面向患者的智能醫生框架研究
2018-09-12 02:22:20吳高巍任俊宏張似衡牛景昊張文生
計算機與生活 2018年9期
謝 剛,吳高巍,任俊宏,張似衡,牛景昊,張文生+
1.中國科學院 自動化研究所,北京 100080
2.貴州師范大學 大數據與計算機科學學院,貴陽 550001
1 引言
由于醫療資源緊缺和分級診療實施困難,“就醫難”、“就醫貴”成為當今中國醫患矛盾的焦點,如何借助互聯網和人工智能來有效解決遠程健康咨詢與智能問診成為國際人工智能應用的熱點。
智能醫生屬于醫療領域自動問答的范疇。目前,一部分研究者研究基于傳統檢索技術的問答系統,如 MdeQA[1]、AskHERMES[2]、MiPACQ[3]、Enquire-Me[4]、HealthQA[5],這類系統利用關鍵詞匹配技術對問題答案對進行檢索;一部分研究者研究基于語義技術的問答系統,如MEANS[6]、AskCuebee[7]、QASSD[8]、Watson[9]這類系統從語義層面理解用戶提出的問題,同時將數據以資源框架(resource description framework,RDF,https://baike.baidu.com/item/RDFS/9869002)三元組形式進行存儲,從而實現醫學知識的共享和利用。但在已有文獻里,對中文醫學領域的問答系統研究不多,尤其是針對患者的醫學領域問答系統則更少,因此迫切需要針對患者的中文醫學領域的問答系統。
由于患者缺乏相應的醫學知識,對問題和意圖的表述往往不清楚,同時在表述問題時口語化現象比較嚴重,因此怎樣正確識別患者的意圖和將口語化的臨床表型數據轉換成相應的醫學術語將是醫療問答系統的一大挑戰。本文在這樣的需求下提出一種“一問一答”智能醫生框架,該框架以自建的中文醫學知識圖譜和抓取的健康網站的問題答案對為基礎,對用戶的提問進行分析,根據問題分析出結果,對產生出來的候選答案采用多種問題評分策略和答案生成策略。實驗表明該框架是有效的。該項成果已成功應用于某公司的健康咨詢APP中。
本文組織結構如下:第2章介紹了智能醫生架構;第3章對實驗結果進行了描述;第4章總結全文。
2 智能醫生架構
本文的智能醫生架構如圖1所示。該系統主要包括問題分析、候選答案生成和答案生成等三大模塊。系統主要流程為:首先,系統對用戶輸入的問題進行分析;其次,根據問題分析的結果,生成候選答案;最后,將生成的答案返回給用戶。下面對各模塊進行相應的介紹。
2.1 知識庫
知識庫的構建是實現智能醫生的第一步。本文構建的知識庫包括詞庫、知識圖譜、問題答案庫和答案模板庫等4類。其中,詞庫用于分詞和詞性標注,知識圖譜用于生成語義三元組和答案生成,問題答案庫和答案模板庫也用于答案生成。
2.1.1 詞庫
本文用到的詞庫如下:
(1)通用詞庫:系統使用了上海林原信息科技有限公司的開源漢語言處理包(han language processing,HanLP,http://hanlp.linrunsoft.com/)中的通用詞庫。
(2)醫學詞庫:包括疾病詞庫、檢查詞庫、癥狀詞庫、手術詞庫、藥品詞庫、醫院詞庫、醫學單位詞庫。
(3)自定義詞庫:疑問詞詞庫、否定詞詞庫、同義詞庫。
2.1.2 醫學知識圖譜
