基于主成分分析與廣義回歸神經網絡的股票價格預測
2018-10-17 08:38:38于卓熙趙志文
統計與決策 2018年18期
于卓熙,秦 璐,趙志文,溫 馨
(1.吉林財經大學a.管理科學與信息工程學院;b.互聯網金融重點實驗室,長春 130117;2.吉林師范大學 數學學院,吉林 四平 136000)
0 引言
隨著股市的發展,國內外學者提出了許多股票預測的方法:(1)傳統投資分析法,主要包括基本分析法和技術分析法。基本分析法適用于周期相對較長的證券價格預測,以及相對成熟的證券市場和預測精準度要求不高的領域。技術分析法更適用于短期行情預測,但其方法多種多樣,選擇哪一種方法依賴于主觀判斷。多種方法綜合使用,對使用者要求較高,并且占用大量時間,影響時效性[1]。(2)時間序列分析法,主要包括趨勢外推法、移動平均預測法以及指數平滑法。適用于較為簡單、平滑的數列預測,此方法應用簡單、直觀[1]。(3)非線性系統分析法,主要包括神經網絡。適用于處理類似于股價預測等多因素、不確定、非線性的時間序列預測問題,既可以模擬基本分析,也可以模擬技術分析,具有分布處理、自組織、自適應、自學習、容錯性等優良特性。但是該算法本身存在一定的局限性[3],比如神經網絡不能對輸入變量進行選取。如果輸入變量過多時,就會使網絡結果變得復雜,從而對神經網絡的訓練造成負擔,進而使學習速度下降;同時,如果主觀選擇變量,很可能選出與輸出相關性很小的輸入變量,由于帶有人為的主觀性,會嚴重影響神經網絡的預測精度[2]。針對以上神經網絡中的問題,結合Donald(1990)[3]提出的廣義神經網(簡稱GRNN),其是由徑向基函數引申而來。與前饋神經網絡相比,有較短的訓練時間和較低的計算成本以及網絡計算結果能達到全局收斂而不會停止在局部收斂的優勢。且只有一個自由參數的優點,決定了該網絡能夠最大限度地避免人為主觀選擇對預測結果帶來影響。
