從FRBR-LRM到IFLA LRM
2018-11-02 01:16:08蔡丹羅翀
山東圖書館學刊 2018年5期
蔡 丹 羅 翀
(國家圖書館,北京 100081)
1 引言
1961年,著名的“國際編目原則會議”所確立的《巴黎原則》曾對國際編目的規范化和標準化產生過深遠的影響。此后,圖書館資源從數量到類型的迅猛增長,機讀目錄的異軍突起,讀者需求的與日俱增,都迫使業界重新審視《巴黎原則》對編目環境的適應度,確立國家級記錄的“基本要求”以解決編目積壓和促進書目信息交換成為一種新的思路,《書目記錄的功能需求》(Functional Requirements for Bibliographical Records,簡稱FRBR)應運而生。在其影響下,《規范數據的功能需求》(Functional Requirements for Authority Data,簡稱FRAD)和《主題規范數據的功能需求》(Functional Requirements for Subject Authority Data,簡稱FRSAD)隨之產生,三者均以“實體—關系”(Entity-Relationship)為框架建立模型,將對書目領域的研究延伸至規范控制領域,由此構成了彼此補充,相互聯系又各自獨立的“概念模型家族”。
然而,分立建模也存在明顯的局限性,主要表現在:即使針對相同的問題,其界定及處理方法也存在差異;平面結構使模型重復冗贅;在一個編目系統中同時使用三個模型存在障礙等。對模型的統一與完善由此提上了日程。模型的統一版編制由FRBR評估組下屬的統一版編輯組(Consolidation Editorial Group,簡稱CEG)負責。該項工作始于2013年,經過三年的努力,2016年2月模型草案編制完成,并被命名為“FRBR圖書館參考模型”(FRBR-Library Reference Model,簡稱FRBR-LRM)。草案于2016年5月進行了全球評審,CEG隨即匯總反饋意見并著手修改草案。修改之后的草案以新名稱“IFLA圖書館參考模型”(IFLA-Library Reference Model,簡稱IFLA LRM)示人,并提交至IFLA專業委員會審議。2017年8月,IFLA LRM最終獲得批準并正式發布。
除名稱變化之外,相較于草案,正式版在框架結構、實體定義、屬性特征、關系類型等方面均有一定程度的變化。IFLA LRM是概念模型,雖不能直接作為編目規則使用,但卻是制定編目規則的基礎。基礎發生變化,勢必會對編目規則的修訂產生重大影響。可以預見,以FR家族為基礎的國際編目規則——《資源描述與檢索》(Resource Description and Access,簡稱RDA)即將依據IFLA LRM進行大規模修訂。
從草案到正式版,多方面的變化值得總結,變化背后的原因更值得思考。筆者通過對草案和正式版的詳細比對,洞悉兩者差異,探究變化原因,以期促進IFLA LRM的未來研究,進而明確其即將對編目規則的修訂帶來的影響。
