工作記憶與詞匯學習:基于詞圖匹配任務的事件相關電位研究
2019-02-20 01:58:00樊瑞文史華偉黃幸段懌煒鄢鶴銘常靜玲
中國康復理論與實踐 2019年1期
樊瑞文,史華偉,黃幸,段懌煒,鄢鶴銘,常靜玲
北京中醫藥大學東直門醫院神經內科,北京市100700
語言研究常常將語言結構拆分成不同的單位級,如音素、音節、單詞和短語等[1]。詞匯的產生涉及多個連續過程的相互協調,如概念準備、詞匯檢索、語音編碼、語音編碼和發音等[2]。目前對大腦學習詞匯形態的探索研究相對較少[3-4]。
工作記憶是大腦在短時間內維護和處理信息的重要功能單元[5]。Ullman 的語言模型認為[6],語言學習效率與人腦工作記憶系統密切相關。言語工作記憶與閱讀技能的顯著相關性在多個研究中已被證實,尤其體現在語義理解和語音流利度上[7-8]。工作記憶和音韻學的儲存與記憶密切相關,工作記憶受損的患者存在語言學習障礙,同時不能進行正常的語音表達[9]。巴德利語言交流循環模型認為[10],工作記憶與聽理解和口語表達密切相關。匹配和不匹配任務范式研究顯示[11],工作記憶在語言輸入和語言輸出過程中起緩沖和儲存作用。
漢語為象形文字,其詞匯與圖片聯系機制與符號文字存在差異。既往研究表明[12],漢語與英語的語言發生模式完全相反。對漢語-英語雙語者來說,工作記憶是實現語言實時交互的重要參與內容,在這個理論基礎上建立了Gerver 和Moser 模型。在Gerver 模型中,工作記憶參與書面詞匯信息的儲存和處理,也與語言輸出的轉錄編碼有關。在Moser 模型中,工作記憶在語言轉錄的不同過程參與書面詞匯的儲存和處理[13]。國內研究表明[14],在學習漢語字詞時,默寫法比抄寫法成績更好;具體到形、音、義的習得,默寫法對字形的習得更有效;對字音和字義,兩種方法沒有顯著性差異。該研究提示,工作記憶的參與對有鮮明字形特征的漢語語言學習十分重要。
對詞匯的掌握是語言學習的基礎,對詞匯形態特征的識別是學習詞匯的重要環節。大量研究通過測試詞匯水平來評價個體語言水平[15],其中圖片命名訓練和詞圖匹配訓練是常見的以語義理解為重點的詞匯學習方法[16],均可提高語義理解能力,但其響應腦區有較大區別,且受詞頻影響,詞圖匹配訓練模式增益效果穩定性更高[17]。詞圖匹配語言任務被廣泛應用于探索語義發生過程的認知實驗中[18],尤其是針對存在語言功能障礙的特殊人群,相對簡單的任務設計可更快、更早地發現語言理解問題[15],幫助臨床早期診斷。學習詞匯的不同策略對語言學習效果有重要影響[19]。開展基于漢語的詞圖匹配語言任務,對探索工作記憶影響漢語詞匯學習過程有重大意義。
人腦對語言的接收速度為每分鐘120~200個詞[20]。如何捕捉人類語言發生瞬間的腦功能特點,對測試手段的時間敏感性要求極高。事件相關電位(event-related potential, ERP)通過特定的任務刺激,記錄頭皮上反映特征成分偏轉的電位信息,客觀呈現大腦在語言產生過程中的動態變化,以毫秒級的高時間分辨率,在過去幾十年成為言語語言學家開展研究的有力工具,支持建立各種心理語言學模型[21-22]。
