基于中文病例報告文獻的醫學診療命名實體識別研究*
2019-07-25 02:45:46夏光輝李軍蓮邢寶坤崔勝男
醫學信息學雜志 2019年6期
夏光輝 李軍蓮 邢寶坤 崔勝男
(中國醫學科學院醫學信息研究所 北京 l00020) (中國醫學科學院北京協和醫院 北京 100730)
1 引言
1.1 研究背景與必要性
2011年Watson 在美國最受歡迎的智力問答電視節目中亮相,一舉打敗人類智力競賽的冠軍,使人們認識到醫療人工智能應用前景廣闊,智能醫療逐漸成為計算機和醫學領域共同的研究熱點。基于人工智能的醫療服務系統可以有效緩解優質醫療資源缺乏、分布不均而導致的看病難、醫患關系緊張等問題,而建設智能醫療服務系統需要將海量的醫療數據轉變為計算機可識別和計算的結構化形式,如何使計算機理解醫療大數據文本中的自然語言已經成為智能醫療領域信息處理和數據挖掘研究面臨的關鍵問題。
1.2 命名實體識別相關研究
命名實體識別(Named Entity Recognition,NER)是指從非結構化文本中抽取表達特定含義的實體,從而形成結構化、有明確類別歸屬的實體數據。中文醫學領域的NER研究主要針對生物醫學文獻和電子病歷兩類文本,近年來基于中文電子病歷的實體識別研究已經有比較多的成果,基于條件隨機場(Conditional Random Field,CRF)的實體識別方法成為主流。目前國內研究者基于CRF模型提出多種中文電子病歷實體識別的優化改進方案。許源等[1]針對腦卒中專科的500份入院記錄構建語料庫,采取基于CRF和規則相結合的方法進行醫學實體識別。孫安等[2]以CCKS2017提供的400份電子病歷數據作為研究對象,使用CRF++工具,通過構建字粒度詞語特征提升實體識別模型的性能。于楠等[3]以400份電子病歷構建語料庫,采取CRF++工具進行實體識別,增加引導詞特征和構詞結構特征提升識別的準確性。張祥偉等[4]以100份中文電子病歷構建語料庫,基于CRF模型,構建語言符號、詞性、關鍵詞、詞典、詞聚類等多種特征識別疾病、癥狀、檢查和治療4類實體。楊紅梅等[5]以240份肝細胞癌患者入院記錄和出院小結構建語料庫,采取長短期記憶網絡(Long Short Term Memory,LSTM)與CRF相結合的方法構建命名實體識別模型。此外國內學者基于條件隨機場模型的中文電子病歷實體識別研究還包括電子病歷中時間類實體信息抽取研究[6-7]、充分利用未標注語料的半監督學習方法研究[8]等。綜上研究,條件隨機場不僅可以使用字、詞、詞性等多種上下文特征,還可以靈活引入詞典等外部特征,在命名實體識別任務中的效果已被廣泛認可。但是由于患者隱私問題,電子病歷難以獲取,國內還沒有公開可獲得的電子病歷數據庫,因此研究者只能局限于在較小規模的數據集上進行算法驗證,尚不能有效驗證條件隨機場模型在醫學全學科進行命名實體識別的泛化能力。
