一種基于均勻分布策略的NSGAII算法
2019-08-21 03:28:58喬俊飛李霏楊翠麗
自動化學報 2019年7期
喬俊飛 李霏 楊翠麗
大多數的工程和科學應用,如工業制造、城市運輸、污水處理和資本運算等,幾乎每個重要的現實生活中的決策都存在多目標優化問題.這些目標往往是不可比較,甚至是相互沖突的.因此多目標優化問題(Multiobjective optimization problem,MOP)一直是近幾年主要的研究課題之一.為了解決該問題,多目標進化算法(Multiobjective evolutionary algorithm,MOEAs)已被廣泛研究.其中Schaffer[1]提出了向量評估遺傳算法(Vector evaluated genetic algorithm,VE-GA),該算法對單目標遺傳算法進行了改進.但VEGA只能找到Pareto前端的始末端,產生不了均勻分布的解.為此Fonseca等[2]提出了多目標遺傳算法(Multiobjective genetic algorithm,MOGA),這種算法效率較高,而且易于實現.但該算法的不足在于如果小生境數目信息是基于目標函數的,那么兩個具有相同目標函數向量的不同個體無法在同一代種群中存在.為了解決該問題,Srinivas等[3]提出了非劣分類遺傳算法(Nondominated sorting genetic algorithm,NSGA),該算法先按解個體的非劣關系進行排序,再按照共享機制來保持進化的多樣性.但是該算法計算效率較低,計算復雜度大,且共享參數σ需要預先確定.為了減小算法的計算復雜度,Deb等[4]提出了改進型非劣分類遺傳算法(Nondominated sorting genetic algorithm II,NSGAII),該算法采用非支配排序進行分級,通過計算擁擠距離選擇最優解,并將其做為精英解保存起來.但該算法是一種類隨機搜索算法,存在操作次數多收斂速度慢和解分布特性較差的問題[5].
由于種群在迭代過程中種群分布不均會導致種群多樣性變差從而易使解陷入局部最優,并且在迭代過程中Pareto前沿部分區域易出現空白,收斂速度變慢.為了解決種群分布不均帶來的上述的問題,Goldberg等[6]提出了基于共享機制的小生境技術,該方法考慮了一個個體與群體中其他個體之間的相似程度,但計算開銷比較大.朱學軍等[7]提出用進化群體熵來刻畫進化群體的多樣性和分布性.然而這種方法缺乏對群體內部個體之間關系的刻畫,因此不便于調控群體進化過程中的多樣性和分布性.為了解決這個問題,Corne等[8]提出了網格方法,將網格中聚集密度大的個體刪除,但不能刪除極點個體.Knowles等[9]提出了自適應網格技術,在每一代進化時,根據當前代的個體分布情況自適應地調整邊界.Morse[10]提出了聚類分析的方法來保持種群的多樣性.Han等[11]提出了基于種群間距信息和種群分布熵的方法.但是以上方法只能刪除種群中擁擠距離較小的個體,無法解決解的過程中Pareto前沿部分區域出現空白的問題.
基于以上問題,本文提出了一種基于均勻分布的NSGAII(NSGAII-UID)多目標優化算法.該算法受文獻[12]的啟發,將種群映射到目標值對應的超平面上,并在該平面上聚類.但是文獻[12]中提出的算法仍然存在種群分布不均的問題,從而影響了種群的多樣性,為了解決該問題,本文將映射平面均勻分區.當對應區間的分布性不滿足時,分布性加強模塊激活.由于種群在迭代的過程中對應區間會出現種群個體不足或缺失的狀況,此時需要在該區間內放入一些個體.為了解決該問題,本文將所選聚類子群體中擁擠距離最大的點進行局部搜索,采用極限優化變異[13]的方法產生新的個體.實驗結果表明,該方法綜合評價指標(Inverted generational distance,IGD)值和分布性評價指標(Spacing,SP)值均高于其他算法.因此表明該方法具有較好的種群多樣性和分布性,且收斂速度較快.
1 基本概念
1.1 多目標及相關定義
定義1.多目標優化問題(MOP)
一個具有n個決策變量,m個目標函數的多目標優化問題可以描述為:
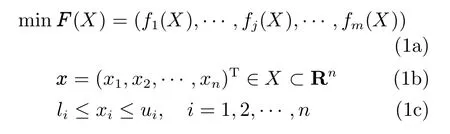
式中,x稱為決策變量,X是n維的決策空間;F(X)∈Rm為m維目標向量;fj(X)(j=1,2,···,m)為第j個目標函數,li和ui分別為第i個決策變量的上界和下界.
定義 2.Pareto-占優對于給定的兩點x,x?∈Xf,x?是Pareto-占優(非支配)的,當且僅當式(2)成立,記為x?>x.
