語義相似度計(jì)算在內(nèi)檢測數(shù)據(jù)參數(shù)匹配中的應(yīng)用
2019-01-02 11:20:18張河葦金劍董紹華張來斌李寧
石油科學(xué)通報(bào) 2018年4期
張河葦,金劍,董紹華*,張來斌,李寧
1 中國石油大學(xué)(北京)機(jī)械與儲運(yùn)工程學(xué)院,北京 102249
2 中石油管道有限責(zé)任公司西部分公司,烏魯木齊 830000
0 引言
管道內(nèi)檢測數(shù)據(jù)是維護(hù)管道運(yùn)行的重要參考數(shù)據(jù),通過內(nèi)檢測數(shù)據(jù)可以獲得很多有價(jià)值的信息,是管道公司查找管道缺陷、進(jìn)行管道修復(fù)的重要依據(jù),因此針對同一管段往往會進(jìn)行多輪內(nèi)檢測。然而,由于管道所處的環(huán)境以及檢測過程中部分因素的影響,例如起始點(diǎn)不同、內(nèi)檢測器運(yùn)行速度不同等,使得多次內(nèi)檢測數(shù)據(jù)無法完全對齊,降低了數(shù)據(jù)的利用水平,出現(xiàn)缺陷無法匹配等問題,甚至如果兩次檢測的檢測商不同,則會進(jìn)一步加劇這個(gè)情況。針對多輪內(nèi)檢測的比對問題,目前檢測公司都是通過人工比對兩次內(nèi)檢測數(shù)據(jù),業(yè)務(wù)量巨大,而且對于管道運(yùn)營商來說無法確定結(jié)果的真實(shí)性。
鑒于內(nèi)檢測數(shù)據(jù)比對的重要性,近期在內(nèi)檢測數(shù)據(jù)的比對理論方面,部分國內(nèi)學(xué)者也進(jìn)行了一些研究。王良軍等[1]通過調(diào)研了解到國外的管道運(yùn)營公司,例如DOW、BP、EnbrigeSingapore、Gas Company等,已有百余條管道開展了內(nèi)檢測數(shù)據(jù)比對工作。王良軍等綜述了內(nèi)檢測比對方法的研究現(xiàn)狀,歸納出此項(xiàng)研究工作中的兩個(gè)關(guān)鍵步驟為內(nèi)檢測里程數(shù)據(jù)對齊和內(nèi)檢測特征數(shù)據(jù)比對[1]。王丹丹等[2]提出在確定關(guān)鍵點(diǎn)對齊的前提下,以相對里程、時(shí)鐘方位以及表面位置為核心參數(shù)的比對方法,并運(yùn)用改進(jìn)方法對海底管道的剩余強(qiáng)度和剩余壽命進(jìn)行了評估。孫浩等[3]對內(nèi)檢測比對的流程進(jìn)行詳細(xì)敘述,包括關(guān)鍵點(diǎn)對齊和缺陷的活性判斷方法,并以天然氣管道為例進(jìn)行方法驗(yàn)證,得到較好的計(jì)算效果,其限制條件主要為內(nèi)檢測數(shù)據(jù)須由同一檢測承包商提供。楊賀[4]對比對中的關(guān)鍵流程(焊縫對齊、缺陷點(diǎn)識別)算法進(jìn)行了設(shè)計(jì),其限制條件為導(dǎo)入文件的格式必須與模板一致。
