區域經濟與城市稅收合理性配置分析
2018-11-22 09:30:28趙偉光
統計與決策 2018年20期
趙偉光,劉 晶
(1.中央財經大學 財政稅務學院,北京 100081;2.首都經濟貿易大學 城市經濟學院,北京 100070;3.齊魯工業大學 金融學院,濟南 250100)
0 引言
我國的稅收收入自分稅制度改革以來一直呈增長趨勢,與GDP年平均增長率相比,同期稅收收入增長已遠超出它的范圍。城市稅收是經濟政策的重要組成部分,利用稅收增加財政收入,促進區域經濟的發展是國家制定稅收政策的主要目的。我國學者認為稅收超增長的原因主要有三個因素:一是經濟因素,二是管理因素,三是政策因素。但目前我國有關稅收超增長的研究,特別是在隨機生產的基礎上,全要素生產率增加對中國稅收超增長各因素的貢獻率研究方面還僅局限于理論,實證方面的研究還較少。目前國內外學者對于城市稅收政策的研究大都集中于納稅人角度,且線性回歸、數據調研分析等研究方法比較單一,部分學者采用了隨機生產邊界模型,但是實質性的征管變量卻并未引入,未對產業區域進行分類。因此,本文基于隨機影響模型研究區域經濟與城市稅收兩者之間的關系。
1 隨機生產邊界模型的構建與檢驗
1.1 隨機生產邊界模型的構建
Meensen最早提出了隨機生產邊界分析方法,這種分析已經成為衡量經濟學中生產效率的工具之一。隨機前沿生產函數模型為:
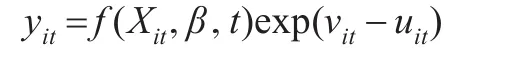
其中,yit指i在t時期的產出,Xit指投入向量,包含各種要素的投入;t指生產邊界隨時間變化的可能性,表示前沿技術進步的趨勢。考慮到生產函數的包容性問題,本文選擇超越對數生產函數作為研究稅收征管投入產出的生產函數形式。這是因為超越對數生產函數不僅包含所有投入要素的產出彈性、技術進步、技術非中性、技術效率和要素間替代彈性,還能退化成柯布·道格拉斯生產函數,因而具有較強的說服力。投入要素包括稅務人員投入(P)、第二產業增加值(G2)、第三產業增加值(G3)等變量,前者為稅務機構方面的投入,后兩者則是地方經濟體系可以利用的客觀資本投入,需要說明的是,基于第一產業稅收占總稅收的比例已經不足0.002,因此未將其計入投入要素中。生產函數具體如下:
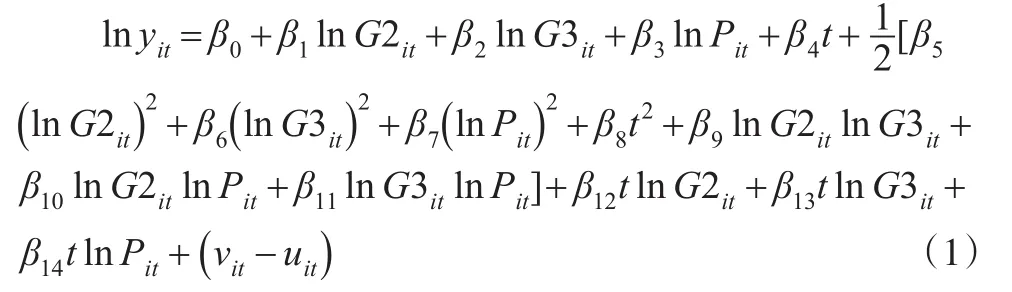
