基于詞向量相似度的食品安全問答系統設計與實現
2019-10-15 02:21:53楊晨張鵬
軟件導刊 2019年8期
關鍵詞:食品安全
楊晨 張鵬
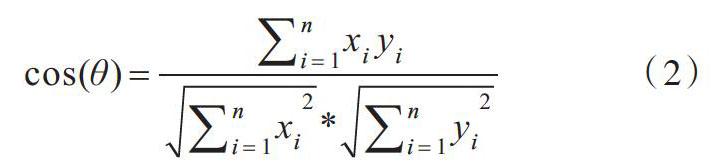


摘 要:針對目前食品安全問答系統準確率不高且無法滿足智能化問答要求等問題,基于詞向量相似度設計食品安全問答系統。采用深度學習方法構建食品安全領域知識庫及詞向量模型,結合近義詞庫提出問句相似度計算方法,將問句與知識庫內所有問句進行匹配,返回相似度最高問句對應的答案。實驗結果表明,該系統問答準確率達到80%,能滿足食品行業用戶的日常問答需求。
關鍵詞:食品安全;詞向量;句子相似度;問答系統
DOI:10. 11907/rjdk. 182790 開放科學(資源服務)標識碼(OSID):
中圖分類號:TP301文獻標識碼:A 文章編號:1672-7800(2019)008-0016-05
Application of Food Safety Question Answering System
Based on Word Vector Similarity
YANG Chen, ZHANG Peng
(School of Computer Science, Jiangsu University of Science and Technology, Zhenjiang 212003, China)
Abstract:Aiming at the current problem of the accuracy of the question and answer system in the field of food safety, and the inability to meet the requirements of intelligent question and answer,a food safety question and answer system based on word vector similarity is proposed. The system uses the deep learning method to construct the knowledge base and word vector model in the field of food safety, and combines the thesaurus to propose the method of calculating the similarity of questions, matching the questions with all the questions in the knowledge base, and returning the corresponding questions with answers of the highest similarity. The experimental results show that the accuracy rate of the system is 80%, which can meet the users' daily need of questions and answers in the food industry.
Key Words:Food safety; word vector; sentence similarity; question answering system
作者簡介:楊晨(1994-),男,江蘇科技大學計算機學院碩士研究生,研究方向為智能信息處理;張鵬(1994-),男,江蘇科技大學計算機學院碩士研究生,研究方向為智能信息處理。
0 引言
隨著網絡技術的發展,信息來源愈加豐富,但也帶來信息質量參差不齊、難以得到準確信息等問題,利用自然語言處理技術構建面向不同領域的問答系統應運而生[1]。
相關研究有:考慮到命名實體和實體關系對答案匹配的影響,通過分析命名實體和實體關系,于根等[2]構建了基于信息抽取技術的問答系統,并提出基于層次的答案提取方法;秦兵等[3]根據用戶提問內容構建候選問題集,通過計算問題集與問句相似度并返回答案的方法實現基于常見問題集的問答系統,并證明此方法能有效提高問題匹配的準確率;蘇斐等[4]通過對問答系統中問句信息的深入挖掘,實現了基于問句表征的問答系統,有效改善了問答系統的答案抽取準確性和系統性能。
