Spark GraphX上的SPARQL查詢處理算法*
2018-09-12 02:21:30鄒兆年
計算機與生活 2018年9期
邱 慧,鄒兆年
哈爾濱工業大學 計算機科學與技術學院,哈爾濱 150001
1 引言
資源描述框架(resource description framework,RDF)[1]是W3C提出的一種知識表示模型,用于描述和表達網絡資源的內容和對應的結構,是一種用來描述元數據的數據。圖1(a)是一個簡單的包含16個元組的RDF三元組,三元組包括主體、謂詞和客體。從圖的視角來看,RDF也是一個天然的圖模型。其中,三元組的主體和客體被當作圖的頂點,而謂詞被當作邊。圖1(b)是圖1(a)三元組對應的RDF圖模型表示。對于RDF數據,W3C提出了一種形式化的查詢語言SPARQL(simple protocol and RDF query language)[2]作為檢索和查詢的標準語言。SPARQL查詢也可以被看作是一個查詢圖。因此利用SPARQL在大規模的RDF數據中檢索信息可以看作是大型圖的子圖匹配問題。例如,圖2(a)是一個簡單的SPARQL查詢語言,圖2(b)是其所對應的查詢圖。查詢對應的意思是找出所有類型為出版物并且作者是助理教授2的圖書。近年來,隨著人們對語義網和知識庫日益增長的興趣和關注,RDF數據集的規模在不斷增大,現有的RDF數據集的規模已經超出了單機處理能力的限制。因此,利用分布式系統來儲存查詢RDF數據成為了一個熱門的研究課題。
現階段,由于分布式平臺例如Hadoop、Spark等強大的存儲和并行計算能力,學術界提出了大量基于分布式計算平臺的RDF檢索方案,例如文獻[3-8]等。Hadoop是Apache基金會開發的開源分布式存儲計算框架,其核心是HDFS和MapReduce。HDFS為海量數據提供了存儲功能,而MapReduce則提供了強大的分布式計算能力。除了其強大的存儲性能和并行計算能力,Hadoop另一個顯著的特點是其具有良好的可擴展性,可以擴展至幾千甚至上萬個節點。因此,對于數據量持續增長的問題具有很強的適用性。Hadoop的出現為海量數據的存儲和查詢提供了一種可行的方案。但是,基于Hadoop的檢索方案有一個共同的缺點:由于內存空間的限制,數據計算過程中產生的大量中間結果會被寫回到磁盤,從而會產生大量的I/O操作,嚴重影響查詢性能。
Apache Spark[9]是一個針對大規模數據處理而設計的通用內存計算框架,在它的基礎上有一系列的擴展,例如 SparkSQL、Spark Streaming、MLlib和GraphX[10]。Spark使用一個新的數據結構——彈性分布式數據集(resilient distributed datasets,RDD)來將計算結果存儲在內存中,從而減少I/O次數,有效克服了基于Hadoop的SPARQL查詢方式的缺點。GraphX是一個基于Spark的分布式并行圖計算引擎,由于利用SPARQL檢索RDF數據可以被看作一個大圖上的子圖匹配問題,因此GraphX可以很方便地被用來處理大型RDF數據集上的SPARQL查詢。

