小語料庫重慶話語音識別的研究
2018-11-28 09:21:34,,
計算機測量與控制 2018年11期
, ,
(重慶第二師范學院 數學與信息工程學院,重慶 400065)
0 引言
語音識別技術[1]是人機交互領域的重要研究內容,解決了人機交互過程中計算機不能夠聽懂人說話的問題。語音識別技術起步于上世紀五十年代,發展至今已經取得了長足的進步。國內外很多科技公司都在語音識別領域進行了深入的研究。如谷歌、微軟以及科大訊飛等公司已經走在了語音識別領域最前沿。目前研究語音識別主要的研究對象是主流的語言,而關于方言的研究就相對少些。
重慶話是重慶地區方言文化,承載著重慶本地的傳統文化,人口覆蓋超過3 000萬。近些年來,重慶的電子信息產業已經成為重慶經濟的重要增長極,在2012年重慶市提出的“兩江有云,西永有端,南岸有網”的電子信息產業發展總戰略布局背景下,人工智能產品將在重慶各個領域廣泛應用。語音識別是人工智能領域的重要組成部分,實現了計算機能“聽懂”人的語音。重慶話語音識別的研究將有助于實現重慶地區的人們能夠自然地利用重慶話與人工智能產品進行交流,實現“人機對話”,從而讓人們享受到科技發展給生活帶來的便利和高效。
1 重慶話的發音特點
重慶方言雖然也屬于漢語,但是和漢語普通話存在一些差異。在聲母方面的差異,漢語普通話有21個聲母[2],而重慶話中沒有翹舌聲母/zh/、/ch/、/sh/以及鼻音聲母/n/;重慶話只有17個聲母[3-6],重慶話不能區分/n/和/l/,也就是說沒有鼻音聲母/n/,并且通常把聲母/h/讀成/f/。在韻母方面的差異,漢語普通話共有39個韻母[2],而重慶話只有37個韻母[3-6],沒有/ing/和/eng/這兩個后鼻音韻母,多一個/vu/,少一個/ui/。漢語普通話、重慶話的聲母和韻母分別如表1、表2、表3和表4。

表1 漢語普通話聲母表
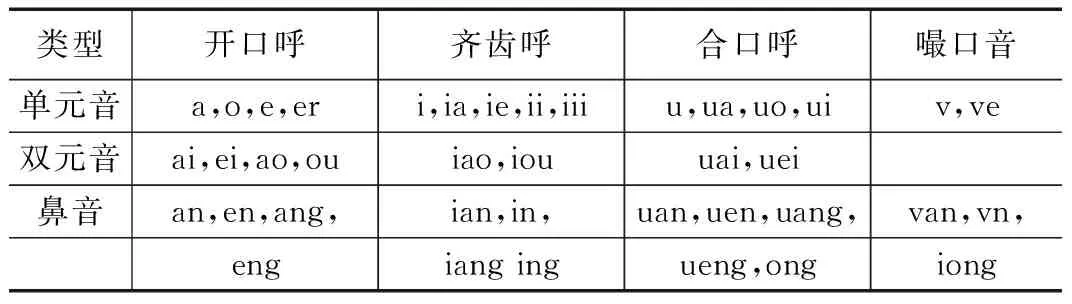
表2 漢語普通話韻母表
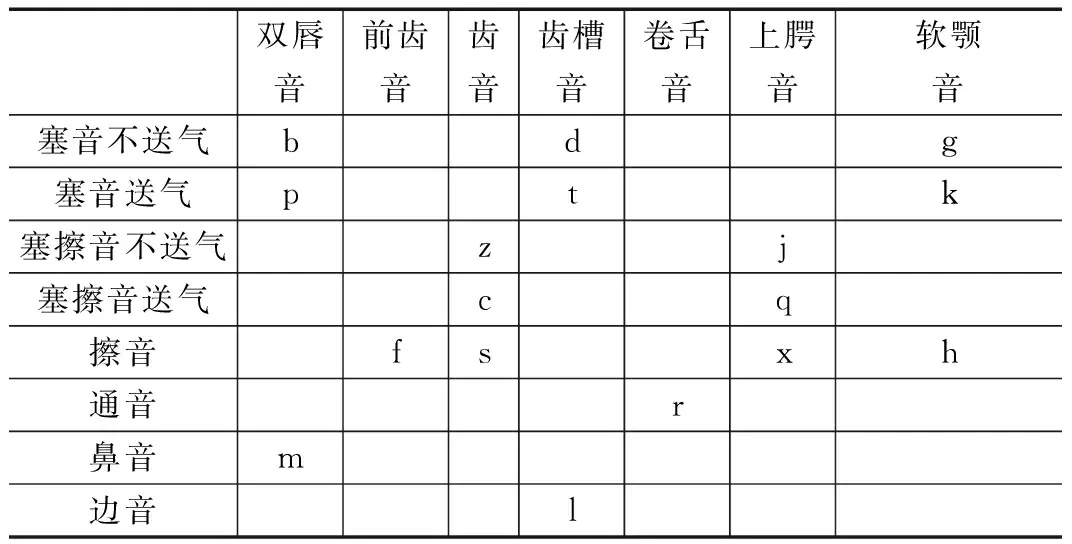
