自然語言處理中MapReduce原理的應用
2019-10-28 06:39:32李光遠中國人民大學河南
新生代 2019年8期
李光遠.中國人民大學.河南
所謂自然語言處理主要指的就是,針對人和計算機這兩者之間通過自然語言展開合理通信與交流的理論與方式展開詳細研究,其不僅可以為計算機技術的發展起到一定程度的推動作用,還可以為Artificial Intelligence技術的發展起到一定的完善作用,屬于一門將語言、計算機、數學相互結合而來的學科。由于如今計算機網絡中的信息資源一直處于持續增加的狀態,導致互聯網中所儲存的信息數據較為龐大,在針對其中的信息數據展開有效處理時,對于計算機的中央處理器與服務器等部件而言都是一種挑戰,于是就開始在對信息數據展開處理時,經常會在速度、空間與容錯性等多方面出現問題。而MapReduce這種編程模型的誕生,不僅能夠優化計算機中的配置,也能夠提升計算機處理信息數據的實際效率,因此,就需要針對自然語言處理中MapReduce原理的實際應用展開詳細分析,從而確保在如今時代下,對于自然語言處理的準確性與穩定性。
一、MapReduce原理的主要概述
MapReduce自身屬于一種在編程時所應用的模型,通常都是應用在實際規模較大的數據集并行與計算中,其在工作過程中的主要原理如圖1所示:
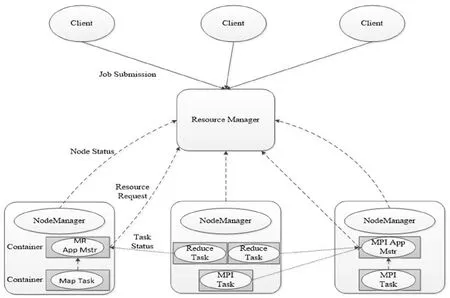
圖1:MapReduce的工作原理
在MapReduce其中的Map所代表的映射,而Reduce所代表的是歸約,這兩者中所蘊含的核心理念都是由編程語言中的函數而來,還具有一些編程語言中矢量特性【1】。在MapReduce中的主要原理在于,集合相關用戶所定義key與value對的輸入處理,再根據中間輸出集合key與value對,并將中間完全相同的key與value相互集合后,傳輸到MapReduce的函數之中,然后在其中的函數就能夠講完全相同的key與value相互合并,最終形成value值較小的集合【2】。在MapReduce這種編程模型實際展開運行的過程中,主要涵蓋了:對大量的輸入信息數據劃分交由多個計算機對其展開處理、通過worker將所有輸入的信息數據分為key與value、通過函數將所有輸入信息數據中的key與value轉換為中間形式、根據key的實際值排列出中間形式中的key與value、將各不相同的key與value交由各不相同的計算機、對Reduce展開實際計算、最終得出Reduce的計算結果【3】。
二、MapReduce原理的格式種類
通過MapReduce所構建的信息數據模型會較為簡單,因為在其中Mao與Reduce的有效函數,能夠充分利用key與value展開合理的輸入或是輸出,但一定要嚴格遵守相應形式【4】。如以下所示:
Map=(k1.v1)→ list(k2.v2)
Reduce=(k2.list(v2))→ list(k3.v3)
在MapReduce這種模型庫中,對于多種格式有所不同種類的輸入數據會提供一定的支持,例如:在文本類型的輸入數據中,每行都會被當做一對key與value,在這其中key所代表的是文本文件所出現的偏移量,而value所代表的是在整個文本中此行的實際內容。而且在MapReduce中預定義類型的輸入方式,不僅可以在真正意義上滿足多種輸入的實際需求,還可以讓應用者充分利用MapReduce所提供的簡單接口,創新一種全新輸入的種類。除此之外,在MapReduce中還包含有預定義類型的輸出方式,充分利用就可以制作出格式各不相同的輸出數據,而且相關用戶還能夠通過增加輸入數據的種類方法,對輸出數據的種類方法展開合理、有效的增加【5】。
三、自然語言處理中MapReduce原理的實際應用
1、索引及MapReduce的構建
構建索引系統是信息檢索系統中最為重要的階段之一。在信息檢索領域中,創建大規模語料庫搞笑的索引是目前而言較為困難的問題之一,而通過使用分布式狂階對廣泛的文本語料庫展開與行化索引,是創建較為合適的索引以及可以方便展開搜索的有效方式。Jeffrey Dean與Sanjay Ghemawat共同完成的Mapreduce學術論文中曾經給出的索引策略是:map函數解析每個文檔,輸出的一系列word、documentID對,reduce函數的數據屬于一種給定word相應的文檔ID,輸出一個《word、document ID》對,所有輸出集合形式就可以形成一個較為簡單的倒排索引,這樣一來通過一種較為簡單的算法就可以準確的尋找出跟蹤詞在文檔中的具體位置。這種策略雖然只是簡單的描寫出了運用MapReduce構建索引的方式,但是卻說明了運用MapReduce可以實現大規模銀鎖構建的可能性,同時也會為相關研究人員在MapReduce中實現文本索引的研究提供了較為有益的研究空間。基于MapReduce模型可以充分實現構建索引,在實際構建的過程中策略為:map函數為文檔中的詞,輸出一個文檔ID對,reduce函數將相同的文檔ID展開合并,通過合并的方式獲得項頻率。這種策略的最大優點是map階段較為簡單,通過將每個詞作為輸出基礎的同時,確保基礎的準確性與穩定性。但是一旦出現一個詞在某個文檔中出現tf次時,就會促使文檔ID中的輸出次數轉變為tf次。這樣一來就會促使map的數據不斷增加,因為語料庫中的每一個詞都會自動升恒一個文檔ID,所以當map任務輸出在多數中間數據中時,這些中間數據就會被全面的保存在設備的本地磁盤C中,而后再通過傳輸的方式傳輸給更加合適reduce任務。大量的map中間數據會不斷增加map至reduce傳輸過程中所使用的網絡流量,同時還會最大幾率的延長排序階段,這些因素最終就會對實際執行的時間造成影響【6】。