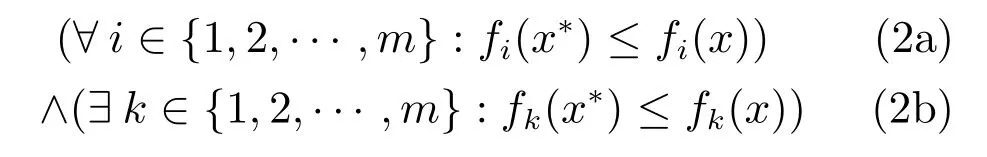
定義 3.Pareto-最優解
若對于任意解x,不存在x’∈?使得F(x’)=(f1(x’),f2(x’),···,fm(x’))占優于F(x)=(f1(x),f2(x),···,fm(x)),則稱x為Pareto最優解或者非劣解.
定義4.Pareto-最優解集
所有Pareto-最優解組成的集合Ps稱為Pareto-最優解集.
定義 5.Pareto-前沿
Pareto-最優解集合Ps中的解對應的目標函數值組成的集合PF稱為Pareto-前沿,即:
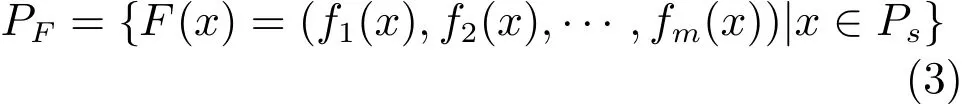
1.2 模糊 C-均值聚類算法
設n個數據樣本為P={p1,p2,···,pn},c(2≤c≤n)是要將數據樣本分成不同類型的數目,{A1,A2,···,Ac}表示相應的C個類別,U是其相似分類矩陣,各類別的聚類中心為{v1,v2,···,vn},μk(pi)是樣本pi對于類Ak的隸屬度(簡寫為μk).則目標函數Jb可以表達為:
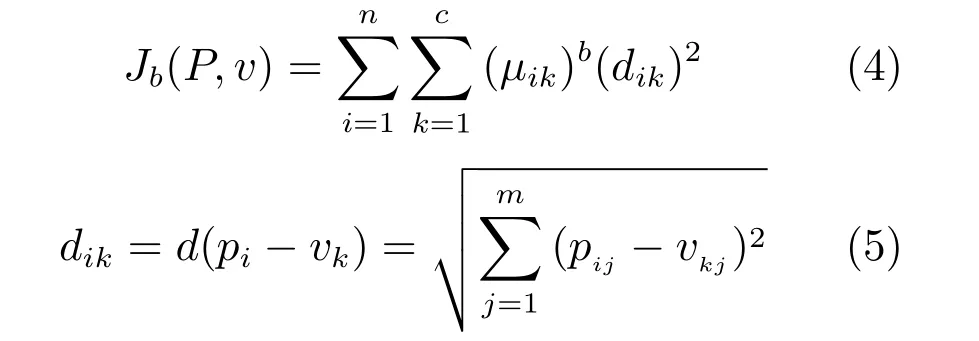
其中,dik是歐幾里得距離,用來度量第i個樣本pi與第k類中心點之間的距離;m是樣本的特征數;b是加權參數,取值范圍是1≤b≤∞.模糊C-均值聚類方法就是尋找一種最佳的分類,以使該分類能產生最小的函數值Jb.它要求一個樣本對于各個聚類的隸屬度值和為1,即滿足:
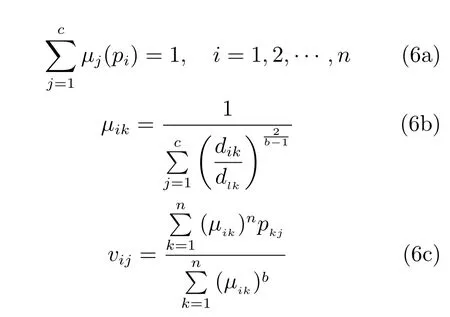
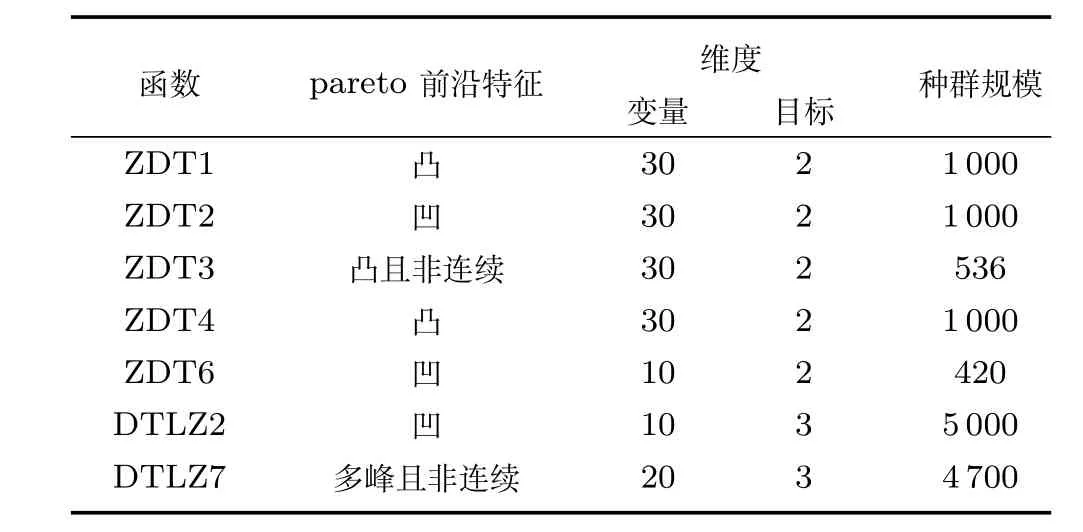
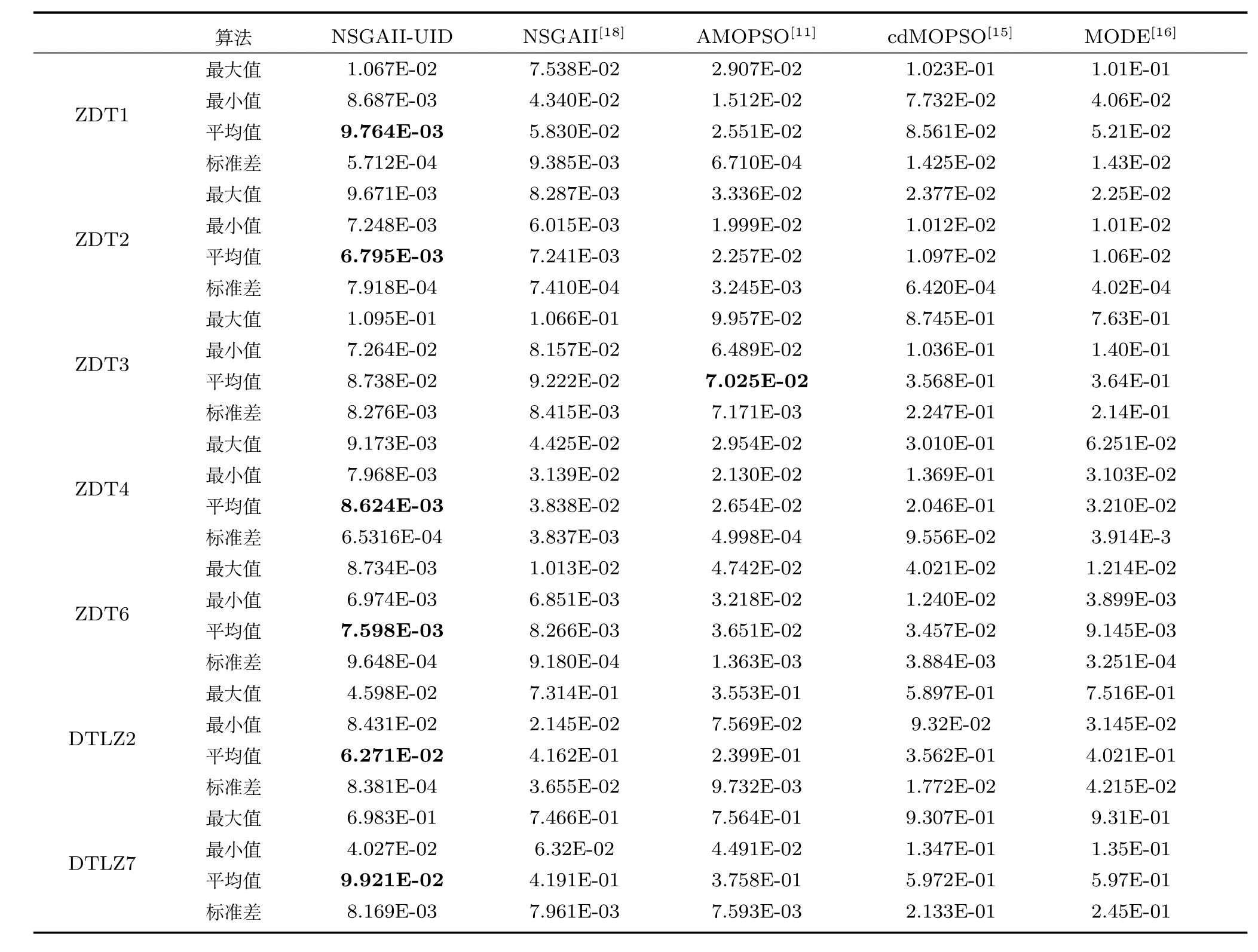
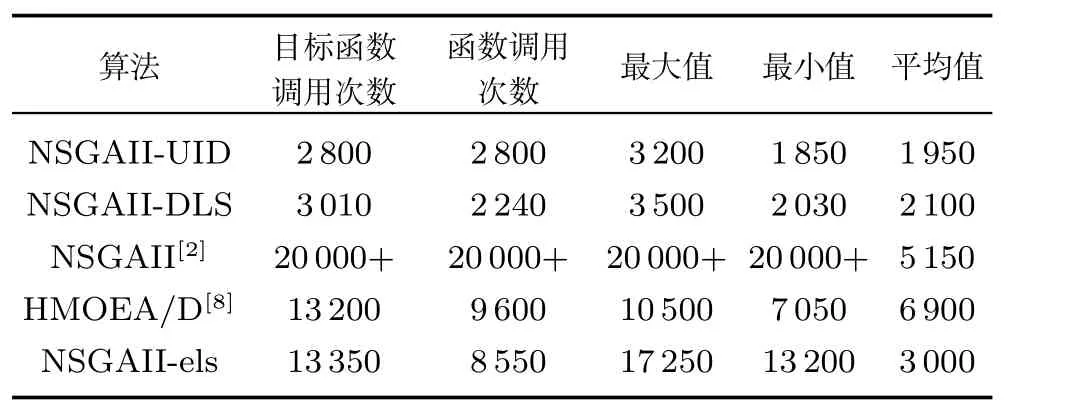
設Ik={i|2≤c 為了解決種群分布不均的問題,本文提出了將目標空間均勻分區,選取相同數量個體的方法.由于目標空間一般為曲線或者曲面,想要均勻劃分較難操作.為了解決這個問題,本文受文獻[12]的啟發,在文獻[12]中,種群中的個體映射在一個超平面上,并在目標空間中聚類.為了驗證種群的多樣性將集群質量度量標準.但是該方法在迭代過程中存在種群分布不均的問題,從而影響種群的多樣性,進而造成收斂速度慢,Pareto前沿有些區域出現空白的現象.針對以上問題本文提出了將種群映射到目標函數值對應的超平面H,在H上進行均勻分區以增加種群的多樣性的方法.