神經網絡對強化學習方法做出的改進。Mnih等[15]首先使用深度強化學習算法DQN在Atari游戲上取得突破性成功,其核心思想在于引入了經驗回放(experience replay)機制。隨后,Hasselt等[17],Schaul等[18],Wang等[19]分別從不同的角度對DQN算法進行了改進。
與此同時,在對話系統的相關任務中引入深度強化學習方法也獲得了越來越多研究者的關注。Guo H將DQN算法應用到了seq2seq模型每個詞語的解碼過程中,從詞語解碼的級別上對模型做出了改進[20]。Li等[7]使用了深度強化學習的策略梯度(policy gradient)算法,在seq2seq的訓練過程中利用深度強化學習算法提供的梯度改變模型原有的訓練進程,從而達到優化模型的目的。Su等[10]結合強化學習和在線學習(online learning)的方式,通過與用戶的實時交互,提高了任務型系統對話的性能。
開放域多輪對話方面,Lowe等[11]利用ubuntu數據集進行了多輪對話的嘗試,雖然利用了多輪對話數據集的優勢,但是沒有建模多輪對話的上下文信息。Pascual等[12]考慮到了歷史對話信息對于生成當前回復的影響,提出了一種能夠感知歷史信息的神經網絡回復生成方法。Serban等[13]在電影臺詞數據集上進行實驗,同樣考慮了上文對于當前回復生成的影響。開放域多輪對話系統的一個重要目標就是盡可能地使對話過程持續下去,然而這些工作都沒有從如何回復才更有利于對話過程繼續的角度考慮問題。Li等[7]針對這一問題,利用深度強化學習策略梯度的方法建模了多輪對話過程,改進了seq2seq模型的訓練過程。
在深度神經網絡的相關優化方面,Graves等[21]在神經網絡解碼過程中使用了束搜索(beam search)方法,用于平衡解碼過程中的搜索質量與搜索開銷;Bahdanau等[22]提出了注意力模型,在深度神經網絡中引入了一種動態賦權的機制;Srivastava等[23]提出了dropout機制,用于防止深度神經網絡訓練時的過擬合。
與本文比較接近的工作是Li等[7],本文關于多輪對話過程的強化學習建模方式以及實驗結果評價指標也參考自這篇論文。雖然都是使用深度強化學習方法,但是本文與Li等[7]的區別也是顯著的: 首先,本文的目標是學習多輪對話的策略,而文獻[7]的目標是進行對話生成。