基于QPSO-ELM的某型渦軸發動機起動過程模型辨識
2018-11-30 05:28:02伍恒李本威張赟楊欣毅
航空學報 2018年11期
伍恒,李本威,張赟,楊欣毅
海軍航空大學 航空基礎學院,煙臺 264001
航空發動機是一個高度非線性的時變系統,建立準確的航空發動機模型可用于發動機的健康監測與狀態評估、性能分析與故障診斷以及控制規律設計等多方面研究。目前建立航空發動機模型的方法主要有兩種:一種是分析部件氣動熱力特性的解析法,另一種是把發動機作為一個整體,對輸入輸出發動機的參數之間的函數關系進行分析的數據辨識法。解析法需要充足的發動機部件特性,但發動機起動階段的轉子部件特性往往不可獲得,而且建模過程比較復雜,需要進行大量的假設、近似處理和反復的迭代運算。近年來,基于數據驅動的模型辨識方法得到越來越多的研究。傳統的辨識方法主要有最小二乘法以及子空間狀態辨識法等,但它們都是假定發動機是線性時不變系統,因此精度較低。而且發動機起動過程是非線性大偏差的,不存在穩態工作點,目前還無法確定模型或傳遞函數的結構。以人工神經網絡(Artificial Neural Networks, ANN)、支持向量機(Support Vector Machine, SVM)和極限學習機(Extreme Learning Machine, ELM)為代表的數據挖掘機器學習算法展現出了良好的非線性逼近能力。
針對建立航空發動機起動過程辨識模型,Asgari等[1]利用外部輸入非線性自回歸(Nonlinear Auto Regressive models with eXogenous inputs, NARX)神經網絡建立了某型單軸燃氣渦輪起動階段模型,并對模型進行了仿真分析;Pogorelov等[2]利用動態神經網絡對一個雙軸燃氣輪機差分形式的非線性動態模型進行辨識,并應用于起動控制模式;陳超和王劍影[3]使用ANN對發動機起動過程進行辨識與仿真分析,但以上采用的ANN方法常常存在局部極小值、過學習等問題;李應紅[4]和王冠超[5]等分別提出使用SVM以及優化改進的SVM來辨識發動機起動過程,取得了不錯的效果。ELM[6-8]是單隱含層神經網絡,僅需設置輸入權重和隱含層結點數,就能產生唯一的最優解,使得其學習效率大幅提升,而且相關研究表明其非線性擬合能力要優于一些傳統的ANN和SVM算法[9-11],但仍需進行參數的優化選取。
量子粒子群優化(Quantum-behaved Particle Swarm Optimization, QPSO)算法中粒子搜尋的位置由概率密度函數確定,取消速度參數,不僅簡單,而且算法穩定性好,具有較強的全局搜索和尋優能力[12-14]。文獻[15-17]在典型的回歸和分類問題上進行試驗,證明了基于QPSO選取ELM特征參數算法的有效性。