1.3 病例報告
病例報告是醫學論文的一種常見體裁,往往通過對1 個、2 個或系列病例的診療經過進行生動記錄和描述,試圖在疾病的表現、機理以及診斷治療等方面提供第一手感性資料[9]。病例報告類論文一般關注于一些首次發現或罕見、治療相關的副作用以及多種癥狀重疊容易誤診的病例,病例報告中的病例資料是經過遴選、編輯、審校后的高質量病歷數據。針對這些公開的優質病例資料自動識別與提取相關診療信息,不僅能為公眾提供精準的健康信息服務,還能為臨床決策支持、輔助問診等應用場景提供數據支持。本文以公開發表的病例報告文獻中的臨床資料構建醫療實體識別語料庫,使用條件隨機場模型,融合多種特征,實現疾病、癥狀、檢查、治療等醫療實體的識別。
2 材料與方法
2.1 語料數據來源
本研究使用的病例報告原始語料均來源于中華醫學會系列期刊2015年發表的300篇相關文獻,為盡量保證病例資料覆蓋醫學全領域,分別從11種期刊中隨機選擇文獻,獲取病例報告文獻的標題和臨床資料兩部分內容,具體情況,見表1。
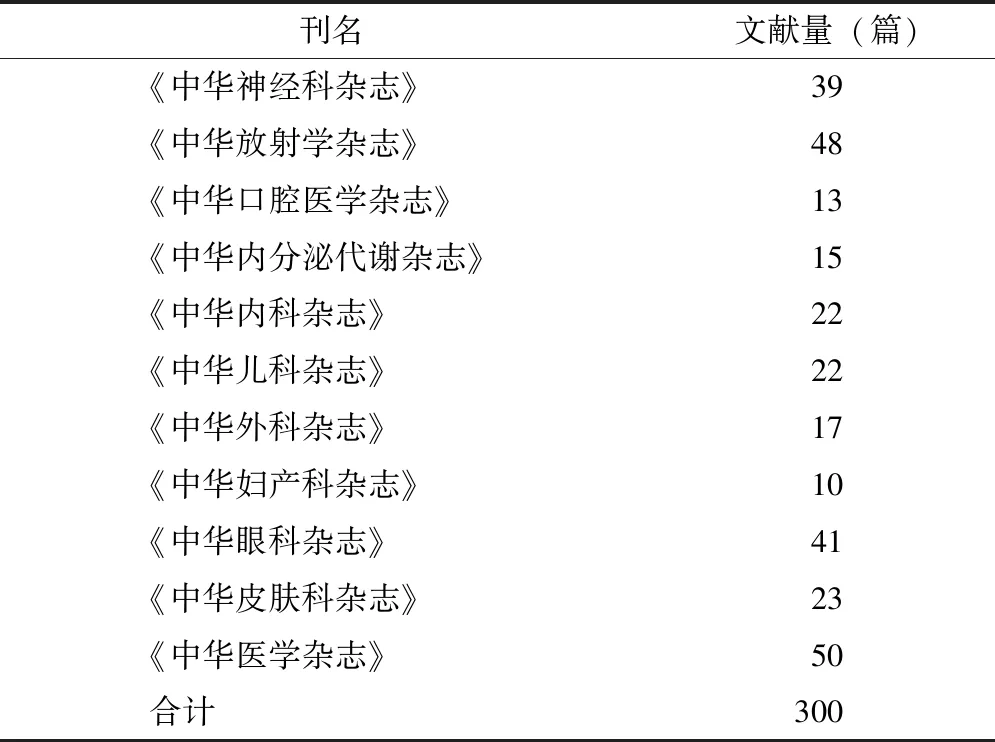
表1 病例報告語料數據分布情況
2.2 命名實體分類設計
I2B2 2010語料的實體類型分為醫療問題(medical problem)、檢查(test)和治療(treatment)3類[10];楊錦鋒等構建的電子病歷語料庫中實體類型分為疾病、疾病診斷分類、癥狀、檢查、治療5類[11]。本研究借鑒以上語料庫構建經驗,將病例報告中的實體分為疾病、癥狀、檢查和治療4種類型,參考一體化醫學語言系統(Unified Medical Language System,UMLS)的語義類型界定每一類實體涵蓋的范圍,但不局限于UMLS中的概念。疾病(diseases)是導致患者處于非健康狀態的原因或者醫生對患者做出的診斷統稱為疾病,如高血壓、股骨骨折、畸形等。癥狀(symptoms)是指患者主觀感受到的不適應或痛苦的異常感覺或某些客觀的病態改變,同時還包括醫師或其他人客觀檢查到的改變,即體征(sign),如肢體無力、耳鳴、惡心、低血壓等[12]。檢查(test)指的是為證實患者是否具有某種疾病或者出現某種癥狀而進行體格、實驗室、器械檢查等過程以及相應的檢查設備、項目,如尿常規、心電圖、心肺聽診等。治療(treatment)指的是為解決疾病或者緩解癥狀而施加給患者的治療程序、干預措施、給予藥品、手術操作,如輸血、胰島素、肺切除術等。本研究所定義的命名實體遵循3條基本原則:實體是意義完整的最小片段;實體間不重疊、不嵌套、不含有除頓號以外的標點符號;“頓號”、“伴”、“及”、“并”等表達并列關系的字符,基于上下文語境理解不可或缺時可作為實體的組成部分。
2.3 實體語料標注