系列ERP研究表明[23-25],在語言學習的最初階段,相比正確的字形,錯誤的字形能誘發出較為明顯的N400 成分。N400 作為經典的語言相關成分,多年來對其特征的研究已達到一定的廣度與深度,該特征對刺激模式和感官輸入類型并不敏感[26]。對采用的研究方案,更推薦根據特定實驗目的定制實驗范式,而不是照搬套用既有經典模式。
本文基于漢語詞匯挑選實驗素材,以工作記憶作為變量,設計兩種適用于漢語為母語人群的詞圖匹配語言任務范式,通過對比N400 成分,探討影響詞匯學習的可能因素,討論詞圖匹配語言訓練的可能作用機制。
1 資料與方法
1.1 一般資料
2017 年12 月至2018 年6 月,在北京中醫藥大學東直門醫院招募20 例健康成年人,其中男性10 例,女性10 例。所有被試均為右利手,平均年齡(52.21±2.3)歲,平均學歷(9.21±0.73)年。自述無軀體疾病和精神障礙,裸視或矯正視力正常,母語為漢語,小學以上文化水平,既往無參與類似語言任務實驗經歷。
本實驗得到北京中醫藥大學東直門醫院倫理委員會批準。所有被試實驗前均簽署受試者知情同意書,實驗結束后按約支付一定報酬。
1.2 方法
從《現代漢語常用詞表》詞頻最高的12,000 個詞中,挑選日常生活中出現頻率較高的60個漢語雙字詞匯,筆劃5~30 劃,白底黑字,100 磅宋體。由首都師范大學美術專業技術人員繪制與詞匯對應的黑白素描圖,大小6 英寸(15.2×10.2 cm)。相關任務材料內容已在團隊前期研究發表[27]。
語言任務采用E-Prime 2.0 軟件進行編程和快速事件相關設計,以視覺方式在LED顯示屏上呈現。屏幕比例16∶9,分辨率1600×900。
任務1呈現順序:①呈現圖片1500 ms;②呈現空屏500 ms;③呈現漢語詞語1500 ms;③注視點“+”隨機呈現1800~2200 ms(平均2000 ms),提示被試者對詞、圖的語義進行判斷,若判斷詞、圖語義匹配,則按左鍵,不匹配則按右鍵。詞匯與圖片均隨機呈現,詞圖語義一致和不一致情況出現次數相等。
任務2 呈現順序:①呈現注視點“+”2000 ms,提醒患者做好準備;②詞語、圖片隨機呈現2000 ms,屏幕左側為圖片,右側為詞語;③注視點“+”隨機呈現1800~2200 ms(平均2000 ms),提示被試者對詞、圖語義進行判斷,若詞、圖語義匹配,則按左鍵,不匹配則按右鍵。詞匯與圖片均隨機呈現,詞圖語義一致和不一致情況出現次數相等。
兩組任務均重復120個周期。
1.3 數據采集