現(xiàn)階段內(nèi)檢測數(shù)據(jù)比對方法的基本流程已經(jīng)確定,存在的問題主要是缺少快速匹配不同檢測商提供的內(nèi)檢測報(bào)告的方法,該問題的存在限制了大數(shù)據(jù)背景下的數(shù)據(jù)對齊研究。通過語義相似度計(jì)算方法研究,有利于建立數(shù)據(jù)匹配字段的關(guān)聯(lián)關(guān)系,實(shí)現(xiàn)數(shù)據(jù)的快速入庫,為大數(shù)據(jù)技術(shù)的應(yīng)用奠定基礎(chǔ)。
1 基礎(chǔ)理論
語義相似度計(jì)算是處理自然語言的重要研究內(nèi)容,在信息檢索、翻譯等涉及到同義匹配等領(lǐng)域均有應(yīng)用。目前絕大多數(shù)描述概念詞語相似度的計(jì)算模型的基本思想是Dekang Lin從信息論的角度給出的如式1所示的理論[5]。含義為任意兩個(gè)對象之間的相似度取決于它們之間的共性commonality和個(gè)性differences,共性越多,相似度越大;個(gè)性越多,相似度越小[6]。
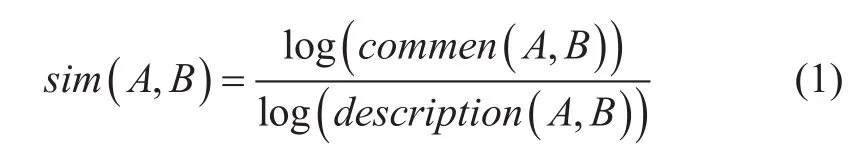
式(1)中的分母表示完整描述A,B所需的信息量大小,分子表示描述A,B共性部分所需的信息量大小,sim(A,B)表示A,B之間的語義相似度。
語義相似度計(jì)算的研究領(lǐng)域主要分為兩大類[7]:一是依據(jù)某種世界知識來計(jì)算,主要是通過詞典中概念結(jié)構(gòu)關(guān)系(上下位關(guān)系、同位關(guān)系、整體-部分關(guān)系等)來計(jì)算相似度;二是利用大規(guī)模的語料庫,利用統(tǒng)計(jì)學(xué)方法將上下文信息的概率分布作為詞語語義相似度的度量。
本文研究的方法屬于第一類。目前國外的語義研究詞典主要包括WordNet[8]、FrameNet[9]、MindNet[10]等。國內(nèi)的漢語語義研究詞典主要為知網(wǎng)[11]、同義詞詞林[12]等。由于《同義詞詞林》的編排結(jié)構(gòu)與國際研究常用的WordNet詞典結(jié)構(gòu)最為相似,該詞典已逐漸成為漢語語義研究的重點(diǎn),本文討論的方法也是基于同義詞詞林建立的。
1.1 同義詞詞林
《同義詞詞林》是1983年由梅家駒等[12]編篆而成的。后來哈工大信息檢索研究實(shí)驗(yàn)室根據(jù)人民日報(bào)語料庫中詞語出現(xiàn)的頻率對其進(jìn)行擴(kuò)展并對詞林的結(jié)構(gòu)和編碼進(jìn)行了改進(jìn),形成一部具有漢語大詞表的《哈工大信息檢索研究室同義詞詞林?jǐn)U展版》(《詞林?jǐn)U展版》),共包含77 343詞語。原版中只針對大類、中類、小類進(jìn)行了編碼,而《詞林?jǐn)U展版》形成了5層結(jié)構(gòu),同時(shí)將編碼等級由三級擴(kuò)充到了五級,劃分為12個(gè)大類,95個(gè)中類,1428個(gè)小類,小類下方進(jìn)一步劃分為4026個(gè)詞群和17 797個(gè)原子詞群[13]。《同義詞詞林》擴(kuò)展前后詞典文件特征對比如表1所示。