考慮到病例報告涉及的內容專業性較強,語料標注采取規范制定團隊預先形成語料標注規范指導標注人員人工標注,遇到疑惑時標注人員可將實體標注狀態修改為存疑,待與規范制定團隊討論達成一致后,修改實體標注狀態并完善標注規范。標注團隊主要包括1名醫院病案科研究人員、1名醫院醫護人員,他們在工作中參與電子病歷的書寫和核查,具備足夠的醫療知識,積累豐富的臨床經驗;規范制定團隊包括兩名自然語言處理領域相關研究人員。整個語料標注過程分為4輪,其中前兩輪是預標注,第3輪是正式標注,第4輪是標注審核。預標注旨在培訓標注人員,熟悉標注規范的同時理解語料標注的目的,逐步完善標注規范,解決標注人員的疑問。經過兩輪預標注,兩名標注者的一致性達到90%,開始正式標注[13]。預標注共包含50份病例報告,每輪的25份病例報告由兩名標注者分別獨立標注,簡稱為A和B。病例報告語料標注流程,見圖1。兩名標注者通過標注平臺,參照標注規范,單獨完成25份病例報告的標注。通過平臺的比較功能,標注人員與規范制定人員共同討論,針對不一致的標注實體達成一致后可在平臺上進行修改、確認和刪除,完善標注規范并補充標注樣例,指導后續標注工作。病例報告標注平臺語料審核示例,見圖2。兩名標注人員標注結果不一致,標注平臺將以不同顏色的文字表示實體類別,同時通過添加底紋的方式突出顯示不一致的實體文字,以便于討論修改形成統一共識的標注規范和語料庫。第3輪正式標注共包含300份病例報告文本,其中包括預標注的50份病例報告。正式標注由兩名標注者共同完成。為確保人工標注的進度和質量,規范制定者可在平臺上實時查看標注進度并對已完成的標注文本進行審核。
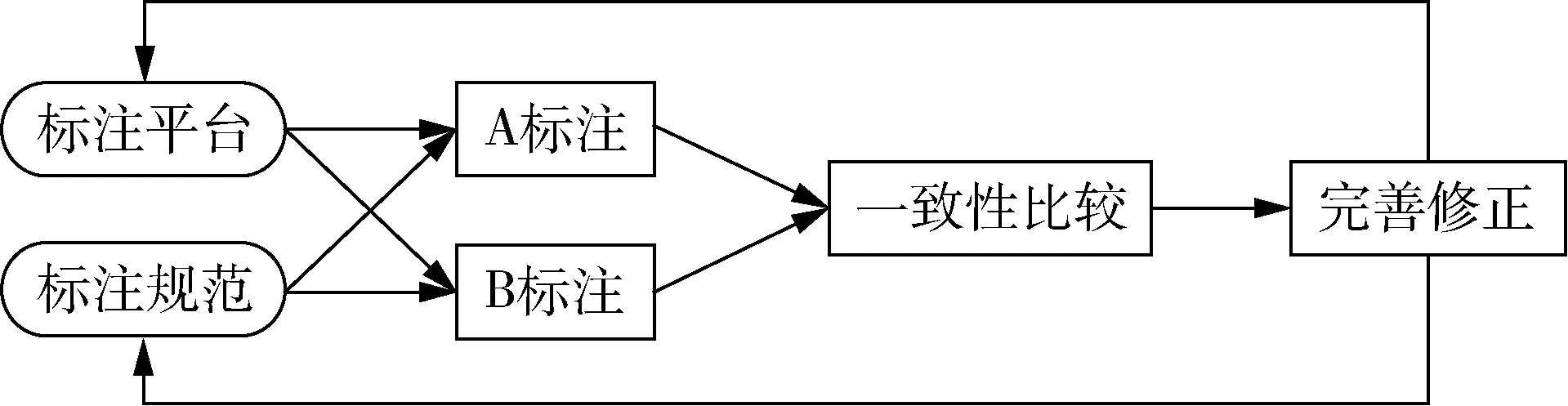
圖1 病例報告語料標注流程

圖2 病例報告標注平臺語料審核
2.4 特征提取方案
實體特征是命名實體識別準確與否的決定性因素。在命名實體識別任務中常構建的實體特征包括字符、詞性特征等,特征之間可以構成不同的組合。實體識別過程中關鍵在于針對相應任務模型選取合適、準確度高的特征來表示文本中隱含、嵌套的語言邏輯。醫學病例報告文本一般采用敘述形式,具有語言簡潔以及非標準的描述特性,因此沒有高層次的句法特征。通過分析病例報告文本結構,本文從常用的特征集合中選取幾種合適的來標識病例報告文本。(1)字符特征。是最基本、最直接地表達文本序列中元素的一類特征,本文所指的字符包括漢字、標點符號、外文字母、數字和日期等。(2)詞邊界特征。用于反映邊界特征字符的位置信息,幫助確定命名實體的邊界。本文實驗中采用BIEO 編碼模式來表示輸入觀測序列元素的詞邊界特征。其中 B表示實體名稱的開始,即左邊界;I 表示實體名稱的內部,即實體的非邊界部分;E 表示實體的結束,即右邊界;O 表示非實體。(3)上下文特征。