鑒于上述分析,本文提出一種基于QPSO-ELM的某型渦軸發動機起動模型數據驅動辨識方法。首先構建基于狀態空間法描述的某型渦軸發動機起動過程分段模型,然后結合發動機起動試驗數據,采用QPSO-ELM算法對該起動模型進行辨識和驗證,最后對比不同方法的回歸辨識效果,表明本文提出的一種基于QPSO-ELM的某型渦軸發動機起動過程模型辨識方法的可行性和優越性,為進行不同大氣條件下的發動機起動性能遞推估算以及進一步研究該型發動機起動控制規律優化并對發動機進行監控和健康狀態的評估奠定基礎。
1 基于QPSO的ELM算法原理
1.1 ELM概述
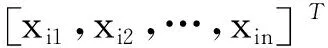
Hα=T
(1)
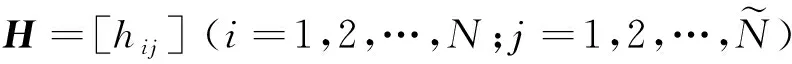
(2)
式中:H+為隱含層輸出矩陣H的Moore-Penrose廣義逆矩陣。
1.2 QPSO算法
粒子群優化(Particle Swarm Optimization, PSO)算法是基于群體進化的算法,認為群體中個體之間的信息共享能提供進化的優勢,群體間個體的合作與競爭能實現優化問題的求解[18-20]。Sun等[21]提出的QPSO算法是在PSO算法的基礎上引入量子力學原理,在量子空間中,通過波函數來描述粒子的狀態,求解薛定諤方程得到粒子在某一點出現的概率密度函數。粒子移動的搜索方程可表示為
(3)
(4)
(5)
(6)

1.3 基于QPSO的ELM特征參數優化流程
利用QPSO算法優選ELM的特征參數不僅包括輸入權重和隱含層偏置,也包括隱含層神經網絡的結構或者說隱含層神經元的個數。具體的優化流程如下:
步驟1初始化。首先隨機生成粒子種群,種群數量一般取30~50即可。種群當中的每一個粒子Li由一組輸入權重、隱含層偏置和s變量組成,即
(7)
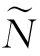
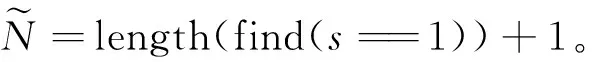
(8)
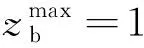
步驟2適應度函數值的計算。粒子的適應度函數值計算采用預測輸出與目標輸出的均方根誤差來實現,QPSO尋優的目標即為最小化適應度函數。
(9)
步驟3更新粒子的個體歷史最好位置pbesti和種群歷史最好位置gbest,重新根據式(4)和式(5)計算每一個粒子的局部吸引點和平均最好位置,再根據式(3)更新每一個粒子新的位置。