其中,yit用來表示不同省市稅務局和區域稅務局稅收量,而各要素的投入向量以Xit為代表。本文中的稅務人員是指在稅務機構上投入的人力,而地方經濟體可利用的客觀稅基指的是第二產業、第三產業的增加值。投入要素中并沒有加入第一產業,是因為其稅收收入不足總稅收的一半。本文將2012年的時間變量t記作數字1,并依次往后遞增,來衡量稅收征管中各因素所產生的作用。Christensen指出在結構模型中,超越對數生產函數模型也屬于平方反應面模型,它具有變替代彈性、易估計和包容性強等特點。因此,本文使用超越對數生產函數模型,來解決傳統函數模型無法衡量技術進步的缺點。
1.2 技術效率方程的構建
式(1)的生產函數中,其隨機擾動項是由vit和uit構成的。其中,vit表示經典白噪聲,uit表示非負隨機誤差項。這代表了低效率項目的生產(技術效率TEit=exp(-uit))。如果假設uit=0,TEit=1,則其表示為個體生產技術的完整效率狀態;但是如果將uit比作0的數字時,TEit就比1小,這代表了邊界生產中的個體生產,生產效率比較低下。學者對υit的分布假設提出了各種觀點,目前在實際應用中最常見的是Battese、Corra的假設,設定其服從非負截尾的半正態分布。在此基礎上,根據υit變化形式設定的不同,隨機生產邊界模型也有很多種形狀。該模型假設vit具有指數線性增長率,根據線性系數是否為0,將模型分為兩種:
Ti指生產單位i的最后一個時期,μ指衰退參數,當μ比0大時,生產單位的非效率水平就隨時間遞減,當μ比0小時,生產單位的非效率水平就隨時間增加。
在實際計算中,具體的操作步驟是:先使用模型估計方程,然后對估計出來的參數進行檢驗,如果假設成立,說明模型適用;若不成立,說明模型不適用。這里重新設定了技術效率方程式,以表達uit的形式和使用方法:
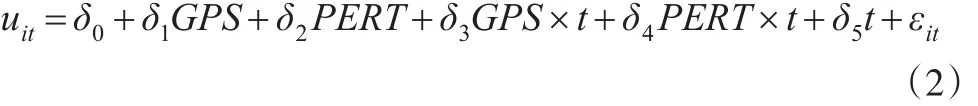
式中,GPS為第二產業增加值占總值的比重,它突出了區域經濟結構的特點;而第三產業增加值除以稅務人員總數得出的數值則用PERT代替,這表示了稅源的集中度。
1.3 模型形式的檢驗
通過對上述方程式的檢驗建立隨機生產邊界模型,得到:
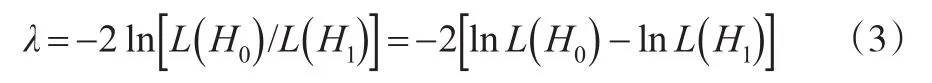
1nL(Ho)用來表現受限制的隨機邊界模型的對數似然函數,那么無限制的隨機邊界模型的對數似然函數表示形式為1nL(H1)。當(Ho)成立時,其限制隨機變量的數量為自由度,得出結論:統計需要遵守混合卡方的部署。
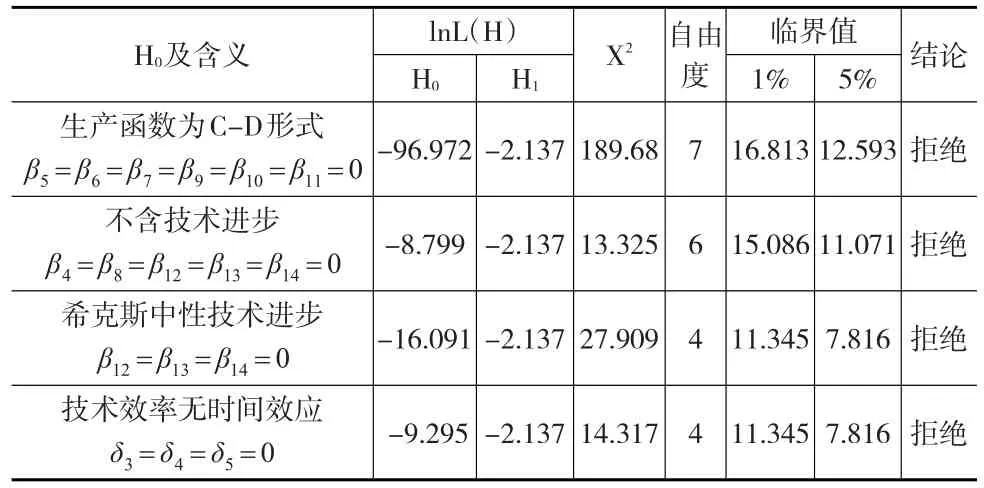
表1 函數形式的檢驗
從表1中可以看出,顯著性水平5%下,其所列的四項假設被對系數的似然比檢驗拒絕了,這也證明了本文隨機生產邊界模型建立的正確性。
1.4 基于隨機生產邊界模型的TFP增長分解
