基于時間序列分析法對社會消費品零售總額的預測
2019-06-27 00:18:42馬愛華楊右棟李莉
經濟研究導刊 2019年12期
馬愛華 楊右棟 李莉

摘 要:針對張掖市2004—2017年的社會消費品零售總額數據值構建時間序列長期趨勢擬合分析模型,并對2018—2020年張掖市的社會消費品零售總額進行預測,得出張掖市社會消費品零售總額呈現出逐步增長的上升趨勢,預測的結果有較強的可利用價值,為張掖市未來五年內的宏觀調控提供了可靠的科學理論支持。
關鍵詞:社會消費品零售總額;時間序列分析法;長期趨勢預測;張掖市
中圖分類號:F224? ? ? ? 文獻標志碼:A? ? ? 文章編號:1673-291X(2019)12-0061-03
引言
中國經濟自2002年以來保持持續增長的發展趨勢,同時居民收入穩步提高,人們的消費水平也隨著消費環境的逐步優化而不斷提升,由此直接推動了社會消費品零售總額的增加。因此,對社會消費品零售總額進行科學的推測是促進中國經濟健康發展的必要前提。
一、社會消費品零售總額的內涵
(一)社會消費品零售總額概述
1.指標簡述。社會消費品零售總額是指批發業、零售業、住宿業、餐飲業和其他行業直接售給城鄉居民和社會集團的消費品零售總額。居民消費品零售額,是指銷售給城鄉居民的用于日常消費的生活性商品銷售額[1]。社會集團的消費品零售額,是指售賣給黨政機關、社會團體、軍隊、學校、企事業單位、居民委員會或村民委員會等,使用公共財產購買的主要用于非生產、非經營消費和公共共同使用的商品銷售額。該指標充分反映了特定時期內人們的生活水平提升程度、社會零售商品的支付實現情況、社會生產、零售市場的規模概況、貨幣流通以及物價發展變動趨勢。在各類與消費相關的統計數據中,該指標最直觀地表現了國內消費需求,研究了國內零售市場的變動態勢、宏觀經濟的景氣程度[2]。
2.指標統計方法。社會消費品零售總額統計指標于20世紀90年代初具模形,為了更科學地進行統計,并使統計到數據值更加精準,21世紀初,國家統計局對該指標的統計范圍、統計方法、統計口徑和填報內容等進行了統一規定,逐步形成“聯網直報、超級匯總、抽樣調查相結合”的統計調查體系[3]。
(二)社會消費品零售總額的構成
社會消費品零售總額統計指標用來研究人民生活、社會消費品購買力、貨幣流通等問題,因此在實際的應用中[4],會根據研究范圍、研究用途、研究目的等需求的不同,將范圍較廣的社會消費品零售總額以不同的劃分標準分為若干個相關的子范圍,使研究范圍、用途、目的等更加明確、精細化,逐步擴大了社會消費品零售總額統計指標在實際生活中的可用性。
二、時間序列分析的基本方法
(一)時間序列分析法概述
時間序列分析法是根據預測目標的歷史和現在的時間數據,通過研究其基本發展趨勢和規律,構建擬合度較高的數學模型,根據此模型外推預測目標的一種定量預測法。其預測的根本依據是“慣性原理”,因此一般運用該方法預測時包含以下兩個假定前提:一是承認預測對象所具備的慣性。利用過去的統計數據,就能延續預測出事物未來幾年的數據。二是設定預測對象的趨勢性僅與時間這個變量相關。任何事物的發展都不是必然的,或多或少都會受到偶然因素的影響,因此假定主要考慮的只有一個影響因素——時間。其內容包括:其一,收集并整理需要預測數據的歷史值;其二,檢驗所采集的數值,依照次序組成數列;其三,觀察時間數列,找到研究指標隨時間變化而變化的趨勢性;其四,擬合適當的模型來預測該統計指標以后年份的數據值。
