基于疾病模式的臨床決策支持系統構建
2018-10-22 00:25:06姬娜李桂祥陳鵬崗
中國醫療設備 2018年10期
關鍵詞:糖尿病
姬娜,李桂祥,陳鵬崗
西安交通大學第二附屬醫院 信息網絡部,陜西 西安 710004
引言
近年來,臨床決策支持系統成為各大醫療機構關注與發展的熱點,隨著醫院規模的不斷擴張和醫療數據的爆發式增長,如何利用大數據處理技術從海量業務數據中發掘有針對性的信息,構建疾病模式知識庫,輔助醫生進行臨床決策,成為未來醫院醫療信息化建設發展的趨勢[1-2]。
目前,臨床醫生在疾病診斷的過程中大都綜合臨床癥狀、體征和輔助檢查來做出判斷,所以對診斷質量和標準把握不高,無法利用電子病歷信息系統所積累的數據來做臨床決策支持。精準醫療是一種基于病人定制的醫療模式,通過醫學數據和專業知識分析患者病癥,提供個性化疾病治療方案,基于這種迫切的需求,臨床決策支持系統(Clinical Decision Support System,CDSS)的開發與應用將被進一步有效推動[3-4]。
基于疾病模式的臨床決策支持系統構建將當前醫療行為過程中記錄的散落診療數據整合成標準的患者疾病模式。然后對不同疾病的不同核心信息進行轉換和識別之后確定“這是一個什么樣的患者”“哪些是相似的患者”“這是一種什么疾病”“如何評價一個診療過程質量”。因此,構建的系統有助于為患者個體的疾病診斷和治療提供精準的決策,從而提高醫生的診療水平及醫療質量,最終受益于患者。
1 臨床決策支持系統現狀與存在問題
美國典型的臨床決策支持系統包括QMR、DXplain、MYCIN、Isabel、VisualDX等在發展過程中的問題及經驗值得我們借鑒[5-6]。2007年,IBM開發的“沃森(Watson)”人工智能系統不斷與各醫院、診所、疾病研究中心合作,將“沃森”應用到醫療的各個方面,但“沃森”在中國的工作仍面臨著本土化問題[7-8]。國內臨床決策支持系統主要以單病種或單學科的診斷為主,多處于探索階段。真正具有基于不同患者的個性化分析及輔助決策功能的臨床決策支持系統還未實現[9-10]。
臨床決策支持系統的推理方法——基于規則、基于案例和基于模型等[11-13]。基于規則效率高、知識庫構造簡單,但表述規則難度大和存在知識瓶頸。基于模型相比基于規則的方法,降低了知識表示與抽取的難度。基于案例主要指利用已有經驗。陳全福等[11]使用案例推理(Case-Based Reasoning,CBR),通過對案例的學習來拓展臨床思維,然后采用智能神經算法進行自我學習,但由于病情多樣性、案例多屬性、屬性值的復雜性和不確定性,案例表示具有局限性,對噪音數據敏感,案例修正規則獲取困難。徐云偉[12]將文本形式的臨床指南基于適當的建模形成計算機可讀的形式,通過執行指南,在診療過程中提供針對性建議。但大多數臨床指南是基于靜態文本的自然語言,因此計算機無法對未經結構化的、基于自由文本的指南進行分析。劉永斌等[13]提出基于知識庫的臨床決策支持系統技術框架,但權威知識庫建設困難、醫學知識更新迅速、臨床診斷中不確定因素較多、推理機制復雜。
2 疾病模式建立
2.1 疾病模式識別
疾病識別通常采用專家醫師根據自身的經驗進行分析,得出結果。疾病模式識別是以識別疾病特征的方法研究疾病科學問題,疾病特征識別就是從數據集的數據中識別出某類事物最具代表性特征子集的過程。通過度量不同特征與類別的相關程度,實現在高維特征中選取與類別相關度高的特征子集[14-15]。根據病患在真實臨床條件下所生成的數據出發,對這些在醫院內積累的大量數據進行深度治理、分析和挖掘,尋找體征、診斷、用藥、治療方式等的相關性,結合醫學知識圖譜,最終形成患者畫像,疾病模式生成如圖1所示:

圖1 疾病模式生成示意圖
2.2 特征向量提取
建立每個疾病的專屬疾病模式,除疾病中基本信息、一訴五史、體格檢查、專科檢查、診斷等之外,每個疾病都有自己專屬的疾病信息,各類專科系統疾病信息,包括疾病名、縮寫、別名、ICD疾病代碼、臨床表現、并發癥、實驗室檢查、其它輔助檢查、診斷、鑒別診斷、手術、治療、預后、隨訪等。
