基于LightGBM的銀行信用卡違約研究
2019-07-08 02:54:44張國慶昌寧
科技資訊 2019年12期
張國慶 昌寧
摘? 要:隨著全球經濟的變化和我國金融制度的改革,信用卡借貸業務在金融行業中發展的十分迅猛,為銀行帶來了巨大的收益。但是,高收益往往伴隨著高風險,信用卡借貸隱藏著巨大的風險。如何在已有的信用卡數據基礎上,利用科學的方法來鑒別風險,是各個銀行急需解決的問題。該文主要研究LightGBM在銀行信用卡違約問題中的作用,通過實驗,與LR、SVM、隨機森林等幾個常用模型的對比,發現LightGBM模型的準確率最高,說明LightGBM模型效果較好,有一定的實用價值。
關鍵詞:信用卡違約? 金融欺詐? LightGBM
中圖分類號:F832? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?文獻標識碼:A? ? ? ? ? ? ? ? ? ? ? ? ? 文章編號:1672-3791(2019)04(c)-0008-02
1? 信用卡違約研究的背景
隨著經濟全球化和我國金融體制的改革,國內外各大銀行都不斷的擴展自己的業務規模,出現了許多新型的線上交易。以金融機構來講,支付寶、微信支付等侵占了大量的市場;以個體來講,不論是穩定的余額寶、理財通,或者是風險較大的股票等,各種理財方式逐漸被大家所接受。所以說,我國銀行業面臨巨大的困難。
依靠傳統的方式難以改變銀行業目前的狀況,管理者們需要改變銀行的經營策略。銀行卡業務是金融市場中最有前景的產品之一,數據顯示,工商銀行的信用卡到2018年6月末為止,共發卡1.56億張,授信總額為13.98萬億元,環比增長9.09%[1]。信用卡業務給銀行帶來了巨大的利潤。
同時,信用卡也給銀行帶來了巨大的風險。隨著信用卡數量的增加,銀行在獲利的同時,也會存在一些“賴賬”用戶,這些不遵守規定的用戶給管理者帶來了很大的困難。如何利用已存在的借貸數據來辨別用戶是否違約便成了一個關鍵問題,既要獲得最大的利潤,同時又要減小違約所帶來的損失。因此,關于信用卡違約的研究是一個值得研究的問題。
2? 國內外研究現狀
人們現在普遍認為,信用卡最早在19世紀末出現,但是當時僅僅是一種短期的借貸行為,沒有形成正規化的授信額度。1952年,Franklin National Bank第一次公開發行信用卡,于是關于信用卡欺詐的研究便有了開端。
在國外,BrauseR等在1999年通過關聯規則和神經網絡來研究信用卡欺詐問題,得到的結果有較高的辨識度,且誤報率較低[2]。QuahJTS和SriganeshM在2007年通過自組織映射網絡的方法,來研究用戶的行為,并進行了實時欺詐檢測的研究[3]。2016年,FlorentinButaru等比較了邏輯回歸、決策樹和隨機森林三種方法,結果表明,不同的銀行適用于不同的模型,沒有一種模型適合所有的銀行[4]。
在國內,2008年,楊璽等使用支持向量機來研究銀行的欺詐問題,可以有效的檢測高風險的交易行為[5]。2013年,楊屹等使用Adaboost來研究銀行的欺詐問題[6]。2016年,王純杰等使用Kmeans將客戶分為不同的類別,通過多值有序的Logistic回歸模型來研究銀行的欺詐問題[7]。
3? LightGBM介紹
Microsoft在2016年末提出了輕量級梯度提升機,它是基于決策樹算法的梯度提升框架,可用作分類、排序等許多機器學習的任務中[8]。
GBDT[9]梯度提升決策樹,和隨機森林類似,都是多棵決策樹的一種集成。所不同的是,GBDT所生成的樹是有序的,下一棵樹的輸入是上一棵樹所預測的結果,由此不斷迭代。以下舉例說明GBDT的基本思想,假設小明的真實年齡為18歲,第一棵樹得到的結果是10歲,與真實的年齡相差8歲,那么第二棵樹就會在殘差8歲的基礎上去學習,以此類推。每一輪迭代,擬合的誤差都會減小。
