地震前兆數據的大數據挖掘研究
2018-09-19 09:41:04李秀明
計算機測量與控制 2018年9期
關鍵詞:數據挖掘
李秀明,乜 勇,劉 磊
(1.青海民族大學物理與電子信息工程學院,西寧 810007;2.陜西師范大學教育學院,西安 710062;3.青海省地震局,西寧 810000)
0 引言
地震前兆觀測指的是實現地震預報及其他地球物理科學研究的基礎,千兆預測數據質量及數量對此研究過程和結果具有直接的決定作用。所以,前兆觀測屬于我國地震監測工作中的主要內容。通過我國多年的發展,我國地震前兆觀測系統已經創建成為覆蓋全國單位、智能化及涉及多學科的網絡觀測系統。目前數字化前兆觀測系統數據的采樣率及精度有了進一步的提高,也提高了數據量,增加了前兆臺站、前兆臺網的數據及數據檢查工作量。目前,地震前兆數據預處理工作還是根據人工檢查方式實現,因為數據量較大,人工檢查方式效率較低。并且,人工檢查過程具有一定的直觀性,不同人員的判斷各有不同。數據挖掘就是基于此種需求逐漸發展的學科,其能夠從隨機、大量、模糊、有噪聲及不完整數據中檢測有用信息,以此對人們提供決策根據。那么,本文就將大數據挖掘應用到地震前兆數據分析中,從而解決現代前兆臺網數據人工檢測效率較低的問題,以此為目前觀測數據大數據庫量分析及使用工作的全新方法進行探索。
1 大數據挖掘技術的研究
數據挖能夠使人們對信息數據進行分析、理解和使用的全新學科,海量數據挖掘指的就是從不完全、大量、隨機、模糊的實際收集信息中,利用提煉隱藏在不輕易被人發現的有用信息及知識過程。此都是利用數據挖掘分析得到的知識及信息,不僅能夠被人們所理解,還能夠便于存儲、使用及傳播。大數據挖掘從出現之后,此領域備受人們的重視。在信息技術不斷發展的過程中,通信水平也在不斷的提高,大多數行業信息都實現了高度集中。所以,大數據挖掘技術被廣泛應用到多領域中。
大數據挖掘屬于全新的學科,其中具備了傳統領域的思想,比如估計及假設檢驗、統計學抽樣;模式識別、人工智能及機器學習搜索算法、學習理論和建模技術等。以上領域都包括進化計算、最優化、信息論、可視化及信號處理等技術,其被廣泛應用到大數據挖掘中。另外,數據庫系統還具有有效存儲、查詢處理、索引的支持,分布式技術能夠幫助對海量數據進行處理,還能夠在數據無法聚集的過程中一起處理。
大數據挖掘具有完整的方法對實際問題進行解決,根據此分類估計、預測分析、抽象聚類、相關性分組、建模描述可視化及復雜數據類型挖掘,能夠實現大量信息的挖掘,此套完整方法在地震檢測系統中使用,實現海量數據分析,能夠使地震檢測時效性及精準度得到有效的提高[1]。
2 地震預報中的數據挖掘
2.1 地震預報方法
地震預報復雜性及科學難度為世界公認,通過長時間的研究及探索,人們總結了地震學預報、千兆預報、地震活動大形勢預報及綜合預報等,本文所研究的為前兆預報方法。千兆預報是利用對大地形變場、地磁場、應力應變場、重力場、大地電場等地理物理場及物理量異常變化對未來大地震進行預報。對于中短期的地震預報探索分析,得到可靠地震前兆具有重要的意義。實現地震預測的主要內容就是確認地震前兆,地震前兆的重現性理為地震預測基礎。
地震數據的主要特點為:1)具有較多的經驗性知識。由于大部分預報知識和領域具有密切的關系,一般都是通過地震預報專家經驗進行總結的;2)具有較大的數據量。地震前兆觀測數據是通過傳感器獲得流數據,其中的采樣頻率每秒一次;3)具有較強的實踐性。因為地震前兆預測監測要求具有實時性,從而方便對異常現象進行反應。并且要求地震數據具備時序性,由于地震數據和時間具有密切的聯系,所以數據之間的時間約束關系較強。簡單來說,地震數據和實踐具有一定的關系,其是一種時間序列數據。4)具有大量干擾,具有較強的隨機性及不確定因素[2]。