Fig.1 RDF triples and graph model圖1 RDF三元組及圖模型
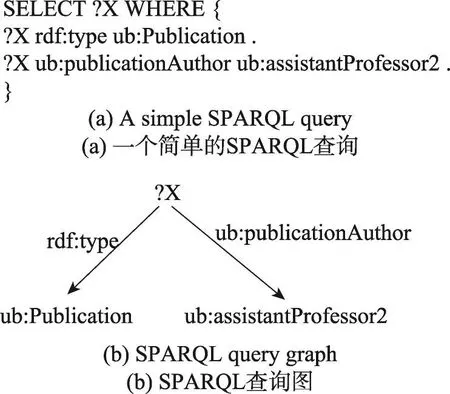
Fig.2 SPARQL query and SPARQL graph圖2 SPARQL查詢及其查詢圖
本文研究的主要內容是在Spark GraphX(為了方便,后文簡稱為GraphX)上處理SPARQL查詢。據所知,目前只有兩種基于GraphX的SPARQL查詢處理方案,S2X[3]和Spar(k)ql[4]。S2X的主要缺點是在第一輪迭代中執行查詢中所有的三元組模式,從而產生大量不必要的中間結果,大量消息需要在不同節點之間傳輸,嚴重影響查詢效率。而Spar(k)ql的主要缺點是每次只能處理SPARQL查詢中的一個三元組模式,從而沒有完全發揮GraphX分布式圖計算的威力。
本文提出了一種新的基于GraphX的SPARQL查詢處理方案SQX。本文的主要工作如下:
(1)以屬性圖模式存儲RDF數據,原始RDF圖中的部分邊被轉化為數據屬性存儲在頂點內部,從而有效減少了RDF屬性圖中頂點和邊的數量。同時對于部分三元組模式的匹配可以在節點內部完成,有效降低了數據的傳輸代價。
(2)SQX對于給定的SPARQL查詢生成相應的查詢計劃,查詢計劃包括查詢樹、非樹邊和約束條件。查詢計劃首先對查詢樹進行匹配,然后利用非樹邊和約束條件進行篩選得到最終的結果。
(3)在查詢樹的匹配階段,SQX采用自底向上分層匹配的策略。相鄰頂點層之間的查詢邊將在一個超級步中被匹配,充分利用了GraphX的并行計算能力。
(4)做了大量的實驗來驗證SQX的查詢性能。實驗表明,SQX可以有效處理各種形狀的SPARQL查詢,并且具有良好的可擴展性。
2 相關工作
近年來,學術界在分布式平臺上針對RDF存儲查詢方面做了大量的研究工作。其中一種方式是將集中式的RDF查詢系統部署到分布式集群的所有節點上,在它們之間建立一個消息傳遞層,例如文獻[5,11-13]。它們的不同之處在于劃分策略,一些方法通過劃分RDF數據集,將數據存儲到不同的節點上,在每一個節點上做查詢,最終得到的結果為在每一個節點上得到結果的連接,例如文獻[13]。這種方法的缺點在于在數據劃分階段會產生大量的信息冗余。另外一些方法采用不同的劃分策略,它通過劃分查詢而不是劃分數據集來實現分布式查詢處理。通過劃分查詢而不是數據集可以有效減少中間結果的傳輸,通過對局部結果的連接操作得到最終的結果。這種方式的缺點在于每一臺機器需要存儲所有的數據集,例如DREAM(distributed RDF engine with adaptive query planner and minimal communication)[5]。
