基金項目論文中的科研數據引用行為研究*
2019-07-29 06:05:12劉亞男劉江榮
圖書館論壇 2019年7期
關鍵詞:規范
劉亞男,劉江榮,肖 明,于 佳
0 引言
隨著數據密集型研究范式興起,科研數據的透明性、知識產權保護及數據的再利用價值等問題引起重視,科研數據引用行為也日益受到關注。規范的數據引用指導和引用行為對提升科研成果的可溯源性和透明性、保護數據利益相關者的知識產權以及完善科研數據的貢獻識別及獎勵機制等都具有重要意義。國外圍繞科研數據的引用實踐開展很多調查研究,對研究科研項目成果的數據引用情況、科研人員的數據引用行為模式等提供了重要依據。目前我國關于科研數據引用行為的實證研究還比較少,暴露了我國數據引用研究和實踐方面的諸多不足。本文通過對國家自然科學基金、社會科學基金資助的學術成果中科研數據引用的實踐狀況進行實證分析,嘗試了解我國科研人員數據引用行為模式,為相應規范和策略的制定提供參考。
1 研究現狀
科研數據是指對科研過程和結果具有支持作用的任何格式或以任何媒介存在的數據。包括科研人員在研究過程中通過觀察、實驗、模擬、調查、分析所創建的數據,以及從其他機構收集的二手數據,可以是文本、數值、圖像、音頻、視頻、模型、計算機代碼或特定工具的輸出結果等多種形式。科研數據引用是類似于研究人員通常為期刊文獻、報告或會議文獻中提供文獻參考的方式來提供數據參考的做法,通過一定的標識技術和參考機制,對所使用的數據資源進行描述,標識數據的來源,從而加強對科研數據的知識產權保護,也便于對數據引用情況進行統計和分析。國外對科研數據引用行為的研究主要集中在針對特定數據集和針對期刊論文中的數據引用行為的研究。
針對特定數據集的引用行為研究方面,Parsons 等[1]對美國國家冰雪數據中心(National Snow and Ice Data Center,NSIDC)的使用中分辨率成像光譜儀資料的論文進行分析,研究表明該中心并未提供引用相關的指導說明,并且只有少量作者在文中明確注明引用了該中心的數據。Mooney[2]對大學間政治社會研究聯盟(Interuniversity Consortium for Political and Social Research,ICPSR)數據中心的數據集引用情況進行分析,結果表明部分作者引用數據時不會注明數據來源。Henderson 等[3]對使用CRAWDAD倉儲庫中數據集的1281 篇論文中的數據引用行為進行分析,發現通常情況下論文作者能夠以一定合理的方式引用數據,僅11.5%的論文沒有說明數據來源,但普遍存在引用的是數據相關的論文而非數據本身、無法提供獲取數據的唯一標識符DOI(Digital Object Identifier)等問題。Read 等[4](2015)分析了NIH 資助的發表于2011年的論文,排除掉存儲在PubMed 倉儲庫以及在文章中有明確引用過該數據倉儲的論文,通過將其他論文作為隨機樣本來評估隱形數據集的情況,結果顯示大概12%的文章提到了存儲數據集在倉儲庫中,其余88%的為隱形數據。