2 主要變化
2.1 名稱的變更
從草案到正式版,最顯著的變化莫過于名稱由“FRBR-LRM”改為“IFLA LRM”。變化背后其實有著多方面的考慮:首先,FRBR本身的含義具有明顯的局限性。“FR”指功能需求,容易誤導理解為計算機系統的需求,而“BR”指書目記錄,但是模型實際上已經涵蓋了整個書目世界,其范圍已遠遠超出了“書目”的范疇;其次,該模型是FR家族三模型的合并版,如果名稱上僅出現FRBR,則FRAD和FRSAD的信息無法體現。目前,圖書館、檔案館、博物館等正尋求使用統一的信息組織標準,RDA就是一個突破圖書館藩籬的范例,但是模型之所以依然保留了“圖書館”(Library)的字樣,是因為計劃為這幾類機構分別建模之后,再建立跨界的統一版。為了清晰表達模型依然僅應用于圖書館范疇的內涵,正式版還增加了一個副題名“書目信息的概念模型”(A conceptual model for bibliographic information)。
2.2 框架體系的變化
從整體結構來看,正式稿變化并不大,僅增加了第七章“建模術語詞匯表”,將草案中的第七章“參考來源”變為第八章,且章名變為“參考概念模型”。然而,縱覽模型全文框架體系,還是可觀諸多變化:
2.2.1 整體結構更邏輯化
為了提升模型的邏輯性,正式版中添加了若干匯總性的表格,便于用戶概覽。最主要的是在正式版4.2(屬性)和4.3(關系)部分添加了若干表格,分別是表4.3(屬性層級表)、表4.6(關系層級表)、表4.5(按名稱排序的屬性索引表)、表4.8(按域排序的關系索引表)。添加之后使屬性和關系的文本變為,正式內容的列表之前是層級表,正式內容的列表之后是索引表。這樣的結構無疑大大增加了文本的邏輯性,使屬性和關系得到很好的歸納總結,從而一目了然。
關于層級表,模型認為由于實體具有層級結構,附著于實體的屬性和關系也因此具有層級特征。其中屬性層級表部分內容如表1所示。
模型將頂層實體“Res”的屬性“類別”列為頂層屬性(第3列),該屬性可被分為子類型,從而為“Res”實體的子類實體(如作品、內容表達、載體表現、單件)提供“類別”屬性,而這些子類實體的“類別”屬性被列為低層屬性(第4列),其他屬性由于不是某個屬性的子類型,因此模型將其均列于頂層屬性。關系層級表的部分內容如表2所示。
模型認為只有與頂層實體“Res”相關的關系才是頂層關系(第1列),其他所有關系都是頂層關系的細化,均屬于第2層關系(第2列)。為使列表更為緊湊,模型僅列出了關系名稱(第3列),未列出反向關系名稱。
關于索引表,模型將屬性按名稱進行排序,將關系按關系中的領域的編號進行排序。其中屬性索引表的部分內容如表3所示。
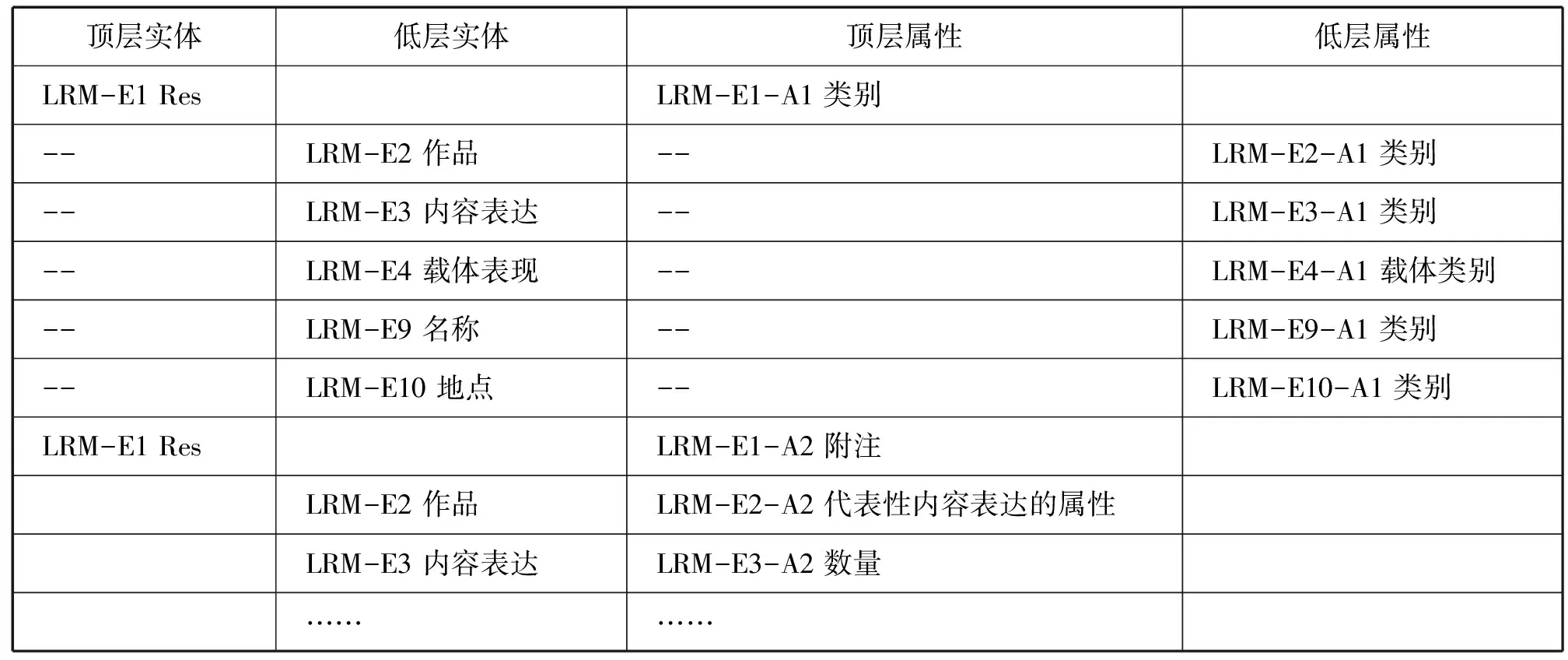
表1 屬性層級表[1]

表2 關系層級表[2]
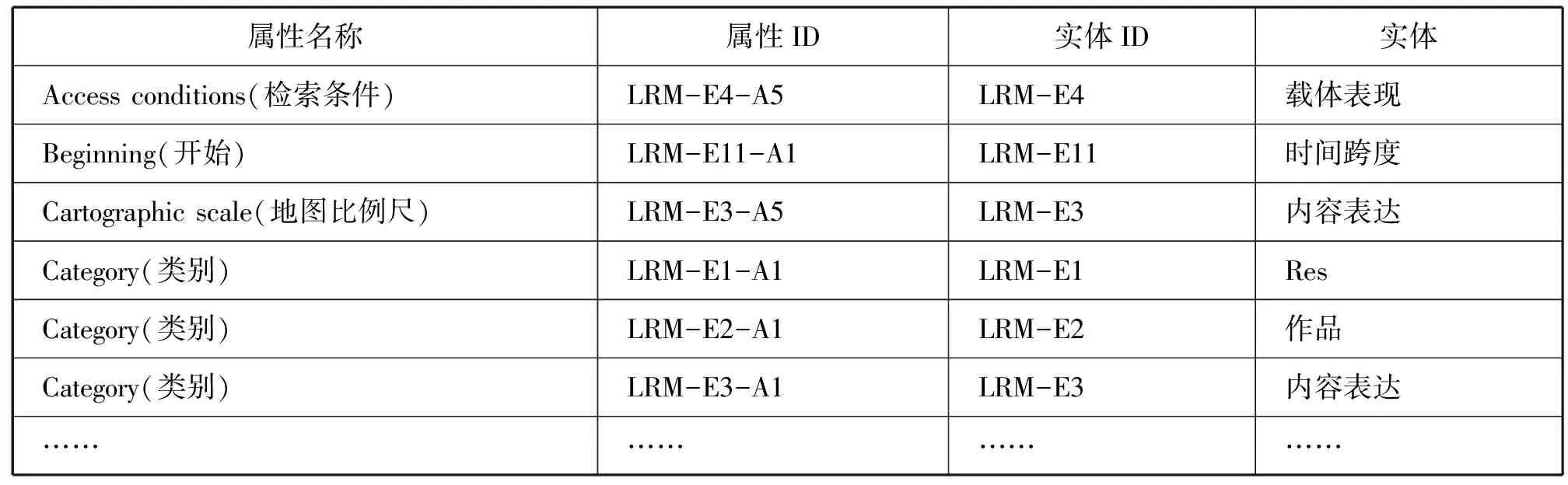