2.2 地震地區的相關性
地震和地質構造具有密切的聯系,產生地震的原因和板塊地震成因及內部地震成因、地震發生時間、地點及強度具有密切的聯系。在地震預報科學中,通過長時間的觀測研究及經驗積累,專家表示的大范圍地震活動高漲或者平靜的時候,此地區地震活動具有同步漲落。此種距離的兩個地區中某個指定震級以上顯著地震相伴的現象就是地震相關現象,也就是地震地區相關性。比如華北北部三個地震活動區,圖1為中山、東區及西區的范圍,使用此三個相關地區中,做出圖2的地震震級時間關系圖。通過圖中表示,在中區存在震級發生地震前后,和其相鄰的東區和西區都有發生地震。
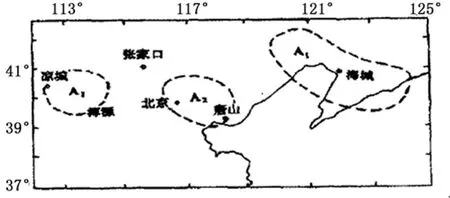
圖1 中山、東區及西區的范圍

圖2 地震震級時間關系圖
在長期觀測積累中國地震目錄中記錄了全國的地震信息,大量地震信息中具有發生地震的規律,此數據挖掘技術也是挖掘隱藏在數據知識及規律產生的。通過地震數據,結合關聯規則挖掘算法,能夠找到其中的地震知識。具體的工作為:準備數據。選擇太原臺站數據,對數據進行預處理,之后將數據轉換成為滿足關聯規則挖掘算法的地震事件序列;實現地震時間序列關聯分析。對于通過數據整理的地震時間序列數據特征及數據量,對關聯規則挖掘算法進行全面的研究,使用算法實現關聯分析,找到不同地區地震的相關性;實驗模擬及結果評價。選擇最具代表性的地震數據實現模擬,對結果進行解釋及分析[3]。
2.3 數據的獲得
太原基準地震臺在華北腹部,山西中部,其為最佳的測震地段。太原臺站不僅臺址的選擇理想,而且測震設備及環境齊全。太原地震臺被流體、形變、電磁三大學科觀測手段覆蓋,每項觀測手段中都具有二十六個測項分量。觀測儀器主要包括數字石英擺傾斜儀、數字體應變儀、數字伸縮儀、磁通門磁力儀、電離層斜測儀、數字化電阻率測量儀等,摒棄臺站具有全省的流動地磁觀測任務,一共有三十五個觀測點。通過觀測點得到數據[4]。
2.4 數據預處理
首先,對數據進行噪聲處理。利用數據清洗技術能夠對不同情況中的缺失問題進行適當處理,在數據清洗過程中使用聚類、桶分及回歸技術實現異常點識別及平滑除燥。在地震數據中,噪聲主要包括發生地震的時間有誤、位置經緯度有誤等。時間噪聲私用手工處理,比如將2015年12月10日16:60:00中的時間替換成為17:00。
其次,實現數據正規化。正規化能夠使數據屬性值從原本取值區間中到適當區間中映射,在實現數據挖掘之前實現正規化。一般正規化包括零均值、最小最大及小樹尺度三種正規化。假設及為屬性A的最小值及最大值,那么最小最大正規化的公式為:
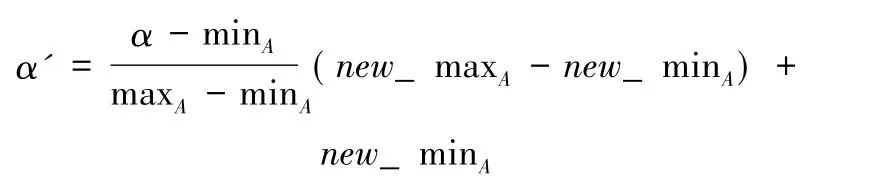
最后,對數據進行變換。為了滿足關聯分析及時間序列相似性的匹配算法需求,就要對地震目錄數據根據地理區域實現劃分,分別包括空間跨度、時間跨度及震級預處理,最后轉換成為根據不同參數進行劃分排列的地震事件序列。實現空間跨度預處理的主要方式就是劃分地理位置,并且對其進行分片編號,使用區間標號代替實際經緯度數據值,從而滿足空間屬性與離散化需求,降低指定連續屬性值數量[5]。
2.5 關聯規則挖掘算法
關聯規則指的是對事物及其他事物相互關聯及依存關系的描述,關聯規則挖掘屬于工人的數據挖掘方法,能夠尋找大量數據中項目集的相關聯系。關聯規則挖掘步驟為:
1)尋找所有頻繁項集;
2)通過頻繁項集得到強關聯規則。
3 基于時間序列數據流的增量式挖掘
3.1 問題定義
