自動回復系統(tǒng)中基于焦點的問題分類
2018-11-22 00:46:50劉淑婷
微型電腦應用
2018年11期
關鍵詞:語義
劉淑婷
(西安翻譯學院 工程技術學院,西安 710105)
0 引言
醫(yī)保卡自動回復系統(tǒng)的建設補充了現(xiàn)有的咨詢渠道,實現(xiàn)了信息及時、高效地傳遞,方便參保用戶通過短信平臺及時咨詢醫(yī)保繳費、報銷、辦理流程等問題,用戶能隨時了解參保情況,并享受醫(yī)療保險待遇,提高了西安市人社局的辦公效率和對參保用戶的服務質(zhì)量,在參保用戶與西安市人社局之間建立了一種快捷、高效、方便地的溝通渠道。
1 自動回復系統(tǒng)
自動回復系統(tǒng)目的是將精確答案發(fā)送到用戶手機上,并將已發(fā)送信息保存到數(shù)據(jù)庫中備查[1]。按照處理順序分為問題理解、信息檢索、答案抽取[2]。問題理解是對問句進行分析,包括詞法分析、語義分析、問題分類,其準確度直接影響后續(xù)階段的處理[3]。信息檢索是在文檔集合中利用問題理解抽取出來的關鍵字查找出相關的文檔[4]。答案抽取是從信息檢索得出的文檔中提取與問題相關的段落生成答案[5]。自動回復系統(tǒng)的主要流程如圖1所示。
2 基于焦點的問題分類
問題理解需要對問題語句做出分類,并對問題的類型、語義和答案類型等進行定性和定量。問題分析的質(zhì)量限定了備選答案的范圍,并減少了答案的搜索空間,決定后續(xù)步驟采取的處理策略。
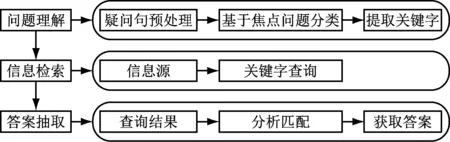
圖1 自動回復系統(tǒng)的主要流程
2.1 利用問題焦點分析分類的優(yōu)勢
傳統(tǒng)的問題分析在對問題分析完成后留下的是關鍵詞和一些對關鍵詞的擴展,將句子分割成詞,降低了語言表達能力,并且丟失了詞語之間的關系,而問題焦點表示的問題分析在輸出關鍵詞集合的同時,還完整的保留了問句的句式結(jié)構(gòu)和語義。……
登錄APP查看全文
猜你喜歡
小學時代·科學小問號(2024年10期)2024-10-31 00:00:00
開放教育研究(2020年2期)2020-03-31 01:54:14
中國社會歷史評論(2016年2期)2016-06-27 07:11:52
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
長江學術(2016年4期)2016-03-11 15:11:31
中學語文·大語文論壇(2015年1期)2015-05-30 22:02:35
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語言與翻譯(2014年2期)2014-07-12 15:49:25
語文知識(2014年2期)2014-02-28 21:59:18
當代修辭學(2011年6期)2011-01-29 02:49:50