表3 屬性索引表[3]
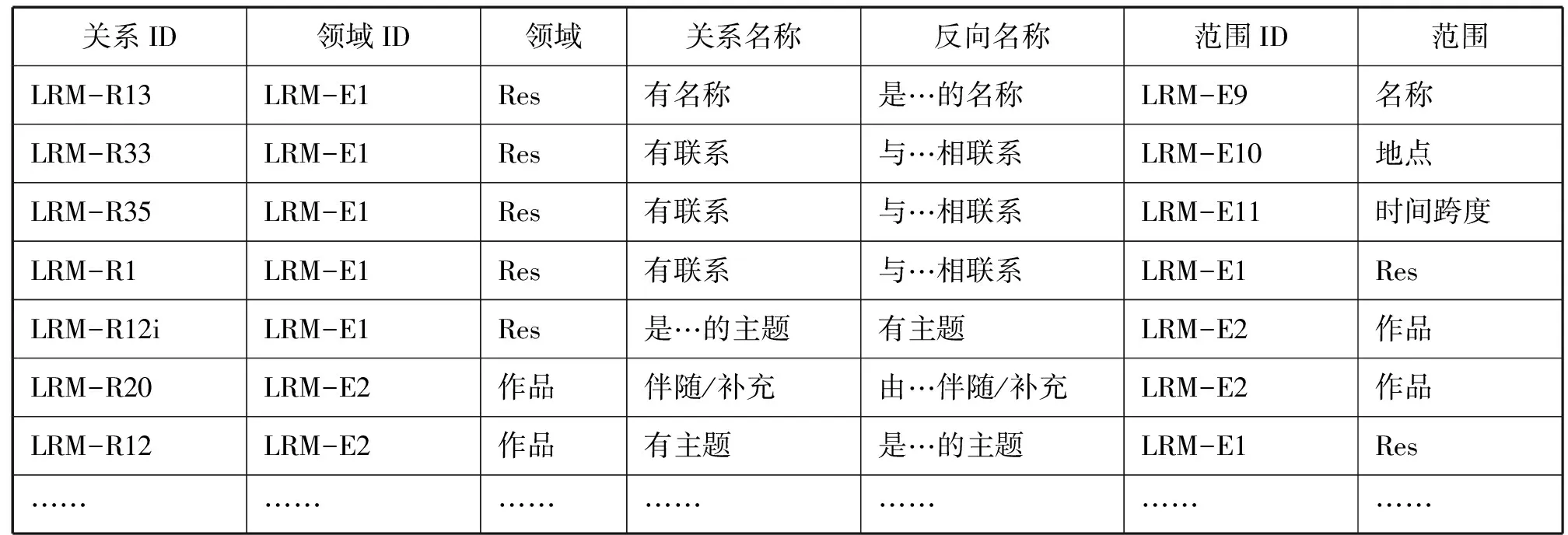
表4 關系索引表[4]
表格按屬性名稱的字母順序排序,列于第1列,當不同實體的屬性名稱相同時,再按實體編號排序。后面三列分別列出了相應的屬性編號、所屬實體編號以及實體名稱。關系索引表部分內容如表4所示。
模型根據關系中作為領域的實體編號對關系進行排序(第2列),領域實體相同的,再按關系名稱的字母順序排序,若仍相同,進而按關系中作為“范圍”的實體編號排序。第1列是關系編號,如果是反向關系,則在關系編號后加“i”,如“LRM-R12i”是“LRM-R12”的反向關系,即“Res是作品的主題”,其對應的正向關系是“作品有主題Res”。
調整模型的編號體系可以說是正式版提升邏輯性的又一舉措。在草案中,屬性的編號體系構成為“模型名稱—屬性序號”,所有屬性不標識其所隸屬的實體,均按序號進行大排序,如實體“內容表達”的屬性“數量”的編號為“LRM-A6”,實體“載體表現”的屬性“載體類別”的編號為“LRM-A13”。在正式版中,屬性編號體系構成變為“模型名稱—實體編號—屬性序號”,如上述為“LRM-A6”的編號變為“LRM-E3-A2”,“LRM-A13”變為“LRM-E4-A1”。新的編號體系既直接表明了屬性所隸屬的實體,還間接反映了每個實體所定義的屬性數量,模型的邏輯性和文本的可讀性由此大大增強。
2.2.2 標識符更明確化
模型中提供了大量樣例,樣例標識符的合理使用能夠使用戶更好的理解模型中紛繁復雜的概念。正式版對樣例標識符的修訂主要體現為兩點:一是,“Res”實體的實例置于大括號內這一做法得以全面落實,草案中只有“Res”實體的實例加了“{}”,正式版為其他實體中表示“Res”實例的樣例均添加了“{}”;二是,正式版為實體“名稱”(Nomen)新增了一個屬性,即“名稱字符串”(nomen string),為了將其與“名稱”實體的實例加以區分,正式版規定將代表“名稱”實例的術語置于單引號內,而將“名稱字符串”屬性的值置于雙引號內。例如,‘Agatha Christie’是指代實體“個人”{the person Dame Agatha Christie,Lady Mallowan}的“名稱”,而拉丁字母字符串“Agatha Christie”是“名稱”的屬性值。
值得注意的是,“Res”可以理解為表象背后的本質,是最抽象的概念,在正式版中,“作品”“個人”“集體代理”“地點”和“時間段”幾個實體均可歸入“Res”,因此需添加“{}”,而“內容表達”“載體表現”“單件”幾個實體不能視為最抽象的“Res”,而是與“作品”相關聯的具象化的實體,因此這些實體的實例沒有添加“{}”。另外,“Res”與“名稱”以及“名稱字符串”之間的區別和聯系也至關重要。“Res”是事物本質,其實例需要通過與其相聯系的實體“名稱”來指代,而“名稱”又需要通過“名稱字符串”這一屬性來識別。