針對期刊論文中的數據引用行為研究,Enriquez 等[5]選擇環境科學領域的6 種期刊,對期刊中2000-2010年的500 篇文章的數據引用行為進行研究,結果表明221 篇文章有數據再利用行為,其中53%注明了引用數據的相關論文,47%提及了引用數據的存儲機構,只有13%的文章標注了DOI。Sarah C.Williams[6]發現農作物學科的科研人員在研究中使用的科研數據來源非常廣泛,然而數據引用行為非常不規范。Stuart等[7]對140 種社會學期刊的科研數據相關政策進行調研,并選擇其中5 種期刊,按照抽樣的方式篩選這些期刊上近兩年來發表的論文,確定作者是否真的引用和共享他們的數據以及與其相關的影響因素。結果發現140 種期刊中只有少數有明確的科研數據引用政策,并且為具有較高影響因素和數據引用政策的期刊撰寫文章的作者更可能引用數據并使數據真正可訪問。Womack[8]使用分層隨機抽樣的方法從2014年生物學、化學、數學和物理學影響因子排名前10 名的期刊中選取文章,對其數據引用和數據共享情況進行分析,結果表明即使是在高影響力期刊中,數據引用行為仍然非常不規范,使用DOI 和直接鏈接到原始數據的行為非常少。另外所有學科的文章中都很少提供大規模原始數據的鏈接來共享數據,但總體來說數學和生物學在數據共享方面比化學和物理學要好一些。Mengnan Zhao 等[9]通過對發表在PLoS One 的600 篇論文進行編碼和數據集引用情況進行分析,結果發現不同學科之間對數據集的采集和引用有很大的差異,只有有限的文章通過DOI的方式來引用數據集,另外只有少于30%的文章中有數據集重用的現象。
目前我國對科研數據引用行為的研究較少,已有研究集中在對有關科學數據引用的標準規范方面。黃如花等[10]在調研了國外科研數據引用規范的基礎上,提出我國應該將科研數據引用納入科研評價體系,完善科學數據引用規范。彭潔等[11]通過問卷調查的方式,調查科技期刊和科研人員對科學數據引用的態度、平臺、動機、標注和描述,對各個因素進行對比,提出針對期刊論文、科研數據庫和科研人員三種模式的科學數據引用框架。王雪等[12]認為應基于引用行為建立針對科學數據的評估機制,有利于科研人員認識到科學數據再利用的價值,并正視數據引用的重要性,從而規范化數據引用。
2 研究設計
2.1 研究方法
采用抽樣調查和內容分析研究方法,選取自然科學領域和人文社科領域20 種期刊作為抽樣對象,按照等距抽樣原則選取2015-2016年的基金項目論文。參考已有研究成果構建科研數據引用完整性標準,并根據構建的標準對論文進行內容分析,從引用元數據、引用位置和引用完整性三個方面對論文中作者的數據引用行為進行分析。
2.2 數據樣本選擇及處理
2.2.1 樣本選擇