步驟4重復步驟1~步驟3直到達到最大迭代次數。這樣即可針對實際問題,得到ELM優選的特征參數,再利用優選特征參數的ELM進行分類或回歸辨識的應用。
文獻[15-17]詳細描述了利用幾個經典函數和數據集驗證QPSO-ELM方法的分類和回歸辨識效果,以及該方法與其他算法性能的對比分析,不再贅述。結果表明QPSO-ELM方法的回歸辨識效果更好。
2 某型渦軸發動機起動過程模型辨識方法
2.1 某型渦軸發動機起動過程模型建立
航空發動機模型具有時變非線性特點,某型渦軸發動機是由燃氣發生器和與減速器相連的自由渦輪組成,通過減速器的輸出軸使發動機功率輸出。對于一個動力學系統或過程,通常有兩種類型的數學描述,即輸入輸出描述和狀態空間描述。狀態空間描述可以作為系統或過程的一種完全描述,建立發動機起動狀態空間模型,需找到能完全表征起動過程時間域行為的最小內部狀態變量組。在某型渦軸發動機的起動過程中,起動機、發動機、點火系統、供油系統以及負載系統等相互配合工作,協同完成不同大氣條件下的發動機起動。發動機起動過程模型結構如圖1所示。
其中,數學模型的核心是發動機的氣動熱力特性,模型的輸入量為大氣條件、起動機特性、燃燒室供油特性(在正常起動的情況下,點火特性可以與供油特性一起考慮)以及負載特性;模型的輸出量為發動機起動過程狀態和性能。因此,用狀態空間法描述的起動模型的一般形式為
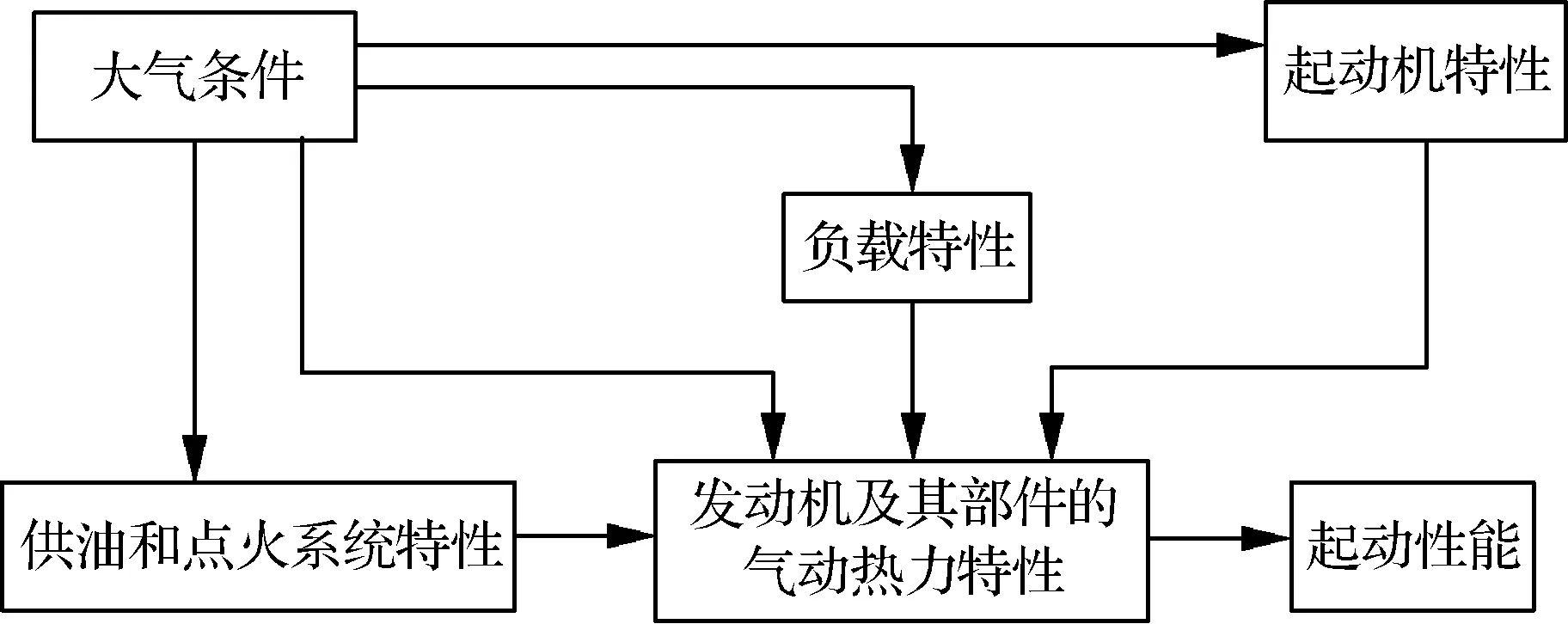
圖1 發動機起動過程模型結構Fig.1 Structure of model for engine starting process
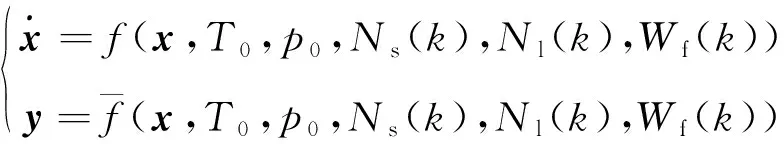
(10)
式中:T0、p0分別為大氣溫度和壓力;Ns為起動機的輸出功率;Nl為負載阻力矩;Wf為燃燒室燃油消耗量;k為樣本集中采樣數據點對應的時刻;x為狀態向量;y為輸出向量。由于發動機起動過程的負載阻力在常溫環境變化不大的條件下較小,可以不予考慮。當考慮發動機轉子慣性和燃燒室的能量存儲以及熱損失時,分別取燃氣發生器轉子轉速ng、發動機輸出軸轉速nr和燃氣渦輪后溫度T4作為狀態變量。對于狀態空間模型,取輸出向量與狀態向量元素相同,即可得到離散形式的發動機起動非線性動態數學模型。
某型渦軸發動機的起動過程主要可以分為3個階段,如圖2所示(注:實際轉速上升為非線性),圖中t為時間。不同階段模型的輸入輸出量不一樣,因此,為了提高準確度,本文建立起動過程分段非線性模型。