表3 重慶話聲母表
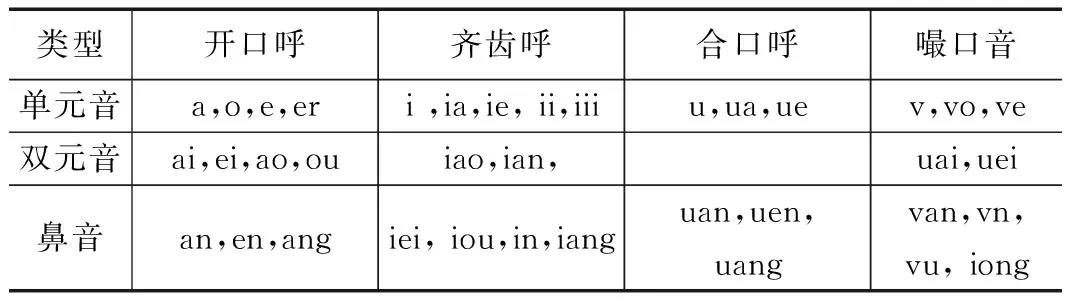
表4 重慶話韻母表
2 重慶話識別方法
簡單來講,重慶話語音識別是利用聲學模型匹配方法將輸入是語音識別系統的待識別語音與經過訓練的聲學模型進行模式匹配,并按照一定的判別規則得到待識別語音對應的文本信息。
2.1 訓練方法
語音識別過程中需要對語料庫中的語音基元建立聲學模型,并對語音基元的聲學模型的參數進行訓練[7],得到含有語音特征信息的聲學模型。對建立的聲學模型的狀態轉移概率進行重估訓練,重估訓練的方法如公式(1)所示。
(1)
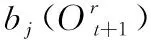
(2)
從HMM模型的非發射入口狀態進入HMM模型的由公式(3)嵌入式重估完成。
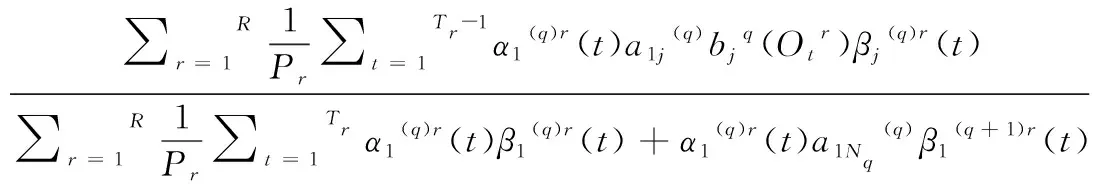
(3)
然后,從HMM模型進入HMM模型的非發射入口狀態由公式(4)嵌入式重估完成。
(4)
最后,從HMM模型的非發射入口狀態進入HMM模型的非發射入口狀態由公式(5)嵌入式重估完成。
(5)
在公式(2)、公式(3)、公式(4)以及公式(5)中的下標q表示嵌入式重估的次數,如果q沒有明顯的標注出來,嵌入式重估的輸出概率分布公式和單個模型的輸出分布是一樣。然而,概率計算公式必須將公式(6)變成公式(7)才能實現從入口狀態的轉移。
(6)
(7)
語音識別中訓練聲學模型的方法較多,以上7個公式僅僅是語音識別中對聲學模型進行重估訓練所涉及的基本公式。
2.2 識別方法
語音識別過程就是待識別語音的聲學模型和聲學模型庫中的模型進行匹配,得到匹配度最高的聲學模型即是識別結果。待識別語音的聲學模型和聲學模型庫中的語音的匹配過程采用維特比算法實現。本文基于HMM模型的維特比算法基本思想是從觀測序列O=(o1,o2,o3,...,ot)中求取給定模型λ=(A,B,π)下的最大似然概率。維特比算法用于語音識別解碼的公式[7]如下所示。