目前特定領域(如食品安全)問答系統研究較少,且存在回答效果差、性能低下等問題[5]。因此,利用自然語言處理技術進行特定領域問答系統的研究有著重大意義。本文通過引入近義詞詞典,提出一種基于近義詞詞向量相似度的問句相似度算法,實現了基于此算法的食品安全問答系統。
1 相關技術
1.1 自然語言處理
文本預處理是實現自然語言處理的基礎[6],文本預處理主要包括分詞、去除停用詞等操作。中文文本的分詞方法[7]主要有基于字符串匹配的分詞方法、基于理解的分詞方法和基于統計的方法。
基于字符串匹配的分詞方法主要包含正向最大匹配法、逆向最大匹配法、最少切分和雙向最大匹配法。在正向最大匹配分詞算法基礎上,常建秋等[8]提出一種正向最大逐字匹配方法,提高了分詞的準確性,增強了基于字符串匹配分詞方法的實用性。
基于理解的分詞方法[9]需要大量的信息和語言知識作為基礎,但漢語語言知識的復雜性、多樣性使基于理解的分詞方法難以在實際中運用。
基于統計的分詞方法則是利用統計機器學習模型對已分詞后文本進行詞語切分規律的學習,進而對未知文本進行分詞。基于統計的分詞方法,常用的統計模型有最大熵模型[10](ME)、隱馬爾可夫模型[11](Hidden Markov Model ,HMM)、N元文法模型[12](N-gram)和條件隨機場模型(Conditional Random Fields,CRF),從而衍生出最大熵分詞方法、最大概率分詞方法等基于統計的分詞方法。
常見的分詞工具有jieba分詞、IKAnalyzer、漢語詞法分析系統(ICTCLAS)和Stanford 漢語分詞工具[13]。
文本中詞匯間的關系難以依靠詞語本身獲得,只有將其轉換為向量形式并放入一個較大的語料庫中,才能判斷詞匯之間的關系[14]。
Word2vec是Google于2013年推出的一個自然語言處理工具,它采用兩種神經網絡語言模型CBOW和Skip-gram模型實現詞的分布式表示[15]。CBOW模型和Skip-gram模型都屬于淺層的雙層神經網絡,包括輸入層、隱藏層和輸出層。CBOW模型的基本原理為輸入一個特定詞的上下文相關詞的詞向量,輸出這個特定詞的詞向量,而Skip-Gram模型的原理則是將特定的一個詞的詞向量作為輸入,輸出是特定詞對應的上下文詞向量。Skip-gram模型的精度一般優于CBOW模型[16],因此本文采用Skip-gram模型進行訓練。
1.2 相似度計算
相似度計算是實現問答系統的重要一步[17],通過計算用戶輸入的問句與知識庫中每一條知識所對應問題的相似度,返回相似度排名中較為靠前的知識,從而確保答案更加精準。計算語句相似度方法很多,包括計算余弦相似度[18]、N-gram相似度[19]等方法。
(1)N-gram相似度是一種模糊匹配方法,通過兩個相似句子間的“差異”衡量相似度。計算方法為將原句子按長度N(N一般取值為2或3)切分得到詞段,即原句中所有長度為N的子字符串,對于這兩個句子,則可通過共有子串的數量定義相似度,公式如下:
[P(T)=P(w1|begin)*P(w2|w1)*?*P(wn|wn-1)] (1)
其中,[P(w1|begin)]可以理解為以[w1]開頭的所有句子在句子總數中的比例,[P(w2|w1)]表示[w2,w1]同時出現的次數與[w1]出現的次數比值。
(2)余弦相似度指利用向量空間中兩個向量夾角的余弦值表示兩個個體間差異的大小程度。余弦值越接近1表示夾角越接近0°,即兩個向量越相似;反之,余弦值越接近0表示夾角越大,說明這兩個向量不同,稱為“余弦相似性”。相比距離度量,余弦相似度更加注重兩個向量在方向上的差異,而非距離或長度上的差異。
[cos(θ)=i=1nxiyii=1nxi2*i=1nyi2]? ? (2)
其中,[xi]為句子1中的某一個特征詞的詞向量,[yi]為句子2中某個特征的詞向量。
2 基于詞向量的問句相似度算法
2.1 分詞處理
將用戶輸入的問句記作[Si],同時將知識庫中對應的問句記為[Ai],通過jieba分詞工具對[Si]和[Ai]進行分詞,然后去除停用詞,得到一個由N個詞組成的句子[Si'={x1,x2,?,][xN}]與一個由M個詞組成的句子[Ai'={a1,a2,?,aM}]。
2.2 分詞替換為標準詞
近義詞采用人工錄入方式進行。經過多年積累,系統常用詞匯基本上都有比較全的近義詞集,其中詞條已達千萬級。針對零售行業系統也作過相關業務詞的近義詞擴展。