該方法將種群在映射平面上進行聚類,并記錄聚類中心,計算每個分區中的聚類中心個數,從而判斷是否滿足均勻分布條件.當條件不滿足時,分布性加強模塊激活.由于在計算過程中區間內有時會出現個體數量不足或者為空的情況,為了在該區間獲取缺失的個體,本文采用極限優化變異產生新的個體.當該區間個體不為空時,將聚類子群體按照擁擠距離從大到小排序,選取第一個個體進行變異.當該區域為空時,將離該區間最近的個體進行變異.該方法不但可以使種群跳出局部最優,并且能夠較快地找到Pareto前端. 設目標向量為: 定義超平面[12]H為k維歐氏空間的k?1維線性子空間,bs=?1,h·i為歐氏內積 目標向量f映射到超平面[12]H為PI,公式如下所示: 由于NSGAII在運算過程中種群的分布性較差,為了解決這個問題,本文加入了分布性判斷模塊.該模塊用來判斷每個均勻分段區間內聚類子群體的分布情況,同時選取聚類子群體中種類數量最大值作為閾值來判斷分布性.當區間內種群類別小于該閾值時,則判斷該區間不滿足分布性,分布性加強模塊激活.否則,該區域滿足分布性,且選取每個聚類子群體中擁擠距離最大的個體放入精英檔案. 該算法首先將目標區間均勻分區,其中每個區間的種群分布如下: n為分段區間的數量,Doi為第i個區間所包含的子群體所有類別的集合,i∈[1,n],如下所示: NRPij為第i個區間內的種群中心編號,其中i∈[1,n],j∈[1,r],r為種群中心數量,ABnrk為第i個區間第r個聚類中心所對應的個體,k∈[1,m],m為該類子群體個體數量.區間內種群中心數量最大值為maxnr.判斷種群分布性的方法如下所示: 其中,ir為第i個區間內的種群中心數量,maxDon為分段區間內種群中心數量最大值. 情況1.若該條件成立,則分布性加強模塊激活. 情況2.將該類子群體按照擁擠距離從大到小排序,選擇每個聚類子群體第一個個體. 當種群不滿足上述分布性條件時,分布性加強模塊被激活.在種群選取的過程中,每個區間選擇相同數量的個體.同時為了增加種群的多樣性,從每個聚類子群體中按照方法1)與2)選取擁擠距離較大的個體放入精英檔案.然而在運算的過程中,區間內有時會出現種群數量不足或空缺的狀況.在以往文獻中多是采用將擁擠距離較小的個體刪除的方法,當種群空缺或不足時,并未有相關文獻進行介紹.為了解決這個問題,本文提出了對所選精英個體進行極限優化變異的方法,來填補欠缺的個體.由于在計算過程中區間內種群中心的數量不同,采取的策略也不相同.具體方法如下所示: 1)第i個區間種群中心個數量ir為0: 其中icm為在第i個區間內第c個聚類中心對應的子群體中的個體數量,c∈[1,ir]∪0. 