給定一個模型M,設Φj(t)表示在t時刻觀測到語音序列從O1到Ot處于j狀態的最大似然,那么Φj(t)如公式(8)所示。
(8)
其中:i和j為不同的狀態,aij為狀態轉移概率,bj(ot)為輸出概率密度如公式(9)所示。
(9)
其中:cjsm是第m個分量的權重,Ν(o;μ,Σ)是具有均值向量μ和協方差矩陣Σ的多元高斯模型,ost是在時間t觀測向量被分成s個獨立的數據流。
3 重慶話識別過程
重慶話語音識別是將重慶話語音識別成文本的過程。重慶話語音識別分為兩個過程,即訓練過程和識別過程。其中訓練過程是利用語料對聲學模型進行訓練,最終得到聲學模型庫;識別過程是將待識別的語音進行預處理,然后提取語音的特征參數,最后利用相應的識別方法實現語音識別,并對識別結果進行分析得到識別結果。重慶話語音識別過程如圖1所示。
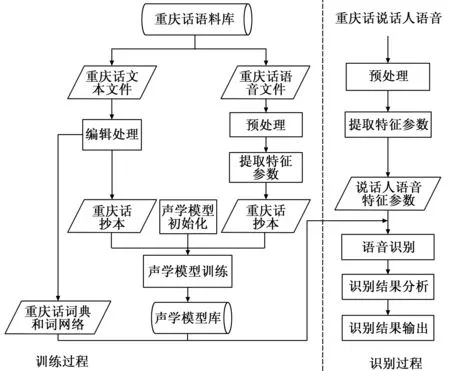
圖1 重慶話語音識別過程
3.1 建立重慶話語料庫
首先采集本實驗需要的語音文件對應的文本,選擇重慶話和普通話發音標準的錄音人;然后按照實驗方案分別錄制重慶話語音30句,重慶話口音的普通話語音30句,每句語音發音10遍,共得到(30+30)*10句語音;最后由重慶話語音以及重慶話口音的普通話語音文本和與之對應的語音文件形成語料庫。
語料庫由訓練集和測試集組成,訓練集中包含(30+30)*7句語料,測試集中包括(30+30)*3句語料。其中測試集細分為(30+30)*1句、(30+30)*2句以及(30+30)*3句。語料庫中語音對應的文本如表5所示。
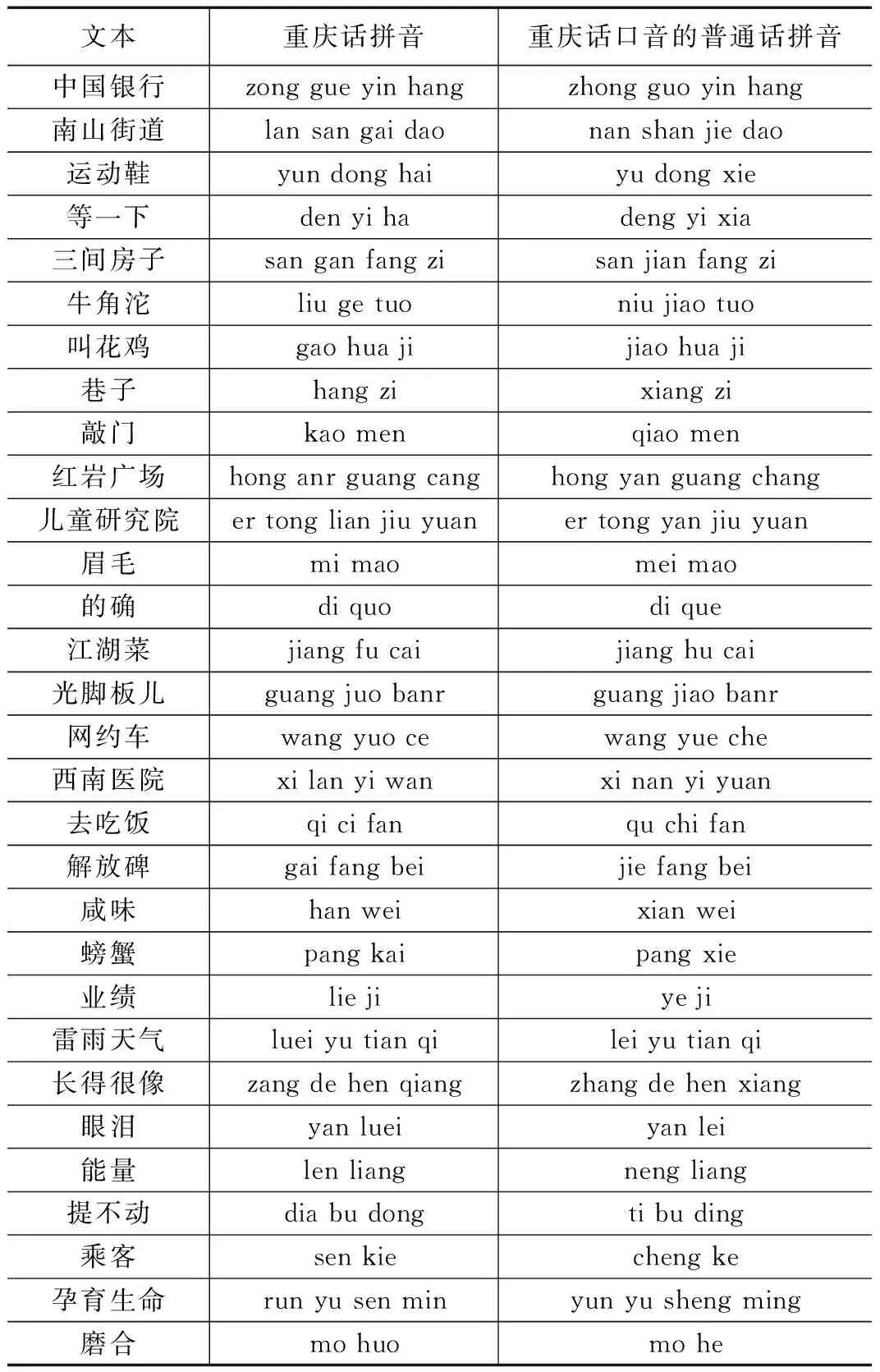
表5 重慶話語料庫文本與發音對照表
3.2 語音預處理
語料庫中的語音是連續且非平穩的信號,而非平穩的信號不便于處理,因此需要對語音信號進行預處理。預處理包括采樣量化、分幀加窗以及預加重等過程。
1)采樣量化是將連續語音信號轉換成離散數字信號。本實驗的語料庫采用的采樣量化標準是16 kHz采樣、16 bit量化。