LightGBM是更為優化的GBDT算法框架,它采用按葉子生長的策略來構建決策樹,并且會限制其最大深度,不僅能過保證效率,還能預防過擬合。
LightGBM具備一下優點:(1)訓練效率高,低內存使用;(2)支持并行學習,可處理大規模數據;(3)優化了對類別特征的支持。
4? 實驗
該文所使用的數據是來自UCI上的German credit dataset,一共包含1000條數據,其中違約樣本300條,正常樣本700條。樣本特征包含借貸金額、年齡、個人資產、婚姻狀況等信息。該數據集已經做了很好的預處理,包括特征選擇、異常值的篩選和缺失值的填充等。為了防止量綱的不同導致的差異,該文采用min-max方法對數據進行標準化處理。
該文選取LR、SVM、隨機森林三種模型與LightGBM進行對比,四種模型均使用Python實現。該文將數據集隨機劃分為兩部分,其中訓練集占70%,測試集占30%。
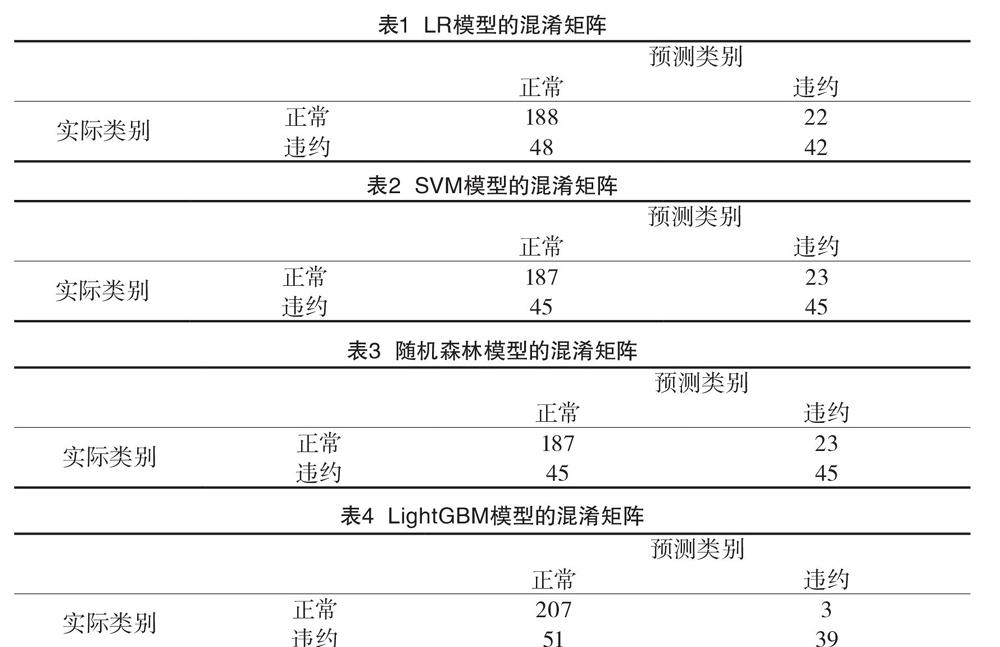
LR模型對測試集預測結果的混淆矩陣如表1所示,此時模型的準確率為76.67%。
SVM模型對測試集預測結果的混淆矩陣如表2所示,此時模型的準確率為77.33%。
SVM和LR所預測的結果在各部分的數值大致相同,準確率也相近。隨機森林模型對測試集預測結果的混淆矩陣如表3所示,此時模型的準確率為77.33%,值得一提的是,使用隨機森林在訓練集上的準確率高達99%,這里可能是由于訓練數據不足,導致了過擬合。
在LightGBM中,學習率設置為0.01,決策樹棵樹設置為20棵,樹的最大深度設置為6,樣本采樣比例為0.75。LightGBM模型對測試集預測結果的混淆矩陣如表4所示,此時模型準確率為82%。
5? 結語
從實驗中可以得出,LightGBM模型較優于其他三個常用的模型,采用LightGBM可以幫助銀行更好的鑒別違約客戶,從而使銀行獲得更多利潤。
參考文獻
[1] http://www.sohu.com/a/253249429_100216228.
[2] Brause R,Langsdorf T,Hepp M.Neural Data Mining for Credit Card Fraud Detection[C]//IEEE International Conference on TOOLS with Artificial Intelligence, 1999:103-106.
[3] Quah J T S, Sriganesh M. Real Time Credit Card Fraud Detection using Computational Intelligence[C]// International Joint Conference on Neural Networks. IEEE,2007:863-868.
[4] Butaru F, Chen Q, Clark B, et al. Risk and Risk Management in the Credit Card Industry[J]. Journal of Banking & Finance,2016(72):218-239.
[5] 楊璽.基于支持向量機的信用卡欺詐檢測研究[D].四川師范大學,2008.
[6] 楊屹.基于稀有類分類的信用卡欺詐識別研究[D].北京工商大學,2013.
[7] 王純杰,李群,董小剛,等.基于K-均值聚類的多值有序Logistic回歸模型在信用卡信用評級中的應用研究[J].吉林師范大學學報:自然科學版,2016,37(3):72-81.
[8] https://github.com/Microsoft/LightGBM.
[9] Ye J, Chow J H, Chen J, et al. Stochastic gradient boosted distributed decision trees[J].2009:2061-2064.