本文工作的核心是進行多輪對話的策略學習,使用的強化學習方法DQN沒有涉及回復生成模型的訓練過程,而是從已經訓練好的回復生成模型中選擇出最有利于多輪對話的回復;而文獻[7]使用的是策略梯度方法,是在seq2seq模型的基礎上改變回傳前的梯度計算方式,從而引導回復生成模型的訓練方向。其次,基于Q-learning的強化學習算法DQN和基于策略梯度的強化學習算法在原理和應用方式上完全不同,細節此處不再贅述。此外,本文使用了獨立的深度神經網絡來對回復的收益進行估計,最終學習得到的深度神經網絡就代表了多輪對話的策略。
本文實驗的總體結構如圖1所示,從圖中可以看出,DQN的學習過程是獨立于對話生成模型的,因此通過DQN進行對話策略的學習并不會改變基礎的回復生成模型;也正是因為本文使用了獨立的深度網絡,所以對話策略的學習過程并不依賴于回復生成模型的梯度,即使應用場景改變,回復生成模型自身無法提供梯度,也不會影響本文對話策略學習方法的使用。

圖1 本文實驗的整體結構
2 DQN用于對話策略學習
DQN作為一種深度強化學習算法,基本結構仍然是“環境—代理”(environment-agent)框架: 代理根據當前狀態s選擇一個動作a作用于環境,然后環境的狀態s發生改變并返回相應的獎勵r,代理的目標是最大化未來能夠獲得的所有獎勵之和,由此調整動作并構成一個循環過程。關于強化學習模型的更多細節請參考文獻[16]。
本文的目標是得到一個有利于多輪對話持續進行的對話策略。這個總體目標分解到每一輪的對話中可以等價為每一輪都選擇出能夠為整個對話過程帶來最大收益的句子。參考文獻[7],這里衡量回復帶來的收益可以從是否產生萬能回復、是否引入新的信息、是否與歷史信息一致等方面來衡量。基于這些設定,就可以將對話策略的學習過程建模為典型的強化學習過程。
DQN方法的核心在于一個深度價值網絡Q,網絡Q按照相應的算法迭代更新,目標是估計每個狀態s下選擇動作a的價值q(s,a)。這個價值q代表了當前狀態s下選擇動作a能夠帶來的未來折扣獎勵之和。更多細節和原理請參考強化學習有關Q-learning的部分。
在多輪對話過程中,把當前的輸入語句記為x,輸入x通過回復生成模型以及束搜索得到了若干候選回復y0,y1,...,yn。基于自然語言的句子是變長和離散的,無法作為狀態s參與到網絡Q的計算中,因此通過一個自編碼器(autoencoder)將輸入映射為固定維度的特征向量c,使用這個特征向量表達當前狀態s。同樣,得到的回復也是句子,無法直接參與計算。但是回復與輸入不同的地方在于,一旦回復生成模型和輸入給定,那么這些候選項及其順序也是確定的: 本文中候選項的順序是按照生成概率從高到低的順序排列的。因此,表示回復并不需要對候選回復進行編碼,只需要保留相應的序號即可。那么,一個候選回復yi就有一個與之對應的動作ai,這個動作表示了這一輪選擇yi作為對輸入x的回復。每一輪的對話中,通過深度價值網絡Q對候選回復yi進行評估,得到q(si,aj)。對話的策略就是選擇q值最大的動作所對應的回復。