除近義詞關系外,系統還考慮了其它關系,如 “檢驗”是一個詞匯,包含“檢驗流程”、“檢驗單位”等,為這種“包含”關系定義 “檢驗父類”進行管理。“檢驗”本身又可表述成“檢查”等,為這種同義詞關系定義 “檢驗近類”進行管理。通過這種詞匯級的語義關系管理,最真實且精確地表達了詞匯本身的含義,從而為精確的語義理解打下基礎,同時為每一種語義設定標準,此分詞稱為標準詞。
此步驟把[A'i=a1,a2,a3,?,aM]中的各個分詞元素替換為標準詞。
2.3 詞向量訓練
Word2vec的訓練模型具有一個隱含層的神經元網絡,輸入詞匯表向量,以詞匯表為參照,對于訓練樣本中的每個詞,若詞存在詞匯表中,則將其在詞匯表中的位置標志置為1,否則置為0。輸出結果是詞匯表向量,對于訓練樣本標簽中的每一個詞,把在詞匯表中出現的位置值置為1,否則置為0,最終將輸入樣本中的詞轉化為128維的向量。
使用Word2vec模型將[S,i]和[A,i]表示為詞向量:
[xi'={ω1,ω2,?,ωn}](i=1,2,…,n)? ? ? ? ? ? ? ? (3)
[aj'={φ1,φ2,?,φm}](j=1,2,…,m)? ? ? ? ? ? ? ? (4)
其中[ωi]和[φi]分別表示詞向量[xi]和[aj]在第i維的向量值,[xi']和[aj']分別表示詞[xi]和詞[aj]由word2vec處理成的詞向量,則[Ai]與[Si]間的詞向量相似度為:
[Sim1(Ai,Si)=i=1nωiφii=1nωi2*i=1nφi2]? (5)
2-gram相似度計算:計算輸入問句和知識中答案對應的問句之間的2-gram相似度前,分別計算[Ai]和[Si]的2-gram序列:
[Aseqi={Bw1,w1w2,?,wn-1wn,wnE}] (6)
[Sseqi={Bw'1,w'1w'2,?,w'n-1w'n,w'nE}] (7)
其中[B]和[E]是特殊符號,分別表示輸入問句(知識庫中答案對應的問句)的開始和輸入問句(知識庫中答案對應的問句)的結束,則[Ai]和[Si]間的2-gram相似度為:
[Sim2(Ai,Si)=|Aseqi?Sseqi||Aseqi?Sseqi|]? ?(8)
搭配相似度計算:在計算輸入問句和答案對應的問句之間搭配相似度前,對輸入問句(知識庫中答案對應的問句)進行搭配分析,獲取輸入問句(知識庫中答案對應的問句)中的搭配對,其中[Acoli]為[Ai]的詞搭配集合,[Scoli]為[Si]的詞搭配集合,則[Ai]和[Si]間的搭配相似度為:
[Sim3(Ai,Si)=|Acoli?Scoli||Acoli?Scoli|]? ? (9)
最終相似度計算:通過多特征的相似度融合算法計算輸入問句與知識庫中答案對應問句的相似度為:
[Sim(Ai,Si)=α1*Sim1(Ai,Si)+α2*Sim2(Ai,Si)+α3*Sim3(Ai,Si)] (10)
其中[α1,α2,α3]分別表示這3種相似度權重,滿足[α1+][α2+α3=1]。
3 系統設計
食品安全問答系統由食品安全知識庫、文本預處理、問句與知識相似度計算以及答案生成4個部分組成。
3.1 食品安全知識庫構建
食品安全知識庫構建是食品安全問答系統的基礎和重要環節。系統通過各種渠道收集食品安全領域知識,對這些知識進行分類和整理后存入數據庫中。每條知識數據包含以下信息:所屬類別、知識庫問句、知識庫答案、知識來源。這些知識包含300個知識庫問句和500個對應的知識庫答案,其中食品安全法律問句80個,對應的食品安全法律答案120個;食品安全常識問句90個,對應的食品安全常識答案140個;偽劣食品防范方法問句70個,對應的偽劣食品防范方法答案130個;食品經銷存儲管理辦法問句60個,對應的食品經銷存儲管理辦法110個。
3.2 文本預處理
(1)對食品安全知識庫中答案對應的問句進行預處理,包括去除標點、停用詞以及分詞等。本文采用的分詞工具為jieba分詞,jieba分詞支持3種分詞模式:將句子作最精確切分的精確模式、掃描出句子中所有可以合成為詞組的全模式、在精確模式上再度切分的搜索引擎模式。
(2)分詞完成后對分詞結果采用術語語義網擴展分詞語義網(semantic web)。語義網是一種描述事物的網絡,運用計算機能理解的方式構建,如圖1所示。
圖1 語義網結構
語義網由7層組成[20],分別為:
(1)Unicode和URI。“統一字符編碼”與“統一資源定位”是語義網的基礎,統一國際編碼格式以實現事物的統一表達。
(2)XML和NS。用XML語言實現數據與形式的剝離,提取出數據,并將表現形式格式化。
(3)RDF和EDF Schema。表示Web上的元數據。
