輸入強化視角下語塊與口譯產出關系研究
2019-10-29 04:08:02閻先寶曹少森
宿州學院學報 2019年9期
閻先寶,曹少森
安徽財經大學文學院,安徽蚌埠,233030
計算科學和信息技術的進步,特別是大數據和云技術的發展,使得語料的收集、語料庫的構建以及大規模處理人類語言數據成為現實,語料庫語言學(Corpus Linguistics)亦隨之應運而生。語料庫語言學是基于語篇語料對語言進行研究的一門科學[1]。其目的是研究語言意義,研究對象為語言使用。語言意義在使用中產生并得以實現。為實現語言意義,當代語料庫語言學家Sinclair認為,言語交際經常使用基于語法的規則型編碼和基于語塊的范例型編碼[2]。其中基于語塊的范例型編碼,屬于預制語言單位的范疇,具有整存整取的心理現實性,在即時交際中無須啟動較多計算資源就能夠被快速提取和運用,從而顯著緩解即時交際壓力,提高交際的流暢度。另外,準確的語塊運用也是交際用語標準關鍵所在。口譯是一種即時性的言語交際行為,因此有理由推斷,語塊使用會對口譯信息輸出產生積極影響。但是,語塊到底會在多大程度上以及如何影響口譯信息的輸出行為仍需要進一步研究。
1 語塊與口譯研究現狀
語塊亦稱詞塊,是指“以固定或半固定預制模塊形式存在于語言使用者詞匯記憶庫中的,被人們在實際言語行為中頻繁使用的,在語義、語用、語言認知和話語結構等方面具有特定語言生成能力的多詞組合”[3]。作為普遍存在于自然語言中且在言語交際中被頻繁使用的基本語言單位,語塊以預制模塊的形式被存儲在大腦記憶中。這些預制模塊由兩個或兩個以上詞項組成,但比零散的單詞語義信息更加豐富。在遇到觸發條件時,這些語塊便以預制模塊的形式被快速從記憶中提取出來并應用于言語交際。這點在閻先寶有關詞匯法的心理語言學研究中得以充分體現,即無論是從“寫入”“存儲”過程來看,還是從“寫出”“加工”過程來看,基于詞匯教學法的語塊理論都符合人類大腦對語言信息進行處理的心理活動規律[4]。Lewis根據詞匯內部語義關系和句法功能將語塊分為單詞和多詞詞匯(words and polywords)、搭配(collocation)、慣用話語(institutionalized utterances)和句子框架和引語(sentence frames and heads)四種類型[5]。Nattinger和DeCarrico根據語塊的結構特點將其分為4類:(1)多元詞結構語塊(polywords),無論是在理解上還是在運用時,總是如同一個單詞一樣被作為整體處理,如as soon as possible,run the risk of等;(2)習慣表達語塊(institutionalized expressions),具體包括言語交際套語和諺語等,如Spare the rod,spoil the child和An apple a day keeps the doctor away等;(3)短語規制架構語塊(Phrasal constraints),這類結構允許內部發生局部調整和變動,部分詞語之間可以進行橫向和縱向的替換和插入,如as far as I know等;(4)句子建構語塊(sentence builders),如as is known to all等[6]。