本文構建的醫學知識圖譜部分如圖2所示。
可見,醫學知識圖譜是一張圖G,由模式圖、數據圖和邊構成,其形式化定義如下:
定義1(模式圖)[10]模式圖Gs=<Vs,Fs,Es>,其中:
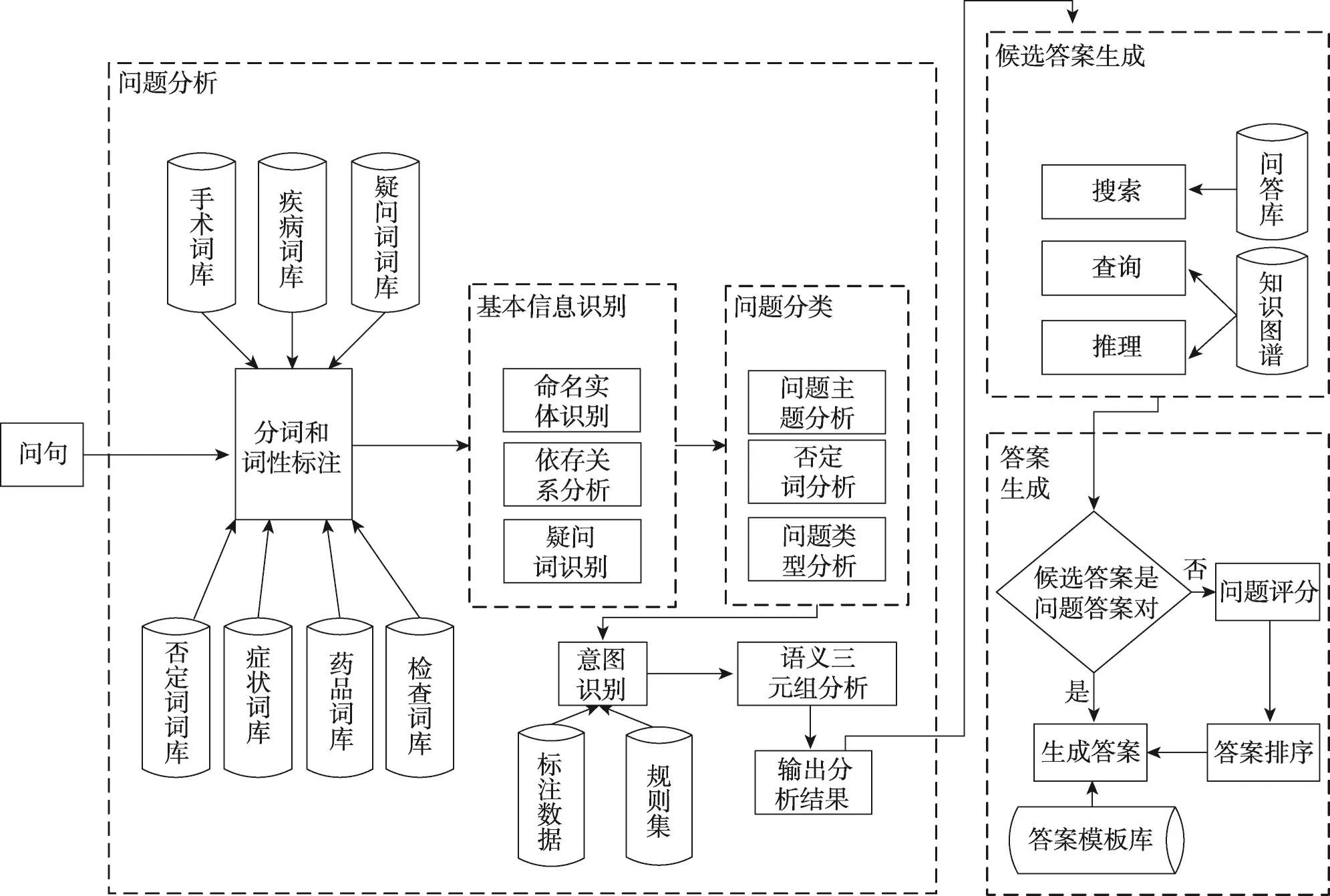
Fig.1 Intelligent doctor architecture圖1 智能醫生框架
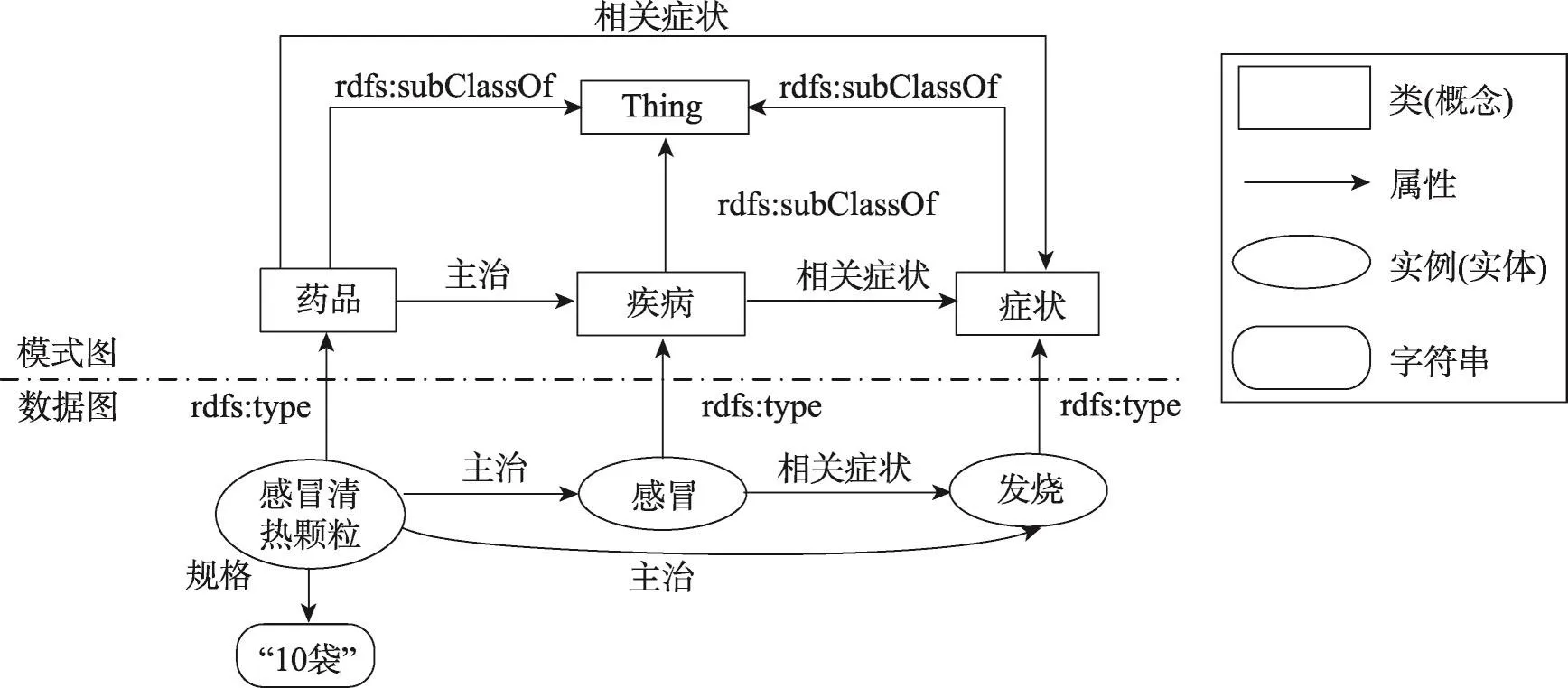
Fig.2 Example of knowledge graph圖2 知識圖譜示例
Vs表示模式圖的頂點集,每個頂點表示一個醫學概念,如藥品、疾病等。
Fs表示模式圖的邊標記集,每個標記表示一種概念之間語義關系,其元素為像rdfs:subClassOf、rdfs:equivalentClass這類來自語義網絡現有標準RDFS的屬性和像“主治”這類用戶自定義的屬性。
Es表示模式圖的邊集,即Es={<vi,vj,Fk>|vi,vj∈Vs,Fk∈Fs(i=1,2,…,n,j=1,2,…,m,k=1,2,…,h)},<vi,vj,Fk>表示結點vi與vj具有關系Fk。如<醫生,專家,rdf:subClassof>表示專家和醫生是子類關系。
定義2(數據圖)[10]數據圖Gd=<Vd,Fd,Ed>,其中:
Vd表示數據圖的頂點集,每個頂點要么表示一個概念的實例,如“感冒”為疾病的一個實例,要么表示屬性的值,如“10袋”為藥品規格這一屬性的值。
Fd表示數據圖的邊標記集,定義與Fs相同。
Ed表示數據圖的邊集,即Ed={<vi,vj,Fk>|vi,vj∈Vd,Fk∈Fd(i=1,2,…,n,j=1,2,…,m,k=1,2,…,h)},<vi,vj,Fk>表示一個結點vi的屬性Fk的值vj。例如<感冒,發燒,@相關癥狀”>表示“感冒”的相關癥狀為“發燒”。
定義3(知識圖譜)[10]知識圖譜G=<V,E>,其中:
V表示知識圖譜的頂點集,包括模式圖和數據圖的頂點,即V=Vs∪Vd。
E表示知識圖譜的邊集,包括模式圖和數據圖的邊及標記為rdf:type的邊,即E=Ed∪Es∪{<vi,vj,rdf:type > |vi∈Vs,vj∈Vdi(i=1,2,…,n,j=1,2,…,m)}。
在定義1~定義3和現有本體[11-12]的基礎上,本文首先利用protégé(https://protege.stanford.edu/)構建醫療領域知識圖譜的模式圖;其次,利用D2R(relational database to resource description framework,http://d2rq.org/d2r-server)將關系數據庫轉換成RDF三元組。目前已有1 126 214個三元組,構成知識圖譜的數據圖,并以RDF三元組存儲在fuseki(http://jena.apache.org/documentation/fuseki2/index.html)服務器中。
2.1.3 問答庫
本文的問題答案庫來源于智能問醫生、99健康網和名醫在線的問答數據,通過人工整理了60萬條,并以(編號,問題,答案)的形式存儲在數據庫管理系統中,其表結構如表1所示。