(4)Ontology vocabulary。對數據資源分析,提取出語義信息。
(5)Logic。提供語義推理規則。
(6)Proof。在邏輯層上利用公理進行推理與證明。
(7)Trust。提供信任機制。
本文利用術語語義網對分詞進行擴展,算法如下:
算法1:分詞替換為標準詞算法
輸入:一組分詞question1
輸出:擴展后的分詞組question2
過程:
For each i[∈]question1 do
S = S.replace(i)//用術語語義網進行標準詞替換
End For
擴展后的分詞詞組在食品安全知識庫中不一定能找到答案對應的問句分詞,需要把分詞轉化為標準詞之后再查找答案對應的問句分詞。本文通過近義詞詞典找出標準詞。如“食品檢查”、“食品測試”在近義詞詞典中查找出標準詞為“食品檢驗”。
通過一系列處理將輸入問句拆分成多個詞語組成的集合,為進行基于詞向量的相似度計算作準備。
3.3 問句相似度算法
問句與知識相似度計算是本系統核心功能,計算步驟如下:
算法2:基于近義詞詞向量相似度的問句相似度算法
輸入:食品安全相關問句[Si={x1,x2,?,xN}]
輸出:問句與知識庫中所有答案對應問句的相似度集合[Sim(Ai,Si)]
(1)用戶輸入問句,系統將輸入問句去除標點符號、去除停用詞和分詞。
(2)For each i[∈]Si do
i = i.replace()
End for
//在近義詞詞典中尋找分詞結果中詞匯的近義詞,并替換分詞為標準詞。
(3)For each i[∈]Si do
i = i.Word2vec()
End for
//利用Word2vec工具分別將分詞得到的結果及系統中的知識庫問句轉化為詞向量。
[Sim1(Ai,Si)]
[Sim2(Ai,Si)]
[Sim3(Ai,Si)]
//Sim1為兩者詞向量間的相似度計算。Sim2為構建輸入問句詞集合與系統中知識庫問句集合的2-gram序列,然后用輸入問句詞集合的2-gram序列依次與系統中每一個知識庫問句詞集合的2-gram序列進行相似度計算。Sim3為對輸入問句詞集合與知識庫問句詞集合進行搭配分析,獲得對應的輸入問句詞搭配集與知識庫問句詞搭配集,并依次進行問句與每一個知識庫問句的搭配相似度計算。
[Sim(Ai,Si)=α1*Sim1(Ai,Si)+α2*Sim2(Ai,Si)+α3*Sim3(Ai,Si)]
//綜合考慮多種相似度權重,進行多特征的融合相似度計算,從而得出輸入問句與系統中所有知識庫問句的最終相似度。
3.4 答案返回
用戶輸入問句,系統運用輸入問句與知識庫相似度算法求得輸入問句與知識庫問句相似度,判斷是否匹配(設立相似度閾值,超過閾值即為匹配),按匹配程度進行排序,并將與輸入問句匹配度最高的N個知識庫問句對應的答案返回給用戶。
4 閾值計算
詞向量模型訓練完成后,隨機從測試數據集中抽取兩個答案對應的問句進行相似度計算,得兩個問句的相似度值記為x,真實值為y(相同問句真實值記為1,不同的記為0)。重復此過程n次,則測試數據結果可表示為:
[(X,Y)={(x1, y1),(x2, y2),(x3, y3),?,(xn, yn)}]
滿足:
xi∈[0,1] (1≤i≤n)
yi = 0 or 1 (1≤i≤n)
則閾值[λ]的求取過程可形式化為以下問題:
一個函數:[F(x,λ)=1,xλ0,x<λ]
求:閾值[λ],使得[mini=1n|F(xi,λ)-yi|]
給出定義1:函數
[F(λ)=i=1n|F(xi,λ)-yi|]
在閾值算法計算中,精度P初始值為1000,abs函數用來計算絕對值,過程見算法3。
算法3:閾值計算
輸入:(X,Y),P
輸出:λ
初始化:sum1 = P,sum2 = 0,z = 0
For? each (xi,yi)∈(X, Y)? do
xi = xi×P
yi = yi×P
end for
//把每一個相似度xi,和真實值yi都乘以精
度P,使得xi∈[0,1000],yi=0 or 1000。
For? each i∈[0,1000]? do
For? each (xi,yi)∈(X, Y)? do
If? xi >i :
z=1000
Else :
z=0
T=abs(z-yi)
sum2=sum2 + T
end if
end for
if? sum2 < sum1? then
sum1=sum2
λ=i
end if
end for//i從0開始遍歷到1000,求出定義1函數F(λ)的最小值,同時也求出閾值λ
5 數據集與評估方法
5.1 實驗數據
