基于數據挖掘的圖書館智慧服務體系研究
2019-05-24 06:29:14琦b
圖書館界 2019年2期
康 娜,于 琦b,李 琳,賀 強
(山西醫科大學 a.圖書館;b.管理學院,山西 晉中 030619)
1 圖書館智慧服務現狀
隨著信息技術的不斷發展,圖書館正在從封閉、機械的服務方式向開放、智慧的服務方式轉變,如何存儲海量數據、如何從海量數據中挖掘出有價值的信息、如何培養出高水平的圖書館員是實現圖書館智慧服務的重點。2003年,芬蘭學者Aittola M提出“智慧圖書館”的概念,隨即成為圖書館的研究熱點。武漢大學信息資源研究中心陳遠等提出,智慧服務包括智慧性技術服務和智慧性知識服務。智慧性技術服務是指通過使用智慧化設備幫助讀者實現知識的“易知易用”。例如Kiril Antevski等提出一種基于低功耗藍牙和Wi-Fi的混合定位系統,用戶通過該系統在智慧圖書館中按照興趣創建學習群,在該群內與興趣相同的人進行學習和討論。智慧性知識服務指通過對圖書館海量數據進行挖掘,最大限度地開發其價值,為圖書館智慧性知識服務提供建議。例如青島大學陳淑英等采用關聯規則數據挖掘技術對不同專業用戶群4年圖書借閱數據進行分析,為圖書館提供有針對性的圖書推薦方法,提升圖書館智慧性知識服務能力。江蘇理工學院柳益君等提出圖書館智慧服務需求表現在四個方面:1)知識零空間共享,讓隱性知識顯性化,讓知識的傳播沒有障礙;2)個性化推薦,根據用戶需求,為用戶提供更有針對性的知識服務;3)知識導航,將知識按主題劃分模塊,為用戶提供不同主題的知識模塊;4)圖書館業務優化,優化圖書館館藏、采購質量、人員配備、信息安全等,并根據用戶需求安排閱讀推廣、講座等不同主題的活動。目前,國內圖書館智慧服務研究主要集中于智慧服務模式、發展策略和技術實踐這三個方面,其中關于技術實踐研究的論文較少。鑒于此,本文基于圖書館智慧服務需求提出基于Hadoop的圖書館智慧服務體系,探討圖書館智慧知識服務,為圖書館采用大數據挖掘算法和技術實現智慧化知識服務提供參考。
2 基于數據挖掘的圖書館智慧服務體系
2.1 基于Hadoop的技術支撐體系
隨著互聯網技術的快速發展,圖書館產生巨大的數據量,海量數據的挖掘成為圖書館實現智慧服務的關鍵問題。Hadoop是Apache開源組織的一個分布式計算開源框架,具有跨數據源分析、離線計算、對數據進行二次加工等優點,Hadoop HDFS具備動態擴容和冗余化存儲的能力,滿足圖書館數據挖掘的需求。故本文構建了基于Hadoop的圖書館大數據挖掘技術支撐體系,以支持圖書館的智慧服務,如圖1所示。
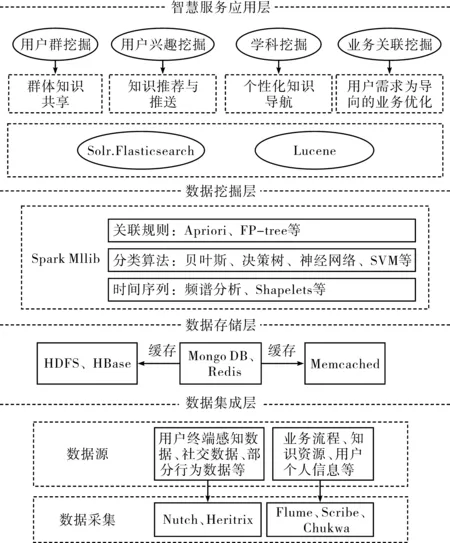
圖1 基于Hadoop的技術支撐體系
2.2 數據集成和存儲
2.2.1 用戶數據。用戶數據包括:1)顯性行為數據,如讀者借閱數據、下載、收藏、打分等;2)隱性行為數據,如讀者瀏覽記錄、點擊量等;3)個人信息數據,如性別、年齡、專業等;4)社交數據,如論壇、微博、微信等;5)終端感知數據,如位置、時間、設備參數等。
2.2.2 知識資源。知識資源數據包括書目庫、專利庫、中外期刊文獻、電子資源等。
2.2.3 業務流程。業務流程數據包括各類咨詢、檢索查新、資源采購、館際互借、文獻傳遞、門禁、選座系統等。