此外,在定義關系時,正式版修改了名稱術語,將原來的“正向關系”全部改為“關系名稱”。筆者認為原來“正向關系”與“反向關系”相對應,似乎二者地位對等,修改之后,則打破了對等地位,而強調了從領域到范圍的關系。
2.3 用戶任務的變化
在用戶任務方面,正式版與草案相同,仍然是“查找”“識別”“選擇”“獲取”和“探索”五項,內容上也無實質變化,僅對個別用戶任務的定義及釋義在措辭上進行微調。例如,將“查找”和“識別”任務中的“實體”(entities)均改為“實體的實例”(instances of entities),這一變化更符合用戶檢索行為的實際情況。又如,在“選擇”任務的定義中刪去了與用戶任務本身重復性的文字“選擇”,使文字更加凝練,同時在其釋義“……從而讓用戶做出決定”之后添加了“并付諸行動”(act on it),因為“選擇”的目的不是決定而是行動。再如,草案中“探索”任務的定義表述為“To use the relationships between one resource and another to place them in a context”[5],而正式版表述為“To discover resources using the relationships between them and thus place the resources in a context ”[6],增加了反映任務目的性的短語“發現資源”,從而明確表達了“探索”的關鍵意義,不僅是“利用關系”,更重要的是要由此及彼,找到意想不到的資源。
2.4 實體的變化
正式版與草案相較,所定義的實體從名稱到數量均未變化,仍為11個實體,發生變化的是某些實體的定義和范圍注釋。其中,定義發生變化涉及5個實體,有的變化僅是措辭上的微調,如“內容表達”定義中的“系列”(constellation)一詞改為了“組合”(combination);有的是刪除了部分文字,如“單件”定義中刪除了“物理的”(physical)和“由制作過程產生的”(resulting from a production process),反映出單件不一定是物理載體,還可能是電子載體,也不一定是在制作過程產生,也可能自然存在,使其范圍更加廣泛;有的是增加了一些文字,如“集體代理”定義從原來的“作為一個單位活動”(acting as a unit)變為“能夠作為一個單位活動”(capable of acting as a unit),強調了集體代理實施活動的能力,這樣與實施責任關系的聯系更緊密;有的是表述完全被改變,如“名稱”的定義,草案中表述為“一個實體為人所知的名稱”(A designation by which an entity is known)[7],正式版變為“一個實體及指代其的名稱之間的關聯”(An association between an entity and a designation that refers to it)[8],以關系的角度來表述“名稱”的定義,從而更準確地表達了“名稱”是實體“Res”與“名稱字符串”之間紐帶的內涵。
