基于SOM神經網絡的網絡輿情信息分類模型
2019-04-11 02:01:36胡欣杰
兵器裝備工程學報 2019年3期
胡欣杰,路 川,齊 斌
(航天工程大學, 北京 101416)
隨著互聯網技術的快速發展,網絡成為人們工作和生活不可缺少的工具,使用互聯網的用戶呈現快速增長的趨勢,公眾在互聯網上發表言論的活躍程度空前高漲,網絡媒體成為繼電視、報紙、廣播之后的“第四媒體”。根據CNNIC第42次中國互聯網發展狀況統計報告,截止2018年6月,我國網民規模為8.02億,手機網民規模達7.88億,輿論觀點、意見、情感態度等信息都可以在網絡上充分表達。輿情是指在一定的社會空間內,圍繞中介性社會事件產生及發展變化,民眾對社會管理者產生和持有的社會政治態度[1]。網絡輿情是人們通過互聯網表達和傳播的各種不同情緒、態度和意見的總和[2],在傳播、演化和形態上有四個特點[3]:一是傳播速度快,網絡輿情通過網絡,以網頁新聞、論壇等形式同時被人瀏覽、討論和發表觀點,其傳播速度之快其他媒介無法企及;二是形態多樣,網民在網絡上不受約束地發表各種觀點、態度和看法,形成了各種形態的輿論;三是傳播廣泛,網絡環境的復雜性使得網民分布在世界各地,各種類型的網民都可以對一個輿情發表觀點,通過網民的討論轉發能快速傳播至世界各地;四是事件突發,由于網絡遍及世界的各個角落,無論在什么地方,一旦出現突發情況,通過網民的討論轉發及傳播,事件會被不斷地放大,迅速成為網絡輿情,引發全社會關注和討論,因此研究網絡輿情檢測技術,構建輿情監測系統是非常重要的,是構成國家和軍隊安全的重要裝備。
1 網絡輿情信息分類方法
有效地監測網絡輿情信息的途徑是首先進行網絡輿情信息的采集,之后對輿情信息進行預處理,即對采集到的信息進行文本的分析和歸類,主要采用的技術有輿情信息的分詞、分類聚類、文本的表示與主題發現、話題的識別與跟蹤、文本信息的情感性分析等。分詞是將連續的字序列信息按照一定的規則分解成詞序列,實現信息按詞識別,目前已有較為成熟的分詞系統,但隨著語言的復雜化,要解決多語言的分詞方法、詞性的標注、歧義詞處理和識別等問題;分類聚類是對采集的數據進行歸類處理,實現信息按照類別的劃分,分類和聚類的方法很多,其目的是實現聚類分類的準確率和高效率;文本表示與主題發現是對各種類型的信息進行文本歸一化處理,概括出信息的主題;話題的識別與跟蹤是指自動識別新話題和持續跟蹤原有的話題;文本信息的情感性分析是指根據文本的觀點性詞語,分析和總結網民主體的態度和傾向性[4-5]。
輿情信息的分類是指預先定義好文本的類別,對大數據文本進行高效快速的分類,而輿情信息的聚類無需事先定義類別,通過聚類算法劃分出群和類別,后者更具有自主學習性,二者都屬于輿情信息分類的大范疇,針對信息屬性的不同采用不同的方法或二者聯合使用[6]。輿情信息文本分類的方法有基于統計的文本分類方法、基于連接的文本分類方法和基于規則的文本分類方法。
基于統計的文本分類算法有樸素貝葉斯算法和支持向量機分類算法,樸素貝葉斯分類算法是以貝葉斯定理為基礎,對于文本相互獨立,取后驗概率最大的一個或幾個類別作為文本最終類別,面對網絡輿情大數據,使用樸素貝葉斯分類算法訓練集的完備性較差,需要花費大量的時間運算和存儲管理,時間效率降低;支持向量機算法是基于統計學習理論的機器學習方法,計算相對簡單,主要是通過尋找結構化風險最小來提高學習的泛化能力[7]。