本文運用廣義回歸神經網絡(GRNN)模型對華夏銀行(600015)從2013年3月11日到2015年6月3日內的股票數據進行了驗證性測試與分析。首先運用主成分分析法對影響股價的因素進行降維,避免輸入變量過多和選擇主觀性問題。將主成分分析與廣義回歸神經網絡相結合的預測效果與時間序列ARIMA模型的預測效果進行了對比分析。
1 主成分分析法與廣義回歸神經網絡
1.1 主成分分析法
確定主成分的方法有兩種,一是通過選取特征值大于1的指標來選取主成分;二是通過方差累計貢獻率來選取,一般要求選取的主成分的累計貢獻率大于等于85%。本文通過第一種方法來選取影響股價的主成分。其主要的算法步驟如下:
(1)對原始變量進行標準化。目的在于消除原始變量間量綱影響和數值差異的影響,使得原始數據間具有可比性。即:
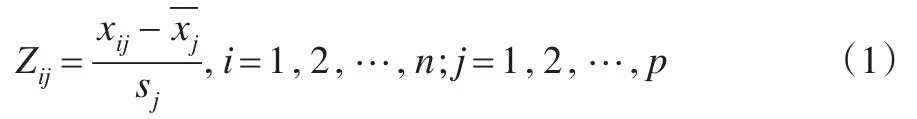
(2)計算相關系數矩陣。

其中,rij為原始變量xi與xj的相關系數。
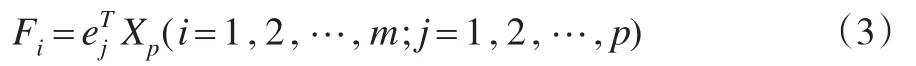
原變量協方差矩陣的特征根是主成分的方差,即前m個較大特征根為前m個較大主成分方差值;原變量協方差矩陣前m個較大特征值所對應的特征向量為相應主成分Fi表達式的系數。將計算得出的各主成分得分值作為廣義神經網絡的輸入值。
1.2 廣義回歸神經網絡
廣義回歸神經網絡(GRNN)是徑向基神經網絡(RBF)的一個分支,是一種通用的非參數回歸模型,不像傳統的回歸分析需要先假設一個明確的函數形式,只需要以機率密度函數的方式表達[4]。GRNN神經網絡結構的四部分,即分別為輸入層、模式層、求和層和輸出層,如圖1所示。
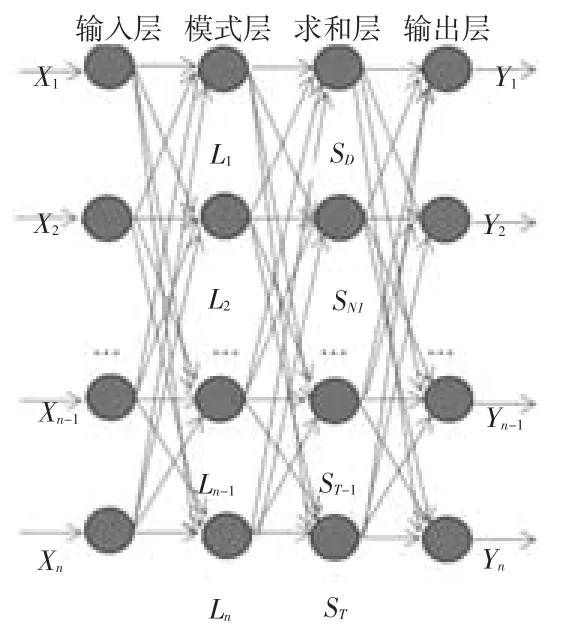