另一種類型的存儲查詢方案是基于分布式云平臺的RDF數據管理系統。最常用的分布式云計算平臺是Hadoop,學術界在此之上做了大量的工作,例如文獻[6-7,14-16]。基于Pig的PigSparql[7],將數據存儲在HDFS(hadoop distributed file system)中,使用Pig作為一個中間層,而不是直接使用MapReduce進行計算。基于Sch?tzle等人提出的Sempala[6],通過將SPARQL查詢分解成一系列Parquet上的SQL子查詢,對這些子查詢得到的結果進行連接形成最終結果。基于Hadoop方式的主要缺點是中間結果必須回寫到磁盤,從而產生大量的I/O代價,降低查詢性能。為了解決這個問題,近年來,基于Spark的RDF存儲查詢成為一個熱門的研究學術課題,產生了大量的研究成果,例如文獻[2,4,8,17]。Spark是一個通用內存分布式計算平臺,計算的中間結果被保存在內存中,從而可以有效降低I/O代價。S2RDF[8]是一個基于Spark的分布式RDF數據管理系統,使用了Spark的關系數據庫接口SparkSQL,通過垂直劃分的方式將結果存儲在Spark中。在查詢階段,將每一個三元組模式對應一個數據表,對結果進行連接得到最終結果。由于RDF可以被表示為圖模式,因此也可以使用分布式圖并行計算框架來實現SPARQL查詢。第一個工作是Goodman等人基于GraphLab實現的[18]。Spar(k)ql[4]的原理類似于文獻[18],基于GraphX實現。這兩種方式的缺點在于在每一個超級步中只能處理一個三元組模式。另外一個工作是S2X[3],這種方式的優點是將圖并行和數據并行結合到一系統中,但是缺點是會在第一輪迭代中產生大量的中間結果。
3 問題定義
定義1(RDF三元組)RDF三元組是一系列形如(s,p,o)的數據組合。其中s代表主體(subject),p代表屬性(property),o代表客體(object)。三元組的取值區間可以表示為(U?B)×(U?B)×(U?B?L),其中U代表URI,B代表空值,L代表文本信息。
例如,對于三元組(蘋果,種類,水果),蘋果代表主體,種類代表屬性,水果代表客體。三元組表示的意思是蘋果的種類是水果。
定義2(RDF圖模型)RDF圖模型可以用一個四元組(V,E,LV,LE)來表示。其中,V代表RDF數據圖中的頂點集,每個點代表RDF三元組中的主體或者客體;E是RDF圖模型中的所有邊的集合,每條邊代表RDF三元組中的屬性;LV是圖中所有的頂點標簽的集合;LE是圖中所有邊標簽的集合。通常,任意兩個頂點之間不存在雙向邊。
圖1(b)給出了一個對應圖1(a)中RDF三元組的圖表示。其中方框中的元素代表URI或者空值,雙引號中的元素代表文本屬性。
定義3(三元組模式)當一個三元組中的元素被變量取代時,該三元組被稱作一個三元組模式。一個三元組被稱作是三元組模式的匹配當且僅當對應位置元素相互匹配。其中,變量可以匹配上所有元素,常量只能匹配上同標簽元素。
定義4(SPARQL查詢)一個SPARQL查詢是一系列三元組模式的集合。SPARQL查詢圖是SPARQL查詢的圖模型表示。本文關注的主要是以select開頭的選擇性查詢。
定義5(SPARQL查詢匹配)給定一個RDF圖G和一個SPARQL查詢圖Q,M是G的子圖,M是Q的一個匹配當且僅當存在函數f:V(Q)→V(M)使得:
(1)對Q中的任意頂點v,如果v是一個變量,f(v)可以匹配任意值。如果v是一個常量,那么f(v)和v具有相同的URI或者文本屬性。