2.1 基礎的回復生成模型
本文參考文獻[5]中的seq2seq模型,訓練了對話生成模型。在訓練過程中加入了Bahdanau提出的注意力機制和Srivastava提出的dropout機制。
seq2seq的解碼過程使用了束搜索的方法。束搜索在每一步中按照啟發式規則保留最優的若干候選項,其他較差的結點則被剪掉。在對話系統中,由于對話過程的靈活性和多樣性,回復生成的搜索過程并沒有一個確定的“最優解”。因此,在回復生成的解碼過程中應用束搜索方法,對于得到更加多樣的回復是有幫助的。
2.2 多輪對話模擬
所謂模擬對話,就是基于回復生成模型,通過兩個代理的彼此對話來模擬多輪交互的過程。兩個代理進行模擬對話的過程如下: 一開始,從測試集中隨機找到一句話輸入給第一個代理,這個代理通過編碼器網絡把這個輸入編碼成一個隱層向量,然后通過解碼器來生成回復。之后,第二個代理把前一個代理輸出的回復同對話歷史拼接,重新通過編碼器網絡編碼得到一個隱層向量,更新對話的狀態,然后通過解碼器網絡生成回復,并回傳給第一個代理。這個過程不斷地重復,直到達到最大的模擬對話輪數。具體過程如圖2所示。
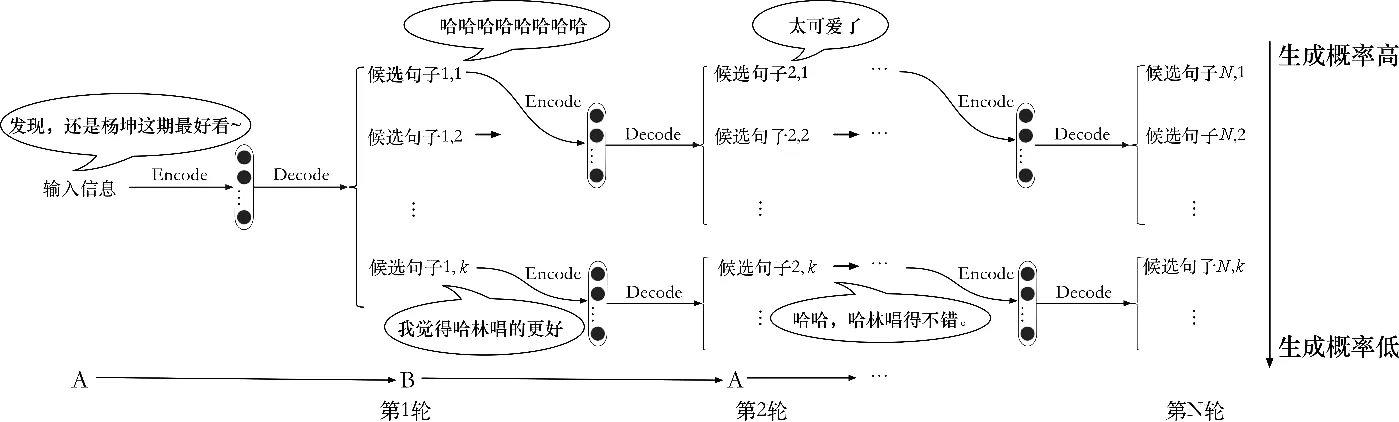
圖2 模擬多輪對話過程
2.3 自編碼器
自編碼器(autoencoder)是一類無監督的神經網絡學習方法,其最大的特點是輸入值和目標值相等。自編碼器的目標是學習一種類似恒等映射的函數,如式(1)所示。
φw,b(x)≈x
(1)
即輸入數據到本身的一種映射函數。當自編碼器學習得到這樣一種恒等映射或者近似恒等映射的關系時,神經網絡的隱層實際上就包含了數據的一種編碼信息。
自編碼器通常由編碼器和解碼器兩部分組成。形式化地,編碼器和解碼器的作用可以定義為兩個函數φ和ψ,那么:
則自編碼器的學習目標如式(4)所示。
φ,ψ=argminφ,ψ‖X-ψ(φ(X))‖2
(4)
其中,式(2)和式(3)中的θ就是自編碼器得到的數據特征表示。
用于對話表示學習的自編碼器需要處理變長的句子,并且由于句子數量巨大,所以需要學習的映射關系φ和ψ都會非常復雜,因此本文用到的自編碼器的編碼器和解碼器都由循環神經網絡構成。由于自編碼器的學習過程是無監督的,所以自編碼器在任意語料上都能夠學習得到該語料中句子的特征表示。