圖1 廣義回歸神經網絡模型的結構
網絡的輸入為X=[X1,X2,…,Xn-1,…,Xn]T,輸出為Y=[Y1,Y2,…,Yn-1,Yn]T。
(1)輸入層。用來接收學習樣本,并將輸入樣本直接傳送給模式層。
(2)模式層。平滑參數存在于模式層,模式層中不同的神經元對應不同的樣本,該層的傳遞函數為徑向基函數,即:

其中,X為網絡輸入變量;Xi為第i個神經元對應的學習樣本;σ代表光滑因子[5]。
(3)求和層。對模式層所有神經元的輸出進行求和,該層的傳遞函數也為徑向基函數。該層中使用兩類神經元求和:
一類為:
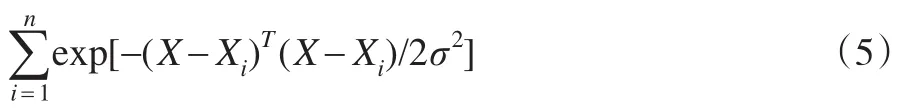
它對所有模式層神經元的輸出進行了算術求和,其中,模式層和各個神經元的連接權值為1,傳遞函數為:

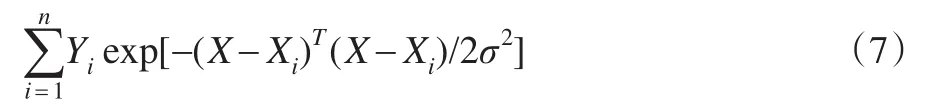
它對所有模式層神經元的輸出進行加權求和,模式層中第i個神經元與求和層中第j個分子求和,神經元之間的連接權值為第i個輸出樣本Yi中的第j個元素[8]。其中傳遞函數為:
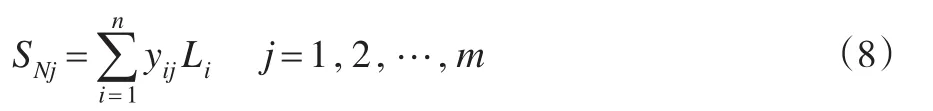
另一類為:
(4)輸出層。該層的函數為線性函數,對結果進行輸出,對應的函數方程為:
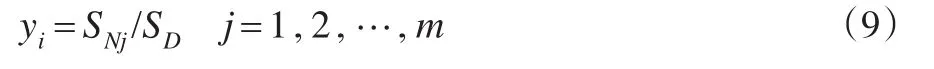
2 實證分析
2.1 數據選擇
本文選取了華夏銀行(600015)從2013年3月11日到2015年6月3日共543個交易日的數據,根據該股票的信息,選取了開盤價、收盤價、最高價、最低價、成交量、成交金額、每股收益、凈資產收益率、每股凈資產這9項重要指標進行分析[6]。選擇收盤價作為股票價格預測指標,其他指標作為股票價格的影響因素,數據來源于瑞思金融研究數據庫。部分數據如表1所示。