(2)對于Q中的任意邊(u,v),(f(u),f(v))是M中的邊,且邊上的標簽一致。
對于圖2(b)中的查詢圖和圖1(b)中的RDF圖,(ub:publication4,rdf:type,ub:Publication),(ub:publication4,ub:publication Author,ub:assistant Professor2)組成Q的一個匹配。
本文解決的問題可以形式化地表述為如下形式:給定一個RDF圖G和一個SPARQL查詢圖Q,找出Q在G中的所有匹配。
4 SPARQL查詢處理
本文提出了一種新的基于GraphX的SPARQL查詢處理方式,利用GraphX的并行計算的威力來加速SPARQL查詢。4.1節詳細介紹了SQX用到的數據模型;4.2節介紹了如何根據給定的SPARQL查詢圖生成相應的查詢計劃;4.3節介紹了查詢處理算法的具體細節。
4.1 數據模型
在本文方法中,RDF數據以屬性圖(property graph)的形式存儲在GraphX中。在RDF數據中,存在兩種類型的屬性,分別為數據屬性和對象屬性。其中數據屬性指的是連接實體和文本的屬性,而對象屬性代表連接兩個實體的屬性。例如在圖1(b),謂詞“ub:name”是一個數據屬性而謂詞“ub:publication Author”是一個對象屬性。在本文的模型中,將數據屬性存儲到節點的內部,而對象屬性被保留為邊。通過將數據屬性存儲到節點的內部,可以有效減少圖中頂點和邊的數量,從而有效減少圖的大小。對于每一個頂點,對應的頂點數據格式為(頂點ID,URI,數據屬性集)。特殊的,將對象屬性“rdf:type”當作數據屬性存儲在節點內部,這是SPARQL查詢中最常見的屬性,并且通常不會將該屬性作為查詢結果。通過將“rdf:type”存儲在節點的內部,可以有效減少屬性圖中邊的數量并且可以快速定位到相應類型的節點[18]。
圖3是圖1(b)中RDF圖的一個屬性圖表示,其中對象屬性被當作一條邊,而數據屬性被存儲在節點的內部。
4.2 查詢計劃生成
給定一個SPARQL查詢Q,首先為Q生成一個相應的查詢計劃。查詢計劃代表查詢圖中三元組模式的匹配順序。例如,對于圖4(a)中給出的查詢圖,圖4(b)給出了對應的查詢計劃。查詢計劃由以下三部分組成:
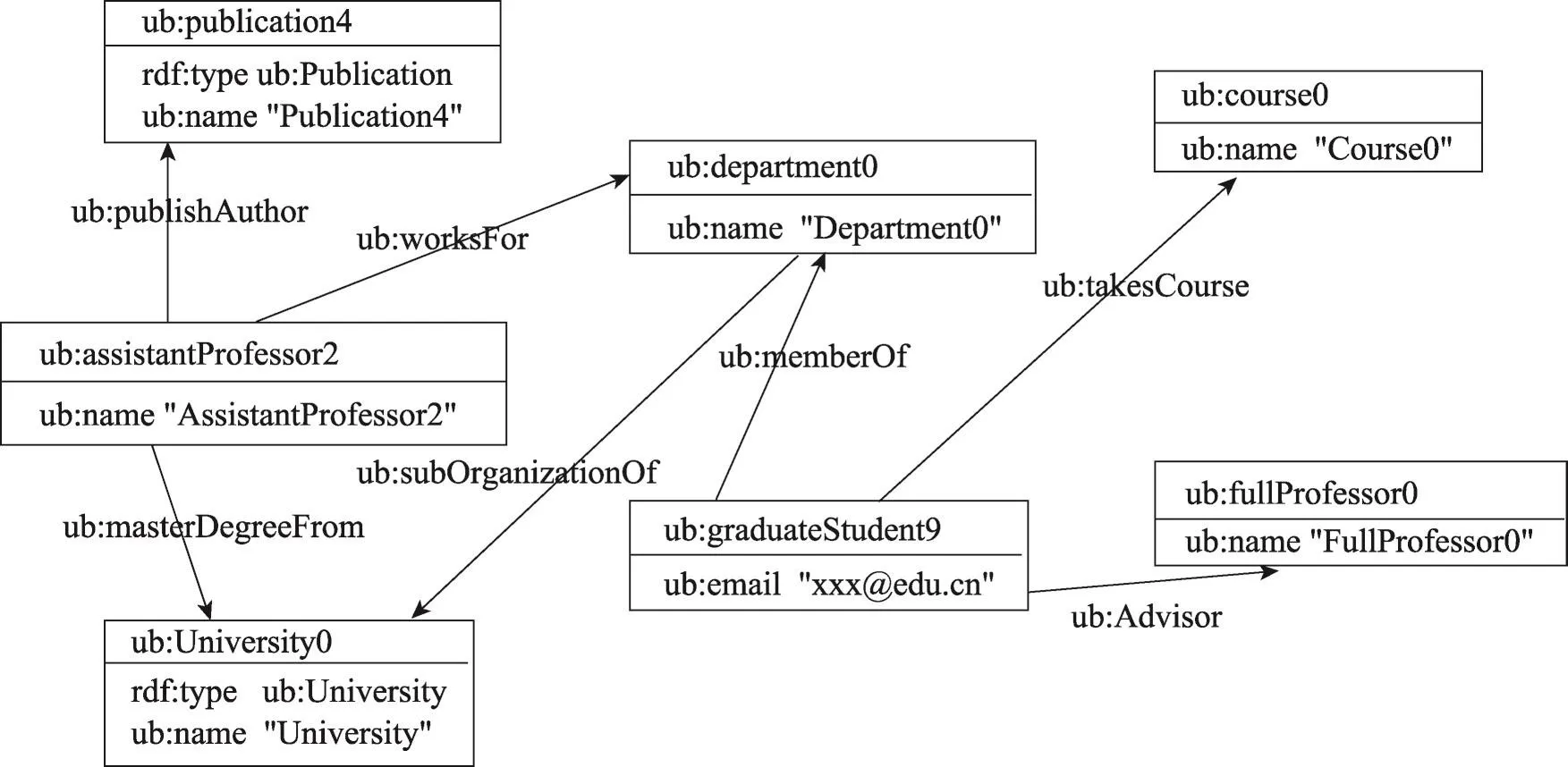
Fig.3 RDF property graph圖3 RDF屬性圖
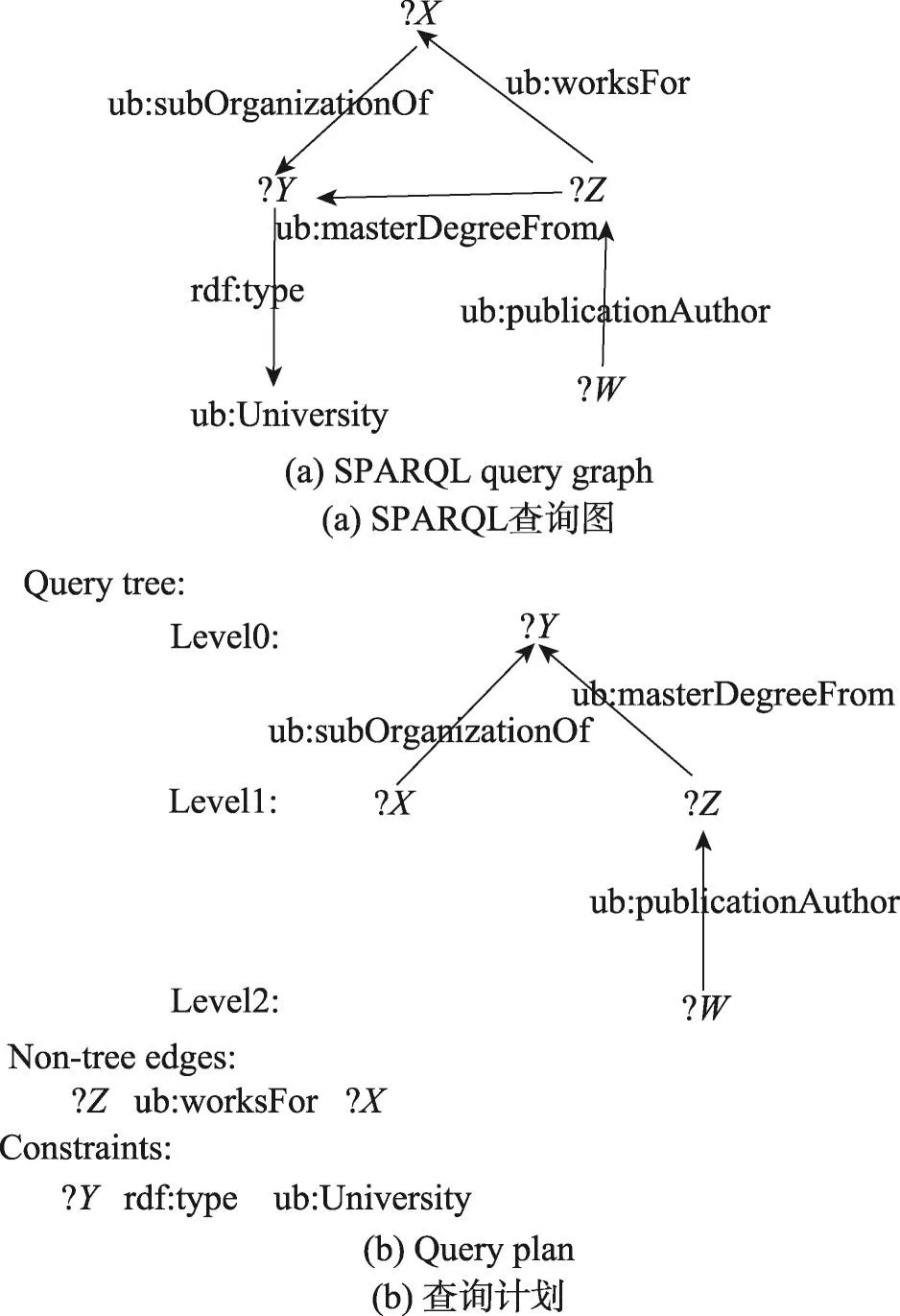
Fig.4 SPARQL query plan generation圖4 查詢計劃生成
(1)查詢樹。查詢樹是從給定的查詢圖中提取出的樹結構。在這個例子中,三元組模式(?X,ub:publicationAuthor,?Y),(?Z,ub:master Degree From,?Y),(?W,ub:publication Author,?Z)構成了相應的查詢樹。樹中的節點被分配到不同的層中,根節點所在的層為第0層,其他每一個節點的層數為該節點到根節點的距離。例如?Y的層數為0,?X的層數為1。相鄰頂點層之間的三元組模式將在一個超級步中被處理。