在本文中指的是窗口長度內觀測值之間或特征之間的相互依賴關系,既可以表示實體內部的依賴關系,也可以表示實體內部與外部的相互關系。上下文窗口由當前詞以及前后若干個詞組成,上下文窗口長度依據所識別實體的長度進行設定[14]。在本文試驗中窗口大小設置為9。(4)詞性特征。在自然語言處理任務中詞性標記可以深度挖掘詞語組合形成的詞法信息,表達句子中存在的固有結構,提升特征集的區分度。詞性特征由ANSJ中文分詞工具生成。(5)詞典特征。本文基于CMeSH,依據主題詞的樹狀結構號構造疾病、癥狀、檢查、治療等實體詞典,基于實體詞典采取字符串匹配的方式構建語料詞典特征。(6)融合特征。當單一的特征不足以準確表達輸入觀測序列中元素之間的相互依賴關系時,可通過對不同單一特征的相應組合表示觀測元素間更為深層次的語義結構。通過特征模板提出一種融合特征,由字符、詞性和詞典特征隨機融合而成。
2.5 條件隨機場模型
2001年由John Lafferty等人提出基于統計的序列標注識別模型[15]。是連續優化的最大熵模型,具有較強的特征融合能力,可以在模型中靈活添加特征來表示元素之間的關系。克服觀察值之間的獨立假設,采用全局歸一化的方法,有效避免數據稀疏性問題,特征權值全局最優,避免標注偏倚問題,在CCKS 2017中文電子病歷命名實體識別評測會議中被廣泛使用[16-17]。在條件隨機場模型中,若令x={x1,x2,…,xn}為觀測序列,y={y1,y2,…,yn}為與之相應的標記序列,則條件概率為:
公式(1)
其中Zx是所有狀態序列的標準化因子,fj是特征向量函數,λj是特征權重。當訓練狀態序列被完全明確地標記后可為該模型找到最優的λ值。在此基礎上使用Viterbi算法得到最佳狀態序列。本文使用斯坦福大學開源的命名實體類識別工具Stanford NER,其基于CRF模型實現。
3 試驗結果與分析
3.1 評測結果
本文將300份病例報告語料中的200份作為訓練集,100份作為測試集。評價指標采用機器學習領域常用的準確率P(Precision)、召回率R(Recall)和F值(F-measure),具體計算公式如下:
公式(2)
公式(3)
公式(4)
為驗證不同特征對識別效果的影響,首先選擇字符特征(word),然后逐漸增加詞性特征(pos)、詞典特征(dic)。不同特征的實驗情況,見表2。可以看出當添加詞典特征時,相比于只用到字符特征,準確率略有上升,最終達到79.40%,F值也有提升,最終達到76.67%。而添加詞性特征時,相比于只用到字符特征,召回率略有上升,最終達到74.30%,但準確率下降較多,最終F值為76.44%。實驗結果表明當融合字符、詞典特征時實體識別的準確率能有效提高。而因病例報告中臨床資料文本的語言特性,如行文中句子語法成分不完整、動詞缺失,導致詞性特征用于病例報告臨床醫學診療實體的識別效果不明顯。