第1階段是起動開始后1.25 s內,由起動機發出功率單獨帶動燃氣渦輪工作階段。發動機轉速在設定的時間內達到(0.08~0.12)·33 400 r/min,并成功觸發起動點火燃油系統開始工作點火。由于第1個階段只有起動機帶轉并無供油點火,燃氣渦輪后溫度接近大氣溫度,可得發動機非線性起動模型為
ng(k+1)=f1(ng(k),T0,p0,Ns(k))
(11)
第2階段是供油點火燃燒,由起動機和燃氣發生器共同發出功率帶動發動機加速工作階段。起動燃油調節裝置按燃油調節規律供油,持續穩定燃燒,起動機和燃氣發生器共同帶動發動機在設定的時間內加速到脫開起動機的轉速14 000 r/min。發動機非線性起動模型為
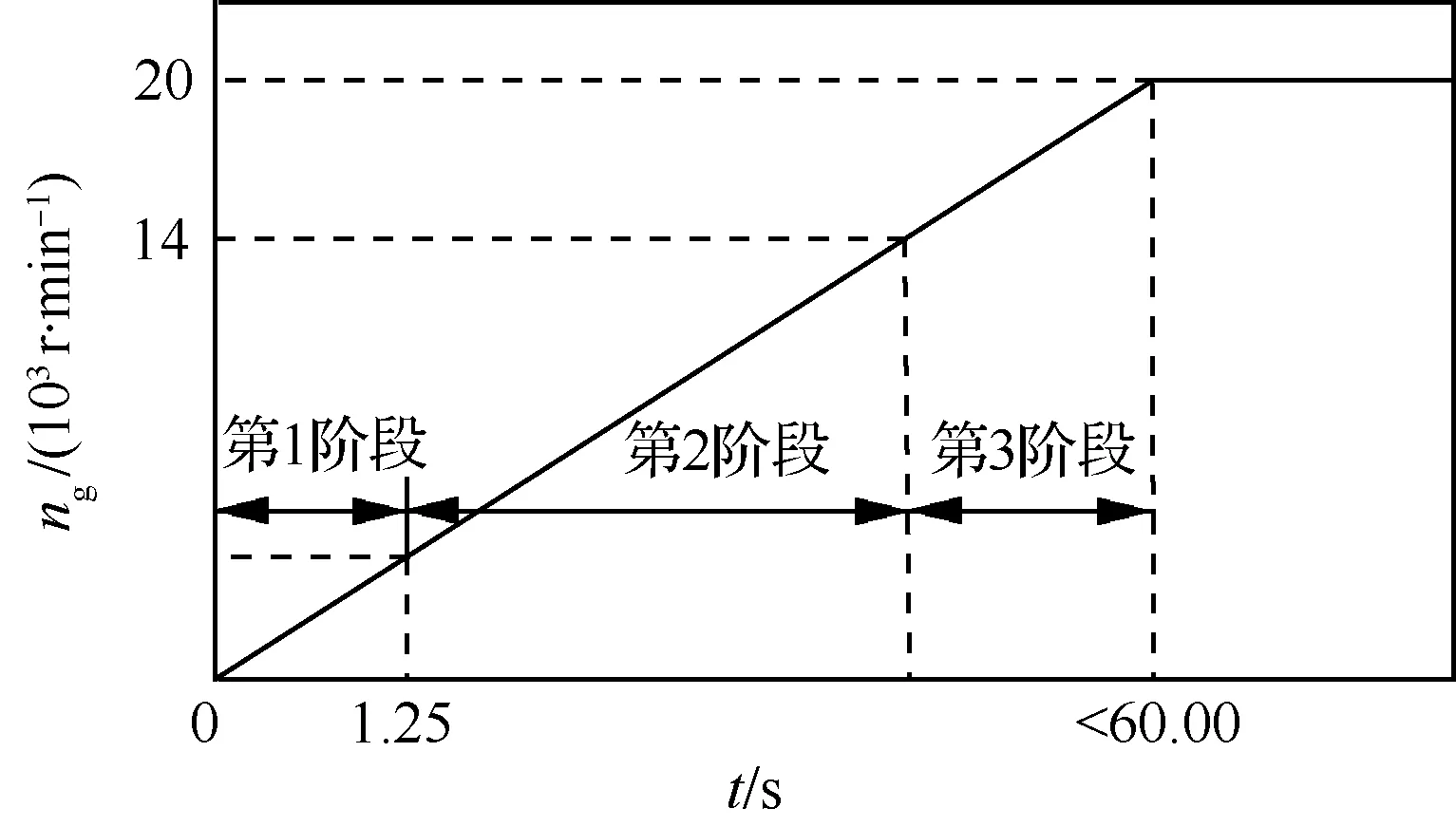
圖2 發動機起動過程不同階段示意圖Fig.2 Diagram of different stages of engine starting process
(ng(k+1),nr(k+1),T4(k+1))=f2(ng(k),nr(k),T4(k),T0,p0,Ns(k),Wf(k))
(12)
第3階段是當燃氣發生器轉速達到14 000 r/min的自立轉速時,起動機斷開,由燃氣發生器單獨產生功率帶動發動機加速工作到地面慢車狀態,即完成起動,整個起動過程不能超過60 s。發動機非線性起動模型為
(ng(k+1),nr(k+1),T4(k+1))=f3(ng(k),
nr(k),T4(k),T0,p0,Wf(k))
(13)
2.2 基于QPSO-ELM的起動模型辨識方法
ELM在進行函數逼近時,首先利用QPSO算法對其輸入權重、隱含層偏置和隱含層神經元個數等特征參數進行尋優,尋優的目標即為最小化適應度函數,也即最小化預測輸出與目標輸出的均方根誤差值。如圖3所示為ELM的網絡結構圖。
(14)
其矩陣表示形式如式(1)所示,H、α、T的具體表達式為
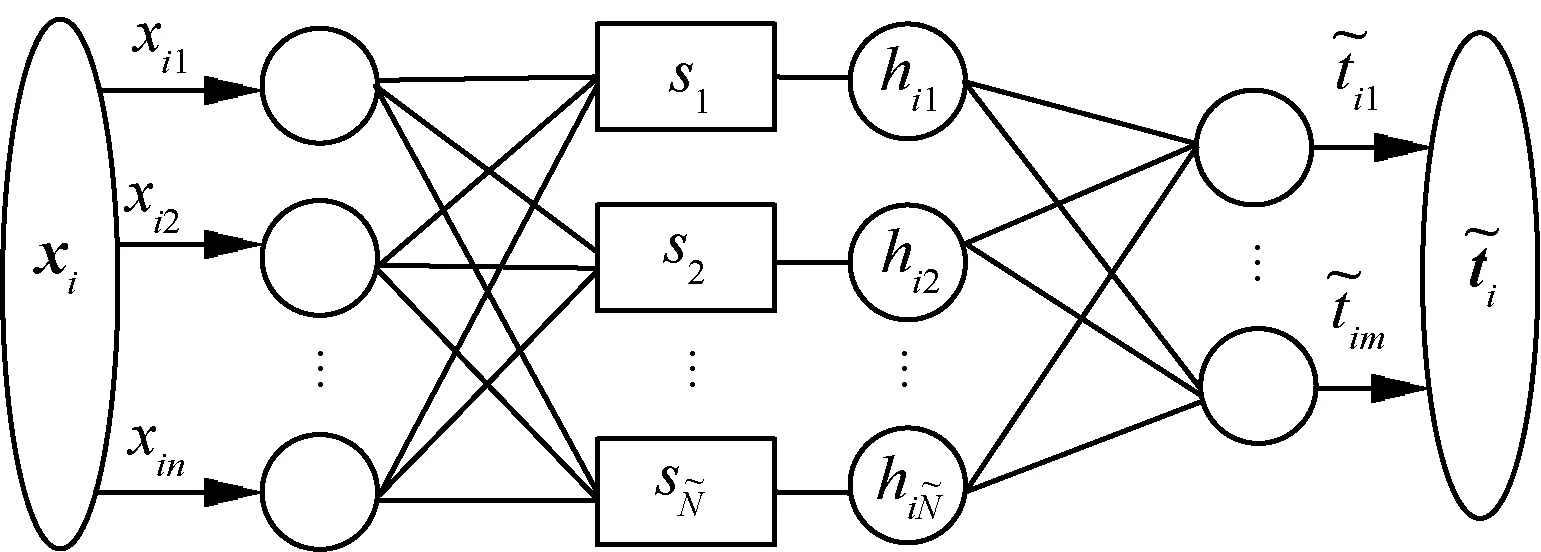
圖3 ELM的網絡結構Fig.3 Network structure of ELM
最后,ELM的輸出為
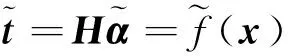
(15)
綜上,基于QPSO-ELM的某型渦軸發動機起動模型辨識的具體流程如圖4所示。
步驟1根據某型渦軸發動機起動過程原理,建立包含輸入輸出量函數關系的分段非線性起動模型。
步驟2選取發動機起動試驗數據,建立模型辨識的訓練和驗證樣本集,并進行樣本集的平滑、濾波和歸一化處理。
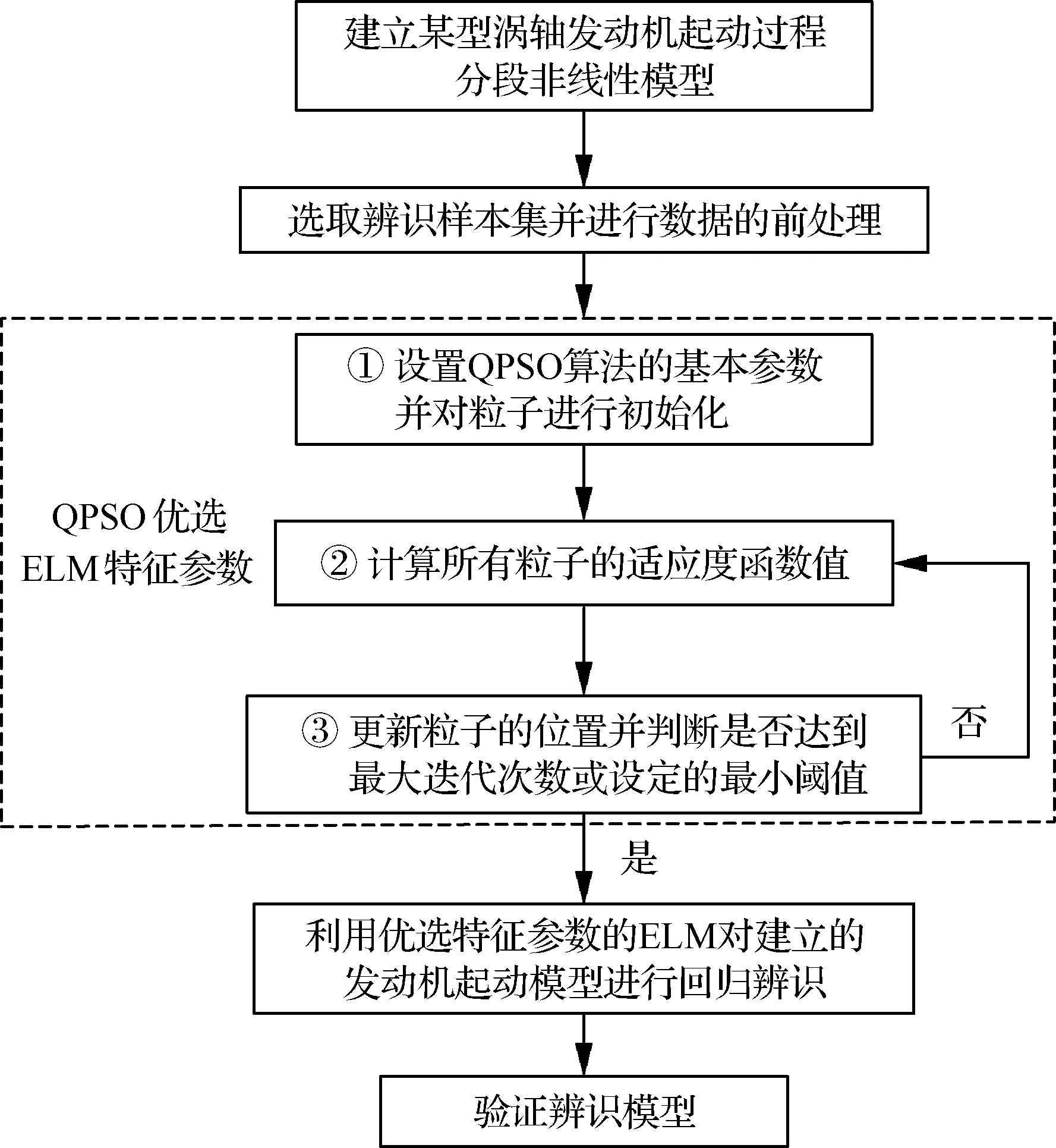