范圍注釋發生變化涉及9個實體,例如,“作品”的范圍附注中增加了關于內容相似的不同作品的判定;“載體表現”的范圍附注中增加了關于產生了新的載體表現的判定;“名稱”的范圍附注中引入了“名稱字符串”屬性,強調“名稱”本質上是實體“Res”和字符串之間關系的具體化;“地點”強調了作為空間范圍的地點和行政管轄區的區別;“時間跨度”增加了時間范圍的精度等。
2.5 屬性的變化
模型對屬性定義的指導思想與草案相同,即盡量保持模型的通用性,提取實體具有高度代表性的屬性,并非窮盡所有,也并非要求實體的所有實例都具備這些屬性。從整體來看,模型所定義的屬性數量沒有變化,仍為37個,但其中刪除了兩個,增加了兩個,此外,模型還重新定義了一些屬性。
2.5.1 新增的屬性
正式版新增了兩個屬性,分別是實體“作品”的 “代表性內容表達的屬性” (representative expression attribute)和實體“名稱”的“名稱字符串”(nomen string)。
作為實體“作品”的新增屬性,“代表性內容表達的屬性”是指“對體現作品特征具有重要意義的屬性,其值取自作品有代表性的或典型的內容表達”[9],例如,莎士比亞的作品“哈姆雷特”的一個“代表性內容表達的屬性”是“語言”,其值為英語。關于該屬性,模型在5.6有專門說明,涵蓋了幾層含義:一是,有代表性的內容表達通常是首個或原始內容表達,但由于某些作品內容表達衍生歷史的復雜性,其代表性內容表達的屬性可能并未出現在原始內容表達中,而是基于終端用戶的文化推斷和約定俗成;二是,該屬性的值嚴格來說,涉及的是內容表達的特征而非作品的特征,但由于特征對描述和識別作品很有用,因此,相關內容表達屬性的值可以名義上“轉移”給作品并用于作品的識別;三是,該屬性依作品類型而有所不同,且是多值的,例如,對于文本作品,“語言”“讀者對象”可以作為代表性內容表達的屬性;對于音樂作品,“調”“表演媒介”可被選作代表性內容表達的屬性;對于地圖作品,“地圖比例尺”“投影”可被選作代表性內容表達的屬性。
作為實體“名稱”的新增屬性,“名稱字符串”是指“構成一個通過‘nomen’與某實體相聯系的名稱的符號組合”[10]。實體“名稱”的字符串可以任何形式的標記符號來表示,如字母組合、數學符號、化學結構符號等。在真實世界里,同一實體可通過多個“名稱”來指稱(如同義詞),而“名稱字符串”屬性的值在沒有語境的情況下,對于不同實體的實例來說也有可能是相同的(如一詞多義或同形異義)。但是,在書目系統的受控環境中,實體“名稱”的屬性“名稱字符串”被消除了歧義,從而做到每個“名稱字符串”僅與一個“Res”實體的實例相聯系。
2.5.2 刪除的屬性
正式版刪除的兩個屬性分別是實體“內容表達”的“代表性”(representativity)和實體“名稱”的“狀態”(status)。