同義詞詞林詞典的5層結(jié)構(gòu)如圖1所示。上面四層的結(jié)點(diǎn)都代表抽象的類別,第5層的葉子結(jié)點(diǎn)表示具體的詞條或義項(xiàng)[14]。對應(yīng)5層結(jié)構(gòu)設(shè)置了5層編碼,第1層用大寫英文字母表示;第2層用小寫英文字母表示;第3層用二位十進(jìn)制整數(shù)表示;第4層用大寫英文字母表示;第5級用二位十進(jìn)制整數(shù)表示。編碼總長度為8位,結(jié)構(gòu)具體如表2所示。
需要注意的是,第 8位的標(biāo)記有“=”、“#”、“@”3種。其中,“=”代表“相等”、“同義”;“#”代表“不等”、“同類”,表示屬于同類,但是語義不同;“@ ”代表“自我封閉”、“獨(dú)立”,它在詞典中既沒有同義詞,也沒有相關(guān)詞[12]。
1.2 語義相似度計(jì)算方法
部分學(xué)者在基于同義詞詞林的語義相似度計(jì)算方法研究方面已取得一定的成果,認(rèn)可度較高的有田久樂[15]和王汀[16]提出的算法。

表1 《同義詞詞林》擴(kuò)展前后詞典文件特征對比Table 1 Comparison of dictionary file features before and after Synonym Word Forest expansion
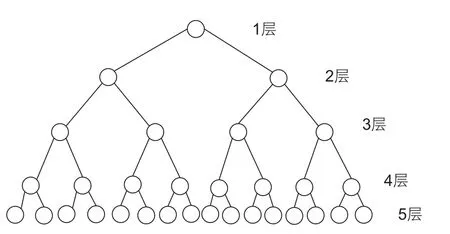
圖1 同義詞詞林詞典結(jié)構(gòu)Fig. 1 Synonym Word Forest dictionary structure

表2 編碼結(jié)構(gòu)Table 2 Coding structure
1.2.1 田久樂算法
田久樂提出基于義項(xiàng)的語義距離來衡量詞語的相似度[15]。假設(shè)兩個(gè)義項(xiàng)A,B的相似度用sim表示。
(1)若兩個(gè)義項(xiàng)不在同一棵樹上

(2)若兩個(gè)義項(xiàng)在同一顆樹上
若在第2層分支,系數(shù)取a,
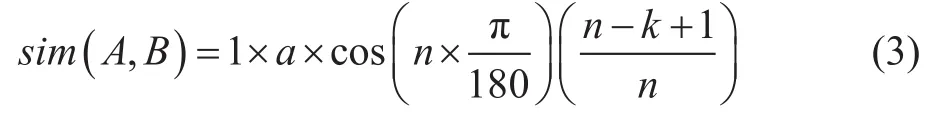
若在第3層分支,系數(shù)取b,
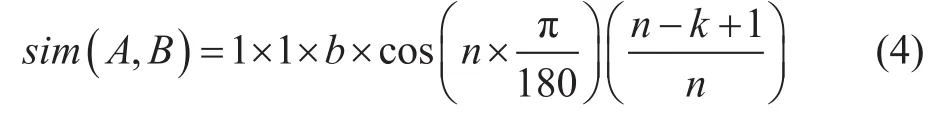
若在第4層分支,系數(shù)取c,
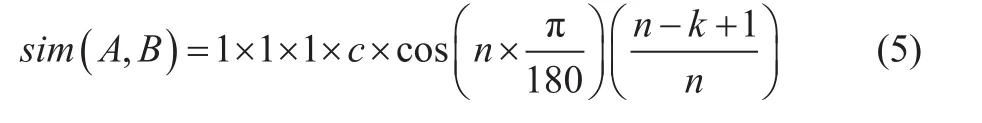
若在第5層分支,系數(shù)取d,
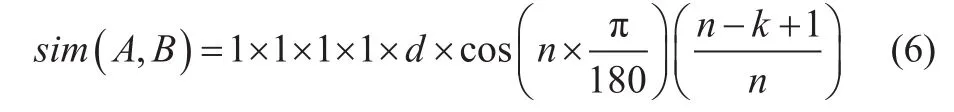