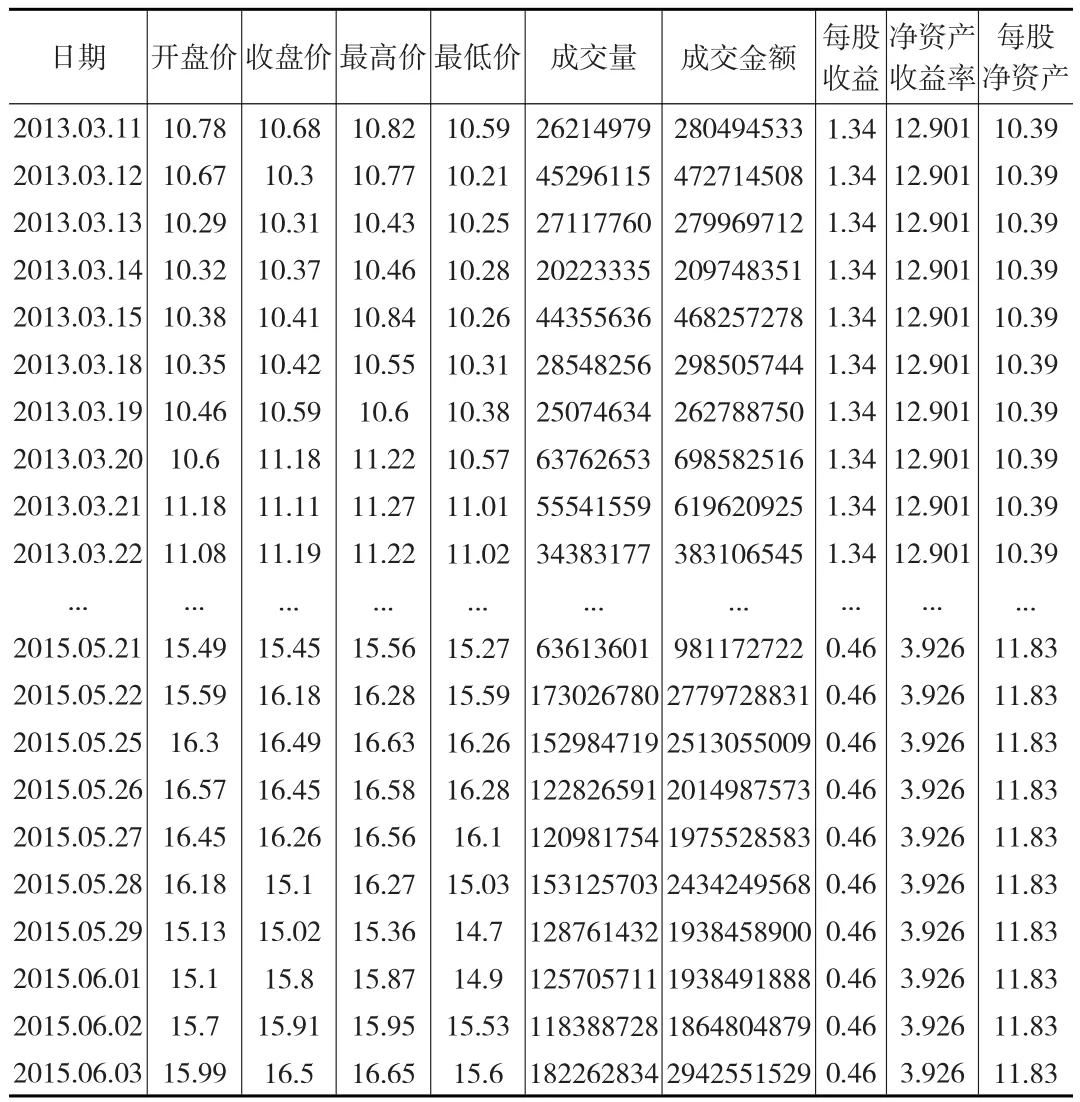
表1 華夏銀行在批發和零售業的部分數據
2.2 PCA-GRNN神經網絡模型
2.2.1 主成分析析結果
運用SPSS軟件對所有數據進行分析,從得到的KMO和Bartlett檢驗結果可以看出,原變量之間存在著很顯著的相關關系,說明存在數據冗余,有必要對這些數據指標進行主成分分析。經過選擇特征值大于1這項指標進行主成分選擇,并結合表2所示的解釋總方差,可以看出前兩個主成分的累計貢獻率已超過85%,因此需要提取兩個主成分。
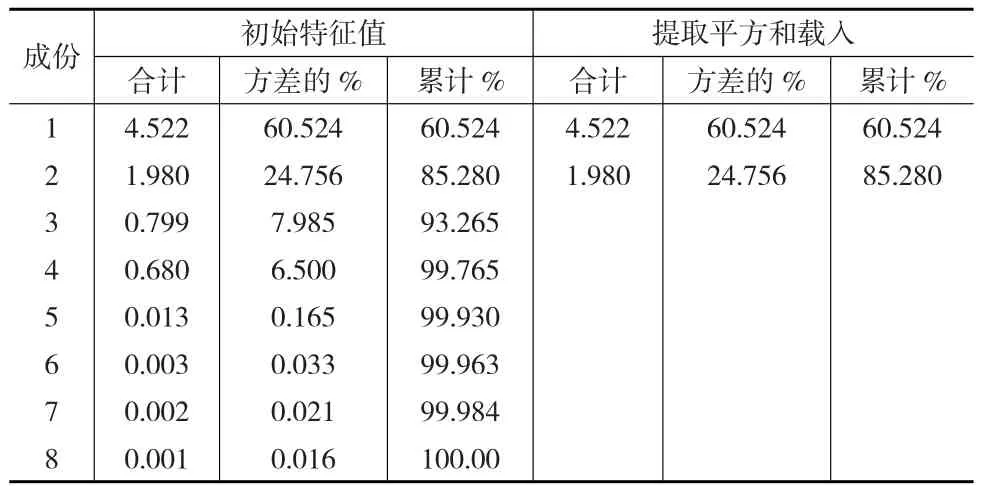
表2 解釋的總方差
由表3所示的成分矩陣表,可以提取到的主成分公式為:

式(10)和式(11)中F1、F2分別代表兩個主成分,X1、X2、X3、X4、X5、X6、X7、X8、X9分別代表開盤價、最高價、最低價、成交量、成交金額、每股收益、凈資產收益率、每股凈資產、收盤價。
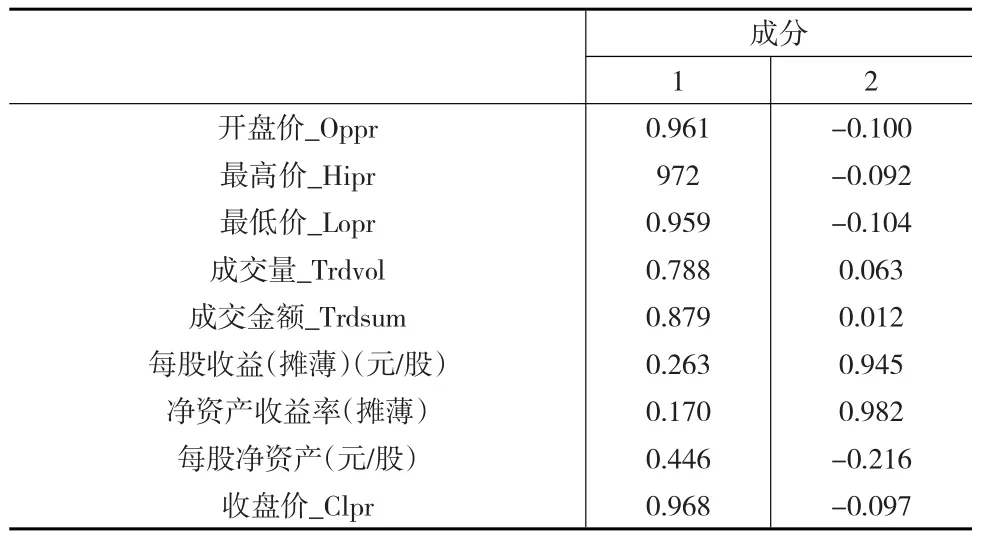
表3 成分矩陣
2.2.2 GRNN預測建模
將提取出的兩個主成分作為PCA-GRNN神經網絡模型的輸入進行網絡訓練建模,運用交叉驗證法選出最優的輸入輸出值及最優的平滑參數。經過不斷測試,最終選擇運用4折交叉驗證,再將運用4折交叉驗證選出的最優輸入輸出值進行歸一化,歸一化的數據分布在[-1,1]區間。運用歸一化的輸入輸出值及最優平滑參數進行建模,進而對后五天的股票價格進行預測,此過程均在Matlab軟件中實現,且得到最優的平滑參數值spread為0.009。數據分為兩部分,2013年3月11日到2015年5月29日期間的數據作為訓練數據集,2015年5月30日到2015年6月3日期間的數據作為測試數據集。本文選取交叉驗證方法的原因是:(1)可以從有限的股票數據中獲取到盡可能多的信息;(2)從多個方向開始學習樣本的,能夠有效地避免陷入局部最小值;(3)可以在一定程度上避免過擬合的問題。