(2)非樹邊。非樹邊指那些在查詢圖中而不在查詢樹中的邊,用于迭代完成之后的結果過濾。在這個例子中,非樹邊為(?X,ub:works For,?Z)。
(3)約束條件。約束條件指的是查詢圖中的數據屬性。用于從非樹邊過濾完成后的結果中篩選出最終的結果,最終結果必須滿足所有約束條件。在這個例子中,三元組模式(?Y,rdf:type,ub:University)是一個約束條件,?Y匹配上的節點中滿足類型是大學的頂點才有可能成為最終的結果。
SPARQL查詢處理具體步驟的形式化表述如下:給定一個SPARQL查詢圖,生成相應的查詢計劃,根據生成的查詢計劃首先匹配查詢樹,在得到的匹配結果中,利用非樹邊和約束條件進行結果過濾。
算法1給出了查詢計劃的具體生成過程。給定一個SPARQL查詢,算法主要運行以下兩個步驟:
步驟1(約束提取)首先提取數據屬性并將它們轉換成約束(第1行)。特殊的,如果給出的SPARQL查詢中所有的三元組模式都是數據屬性,那么將沒有必要進行迭代,算法將不會發送任何消息,最終的結果將從所有滿足約束條件的頂點中得到(第6行)。
步驟2(查詢樹構建)提取完數據屬性之后,根據剩下的三元組模式構建查詢樹。一個查詢圖可能對應多棵生成樹,需要從這些樹中挑選最優的一棵。直觀的,這棵查詢樹需要擁有最低的查詢代價。因此提出了一種基于代價的查詢樹構建方案,為每一條邊分配一個權值,然后找到該查詢圖的最小生成樹MST(第3行)。邊上的權值是對應的謂詞在RDF數據庫中出現的頻率。這樣做的原因在于出現頻率低的邊將發送更少的消息,通過使用最小生成樹可以有效降低傳輸代價。不被最小生成樹所包含的邊被加入到非樹邊集合中。在得到最小生成樹之后,為了使每一個超級步中的數據傳輸相對均衡,采用使層與層之間權值邊權值方差最小的方案來挑選根節點。根節點的層數為零,其他節點的層數為該節點到根節點的距離。相鄰層之間的所有三元組模式將在一個超級步中完成。采用一個自底向上的匹配方式來完成匹配過程,因此定義查詢樹中邊的方向為從子節點指向其父節點。
為了方便后續查詢,對每一個三元組模式構建一個匹配模式(第10行)。匹配模式包含三部分:三元組模式、源頂點和所有發送消息到該頂點的頂點集合。源頂點的作用是指明三元組模式中消息傳遞的方向,消息從源頂點發送到三元組模式的另外一個頂點。而所有發送消息到該頂點的頂點集合用于計算最終結果是否涉及查詢圖中的所有頂點,集合元素少于查詢圖中頂點個數的結果將被過濾。匹配模式自頂向下構建,相鄰層之間的匹配模式將在一個超級步中被處理。
算法1查詢計劃生成
輸入:謂詞權值集合W,SPARQL查詢Q。
輸出:查詢計劃QP,迭代集合IL,非樹邊NonTreeEdges,約束條件Constraints。
1.將SPARQL查詢劃分為約束條件Constraints和對象屬性OP
2.IfOP不為空Then
3.找到使相鄰層之間邊權值方差最小的最小生成樹MST
4.非樹邊NonTreeEdges←OPMST中的三元組模式
5.Else
6.returnConstraints
7.End if
8.IL←?