因為要使用挖掘結果對模式庫進行更新,假如每挖掘一次就更新模式庫,不僅會增加服務器負擔,并且會影響到挖掘效率。本文使用內存及外存兩級式序列模式的存儲結構,基于時間窗口找到最新的頻繁模式,只需要將最近出現的頻繁模式在內存中存儲,在超過數量之后,就到模式庫中發送更新,之后到內存中將此頻繁模式去除,以此保證全部頻繁模式狀態的監控。圖3為挖掘的步驟。

圖3 挖掘的步驟
1)基本窗口。假如BW屬于基本窗口,其對應數據流子序列,長度為bw.size=|BW|。一個基本窗口對一次模式的基本單元提取,也就是和一個時序模式集合對應。基本窗口bw為窗口w的分類,w為基本窗口表示的方法。
2)滑動窗口。假如SLW屬于滑動窗口,其和連續基本窗口序列對應,表示為SLW=bw1,bw2,bwk。
3)TPSS。對滑動窗口中的時序模式來說,在其中的每個基本窗口都具有 TPSS[6]。
3.2 基于重要點分段
從時間序列中實現模式抽取的方法為:先分割原始時間序列,將其中的子序列轉換成為某個高級的數據,之后實現模式發現。本文使用基于重要點分段,此方法的計算時間比較小,能夠避免時間序列受到噪聲的影響,掌握序列整體變化的特點,其方法較為簡單并且有效。重要點指的是序列變化過程中視覺具有主要影響的觀測點,也就是序列匯總某部分局部極大、極小的點,圖4為序列的重要點。

圖4 序列的重要點
假設 S= < X1=(v1,t1),..,Xn=(vn,tn) > 屬于時間序列,其中的v1指的是時間t1中的觀測值,本文假設△=1,并且t1=0。
雖然時間序列和全文序列中的基本元素具有區別,時間序列為連續取值實數構成,全文序列為有限字符構成。實現序列的分段,每個字段表示變化模式。之后在模式中實現相似性定義,從而實現符號化,最終將時間序列轉化成為符號序列。
對給定常量 R>1 及時間序列<X1=(v1,t1),..,Xn=(vn,tn)>進行定義,假如數據點Xm(1≤m≤n)為主要極小點,那么其要滿足以下需求:
在 1<m<n 的時候,下標 i及 j為 1≤i<m<j≤n。
給定常量直觀的含義就是:Xm為序列 Xi,..,xj的最小值,在此段中的兩個端點值比XmR大,R屬于可控制選取參數,R值越大,那么被選中的相對重要點就會越少,時間序列線段的描述就會越粗。所以,利用R的選擇,能夠在不同精細度程度中實現數據挖掘。
因為是在數據流中實現劃分,為了能夠對流連續性進行保證,只要尋找小于n的重要點,最后重要點后面數據在后續數據中分析。
算法Selesc_Improtant_ (S,R,SC)
輸入:時間序列S,選擇參數R;
輸出:通過重要點構成序列SC;
步驟:(1)i=find_first_importmt_point(SC);
(2)if I<N and vi≥v1then i=find_minimum(i);
(3)while i<N do
(4){i=find_maximum(i)}
(5)if i<N then i=find_minmum(i)
以此表示,此算法只要掃描一次序列,在分段過程中進行簡單對比計算,不需要復雜的最小二乘法計算。并且此算法支持序列在線選擇。
以算法所獲得的重要點集,能夠實現序列的逐段線性化,以此得出通過線段所表示的趨勢變化特征模式構成的序列集合SC。圖5為序列分段。
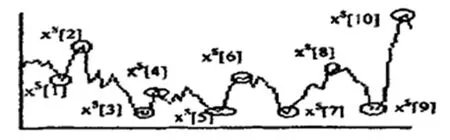
圖5 序列分段
3.3 數據并行挖掘
在數據挖掘過程中不僅要考慮速度,還要考慮最近數據挖掘中挖掘,其結果的精準性比靜態數據挖掘結果要差,所以要盡量提高挖掘結果。充分考慮此點問題,在數據挖掘過程使用并行挖掘方法,其思想為:
假如具有N+1個處理器,其中0屬于主處理器。假如TPSS具有K個基本窗口。算法在全新基本窗口中產生之后刪除傳統窗口,之后觸發模式分析。在第一次執行算法的時候,通過挖掘模式創建前綴樹,并且將其在頻發模式中使用,創建互聯之后到處理機1中保存。之后每次觸發算法,在處理器2,..N中對此數據進行處理,然后創建互聯后繼樹,之后和處理機1中的后繼樹進行合并,并行實現模式挖掘,對頻繁模式前綴樹進行更新,以頻繁模式前綴樹實現模式庫的封信[7]。圖6為并行挖掘模型。
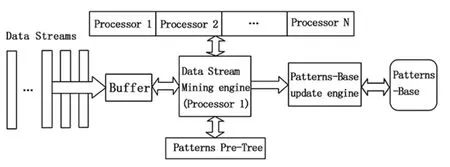
圖6 并行挖掘模型
算法步驟為:
1)在SIRST中尋找最早的基本窗口線段序列;
2)對序列中每類線段序列Cidi出現次數進行計算;
3)實現SIRST中字數的遍歷,并且將葉子節點中Cidi相應的tagj進行修改成為tagj-Num。
在每次模式分析之后,處理器0就會對頻繁模式進行收集,對前綴樹中的頻發模式進行更新,之后對前綴樹進行檢查,并且將滿足規測需求的頻繁模式到模式庫中發送實現模式庫更新,之后對模式前綴樹進行調整。以此表示,每次分析序列能夠使算法效率得到提高,并且還能夠對分析時序列完整性進行保障,是模式庫更新頻率得到降低。
4 算法驗證
將以上所分析的算法通過Weka數據挖掘工具實現驗證,安裝Weka工具。Weka自身是以Java所編寫的,本文使用可擴展及開放的集成開發工具Eclipse。算法驗證的過程為:
將Weka打開,在預處理面板中加載本文所選擇的地震前兆數據。之后切換到Cluster面板中,單機Choose按鈕,就能夠到下拉菜單中實現DFCM算法的導入。單擊文本輸入框,在所彈出的對象編輯器中使epsilon參數設置為0.5。之后單擊Ignore,在彈出的Select窗口中選擇time屬性,關閉此窗口。在Result中右擊結果列表中的新添加條目,在彈出的菜單中選擇簇分配可視化菜單,Weka就會彈出可視化窗口,可視化界面的結果利用坐標選擇不同測項,以此顯示所有的結果。
根據以上步驟,通過多次的參數選擇,將DFCM兩個關鍵參數進行反復的設置對比,以臺站測試需求,每年使監測儀器調整為相對零值,并且每年的數據分布形態相同,實驗聚類數量為6,閾值為0.5。圖7為聚類結果。

圖7 聚類結果
通過圖7可以看出來,中間的黃色部分數據為聚類質心群,以顏色對數據程度進行區分,黃色為0.8~1.0,淺黃色為0.6~0.8,此種顏色的數據為此簇類。灰色為0.4~0.6,淺藍色為0.2~0.4,其隸屬簇權值較大,標記藍色數據為0.0~0.2,此屬于此類以外數值,以此為相對孤立值。
對測項進行總結,2012年~2017年的數據異常結果詳見表1。

表1 前兆數據的檢測結果
本文一共選擇了十三個測項中的十二測項數據實現分析,為2791天的數據記錄,以實驗過程選擇聚類結果較好的參數閾值0.3和0.5實現結果羅列,得到前兆數據處理結果。通過結果分析,其中2231、2232、2241、2242、2243、2244、9140的檢測結果良好,從聚類時間分析,六年的數據記錄時間為395.53 s。以此表示,從時間及結果方面,本文所研究的方法具有實際意義[8]。
5 結束語
地震前兆數據觀測項較多,并且種類較為繁多,跨越的時間較短,來自于不同技術系統。另外,因為種種原因,導致目前實際數據集較為混亂。實現此數據的聯合使用及長時間的數據分析,傳統數據分析方法已經無法滿足需求。大數據分析思路為使用前兆數據提供了全新的模式,通過此全新的思路,和地震前兆觀測物理意義相互結合,能夠從其中挖掘有用的規律及信息,對于前兆觀測地震及研究其他地震問題都有重要的現實意義。通過大數據研究思想,能夠對前兆數據傳統使用及研究模式進行創新,不管是前兆數據推廣使用,還是使用其進行科學研究,都是有意義的嘗試。
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