“代表性”是指“說明被視為代表‘作品’的‘內容表達’是否實現”[11],僅有兩個取值“是”和“否”,用于標記特定上下文中具有代表性的內容表達。該屬性已經被正式版中“代表性內容表達的屬性”所取代。
“狀態”是指“‘名稱’建立體系中‘名稱’的狀態”[12],其取值在自然語言中包括“廢棄的”“文學的”“方言的”,在正式體系中包括“提議的”“臨時的”“廢棄的”“當前有效的”。不難看出,該屬性屬于管理型元數據,對圖書館終端用戶任務沒有影響,因此不在本模型范圍之內,正式版中予以刪除。
2.5.3 重新命名或定義的屬性
正式版重新命名和重新定義的屬性主要是文字表述上的一些變化,屬性內涵并沒有實質性的改變,但從表述來看更加恰當、準確。其中,重新命名的屬性有4個,分別是“比例尺”(scale)變為“地圖比例尺”(cartographic scale),有三個實體的屬性名稱從“權利”(rights)變為“使用權利”(use rights)。重新定義的屬性有10個,基本都是措辭的微調,例如,“附注”的定義中刪除了“文本材料”,突破了附注形式的局限性;“表演媒介”的定義中刪除了與屬性名稱重復的文字,改為表述更準確的“演奏工具的組合(聲音、樂器、合奏等)”;載體表現的“檢索條件”和“使用權利”兩個屬性的定義中均將“載體”(carrier)改為“物理載體”(physical carrier),使概念表達更為具體;將名稱實體的“語言”和“文字”兩個屬性中的“被表達”(is expressed)分別由“被證實”(is attested)和“被標記”(is notated)替代等。
2.6 關系的變化
模型正式版定義了36種關系,比草案多兩種,同時對部分關系的定義進行了重新描述,并調整了很多關系的順序編號。
2.6.1 新增的關系
正式版增加的兩種關系分別是LRM-R25內容表達之間的集合關系(expression was aggregated by/aggregates expression)和LRM-R28單件和載體表現之間的復制關系(item has reproduction/is reproduction of manifestation)。
內容表達之間的集合關系被定義為“表明某個作品的一個特定內容表達被選作一個計劃的集合內容表達的一部分”[13]。該關系有兩層含義:一是,一個集合內容表達選擇不同作品的特定內容表達集中在一起;二是,被選中的特定內容表達在一個集合載體表現中被一起具體化。該關系與原有內容表達之間的“整體—部分”關系有所區別,那種關系適用于那些所實現的作品本身就是整體—部分關系的情形,而新定義的關系中集合和被集合的內容表達所實現的作品并不存在整體—部分的內在特質。從模型所列出的樣例可以發現,叢編就被認為是內容表達集合關系的一種體現,例如:叢編“IFLA series on bibliographic control”可以看作一個集合內容表達,它集合了“ISBD:International standard bibliographical description”2011年統一版的英文文本這個特定的內容表達。模型在5.7“集合的建模”中詳述了集合作品、集合內容表達和集合載體表現之間的關聯,本文不再贅述。