2.3 ARIMA模型
ARIMA(p,d,q)模型處理的是平穩序列。本文中原始數據的時序圖如圖2所示。
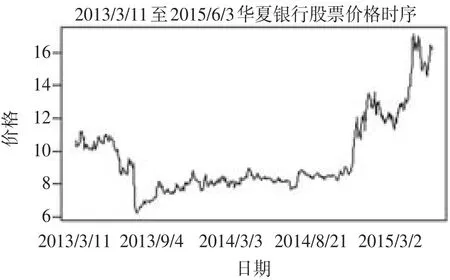
圖2 時序圖
從時序圖可以看出總體呈上升趨勢,可判斷該序列是非平穩序列;需要對該序列進行平穩化處理,即需要對原始序列進行差分,差分后的序列為圖3所示。

圖3 三階差分序列圖
根據差分后序列方差的變化,最終決定選擇三階差分;接著對差分后的序列進行單位根檢驗,檢驗結果為該序列為平穩序列;因此可以根據該序列進行建模。
根據ACF圖(下頁圖4)可以看出在3階之后截尾;由PACF圖(下頁圖5)可以看出5階之后,誤差大部分都在2倍標準差左右,并根據AIC最小的原則,最終得到的綜合模型為ARIMA(1,3,1)。該模型的方程為:

模型的建模參數結果如表4所示。

表4 ARIMA(1,3,1)模型參數估計
從表4可以看出回歸系數均顯著,且擬合優度相對較高為R2=0.980。
3 結果分析
運用ARIMA模型與基于PCA-GRNN神經網絡模型對2015年5月28日到2015年6月3日五天的收盤價進行預測。預測結果如表5所示,并對兩種模型的預測結果進行了誤差分析,分析結果如表6所示,兩種模型對后五天的股票價格的預測值與真實值之間的對比結果如圖6所示。

圖4 三階差分序列自相關圖
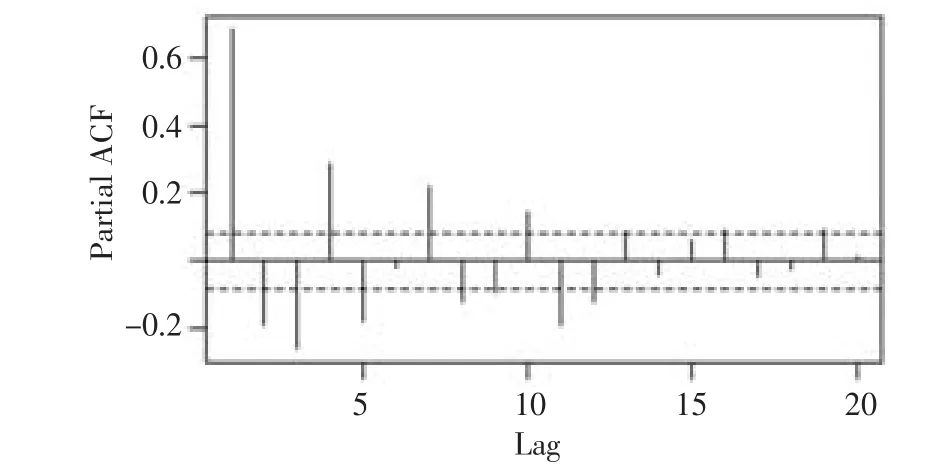
圖5 三階差分序列偏自相關圖
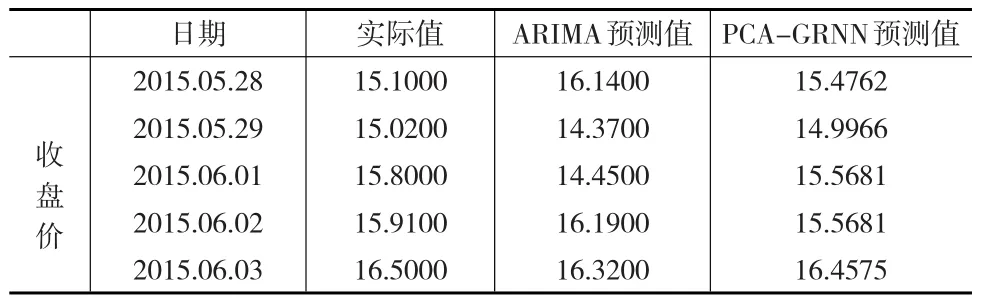
表5 預測結果分析

表6 誤差分析結果