自然科學基金和社會科學基金項目是國家級科研基金,其資助項目的選題、成果反映了我國自然科學、社會科學各學科研究的國家水平。本文選擇期刊論文中的基金項目論文成果作為研究對象,對我國各學科領域的研究人員科研數據引用行為模式和特點進行分析。選擇中國知網全文數據庫,利用核心期刊導航功能,按照期刊復合影響因子進行高低排序,在社會科學領域和自然科學領域各選擇10 種期刊,共20 種核心期刊。樣本文獻來源期刊信息見表1、表2。
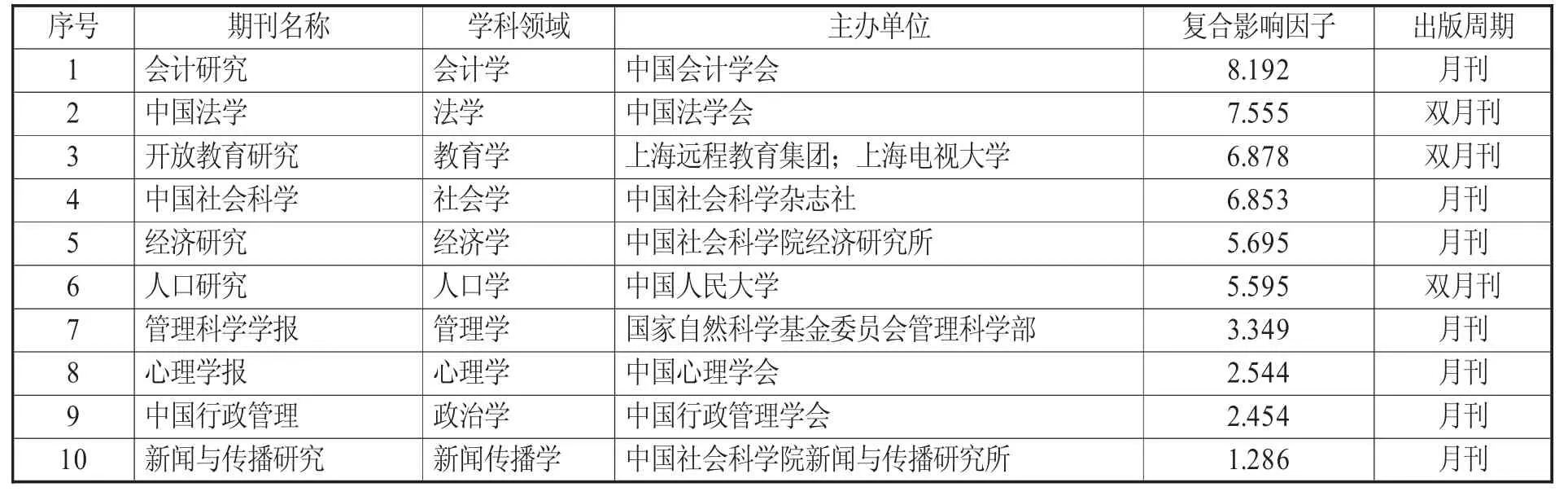
表1 樣本文獻來源期刊信息(社會科學領域)
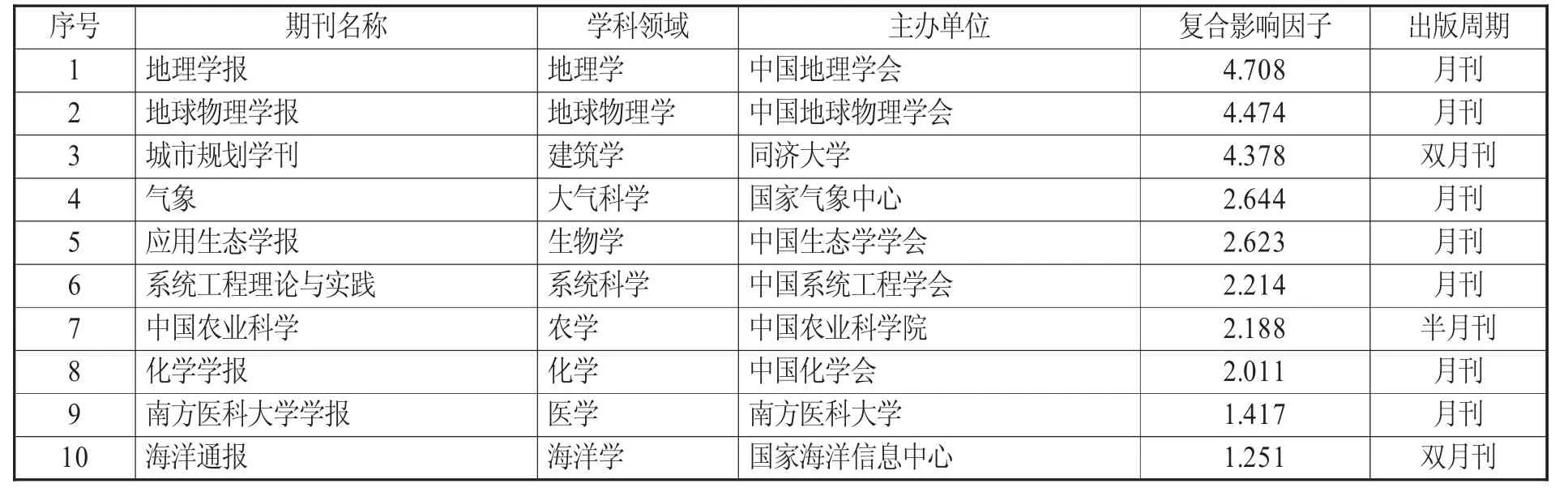
表2 樣本文獻來源期刊信息(自然科學領域)
2.2.2 文獻選擇
在20 種期刊中,采用等距抽樣方法,選擇2015-2016年兩年中上半年第1 期和下半年第1期(即雙月刊每年的1、4 期,單月刊每年的1、7期,半月刊每年的第1、13 期)刊登的論文為初步篩選對象。然后利用數據庫中的“基金來源”字段篩選論文中獲得自然科學基金項目和社會科學基金項目論文,共計815 篇文章為研究樣本文獻。具體數量分布見表3、表4。
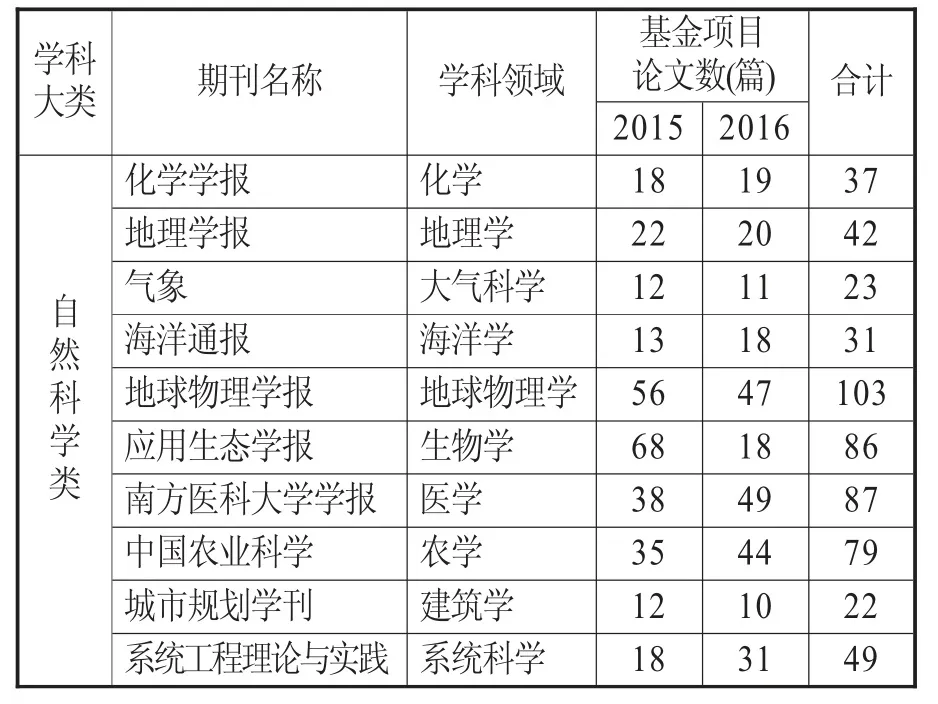
表3 樣本文獻分布情況(自然科學類)
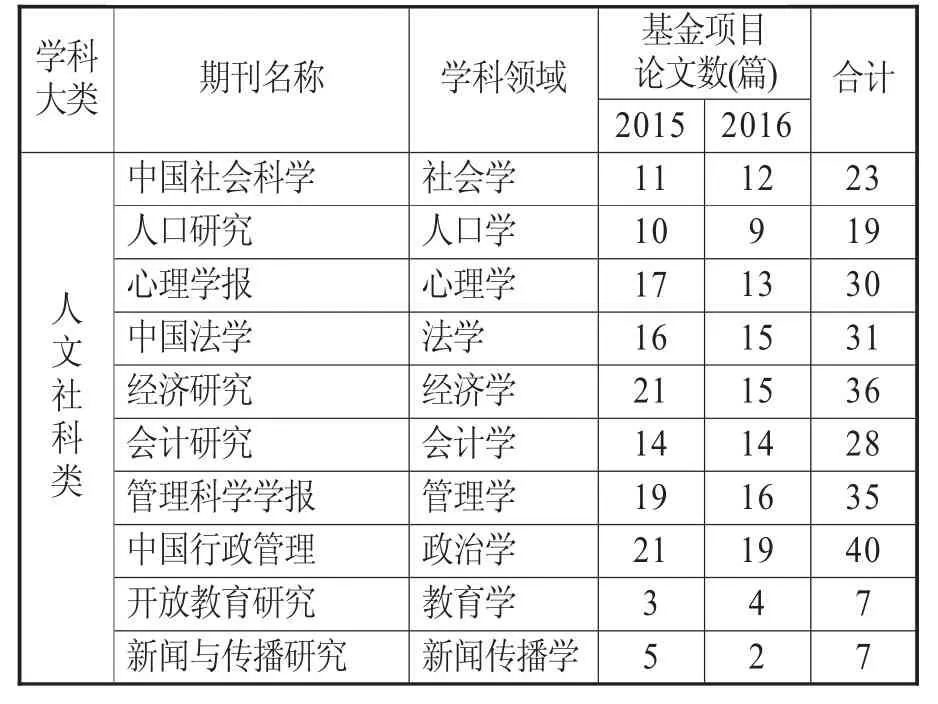
表4 樣本文獻分布情況(人文社科類)
2.2.3 樣本處理
為分析基金項目論文中科研數據的引用規范程度,需分析論文中的具體引用行為。由于目前還沒有較大規模的標注數據對內容進行自動識別,筆者主要使用人工方式對數據引用行為和規范程度進行內容分析,判斷和歸類相關內容。為了保證分析結果的有效性、一致性,減少標引人員的判斷失誤,在正式標引前對論文的篩選步驟、判斷標準、分析角度等進行反復討論和完善,補充了很多標引時可能遇到的問題的解決辦法,保證了統計分析結果的一致性和準確性。篩選步驟如下:
(1)確認文章是否涉及科研數據。通過閱讀樣本文獻的摘要內容進行初步判斷,進而分析文章的整體框架結構,分析文章是否會涉及到科研數據。
(2)確認文章中的科研數據是屬于作者創建的數據還是引用的數據。如果文章中使用了數據,則需要進一步判斷數據的來源,對屬于作者自己創建、搜集的數據不在本文的分析范圍。如果可以判斷該篇文章的數據屬于引用數據,則選為本文分析的樣本。
(3)深入分析數據引用行為的相關內容。論文中與引用數據相關的時間變量包括數據覆蓋時間區間、數據發布時間、數據獲取時間等不同表述,本文只標引數據的發布時間和獲取時間。此外,在數據個數計算方面,有些表格或圖表會出現同時引用多個數據的情況,本文在標注時使用作者注明的數據來源數量作為引用數據個數,并根據引用的元數據情況進行引用完整性評分。