對于語塊與口譯之間的關系,相關學者開展了多視角的研究。第一個視角是文獻評述類,如崔清夏通過文獻評述的方式總結并反思了西班牙語口譯中存在語塊意識缺失問題[7]。第二個研究視角主要關注譯員的語塊運用特征。如李洋利用PACCEL語料庫,調查了口譯受訓學員的語塊運用特征,發現學生譯員運用最多的是名詞-介詞短語片段,其次是動詞短語片段,最后是依附從句片段[8]。陳惠惠通過小樣本口譯語料,從語塊使用頻率和語法結構類型兩個角度,研究了翻譯碩士的語塊運用特征,發現譯員更多使用3詞語塊,同時存在大量重復使用相同語塊現象。她還發現,與動詞性語塊相比,譯員更多使用名詞性語塊,而其中“NP + of”類語塊出現頻率最高[9]。第三個研究視角聚焦在語塊運用與口譯準確性的關系上。王建華通過為期9周的跟蹤實驗得出結論,認為語塊運用對口譯準確性具有正向預測作用[10]。第四個研究視角主要基于語塊探討口譯模型的建立。張月佳利用溫家寶、李克強等國家領導人在記者招待會上的發言或問答口譯語料,歸納總結了漢語語塊和英語語塊的分類實例,并通過對比分析總結了兩種語言語塊之間的對應關系,進而構建了包含七個步驟的漢英會議口譯模型[11]。第五個研究視角著重關注語塊運用和口譯流利度之間的關系。孫瑜采用實驗研究、調查問卷和學生日記相結合的方法,研究了語塊對口譯學員傳譯流利度的影響,結果發現正確使用語塊的數量和口譯流利程度具有顯著相關性[12]。
綜上所述,翻譯研究界不僅從理論角度回顧了語塊對口譯產出的積極影響,還從實證的角度多方位論證了語塊對口譯的重要作用。然而,針對語塊輸入強化與口譯產出語言之間關系的研究則頗為稀少,有關語塊運用和口譯產出質量的研究尚缺少足夠的實證數據支持,有諸多問題有待進一步研究。例如,語料輸入強化是否能夠提升口譯學員在漢英翻譯過程中使用語塊的數量和頻率?正確語塊的運用與口譯產出質量是否正向相關?本研究將通過對比實驗和訪談的方法,以商務英語專業本科生為研究對象,嘗試性探究和解答這些問題。
2 研究設計
2.1 問題的提出
針對以往研究中存在的不足,本文將重點分析并解答以下兩個問題:
(1)語料輸入強化是否能夠提升譯員在翻譯過程中使用語塊的數量和頻率?
(2)正確語塊的運用與口譯產出質量是否正向相關關系?
2.2 研究語料
語料庫是語料庫語言學研究的基礎;語料收集在語料庫語言學研究中至關重要。按其性質,語料可分為自然語料和引發式語料。前者的獲取可以通過語料庫和實錄法進行;后者則可以通過訪談、日記、報告、話語補全測試、多項選擇測試、分級測試以及角色扮演等諸多方式予以獲取。本文將通過對比實驗和訪談的方法獲取語料。研究語料由兩部分組成:輸入強化語料和口譯測試語料。輸入強化的語料采集自外文出版社出版王燕編著的《英語口譯實務》(2級和3級),以及上海外語教育出版社出版梅德明編著的《中級口譯教程》和《高級口譯教程》。口譯測試材料則采集自外語教學與研究出版社出版徐小貞總主編趙敏懿、劉建珠主編的《商務現場口譯》一書。研究中待譯語料平均句長為82字,段落長度為703詞。