疾病模式的建立有賴于臨床信息化進程中產生的大量真實醫療數據,這些數據的產生以醫生與患者的診療活動為核心,并以結構化與非結構化數據的形式存在于HIS、LIS、PACS、腦卒中信息系統以及遠程會診系統等中。首先,結構化數據包括:患者人口學信息、檢驗結果、醫囑信息、診斷信息等,將這些數據進行標準化、歸一化直接與現有知識庫關聯。其次,非結構化數據包括:入院記錄、病程記錄、出院小結、手術記錄、影像學報告、病例學報告等。這些數據進入自然語言處理模塊進行處理,關聯臨床醫學術語標準(SNOMED CT)、國際疾病分類(ICD 10)、面向藥物的命名系統RxNorm、針對觀測指標的編碼系統LOINC、基因本體(gene ontology)、DRUGBANK等國際標準術語集[16],提取隱含事實信息,包括醫學義元顆粒度分詞、醫學命名實體識別、語義依存分析、語法結構解析等模塊,從非結構化文本中提取標準有效的信息,使其得到有效治理,形成結構化的數據倉庫。
在已經完成清洗、標準化(歸一)、結構化的數據之上,通過機器學習,進一步豐富患者畫像(特征向量),通過概率統計、因果推斷、主成分分析(Principal Component Analysis,PCA)、高斯混合模型(Gaussian Mixture Model,GMM)等方法去推薦可能的疾病診斷,最終產生服務于臨床診療、診斷、治療、預后的疾病模式。糖尿病和白血病兩種疾病模式建立,見圖2。
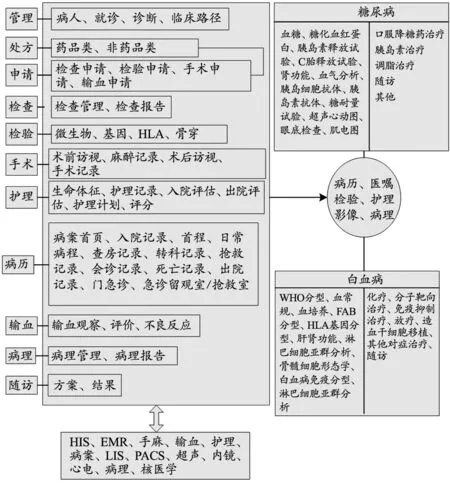
圖2 兩種疾病模式建立示意圖
2.3 患者畫像
患者畫像是對當前病人疾病狀況的刻畫。通過收集和處理大量數據,接入疾病模式,構建以患者為中心的疾病畫像。患者疾病維度的畫像,是指以患者的各個活動記錄為元數據,每次就診的病歷為組織,以病歷主診斷聚合出來的“疾病軸”為對象,將患者疾病的各個屬性(疾病癥狀、各種不同的治療方案、病情的檢驗、檢查體現等)抽象成特征向量,然后建模,通過權重的調節和條件的設置,建立相似患者和合并疾病、并發疾病等模式。
3 基于疾病模式的臨床決策支持系統構建
3.1 系統架構
數據處理平臺基于主流的云計算和大數據技術,采用多節點服務器堆疊技術(Hadoop2.0)框架及Spark并行計算框架,采取應用與計算能力的架構設計和Docker封裝技術。基于內存、SSD高效存儲介質的搜索引擎通過數據分片技術,構建在整個私有云分布式計算框架之上,實現院內數據的“百度”,支持在癥狀、用藥、患者特征等診療維度的統計分析。
對疾病數據源進行預處理后,整理成能進行分析的格式或結構,形成以疾病為中心、元數據為基礎的知識庫數據,分析出疾病參數與疾病發生之間的一些規則,得到需要的臨床知識,給出治療和藥品用量、用法、用次等方面的建議,供醫生和患者協調選擇,對超過范圍的醫療指標進行報警,指出不合理的醫囑等意見,保證診斷結果的客觀性、科學性。系統架構,見圖3。
3.2 診療數據獲取
數據處理平臺需要解決數據獲取、數據清洗等方面的工作,通過將醫院當前HIS和兩個歷史HIS、LIS、PACS、手麻、心電、病理等系統的數據通過ETL進行抽取、匯集、結構化、映射到兼容國際國內醫療數據規范標準的全局Schema中,對字段信息清洗和語義歸一,為上層應用服務提供準確的基礎數據支撐和業務模型訓練。
3.3 數據標準化與結構化
標準化保證后續應用的準確性和統計口徑的一致性,參照ICD10、ICD9、LOINC、藥品基本數據庫、醫療服務價格項目、醫用耗材基本數據庫、醫學一體化語言系統(Uni fi ed Medical Language System,UMLS)、醫學主題詞表(Medical Subject Headings,MeSH)、臨床醫療術語集(Systematized Momenclature of Medicine-Clinical Terms,SMOMEDCT)、中文醫療健康知識圖譜等國內外通用標準,對現有數據的診斷、手術、藥品、檢驗、檢查以及科室等信息進行標準化、規范化,形成以患者為中心的數據,也可自定義數據采集表,通過醫生或患者進行錄入或批量導入,還可結合平臺自身客觀數據,包括公共衛生數據、基因檢測數據、第三方開放數據等。