情況1.將該類子群體按照擁擠距離從大到小排序,取前maxnr個個體. 情況2.選取所有個體,剩余maxnr-icm個個體由擁擠距離最大的個體變異得到.(詳見第2.4節) 情況3.由于該區間無個體,本文選取離該區間最近的兩個個體變異得到maxnr個個體(詳見第2.4節).若該區間連續20次為空則該區間設定為空. 2)第i個區間種群中心個數量ir不為0: 當該區間種群中心個數不為零時,需要從聚類中心對應的子群體中選擇相應的個體.選擇方式如下所示: S-num為每個聚類子群體應當平均選擇的個體數目,Renr為需要選擇的剩余個體的集合,|Renr|為需要選擇的剩余個體的集合的數量,Renri為剩余的個體對應編號,i∈[1,t],t為余數的個數.根據余數的是否為0,選擇方式也不相同,具體如下: a)余數Rer為0: 情況2.選取所有個體,剩nrm-S-num個個體由變異得到.(詳見第2.4節) b)余數Rer不為0: 當剩余個體數量不為0時,選擇的方式如下所示: 由于在迭代過程中有的時候區間會出現種群數量不足或為空的狀況.為了保證每個區間個體選取數量相同.本文采取最優個體極限優化變異策略.首先找到需要選擇子群體中擁擠距離最大的個體或者離該區間最近的兩個個體,然后對其進行變異,本文采用兩種變異策略來產生局部解[13]: 1)第一種變異策略: 對于選定的對象,每次只有一個決策變 量發生變異,這樣有效的提高了種群的局部搜索能力,從而提高了解的計算精度.設當前選定個體ABnrm=(ABnrm1,···,ABnrmi,···,ABnrmj),j為決策變量的個數.種群總數為N,則產生局部解的個數為μ,μ的值由上文(詳見第2.3節)的需要動態決定.具體如下: 其中,ABnrmi為待變異個體的決策變量;α為 (0,1)區間的隨機變量;β∈R,且為形狀參數,本文通過多次實驗得到β設為11為最佳.θmax(ABnrmi)為決策變量ABnrmi可變動區間的最大值.該變異方法因為每次只將一個決策變量變異,所以具有較強的局部微調能力.但是該方法只能夠在小范圍內搜索.為了避免種群陷入局部最優,同時提高搜索速度,本文加入了第二種變異策略.該策略將產生20%×μ個局部解[14](如非整數則取整),具體方法如下所示: 2)第二種變異策略: 其中,λ∈(0,1.2)為一隨機數.以上兩種變異策略共產生λ+[0.2λ]個局部解. 