輸入強化(input enhancement)是二語習得研究中的重要概念。該概念于1993年由Sharwood Smith正式提出,其目的在于增加語言習得者從語言“輸入”(input)轉化為語言“攝取吸收”(intake)的機會,主要包括大量輸入(input flood),文本強化(textual enhancement),結構化輸入活動(structured input activity)和提升語法意識任務(grammar consciousness-raising task)[13]。從模態上看,輸入強化有視覺、聽覺和混合輸入強化。為了盡可能讓學生譯員準確理解和把握所接觸的語塊含義,本實驗采用了文本輸入強化和閱讀后解釋討論強化的混合輸入模式。文本輸入強化建立于注意假說(noticing hypothesis)基礎之上。這種做法通過改變輸入信號的視覺特征,提高目標語料的顯著性,從而改變信號接收者的感知方式和加工深度,加速語言習得過程的發生。具體而言,文本輸入強化就是將目標語塊置于相應的文本中,通過加粗、斜體、配色、大寫或者下劃線等方式以提升其顯示度。在閱讀后解釋討論強化過程中,教師則通過對討論過程中所出現的語塊材料予以強化輸出,強化輸出的方法包括并不僅僅局限于對語塊材料進行重讀處理,比如加重語氣、放慢語速、重復或者讓研究對象辨識并運用語塊進行即興造句演講等諸多方式予以實施。本研究將主要采用文本輸入強化的做法,一方面可以營造真實的語塊使用語境,另一方面也可以檢驗文本輸入強化在口譯能力培養中的信度和效度。
2.3 實驗步驟
第一步,對擬選定的被試者進行背景訪談。訪談包含三個問題:(1)你是否參加過專門的口譯培訓?(2)你是否有過口譯工作經歷?(3)你是否聽說過語塊這個術語?凡是對此3個問題回答均是否定的同學才會被選定為研究對象。經過此輪訪談,最終確定60名商務英語專業大三的學生參加實驗。他們平均年齡約為20歲,上下浮動年齡差為1歲以內,因而基本上排除年齡因素所造成的領悟力對本實驗可能產生的影響。
第二步,將選定被試者隨機分配到參照組和實驗組,從而盡可能避免個體差異對實驗結果產生可能的影響。
第三步,對輸入所用語料進行分類處理。參照組使用的語塊輸入語料沒有經過任何特殊加工,而實驗組所使用的語料則經過了目標語塊顯示度提升處理,即所有目標語塊均被加黑、加粗、大寫并配有下劃線。
第四步,開展為期15周的語塊輸入強化實驗。參照組每周會被要求閱讀5篇含有目標語塊但未經特殊處理的語料。閱讀分5次進行,每次閱讀一篇,閱讀完成后,需回答4到5個有關文章理解的問題,限定時間為15分鐘。實驗組每周也需要閱讀5篇含有目標語塊但經過加黑、加粗、大寫并配有下劃線等顯示度提升處理的材料。閱讀同樣分5次進行,每次閱讀完一篇,需用大約5分鐘時間來回顧和討論所遇到的語塊,回答4到5個有關文章理解的問題爾后,兩者時間相加同樣被限定在15分鐘以內。