由表5的對比分析可知,PCA-GRNN神經網絡的預測結果比ARIMA模型的預測結果更接近真實值,說明PCA-GRNN是一種較為有效的股票價格預測方法。
從表6可以得出PCA-GRNN模型的均方誤差(MSE)為0.062922,要低于ARIMA模型的均方誤差值(MSE)0.68748;由平均絕對誤差百分比(MAPE),PCA-GRNN神經網絡模型1.304%的值也明顯低于ARIMA模型的4.522%。說明PCA-GRNN模型的預測效果要優于ARIMA模型。

圖6預測值與真實值的對比圖
圖6 中,y1表示股價真實值,y2表示基于PCA-GRNN模型的預測值,y3表示ARIMA模型的預測值;橫坐標x表示天數,1代表預測的第一天即2015年5月28號,依次類推,5代表2015年6月3號。從圖6可以得出PCA-GRNN神經網絡的預測結果趨勢與真實值基本一致,且誤差較小,而ARIMA模型的預測結果明顯均高于真實值,存在較大的誤差。
4 結論
通過主成分分析和廣義回歸神經網絡結合的模型以及時間序列ARIMA模型對股票價格進行預測分析,結果表明:基于PCA-GRNN模型的預測結果要優于ARIMA模型。這主要是由于股票數據是隨機的、非線性的、不確定的非平穩時間序列,而ARIMA模型屬于線性模型,對股票價格預測分析這種非線性行為的分析與預測存在一定缺陷;而神經網絡能夠以任意精度逼近任何非線性連續函數,同時它在模擬多變量時,并不需要對輸入變量做出復雜的假定,只需依靠觀測到的數據,通過訓練得到精確的模型。且廣義回歸神經網絡只有一個受人為因素影響的參數,大大降低了人為因素帶來的誤差[7],對投資者能夠準確地預測股票價格及更好地把握股票市場的發展提供了相應的參考依據。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