實驗在東直門醫院腦電生理室進行。被試戴上降噪無聲耳機,以舒服的姿勢坐在椅子上,盡量克制吞咽口水、眨眼、眼球移動等動作。采用Neuroscan Quik-Cap 64 導聯電極帽,按照10-20 國際標準安放。電極為Ag/AgCl 合金,包裹在軟橡膠內固定。采用SynAmps2 放大器和信號采集系統采集信號,帶通0.05~250 Hz,陷波50 Hz,采樣頻率1000 Hz。參考電極置于雙側乳突,同時記錄水平眼電和垂直眼電,頭皮中線FPz和Fz間中點接地,每個電極處頭皮電阻保持在5 kΩ以下。記錄N400成分的潛伏期和振幅測量
1.4 統計學分析
腦電數據在Matlab (美國MathWorks 公司)平臺上用eeglab 工具包離線處理,以全腦平均值作為參考,采用0.05~30 Hz 帶通濾波,同時去除眼電、肌電偽跡、差值壞導等。分析時程為從刺激呈現前200 ms到刺激呈現后1000 ms,以刺激前100 ms 作為基線進行校正。每個被試所有腦電數據進行疊加。
以具有代表性的電極代表不同腦區,包括左前額區(F3、F7、FC5)、前額中部(FC1、FZ、FC2)、右前額區(F4、F8、FC6)、左側中央區(T7、C3、CP5)、中央區(CP1、CZ、CP2)、右側中央區(C4、CP6、T8)、左側頂枕區(P7、P3、PO3)、中央頂枕區(PZ、O1、OZ、O2)、右側頂枕區(P4、P8、PO4)共9個腦區。
獲取被試各條件下N400 振幅,排除數據(±3 SD)以外的資料。用SPSS 21.0 統計軟件比較兩種任務下兩種條件的振幅;取兩種任務350~450 ms 范圍內振幅,以不匹配條件與匹配條件振幅差,進行組間配對t檢驗。
2 結果
6 例被試數據因實驗完成度差、偽跡噪聲大等因素被剔除。最終14 例納入分析,其中男性8 例,女性6例。
兩組任務在400 ms 左右均可誘發出N400 成分,任務1 平均潛伏期(326±7.84) ms,任務2 為(309.8±11.5)ms。任務1 峰值平均出現時間(394.8±18.58)ms,任務2 出現時間為(377.4±21.11) ms;任務1 平均振幅(-1.38±0.35) μⅤ,任務2 為(-0.28±0.25) μⅤ。各腦區N400情況見表1。
N400 效應較大的腦區為左側頂枕區、中央頂枕區、右側頂枕區,右側前額區也可見較為明顯的N400 效應。任務1 能誘發出更大的N170、P1 成分,N400 振幅更大;不匹配下N400 振幅高于匹配。作400 ms 時點任務1 與任務2 腦地形圖,兩個任務均在中央頂枕區有激活,任務1 激活強度更大,且有右側偏向特性。見圖1、圖2。
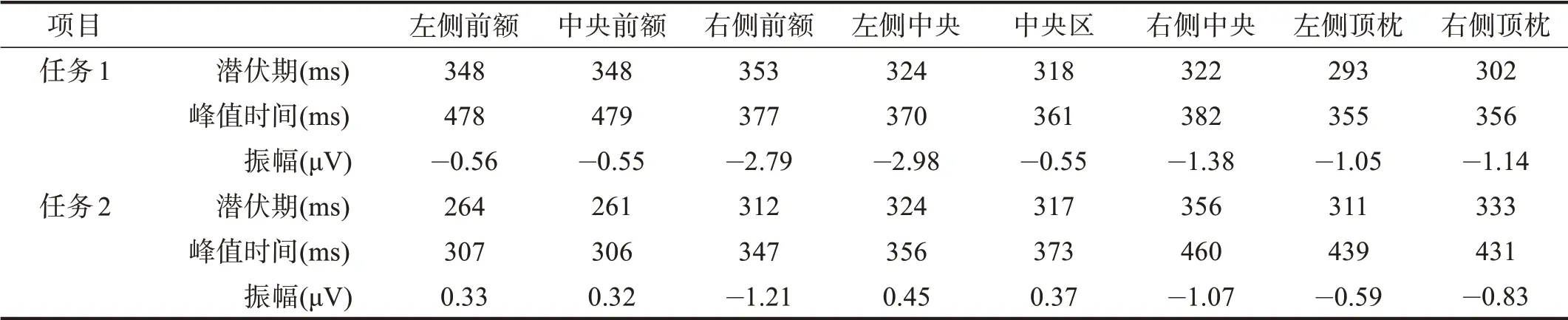
表1 兩種語言任務腦區激活情況表
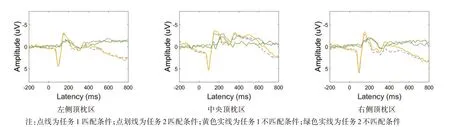
圖1 不同條件下各任務ERP總平均圖
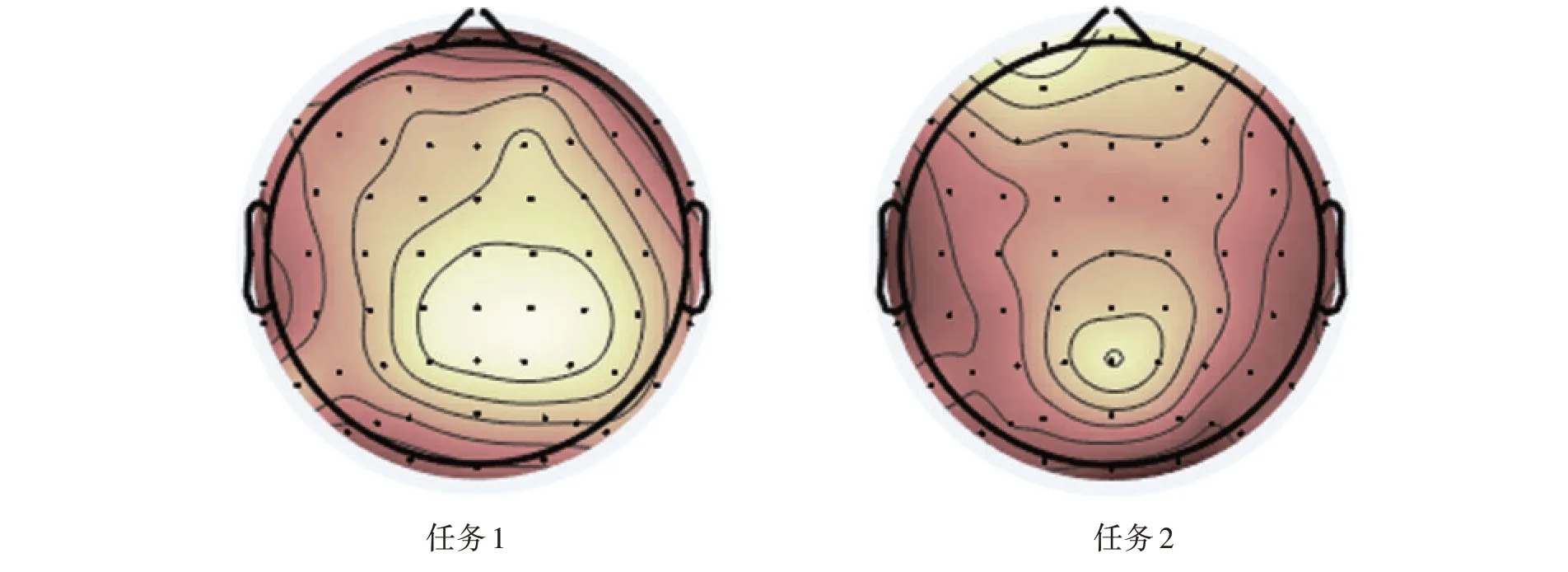
圖2 各任務腦地形圖