基于連接的文本分類方法有人工神經網絡算法,人工神經網絡是模擬人腦神經系統進行迭代運算,其間輸入神經元和輸出神經元有大量的節點相互連接,具有自學習和聯想存儲功能,具有高速尋找最優化解的能力。
基于規則的文本分類方法主要有決策樹方法,根據已知各種情況發生的概率,通過訓練數據形成決策樹,實現對未知數據的分類,決策樹算法可讀性好、效率高、一次構建重復使用。
文本聚類也是文本分類最有效的方法[8],文本聚類有多種算法:層次聚類算法,可實現自底向上的聚類,也可以實現自頂向下的聚類,此方法對聚類的對象屬性沒有要求,聚類粒度靈活,可大可小,但不適應動態聚類;基于密度的聚類方法,是通過考察一個臨近區域的某個點的密度是否超過一定的閾值,如果超過,則將其納入聚類中;除此之外還有基于網格的聚類算法、基于模型的聚類算法如SOM神經網絡聚類算法等。各種算法有其優缺點,根據應用需求加以選擇。
2 改進的SOM分類模型算法和流程
SOM是自組織神經網絡,非監督式學習算法,采用競爭式網絡架構,其輸出層神經元根據輸入層神經元的數據特征,將任意維度的輸入向量以非線性的投影法映射到二維或低維度的特征空間上。SOM的3層架構包括,輸入層、輸出層和網絡拓撲層,輸出層是以網絡拓撲層為核心形成的輸出神經元的集合。
輸入層設有m個輸入神經元,用輸入向量X={x1,x2,…,xm}表示,每一個神經元相互獨立,神經元之間連接權重相互獨立,輸入層神經元個數依據具體問題確定,沒有限制。
輸出層由n個神經元組成一維或二維平面網絡拓撲結構,每一個輸出神經元都與所有的輸入神經元連接,依據連接權重作為神經元之間關系的強弱,輸出層神經元個數依據問題確定,使用鄰近區域來描述鄰近神經元之間的關系,包括的參數有鄰近中心C,鄰近半徑R,鄰近距離D等。
鄰近區域是以鄰近中心為原點鄰近半徑范圍內的區域;一般是以網絡拓撲中勝出的神經元作為鄰近中心,其計算公式如下[9]:
Ck=mink||X-Wk||
(1)
通常情況下,初始的鄰近半徑設置較大,隨著學習訓練的次數的增加不斷迭代,逐漸縮小,設初始鄰近半徑為R0,第n次循環的半徑為Rn,則n+1次的半徑為γRn,0<γ<1,γ為調整系數。
鄰近距離表示某個輸出神經元k與鄰近中心C的距離,一般用歐式距離來計算鄰近距離,如式(2)所示[9]:
(2)
使用SOM神經網絡進行分類的基本思想是,對于提供給網絡的任意一個輸入向量,確定輸出的獲勝神經元s,其中s=arg minc|τ-Wc|,所有的c屬于δ。確定獲勝神經元s的一個鄰域范圍,利用迭代計算各輸入神經元(輸入向量)與輸出層處理單元間的連接權值向量,使得內神經元的權重向量向輸入向量靠攏,通過競爭學習算法不斷調整連接權重值,不僅獲勝的神經元要訓練調整權值,它周圍的神經元也要不同程度的調整權值,Wc=Wc+ε(τ-Wc),所有的c屬于M。以獲勝神經元為中心,設定一個鄰域半徑R,該半徑圈定的范圍為優勝鄰域,通過多次訓練和迭代,直到輸入向量與連接權重的總距離為最小時或者最大學習循環時,停止訓練,形成一種分類[10-11]。
使用SOM神經網絡實現網絡輿情信息的分類聚類,具有簡明性和實用性,具備自主學習功能,會取得較好的效果,但是SOM神經網絡算法要求網絡結構是固定的,不能動態改變,網絡訓練時有些神經元始終不能獲勝,成為“死神經元”,網絡連接權重的初始狀態,算法中的參數選擇對網絡的收斂性影響較大,這樣在進行網絡輿情分類時,降低了分類的查全率,同時受到網絡連接權重初始值的影響,查準率也受到影響,為此基于SOM神經網絡進行了算法的改進,為每個輸出的神經元增加一個閾值,每次使競爭獲勝的神經元閾值增加,使經常獲勝的神經元獲勝的機會變小,避免死神經元的出現,同時為每個輸入神經元都增加了學習效率和鄰域區域,并按照學習時間自動調整學習效率和鄰域的大小,提高了分類的準確性。改進后的SOM算法流程如下:

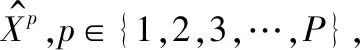


步驟5:為每個輸出神經元設置閾值ρj+1=ερ,0<ε<1;
步驟6:定義優勝鄰域Nj*(t),該優勝鄰域為鄰域中心確定時刻的權值調整域,通常設置一個較大的初始鄰域,訓練時隨著訓練時間增長逐漸收縮鄰域范圍;
步驟7:對優勝鄰域Nj*(t)內的所有神經元調整權重:
i=1,2,…,n;j=nj*(t)
步驟8:設L=L+1,返回步驟3繼續迭代;
步驟9:查看學習率μ(t)是否小于0,或者小于閾值μmin,或者循環次數是否最大為T,是,則結束,否則返回步驟3繼續迭代。
3 實驗驗證及結果分析
衡量分類或聚類算法的優劣,最直觀的方法是類內盡可能相近,類間相似度最小,使用平均正確率、平均墑、查全率和查準率均能在一定程度上反映出聚類算法的效果。
本文基于改進的SOM神經網絡分類模型算法實現網絡輿情分類實驗,使用查全率R和查準率P作為檢驗本算法有效性的參數,查全率R越大表示信息分類聚類覆蓋性越全;查準率P越大表示信息分類越準確。事實上,R與P之間是一個相互制約的關系,在極端情況下,只聚類出一個結果且是準確的,P為100%,R則很低,如果把所有的聚類結果都返回,R為100%,P則很低,因此P和R是一個反比的關系。R和P定義如下:
R=(聚類后正確反應主題某一個類的文檔數/人工判斷主題某一個類所包含的文檔總數)×100%
P=(聚類后正確反應主題某一個類的文檔數/聚類后輸出的反應主題某一個類所包含的文檔總數)×100%
以目前比較熱門的芯片業“微處理器”為主題,在網絡上搜索出以此為主題的網頁1 880篇,隨機抽取100篇、300篇、500篇、700篇,使用本文改進的SOM神經網絡模型進行聚類,分別得到10、13、16、18個分類,均包含有“嵌入式微處理器”類,進行兩次聚類,第1次設網絡學習總的迭代次數L=15,輸出層節點40×40,初始鄰域半徑20,學習效率為1;第2次設網絡學習總的迭代次數L=20,輸出層節點60×60,初始鄰域半徑30,學習效率為1,結果如表1所示。
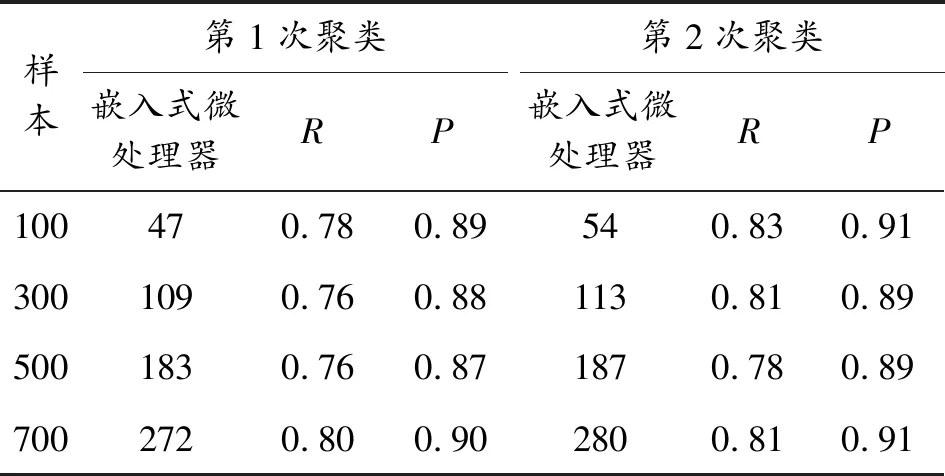
表1 基于改進的SOM聚類模型查全率R和查準率P
按照統計分析SOM神經網絡算法的正確率在60%~90%之間,從上表可以看出,通過改進SOM算法,使查全和準確率均有提升;另外當使用該算法將迭代次數增加,輸出節點數增加,初識鄰域半徑擴大,也會提高其查全和準確率。在信息檢索中,查全率和查準率是相互制約的,本算法在保證較好的查全率基礎上,得到了好的查準率。
4 結論
SOM分類算法用于文本的聚類的優點在于它是一個無監督的學習方法,網絡拓撲結構反映了輸入文本的分布情況,不需要對文本之間的相對獨立性做任何假設,可以自動提供類別標注且易于可視化,但由于其網絡拓撲結構的局限性,本文對此進行改進并將其應用到網絡輿情信息分類建模中,取得了較好的效果。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