(3)若兩個(gè)義項(xiàng)的編號相同,當(dāng)末尾號為“=”時(shí),相似度為1;當(dāng)末尾號為“#”時(shí),直接把定義的系數(shù)賦給結(jié)果;當(dāng)末尾號為“@”時(shí),因代表在一個(gè)編號中只有一個(gè)詞,所以不予考慮。
需要注意的是,針對有多個(gè)編碼的詞語,在計(jì)算詞語相似度時(shí),取最大值。
1.2.2 王汀算法
相較于田久樂提出的算法,王汀算法引入了概念相似度權(quán)重系數(shù)表示集合L中的元素個(gè)數(shù),恒等于5。算法公式[16]如式7所示。
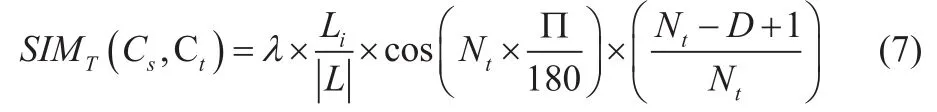
λ∈(0,1),其取值不宜過高;Nt為詞元在第i層分支上的節(jié)點(diǎn)總數(shù);D為詞元的編碼距離;特別地,當(dāng)概念的5 層編碼均相等且詞林編碼末位為“=”時(shí),SIMT的取值為1.0。
權(quán)重系數(shù)的引入使得不同層級的語義相似度區(qū)分更為明確。
2 基于內(nèi)檢測參數(shù)的語義相似度計(jì)算方法改進(jìn)
使用前文介紹的兩種方法進(jìn)行實(shí)驗(yàn)驗(yàn)證發(fā)現(xiàn),大部分的字段可以被區(qū)分開,然而部分字段的相似度計(jì)算差值較小,甚至無法區(qū)分,主要原因是未考慮路徑對語義相似度的影響。由上文兩種算法的公式可以看出田久樂算法僅設(shè)置了層級系數(shù),王汀算法也只針對層級系數(shù)進(jìn)行調(diào)節(jié)。本文通過增加路徑權(quán)重對上述兩種方法進(jìn)行改進(jìn),改進(jìn)后的公式如式8所示:

式(8)中引入新的概念—路徑權(quán)重weight替代原參數(shù)λ,目的是增大路徑所在層級對相似度值計(jì)算結(jié)果的影響。取值參照表3[17]中的設(shè)定值;Li/L為深度調(diào)節(jié)參數(shù),Li={1,2,3,4,5},L=5;N代表分支層的節(jié)點(diǎn)總數(shù);K代表兩個(gè)義項(xiàng)的父節(jié)點(diǎn)的間距。路徑、深度以及N、K的含義如圖2所示,圖中K=3,N=6。特別地,若兩個(gè)義項(xiàng)的編號相同,當(dāng)末尾號為“=”時(shí),認(rèn)為相似度最大;當(dāng)末尾號為“#”時(shí),認(rèn)為相似度最小;當(dāng)末尾號為“@”時(shí),因代表在一個(gè)編號中只有一個(gè)詞,所以不予考慮。
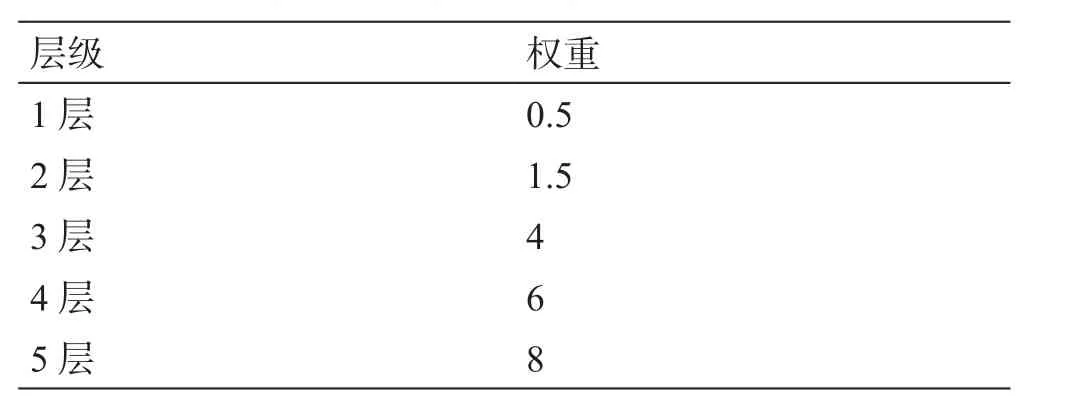
表3 路徑權(quán)重設(shè)定值Table 3 Setting value of path weight
3 案例
為了驗(yàn)證本文改進(jìn)方法的有效性,選取管道缺陷描述字段中較難區(qū)分的模板字段:焊縫和溝槽,進(jìn)行算法分析對比。將溝、坑痕、陷坑、槽子等幾個(gè)描述詞語與模板字段(焊縫和溝槽)通過兩兩計(jì)算語義相似度進(jìn)行匹配。查詢同義詞詞林[13]得到各字段的編碼如表4所示。