9.ForMST中的每一個三元組模式do
10.自頂向下構建匹配模式
11.將相鄰層之間的匹配模式加入同一輪迭代iteration中
12.IL←IL?iteration
13.End for
14.returnQP(IL,NonTreeEdges,Constraints)
4.3 查詢處理
查詢處理主要分為兩部分,查詢樹匹配和結果過濾。在查詢樹匹配階段,采用自底向上分層匹配的方式。在執行匹配之前,首先需要將迭代進行反序。針對圖4(b)中給出的查詢樹,在第一個超級步中首先匹配第一層和第二層之間的三元組模式(?W,ub:publication Author,?Z),完成之后匹配第0層和第一層之間三元組模式(?Z,ub:master Degree From,?Y),(?X,ub:subOrganizationOf,?Y),最終所有節點的匹配結果都將被發送到根節點。將每一輪的匹配結果以消息的形式從源頂點發送到相應的目的頂點。對于查詢樹中的每一個三元組模式,如果該三元組模式對應的邊的方向和SPARQL查詢圖中邊的方向一致,那么對RDF屬性圖中匹配上的三元組,消息從主體發送到客體。反之,消息從客體發送到主體。在本文的方法中,不考慮謂詞為變量的情況。消息的格式包括三部分:目的頂點、謂詞和匹配結果表。匹配結果表的表頭為當前已經匹配完成的頂點,對應的值為相應的匹配結果。當匹配完一個三元組模式之后,在相應的表中添加一列,并添加相應的匹配結果。
以圖4(b)中的查詢和圖3中的RDF屬性圖為例。考慮查詢圖中第0層和第一層之間的三元組模式(?Z,ub:master Degree From,?Y),屬性圖中所有謂詞為“ub:master Degree From”的邊消息從主體發送到客體。消息的頭頂點為?Y,謂詞為“ub:master Degree-From”,由于?Z有一棵子樹,因此最終的?Y收到的消息結果是?Z頂點中存儲的匹配結果和這一輪中匹配上的結果的連接。
在一個超級步完成之后,RDF屬性圖中的頂點可能會收集到從它鄰居頂點發送來的多條信息。需要將這些消息進行合并,從而得到相應的中間結果存儲在目的頂點中。通過例子的方式來說明本文的合并過程。考慮圖5中一個頂點收到的3個消息M1、M2和M3。它們有著共同的目的頂點?X,消息的合并涉及到兩個操作,union和join。第一階段,因為消息M1和M2有相同的謂詞P1,所以通過union操作將它們合并成一個表M12。第二階段,因為消息M12和消息M3謂詞不同,所以通過join操作將它們合并,移除謂詞之后得到最終的合并結果,同時更新頂點的中間結果。具體的過程如圖5所示。通過定義消息的合并順序,算法可以在一個超級步中處理多個三元組模式并保證在合并消息的過程中不丟失結果。
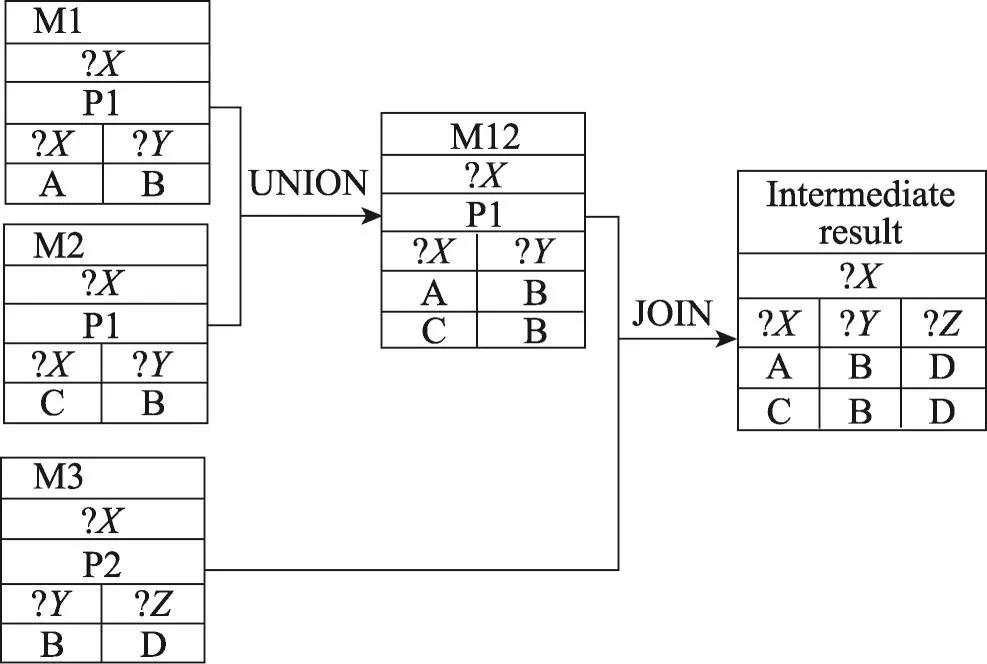
Fig.5 Illustration of message merging圖5 消息合并方案
