自然災害智能化應急救援信息系統關鍵技術研究
2018-10-31 05:46:10劉錫鈴張世良
韶關學院學報 2018年9期
關鍵詞:用戶
劉錫鈴,張世良
(寧德師范學院 計算機系,福建 寧德352100)
自然災害日益嚴重的問題已引起了我國政府和學術界的高度重視.由于城市地形分異明顯,地質環境復雜,氣候頻繁,各類自然災害頻繁發生,尤其是洪水和干旱每年都會發生.臺風,冰雹,暴風雪,沙塵暴,山崩,山體滑坡,泥石流等地質災害,風暴潮,海嘯等海洋災害,森林大火,重大生物災害等自然災害造成的氣象災害傷亡事故,經濟損失高達數十億元,對城市的生命財產造成了嚴重破壞.自然災害通常是暴力的,破壞力巨大,帶來破壞的持續時間長.自然災害可能會造成傷亡,對財產造成巨大損失,并造成相當程度的混亂.災難事件持續的時間越長,對受害者的威脅越大,事件的影響也越大[1].
災害影響的程度與人們能否收到足夠的預警有關.構建一個具有智能決策功能的自然災害應急平臺,形成一套標準化的應急救援平臺變得十分重要.隨著大數據時代的到來,數據體現了時空動態性、復雜性、多尺度性、不確定性、復雜和多用戶態,傳統系統中的分析方法無法滿足大數據的處理,結合當前主流技術,提出構建應急救援系統智能處理通用庫算法、多源、異構空間數據的集成、融合與共享以及嵌入時空信息到地圖的無盲點時空數據可視化等關鍵技術,依據不同用戶形態,不同數據形式以及不同應用需求,通過選擇不同處理算法,實現不同服務應用的智能化處理.
1 多源異構數據集成與融合技術
由于自然災害時空數據來源廣泛,數據源結構變化多樣,沒有統一的標準,具有很大不確定性;數據源隨著時間變化,增加、變更或者修改數據源的時候,要求系統能夠適應這樣的變化;數據量巨大,處理需要占用大量系統資源,如何應用來自多部門的異構數據是一個需要解決的問題.數據融合方法和元數據提供了持續可靠地應用多源數據的手段,需要設計一種可注冊的自然災害異構數據源集成策略,可以方便集成各種結構、半結構或者非結構數據源;發揮 Hadoop的集群優勢,為不同客戶端提供統一的Web Service 接口[2].
自然災害數據源加載程序可以完成自然災害數據源的集成,包括數據源注冊,數據提取,數據清理,數據模型統一和數據存儲.自然災害數據源加載器采用策略模型,解釋器模型和工廠方法模式設計,可以根據不同的數據源動態調整加載策略,也可以適應數據源的變化,滿足需求不同的事件加載和異構數據源的集成[3-4].該模型采用分層體系結構,將系統劃分為數據源層(文件,數據庫和其他形式),數據加載層(ETL工具),數據管理層,業務邏輯層和表示層等功能類別.模型框架結構見圖1.數據源層向系統提供數據.這些數據不能直接使用.數據加載層需要被提取,清理,轉換并加載到ODS中.ODS以增量的方式向數據倉庫提供歷史數據.業務邏輯層為數據訪問提供Web服務接口,并完成數據查詢,修改和處理任務.表示層提供了不同的客戶端來根據用戶需求查詢、分析、下載和可視化數據.解決多源異構地理大數據建立自然災害和大數據集成的統一框架,建立高度可擴展的數據集成模型,實現數據源的“即插即用”,實現軟件模塊化的目標模型;從基礎數據模型層面,統一自然災害大數據的表達,組織和管理;為多源異構地理數據提供統一的參考,一致的訪問模型和集成處理機制.