圖4 起動模型辨識的具體流程Fig.4 Specific process of starting model identification
步驟3設置QPSO算法的種群粒子數量和最大迭代次數等基本參數,利用QPSO算法對ELM的特征參數尋優。
步驟4結合模型辨識的訓練樣本集,利用優選特征參數的ELM對建立的某型渦軸發動機分段非線性起動模型進行回歸辨識。
步驟5利用驗證樣本集對建立的發動機起動過程辨識模型進行驗證。
步驟1~步驟5構成了基于QPSO-ELM的某型渦軸發動機起動模型的辨識方法。
3 辨識結果分析
3.1 模型辨識樣本數據的選取與處理
為研究某型渦軸發動機的起動特性,工廠在2016年針對該型渦軸發動機進行了1 000 h試車試驗。選取4組錄取的被試發動機起動過程試驗數據作為訓練和驗證樣本集,這4組數據分別在9.2、18.3、26.8、34.6 ℃下測得。根據該型渦軸發動機起動試驗采集的數據種類,結合建立的發動機分段非線性起動模型,確定樣本參數為:大氣溫度T0、大氣壓力p0、燃燒室燃油消耗量Wf、起動機發出的功率Ns(由測量的起動機電壓和電流,結合起動機效率計算得到)、燃氣發生器轉子轉速ng、發動機輸出軸轉速nr以及燃氣渦輪后溫度T4。
將每組發動機起動試驗數據按照起動過程的3個階段分為3段數據集,每個階段模型的具體輸入輸出量根據模型結構方程式(11)~式(13)對應選取。第1階段每50 ms選取一個數據,4組數據總共100個數據點作為起動過程第1階段的樣本集。第2、3階段分別均勻選取50個數據點,每個階段4組數據各200個數據點分別作為第2、3階段樣本集。其中一組數據選取的起動過程3個階段的部分樣本數據如表1所示。
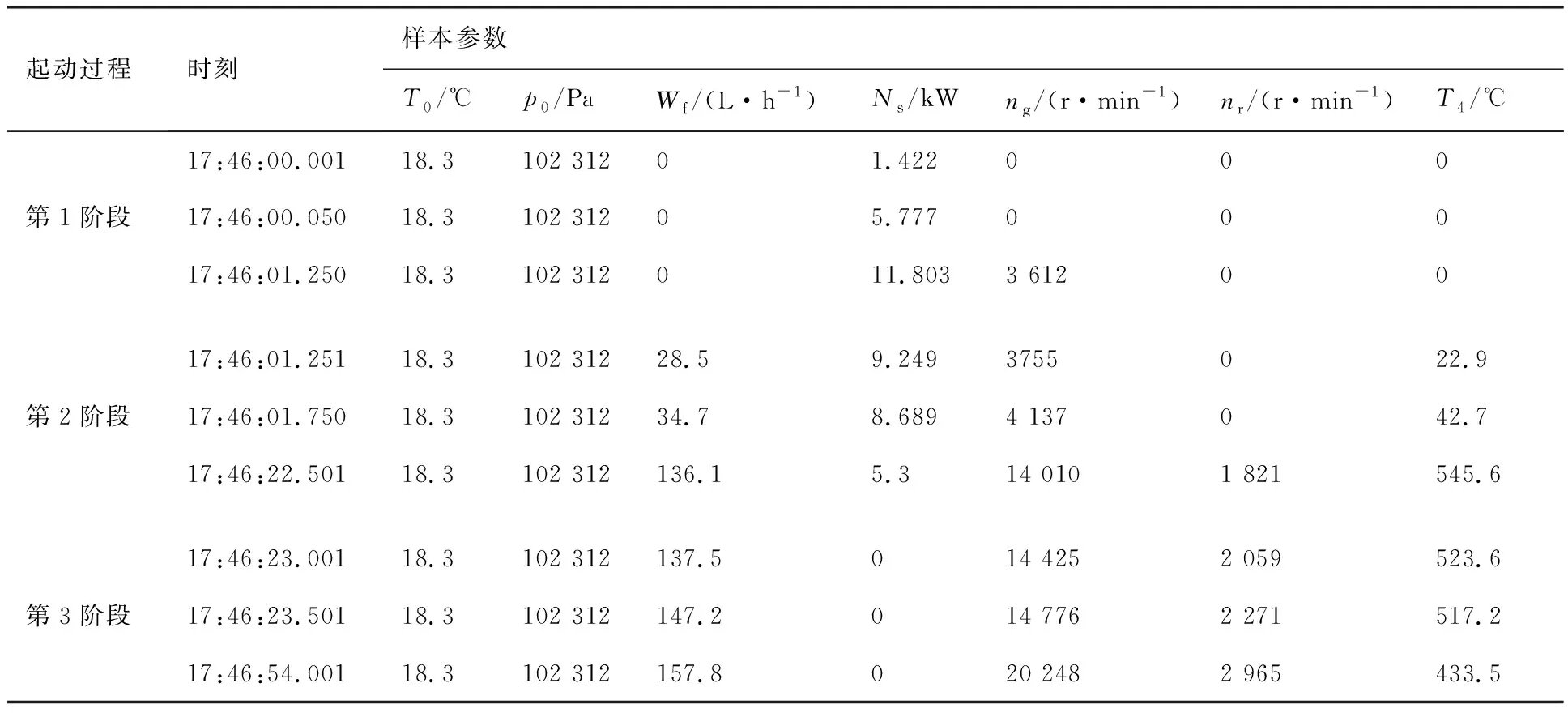
表1 一組發動機起動過程3個階段部分樣本數據Table 1 Partial data in three stages of starting process of a certain engine
對樣本數據進行異常數據剔除、平滑與濾波處理,具體計算公式參照文獻[22]。由于不同的變量取值范圍差異較大,需要以歸一化處理后的數據作為訓練與驗證樣本,并在完成訓練和驗證后對變量進行還原。
為了減少人為數據分組帶來的誤差,本文采用隨機數據分組的方式進行處理,隨機選取其中3組數據作為訓練樣本進行訓練,并用另外1組數據作為驗證樣本,分別對比不同訓練與驗證樣本情況下得到的起動過程辨識模型的辨識精度。
3.2 模型辨識結果