查詢樹的匹配過程基于GraphX的Pregel模式實現,Pregel是一個圖并行計算接口,主要包括3個函數:msgCombiner、vertex Program 和 sendMsg。如果RDF屬性圖中的頂點是激活的,那么它將執行這一輪的超級步中所有這3個函數。在一輪超級步中,所有謂詞和三元組模式中謂詞相同的邊將在sendMsg階段將消息發送到它的對應的鄰居節點,在msg-Combiner階段,到達同一個頂點的具有相同謂詞的消息將通過union操作被合并。最后,在vertexProgram階段,具有不同謂詞的消息通過join操作被合并,并且將合并后的結果作為中間結果存儲到對應的數據頂點中。特殊的,如果想要查找數據屬性,例如對于SPARQL查詢(?X,ub:name,?Y),在查詢計劃的構建過程中,將它作為一條邊而不是約束條件。然而在RDF屬性圖中,對應的屬性被存儲在了節點內部,因此不能通過迭代的方式得到相應的結果。為了解決這種情況,在一個超級步開始之前,檢查每個三元組模式對應的謂詞是否是一個數據屬性謂詞,如果是,那么在頂點的內部將數據屬性合并到頂點的中間結果表中,同時在這一輪迭代中不發送任何消息到它的鄰居頂點。
給定一個查詢計劃和屬性圖,算法2給出了具體的匹配過程。
算法2查詢樹匹配
輸入:屬性圖G,迭代集合IL。
輸出:包含結果的屬性圖G。
1.reverseIL/*反轉迭代,自底向上匹配*/
2.Foriteration∈ILdo
3.Fortriplepattern∈iterationdo
4.If謂詞在頂點內部出現then
5. 將數據屬性合并到頂點的中間結果
6.Else if方向和SPARQL中一致then
7. 消息從主體發送到客體
8.Else
9. 消息從客體發送到主體
10. End if
11.End for
12.For?v∈V&&vis active do
13. 合并到達v的謂詞相同的消息
14.End for
15.For?v∈V&&vis active do
16.合并到達v的所有消息并更新中間結果
17.End for
18.End for
在找到所有的查詢樹的匹配之后,還需要通過非樹邊和約束條件來對結果進行過濾。對于查詢樹匹配上的每一個匹配結果M,任意一個屬于非樹邊集合中的三元組模式(u,p,v),檢查(f(u),f(v))是否是M中的一條邊,并且邊上的標簽為p。如果存在一條非樹邊使得M不滿足條件,那么該匹配結果不可能是最終的結果,該結果可以被去除。完成非樹邊過濾之后,檢查剩余的匹配是否滿足所有的約束條件,滿足所有約束條件的結果將被作為最終的匹配結果。通過這種“查詢樹匹配”+“結果過濾”的匹配方式,可以有效減少迭代輪數,大大提高查詢性能。
5 實驗與結果
在本章中,在數據集LUBM[19]上做了大量的實驗來驗證本文方法的查詢性能。
5.1 實驗設置
本文將在一個包含6個節點的集群上測試SQX的查詢性能。集群包含5個worker節點和1個master節點。每個節點包含一個1.90 GHz 6核Intel Xeon E5-2609v3 CPU,480 GB固態硬盤和12 GB內存,運行系統為CentOS7。在Spark1.6.1上實現本文的算法,并使用Standalone模式,RDF數據被存儲在HDFS中。將SQX和現有的兩種基于Spark GraphX的SPARQL查詢算法S2X[3]和Spar(k)ql[4]進行比較,實驗的數據集為Lehigh University Benchmark(LUBM)。LUBM是一個公開的關于大學的數據集,通過改變相應的參數可以產生不同大小的數據集。實驗使用的數據集對應的參數、文件個數和三元組數量如表1所示。