通過對所獲取的樣本文獻中的數據引用行為進行標注,統計每篇文章的引用數據的數量及引用的完整性情況,并對獲得的數據分類統計,可獲取各領域基金項目論文中數據引用的情況,見表5。在815 篇基金項目論文中,有數據引用行為的論文有250 篇,占30.7%,總數據602 個,平均每篇論文數據次數為2.4 次。
2.3 構建數據引用完整性衡量標準
為了解我國基金項目論文中科研數據引用行為的完整性,參照Hailey Mooney 等[13]文中采用的數據引用完整性指標(Data Citation Adequacy Index,DCAI)構建方法,建立數據引用完整性衡量標準。主要處理方法是:通過對多個引用規范格式進行解構,將列出的數據引用的元素、引用的格式、引用的顆粒度情況等進行對比,找出通用的核心要素,結合核心要素在文中出現的位置,構建“數據引用完整性衡量標準”。最終確定的衡量標準包括兩個維度:引用單元和數據引用在文中出現的位置。在引用單元方面,通過對各國際組織、數據中心和期刊機構的推薦引用格式進行對比,創建者(Author/Creator)、發布年份(Publication Year)、 標 題 (Title)、 發 布 機 構(Publisher)和唯一標識符(Identifier)作為強制要求的引用要素。尤其隨著近年DataCite 等機構對數據唯一標識符的深入研究和廣泛推廣,為數據注冊DOI 成為大部分數據中心和期刊的共同趨勢和強烈建議。所以本文在構建衡量矩陣時對Hailey Mooney 的賦值進行細微調整,將提供數據唯一標識符的權值修改為2,這從某種程度上顯示數據引用技術機制的進步。由于其他引用要素,如資源類型(Resource type)、版本(Version)在特定的推薦格式中出現頻率較高,所以分別賦予一定權重,從而區分完整性較高的引用行為。在引用出現位置方面,分別對未在文中出現引用、在正文中出現、在備注或致謝中出現、在參考文獻列表中出現的四種情況分別賦予一定權值。筆者根據研究認為,在參考文獻部分中引用數據的規范程度最高,相應的權值也是最高。最后構建“科研數據引用規范性衡量標準”,如表6所示。
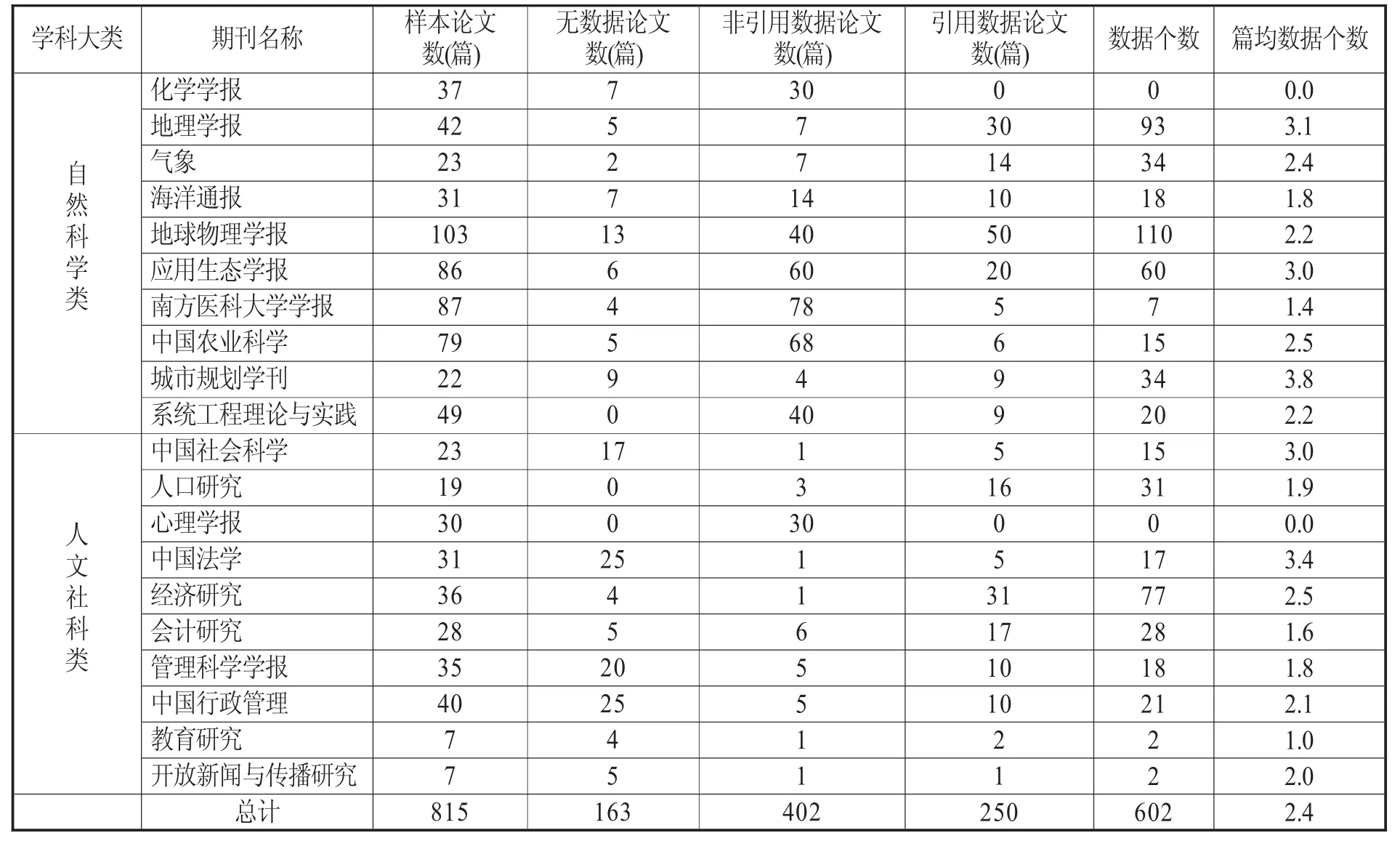
表5 樣本總體情況
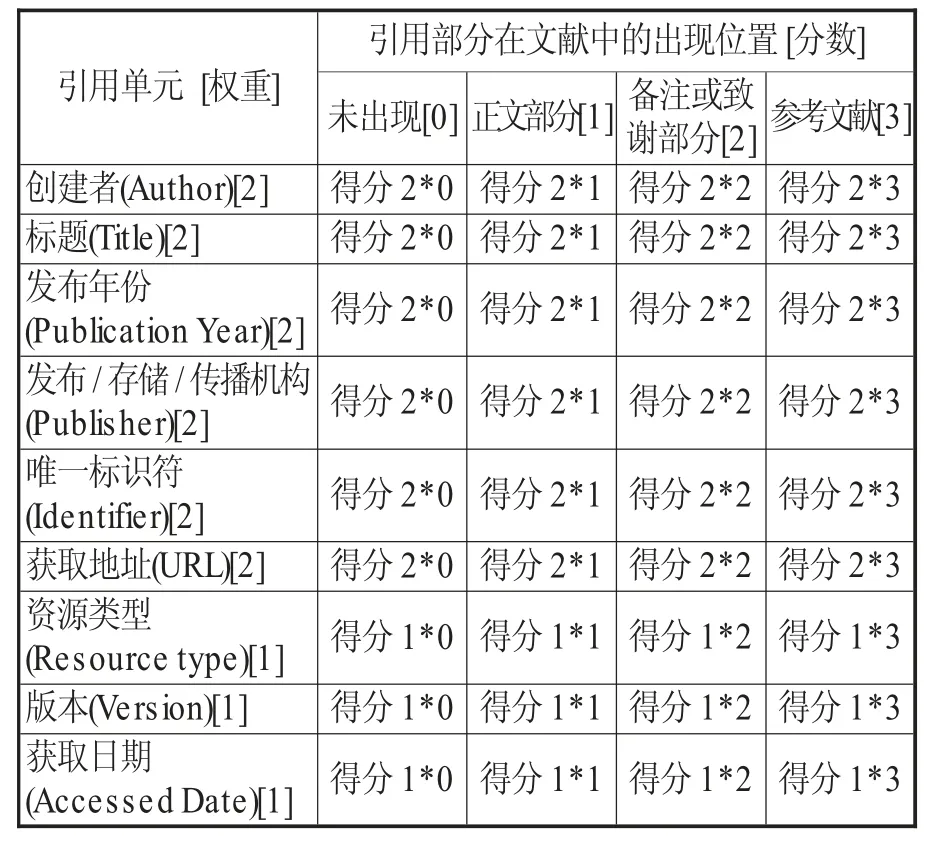
表6 數據引用規范性衡量標準
3 我國科研數據引用行為模式分析
類似于文獻引用,數據引用包括作者、數據標題、出版機構、出版時間、訪問地址等數據,根據這些數據的完整程度,本文從引用元數據、引用位置和引用完整性三方面對我國基金項目論文中的科研數據引用行為進行分析,了解當前我國科研數據的引用規范情況。
3.1 引用元數據分析