3.2 識別錯誤的實體
(1)在語料標注規范中基于臨床含義和上下文語境的考慮,對語料中的頓號,及、和等表示并列關系的符號整體標注為診療實體,但基于語義理解的實體識別還有待進一步提高。如“計算力、記憶力差”識別為“記憶力差”,“腦脊液常規和生化”識別為“腦脊液常規”、“生化”兩個檢查實體,“雙腎上腺CT平掃及強化” 識別為“雙腎上腺CT平掃”、“強化”兩個檢查實體。(2)語料數據稀疏導致實體未識別。如“神經功能”、“瞌睡”等實體未識別。(3)實體邊界識別錯誤。如“雙耳中低頻感音性耳聾”識別為“感音性耳聾”,“闌尾炎術后”識別為“闌尾炎”。(4)實體類別識別錯誤。如誤將治療實體“膀胱肌瘤、大網膜肌瘤、腸系膜肌瘤、闌尾系膜肌瘤切除術”識別為疾病實體“膀胱肌瘤”、“大網膜肌瘤”、“腸系膜肌瘤”和治療實體“闌尾系膜肌瘤切除術”。從以上分析得出,基于臨床真實含義結合上下文語境進行命名實體識別、語料構建時標注人員也基于臨床上下文語境標注診療實體,但本文構建的模型在進行基于語義理解的命名實體識別時精準度還有待提高。
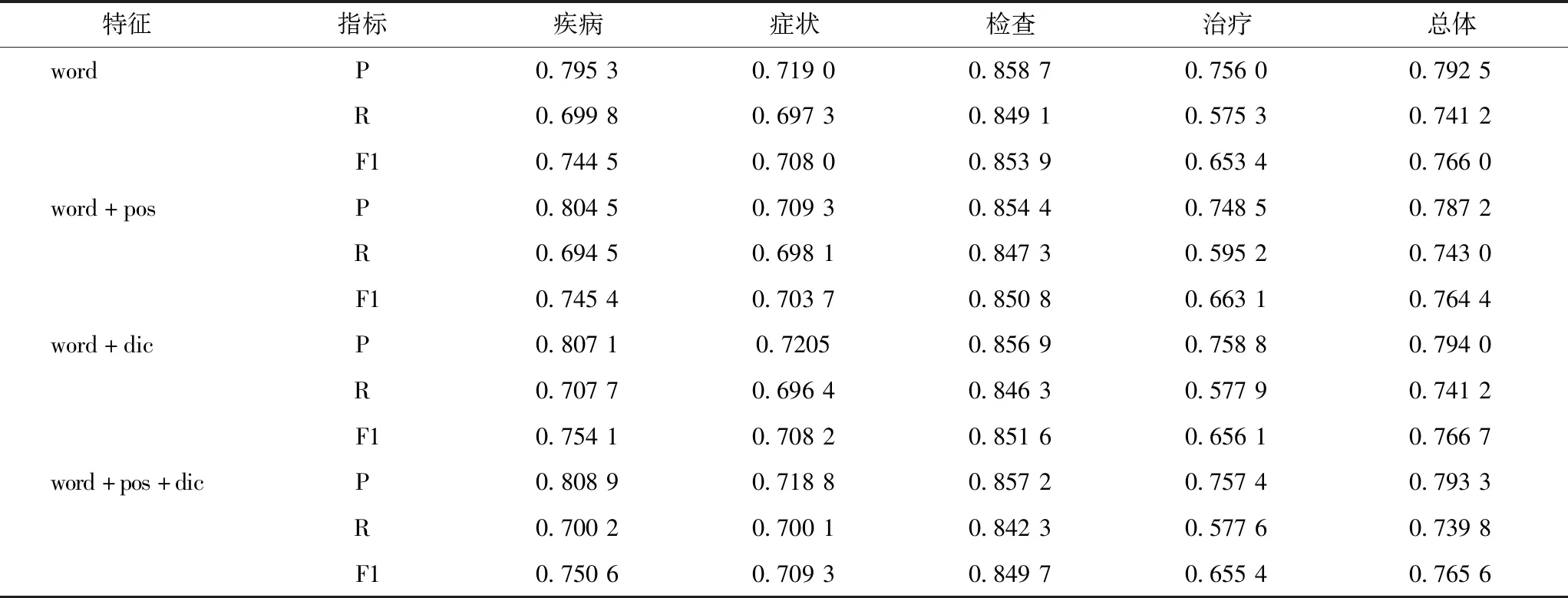
表2 采取不同特征組合的實體識別評測結果
4 結語
本文基于病例報告文獻構建語料集,基于條件隨機場模型提出一種多特征融合的中文病例報告診療命名實體識別方法。采用遞增式的特征學習策略,測試不同特征組合用于中文病例報告命名實體識別的效果,最終融合字符、詞邊界、上下文、詞性和詞典等特征,構建的模型能準確識別出中文病例報告中的大部分診療實體。但由于病例報告中的病例資料高度凝練,其行文中并列結構、縮略語和上下文語義關聯較多,該模型在此方面的識別能力還有待提高,后續可在以下幾方面進一步優化:(1)將機器學習方法與基于語言規則的模式匹配方法相結合,提升針對特定語言結構的實體識別能力。(2)借助于本研究構建的病例報告標注規范和標注平臺,構建更大規模的高質量醫學診療語料庫,提高機器學習模型的識別效果。(3)進一步優化機器學習算法,豐富中文語料特征集,結合醫生臨床診療過程的應用場景,研究基于語義理解的命名實體識別,推動實體識別技術在臨床輔助診療決策中的應用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
南方人物周刊(2017年32期)2017-10-28 22:48:36
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
南風窗(2016年26期)2016-12-24 21:48:09
光學精密工程(2016年6期)2016-11-07 09:07:19
南風窗(2015年22期)2015-09-10 07:22:44