實驗所用數據來自食品安全知識庫,包括食品安全相關法律、食品安全常識、偽劣食品防范方法和食品經銷存儲管理辦法等4大類共500條食品安全領域知識。
5.2 評估標準
(1)查準率(Precision)。[S]表示食品安全知識問答對,[TN(S)]表示問答系統返回知識中正確答案的個數,[RN(S)]表示問答系統返回所有答案的個數,食品安全問答系統的查準率可表示為:
[P(S)=TN(S)RN(S)] (7)
(2)查全率(Recall)。[S]表示食品安全問答對,[TN(S)]表示問答系統返回知識中正確答案的個數,[AN(S)]表示問答系統中所有正確答案的個數,食品安全問答系統的查全率可表示為:
[R(S)=TN(S)AN(S)] (8)
(3)F1-Measure。[P(S)]表示食品安全問答系統的查準率,[R(S)]表示食品安全問答系統的查全率,食品安全問答系統的F1-Measure可表示為:
[F(S)=2*P(S)*R(S)P(S)+R(S)] (9)
6 實驗
6.1 實驗參數設置
實驗選用詞向量工具word2ve的Skip-gram模型進行詞向量訓練,抽樣匹配數(sample)設置為50 000,相似度閾值(threshold)設為0.6,匹配問句數為3,返回知識數為5,進程數(process_num)為10。
6.2 實驗過程
用戶在系統內輸入所要了解的食品安全問題,問答系統將用戶輸入的問句與食品安全知識庫中的問句進行相似度計算,并將相似程度大于閾值的問句答案返回給用戶,由用戶判斷返回答案中正確答案的個數,實驗評估結果如表2所示。
例句:
食品檢驗歸誰管?
分詞結果:
食品,檢驗,歸誰,管
匹配相似度最高的前3個問句:
食品檢驗由誰負責?
例句與問句1的句子相似度計算結果為0.75。
食品抽樣檢查如何實施?
例句與問句2的句子相似度計算結果為0.65。
食品抽樣檢驗流程是什么?
例句與問句3的句子相似度計算結果為0.62。
最佳結果:食品校驗由誰負責?
返回答案:
知識1:第八十四條?食品檢驗機構按照國家有關認證認可的規定取得資質認定后,方可從事食品檢驗活動。但是,法律另有規定的除外。食品檢驗機構的資質認定條件和檢驗規范,由國務院食品藥品監督管理部門規定。符合本法規定的食品檢驗機構出具的檢驗報告具有同等效力。縣級以上人民政府應當整合食品檢驗資源,實現資源共享。
知識2:第八十五條?食品檢驗由食品檢驗機構指定的檢驗人獨立進行。檢驗人應當依照有關法律、法規的規定,并按照食品安全標準和檢驗規范對食品進行檢驗,尊重科學,恪守職業道德,保證出具的檢驗數據和結論客觀、公正,不得出具虛假檢驗報告。
知識3:第八十六條?食品檢驗實行食品檢驗機構與檢驗人負責制。食品檢驗報告應當加蓋食品檢驗機構公章,并有檢驗人的簽名或者蓋章。食品檢驗機構和檢驗人對出具的食品檢驗報告負責。
知識4:第八十九條?食品生產企業可以自行對所生產的食品進行檢驗,也可以委托符合本法規定的食品檢驗機構進行檢驗。
表2 實驗結果評估
[問句數\&查準率(%)\&查全率(%)\&F1-Measure(%)\&20\&76\&69\&72\&40\&68\&80\&73\&60\&80\&79\&79\&80\&82\&82\&82\&100\&77\&81\&78\&]
知識5:第八十七條?縣級以上人民政府食品藥品監督管理部門應當對食品進行定期或者不定期的抽樣檢驗,并依據有關規定公布檢驗結果,不得免檢。進行抽樣檢驗,應當購買抽取的樣品,委托符合本法規定的食品檢驗機構進行檢驗,并支付相關費用;不得向食品生產經營者收取檢驗費和其它費用。
對于此例句,用戶判斷問答系統返回答案中正確的個數為4,即查準率為80%,用戶重復以上操作,可以得出結論如圖2所示,可以看出基于詞向量相似度的食品安全問答系統在答案的查準率上表現較好。
圖2 實驗結果
7 結語
本文構建了基于詞向量相似度的食品安全問答系統。通過引入近義詞詞典和詞向量相似度概念,使詞匯間的相似度計算變得更加準確。同時設計了基于詞向量的多特征相似度算法,將句子相似度融入輸入問句與食品安全知識庫問句相似度計算,使答案生成更加嚴謹。
通過研究問答系統中問句間的相似性,對詞向量空間構建方法以及語句相似度相關計算方法有了更加深入的了解,對問答系統工作流程有了一定認識。下一步研究工作:通過擴大語料庫規模和更深入挖掘問句中的語義信息等方法,對食品安全問答系統性能和準確率進行改進。
參考文獻:
[1] 毛先領,李曉明. 問答系統研究綜述[J]. 計算機科學與探索, 2012,6(3):193-207.