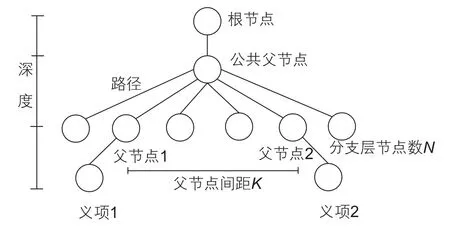
圖2 示意圖Fig. 2 Schematic
采用田久樂算法得到的結(jié)果如表5所示,采用王汀算法得到的結(jié)果如表6所示。由計(jì)算結(jié)果可知,王汀方法在溝槽與槽子、焊縫與槽子的語義相似度計(jì)算中,差值為負(fù)數(shù),未能成功匹配。
采用本文算法得到結(jié)果如表7所示,比較3種方法的差值增加量如表8。對比可知,本文方法相對于其他兩種方法非匹配字段的差值均有所增大,字段區(qū)分更為明顯,并且能夠區(qū)分其他方法難以區(qū)分的字段。
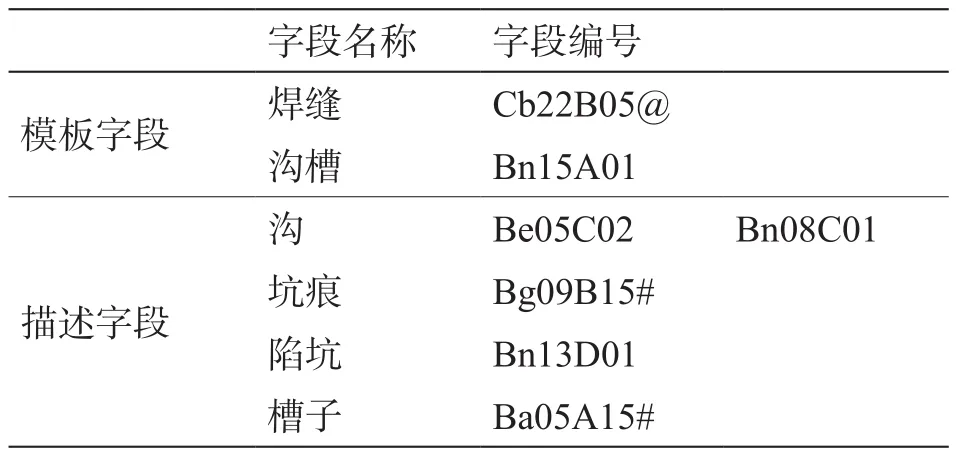
表4 字段編碼表Table 4 Field coding table

表5 田久樂方法計(jì)算結(jié)果Table 5 Calculation results of Tian's method

表6 王汀方法計(jì)算結(jié)果Table 6 Calculation results of Wang's method

表7 本文方法計(jì)算結(jié)果Table 7 Calculation results of the improved method

表8 計(jì)算結(jié)果對比Table 8 Calculation results comparison
4 結(jié)束語
管道行業(yè)數(shù)據(jù)容量已經(jīng)累計(jì)到大數(shù)據(jù)級別,建立大數(shù)據(jù)庫能夠有效提高數(shù)據(jù)利用率,實(shí)現(xiàn)數(shù)據(jù)描述字段的自動匹配,能夠?yàn)橹悄芑瘮?shù)據(jù)導(dǎo)入提供便利,節(jié)省人力物力。本文結(jié)合語義相似度計(jì)算算法,從內(nèi)檢測字段入手,通過增加路徑權(quán)重改進(jìn)現(xiàn)有計(jì)算方法,使其適用于管道行業(yè)。與其他方法對比證明了本文改進(jìn)方法的有效性。現(xiàn)階段管道行業(yè)亟待建立管道大數(shù)據(jù),字段匹配結(jié)合已有的數(shù)據(jù)對齊流程可實(shí)現(xiàn)多輪次數(shù)據(jù)的對齊,提高數(shù)據(jù)利用率的同時(shí),能夠?yàn)榘l(fā)掘管道缺陷和風(fēng)險(xiǎn)預(yù)測奠定基礎(chǔ)。
猜你喜歡
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
開放教育研究(2020年2期)2020-03-31 01:54:14
意林原創(chuàng)版(2016年10期)2016-11-25 10:28:30
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