單件和載體表現之間的復制關系被定義為“向終端用戶提供完全相同的內容,一個特定的單件為后來載體表現的創造提供來源”[14]。該關系強調的是作為復制來源的單件具有重要特征,如特殊的起源,或是特殊的所有權標記,或是有特殊的注釋等。該關系不同于原有的載體表現之間的復制關系,那種關系通常指重印或再版,在選擇復制來源時無需選擇載體表現中的特定單件,即便是選擇了特定單件作為復制來源,該單件也被認為代表的是載體表現的整體。
2.6.2 重述定義的關系
正式版對原有的10種關系的定義進行了重述,主要是措辭的變化或擴充,此外還包括兩種關系方向的反轉,但關系實質并未發生變動,其中變化較多的關系如“載體表現和代理之間的制作關系”(MANIFESTATION was produces by AGENT)變為了“生產關系”(MANIFESTATION was manufactured by AGENT),使其范圍涵蓋了工業生產及手工產品的范疇;“Res”和“名稱”之間的關系定義中“為人所知的符號或符號組合”變成了“一個給定體系或環境中被賦予的符號或符號組合”,從而將對“Res”和“名稱”的理解限定在了特定的書目環境之內,消除了理解上的歧義;作品之間的“整體—部分”關系,方向發生了反轉,草案中的正向關系是“作品是整個作品的部分”,反向關系是“整個作品有部分作品”,而正式版中變為正向關系是“整個作品有部分作品”,反向關系是“作品是整個作品的部分,這樣似乎更合乎常人的邏輯,即先說整體,再說部分;內容表達之間的整體部分關系亦發生了類似的反轉。
2.7 其他變化
正式版除了上述變化之外,其他主要變化是在第5章增加了兩個小節,分別是5.2“實體和校準之間的限制”和5.3“在線發行的建模”。前者主要說明了實體的不相交性,即某個實體的實例不可能同時是另一個實體的實例,對于由于人們對同一實例的不同理解而導致的認為其屬于不同實體的情況,模型認為可以通過附加新的實體和關系進行模型的擴展。后者主要說明了在線發行過程中產生的單件、載體表現甚至內容表達之間的關聯,在應用中,也可以通過附加“數字單件”實體對模型進行擴展,從而為數字發行情況建立更清晰的模型。
3 IFLA LRM對RDA的影響
IFLA LRM是FR家族概念模型的統一版。自1998年FRBR產生之后,編目界的變革有目共睹。可以預見,IFLA LRM的正式發布將對編目的未來產生不可忽視的影響,首當其沖的就是對RDA的影響。