選取樣本數據并處理完之后,設置好QPSO算法的基本參數,主要包括:種群粒子數量為30,最大迭代次數為30,即可利用QPSO算法對ELM的特征參數尋優,并結合模型辨識的訓練樣本集,利用優選特征參數的ELM對建立的某型渦軸發動機分段非線性起動模型進行回歸辨識。將驗證樣本輸入到辨識模型中計算對應的輸出,并對比模型辨識結果和實測數據來驗證建立的發動機起動過程各階段辨識模型。由于各離散數據點的函數值均為輸出參數的一步預測值,通過驗證計算可得,各輸出參數數據點的預測值與實測值相對偏差較小。此外,各輸出參數數據在發動機起動過程中的實際變化是連續的,從而完成起動過程不同階段連接段辨識數據點的連接。最后將起動過程3個階段的辨識結果合并即可得到某型渦軸發動機起動過程辨識模型。
其中,以一組環境溫度為18.3 ℃條件下測得的數據作為驗證樣本時,輸出參數ng、nr和T4的辨識結果與實測數據的對比如圖5所示。
從圖5可看出,輸出參數ng、nr和T4的辨識結果都良好地逼近了實測數據,驗證樣本中各輸出參數不同數據點的最大相對誤差分別為:1.34%、1.63%和2.2%,說明本文提出的基于QPSO-ELM的起動模型辨識方法是可行的。
輪流以選取的4組發動機起動試驗數據中的3組數據作為訓練樣本,另外1組數據作為驗證樣本,對某型渦軸發動機起動模型進行優化辨識,并用驗證樣本對辨識得到的模型進行驗證,可得不同驗證樣本各輸出參數辨識結果與實測數據的最大相對誤差統計分析的盒狀圖如圖6所示。
從圖6可看出,不同驗證樣本驗證得到的輸出參數ng、nr和T4的辨識結果和實測數據的最大相對誤差均未超過3%,最大相對誤差均值分別為:1.358%、1.628%和2.195%,表明本文采用的QPSO-ELM辨識得到的某型渦軸發動機起動模型的精度滿足實際應用的精度需求。
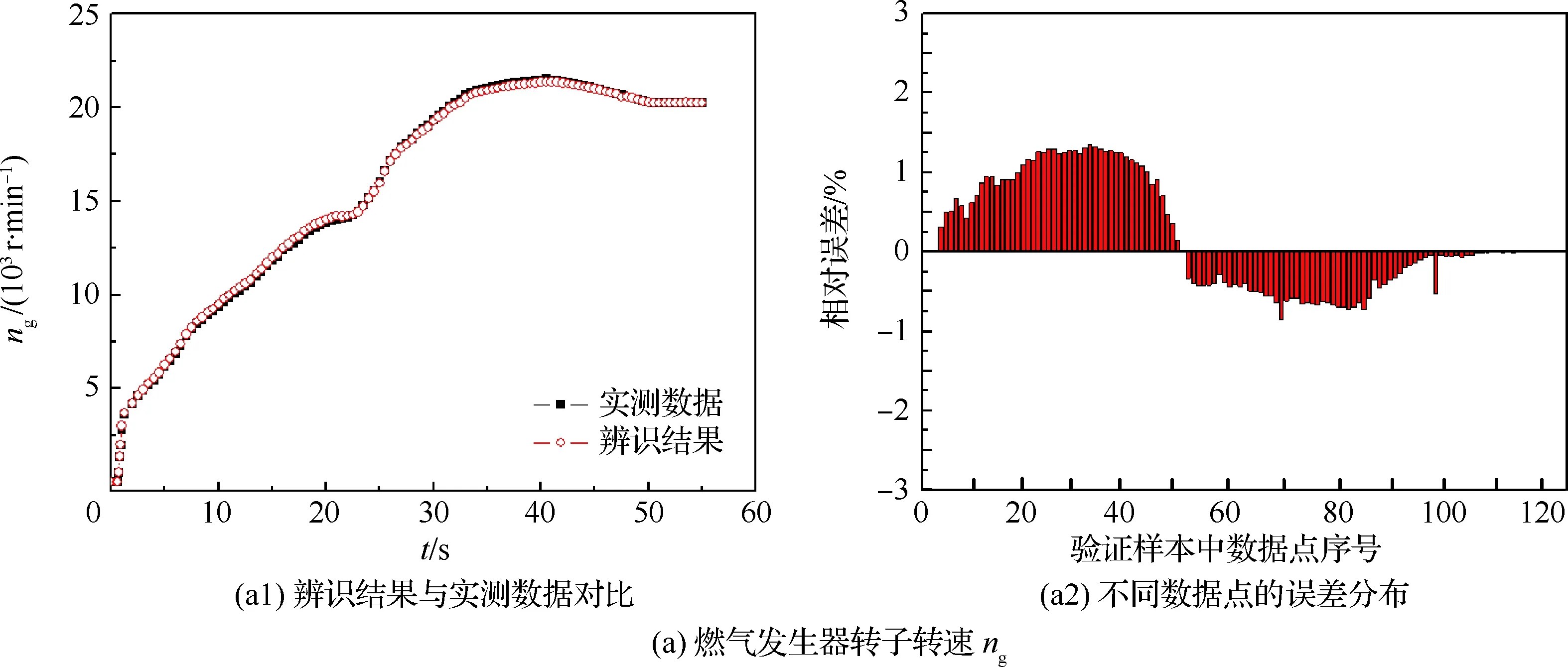
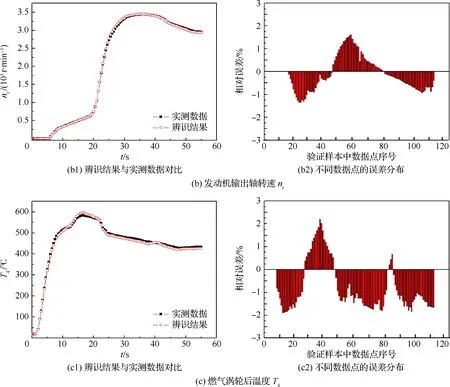
圖5 輸出參數的辨識結果與實測數據對比Fig.5 Comparison of output parameters between identification results and test datas
3.3 不同方法辨識效果的對比
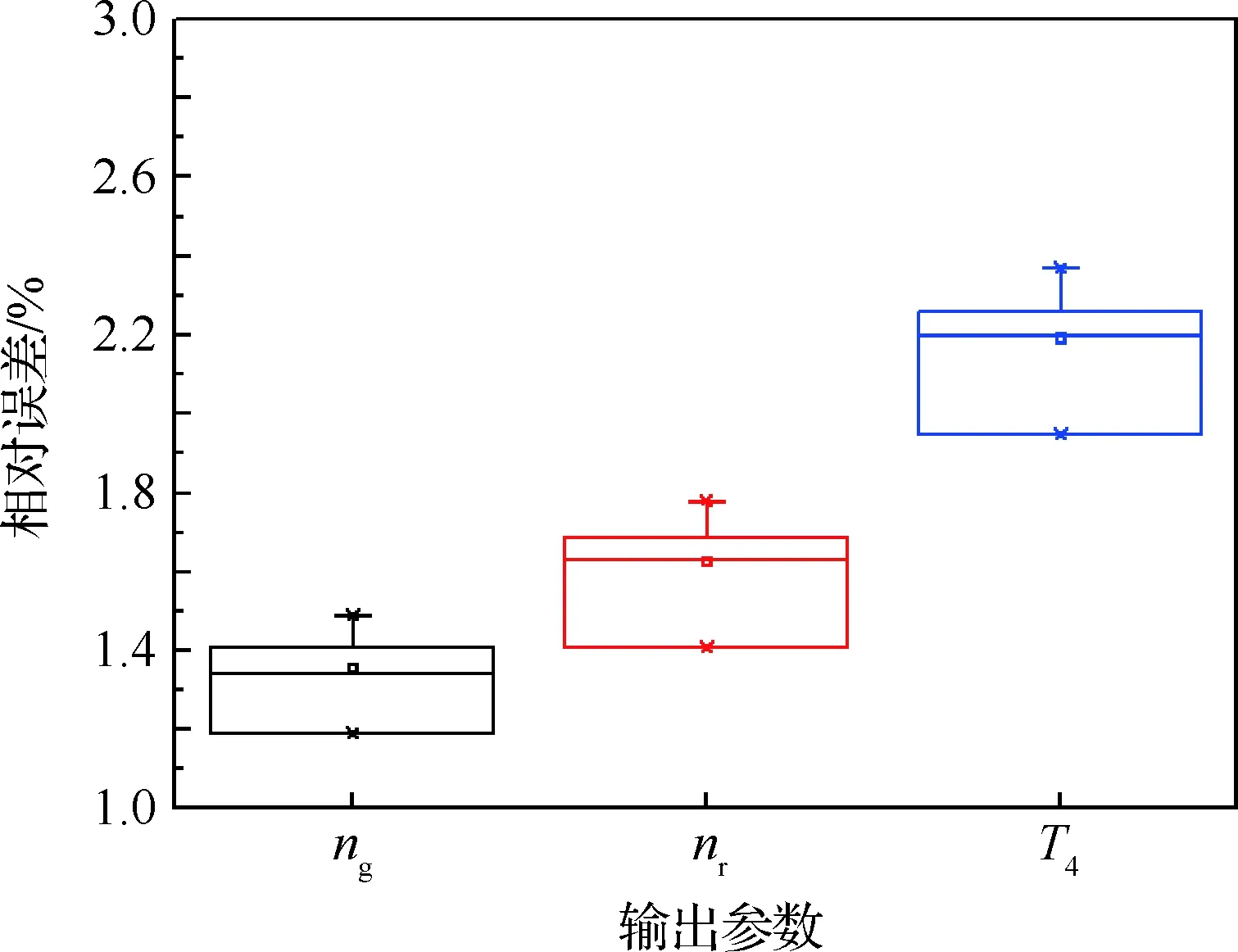
圖6 不同驗證樣本各輸出參數辨識精度盒狀圖Fig.6 Box chart of identification accuracy of output parameters in different verification sample datasets