第五步,口譯測試與數據收集。口譯測試被安排在學校專用語言實驗室內分批次舉行。為避免研究對象之間彼此干擾,被試的座位均經過精心安排,相互之間的前后左右距離均被控制在2米左右。測試開始之前,主考老師還特地安排了時長約一分鐘的暖場聽力材料,一方面為了測試調試設備,調整音量,另一方面也為被試提供了一些適應性刺激,以利于實驗對象盡快進入被測試狀態。測試材料的正式播放以意思相對完整的句段為單位,并留有合理的記錄和翻譯時間(約50秒)。測試結束后,對口譯錄音進行轉寫時,每一份音頻材料均由兩位學生和一位專業教師共同負責。
3 結果與討論
3.1 輸入強化與口譯產出中的語塊運用
本部分要解決的研究問題是:語料輸入強化是否能夠提升口譯學員在翻譯過程中使用語塊的數量和頻率?
要回答該問題,首先需要解決如何認定研究對象口譯產出中的語塊問題。研究借鑒了Wray和Perkins提出的界定語塊的影響因素,即多詞單位是否連續或者相鄰,是否具備完整和固定的語法結構,多詞系列內部的單詞是否可變等[14],同時還參考了Nattinger和DeCarrico有關語塊的分類做法[6]。
根據設定的語塊認定標準,由兩位具備語塊專業知識的教師共同對口譯轉寫文稿中出現的語塊進行統計。統計過程中,錯誤的語塊被剔除。錯誤語塊的界定以是否存在語法錯誤和搭配錯誤為根據。第一類錯誤語塊或違反語法規則(如is happened to),或發生功能詞使用錯誤(如concentrate in)。第二種錯誤語塊不存在語法問題,但存在修飾語使用不當的問題,例如a wealthy variety of。在經過為期15周的輸入處理后,參照組和實驗組在完成口譯測試任務時正確運用的語塊數量統計見表1。

表1 口譯產出中正確語塊使用統計
由表1可知,實驗組在口譯過程中產出正確使用的語塊數量均值為45.38,參照組則為36.45,兩者相差接近9個。為進一步驗證二者之間的差距是否具有顯著性,需對兩組數據進行獨立樣本檢驗。方差方程的Levene檢驗的Sig.值為0.94,大于0.5,說明實驗組和參照組在語塊使用上的數據符合方差齊性條件。均值方程t檢驗的Sig.值為0.003,小于0.05,說明兩組在正確語塊的平均使用數量上具有顯著性差距。由此可以得出實驗結論,語塊輸入強化能夠提升研究對象在翻譯過程中使用語塊的數量和頻率。
3.2 正確語塊的運用與口譯產出質量
為了更為準確地獲取口譯產出質量數據,特邀請兩位多年從事口譯教學和研究的一線教師,綜合考慮轉寫文本和口譯錄音,并根據語言信息點進行評分。參評老師首先共同閱讀和討論評分標準,然后一起評判4位研究對象的口譯錄音和轉寫譯文,以便進一步了解和掌握如何運用評分規則,盡最大可能減少自由裁量所帶來的不利影響。經檢驗,兩位老師的評分相關系數達到0.90,具有較高的信度,故決定取二者評分的均值作為受試者的最后得分。
接下來運用Excel中的RAND函數從參與實驗的60名受試中隨機選出31名,然后利用Excel制表,根據受試的口譯成績排名和在完成口譯任務過程中運用的正確語塊的數量,繪制出如下正確語塊使用量走勢圖。
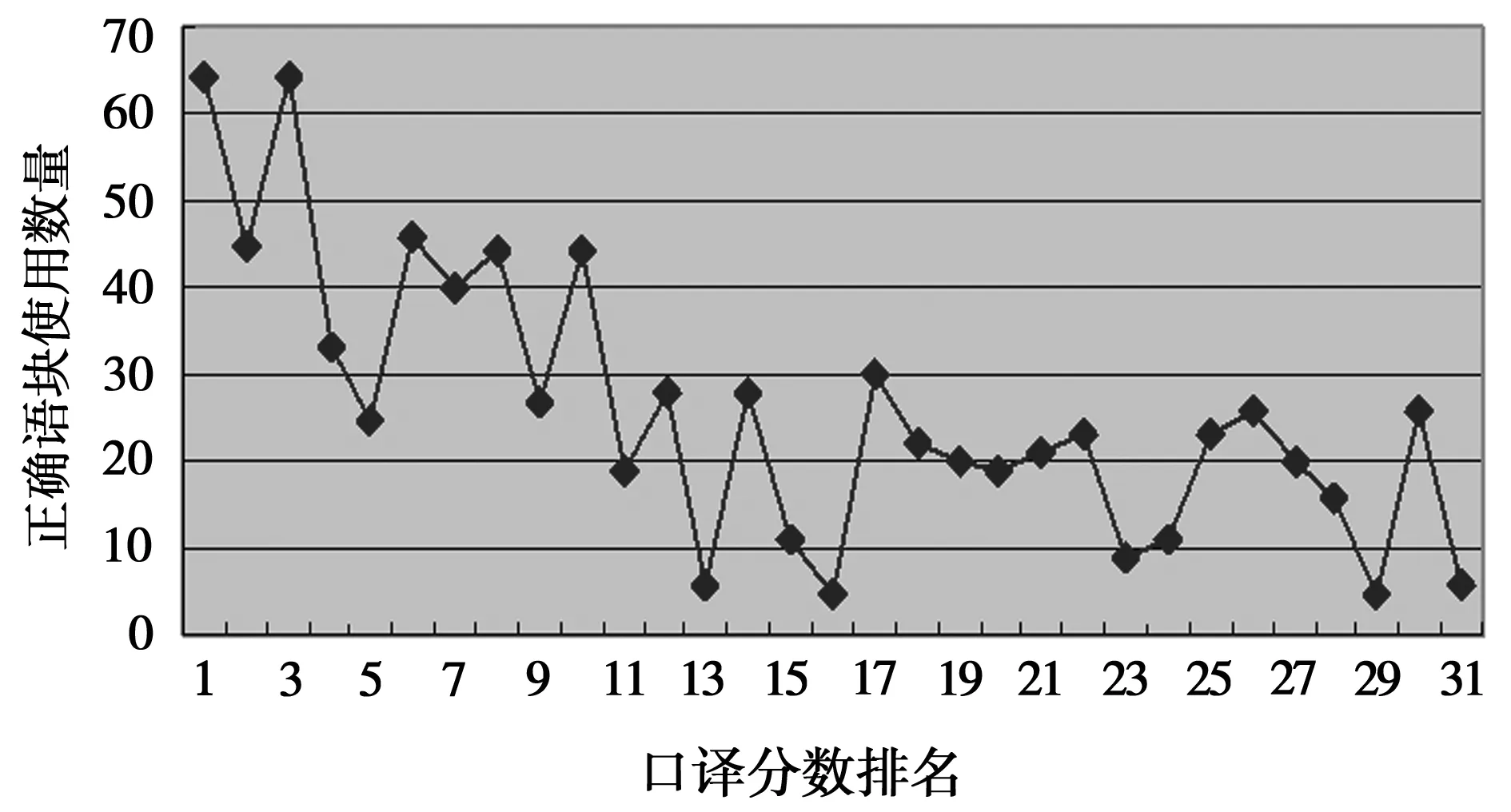
圖1 正確語塊使用量走勢