不同腦區不匹配、匹配條件下振幅差,任務2 多為正(匹配條件振幅更大),任務1 多為負(不匹配條件振幅更大)。9 個腦區,除右側前額和左側中央區外,其他7 個腦區均有顯著性差異,中央前額、中央和右側頂枕區差異最大。見表2。
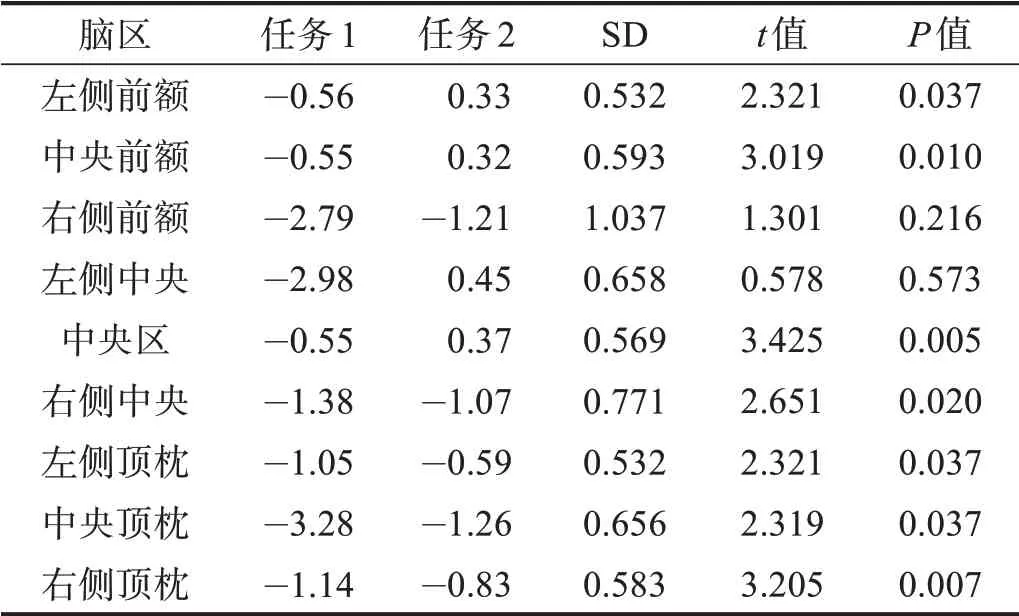
表2 兩種任務各腦區不匹配、匹配N400振幅差值比較
3 討論
圖片與詞匯的關系是語言學研究的熱點。圖片命名的特征認識、發音特點和含義識別三個過程并非同時發生:發音特點在特征編碼之后,在詞匯識別較早期即可發生;而語義識別則在較后的階段才產生[28-29]。詞匯產生過程中,人腦是否需要檢索詞匯語法特征存在爭議。既往研究表明[30],人腦只有在處理復雜形態結構的語言(如意大利語)時,才會涉及語法性過程,而在較為簡單的語言形態處理中,則不涉及該過程。漢語被認為是結構相對簡單的蒙太奇形態語言,詞匯-圖片干擾范式結合腦電圖研究漢語詞匯語法分類特性,表明人腦對漢語裸詞的處理不包含語法性過程[31]。
N400 常被用來反映圖片的概念識別、語義處理及聯系的能力。語義相近的詞圖下,N400 衰減,潛伏期更短[32-33]。相似現象也出現在對詞匯的音韻特點加工處理上,包含語音處理過程的N400 振幅更大,潛伏期更長[34]。本研究顯示,N400在詞圖匹配情況下衰減,潛伏期更短,與傳統結論一致。
本研究實驗素材為漢語詞匯,詞圖匹配任務單純反映人腦對漢語詞匯語義加工處理的神經電活動情況,理論上不涉及語法效應混雜因素。本研究顯示,分屏呈現語言任務形式較同屏呈現形式誘發N400 效應更顯著。可能機制為,分屏呈現形式在同等時間內分配更多資源給圖片和詞語,使人腦對單個刺激擁有更為完整的處理過程。
P1/N170 效應最早被發現于面孔識別研究。研究者發現[35-37],相比面對房子、植物等物體圖片,人類在識別面孔,尤其是倒置面孔時,會誘發更為深大的P1/N170 波。后期研究表明,該效應與“面部”并不相關[38],在信息處理的不同階段包含很多重要的潛在機制。N170 成分反映早期視覺注意定向,更多反映視覺信息處理的一般機制,與刺激對象的內容并無特定聯系。P1 成分代表空間注意對視覺加工的早期影響,反映任務注意力獲取機制,并導致知覺加工增強[39]。
本研究顯示,兩種語言任務在P1/N170 效應方面有明顯差異。在無工作記憶參與的同屏呈現詞圖匹配語言任務中,P1/N170 有較大衰減;而有工作記憶參與的分屏呈現模式中,有較為明顯的P1/N170 效應發生。工作記憶損傷人群(如阿爾茨海默病患者)中P1/N170 潛伏期較健康人增加[40],孤獨癥兒童P1/N170 衰減,同時伴隨記憶力下降[41]。
以上研究表明,P1/N170 效應與工作記憶密切相關。結合N400 效應,可以認為,工作記憶的參與提高個體對目標刺激的注意,強化大腦對詞匯的識別過程;提示在語言康復訓練中,采用詞匯、圖片分別呈現,加入記憶模塊的方式,有助于提高語言康復訓練效率。