2)分幀加窗是為了將語音信號進行短時化處理,我們可以認為語音信號長度在10~30ms時為準平穩信號,因此需要對語音信號加窗函數以實現短時化處理。常用的窗函數有矩形窗、哈明窗以及哈寧窗等,根據語音信號的特點,本文選取哈明窗函數,如公式(10)所示。
(10)
3)預加重是為了解決高頻低功率譜的問題,即語音信號在高頻部分呈現低能量,而低頻部分呈現高能量的現象。在對語音信號進行處理分析過程中需要提高語音高頻部分的功率譜,因此需要預加重處理。
3.3 提取特征參數
語音信號含有大量的信息,包括基頻、時長以及頻譜等基本聲學參數,也包括語音韻律等信息。為了便于對語音信號的處理,去掉一些不太重要的冗余信息,因此需要對語音信號提取能夠表征語音信號的相關參數,即語音信號特征參數。語音特征參數常見的語音特征參數有線性預測系數(linear predictive coefficients, LPC)、線性預測倒譜系數(linear predictive cepstral coefficients, LPCC)、基于Mel頻率倒譜系數(mel frequency cepstral coefficients, MFCC)[8-9]。本論文根據聲學建模的需要,選擇接近人耳對語音信號頻率的感知特性的特征參數。以上3種參數中的基于Mel頻率倒譜系數(MFCC)作為特征參數。Mel頻率與Hz頻率之間的映射關系如公式(11)所示。
fMel=(1000/lg2)×lg(1+0.001fHz)
(11)
MFCC特征參數的產生過程如圖2所示。

圖2 MFCC參數提取過程
本文對語音信號提取的信號是12維的MFCC特征參數,為了反應語音信號的停頓及重音等參數需要加上1維短時平均能量構成13維特征參數,并且為了表示語音的動態特征,需對13維的特征參數求取一階差分和二階差分得到39維的特征參數。
3.4 訓練聲學模型