(二)時間序列分析方法
時間序列分析方法按分析方法的不同分為數據圖法、指標法和模型法[5]。
1.數據圖法。利用直觀的數據比較或繪圖,直接觀察序列的總趨勢和周期變化以及異常點、缺失點、離散點等。其操作簡單、直觀有效,通常是統計時序分析第一步。
2.指標法。是指通過計算一系列的核心指標,來反映所研究的時間序列的動態特征。
3.模型法。是對給定的時間序列,根據統計理論和方法,建立描述該序列的合適或最優的數學模型,并據此進行預測。
本文在分析過程中利用了數據圖法和模型法,選取了長期趨勢序列圖、散點圖、直方圖直觀地觀察了該時間序列的總趨勢,得出R方較高的指數擬合模型,并通過假設檢驗判斷該指數擬合模型的可行性,據此對2018—2020年的社會消費品零售總額數據值做出可信度較高的預測。
三、時間序列分析擬合模型及應用
(一)數據預處理
研究時間序列的意義在于探索它的發展規律,通過對采集的社會消費品零售總額數據值的直觀及相關分析,觀察其序列值變化規律,利于選擇最優擬合模型模型,達到最佳的預測效果。
1.數據采集。本文中采用2004—2016年張掖市社會消費品零售總額的指標值。
2.直觀分析。在平面直角坐標系中將所研究的時間序列值繪成序列圖,觀察圖形是否存在趨勢性或周期性。倘若沒有明顯的趨勢性或周期性,其波動幅度也不大,就認為序列是平穩的,反之則是非平穩的。同時,還需要觀察序列圖有無存在異常點、離群點和和缺失值。本文研究的統計指標的時間序列有明顯的規律性,是非平穩時間序列,而且不存在異常點、離群點和和缺失值。
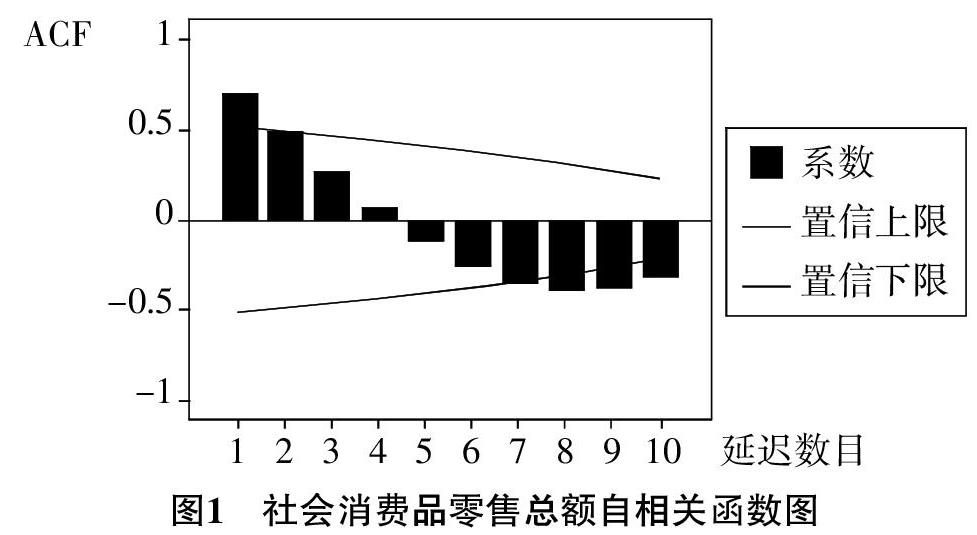
3.相關分析。首先,樣本自相關分析。通過SPSS22.0分析軟件繪制得到樣本自相關系數圖(見圖1)。圖中的橫軸為滯后期(延遲數目),縱軸為樣本自相關系數(ACF),圖中的豎條表示樣本自相關系數值,同時畫出了95%的置信上下限線條。由圖1觀察可知,該時間序列的自相關系數并沒有規律的收斂到零,且自相關函數圖表明自相關系數都在2倍標準差范圍內外做任意波動,因此推斷該序列不是常規的平穩時間序列。
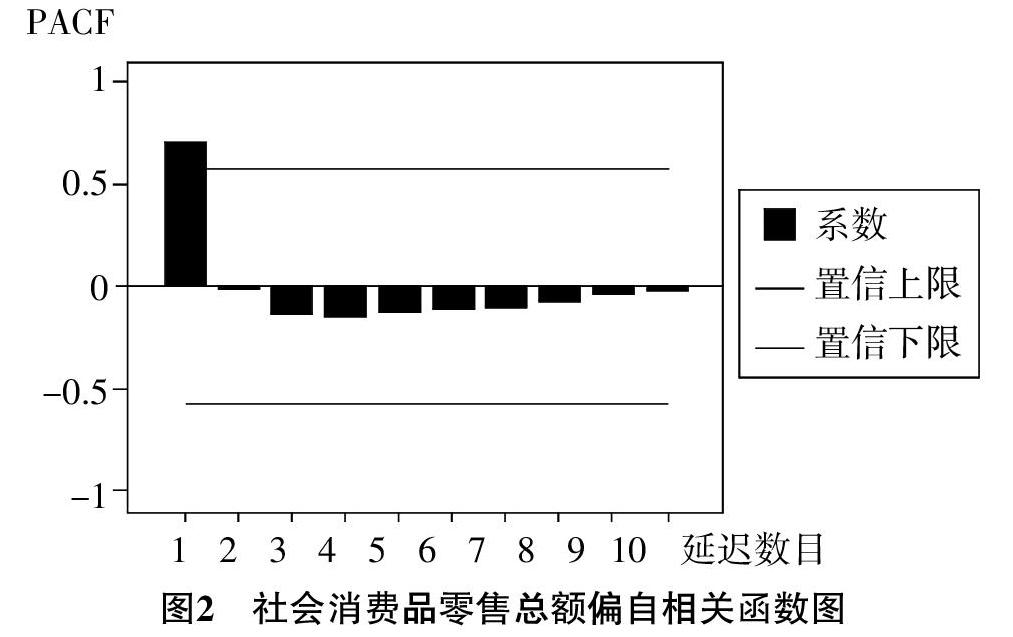
其次,樣本偏相關分析。利用軟件繪制偏相關系數圖(如圖2所示),同樣的,橫軸為滯后期,縱軸為樣本偏相關系數(PACF)。圖中用豎條來表示樣本偏相關系數,并畫出了95%的置信上下限的線條。由圖2可以看出,該時間序列的偏相關系數僅在一階滯后期數值較大,說明該時間序列沒有周期性,且在一階后呈負指數快速收斂至零,是一階截尾的平穩時間序列。
(二)張掖市社會消費品零售總額的趨勢擬合模型的建立
根據上述結論,該統計指標的時間序列自相關系數拖尾,偏相關系數截尾,可得出該時間序列是典型的非平穩時間序列,并通過直觀分析中的序列圖分析判斷,該時間序列以不同的速率增長,呈現出非線性特征,因此選擇曲線擬合模型對社會消費品零售總額進行預測。