引用科研數據時推薦引用的五個核心要素分別是創建者、標題、發布時間、發布機構和獲取地址。通過對樣本文獻中的602 個引用數據進行分析得知,引用數據時注明數據的發布機構的做法最常見,自然科學領域基金論文中有322 條數據、人文社科領域有196 條數據說明數據發布機構。其次是在引用的時候說明數據的發布時間(自然科學領域=161,人文社科領域=103)及數據集名稱(自然科學領域=254,人文社科領域=40),而對數據的創建者、獲取數據的地址或DOI、數據資源類型和數據版本等信息則很少提供規范性的說明,如圖1所示。這說明研究人員在使用外部數據時有一定的引用意識,然而由于缺乏規范的引用要求和指導,只能模糊和籠統地引用數據的發布機構或網站名稱,如“數據來源于中華人民共和國國家統計局網站”或“感謝中國地震局地球物理研究所‘國家數字測震臺網數據備份中心’為本研究提供地震波形數據”。而相對嚴謹的作者會對數據集的具體名稱、數據發布的時間等進一步說明,如“COSMIC 掩星探測資料來自于 2014年COSMIC 數據存檔與分析中心CDAAC 發布的后處理數據文檔IonProf”。
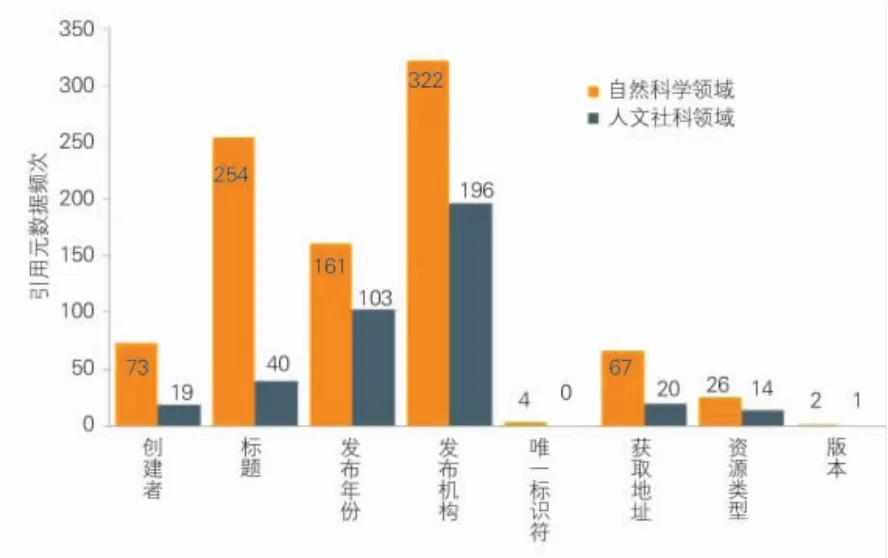
圖1 引用元數據情況分析
在調研的樣本文獻中,引用“數據創建者”主要有三種情況:一是在致謝中說明感謝某位研究人員提供數據;二是說明數據來源是來自論文、專著或報告等出版物,并通過參考文獻引用該篇論文,或在正文中以“作者(年份)”的格式對數據來源進行標明;三是根據數據來源倉儲庫的要求按照格式引用數據,這種情況雖然最規范,但出現頻次最少。說明引用格式不規范的情況較嚴重,不能很好地體現數據創建者的貢獻。
對“數據獲取地址”這個要素,在此次調研的樣本文獻中,大多數提供的都是數據來源的網站信息,而不能提供具體的數據獲取地址,如“高溫脅迫數據來源于中國氣象科學數據共享服務網(http://cdc.cma.gov.cn/home.do)的中國地面氣候標準值日值數據集”,這樣的引用雖然提供了數據的引用地址,但是卻無法精準到數據的描述網頁,而且由于網絡地址不能保證永久的有效性,通過網絡地址的引用方式也容易失去引用追溯的作用。而“數據唯一標識符DOI”在一定程度上可以解決這種困境,但是從調研的結果來看,真正通過DOI 對數據進行標注的只有4 條數據,可見,目前我國基于DOI 的數據引用實踐還非常欠缺,這是與我國目前的引用意識、數據版權意識薄弱、DOI 注冊系統普及程度不高、數據規范引用指導不夠等多方面因素息息相關。
對“數據資源類型”及“數據版本”等要素的引用實踐相對而言更加匱乏。其中,自然科學領域的論文在數據來源的說明中會添加對數據資源類型及版本的說明,例如“本研究所用的長時間序列遙感數據——GIMMSNDVI 3g 數據集,是由美國國家航天航空局推出的最新版的全球植被指數變化數據,該數據集格式為ENVI 標準格式,投影為Albers,其時間分辨率為15d,空間分辨率為8km”,也有部分論文在引用時會注明網址和版本數據等具體信息,如“本文實際使用的重力異常數據來源于http://topex.ucsd.edu網站提供的最新22.1 版本數據”。而在人文社科領域對所使用數據的具體資源情況表述相對要模糊一些,如“本文運用的財政數據來自統計局2006年發布的《全國地市縣財政統計資料》,這些財政統計資料包含了32 個省級行政區、332個地級行政區和2859 個縣級行政區的財政一般預算和基金預算資料,詳細到‘類級’科目。”這種引用的顆粒度顯然是非常粗糙的,對閱讀文章的人而言,并不能明確地知道引用數據的具體情況,也無法實現研究成果的可溯源性和透明性。