結構化保證數據隱含的高價值信息被完整的提取和應用。通過自然語義處理模塊,結合醫療專業術語的語義結構,將醫療語義信息從原始的自然語言表達,擴展分析為結構化的Key-Value模式,主要從若干個獨立維度來進行,對癥狀、體征、過敏史、診斷、鑒別診斷、病理診斷等字段進行劃分,臨床數據結構化處理軟件框架,見圖4。

圖4 臨床數據結構化處理軟件框架
3.4 臨床決策支持系統構建
CDSS的功能在于能夠模擬醫療專家診斷疾病的思維過程,Hadoop開源云計算平臺存儲和處理數據平臺所整合的大數據,通過大數據技術來獲取和處理多元異構的各類數據,將統計分析方法與機器學習相結合,在經過標準化和結構化數據之后,利用SPSS統計工具,以糖尿病為例,將各階段患者的多次生理指標作為研究對象,進行Logistic回歸分析,采用分類、聚類、關聯規則對糖尿病原始數據,包含診斷、生化、糖化、檢驗等多個臨床指標及用藥數據進行多維度分析和計算,并由此構建糖尿病數據倉庫,提取葡萄糖、甘油三酯、血清尿酸、載脂蛋白、總膽紅素、血清白蛋白等14個屬性作為特征變量,通過決策樹機器學習方法實現對糖尿病的分類,糖化血紅蛋白測定值在4%~6%(或己糖激酶GLU-HK在3.9~6.1 mmol/L)為正常參考范圍;糖化血紅蛋白>6.5%均視為糖尿病,分類為“糖尿病”“妊娠期糖尿病”“糖尿病合并冠心病”等共計8類,選取與8類相關的處理后的結構化病歷數據作為樣本數據,供機器學習,形成知識庫。
3.5 系統實現
系統構建在虛擬化平臺上,采用VMware虛擬化軟件。虛擬化軟件運行在3臺高檔服務器和2臺高檔存儲上,服務器配置4顆Intel Xeon E7-4820 v4緩存,內存256 GB DDR4 2400 MHz,硬盤5×600 GB;存儲配置2個SAN+NAS統一存儲節點,支持SAN和NAS存儲模式;存儲網絡交換機2臺,各含12個16 GB短波SFP,交換能力≥768 GB/s。虛擬主機安裝Windows Server 2003 R2操作系統,使用多臺虛擬主機分別運行應用服務軟件、數據集成平臺、數據庫服務軟件。
系統通過集成平臺Health Connet與醫院其他信息系統的數據進行集成,抽取當前HIS和兩個歷史HIS庫中病歷數據488916份到數據中心,通過疾病名篩選、樣本病例庫數據的標準化、專家修訂和機器自學建立糖尿病、白血病兩種疾病模式,將臨床決策支持系統模塊嵌入我院門診醫生工作站,輔助醫生臨床診療決策。
4 結語
基于疾病模式的臨床決策支持系統構建是在對醫院產生的醫療真實數據,采用人工智能等大數據處理方法建立起疾病模式的基礎上,依據信息系統獲取的病人的當前信息,實現對醫生診療過程的個性化建議。將CDSS整合到門診醫生站后,幫助門診醫生進行臨床診斷輔助決策支持。統計入院方式為門診入院的確診糖尿病病人,以今年3月份277例出院糖尿病門診診斷符合率為98.2%和去年3月份252例出院糖尿病門診診斷符合率為95.2%比較,門診診斷質量有所提高。下一步針對肺結核、肺癌等疾病,構建相應疾病模式,開展進一步探討,提升臨床診療質量和安全管理能力,更好的服務于患者。
猜你喜歡
中老年保健(2022年5期)2022-08-24 02:35:42
中老年保健(2022年1期)2022-08-17 06:14:56
中老年保健(2021年5期)2021-08-24 07:07:20
中老年保健(2021年9期)2021-08-24 03:51:04
中老年保健(2021年7期)2021-08-22 07:42:16
中老年保健(2021年3期)2021-08-22 06:49:56
中老年保健(2021年11期)2021-08-22 03:15:16
中國生殖健康(2020年2期)2021-01-18 02:51:44
中國生殖健康(2018年2期)2018-11-06 07:11:04
基層中醫藥(2018年2期)2018-05-31 08:45:04