Table 1 Question answer table表1 問題答案表
2.1.4 模板庫
為了更自然地把答案展示給用戶,根據意圖類別和是非問題的類別利用可擴展標記語言(extensible markup language,XML)共制定了112個答案模板(answermodel,AM)。例如詢問概念定義的模板如下:
其中,<AM>和</AM>表示一個答案模板的開始和結束;<AMID>和</AMID>表示答案模板的編號;<parameters>和</parameters>表示答案模板需要的參數;<Answer_Model>和</Answer_Model>表示答案模板的內容;<EXAMPLE>和</EXAMPLE>表示該模板對應的問題實例。
2.2 問題分析
問題分析是整個智能醫生的第一步,其結果對后續處理過程有很大影響。問題分析的結果表示為八元組 <It,Qc,Nel,N,Ss,I,TL,P>。其中:It表示問題類型,類型與表2中的類型一致;Qc表示問題主題類別,具體類別見表3;Nel表示命名實體集;N表示否定詞集,N={(key,value)};Ss表示問題的依存關系集合;I表示疑問詞;TL表示語義三元組集合;P表示意圖。
問題分析的過程:用戶輸入問題后,(1)利用HanLP根據詞庫進行分詞和詞性標注;(2)利用詞的標注信息得到命名實體集Nel、疑問詞集I和依存關系集合Ss;(3)識別問題類型It、否定詞集合N和問題主題類別Qc;(4)識別問題意圖P;(5)生成語義三元組集合TL;(6)輸出分析結果。其流程圖如圖3所示。下面對問題分析的各個模塊進行介紹。
2.2.1 分詞和詞性標注
本文使用了HanLP對問題進行分詞,同時利用新增的領域專業詞庫和自定義詞庫,對相應的詞語重新進行詞性標注,然后通過同義詞替換操作,得到如下的問題向量表示:
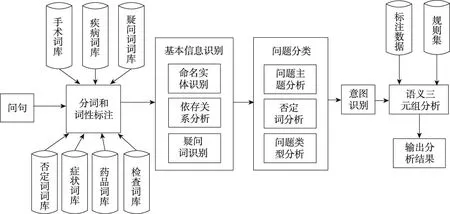
Fig.3 Question analysis flow chart圖3 問句分析流程圖
Q=(q1,q2,…,qn)
其中,qi為(word,nature),word表示單詞本身,nature表示單詞的詞性。
例1“感冒了不發燒也不咳嗽應該吃什么藥”對應的向量表示為((感冒,JB),(不,NW),(發燒,ZZ),(也,d),(不,NW),(咳嗽,ZZ),(應該,v),(吃,v),(什么藥,WHT))。
2.2.2 命名實體識別
本文需要單獨識別的實體包括疾病、癥狀、檢查、藥品、手術和醫院。因為已經收集了大量的專業詞匯,所以直接使用詞性標注來進行命名實體識別,識別算法如下。
算法1命名實體識別算法
輸入:問題向量Q。
輸出:命名實體集Nel。