根據圖1可以看出,隨著研究對象所得分數排名的逐步下降,其在口譯考試過程中所能正確使用語塊的量整體上也呈下降趨勢。這在一定程度可以說明研究對象語塊的使用量,尤其是其正確使用語塊的量和口譯質量的高低呈正向相關關系。但曲線的波動和極端值的出現也意味著,正確語塊的運用數量對口譯產出質量并不具有完全的預測能力。因此該實驗結果尚不能完全支持王建華所得出的研究結論,即語塊運用對口譯準確性具有正向預測作用[9]。也就是說,盡管正確語塊的運用和口譯質量變化整體上呈正向相關關系,但卻不能由此簡單地推論出正確語塊使用越多口譯質量就越高這一結論。比如,口譯分數排名第三的研究對象,雖然其正確使用語塊數量跟第一名幾乎一致,也比排名第二的研究對象正確使用語塊數量多近25%,但是其分數還是不及排名第一、第二的研究對象。再比如口譯分數排名第三十的研究對象,雖然其正確語塊語塊使用數量高達近30個,排名大約在前50%,但是其分數卻在31位研究對象中排名后10%。對此可能解釋為,語塊輸入強化實驗雖然有助于增強譯員的語塊輸出意識,但是在多大程度上能真正轉化為對所強化輸入語塊“攝取吸收”仍值得商榷。
4 結 語
在口譯產出過程中,譯員需要動用多渠道資源,同時進行多項任務加工,因而承擔著繁重的認知負荷。在這種情況下,語塊所具備的整體提取和快速產出的優點可以大大降低大腦對言語信息進行即時處理的負荷,不論是從理論上還是從實踐中都能夠對口譯行為產生積極影響。但這種影響的具體表現形態是什么?如果語塊對口譯確實有積極影響的話,那么又如何更加充分發揮語塊在口譯譯員培養中的作用?這都是有待進一步挖掘和研究的話題。本研究以輸入強化和基于語塊的詞匯教學法為理論依據,以英語專業大三本科生為研究對象,通過綜合運用對比實驗和訪談的研究方法,發現語塊輸入強化能夠顯著提升口譯學員在翻譯過程中使用語塊的數量和頻率,且其正確使用語塊數量跟他們的口譯成績呈正向相關關系。這些發現對以后無論是口譯人才的培養還是筆譯人才的培養均具有重要啟示。首先,應該建立起大量可靠的語塊學習語料庫。其二,需要采取恰當措施對語料庫中的語塊進行顯示度提升處理,以增加相關語塊的曝光度,進而提升它們被學生譯員捕捉到并進行深加工的概率,從而提升目的語在譯員口譯過程中的流利度和自然度。傳統文化“走出去”戰略的實施離不開外宣書刊的翻譯與傳播[15],也離不開廣大口譯人員的辛勤耕耘。兩者相得益彰,均有助于傳播中國文化,提高中華文化在全世界的影響力,進而提升我國文化軟實力。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
文苑(2020年4期)2020-05-30 12:35:30
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
汽車工程學報(2017年2期)2017-07-05 08:13:02
瘋狂英語·新策略(2017年8期)2017-05-31 08:13:46
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