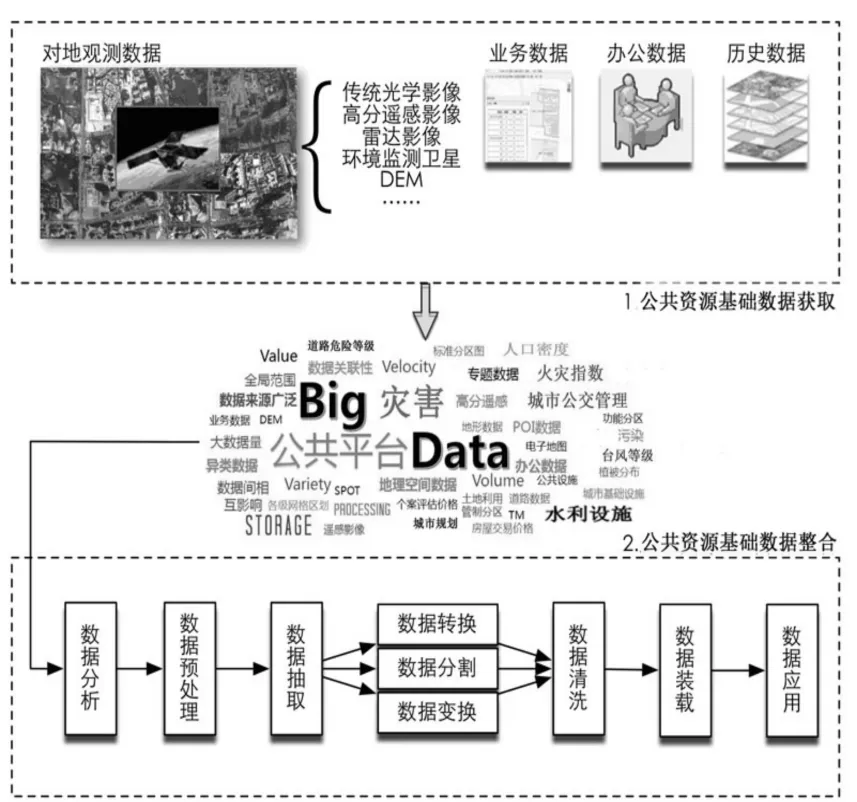
圖1 多源數據集成融合
2 空間信息服務云數據管理技術
自然災害擁有大量的數據.數據處理需要大量的系統資源.傳統的單節點計算機或服務器無法完成處理海量數據的任務.自然災害數據處理需要確保數據處理的響應時間,并且盡可能縮短用戶的等待時間.用戶體驗.基于云計算模型的開源Hadoop被用于通過Map Reduce操作將任務分發到不同的計算節點,并且使用并行計算來提高數據處理效率.該框架極大地簡化了分布式計算的復雜性并確保了數據處理的響應時間.為了消除不同應用服務在實施和訪問方面的差異,降低數據存儲和維護成本,服務器的S端結合云服務的虛擬化和分布特性,并使用數據資源標識符HGML和行業身份XXML在應用程序服務層.實現空間信息的統一交換與描述,并實現空間信息資源管理與集成云服務架構.在空間信息服務云中,其數據資源由“物理云”,“網絡云”和“存儲云”組成,并通過數據注冊中心向G端用戶提供數據訪問服務[5-6].空間信息服務云的體系架構見圖2.
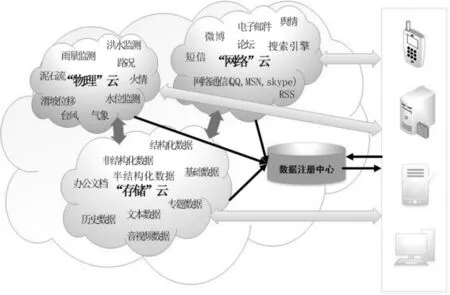
圖2 數據獲取流程
由于大數據資源數據涉及國家安全,數據保密等級要求高,為此在公共服務平臺提供大數據資源和數據服務時需要考慮訪問者身份的安全性、數據交換的安全性和數據存儲的安全性.針對大數據資源數據安全問題,采用基于粒計算的大數據資源數據安全服務框架,通過雙向虛擬身份(Virtual Identities,簡稱VID)的細粒度訪問控制保證數據的安全和用戶訪問行為的限制.高安全等級的大數據資源數據通過數據粒化分類成數據塊以VID的形式呈現給用戶.用戶通過系統安全認證后獲得VID,與數據實體的VID之間通過角色細粒度訪問控制機制建立連接.系統提供認證、授權、統計、審計和計費的A4C(Authentication,Authorization,Accounting,Auditing&Charging)服務框架,運行數據對象的粒化與角色屬性粒化的安全機制,保證大數據資源和數據服務的安全性.
3 無盲點時空數據可視化技術
開發一種全新的能夠把時間顯示無縫集成到地圖的無盲點的時空數據可視化技術.總的目標是支持在保存空間信息的路網圖上做時空格局分析.為了更加精確,在分析某個道路的屬性的時間模式時,希望能夠考慮到的鄰域信息,例如是否該小區道路貫穿的是商業或住宅,以及周邊道路網絡的拓撲結構.這個目標適用于不同類型的任務和用戶.例如,調查交通阻塞的分析師可能希望查明當擁塞發生時的情況,加上了解到的周圍基礎設施信息來推測為什么擁塞發生.計劃跨越城市旅行的人可能在他們出發的時候,希望找到最不塞車的路線而且沿線有加油站.對于在電視上發表對現在正在變化事件的記者來說,他們可能要在空間路網地圖上顯示一些收集的圖片.需要同時分析空間和時間的應用.應用4種類型的時空任務:天氣表征估計在一個大空間區域不同時間段的屬性的趨勢和變化;本地表征估計在局部區域不同時間段的屬性的趨勢和變化;模式檢測定位在其發生的時間和空間位置的屬性的一個特定的圖案;圖案的比較在不同的時間和空間區域比較的屬性值的模式.