在調研的樣本文獻中,以非常規范和完整的方式引用科研數據的情況不多,但是確實也有一些典型案例非常有指導意義。有些數據來源于國家統計局、國家稅務局、國家信息中心等機構部門發布的統計資料或年鑒報告等,對這些資料的引用很多作者會選擇通過參考文獻的形式引用。此外,規范引用的數據與數據來源倉儲庫有直接關系,有些倉儲庫對引用該倉儲庫的數據有比較明確的說明和要求,這樣就在一定程度上使得研究人員在自己的研究成果中按照要求規范地引用科研數據。
3.2 引用位置分析
為了解樣本文獻中的數據引用行為,進一步對引用的位置進行分析。由圖2可知,數據的引用位置主要集中在正文,自然科學領域和人文社科領域在正文處引用數據的頻次分別為239 次(61.1%)和140 次(66.4%)。對基于科研數據開展研究的的論文,通常會在開篇用一個章節介紹數據來源,所以對數據的引用說明會出現在正文中。另外,系統工程、管理工程類論文,通常會在驗證模型的實證部分引用數據集。
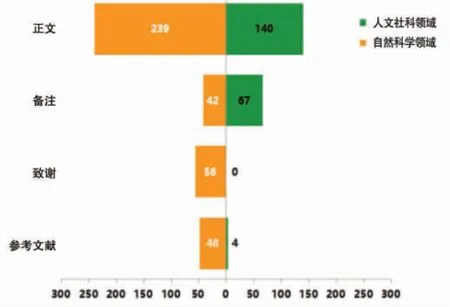
圖2 引用位置情況分析
在調研的樣本論文中,備注部分主要是指圖、表下部的說明或腳注尾注的注釋等內容。自然科學與人文社科分別有 42 次(10.7%)和 67 次(31.8%)引用記錄。通過備注引用數據表明作者對數據來源標注更加明確,在規范程度上比正文更正式,針對性更強。但是,這種引用方式也存在著引用元素不完整,引用顆粒度太粗糙的情況。例如“圖表中數據整理歸納自1993年蘇州統計年鑒”,這樣雖然告知了引用數據的資料來源,但是卻沒有明確標注數據的具體信息。備注部分的引用情況也和某些期刊要求有關,部分期刊在收稿時要求“引用圖表,須在其下方注明出處”。另外,也有些期刊特別說明要通過致謝的方式對論文有貢獻的人員或單位進行感謝和說明,人文社科論文普遍沒有致謝的內容,自然科學領域的《地理學報》《地球物理學報》《應用生態學報》三種期刊里都有致謝部分,所以很多數據及引用內容被放置在了這個環節,這在一定程度上提升了對數據創建者及數據發布存儲機構的貢獻認可,但是由于對數據引用的元數據列舉也不夠規范,并且致謝內容多數都不提供數據的鏈接地址或DOI,所以無法更好地有助于數據的發現、共享和再利用。
對科研數據通過參考文獻的方式進行引用是目前認為最為規范的方式,在此次調研對象中,自然科學領域有48 條引用記錄,人文社科領域僅有4 條引用記錄。但是,值得注意的是,在這48 條記錄中,21 條是直接引用論文,11 條是引用統計年鑒或數據報告,3 條是引用著作或報告,2 條是引用政府網站信息,只有其余的11 條記錄是真正的引用了數據中心的數據集。這種情況也說明即使論文作者嘗試通過參考文獻的方式規范地引用科研數據,但是如果數據引用格式指導缺乏,規范化的引用也很難實現。