自編碼器的輸入是已經分詞的句子,每個詞由其詞向量表示,由循環神經網絡依次讀入;輸入句子經過編碼器的編碼,得到一個中間表示c,這個表示再送入解碼器中,解碼出預測值;網絡學習的目標由式(4)定義,網絡的目標值是和輸入句子完全相同的句子,目標值和預測值之間的誤差就是網絡參數調整的依據。
句子的自編碼器雖然只能做到近似復原輸入,但是這并不影響中間特征在強化學習模型中的使用。因為這些特征向量只需要按照同樣的規則得到,處于同一個向量空間就可以滿足需要。
2.4 DQN模型訓練
先定義獎勵函數。獎勵函數的作用是引導對話向輪數更多、信息更豐富、萬能回復更少的方向進行。首先定義一個表示,如式(5)所示。
(5)
式(5)表達的含義是對于句子s2,在給定的seq2seq模型下生成句子s1的對數概率,并且該對數概率受到s1中詞數的Ns1的約束。參考文獻[7],根據多輪對話的總體目標共定義三個獎勵函數:
對于定義的萬能回復的集合S,懲罰動作a可能導致生成的萬能回復,如式(6)所示。
(6)
對于連續的兩個對話狀態hi和hi+1,懲罰對話狀態過于接近,獎勵對話狀態存在較大差別以引入新的信息,如式(7)所示。
r2=-cos(hi,hi+1)
(7)
對于連續的多輪對話pi、qi和a,獎勵使得對話前后連貫的動作a,懲罰使對話不連貫的動作a,如式(8)所示。
r3=logprob(a|pi,qi)+logprob(qi|a)
(8)
最終的獎勵值式(9)所示。
r=0.45r1+0.2r2+0.35r3
(9)
三個系數在實驗過程中調整得到。
DQN中深度神經網絡的參數更新通過對式(10)進行隨機梯度下降來完成。其中sj表示狀態,aj表示動作,Q表示通過以θ為參數的深度價值網絡對狀態—動作對進行估值,如式(10)所示。
Loss=(yj-Q(sj,aj;θ))2
(10)
其中,價值的估計通過式(11)來完成,公式中的rj表示獎勵:
(11)
本文DQN算法參考文獻[15]的算法實現,更多實現細節請參考原文。
3 實驗
3.1 訓練數據及其表示
本文的實驗在中文微博語料上進行。該語料來源于新浪微博,每一對對話數據分別來自微博的正文和這條微博下面的評論,這樣一組博文—評論對就近似構成了一組對話對。該數據集總共有約110萬組這樣的對話對,語言質量較高,同時該語料也是文獻[6]所使用的數據集。本文通過word embedding的方式將每一個詞語都轉化為一個固定維度的向量,實驗中取300維,并通過所有詞語的向量共同表示原始的句子。使用的訓練詞向量的工具包是Google開源的Word2Vec,具有配置簡單、訓練高效等優點。