2.2.3 依存關系分析
本文使用了HanLP的條件隨機場(conditional random field,CRF)依存句法分析器進行問題的依存關系分析。例1對應的依存關系如圖4所示。
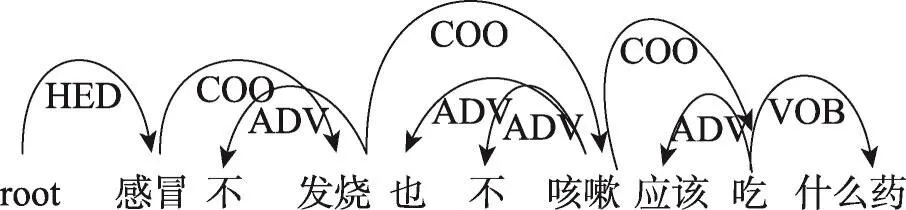
Fig.4 Dependency relation graph圖4 依存關系圖
從分析結果中可以看出,句子的核心詞是“感冒”,主語是“感冒了不發燒也不咳嗽”,謂語是“應該吃”,賓語是“什么藥”;感冒、發燒、咳嗽是并列關系;“不”是修飾“發燒”和“咳嗽”的否定詞。
2.2.4 疑問詞識別和問題類型分析
中文將疑問句分為特殊疑問句、是非疑問句和選擇疑問句。根據統計,在醫療咨詢方面是非問句占30%,選擇問句占1%,特殊疑問句約69%。因此本文只討論是非問句和特殊問句。首先提取是非問句和特殊疑問句的疑問詞,然后按照表2所示的分類體系對疑問詞進行分類。
算法2疑問詞分析算法
輸入:問題向量Q。
輸出:疑問詞集I和問題類型It。