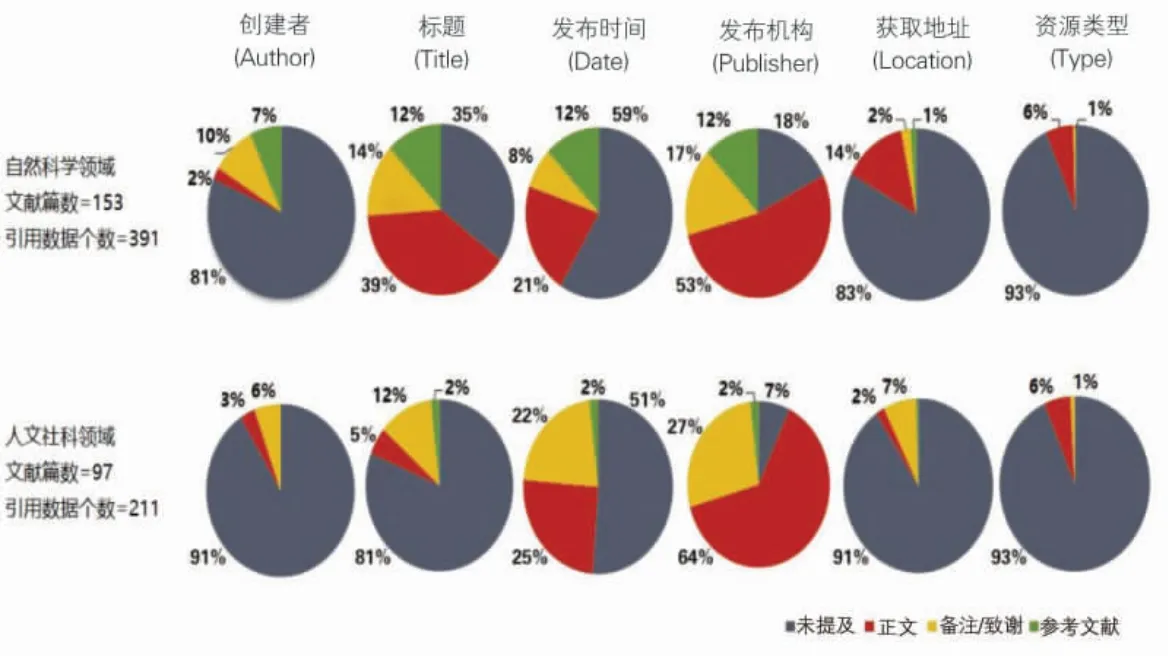
圖3 數據引用元數據按引用位置分類統計結果
由圖3可知,無論數據引用是出現在正文中、還是備注或致謝中,有80%~90%的數據引用記錄都會注明數據的發布機構,而數據的創建者、獲取地址和資源類型則較少提及。選擇通過參考文獻的方式引用科研數據,表明數據來源倉儲庫的規定對于科研數據引用規范化具有重要的作用。
很多數據來源的數據中心會強制要求對使用的數據通過引文的方式進行規范引用,否則會限制該用戶后續對數據的獲取和使用權限,強制性要求使用戶必須重視對所使用數據的說明,督促用戶規范引用行為的同時也增加了數據集、數據中心的傳播范圍和可發現程度,保障了相關利益者的合法權利。很多期刊投稿論文格式的刻板限制也是使得引用數據無法出現在引文列表中的重要原因,而對數據引用指導的缺乏,更加重了期刊論文中數據引用位置的不規范程度。此外,由上圖看到,當作者以參考文獻的方式引用數據時,通常會使用比較完善的元數據信息,這就證明了以引用論文的方式引用科研數據是目前的最佳做法。總體來看,自然科學領域的引用情況要相對人文社科領域來講要稍好一些。
3.3 引用完整性分析
筆者對所獲得的樣本文獻,按照前文構造的數據引用完整性衡量標準,對250 篇有數據引用行為文獻中的602 條數據引用記錄進行評分,判斷數據引用的位置是發生在正文中、致謝或備注中、參考文獻中,并根據引用的元數據情況給予對應的分值,獲得數據引用完整性得分的頻數分布,如圖4所示。
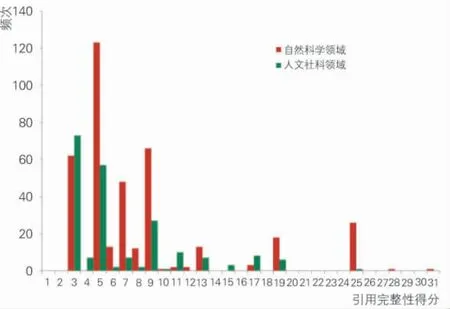
圖4 數據引用完整性得分頻數分布
經過分析可知,自然科學領域的引用完整性程度整體要高于人文社科領域,尤其是高分段的引用得分要更多一些。但是,無論是自然科學還是人文社科領域,從整體上來看我國的引用完整性得分都集中在10 分以內,說明引用行為不規范的情況比較嚴重。
我國自然科學類基金項目論文中,總體數據引用完整性程度頻次最多的是集中在4 分的分段,頻次是132,這類引用多是只在正文或致謝中出現引用數據的來源機構名稱。例如“感謝美國冰雪數據中心(NSIDC)提供ICESat 數據”,這樣的引用只是比較簡單的交代了數據的來源,但過于隨意和籠統,并沒有準確說明使用的數據集的名稱、創建者、創建時間以及獲取的地址等信息,讀者也無法追溯論文所使用的數據來源。其次,自然科學領域的完整性分值集中在2 分和8分的分段,頻次分別是62 和66。得到2 分引用記錄通常只是在正文中交代1-2 個要素,屬于引用方式極不規范的情況。