2、 聚類算法及Mapreduce
聚類算法屬于一種非監督形式的學習方式,并且該種方式在多數應用中已經被基于廣泛的關注與重視,例如:數據挖掘、文檔搜索、模式識別、機器學習等。在處理大規模數據的過程匯總,傳統的串行聚類算法因速度較慢并且效率較低,就會導致無法充分滿足實際應用的要求,這一因素也是導致大規模數據聚類成為一項具備較高挑戰性工作的主要原因,為了可以有效解決這一問題,就需要通過全面研究的方式,通過研究來設計出高效率、高質量的并行聚類算法。Mapreduce編程模型作為一種具備較強分布式計算的亂加,其可以被廣泛應用到數據聚類領域。通過實際研究可以充分實現基于Mapreduce的并行K-Means聚類,Map函數執行每一個對象到距離自身最近的聚類中心程序,Reduce函數可以執行更新聚類中心的程序。浙江大學的溫程在其說是學位論文中,充分研究出了兩種Mapreduce的聚類算法,分別是并行化譜聚類與并行化AP聚類。并行化譜聚類算法的主要策略是通過計算相似矩陣及稀疏化時根據數據點標識展開切分;在計算特征向量時可以通過講拉普拉斯矩陣存儲到分布式文件系統HDFS上的方式,并通過分布式Lanczos來展開運算,最終得到并行計算的實際特征向量;當通過特征向量的轉置矩陣采用并行K-means聚類時,可以得到準確的聚類結果。并行化AP聚類的策略主要是先將吸引度矩陣與歸屬度矩陣分布式儲存在HB阿瑟上,將每次迭代中度吸引度矩陣與歸屬度矩陣的實際計算通過分割的方式展開,并使其矩陣制的實際運算根據行分布的多臺機器上展開運算【7】。
3、文本分類及Mapreduce
文本的分類是一種具備監督設備學習的有效方式,其主要是基于文本中的內容講待定的文本實際劃分到單一或多個預定的類別中。最初是由Google實驗室所提出的MapReduce秉性分布式計算模型,其主要是針對海量數據展開處理,網絡文檔屬于一個海量數據集,MapReduce編程模型更加適合對大型規模的網絡文檔自動分類工作。特征的選擇屬于文本分類中的一種預處理步驟,其可以充分提文本分類的有效性與效率,多數設備中的學習算法在多數程度上會受到來自文本特征選擇的影響,并且還會直接影響到文本分類的具體運行情況。大規模文本分類特征屬于一種高維度的問題,在并行執行特征的選擇中可以充分實現并行化的運行,在實際研究的過程中可以通過并行運算的方式來提高統計特征的實際選擇效率。在實際運用余弦定理來計算文檔之間的相似度時,可以根據相似度對文檔展開分類,在計算文本相似度的過程中,TF-IDF(term frequency-inverse documet frequency)權重計算方式可以起到即為關鍵的作用。通常情況下TF-IDF會經常性的被應用到搜索引擎中,將其作為用戶與文件查詢之間的相關程度評級以及度量,但是因為實際計算量較大,就需要通過應用Mapreduce來解決TF-IDF中存在的計量大且速度較慢等問題。在實際針對目前彈擊中較大的文本自動分類訓練時,實際分類訓練的時間較長,而在相關研究中的某種設計可以充分實現基于Mapreduce結構框架的并行貝葉斯文本分類算法,并且可以充分運用三個Mapreduce過程來實現并行貝葉斯文本分類算法的訓練。其中,在第一個Mapreduce過程中,每個mapper可以接受來自訓練文檔中的部分數據塊,并且其還可以根據實際訓練快來計算出部分訓練分檔中的詞頻以及文檔的書劉昂,reducer可以針對每個由mapper傳輸的文檔展開計算與統計,并將其存儲至相關數據庫而后作為中間結果;在第二個Mapreduce過程中,每個mapper所接收的第一步Mapreduce所生成的中間數據,通過詞頻的方式針對文檔展開特征方面的抽取,并將儲存后的數據作為中間數據;在第三個Mapreduce過程中,每個由mapper所接收的第二步Mapreduce中間數據,通過實際計算之后可以得出各類別的先驗概率,同事還可以通過文檔中的名詞特征來展開分析,最終就可以得到完整度較高的貝葉斯分類模型【8】。
結束語:
綜上所述,MapReduce自身屬于一種編程模型,其不僅能夠針對大量的信息數據展開有效處理,還能夠從大量的信息數據中及時找到最有價值的相關數據。在MapReduce這種編程模型中,將容錯、負載平衡、同步處理等相關技術中的難點與細節完全封裝,即使是自身缺乏開發相關系統經驗的編程人員,也可以輕易的駕馭并應用這種MapReduce模型。在如今時代下,這種MapReduce的相關原理已經開始在社會各領域廣泛應用,但如今針對MapReduce這種模型的主要研究幾乎都在其的實際應用中,針對計算方式與實際效率等方面的優化研究幾乎是少之又少,因此,就需要加強對于MapReduce計算方面的研究力度,從而為MapReduce的后續發展打下較為堅固的基礎。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