3.2 評價指標
對于多輪對話的實驗結果,本文參考Li等[7]的方法,使用以下兩個客觀指標進行評價。
(1) 平均對話輪數。對話輪數是指從輸入到對話結束總共持續的對話輪數。當對話過程出現了類似“哈哈哈”這類的事先定義的萬能回復或者對話進入一個死循環當中,那么就認為對話過程已經結束。
(2) 多樣性。多樣性通過統計模擬對話過程中出現的不重復的一元文法(unigram)和二元文法(bigram)所占的比例來衡量。unigram和bigram是語言模型中的概念,這一指標能夠表征總體生成結果的語言豐富程度。因為多輪對話并不存在一個標準答案,所以BLEU等傳統方法不適用于該任務的評價。同時,進行主觀評價是對話系統中常用的方式。本文還進行了主觀的對比評價: 給定相同的輸入,本文的DQN模型和基礎模型獨立進行單輪回復生成以及進行模擬對話,然后由與實驗無關的評價者主觀對比二者的質量,結果分為DQN更好、DQN更差和平局三種情況。評價者不知道結果所對應的方法,只是給出二者對比的一種主觀評價。對于單輪對話,總共收到400組的對比打分;對于多輪對話,總共收到600組對比打分。
3.3 回復生成及對話模擬
中文微博語料的單輪回復生成結果如表2所示。左側是從測試集中隨機抽取的輸入,右側是對應于輸入產生的回復,每一行組成一個輸入—回復對。

表2 單輪回復生成結果
可以看到,就單輪回復的效果而言,seq2seq模型能生成質量較高的回復語句。
中文模擬對話結果如表3所示。表中的一列為一組模擬對話的結果,第一句輸入從測試集隨機抽取,其余句子都根據上一句話生成得到。

表3 中文模擬對話的結果
可以看到,seq2seq模型和預期的結果一樣,無法有效進行多輪對話。模擬對話很快就陷入了死循環中,并且容易產生萬能回復。
從測試集句子中隨機抽取5 000條進行模擬對話,客觀指標評價結果如表4所示。可以看出,平均對話輪數比較短,說明基礎的seq2seq模型難以有效進行多輪對話。

表4 seq2seq模型模擬對話結果評價
3.4 自編碼器