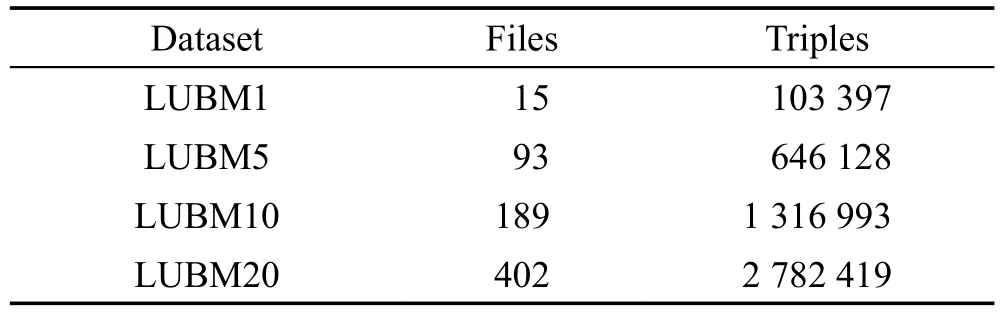
Table 1 Basic information of LUBM dataset表1LUBM數據集基本信息
5.2 查詢評估
在本節中,使用所有的6個節點,在LUBM20上比較SQX、S2X以及Spar(k)ql的查詢性能。使用LUBM提供的Benchmark中的查詢,將查詢分為簡單查詢和復雜查詢。簡單查詢通常為星形查詢,復雜查詢為鏈狀查詢和包含環的查詢。
圖6(a)顯示了針對簡單查詢 Q1、Q3、Q5、Q6、Q10的3種算法的查詢性能。所有的這些查詢都不包含環結構。可以看出,SQX的查詢性能比S2X快很多,因為減少了大量的中間結果,從而有效提高了查詢性能。SQX和Spar(k)ql查詢時間基本一致,因為這些查詢都只包含一個對象屬性,兩種方法都可以在一個超級步中完成,所以在查詢時間上SQX優勢并不明顯。
圖6(b)顯示了針對 3個復雜查詢 Q2、Q7、Q9 SQX和S2X兩種方法的查詢性能。其中,Q2和Q9為環狀查詢,Q7為鏈狀查詢。沒有將Spar(k)ql列入比較是因為Spar(k)ql不能在可接受的時間(8 h)內完成查詢。實驗結果表明,對于復雜查詢本文的方法查詢速度比S2X更快。
5.3 可擴展性評估
在這一節,使用3個查詢Q1、Q2、Q7來驗證SQX的可擴展性。通過改變數據集的大小來驗證方法在不同大小數據集上的查詢性能。使用LUBM1、LUBM5、LUBM10和LUBM20數據集,實驗結果如圖7所示。從實驗結果可以明顯看出,隨著數據集的增大,查詢響應時間呈線性遞增,并且對于不同查詢的增長速度不一樣。查詢2的查詢時間比查詢1和7的查詢時間增長得更為劇烈,原因在于查詢2為帶環查詢,并且包含3個三元組模式,產生的中間結果更多。

Fig.6 Query processing time of different queries圖6 不同查詢的處理時間

Fig.7 Query processing time of different data set sizes圖7 不同數據集大小查詢處理時間
通過改變集群節點個數,來驗證集群大小對查詢的影響,對應的查詢處理時間如圖8所示。可以看到,隨著節點數的增加,對于全部的3個查詢,查詢響應時間先減少后增加,原因在于隨著節點數的增加,集群計算能力增加,但是當節點增加到一定數量時,消息傳遞的代價增大,相應的查詢處理時間將變長。
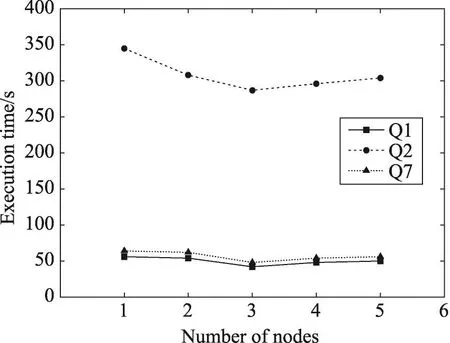
Fig.8 Query processing time of different number of cluster nodes圖8 不同節點數查詢處理時間
6 總結
本文提出了一種新的基于Spark GraphX的分布式RDF數據查詢方法SQX。從圖的視角來評估SPARQL查詢,RDF數據被視為一個屬性圖并且中間結果和最終的結果存儲在屬性圖節點的內部。提出了一個新的查詢計劃生成方案,將SPARQL查詢分解為查詢樹匹配和結果過濾兩個階段。同其他基于GraphX的方法相比,SQX可以在一個超級步中處理多個三元組模式,充分利用了GraphX的并行計算能力。實驗結果表明,本文的方法具有良好的查詢效率和可擴展性。