為了更好地說明基于QPSO-ELM辨識某型渦軸發動機起動模型的優越性,利用相同的模型訓練與驗證樣本集,分別對比QPSO-ELM、ELM、SVM以及反向傳播(Back Propagation, BP)神經網絡4種方法的辨識效果。其中,ELM的隱含層神經元個數設置為回歸辨識效果相對最好的值80,輸入權重和偏置值由算法隨機給定。SVM在進行回歸辨識時的參數取值通過合理調整設置為:平衡因子C=100、不敏感度ε=0.008以及徑向基核函數參數σ=4.5;BP神經網絡采用廣泛應用的Levenberg-Marquardt優化算法結構,并選用3層BP網絡,其中隱含層結點數選為辨識效果相對最好的值7,MATLAB R2010b中有集成的工具包。表2為不同的辨識方法對某型渦軸發動機起動模型進行辨識,驗證得到的輸出參數ng、nr和T4的辨識結果與實測數據的最大相對誤差以及最大相對誤差均值的對比。圖7更為直觀地對比了不同方法的不同輸出參數最大相對誤差的均值。表3為4種不同方法的平均訓練時間對比。
從表3可看出,ELM的收斂速度明顯快于SVM和BP神經網絡,這是由于ELM是單隱含層神經網絡,網絡結構簡單,且相比于SVM,只需設計一個ELM即可實現多輸入多輸出模型的辨識,算法復雜度低,而相比于BP神經網絡無需進行反復的正向計算和逆向的誤差修正,使得學習效率大幅提升。從表2和圖7可看出,ELM的辨識精度高于SVM,而ELM和SVM的辨識精度要顯著高于BP神經網絡,有效地避免了BP神經網絡在訓練時容易陷入局部極值的問題。本文采用的QPSO-ELM方法的平均訓練時間相對較高,是因為需要對所有粒子進行適應度函數值評估和迭代尋優,其辨識精度要高于其他3種方法。
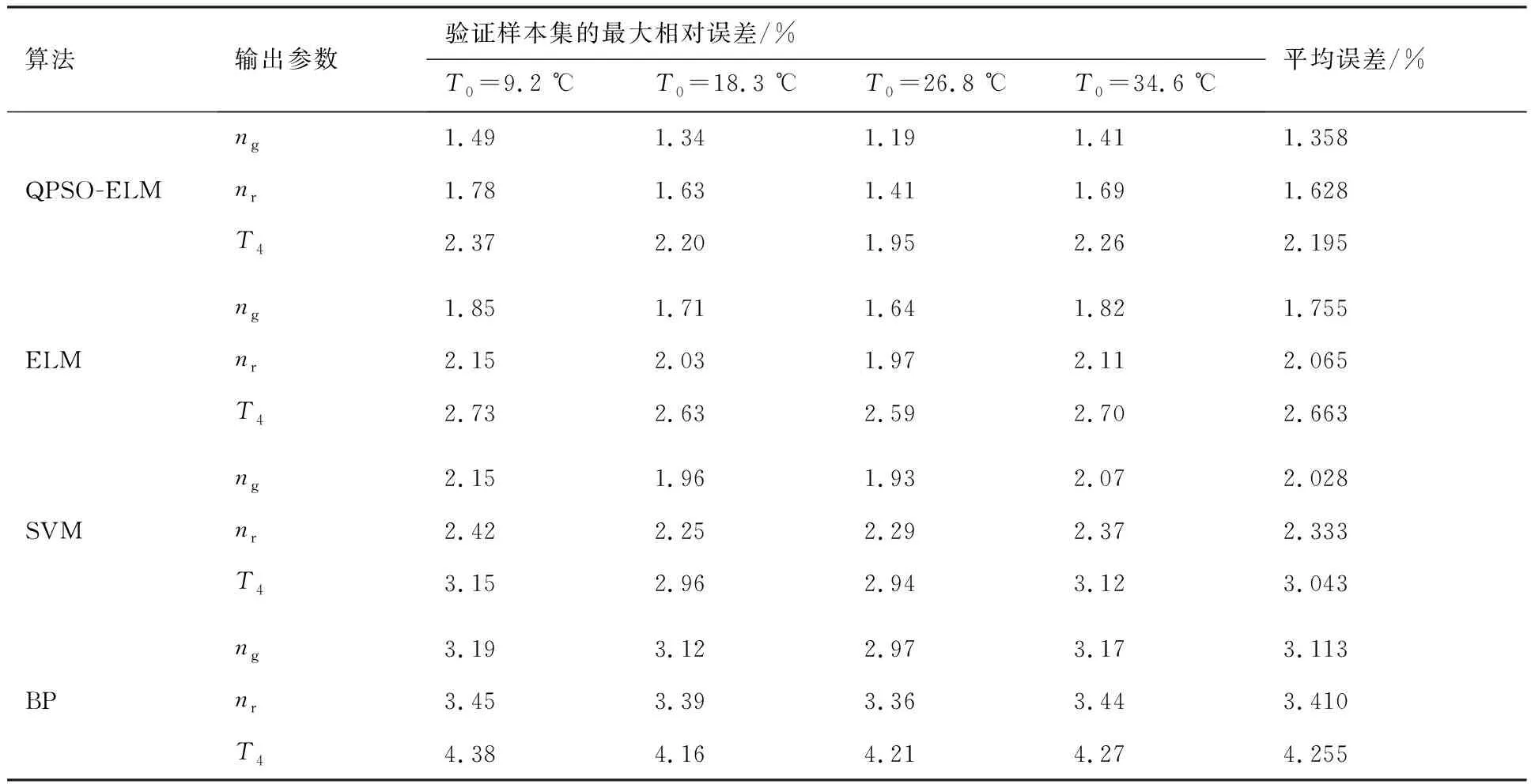
表2 不同方法辨識精度的對比Table 2 Comparison of identification accuracy of different methods
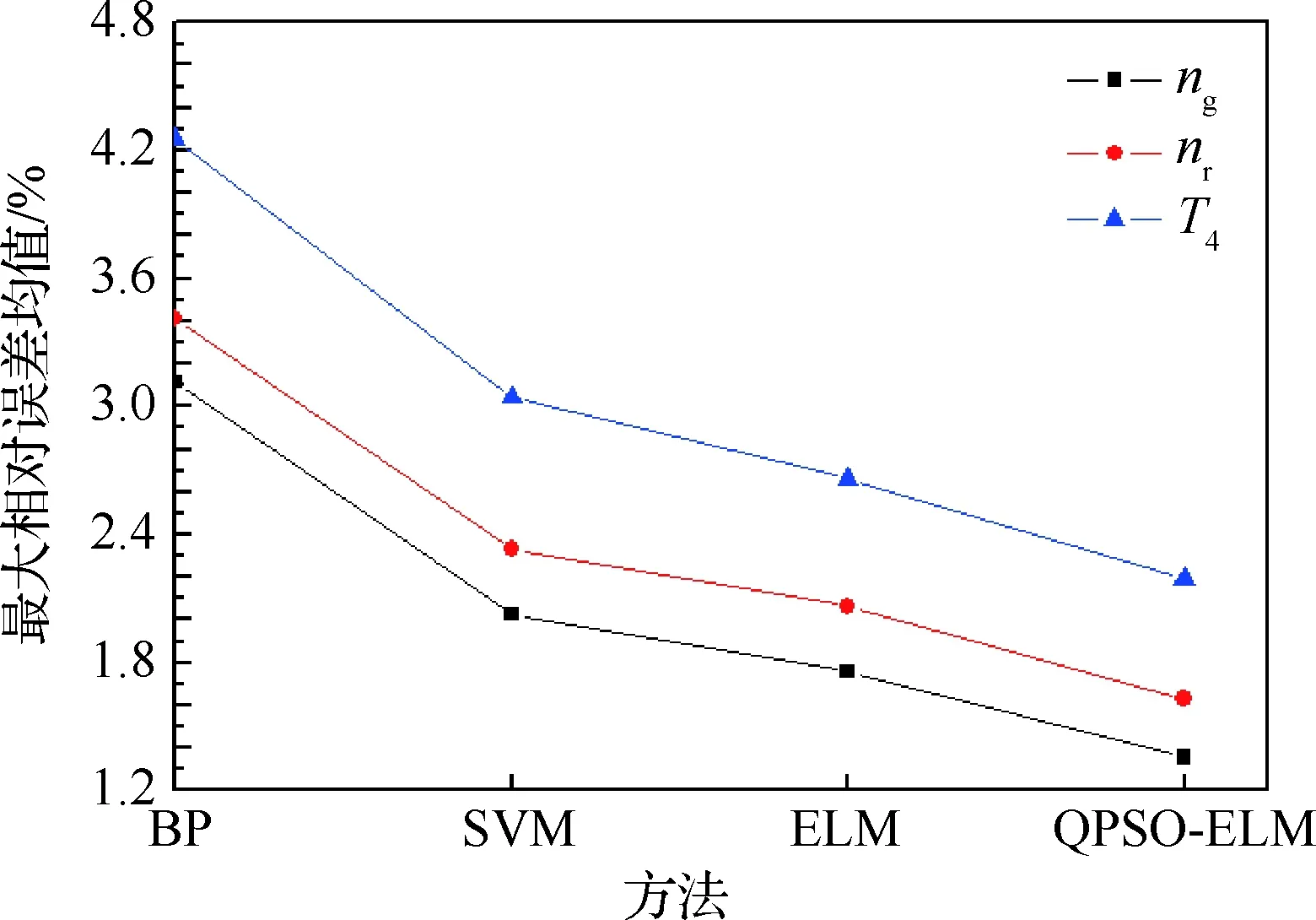
圖7 不同方法3個輸出參數的平均最大相對辨識誤差Fig.7 Mean maximum relative identification error of three output parameters by different methods
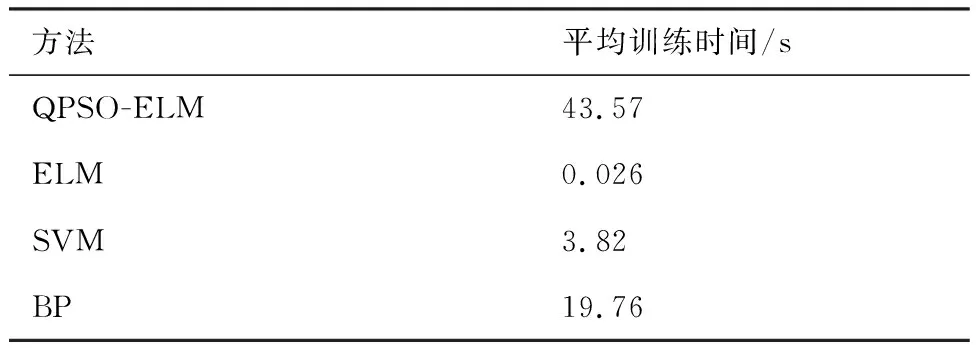
表3 平均訓練時間對比Table 3 Comparison of mean training time
4 模型應用范圍
基于QPSO-ELM辨識得到的某型渦軸發動機起動過程辨識模型可用于對其他大氣條件下的發動機起動性能進行遞推估算,模型遞推估算結構如圖8所示。