詳細了解全要素生產率,并從稅收征管效率的角度出發,計算出稅收TFP增長率的公式為:
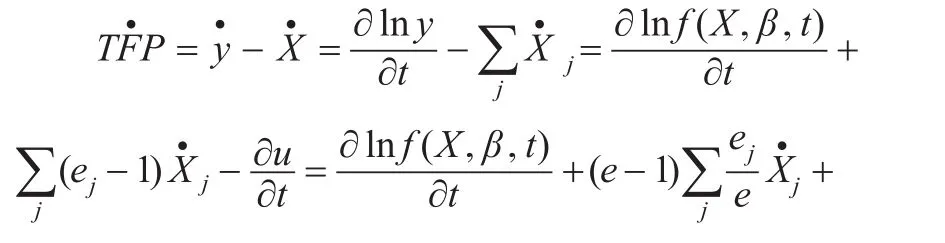
其中,J為各個省市的稅收收入總量,X為各種要素的投入向量,“·”代表相應變量的增長率,例如是投入要素j的稅收收入彈性,規模彈性則是為投入要素j占總成本的份額,這是為了使
在研究了稅收TFP增長之后,可以將其分成以下四個方面:
通過以上分析可知,稅收TFP增長率可以分為三項:前沿外移、技術效率變化、規模效率。公式如下:
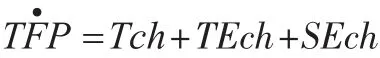
2 實證分析
2.1 模型估計
本文選取我國31個省份的省會城市面板數據作為調查對象,隨機生產邊界模型需要通過GDP(國內生產總值)、第二產業和第三產業的增加值來構建,2016年《中國統計年鑒》提供了分行業附加值的數據,《中國稅務年鑒》提供了稅務機構人員數目和稅收各部門的收入的數據。通過分析提供的數據可知,隨機生產邊界模型估計結果如表2所示。
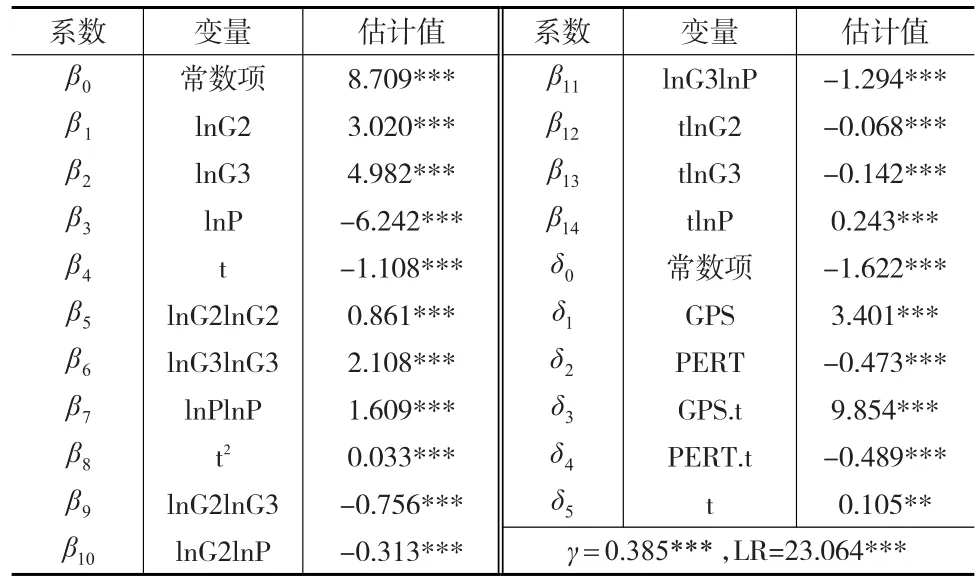
表2 隨機生產邊界模型估計結果
經過對隨機生產邊界模型的研究可以得到γ的統計量為,說明在對其的研究中加入技術非效率和隨機誤差項是有效的,主要是因為實際的稅收收入無法與最優稅收收入相比較,總體概括就是缺乏技術效率。
2.2 TFP增長分解結果
對本文選取的省份的TFP增長值進行分析,所得結果如圖1所示。
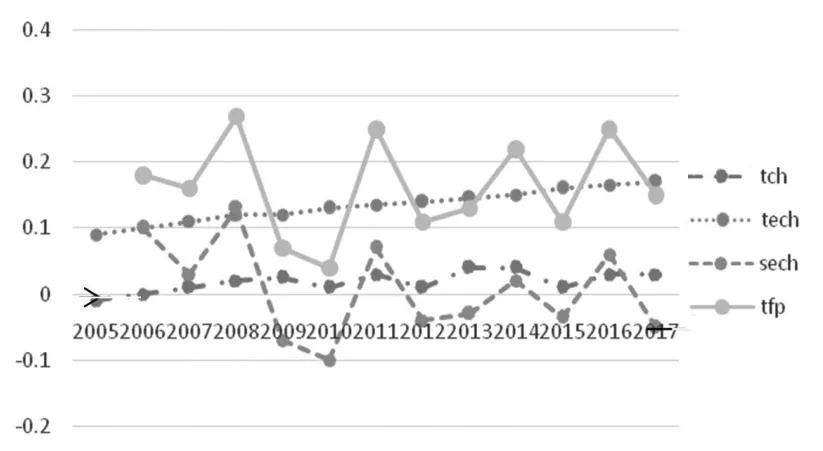
圖1 TFP增長分解示意圖
從圖1中可以看到,提高稅收的征管率可以增加稅收全要素的生產率,因為稅收征管率的平均貢獻率已經到達頂峰。近幾年,技術效率一直呈穩中有升的發展趨勢,說明了我國稅務人員的稅收征管效率在穩步高升。促使稅收征管技術效率不斷提升的主要原因是:我國對稅務人員的學歷水平和實踐能力要求不斷提高,所挑選出來的稅務人員都是經過專業化培訓的,因此稅收征管技術效率才會不斷提升。
前沿外移也是促進我國稅收TFP增長的一個因素,而潛在稅收能力的提高,主要歸功于可稅稅基的擴展。一方面,完善征稅可以降低逃稅率;另一方面,稅收制度的調整雖然降價了稅費,但稅費的征收由于行政因素仍然呈現一種懶散至嚴格的形式,而且,對改革燃油稅、購置車輛稅等稅費也增加了稅基。從圖1中可以看出,前兩年的邊界轉型是負增長,但后來一直保持正增長,說明前沿外移的貢獻率早在2007年規模效率是負數的情況下達到10。