在人文社會科學領域,總體數據引用完整性整體偏低,與自然科學領域相比分數大部分分布在2 分至4 分的區間里,頻次分別為73 和57。這樣的引用記錄只是在文中介紹了數據的發布或存儲機構名稱,沒有其他詳細的信息,如“數據均來自國泰安CSMAR 數據庫”。人文社科類文獻使用的數據種類繁多,有些甚至需要跨越很多省份地區、需要很多年的長期調研才得到的數據,比如有很多論文使用到了歷年的人口普查的數據或統計年鑒等資料,并且大多數只使用了其中的部分數據,并通過進一步的處理和轉換后進行研究。然而文章中卻缺少對所選用的數據集名稱、變量情況等內容的說明,也較少有標注獲取地址或DOI 等信息,使得文章讀者無法追溯原始數據。
由前文文獻綜述部分所述可知,雖然基金組織、期刊論文和數據倉儲庫對數據引用的指導逐漸重視,但無論是自然領域還是人文社科領域仍然存在數據引用方面意識薄弱及引用行為不夠規范等問題。由此可見,無論是自然科學領域還是人文社會科學領域的基金項目論文中,雖然不同領域的引用情況有差別,但總體來說對科研數據的引用情況規范程度都不高,這不僅難以對研究成果進行考證和追溯,也阻礙了科研數據的發現、共享和再利用,需要引起我國各相關利益群體的重視。
4 結語
本文選取自然科學領域和人文社科領域共20 種期刊作為抽樣對象,按照等距抽樣的原則選取了近兩年來的基金項目論文,參考已有研究成果構建出科研數據引用完整性衡量標準,對文章作者的數據引用行為從引用元數據、引用位置和引用完整性三個方面進行分析。在引用元數據方面,注明數據的發布機構的做法是最常見的,其次是在引用的時候說明數據的發布時間及數據集名稱,而對數據的創建者、獲取數據的地址或DOI、數據資源類型、獲取時間等信息則很少規范說明,這種現象反映了我國科研數據引用行為不夠規范。在引用位置方面,主要集中出現在正文,其次是在備注部分。對科研數據通過參考文獻的方式進行引用是目前認為最為規范的方式,并且自然科學領域的數據引用行為要比人文社科領域更加規范。在引用完整性方面,通過構建的引用完整性得分表可以看出,我國基金項目論文中對數據引用的完整性得分總體較低。但在自然科學領域方面,數據的引用完整性程度整體要高于人文社科領域。
猜你喜歡
中小學教師培訓(2022年11期)2022-11-01 03:13:54
中小學教師培訓(2022年10期)2022-10-15 02:18:04
保健醫苑(2022年6期)2022-07-08 01:24:52
北部灣大學學報(2022年1期)2022-06-22 04:58:38
北部灣大學學報(2022年2期)2022-06-21 11:44:36
中國信息化(2022年4期)2022-05-06 21:24:05
北部灣大學學報(2021年1期)2022-01-27 06:40:10
現代儀器與醫療(2021年4期)2021-11-05 08:25:08
北部灣大學學報(2021年6期)2021-06-21 06:01:48
北部灣大學學報(2021年4期)2021-04-28 08:01:04