根據具體問題初始化參數:設定目標函數有m個,初始種群數量為N,精英解數量為N/2,函數最大調用次數設為Imax,決策變量維數為j,決策變量的取值上下界為u=(u1,u2,···,ui,···,uj),下界為ll=(l1,l2,···,li,···,lj),形狀參數設為g,交叉參數θc,交叉概率Pc,變異參數θm,變異概率Pm,具體的算法流程如下所示: 步驟 1.初始化種群P={p1,p2,···,pm,···,pN},其中pm=(x1,x2,···,xj),m=1,2,···,N,其中xj∈(lm,um).計算種群中每個個體對應的目標函數值. 步驟2.對種群P中的解進行非支配排序,排序后當前種群的所有非支配解記為Pc. 步驟 6.當區間內的子群體不滿足均勻分布條件時,需要按照第2.3節所示增加種群的分布性,若該區間個體數量不足時,缺少的數量通過對擁擠距離最大的個體變異得到,詳見第2.4節.當前選擇出來的用來增加分布性的種群記為Pe,種群數量為n×maxnr. 步驟7.將種群Pc中包含在Pe中的個體去掉,然后按照擁擠距離選取N/2?n×maxnr個個體,記為Ps. 步驟 8.合并Pe與Ps,得到種群Pm.將Pm進行交叉變異,得到新的種群Ph.合并Pm和Ph為下一代種群PT. 步驟9.重復步驟2至步驟8,當達到最大迭代次數或者預設的目標時,進行下一步. 步驟10.當前PT中的非支配解即為得到的最優解. 本文采用Matlab R2013b版本,處理器為3.60GHz,8.00GB內存,Microsoft實驗環境.為了驗證算法的收斂性和多樣性采用了以下性能評價指標對算法進行了驗證. 1)綜合評價指標(Inverted generational distance,IGD): IGD用來評價算法的性能,它的值越小則解的收斂性和多樣性就越好.具體計算公式如下所示: 2)分布性評價指標(Spacing,SP): SP用來測量已知帕累托前沿相鄰解間距離的方差.定義如下所示: q為非支配解的個數,q=2,3,···,n,為ui的平均值. 由于雙目標ZDT系列函數和三目標DTLZ系列函數被廣泛地用于驗證多目標優化算法[13],本實驗分別采用(ZDT1~ZDT4,ZDT6)函數和(DTLZ1、DTLZ2)函數來驗證算法的性能.該系列函數的特征、維度和種群規模如表1所示. 表1 測試函數參數Table 1 Paramter setting of the test function 為了檢驗NSGAII-UID算法的性能,該算法分別和一種基于密度的局部搜索NSGAII算法 (NSGAII-DLS[14])、標準 NSGAII[15]、定向搜索算法 NSGAII-els[16]、隨機局部搜索算法 HMOEA/D[17]、自適應多目標粒子群算法(AMOPSO[11])、多目標差分進化算法(MODE[16]6種算法進行了對比. 