規模效率的起伏比較大,主要因為規模效率與技術效率和前沿外移不一樣。規模效率截止到2008年一直呈正數增長并且數值比較大,不過到2009年就出現了變動,一直呈負數增長并且數值也為負數,從這里就可以看出波動比較大。從公式(1)可以看出,規模效率的增加是由每個輸入元件的輸出彈性決定的。從圖2中可以看到稅收彈性的變化。
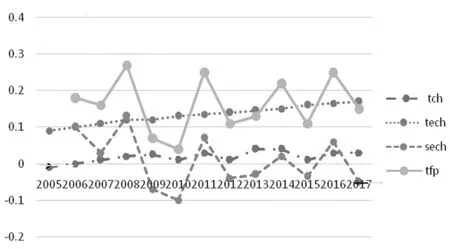
圖2 各投入要素的稅收入彈性示意圖
從圖2中可以看出稅務人員的納稅收入情況,在2013年和2014年的時候呈正數,除此之外都是負數,這說明使用純粹人力投入提高稅收是行不通的,雖然規模效率低下,但是第二、第三產業總增值稅收收入彈性一直保持在1以上,說明提高單位的GDP就可以增加單位的稅收,具體來說就是經濟要素的投入具有規模效率。導致這樣的結果一方面是因為稅制具有漸進性,所以可以通過提高稅收達到想達到的目的;另一方面GDP表征增量的概念,而稅基(課稅基礎)表征總量的概念,它們之間的概念性質是不一樣的。
3 結論
本文選取我國31個省份的省會城市的面板數據建立隨機生產邊界模型。使用Kumbhakar法來分析稅收全要素生產率的增長情況,結果顯示:(1)稅收征管效率的不斷提升是形成我國稅收增長的主要原因,造成這一現象的原因主要與各稅務機關和個人主動納稅意識的強度有關。(2)費改稅的平均貢獻率高于12%,這也是形成我國稅收增長的一個原因。(3)稅收的超增長現象,表現了現在社會經濟發展規模的高效率以及人力資源投入規模的無效率,由此可見,稅務機關以“粗放式”投入人力的做法是造成規模效率因素貢獻值為負數的主要原因。因此,要采用政府與市場機制相結合的方式來促進我國區域經濟的發展,保證我國經濟的優化和區域經濟的協調發展。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
小學科學(學生版)(2020年10期)2020-10-28 07:52:12
甘肅教育(2020年14期)2020-09-11 07:57:42
數學物理學報(2020年2期)2020-06-02 11:29:24
中國化肥信息(2020年7期)2020-03-19 01:54:02
中國軍轉民(2017年6期)2018-01-31 02:22:28
光學精密工程(2016年6期)2016-11-07 09:07:19
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國衛生(2014年11期)2014-11-12 13:11:32