用戶數據中的社交數據、終端感知數據、部分行為數據等屬于外部數據,需要通過爬蟲技術從互聯網上采集,如Nutch、Heritrix等。知識資源、業務流程、讀者個人信息等屬于館內數據,可通過Cloudera的Flume系統、Facebook的Scribe系統、Apache的Chukwa系統等進行采集,以供后續數據分析使用。Flume系統設計架構巧妙,提供了豐富的agent和collector,用戶幾乎不必進行任何額外開發即可使用。Scribe系統設計簡單,易于使用,但容錯和負載均衡方面不夠好。Chukwa系統屬于Hadoop系列產品,直接支持Hadoop,但版本更新較快。
Hadoop的HDFS具備動態擴容和存儲多份數據的能力,是大數據存儲中最主流的解決方法之一,一般用于存儲處理要求不高的數據,例如圖書情報界全年關于智慧服務的論文。MongoDB適用于實時的插入、更新與查詢的場景,例如讀者社交信息、讀者查詢記錄等。HBase適用于海量數據的存儲和高并發查詢的場景,例如圖書館電子資源訪問日志。Memcached和Redis為關系型數據庫提供了緩存機制,提升了系統響應速度。
2.3 數據挖掘算法
數據挖掘可以從海量數據中最大限度地挖掘出有價值的信息,為圖書館智慧服務提供依據。面對海量數據傳統的數據分析模型已經無法應付,基于Hadoop的MapReduce框架提供了解決方案,并得到充足的發展。然而,相較傳統Hadoop MapReduce框架法,SparkMLlib在運行速度、易用性、通用性及容錯性上都有更好的表現,擁有更高更快更強的計算速度。故在數據挖掘層采用SparkMLlib機器學習庫,包括關聯規則、分類、時間序列等50多種常見的分布式模型訓練算法。
2.3.1 關聯規則算法。關聯規則挖掘是數據挖掘重要算法之一,其目的是分析和預測項目間的關聯強度。迄今為止,有很多高效的關聯規則算法被提出,其中最重要的是美國學者R.Agrawal于1993年提出的Apriori算法,以及J.Han等人于2000年提出的FP-tree算法。在圖書館智慧服務中,關聯規則算法使用范圍廣、頻率高,主要用于挖掘讀者借閱記錄和借閱日志建立分析模型,根據分析結果向讀者推薦強關聯圖書,實現圖書館智慧服務,同時還可根據分析結果調整館藏布局,減少讀者找書的時間。北華大學李欣提出在圖書館集成管理系統的基礎上采用強關聯規則挖掘技術實現圖書精準查詢和個性化推薦功能。
2.3.2 分類算法。分類算法的目的是將圖書館讀者群體按照專業、性別、年齡等因素進行分類,找出各群體的特征、群體間的關聯、識別特殊群體等。根據群體特征圖書館可提供有針對性的服務,從而提高圖書館的服務質量,實現圖書館智慧化服務。常見的分類算法有貝葉斯分類、決策樹分類、神經網絡、SVM等。電子科技大學圖書館員彭瑩采用C5.0決策樹對讀者借閱數據進行分析,建立讀者借閱頻度決策樹分類模型,根據分析結果對圖書館的流通規則和采購策略提出優化建議。
2.3.3 時間序列算法。時間序列研究的是該數列隨時間發展變化的規律,主要用于研究圖書館讀者、資源的流通規律,建立分析預測模型,預測未來某段時間圖書館的情況,為圖書館開展服務活動、人員安排等方面提供支持。寧夏師范學院王建對寧夏師范學院圖書館2011—2016年圖書資源相關數據進行短期預測分析,建立季節指數平滑模型,通過實驗證明模型檢驗效能較好。
2.4 智慧服務應用