[2] 于根,李曉戈,劉睿,等. 基于信息抽取技術的問答系統[J]. 計算機工程與設計,2017,38(4):1051-1055.
[3] 秦兵,劉挺,王洋,等. 基于常問問題集的中文問答系統研究[J]. 哈爾濱工業大學學報, 2003, 35(10):1179-1182.
[4] 蘇斐,高德利,葉晨. Web問答系統中問句理解的研究[J]. 測試技術學報,2012,26(3):29-34.
[5] 陶永芹. 專業領域智能問答系統設計與實現[J]. 計算機應用與軟件,2018(5):16-21.
[6] 王燦輝,張敏,馬少平. 自然語言處理在信息檢索中的應用綜述[J]. 中文信息學報,2007,21(2):35-45.
[7] 孫鐵利,劉延吉. 中文分詞技術的研究現狀與困難[J]. 信息技術, 2009(7):187-189.
[8] 常建秋,沈煒. 基于字符串匹配的中文分詞算法的研究[J]. 工業控制計算機,2016, 29(2):115-116.
[9] 蘇勇. 基于理解的漢語分詞系統的設計與實現[D]. 成都:電子科技大學,2011.
[10] 李素建,劉群,張志勇,等. 語言信息處理技術中的最大熵模型方法[J]. 計算機科學,2002,29(7):108-110.
[11] 魏曉寧. 基于隱馬爾科夫模型的中文分詞研究[J]. 電腦知識與技術,2007,4(21):885-886.
[12] 馮連剛. 一種改進的基于N元語法模型的中文分詞方法[J]. 自然科學,2016(10):00284-00287.
[13] SONG M,CHAMBERS T. Text mining with the Stanford CoreNLP[M]. Measuring Scholarly Impact. Springer International Publishing,2014:215-234.
[14] 張志昌,周慧霞,姚東任,等. 基于詞向量的中文詞匯蘊涵關系識別[J]. 計算機工程,2016,42(2):169-174.
[15] 唐明,朱磊,鄒顯春. 基于Word2Vec的一種文檔向量表示[J]. 計算機科學,2016,43(6):214-217.
[16] 熊富林,鄧怡豪,唐曉晟. Word2vec的核心架構及其應用[J]. 南京師范大學學報:工程技術版, 2015(1):43-48.
[17] 王麗月,葉東毅. 面向游戲客服場景的自動問答系統研究與實現[J]. 計算機工程與應用, 2016, 52(17):152-159.
[18] 武永亮,趙書良,李長鏡,等. 基于TF-ID F和余弦相似度的文本分類方法[J]. 中文信息學報,2017,31(5):138-145.
[19] 宋彥,張桂平,蔡東風. 基于N-gram的句子相似度計算技術[C].全國計算語言學學術會議, 2007.
[20] 李潔,丁穎. 語義網關鍵技術概述[J]. 計算機工程與設計, 2007, 28(8):1831-1833.
(責任編輯:杜能鋼)
猜你喜歡
人民論壇·學術前沿(2016年20期)2016-12-06 19:42:59
法制與社會(2016年32期)2016-12-01 14:31:24
職工法律天地·下半月(2016年10期)2016-11-30 11:55:21
中小企業管理與科技·上旬刊(2016年11期)2016-11-28 20:12:30
現代經濟信息(2016年25期)2016-11-24 06:57:41
商場現代化(2016年26期)2016-11-21 00:20:32
新媒體研究(2016年19期)2016-11-18 19:56:49
中國科技博覽(2016年18期)2016-10-19 11:03:18
科技視界(2016年21期)2016-10-17 20:50:50
企業導報(2016年11期)2016-06-16 15:44:24