Table 2 Classification system of interrogative表2 疑問詞分類體系

利用上述算法可以得到例1的疑問詞集I={(什么藥,WHT)}和問題類型It=WHT。
2.2.5 否定詞分析
在醫學領域的信息咨詢中,用戶往往用否定詞來排除某種情況,因此,需要對否定詞進行正確分析。本文的否定詞分析包括否定詞的識別和否定詞修飾的范圍,其算法如下:
算法3否定詞分析算法
輸入:問題向量Q,命名實體集Nel和依存關系集Ss。
輸出:否定詞集N。


利用上述算法可以得到例1中的否定詞集N={(不,發燒),(不,咳嗽)}。
2.2.6 問題主題分析
問題主題分析主要是分析句子的主題。本文按照表3的分類體系進行分類,利用支持向量機(support vector machine,SVM)[13]模型進行分類,首先對每個類別標注200個問題進行訓練,然后隨機挑選了100個問題進行測試,均取得了較好的效果。

Table 3 Classification system of subject表3 問題主題分類體系
按照上述的分類體系,例1的問題主題是“JB”。
2.2.7 意圖識別
本文首先利用詞、問題主題和問題類型之間的搭配關系和次序構造了如表4所示的254條規則;其次,利用規則構造如表5~表7所示的條件概率統計表;再次,根據如下公式得到相應的意圖:

其中,ai表示第i類意圖;qj表示Q中的第j個詞。
如果根據上述公式計算出來的值為0,則利用SVM分類器進行分類。意圖識別算法如下:

Table 4 Rule example表4 規則示例

Table 5 Probability table of intention example表5 意圖概率表示例

Table 6 Conditional probability tablep(focus|intention)表6 條件概率表p(焦點詞|意圖)

Table 7 Conditional probability tablep(entity type|intention)表7 條件概率表p(實體類型|意圖)
算法4意圖識別算法
輸入:Q,Nel,It,Qc;PT,意圖的概率表(表5);CPT,條件概率表(表6、表7)。
輸出:問題意圖P。
1.for each focus wordqofQdo
2.利用相似度求q.word在規則集中的同義詞f;
3.將f替換Q中的q.word
4.end for
5.利用表5~表7所示的概率表和式(1)計算P
6.ifPnot exist then采用SVM分類器對Q進行分類得到P;
7.end if
8.returnP;
利用上述算法識別出例1的意圖為“藥品”。
這種混合意圖識別方法,既不需要分類模型對特征明顯的問題進行訓練,同時也不需要使用多個分類器達到多分類的效果,因而能夠保證分類準確率的前提下,取得較好的時間效率。
2.2.8 語義三元組
本部分根據意圖、問題主題類別生成語義三元組。本文根據語義三元組的作用,將語義三元組分為主三元組(main)、條件三元組(condition)和否定三元組(negative),其中主三元組對應于句子主干的語義,條件三元組是對主三元組的限制,對應于句子的肯定修飾成分,否定三元組也是對主三元組的限制,對應于句子的否定修飾成分。語義三元組的生成思想:首先,從命名實體集合和否定詞中確定三元組的主語和類型;其次,將意圖作為所有三元組的謂語。其具體生成算法如下:
算法5語義三元組生成算法
輸入:P,Nel,Qc,N。
輸出:TL。