1.曲線估計。通過SPSS軟件繪制擬合度較高的復合模型、增長模型、指數模型、Logistic模型。在四種擬合度較高的模型中,指數模型最為貼合,且該時間序列發展趨勢與指數模型走向逐步趨同。因此,本文選擇擬合指數模型進行匹配性檢驗,所有數據值都基本隨著指數模型的趨勢進行排列,確定利用指數模型預測的可行性及可信度較高。
2.指數模型擬合。通過上述曲線估計及檢驗,我們得出該社會消費品零售總額的時間序列動態趨勢與曲線估計中的指數模型走向大概相同,擬合度較高,確定所采集的社會消費品零售總額數據值適合利用指數模型進行預測。
首先,建立模型。通過spss分析軟件得出,該數據值利用指數模型擬合出來的R2=0.997,F=3 347.63,判斷出該指數函數的顯著性水平較高,推斷出該指數模型y=aebx的曲線回歸方程為:
Y=215 229.484e0.16x
其次,假設檢驗。對該曲線回歸方程所做假設檢驗如下:
計算得出Z=1.98。
(3)選定顯著性水平?琢=0.05。
(4)在本文的假設檢驗中,由于實際的Z值大于臨界值Z0.025=1.96,即1.98>1.96,因此有依據拒絕原假設H0:b1=0,接受備擇假設H1≠0,認為該統計指標的總體數值隨著年份的變化有顯著的不同,該曲線估計方程成立。
3. 2016年張掖市社會消費品零售總額及今后發展趨勢的預測。由上述曲線估計方程Y=215 229.484e0.16x可以對2018年及以后的年份進行社會消費品零售總額的數值預測,將年份數值代表的具體樣本數帶入X值,由此計算出Y值。
預測值與真實值相對誤差較小,表明利用該指數模型進行預測的可信度較高,可以選擇進一步預測2018及未來幾年的社會消費品零售總額的數據值:
當2018年,X=15時,Y=1 884 334.13萬元
當2019年,X=16時,Y=2 023 157.15萬元
當2020年,X=17時,Y=2 153 586.22萬元
結語
通過指數模型對社會消費品零售總額進行預測,并抽取實際樣本數值與該指數模型的預測數值進行誤差分析,由計算結果表明,實際數值與該指數模型的預測數值之間誤差較小,擬合度較高。且該指數模型為長期趨勢預測模型,因此,長期預測效果要優于短期預測效果,導致短期預測結果存在一定程度的誤差,并且社會消費品零售總額在實際生活中的增長會受到很多客觀因素的影響,比如收入水平、消費觀念、價格水平等,因此誤差的存在具有一定現實意義。
參考文獻:
[1]? 張鐿瀠.關于我國社會消費品零售總額的統計分析[J].現代商業,2015,(9):127-128.
[2]? 單筱婷.廈門構建區域性消費中心的路徑與政策研究[D].廈門:廈門大學,2014.
[3]? 宋躍征.2009年社會消費品零售總額增長15.5%[N].經濟日報,2009.
[4]? 王璐.武漢市銀行存款影響因素的實證研究[J].當代經濟,2012,(20):90-91.
[5]? 王昭.基于工業數據的報警及預警系統研究[D].北京:北京化工大學,2008.