在圖1的智慧服務應用層中,Lucene是Apache支持和提供的一個開源的全文搜索引擎工具包,提供了完整的查詢引擎和索引引擎。Slor和Elasticsearch則是兩個基于Lucene的、有著豐富的查詢語言的全文搜索服務器,為檢索、推送、知識導航、知識問答等智慧服務應用提供了技術支持。基于數據挖掘的智慧服務應用主要體現在以下4個方面:1)用戶群挖掘。用戶社交數據包括科研成果、研究方向、學歷、專業等個人信息,以及微信、QQ等社交數據,用戶群挖掘是對用戶社交數據采用關聯規則、聚類、時間序列等挖掘方法分析出用戶之間的關聯,實現知識共享。2)用戶興趣挖掘。采用已有的數據挖掘技術對用戶興趣數據進行挖掘,分析用戶需求,根據分析結果有針對性地向用戶推薦各類資源,實現智慧性知識推薦。3)學科和領域知識挖掘。采用數據挖掘方法對文獻、知識資源數據進行挖掘,實現自動知識導航。4)業務關聯挖掘。業務數據包括用戶咨詢數據、科技查新數據、資源采購數據、流通數據、用戶行為數據等,采用關聯規則、聚類、時間序列等分析方法對業務數據進行挖掘,發現某時間段、某類用戶與某種業務之間的關聯,發現進館人數與天氣的關聯,為圖書館開展服務活動、資源采購、人員安排等方面提供支持。
3 基于數據挖掘的圖書館智慧知識服務探討
建立符合自身機構特色的智慧知識服務引擎是圖書館智慧服務方式之一,目的是為用戶提供有針對性的服務,提高圖書館知識資源的利用率。本文提出一種智慧知識服務引擎體系,如圖2所示。
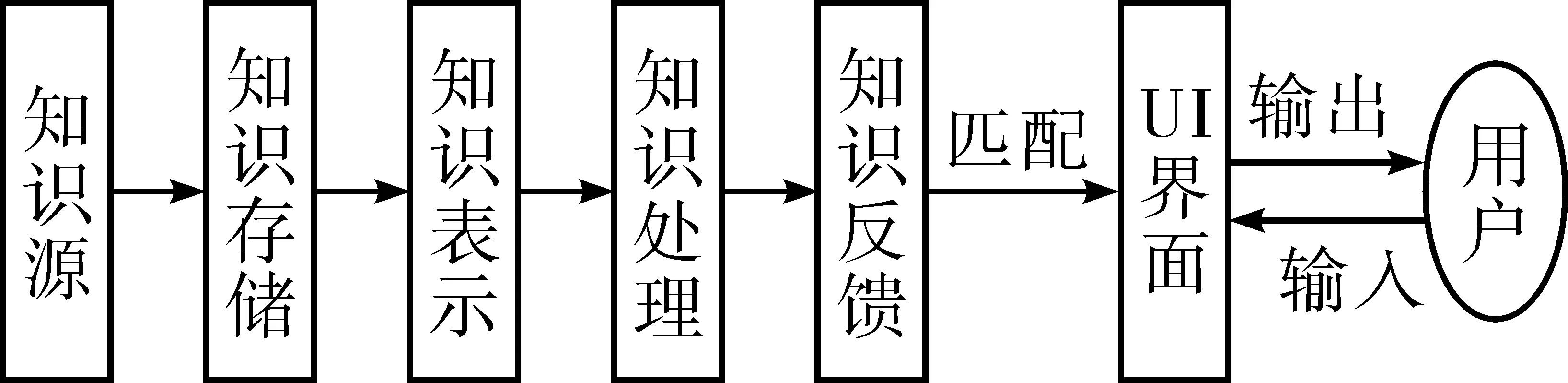
圖2 智慧知識服務引擎框架圖
智慧知識服務引擎包括知識源層、知識存儲層、知識表示層、知識處理層和知識反饋層4個部分。第1層是知識源層,即圖書館數據來源,只要能夠為用戶提供智慧服務、滿足用戶知識需求的數據都可作為知識源,一般分為以下3類:1)館內藏書、文獻、電子數據庫等靜態知識源;2)RFID、讀者借閱行為記錄、圖書館電子設備記錄數據等動態知識源;3)館際互借數據、文獻傳遞等館外知識源。第2層是知識存儲層,根據數據大小、類型、更新頻率等特有性質將知識分層動態存儲,方便隨時調用。第3層是知識表示層,將知識進行統一標識,文章提出的引擎體系采用本體表示法,讓隱性知識變為顯性知識。第4層是知識處理層,主要包括以下3個處理過程:1)對數據進行預處理和簡單的統計分析;2)根據數據特性采用相應的數據挖掘方法,建立知識分析模型庫;3)對分析后的知識進行信度與效度檢驗,通過檢驗將其存入知識庫中,并將知識庫劃為學科庫、專題庫、知識導航庫、特色知識庫等。第五層是知識反饋層,根據第四層建立的知識庫建立索引庫和倒排檔,當用戶輸入服務請求后系統經過前四層的處理,最后在第五層的索引庫和倒排檔中進行知識匹配,并將匹配結果按照匹配度大小輸出到交互界面。經過以上五層知識處理,用戶在交互界面得到與請求相匹配的個性化檢索結果,實現圖書館個性化智慧服務。
4 結 語
在“互聯網+”背景下,信息技術不斷發展,圖書館的數據量激增,應用數據挖掘技術實現圖書館的智慧服務是圖書館發展的必然趨勢。基于Hadoop的技術支撐體系實現了圖書館數據的集成、存儲、處理和應用,數據處理是核心環節,是實現圖書館知識共享、知識推薦、知識導航等智慧服務的關鍵技術,基于數據挖掘的圖書館智慧知識服務成為圖書館服務新模式。本文的研究為圖書館應用數據挖掘方法和技術實現圖書館智慧服務提供了參考,但仍存在一定的局限性和不足,未來可側重于研究如何應用數據挖掘方法從海量圖書館數據中找到更有意義有價值的信息,從而使圖書館實現更精準的智慧化服務。
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
信息通信技術(2015年6期)2015-12-26 01:16:46
小天使·一年級語數英綜合(2014年6期)2014-07-22 23:32:38
電子設計工程(2014年18期)2014-02-27 12:00:13
智慧與創想(2013年7期)2013-11-18 08:06:04
當代修辭學(2011年2期)2011-01-23 06:39:12