語音基元是發聲的基本單元,本文是以重慶話的聲韻母為語音基元,因此要為參與模型訓練的聲韻母建立聲學模型。常用的聲學模型較多,其中隱馬爾可夫模型(hidden markov model, HMM)[10-12]是應用很廣泛的聲學模型。HMM模型是由“單鏈”的馬爾可夫演變為“雙鏈”而來,其中一條隱藏的鏈描述了狀態的轉移,產生了不可觀測的狀態序列;另外一條可見的鏈描述了狀態和觀測值之間的統計對應關系。觀察者只能通過可見的觀測值來感知狀態的轉移關系。五狀態的HMM模型如圖3[13]所示。

圖3 5狀態的HMM模型
從圖3中可以看出,由于5狀態的HMM模型左右兩端的狀態只起到前后連接作用,這兩個狀態并沒有高斯分布,因此5狀態的HMM模型只有中間3個狀態有狀態轉移。
聲學模型p(y|x,λ)在HMM模型中方可以變換如公式(12)所示。
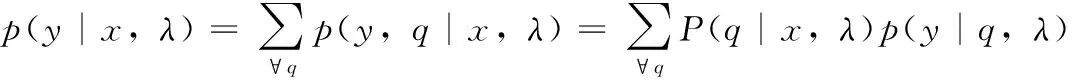
=
(12)
其中:P(·)表示一個概率密度函數,p(yt|qt,λ)是第qt個狀態的狀態輸出概率密度,它是一個典型對角協方差矩陣的單高斯分布,并且q={q1,...,qT}是HMM狀態序列。
為每一個語音基元建立了HMM模型之后,需要對HMM模型進行重估訓練,訓練方法如2.1節。對訓練后的HMM模型建立HMM模型庫,模型庫中包含了(30+30)*7句語料的所有基元對應的聲學模型。
3.5 語音識別
語音識別是將待識別的語音識別成對應文本的過程,即在聲學模型和語言模型下,對待識別語音的特征參數進行解碼,從而將語音識別成對應的文本。
語音識別過程分為4個大組,每1個大組再以測試語句細分為30句、60句以及90句3個小組,共計12組語音識別實驗。具體的實驗方案設計如下:
1)利用重慶話語音庫中訓練集的語料訓練語音模型,重慶話語音庫中測試集的語料為測試語句。
2)利用重慶話口音的普通話語音庫中訓練集的語料訓練語音模型,重慶話口音的普通話語音庫中測試集的語料為測試語句。
3)利用重慶話語音庫中訓練集的語料訓練語音模型,重慶話口音的普通話語音庫中測試集的語料作為測試語句。
4)利用重慶話口音的普通話語音庫中訓練集的語料訓練語音模型,重慶話語音庫中測試集的語料作為測試語句。
4 識別結果
根據以上4個大組,共12個小組的實驗方案分別進行識別實驗,并將實驗結果整理如表6所示。