利用上述算法得到的語義三元組列表TL={<(感冒,藥品,?),main>,<(咳嗽,藥品,?),negative>,<(咳嗽,藥品,?),negative>}。
2.3 候選答案生成
候選答案生成模塊的功能是生成候選答案。本文利用搜索、查詢和推理3個技術來生成候選答案,因此本模塊包括搜索、查詢和推理3個子模塊,其流程圖如圖5所示。
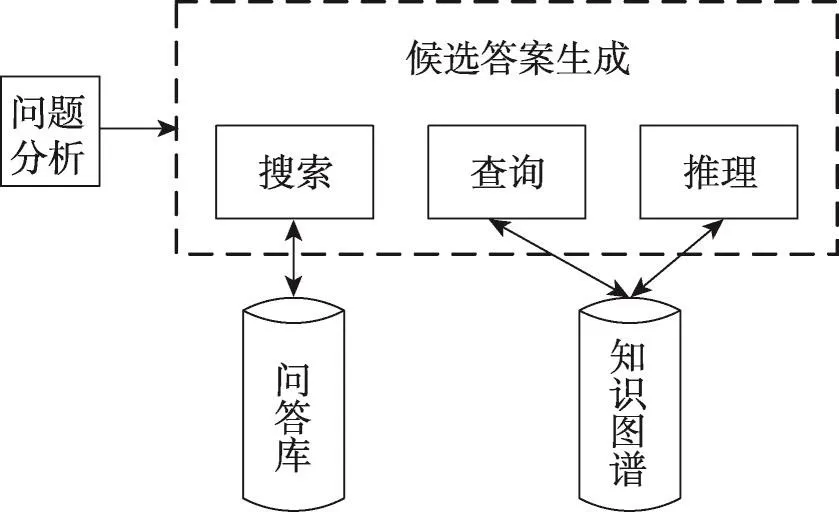
Fig.5 Candidate generation flow chart圖5 候選答案生成流程圖
2.3.1 搜索
本模塊首先根據問題分析得出的命名實體集、主三元組、同義詞,問題通過搜索引擎solr(http://lucene.apache.org/solr/)在問題答案庫中搜索出排名前60的問題答案對。本模塊的核心任務就是搜索語句的構造。本文構造的搜索語句形式如下:
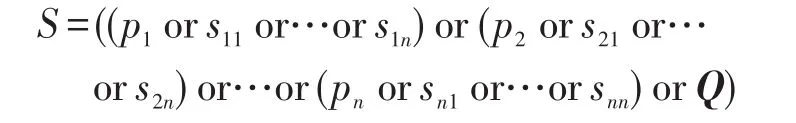
其中,pi∈Nel,sij為pi的同義詞。
例1對應的查詢語句為(感冒or(發燒or發熱)or咳嗽or什么藥or(感冒and不and發燒and也and不and咳嗽and應該and吃and什么藥))。
2.3.2 查詢
本模塊根據文獻[14]的思想首先將語義三元組轉換成SPARQL查詢語句,然后利用查詢語句查詢知識圖譜。三元組轉換成SPARQL是本模塊的主要任務,其轉換思想為:語義三元組的word對應于SPARQL語句的Subject,P對應于SPARQL語句的Predicate,?號對應于SPARQL語句的?object。轉換后的SPARQL示例語句如下:

2.3.3 推理
所謂推理就是利用知識圖譜中已有的知識推出新的知識。例如用戶想問“腹痛和發燒有關系嗎?”,假設知識圖譜中只有癥狀和疾病的關系,此時就需要推理出癥狀和癥狀的關系。
在醫療領域大量用到這樣的推理,尤其在疾病診斷當中。本文利用Jena(http://jena.apache.org/)推理機實現知識的推理。Jena推理機使用規則進行推理。Jena中的規則包括通用規則和自定義規則兩類,其中通用規則為Jena自帶的規則,這類規則主要是對知識的有效性進行檢驗,如模式圖與數據圖的一致性,不能對實際應用的領域知識進行推理;自定義規則是用戶自己定義的領域知識,能對領域知識進行推理,因此,本文共定義20條規則,例如:
[rule1:(?A rdf:type癥狀),(?A疾病?B),(?B癥狀?C)->(?A相關?C)]
該規則說明如果癥狀A是疾病B的癥狀,而疾病B有癥狀C,則癥狀A與癥狀C相關。
2.4 答案生成
答案生成模塊的功能是讓智能醫生將評分排名第一的答案展示給用戶。答案生成的思想是:首先判斷答案是否為問題答案對,如果是,則進入問題答案評分和排序;否則直接生成答案。該模塊流程圖如圖6所示。
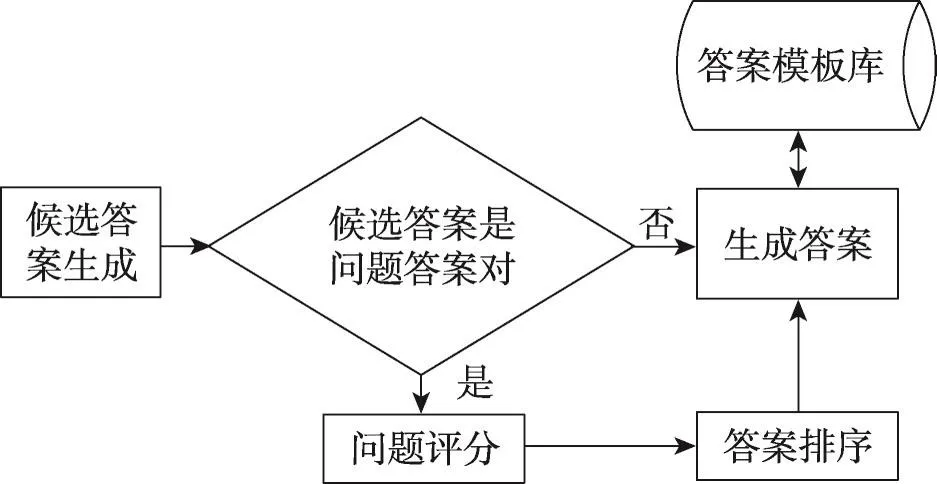
Fig.6 Answer generation flow chart圖6 答案生成流程圖
由圖6可知,問題評分是答案生成的主要組成部分,其作用是計算候選答案的問題與用戶的問題之間的相似度。現有的評分算法都是直接計算這兩個問題的相似度。但這種方法只能說明問題之間的句子含有詞語的相似度,而不能說明它們的語義相似度。本文利用多種評分算法從不同的側面計算它們的相似度,從而使評分更準確。下面將介紹相關的評分算法。
2.4.1 問題詞條匹配算法
該評分算法主要是計算候選答案的問題詞條與用戶的問題詞條的匹配程度,該評分越高,說明與用戶的問題越相似。假設t為問題Q中除疑問詞以外的詞條,即t={t1,t2,…,tn},則該算法的評分公式如下:

其中:

例2Q:“流產有什么危害?”
P1:“流產可能會導致什么?”
P2:“流產危害是什么”
根據式(2)可知,P2>P1,顯然符合實際。
2.4.2 依存句法匹配算法
該算法主要是計算候選答案的問題與用戶的問題句子結構的相似度,值越高,說明句子結構越類似。算法思想是:首先得到問題及所有候選答案的依存關系,然后根據公式得出評分。該算法的評分公式如下:

其中,Ps表示從候選答案問題中抽取出來的依存關系二元組集合;Qs表示從問題中抽取出來的依存關系二元組集合。
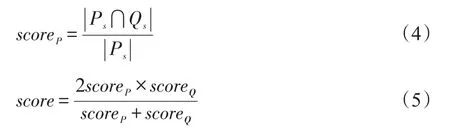

根據式(3)~式(5)可得,P1>P2,顯然與實際相符。
2.4.3 文本余弦相似度算法
本文算法首先基于改進的TF-IDF(term frequencyinverse document frequency)詞頻技術[15]計算問題Q和候選答案問題的TF-IDF值向量,然后利用向量余弦相似度計算用戶的問題和候選答案問題的相似度。假設QTF-IDF={x1,x2,…,xn},qTF-IDF={q1,q2,…,qn},其中xi、qi為相應詞的TF-IDF值,則文本余弦相似度公式如下:
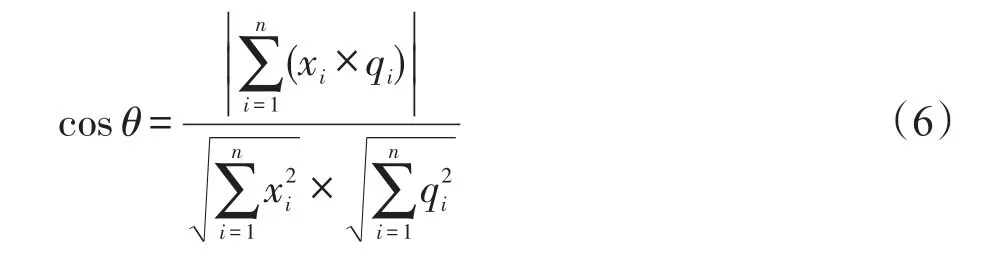
2.4.4 問題評分算法
本文將問題詞條匹配算法、依存句法匹配算法和文本余弦相似度算法的結果按照式(7)計算出問題的最后得分:

其中,si為每個評分算法的評分;wi為評分算法的權重,本文通過實驗發現,當wi為1/3時,效果最好。
3 實驗與結果
本文利用Eclipse開發環境、Java開發語言和Jena框架,初步實現了“一問一答”的婦產科智能醫生,并利用真實的婦產科問答語料測試了本文的系統。
3.1 度量標準
采用正確率(precision)來度量本系統的性能,計算公式如下:

3.2 數據集
本文使用真實的有關懷孕這一主題的問答語料447個問題作為實驗數據集,并進行人工評測。這些問題基本涵蓋了懷孕這一主題的全部類型和關系。實驗數據集中的部分問題樣例如表8所示。

Table 8 Question example表8 問句示例
3.3 實驗和結果
本節首先將真實的語料共計447個問題分別輸入計算機,得到相應的答案,其次將答案提交給醫生進行審核,具體實驗結果如表9所示。