就自編碼器而言,訓練的目標是輸出與輸入一致,或者輸出盡量接近輸入。我們從測試數據中隨機抽取2 000條句子送入自編碼器得到輸出,然后通過計算輸出對于輸入的F值的方式來衡量句子映射到自身的效果。評價時逐句計算輸出對于輸入的召回詞數以及輸入和輸出各自的詞數,所有句子累加到一起得到總的召回值、預測值和標準答案詞數。實驗結果如表5所示。本文實驗中的自編碼器最終的F值為0.872,在很大程度上已經能夠將輸入句子映射為句子本身;此外,自編碼器從輸入得到輸出的映射關系并不會被使用,本文用到的是從編碼器傳遞到解碼器的中間特征向量,這個向量實際上是對于輸入信息的編碼。因此即使F值無法達到理想情況下的1.0,也不會影響中間特征向量作為一種編碼被使用。

表5 自編碼器的F值
3.5 基于DQN的對話策略模型
本文使用DQN模型在測試集上隨機抽取了5 000條句子進行模擬對話。相應的客觀評價結果與基礎的seq2seq模型對比如表6所示。

表6 DQN和基礎模型客觀評價指標對比
可以看到,客觀指標上DQN模型顯著優于基礎模型,平均對話輪數更是增加了二輪。分析其原因,基礎模型對話容易進入死循環,并且傾向于生成經常出現的回復,而DQN模型通過獎勵函數的設置在一定程度上緩解了這些問題,所以DQN模型在對話輪數以及多樣性上的表現都要明顯比基礎模型好。
主觀評價的結果如表7所示。主觀評價指標方面,單輪回復的質量總體來說不相上下,DQN略占優勢,平局的情況占了接近20%;多輪對話上DQN模型的優勢明顯,平局的比例也下降到了不到10%。可以看出,因為單輪對話基于相同的回復生成模型,所以總體上單輪回復質量比較接近;而在多輪對話上,DQN模型則明顯優于基礎模型。

表7 DQN和基礎模型對話質量人工對比評價/%
部分單輪對話和多輪對話的效果對比如表8、表9所示。
續表
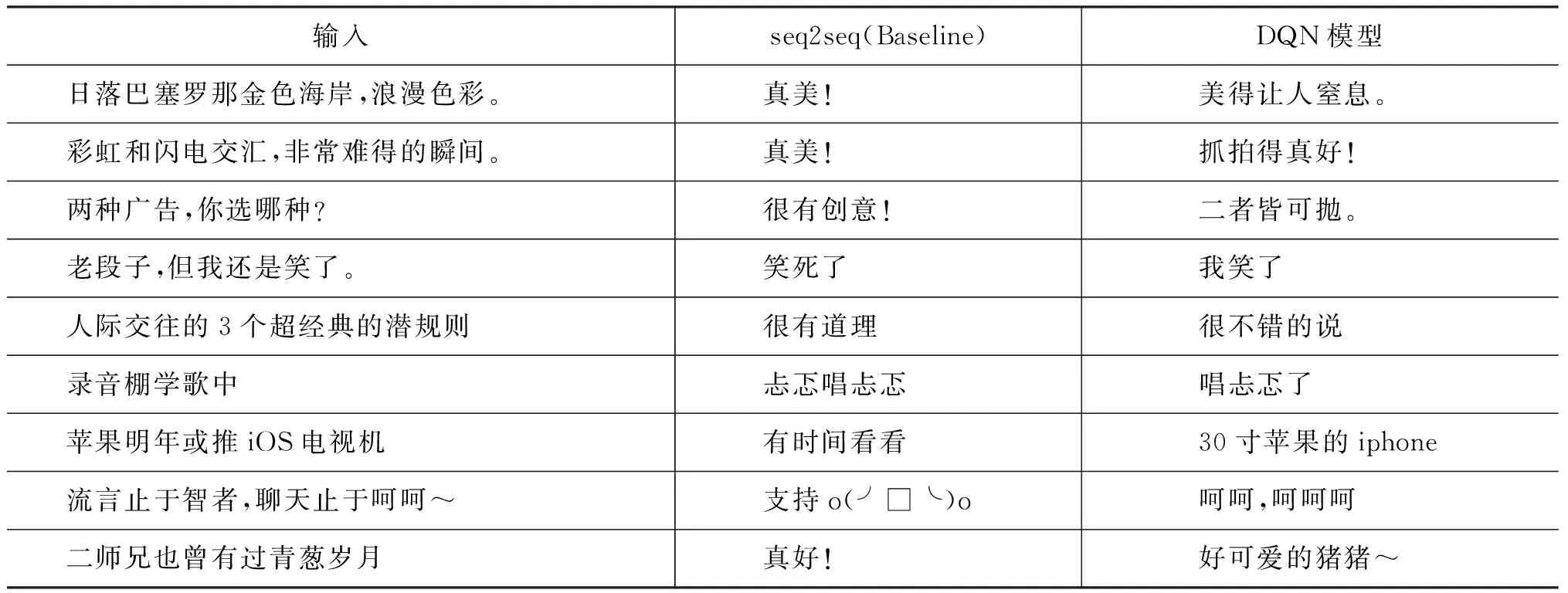
表8 DQN和基礎模型單輪對話對比
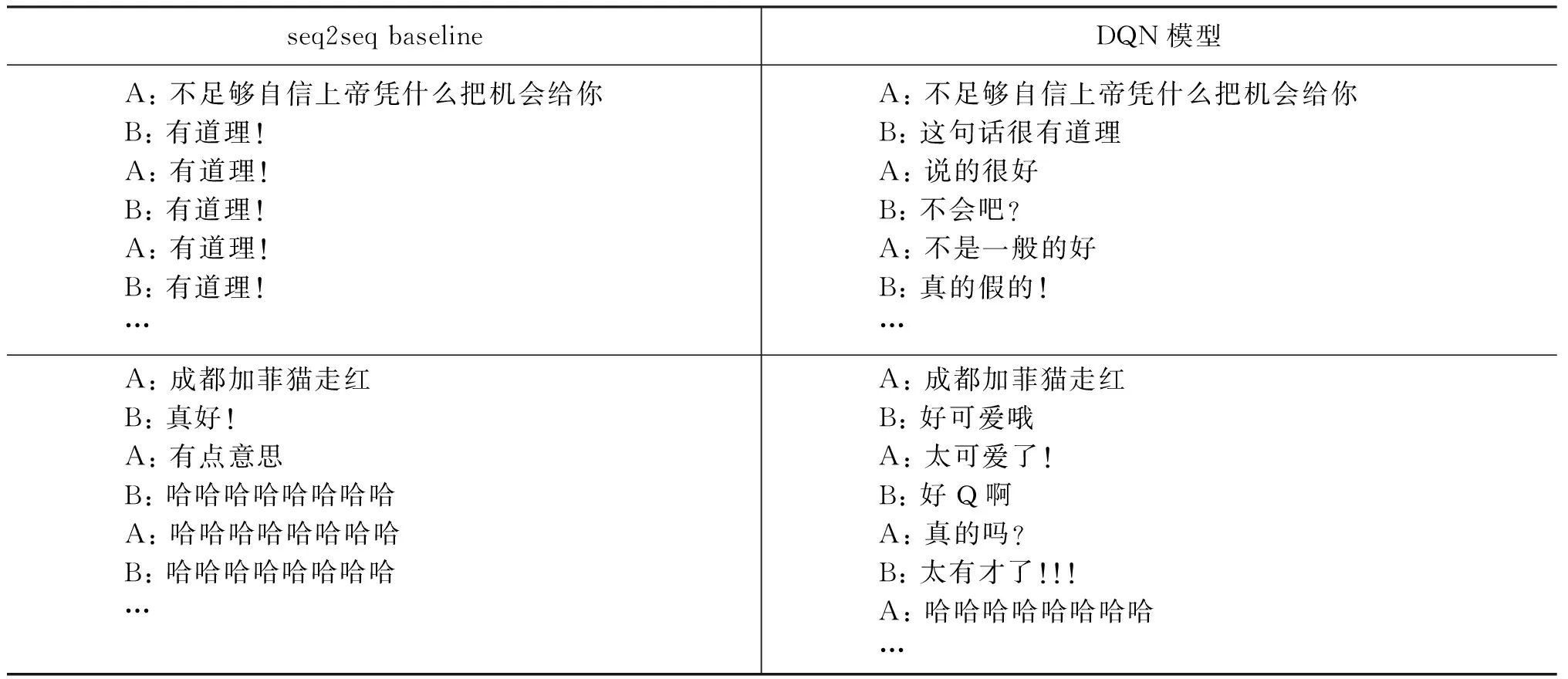
表9 DQN和基礎模型多輪對話對比
基礎模型在解碼過程中基于MLE,最終選擇的總是束搜索結果中生成概率最大那個句子。但是生成概率高并不意味著最有利于對話過程,如圖2所示,候選句子按照生成概率降序排列,因此基于MLE的選擇方式總是會選擇第一個候選句子。從圖中可以看到,生成概率較低的 “我覺得哈林唱得更好”作為回復明顯效果更好;但是因為其生成概率不如類似“哈哈哈”這種經常出現的“萬能回復”的生成概率高,所以導致這個更優的結果被MLE忽略。同時也可以看到,在多輪對話過程中,第一輪選擇的不同直接導致了后續回復生成的不同,從而進一步拉大多輪對話質量的差距。