本實驗采用模擬二進制交叉和多項式變異方法,交叉參數ηc和變異參數ηm均設為20,交叉和變異概率分別為0.9和1/n,n為決策變量的數量;形狀參數q設為11.在進行ZDT實驗時,不同的多目標優化算法采用相同的種群數量:最大計算量設為Imax=5000,種群規模設為100,由于通過交叉變異會產生50個子代,所以共計迭代了100次.為了驗證算法的有效性,實驗結果如圖1~圖5所示. 在進行DTLZ系列實驗時,參數選擇為:最大計算量設為Imax=15000,種群規模設為100,由于通過交叉變異會產生50個子代,所以共計迭代了300次.為了驗證算法的有效性,實驗結果如圖6~圖7所示. 圖1 ZDT1優化效果Fig.1 The optimization effect of ZDT1 圖2 ZDT2優化效果Fig.2 The optimization effect of ZDT2 由圖1~圖7可視,對于凹、凸和非連續的多目標函數,NSGAII-UID可以較好地逼近pareto前端且分布較均勻,NSGAII-UID與其他算法對比結果如表2所示.該表分別列出了當函數調用次數分別為 5000次和 15000次時,實驗結果連續30次的最大值、最小值和平均值.從該表可以看出NSGAII-UID在5個測試函數(ZDT1、ZDT2、ZDT4、DTLZ2、DTLZ7)中 IGD的最大值、最小值和平均值均優于其他算法.在ZDT3和ZDT6中由于Pareto前沿在指定區間內存在空白區域,NSGAII-UID的IGD值略小于AMOPSO[11]算法,在后續的工作中將會就此問題進行更深一步的研究.因此從以上結果可以看出和對比算法相比,該算法具有較好的精度和收斂性. 表2 NSGAII-UID與其他局部搜索算法的ZDT和DTLZ系列實驗IGD結果Table 2 ZDT and DTLZ series performance IGD comparison of different algorithms 圖3 ZDT3優化效果圖Fig.3 The optimization effect of ZDT3 圖4 ZDT4優化效果Fig.4 The optimization effect of ZDT4 表3 NSGAII-UID與其他局部搜索算法的ZDT和DTLZ系列實驗SP結果Table 3 ZDT series performance SP comparison of different algorithms 由圖1~圖7可視,對于凹、凸和非連續的多目標函數,NSGAII-UID可以較好地逼近Pareto前端且分布較均勻,NSGAII-UID與其他算法對比結果如表2所示.