Table 9 Experiment result表9 實驗結果
通過分析實驗結果發現,本系統的正確率為88.81%,在不正確的問題中有64%的錯誤是由于未能對是非疑問句進行準確分析造成的,如對“做輸卵管通液能懷孕嗎?”這樣的問題分析不對;16%的錯誤是由于句子成分復雜和未對口語化的詞語進行理解造成的,如句子“為什么那么多人說懷孕3個月以后就穩定了,沒事了?”這樣的問題分析不對;8%的錯誤是由于在否定詞識別時未能對動詞的否定進行識別造成的,如未能識別句子“懷孕不能吃西瓜嗎?”中的否定詞“不能”是修飾“吃”這個動詞的;6%的錯誤是由于在答案中未對實體限制進行處理造成的,如“孕婦便秘怎么辦?”的答案與“便秘怎么辦”相同;4%的錯誤是由于知識庫不完備造成的,例如未能識別句子“懷孕初期能吃桃子嗎?”中的“桃子”;2%的錯誤是由于未能識別不連續的實體造成的,如未能將句子“輸卵管為什么梗阻”中的實體識別為“輸卵管堵塞”。
3.4 智能醫生用戶界面
本文提出的智能醫生框架已經成功用于某公司的APP中,其用戶界面如圖7所示。
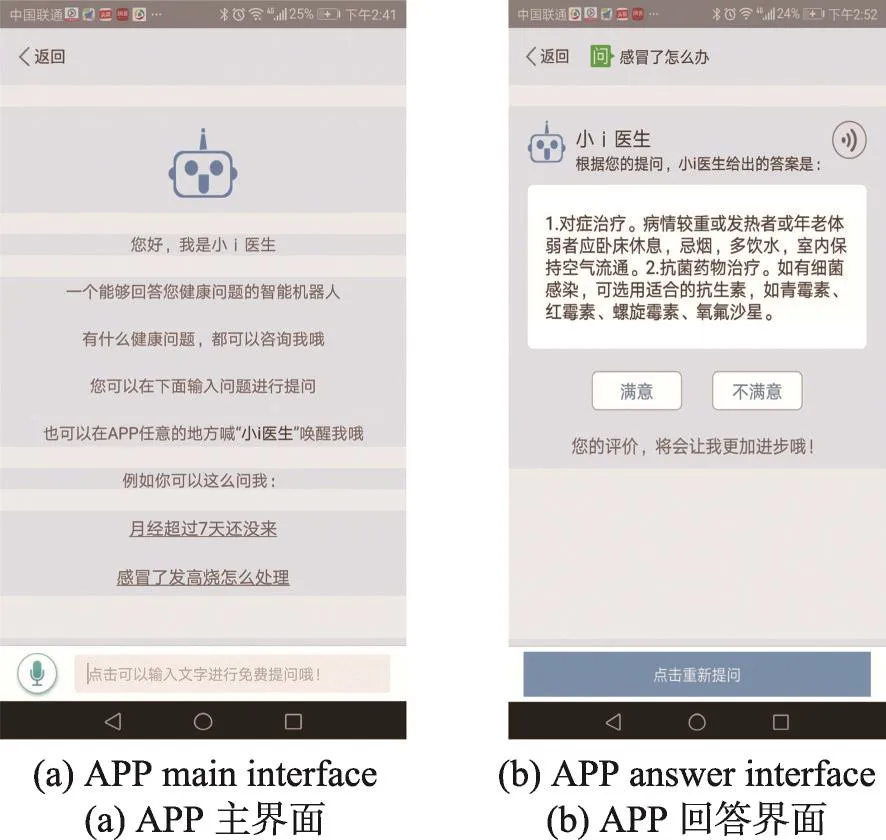
Fig.7 Users'interface圖7 用戶界面
4 總結
本文提出了一種“一問一答”的智能醫生架構,該架構包括問題分析、候選答案生成和答案生成等三部分,并用真正語料對該架構進行了測試,實驗結果表明,本文提出的架構的準確率達到80%以上,因此,該架構是有效的。但該智能醫生的認知水平還有待提高,下一步將在以下幾方面進行改進:(1)利用自動化技術對知識庫進行擴充,增強知識庫的自動更新能力;(2)利用關系抽取技術,對問題分析進行更精確的理解;(3)利用表示學習對意圖和問題類型及主體進行識別;(4)增加推理規則對時間進行推理。
猜你喜歡
中等數學(2022年2期)2022-06-05 07:10:50
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
小學生學習指導(低年級)(2020年6期)2020-07-25 02:31:36
開放教育研究(2020年2期)2020-03-31 01:54:14
電子制作(2018年18期)2018-11-14 01:48:24
小學生學習指導(低年級)(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
山東工業技術(2016年15期)2016-12-01 05:31:22
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