人類有著強大的詞匯學習能力。腦損傷患者詞匯獲取功能不同程度下降[42]。詞匯學習的重塑是語言功能恢復的關鍵環節,詞匯能力的提高與失語癥人群語言能力恢復關系密切[43]。制定密集有效的詞匯康復方案,幫助失語癥患者激發相應腦區對詞匯學習的活躍度[44]。提高對詞匯字形的識別能力,是治療嚴重語言障礙的有效策略[45]。
經典匹配任務時,N400 激活腦區多分布在額頂區,且有右側偏向趨勢[26]。本研究中N400 分布區域與經典理論模型趨勢一致,表明語言任務設計能有效還原人腦學習詞匯過程中的神經元電活動情況。本研究設計語言任務原型為語言康復訓練過程中詞匯學習訓練場景,本研究表明,語言康復訓練激活人腦頂葉神經元電活動。頂葉是人腦重要功能區,一般認為與計算、注意和記憶等高級皮質認知功能相關,也與動作模仿[46]和視覺動態追蹤[47]密切相關。本研究提示,兩種語言任務均可產生頂區激活,而分屏任務誘發N400 更具右偏趨勢,且振幅更高,區域更廣。提示有工作記憶加入的語言任務能更大激發頂葉神經元電活動,調動更多視覺與注意功能。通過調動工作記憶、詞匯、圖片識別刺激,可有效訓練人腦對語義加工、視覺識別以及集中注意力等能力,可應用于對輕度語言障礙人群的篩查、評價和訓練治療中。
本研究以漢語雙字詞及其對應手繪素描圖為實驗材料,模擬語言康復訓練場景,編寫兩種詞圖匹配判斷任務,結合ERP技術,探討工作記憶與詞匯學習識別的關系。研究顯示,分屏呈現實驗任務(有工作記憶因素參與)與同屏呈現實驗任務(無工作記憶因素參與)下,神經元響應特點有明顯差異。語言康復訓練中的詞匯識別對人腦語言功能有正性刺激作用,而充分調動記憶功能,可能對幫助語言發生有強化作用。該模式可進一步運用到語言障礙人群的康復治療中。
本研究不足之處在于,作為評價手段,任務僅適用于詞匯水平,無法對更為復雜的語法、邏輯關系等句義水平進行評價;受試數據集較小,僅有健康人,未體現其應用優勢。相對語言量表(多為自評量表)無法測評輕度言語語言障礙,電生理手段更為敏感且客觀,在諸如失語癥等的治療和評價中,有較好的應用推廣空間。
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
文苑(2020年4期)2020-05-30 12:35:30
開放教育研究(2020年2期)2020-03-31 01:54:14
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
現代語文(2016年21期)2016-05-25 13:13:44
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
大連民族大學學報(2015年2期)2015-02-27 08:28:11