該表分別列出了當函數調用次數分別為5000次和15000次時,實驗結果連續30次的最大值、最小值和平均值.從該表可以看出NSGAII-UID在5個測試函數(ZDT1、ZDT2、ZDT4、DTLZ2、DTLZ7)中IGD的最大值、最小值和平均值均優于其他算法.在ZDT3和ZDT6中由于Pareto前沿在指定區間內存在空白區域,NSGAII-UID的IGD值略小于AMOPSO[11]算法,在后續的工作中將會就此問題進行更深一步的研究.因此從以上結果可以看出和對比算法相比,該算法具有較好的精度和收斂性. 圖5 ZDT6優化效果Fig.5 The optimization effect of ZDT6 圖6 DTLZ2優化效果圖Fig.6 The optimization effect of DTLZ2 圖7 DTLZ7優化效果Fig.7 The optimization effect of DTLZ7 參照文獻[11]的實驗,對算法NSGAII-UID的分布性進行檢驗,不同多目標優化算法采用相同的參數,具體參數設置同實驗1所示.該實驗共與4個算法 (AMOPSO[11]、cdMOPSO[19]、NSGAII[8]、MODE[17])進行了比較,取連續30次實驗平均值作為結果如表3所示. 由表3可見NSGAII-UID算法在6個測試函數(ZDT1、ZDT2、ZDT4、ZDT6、DTLZ2、DTLZ7)的SP最大值、最小值和平均值均小于其他對比算法.在ZDT3中SP值略小于AMOPSO[11]算法,由以上結果顯示該算法和其他算法相比算法相比具有更好的分布性. 為了驗證算法的收斂速度,本文采用記錄算法達到指定性能指標時所調用的函數次數的方法.參照文獻[9]的實驗,設定當IGD值達到0.01時停止優化,記錄函數調用次數.實驗結果如表4所示. 表4 NSGAII-UID與其他局部搜索算法的函數計算次數結果Table 4 Function calculation comparison of different algorithms 由表4可見:在ZDT1-ZDT4和ZDT6的實驗中,當IGD達到設定值時,連續實驗10次的平均值,NSGA2-UID所用函數調用次數均小于其他方法,因此NSGA2-UID達到指定標準消耗的計算量更少,即該算法收斂到Pareto前沿速度更快. 