RDA的編制機構“RDA指導委員會”(RDA Steering Committee,簡稱RSC)已于2017年2月在其官方網站發布了一份聲明,明確表示“要采用IFLA LRM作為修訂RDA的概念模型,從而取代FR家族模型(FRBR,FRAD,FRSAD)…… RDA Toolkit的重構重建項目(RDA Toolkit Restructure and Redesign Project,簡稱3R)將以當前RDA實體和元素與LRM的兼容為目標,并將使用LRM來指導RDA Toolkit適應國際社區、文化遺產社區以及關聯數據社區的修訂。”[15]此外,RSC還就LRM的影響與其他相關工作組達成了協調機制,包括FRBR評估組、ISBD評估組、ISSN國際中心、PRESSoo評估組,以及UNIMARC常務委員會,保證信息互通。該聲明還簡要列出了一些RDA會作出的變化,如引入全新的實體——集體代理、名稱和時間跨度,整合已經隱含的實體——代理和地點;將現有的個人、家族和團體實體作為代理和集體代理實體的子類,適當整合歸納相關說明;需要對RDA中個人的定義進行重大修改,將其范圍限定在真實的人類,虛擬的、非人類實體以及責任說明中出現的筆名等交替名稱的處理將列入新的“名稱”實體予以說明;LRM允許屬性和關系互換的方式使RDA元數據使用的范圍得以擴展等。
RSC的上述聲明發布時IFLA LRM尚未正式通過,但其認為最終版本不會有太大變化,決定將盡早啟動修訂工作。因此,目前在RDA Toolkit上已經出現了LRM的身影,RDA正文中已經引入LRM的實體“代理”,在相關章節都采用了新的術語,如第三部分“記錄個人、家族和團體屬性”變為“記錄代理的屬性”,第六部分“記錄個人、家族和團體的關系”變為“記錄代理的關系”,第九部分“記錄個人、家族和團體之間的關系”變為“記錄代理之間的關系”,附錄I“關系說明語:資源和與資源相關的個人、家族和團體之間的關系”變為“關系說明語:作品、內容表達、載體表現和單件和與資源相關的代理之間的關系”,附錄K“關系說明語:個人、家族和團體之間的關系”變為“關系說明語:代理之間的關系”[16]。此外,還在各部分的一般性規則中介紹了“代理”的概念。
然而,RDA的3R項目并非易事,RDA Toolkit已發布聲明表示該項工作將于2017年4月正式開展,計劃歷時一年,將于2018年4月完成此次重大改版[17]。同時,RDA Toolkit的改版還希望廣大使用者的參與并完善用戶資料信息,“以用戶為導向”的最高原則再次體現,讓我們積極投身其中并拭目以待。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
科學大眾(2022年11期)2022-06-21 09:20:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
臺聲(2016年2期)2016-09-16 01:06:53
山東青年(2016年1期)2016-02-28 14:25:25
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
海外英語(2006年11期)2006-11-30 05:16:56