若已知某些大氣條件下的燃燒室供油特性和起動機特性,再給定起動過程不同階段輸出參數的初始值,即可根據起動過程不同階段辨識模型逐次遞推估算出這些大氣條件下發動機的起動性能,從而為發動機的起動狀態進行監控。當發動機對起動供油調整螺釘適當調節時,仍可利用遞推估算的方法對調整供油特性后的發動機起動性能進行估算,從而為起動性能調整試驗提供指導。此外,利用起動過程不同階段辨識模型還可進一步研究發動機起動控制規律的優化問題。
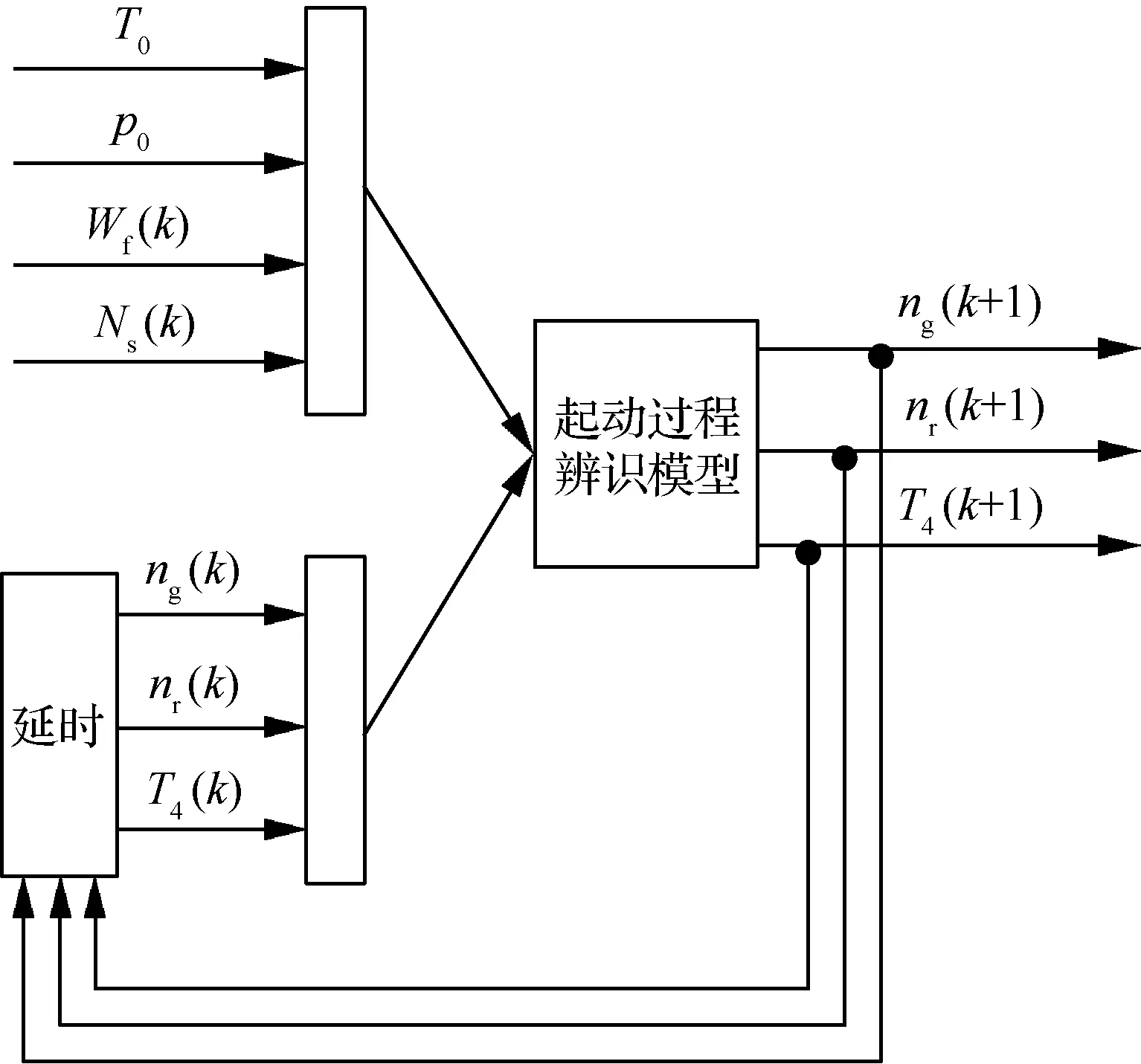
圖8 起動性能的模型遞推估算Fig.8 Model recursive estimation of starting characteristics
5 結 論
本文提出了一種基于QPSO-ELM的某型渦軸發動機起動模型數據驅動辨識方法,通過構建基于狀態空間法描述的某型渦軸發動機起動過程分段模型,結合發動機起動試驗數據,采用QPSO-ELM算法對該起動模型進行辨識,可得如下結論:
1) 輸出參數燃氣發生器轉子轉速ng、發動機輸出軸轉速nr和燃氣渦輪后溫度T4的辨識結果都良好地逼近了實測數據,證明本文提出的基于QPSO-ELM的起動模型數據驅動辨識方法可行。
2) 采用不同驗證樣本驗證得到的輸出參數ng、nr和T4的辨識結果和實測數據的最大相對誤差均值分別為:1.358%、1.628%和2.195%,表明本文采用的QPSO-ELM辨識得到的某型渦軸發動機起動模型的精度滿足實際應用的精度需求。
3) 在相同樣本數據條件下,本文采用的QPSO-ELM方法辨識得到的某型渦軸發動機起動模型的精度要優于ELM、SVM和BP神經網絡,能較好地解決解析法建立某型渦軸發動機起動過程模型難的問題。
由于發動機的起動范圍較寬,針對高原、高空以及高低溫等環境進行起動試車試驗,獲取更多反映不同大氣條件下起動模型非線性特性的訓練樣本,建立該型發動機適用于整個起動包線的辨識模型,是值得進一步研究的。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
汽車維修與保養(2021年8期)2021-02-16 00:28:30
汽車維修與保養(2021年8期)2021-02-16 00:28:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
汽車與新動力(2015年1期)2015-02-27 12:11:01
汽車與新動力(2014年2期)2014-02-27 12:10:15
汽車與新動力(2013年5期)2013-03-11 16:08:17