針對NSGAII在種群進化過程中會出現解分布不均的問題,本文提出了一種基于均勻分布的NSGAII(NSGAII-UID)多目標優化算法.為了使解能夠在目標空間均勻分布,而真正的Pareto前沿大都是曲線或者是曲面,本文采用映射的方法,將解映射到目標空間對應的超平面,并在該平面均勻分區.當對應分區的解不滿足均勻性時,均勻性加強模塊被啟用.同時采用聚類分析的方法來維持和增加進化種群的多樣性和分布性.為了驗證算法的性能,本文采用5個ZDT函數和示,兩個DTLZ函數來進行實驗,實驗結果顯示該算法和其他多目標優化算法相比具有更好的收斂性和分布性,同時收斂速度較快.2 基于均勻分布的NSGAII算法
2.1 映射



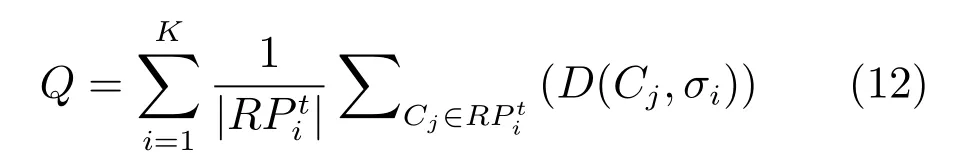
2.2 分布性

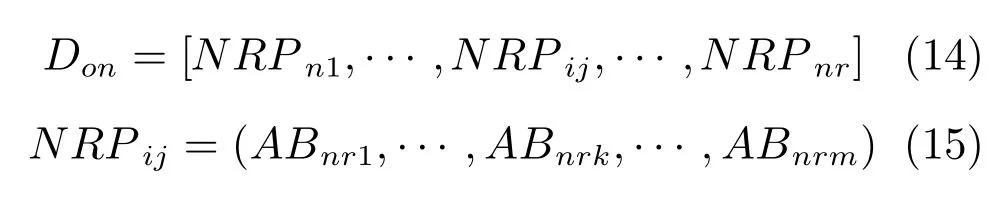

2.3 分布性加強


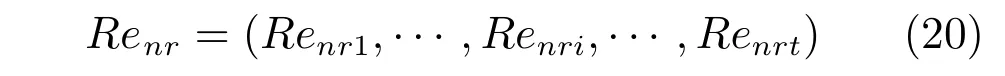


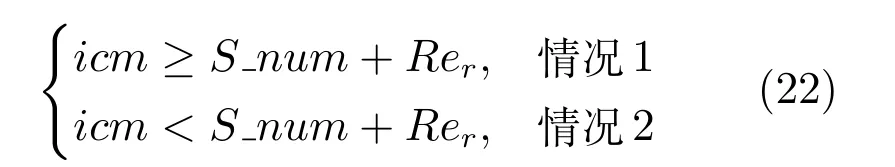

2.4 局部變異策略
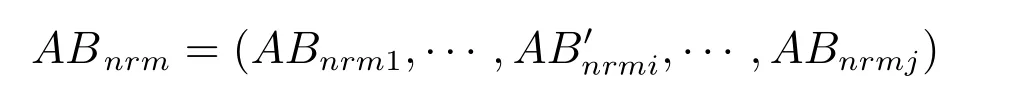
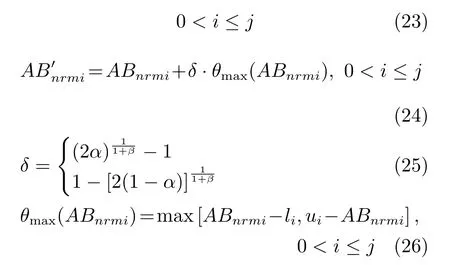

2.5 算法流程
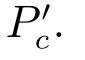

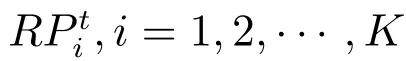
3 仿真實驗



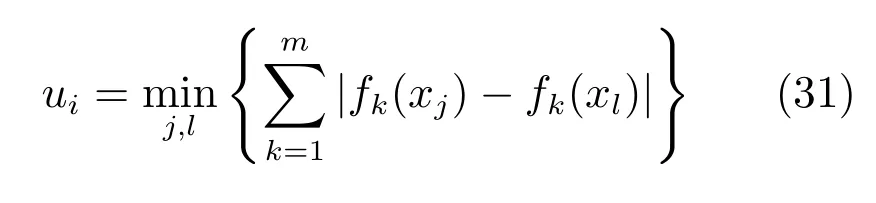
3.1 實驗1
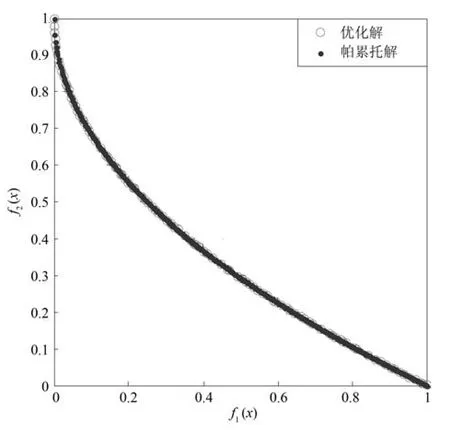
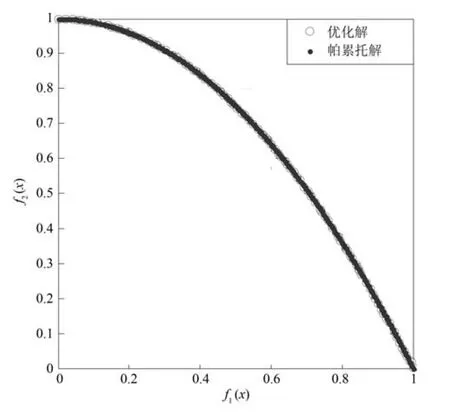
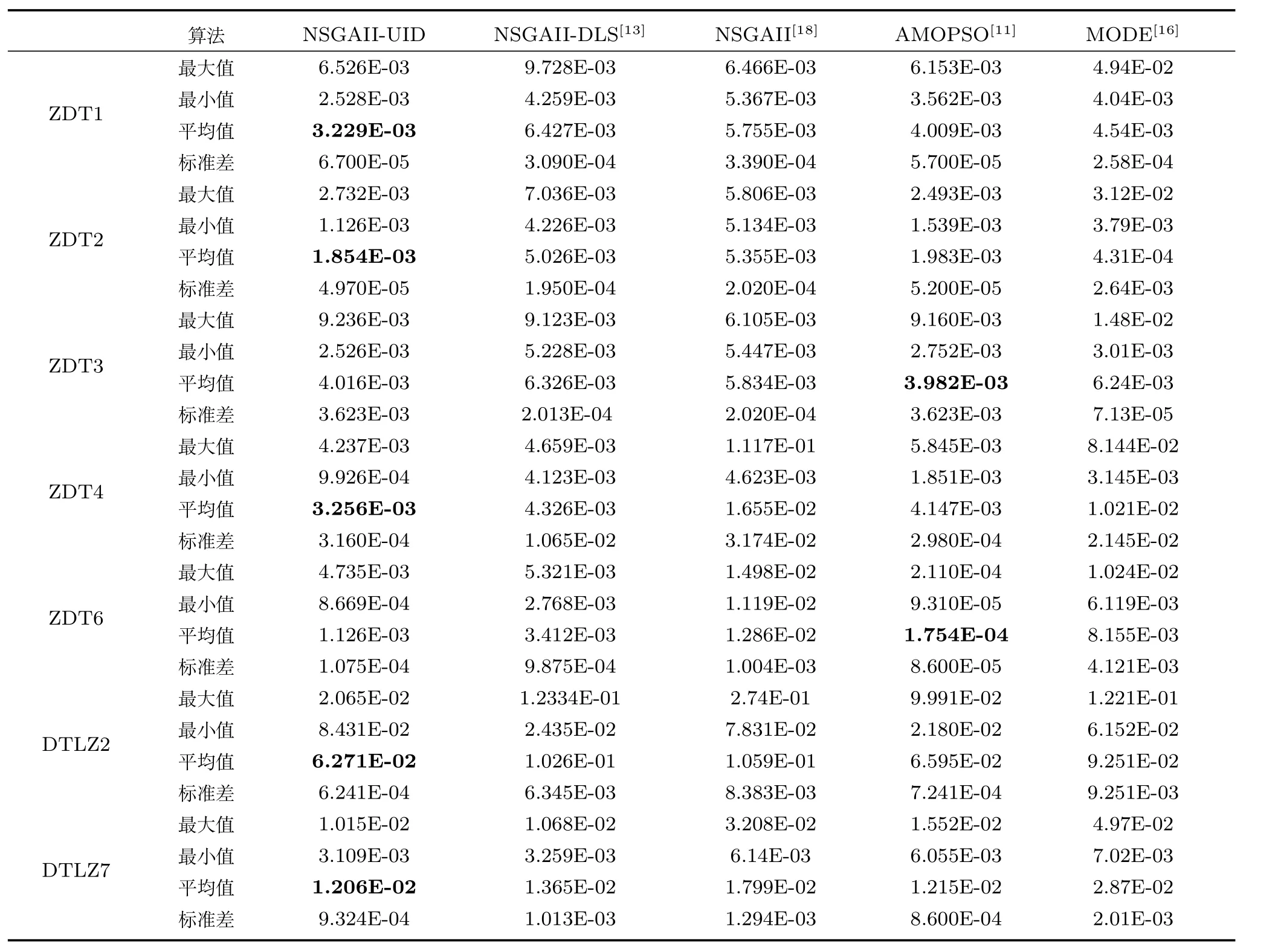

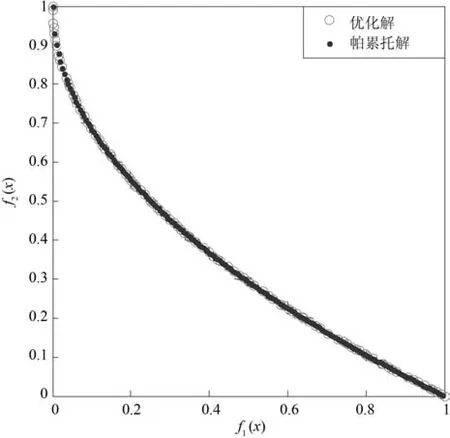



3.2 實驗2
3.3 實驗3
4 結論
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
房地產導刊(2022年5期)2022-06-01 06:20:14
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