新技術的開發將遵循可視化的原則“首先概述,縮放和過濾,然后根據需要提供詳細信息”.概覽首先向用戶提供在地圖上顯示的各種數據的分布.用戶可以直接在地圖上滑動并放大一條或多條道路.將在地圖上使用稀疏的道路空間,同時最大限度地減少其他扭曲.將開發用于擴大縫焊的算法,以擴大道路的選定部分并引入足夠的空間以在地圖上嵌入時間顯示.也將研究編碼時間方向的選擇,因為道路可以是任何坡度,方向總是從左到右或從下到上,但這些方法在這里不適用.有很多方法來表示時間的方向,例如文本標簽,視覺符號,顏色,甚至動畫.我們將進行研究,比較各種方法,并評估其有效性和效率.為了評估內聯視圖的優缺點,我們必須將此方法與傳統的鏈接視圖進行比較.最后,我們將新的可視化工具應用于不同應用程序的各種分析任務.
4 建立通用算法庫
對自然災害資源數據的特點建立其對應的數據智能處理算法庫,利用聚類算法實現分布式處理節點的選擇,數據子集的劃分,用戶的分群,數據質量的提升等數據處理過程;利用分類算法實現用戶的分群,用戶行為的判別,用戶服務的決策,高維數據屬性的約簡等處理過程;利用數據屬性降維方法去除數據的冗余屬性和決策不相關屬性,并通過屬性降維得到數據的主要特征,加快數據后續處理的過程的同時,提供決策對間的準確性;利用矩陣分解技術進行高維數據稀疏,數據的特征選擇,高維數據隱藏信息發現等方面;基于負載均衡理論的大數據分割算法實現負載均衡理論為基礎,研究最佳的數據分配方案,使得多個節點能夠在同樣的時間內完成任務,避免因為單個任務的拖延,導致整體任務實時性減低等算法.通過粒化把大量復雜信息按照其各自的特征和屬性劃分成塊,方便管理控制,這些塊稱之為粒[7-8].智能算法庫依據所提取或學習到的數據特征和屬性構建準則進行.
針對大數據資源大數據自身以及其應用的特點,提出針對資源特定應用的新方法.通過MapReduce分布式處理框架,實現聚類、分類等現有算法的分布式處理,加快算法的執行速度.基于分布式減法聚類的不完整數據填充算法,利用改進的減法聚類算法對整個數據集進行聚類.為了提高聚類算法的效率,利用云計算技術對聚類算法進行優化,實現基于多級MapReduce的分布式減法聚類算法.然后根據聚類結果和加權距離對缺失值進行填充,在保證數據填充精度的同時大幅度降低了填充過程的處理時間.此種離線的數據質量提升算法,能夠為其他數據處理過程提供準確的結果支撐.考慮分布式處理模型的調度機制,以最少的模型開銷,達到最優的數據處理結果.對于離線數據(變為單層選擇機制),通過數據分類選取基于數據主題(礦產、耕地、商業用地等)的分布式數據存儲節點,然后對特定主題數據進行分布式處理;關于在線數據,首先根據離線方法選擇分布式數據存儲節點,然后通過存儲節點的特征標簽與新到在線數據比對,選取最終的數據服務節點,中間過程包括數據標簽的更新、重構.通過張量網絡統一表示資源結構化數據和文本、圖片等非結構化數據,利用高階SVD分解等相關技術降低數據維度,并利用深度計算方法綜合挖掘分析數據隱藏的潛在價值.
5 結論
針對目前自然災害還沒有較高通用性的城市智能化應急救援信息系統的現狀,立足于滿足日益增長的應急救援數字化、智能化管理的需要,進行可復用的面向大數據智能決策的自然災害救援信息系統所需的關鍵技術的研究.提出了自然災害基礎數據獲取、整合與標準化機制,通過研究數據的標準和結構,把握數據的基本情況,把自然災害觀測數據、業務管理數據、辦公數據、歷史檔案數據等自然災害數據中可利用的部分抽取出來,進行各種加工轉換整合,然后對經過“粗加工”的數據進行深層“清洗”,最后裝載到統一的“數據倉庫”上,進行數據應用與服務;提出了適應于結構化、半結構化及非結構化數據的可靠存儲系統,可以為多源異構自然災害大數據任務提供后臺存儲系統在讀寫效率、速度及吞吐率上的重要支撐;針對不同用戶形態,不同數據形式,以及不同應用需求,選擇不同處理算法,達到不同服務應用的自然災害大數據智能處理技術算法庫,可以為自然災害大數據的服務應用提供多選擇、多匹配、實時快速的響應需求.
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