從表6中可以看出,重慶話和重慶口音的普通話對應識別自己本身的正確識別率為100%,而兩種語音交叉進行語音識別則呈現出不同的正確識別率。其中重慶話聲學模型去識別重慶話口音的普通話在不同的測試集下呈現出不同的識別結果,當測試集為30句和60句時均為76.67%,而在90句時達到78.89%;重慶話口音的普通話聲學模型去識別重慶話在不同的測試集下也呈現出不同的識別結果,隨著測試集語句數的增加,正確識別率總體趨勢上也隨之增加,并在30句時達到90.00%,60句和90句時分別達到91.67%和91.11%。
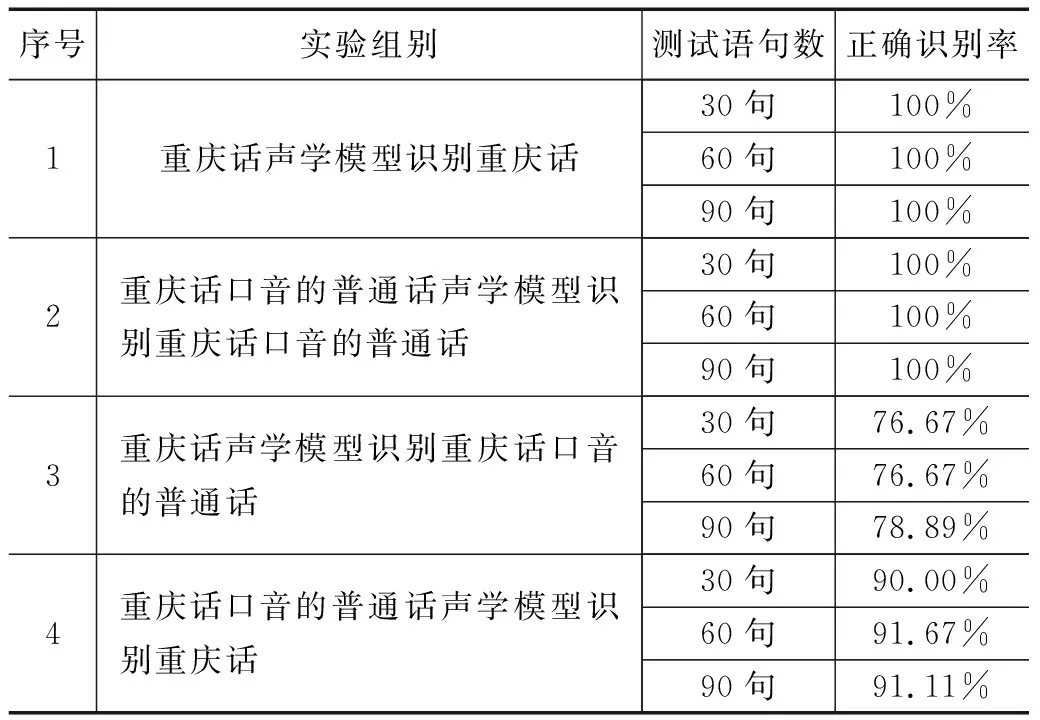
表6 12組實驗結果
5 結語
本文以重慶話為實驗研究對象,采集了重慶話文本,并將文本錄制成重慶話和重慶話口音的普通話,建立了兩種語音與之對應的小語料庫。搭建了基于HMM的重慶話語音識別系統,設計了12組語音識別方案,并得到了12個實驗結果。實驗結果表明:在30句、60句以及90句測試集下重慶話和重慶話口音的普通話訓練得到聲學模型分別去識別對應的兩種語音的正確識別率均為100%;重慶話語音聲學模型識別重慶話口音的普通話語音的正確識別率要比重慶話口音的普通話語音聲學模型識別重慶話語音的正確識別率要高。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
環球人文地理(2022年8期)2022-09-21 03:49:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
意林·全彩Color(2019年11期)2019-12-30 06:08:38
重慶行政(公共人物)(2018年5期)2018-11-06 07:42:18
重慶文理學院學報(社會科學版)(2017年5期)2017-10-23 01:30:02
今日重慶(2017年5期)2017-07-05 12:52:25
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