與MLE的方式不同,本文的DQN模型每次選擇的是價值最大的動作,這一動作最有利于對話的持續進行,并能夠帶來更加豐富的信息。如果生成概率較低的候選回復在深度價值網絡中具有最大的價值,那么這個回復也會被選中,因此DQN模型更容易選擇出有利于對話過程持續進行的回復。
記錄DQN和MLE每次選擇的動作,畫出表1中多輪對話2的動作選擇,如圖3所示,能夠更加直觀地說明DQN相較于MLE如何選擇潛在的更優句子。動作1是選擇生成概率最高的句子,動作10是選擇生成概率最低的句子。值得注意的是,在第一輪中兩種方式選擇了不同的動作,那么在后續幾輪中,兩種方式各自進入了不同的狀態,所以同一個動作也會對應不同的回復。
從圖3可以明顯地看到,MLE每次選擇的動作都是1,因為這是生成概率最大的句子,所有動作構成的路徑是一條直線;而DQN方法選擇動作構成的路徑則更加“曲折”,每次選擇的是通過深度價值網絡估計得到的當前狀態下價值最大的動作,這個價值的最大則結合了獎勵函數的定義,使得這個動作有利于對話過程朝著輪數更多、包含的信息更豐富、更少的生成萬能回復的方向進行。圖4給出了隨機采樣的六組動作選擇路徑的對比。
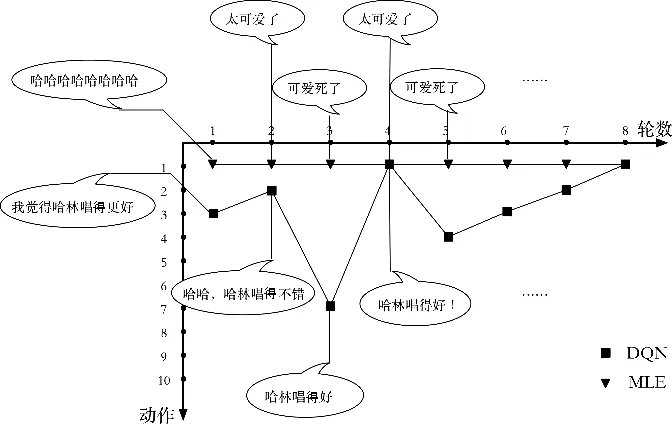
圖3 多輪對話過程中的動作選擇對比(表1多輪對話2)
圖4 隨機采樣的六組動作選擇對比
4 結論及后續工作
本文的主要研究內容針對開放的域多輪對話,關注之前工作中存在的沒有建模整個對話過程、多輪對話中容易產生大量萬能回復、很快陷入死循環等問題,引入了DQN方法進行對話策略學習。通過DQN對每一輪的候選回復的未來價值進行評估,選擇出了最有利于對話持續進行的句子作為回復,減少了萬能回復的產生,并增加了平均對話輪數。
實驗結果表明,在單輪回復質量幾乎持平的前提下,本文使用DQN方法得到的多輪對話策略能夠優化多輪對話的質量,最終各個評價指標上都明顯優于基礎方法: 平均對話輪數提高了二輪,主觀評價獲勝比例高出了接近45%。
本文的后續工作將著眼于將DQN用于seq2seq模型的訓練過程,使用深度價值網絡來估計訓練過程中的損失,使得訓練損失帶有更多的信息,從更細粒度上提高生成句子的質量。此外,如何更加全面地評價對話結果也是一個值得研究的問題。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學大世界(2018年1期)2018-04-12 05:39:14
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
